Pytorch Note25 深層神經網路實作 MNIST 手寫數字分類
文章目錄
- Pytorch Note25 深層神經網路實作 MNIST 手寫數字分類
- MNIST 資料集
- 多分類問題
- softmax
- 交叉熵
- 多層全連接神經網路實作 MINST 手寫數字分類
- 資料預處理
- 簡單的四層全連接神經網路
- 定義loss 函式
- 訓練網路
- 畫出 loss 曲線和 準確率曲線
全部筆記的匯總貼: Pytorch Note 快樂星球
MNIST 資料集
mnist 資料集是一個非常出名的資料集,基本上很多網路都將其作為一個測驗的標準,其來自美國國家標準與技術研究所, National Institute of Standards and Technology (NIST), 訓練集 (training set) 由來自 250 個不同人手寫的數字構成, 其中 50% 是高中學生, 50% 來自人口普查局 (the Census Bureau) 的作業人員,一共有 60000 張圖片, 測驗集(test set) 也是同樣比例的手寫數字資料,一共有 10000 張圖片,
每張圖片大小是 28 x 28 的灰度圖,如下
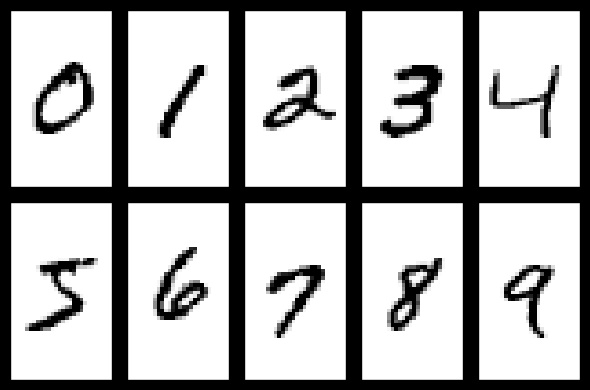
所以我們的任務就是給出一張圖片,我們希望區別出其到除錯于 0 到 9 這 10 個數字中的哪一個,
多分類問題
前面我們講過二分類問題,現在處理的問題更加復雜,是一個 10 分類問題,統稱為多分類問題,對于多分類問題而言,我們的 loss 函式使用一個更加復雜的函式,叫交叉熵,
softmax
提到交叉熵,我們先講一下 softmax 函式,前面我們見過了 sigmoid 函式,如下
s
(
x
)
=
1
1
+
e
?
x
s(x) = \frac{1}{1 + e^{-x}}
s(x)=1+e?x1?
可以將任何一個值轉換到 0 ~ 1 之間,當然對于一個二分類問題,這樣就足夠了,因為對于二分類問題,如果不屬于第一類,那么必定屬于第二類,所以只需要用一個值來表示其屬于其中一類概率,但是對于多分類問題,這樣并不行,需要知道其屬于每一類的概率,這個時候就需要 softmax 函式了,
softmax 函式示例如下
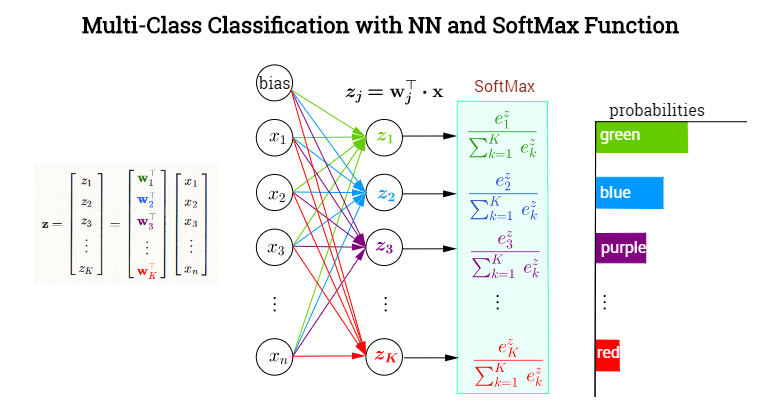
對于網路的輸出 z 1 , z 2 , ? z k z_1, z_2, \cdots z_k z1?,z2?,?zk?,我們首先對他們每個都取指數變成 e z 1 , e z 2 , ? ? , e z k e^{z_1}, e^{z_2}, \cdots, e^{z_k} ez1?,ez2?,?,ezk?,那么每一項都除以他們的求和,也就是
z i → e z i ∑ j = 1 k e z j z_i \rightarrow \frac{e^{z_i}}{\sum_{j=1}^{k} e^{z_j}} zi?→∑j=1k?ezj?ezi??
