問題導讀
1.Flink 1.11 有哪些新功能?
2.如何使用 flink-cdc-connectors 捕獲 MySQL 和 Postgres 的資料變更?
3.怎樣利用 Flink SQL 做多流 join 后實時同步到 Elasticsearch 中?
1 Flink 1.8 ~ 1.11 社區發展趨勢回顧
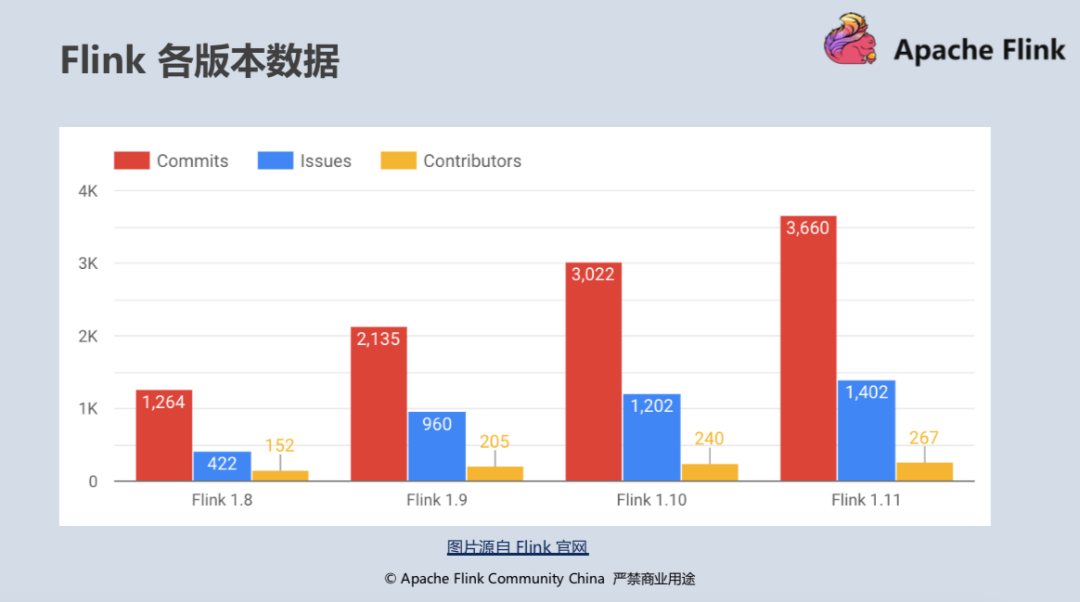
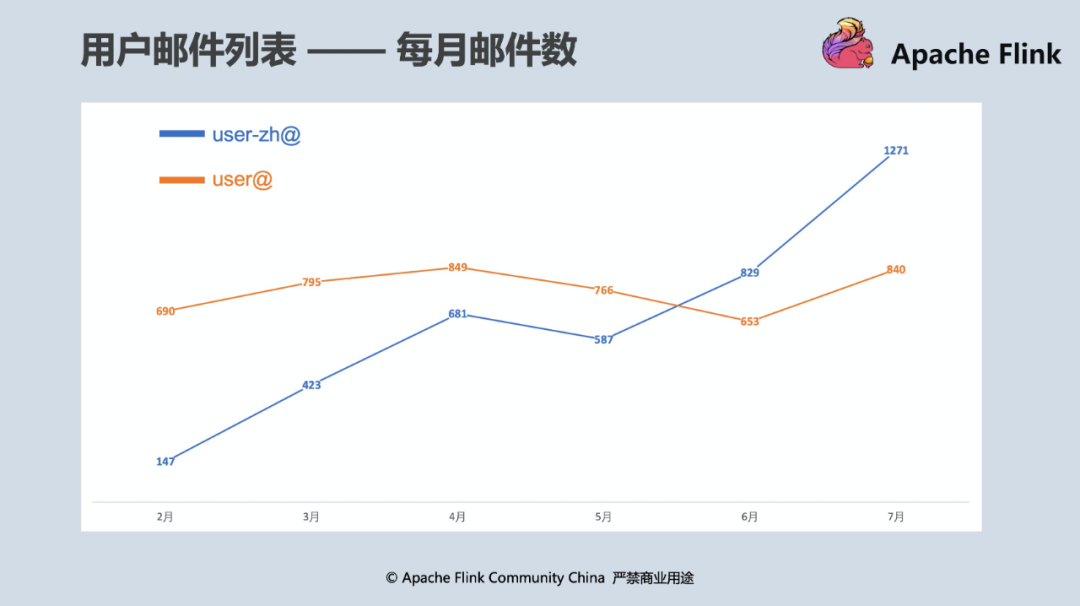
自 2019 年初阿里巴巴宣布向 Flink 社區貢獻 Blink 原始碼并在同年 4 月發布 Flink 1.8 版本后,Flink 在社區的活躍程度猶如坐上小火箭般上升,每個版本包含的 git commits 數量以 50% 的增速持續上漲, 吸引了一大批國內開發者和用戶參與到社區的生態發展中來,中文用戶郵件串列(user-zh@)更是在今年 6 月首次超出英文用戶郵件串列(user@),在 7 月超出比例達到了 50%,對比其它 Apache 開源社區如 Spark、Kafka 的用戶郵件串列數(每月約 200 封左右)可以看出,整個 Flink 社區的發展依然非常健康和活躍,
2 Flink SQL 新功能解讀
在了解 Flink 整體發展趨勢后,我們來看下最近發布的 Flink 1.11 版本在 connectivity 和 simplicity 方面都帶來了哪些令人耳目一新的功能,
FLIP-122:簡化 connector 引數
整個 Flink SQL 1.11 在圍繞易用性方面做了很多優化,比如 FLIP-122[1] ,
優化了 connector 的 property 引數名稱冗長的問題,以 Kafka 為例,在 1.11 版本之前用戶的 DDL 需要宣告成如下方式:
CREATE TABLE user_behavior (
...
) WITH (
'connector.type'='kafka',
'connector.version'='universal',
'connector.topic'='user_behavior',
'connector.startup-mode'='earliest-offset',
'connector.properties.zookeeper.connect'='localhost:2181',
'connector.properties.bootstrap.servers'='localhost:9092',
'format.type'='json'
);
而在 Flink SQL 1.11 中則簡化為:
CREATE TABLE user_behavior (
