文章目錄
- 概述
- 基本概念
- 基本架構
- 資料模型
- Region的橫向切分
- 資料讀寫流程
- 寫流程
- 讀流程
- 檔案合并
- Minor compact
- Major compact
- 資料真正洗掉
- 命令列與客戶端
- 命令列
- 客戶端
- Hbase 優化
- 高可用
- rowKey
- 預磁區
- 記憶體
- hdfs相關
- 客戶端相關
- Hbase & Hive
- 搭建
- 使用
- 關聯
- 分析
- 應用場景
- 微博實戰
- 表設計
- 重點 粉絲關系
- 基于上面的設計 - 高表
- 另一種設計 - 寬表
- 參考文章
概述
- Hbase官網
- 相關代碼
- 基于hdfs的開源、分布式、非關系K-V 資料庫
- 數十億行 X 數百萬列,進行隨機、實時讀/寫訪問
- 通過時間戳控制版本,回傳最新版本資料
- 讀流程比寫流程慢
- 資料沒有型別,都以byte陣列存盤
- 資料自動分片
基本概念
| Hbase | mysql |
|---|---|
| namespace (命名空間) | 庫 |
| table:創建表時,只需要指定列族即可,列可以動態增加 | 表 |
| 列族 | - |
| 列 | 列 |
| row-key:資料通過rowKey查詢和修改 | 主鍵 |
基本架構
- Zookeeper:管理元資料資訊
- Hmaster
- Region Server

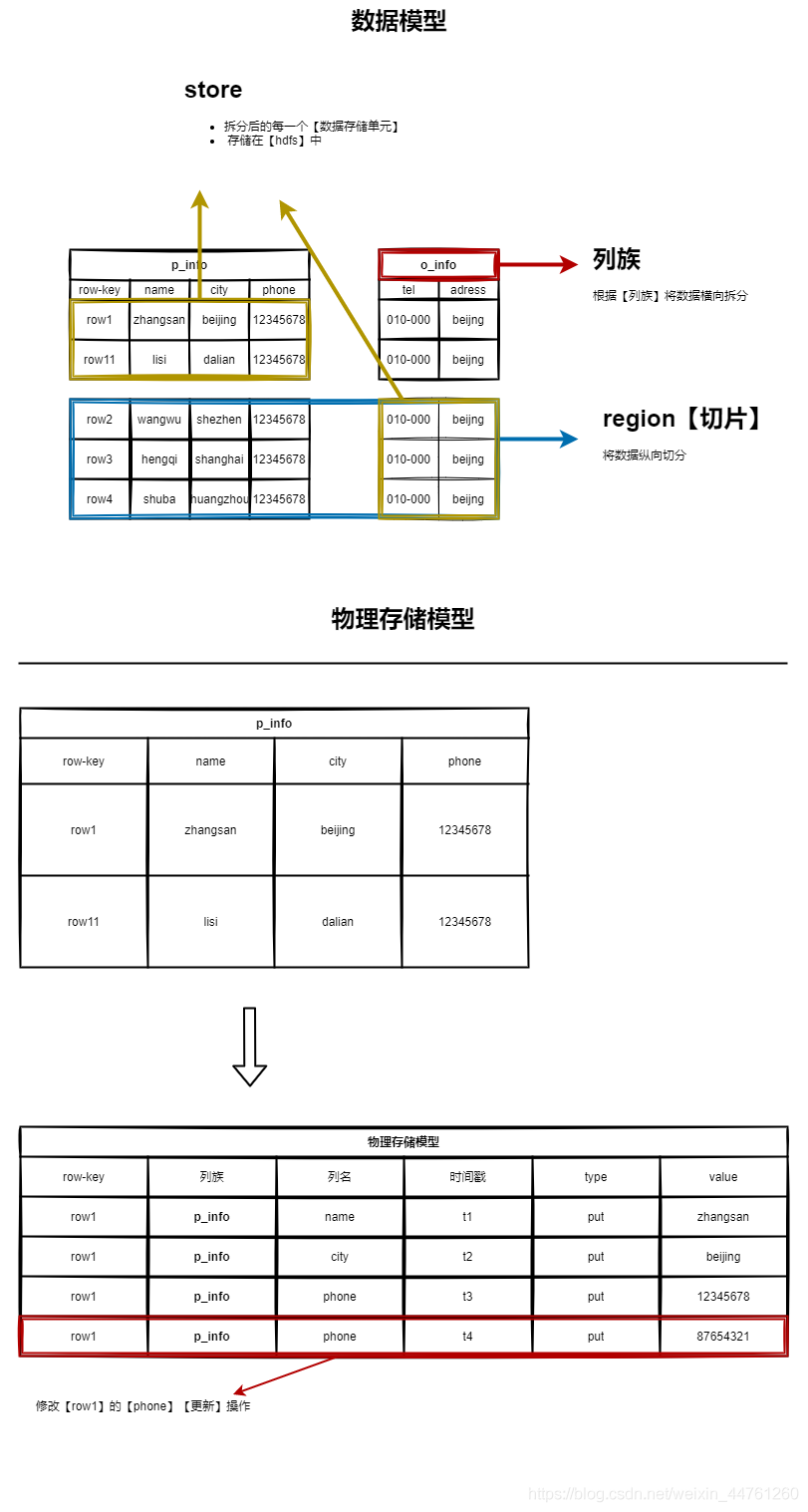
資料模型
Region的橫向切分
- 自動切分:當
Region中store中的檔案超過計算公式時,會自動切分Region - 手動規劃:建表的時候,手動規劃磁區,見優化內容
資料讀寫流程
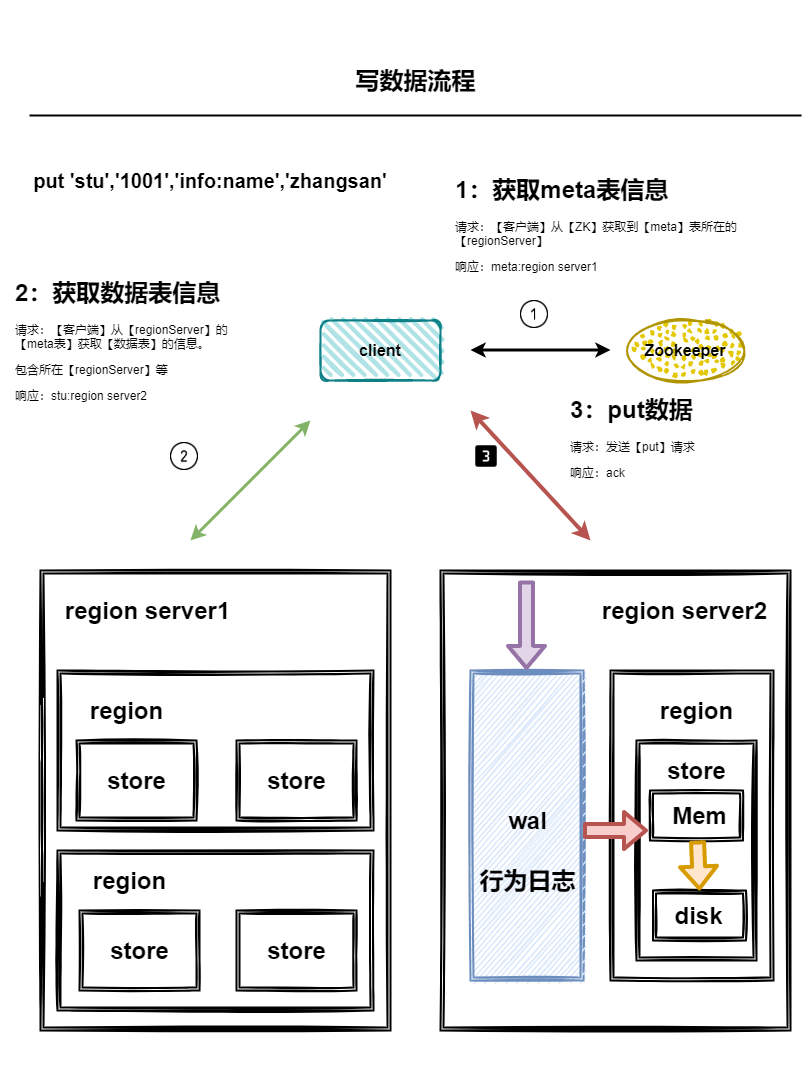
寫流程
- 客戶端從zk獲取meta表所在regionServer
- 客戶端從meta表中獲取資料表所在regionServer
- 客戶端從資料表所在regionServer寫入資料
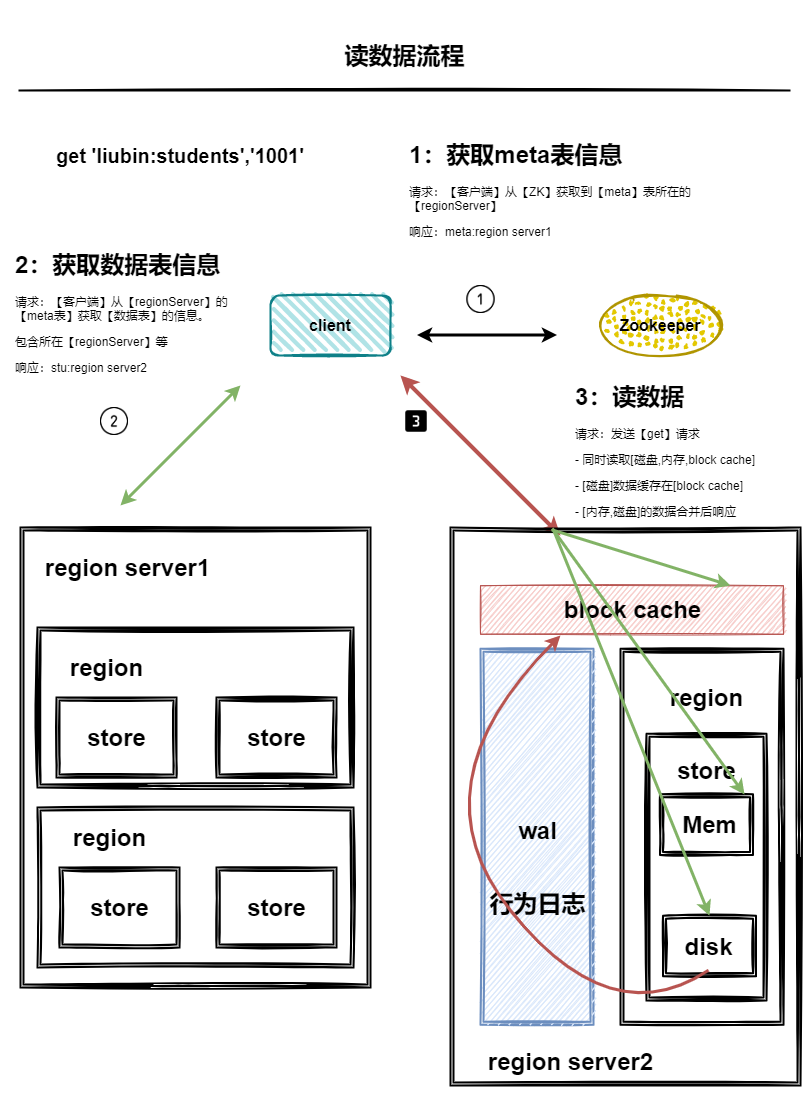
讀流程
- 客戶端從zk獲取meta表所在regionServer