如果對經過 softmax 函式的所有項求和就等于 1,所以他們每一項都分別表示屬于其中某一類的概率,
交叉熵
交叉熵衡量兩個分布相似性的一種度量方式,前面講的二分類問題的 loss 函式就是交叉熵的一種特殊情況,交叉熵的一般公式為
c r o s s _ e n t r o p y ( p , q ) = E p [ ? log ? q ] = ? 1 m ∑ x p ( x ) log ? q ( x ) cross\_entropy(p, q) = E_{p}[-\log q] = - \frac{1}{m} \sum_{x} p(x) \log q(x) cross_entropy(p,q)=Ep?[?logq]=?m1?x∑?p(x)logq(x)
對于二分類問題我們可以寫成
? 1 m ∑ i = 1 m ( y i log ? s i g m o i d ( x i ) + ( 1 ? y i ) log ? ( 1 ? s i g m o i d ( x i ) ) -\frac{1}{m} \sum_{i=1}^m (y^{i} \log sigmoid(x^{i}) + (1 - y^{i}) \log (1 - sigmoid(x^{i})) ?m1?i=1∑m?(yilogsigmoid(xi)+(1?yi)log(1?sigmoid(xi))
這就是我們之前講的二分類問題的 loss,當時我們并沒有解釋原因,只是給出了公式,然后解釋了其合理性,現在我們給出了公式去證明這樣取 loss 函式是合理的
交叉熵是資訊理論里面的內容,這里不再具體展開,更多的內容,可以看到下面的鏈接
下面我們直接用 mnist 舉例,講一講深度神經網路
多層全連接神經網路實作 MINST 手寫數字分類
“Talk is cheap, show me the code”,下面我們用深度學習的入門級資料集 MNIST 手寫體分類來說明一下更深層神經網路的優良表現,
資料預處理
首先需要進行資料預處理,就像之前介紹的,需要將資料標準化,這里運用到的函式是torchvision.transforms,它提供了很多圖片預處理的方法,這里使用兩個方法:第一個是transforms.Torensor(),第二個是transforms.Normalize()
transform. ToTensor()很好理解,就是將圖片轉換成PyTorch中處理的物件Tensor,在轉化的程序中PyTorch自動將圖片標準化了,也就是說Tensor的范圍是0~1接著我們使用transforms.Normalize(),需要傳人兩個引數:第一個引數是均值,第二個引數是方差,做的處理就是減均值、再除以方差,
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5,0.5])])
這里transforms.Compose()將各種預處理操作組合到一起,transforms.Normalize([0.5],[0.5])表示減去0.5再除以0.5,這樣將圖片轉化到了-1~1之間,注意因為圖片是灰度圖,所以只有一個通道,如果是彩色的圖片,有三通道,那么用transforms.Normalize([a, b, c],[d, e,f])來表示每個通道對應的均值和方差,
然后讀取資料集
# 使用內置函式下載 mnist 資料集
train_set = mnist.MNIST('./data', train=True, download=True)
test_set = mnist.MNIST('./data', train=False, download=True)
train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True) # 重新載入資料集,申明定義的資料變換
test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True)
from torch.utils.data import DataLoader
# 使用 pytorch 自帶的 DataLoader 定義一個資料迭代器
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)
通過PyTorch的內置函式torchvision.datasets.MNIST匯入資料集,傳入資料預處理,前面介紹了如何定義自己的資料集,之后會用具體的例子說明,接著使用torch.utils.data.Dataloader建立一個資料迭代器,傳人資料集和batch_size,通過shuffle=True來表示每次迭代資料的時候是否將資料打亂,
使用這樣的資料迭代器是非常有必要的,如果資料量太大,就無法一次將他們全部讀入記憶體,所以需要使用 python 迭代器,每次生成一個批次的資料
簡單的四層全連接神經網路
# 使用 Sequential 定義 4 層神經網路
net = nn.Sequential(
nn.Linear(784, 400),
nn.ReLU(),
nn.Linear(400, 200),
nn.ReLU(),
nn.Linear(200, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
net
Sequential( (0): Linear(in_features=784, out_features=400, bias=True) (1): ReLU() (2): Linear(in_features=400, out_features=200, bias=True) (3): ReLU() (4): Linear(in_features=200, out_features=100, bias=True) (5): ReLU() (6): Linear(in_features=100, out_features=10, bias=True) )
在這個神經網路中,我們用了ReLU這個激活函式,注意我們的輸出層是不用激活函式的,因為輸出的結果表示的是實際的得分
定義loss 函式
交叉熵在 pytorch 中已經內置了,交叉熵的數值穩定性更差,所以內置的函式已經幫我們解決了這個問題
# 定義 loss 函式
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), 1e-1) # 使用隨機梯度下降,學習率 0.1
訓練網路
# 開始訓練
losses = []
acces = []
eval_losses = []
eval_acces = []
for e in range(20):
train_loss = 0
train_acc = 0
net.train()
since = time.time()
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 前向傳播
out = net(im)
loss = criterion(out, label)