...
) WITH (
'connector'='kafka',
'topic'='user_behavior',
'scan.startup.mode'='earliest-offset',
'properties.zookeeper.connect'='localhost:2181',
'properties.bootstrap.servers'='localhost:9092',
'format'='json'
);
DDL 表達的資訊量絲毫未少,但是看起來清爽許多 😃,Flink 的開發者們為這個優化做了很多討論,有興趣可以圍觀 FLIP-122 Discussion Thread[2],
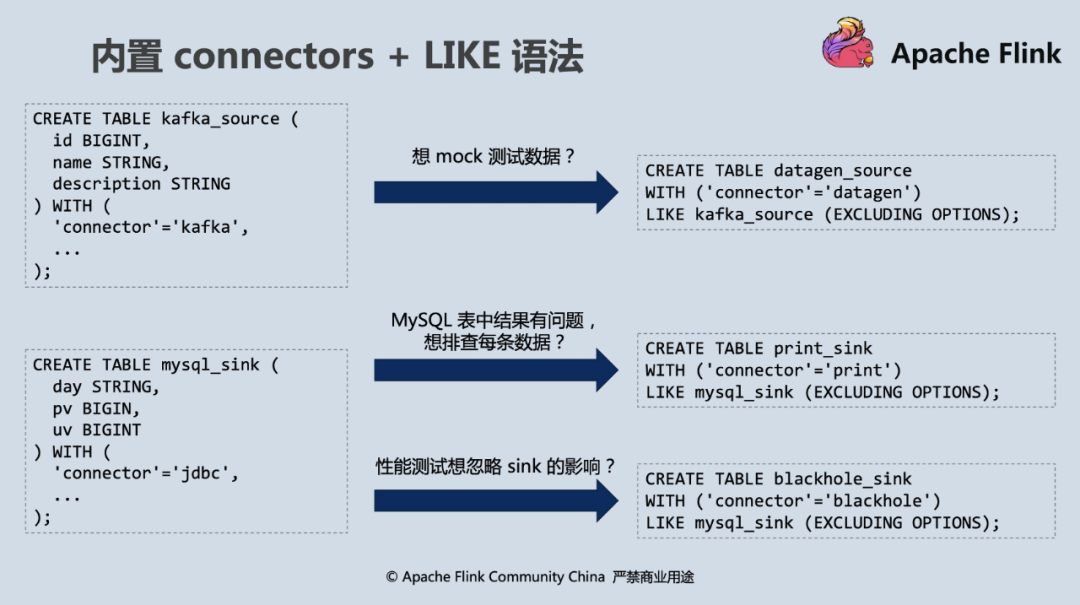
FLINK-16743:內置 connectors
Flink SQL 1.11 新加入了三種內置的 connectors,如下表所示:

在外部 connector 環境還沒有 ready 時,用戶可以選擇 datagen source 和 print sink 快速構建 pipeline 熟悉 Flink SQL;對于想要測驗 Flink SQL 性能的用戶,可以使用 blackhole 作為 sink;對于除錯排錯場景,print sink 會將計算結果打到標準輸出(比如集群環境下就會打到 taskmanager.out 檔案),使得定位問題的成本大大降低,
FLIP-110:LIKE 語法
Flink SQL 1.11 支持用戶從已定義好的 table DDL 中快速 “fork” 自己的版本并進一步修改 watermark 或者 connector 等屬性,比如下面這張 base_table 上想加一個 watermark,在 Flink 1.11 版本之前,用戶只能重新將表宣告一遍,并加入自己的修改,可謂 “牽一發而動全身”,
-- before Flink SQL 1.11
CREATE TABLE base_table (
id BIGINT,
name STRING,
ts TIMESTAMP
) WITH (
'connector.type'='kafka',
...
);
CREATE TABLE derived_table (
id BIGINT,
name STRING,
ts TIMESTAMP,
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector.type'='kafka',
...
);
CREATE TABLE derived_table (
id BIGINT,
name STRING,
ts TIMESTAMP,