- 客戶端從meta表中獲取資料表所在regionServer
- 同時讀取
磁盤記憶體block cache的資料,進行合并 - 同時把
磁盤的資料快取到block cache - 回傳時間戳最大的
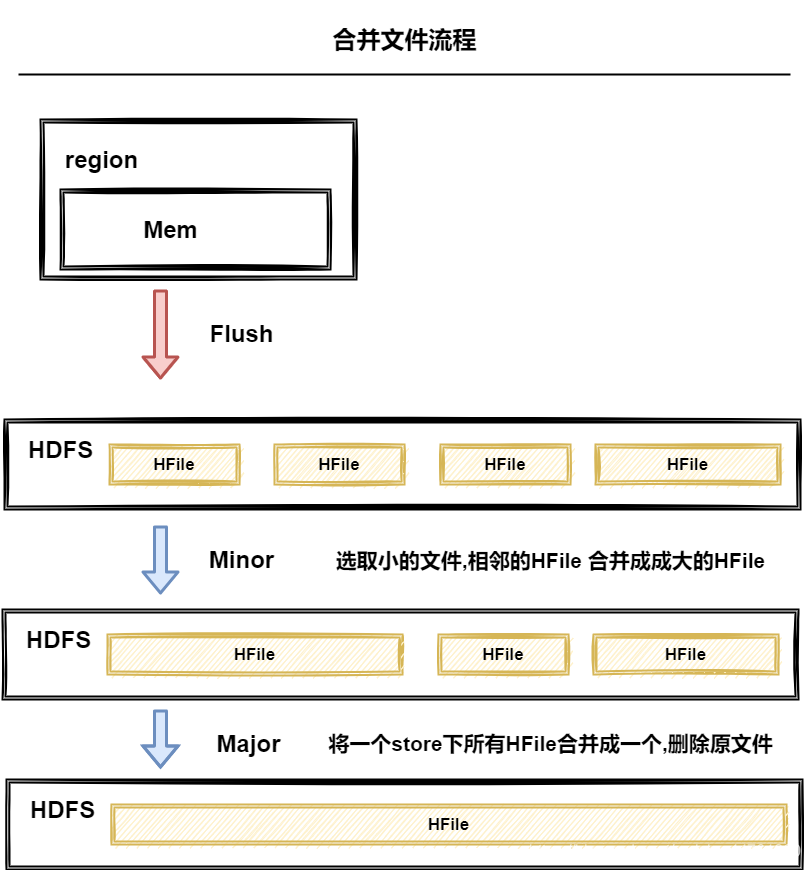
檔案合并
Minor compact
- 小合并
Major compact
- 大合并,需要rewrite資料檔案
- 洗掉原檔案和資料
資料真正洗掉
- Hbase以時間戳控制資料版本,洗掉的資料只是被標記為DELETE
flush時:洗掉記憶體中的被洗掉的資料Major Compact時:洗掉所有被洗掉的資料
命令列與客戶端
命令列
# 獲取所有命令
help
# 獲取get命令的使用詳細
help 'get'
客戶端
<!-- Java 客戶端 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.2</version>
</dependency>
final Scan scan = new Scan();
// 篩選sex='男'的資料
final Filter filter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("sex"), CompareOperator.EQUAL, new RegexStringComparator("男"));
scan.setFilter(filter);
// 預設10個磁區,會把【0-9】平均分成10個
admin.createTable(descriptor, Bytes.toBytes("000|"), Bytes.toBytes("009|"), 10);
Hbase 優化
高可用
- 熱備Master:自帶,直接啟動Master即可
rowKey
- 設計原則:散列性,唯一性,長度
- Hbase 只能通過 RowKey 單行查詢、掃描一段 rowKey或者全表掃描
- 所以,rowKey 的設計十分重要,需要查詢的欄位要拼接在 rowKey 中
- 越高頻的查詢欄位排列越靠左
預磁區
- 手動指定