# 反向傳播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 記錄誤差
train_loss += loss.item()
# 計算分類的準確率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
losses.append(train_loss / len(train_data))
acces.append(train_acc / len(train_data))
# 在測驗集上檢驗效果
eval_loss = 0
eval_acc = 0
net.eval() # 將模型改為預測模式
for im, label in test_data:
im = Variable(im)
label = Variable(label)
out = net(im)
loss = criterion(out, label)
# 記錄誤差
eval_loss += loss.item()
# 記錄準確率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)))
epoch: 0, Train Loss: 0.523102, Train Acc: 0.830007, Eval Loss: 0.216174, Eval Acc: 0.928501 epoch: 1, Train Loss: 0.171620, Train Acc: 0.946562, Eval Loss: 0.133545, Eval Acc: 0.959553 epoch: 2, Train Loss: 0.115787, Train Acc: 0.964086, Eval Loss: 0.108396, Eval Acc: 0.966278 epoch: 3, Train Loss: 0.094116, Train Acc: 0.970566, Eval Loss: 0.114743, Eval Acc: 0.965487 epoch: 4, Train Loss: 0.076188, Train Acc: 0.976046, Eval Loss: 0.105246, Eval Acc: 0.966080 epoch: 5, Train Loss: 0.063090, Train Acc: 0.979711, Eval Loss: 0.103882, Eval Acc: 0.966278 epoch: 6, Train Loss: 0.053535, Train Acc: 0.982576, Eval Loss: 0.266303, Eval Acc: 0.928105 epoch: 7, Train Loss: 0.047297, Train Acc: 0.984525, Eval Loss: 0.073833, Eval Acc: 0.978244 epoch: 8, Train Loss: 0.037940, Train Acc: 0.987440, Eval Loss: 0.082854, Eval Acc: 0.975079 epoch: 9, Train Loss: 0.032827, Train Acc: 0.989023, Eval Loss: 0.096227, Eval Acc: 0.972310 epoch: 10, Train Loss: 0.030245, Train Acc: 0.989839, Eval Loss: 0.088784, Eval Acc: 0.974090 epoch: 11, Train Loss: 0.026338, Train Acc: 0.991071, Eval Loss: 0.069644, Eval Acc: 0.979529 epoch: 12, Train Loss: 0.021635, Train Acc: 0.992954, Eval Loss: 0.070802, Eval Acc: 0.981013 epoch: 13, Train Loss: 0.018965, Train Acc: 0.993820, Eval Loss: 0.069541, Eval Acc: 0.980222 epoch: 14, Train Loss: 0.016696, Train Acc: 0.994486, Eval Loss: 0.086337, Eval Acc: 0.975277 epoch: 15, Train Loss: 0.013487, Train Acc: 0.995836, Eval Loss: 0.081004, Eval Acc: 0.979925 epoch: 16, Train Loss: 0.013038, Train Acc: 0.995985, Eval Loss: 0.064988, Eval Acc: 0.982793 epoch: 17, Train Loss: 0.008298, Train Acc: 0.997451, Eval Loss: 0.071038, Eval Acc: 0.981507 epoch: 18, Train Loss: 0.012613, Train Acc: 0.996169, Eval Loss: 0.090065, Eval Acc: 0.977057 epoch: 19, Train Loss: 0.011836, Train Acc: 0.995969, Eval Loss: 0.086559, Eval Acc: 0.977453
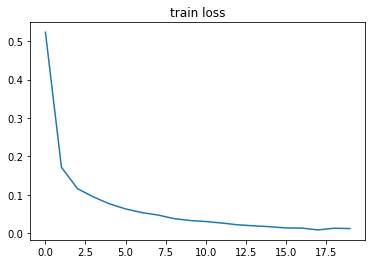
畫出 loss 曲線和 準確率曲線
import matplotlib.pyplot as plt
%matplotlib inline
plt.title('train loss')
plt.plot(np.arange(len(losses)), losses)
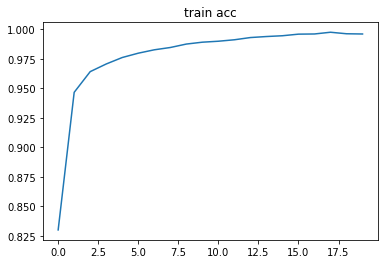
plt.plot(np.arange(len(acces)), acces)
plt.title('train acc')
plt.plot(np.arange(len(eval_losses)), eval_losses)
plt.title('test loss')
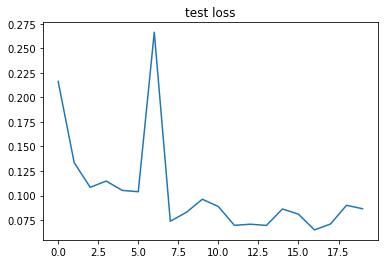
plt.plot(np.arange(len(eval_acces)), eval_acces)
plt.title('test acc')
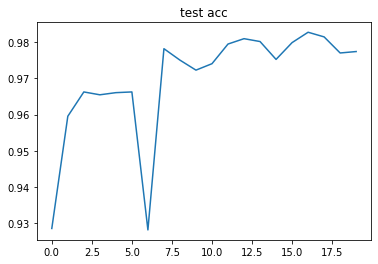
可以看到我們的四層網路在訓練集上能夠達到 99.9% 的準確率,測驗集上能夠達到 97.70% 的準確率
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289471.html
標籤:AI
上一篇:Java版人臉檢測詳解上篇:運行環境的Docker鏡像(CentOS+JDK+OpenCV)
下一篇:人工智能基礎-數學知識之線性代數