-- 創建staff1,手動預設五個磁區,根據【rowkey】的【字典序】進到不同的【Region】
create 'staff1','info',SPLITS => ['1000','2000','3000','4000']
- 檔案規則
-- splits.txt
aaaa
bbbb
cccc
dddd
-- 檔案內部會自動排序
create 'staff3','partition3',SPLITS_FILE => 'splits.txt';
- 16進制磁區
-- hash磁區(少用)
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO =>'HexStringSplit'}
記憶體
- 記憶體建議:不建議過大,【16-48G】
- 如果記憶體過大,flush 時間會過長,影響集群使用
hdfs相關
- 允許 hdfs 追加寫
- dataNode的 允許最大檔案打開數
- 增加 資料操作的等待時間
- 開啟壓縮
- HStore大小【默認:10G】
客戶端相關
- 優化客戶端快取:批量put,會在客戶端快取,然后批量RPC
scan.next()一次回傳的條數- -RPC監聽數量,和 客戶端連接數 有關
Hbase & Hive
搭建
- 軟連接需要使用的jar
ln -s $HBASE_HOME/lib/hbase-common-2.4.2.jar $HIVE_HOME/lib/hbase-common-2.4.2.jar
ln -s $HBASE_HOME/lib/hbase-server-2.4.2.jar $HIVE_HOME/lib/hbaseserver-2.4.2.jar
ln -s $HBASE_HOME/lib/hbase-client-2.4.2.jar $HIVE_HOME/lib/hbase-client-2.4.2.jar
ln -s $HBASE_HOME/lib/hbase-protocol-2.4.2.jar $HIVE_HOME/lib/hbase-protocol-2.4.2.jar
ln -s $HBASE_HOME/lib/hbase-it-2.4.2.jar $HIVE_HOME/lib/hbase-it2.4.2.jar
ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-2.4.2.jar $HIVE_HOME/lib/hbase-hadoop2-compat-2.4.2.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-2.4.2.jar $HIVE_HOME/lib/hbase-hadoop-compat-2.4.2.jar
- 修改hive 組態檔
<property>
<name>hive.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
使用
關聯
- Hbase 和 Hive 同時建表,資料可以自動同步
CREATE TABLE hive_hbase_emp_table
(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate STRING,
sal DOUBLE,
comm DOUBLE,
deptno INT
)
-- 指定hbase
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-- 指定欄位的映射關系
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
-- 指定hbase 的表名
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
-- 插入資料
INSERT INTO hive_hbase_emp_table
SELECT *
FROM emp;
分析
- Hbase 已經存在表,Hive建立一個外部表關聯,可以借助 Hive 分析 Hbase 的資料
-- 外部表
CREATE EXTERNAL TABLE hive_hbase_stu
(
id INT,
name STRING,
sex STRING,
height DOUBLE,
addr STRING,
math INT
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:sex,info:height,info:addr,exam:math")
TBLPROPERTIES ("hbase.table.name" = "liubin:stu");
SELECT
sex,
COUNT(*)
FROM hive_hbase_stu
GROUP BY sex;
應用場景
- 阿里云相關案例
微博實戰
- 相關代碼
- 發微博,洗掉
- 關注用戶,取關
- 獲取關注人的微博
表設計
- weibo-content 微博內容表
- rowKey:用戶id+時間戳
- 包含微博內容
- weibo-user 用戶表
- rowKey:磁區建+用戶id
- 包含個人資訊
- weibo-relations 用戶關注表
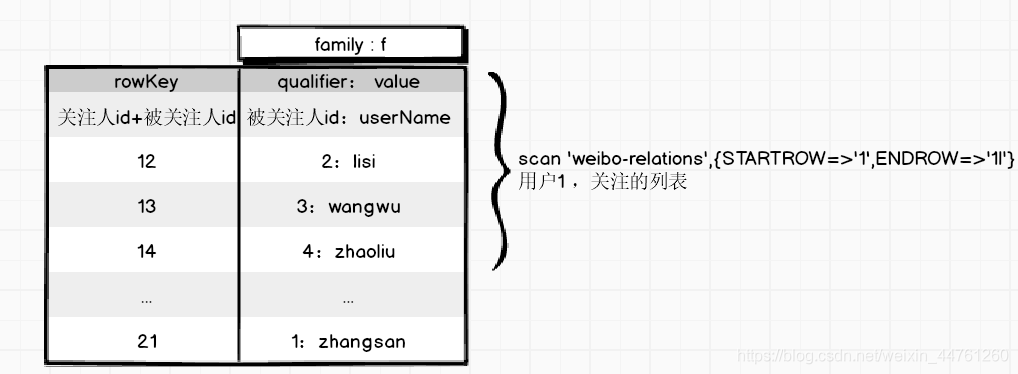
- rowKey:關注人id+被關注人id
- 被關注人id作為列,userName 作為 value
- weibo-relations-fans 用戶粉絲表
- 和關注表相反
- rowKey:被關注人id+關注人id
- 關注人id作為列,userName 作為 value
重點 粉絲關系
基于上面的設計 - 高表
-- 獲取1用戶所有的關注人
scan 'weibo-relations',{STARTROW=>'1',ENDROW=>'1|'}
-- 獲取用戶2所有的粉絲
scan 'weibo-relations-fans',{STARTROW=>'2',ENDROW=>'2|'}
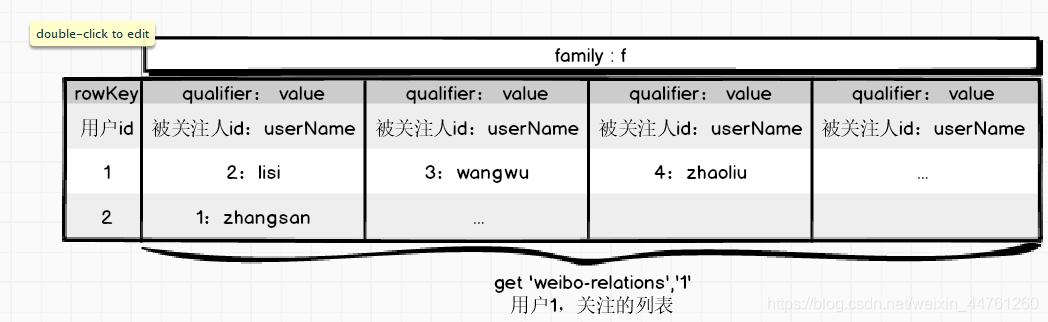
另一種設計 - 寬表
- 每個用戶對應1行,每一個被關注人,增加一列
- 可以保證事務性,因為只是一行
參考文章
- https://help.aliyun.com/document_detail/49503.html
- https://www.bilibili.com/video/BV1Y4411B7jy?p=64
- HBase in Action
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289515.html
標籤:其他