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector.type'='kafka',
...
);
從 Flink 1.11 開始,用戶只需要使用 CREATE TABLE LIKE 語法就可以完成之前的操作,
-- Flink SQL 1.11
CREATE TABLE base_table ( id BIGINT,
name STRING,
ts TIMESTAMP
) WITH (
'connector'='kafka',
...
);
CREATE TABLE derived_table (
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) LIKE base_table;
而內置 connector 與 CREATE TABLE LIKE 語法搭配使用則會如下圖一般產生“天雷勾地火”的效果,極大提升開發效率,
FLIP-113:動態 Table 引數
對于像 Kafka 這種訊息佇列,在宣告 DDL 時通常會有一個啟動點位去指定開始消費資料的時間,如果需要更改啟動點位,在老版本上就需要重新宣告一遍新點位的 DDL,非常不方便,
CREATE TABLE user_behavior (
user_id BIGINT,
behavior STRING,
ts TIMESTAMP(3)
) WITH (
'connector'='kafka',
'topic'='user_behavior',
'scan.startup.mode'='timestamp',
'scan.startup.timestamp-millis'='123456',
'properties.bootstrap.servers'='localhost:9092',
'format'='json'
);```
從 Flink 1.11 開始,用戶可以在 SQL client 中按如下方式設定開啟 SQL 動態引數(默認是關閉的),如此即可在 DML 里指定具體的啟動點位,
SET 'table.dynamic-table-options.enabled' = 'true';
SELECT user_id, COUNT(DISTINCT behaviro)
FROM user_behavior /*+ OPTIONS('scan.startup.timestamp-millis'='1596282223') */
GROUP BY user_id;
除啟動點位外,動態引數還支持像 sink.partition、scan.startup.mode 等更多運行時引數,感興趣可移步 FLIP-113[3],獲得更多資訊,
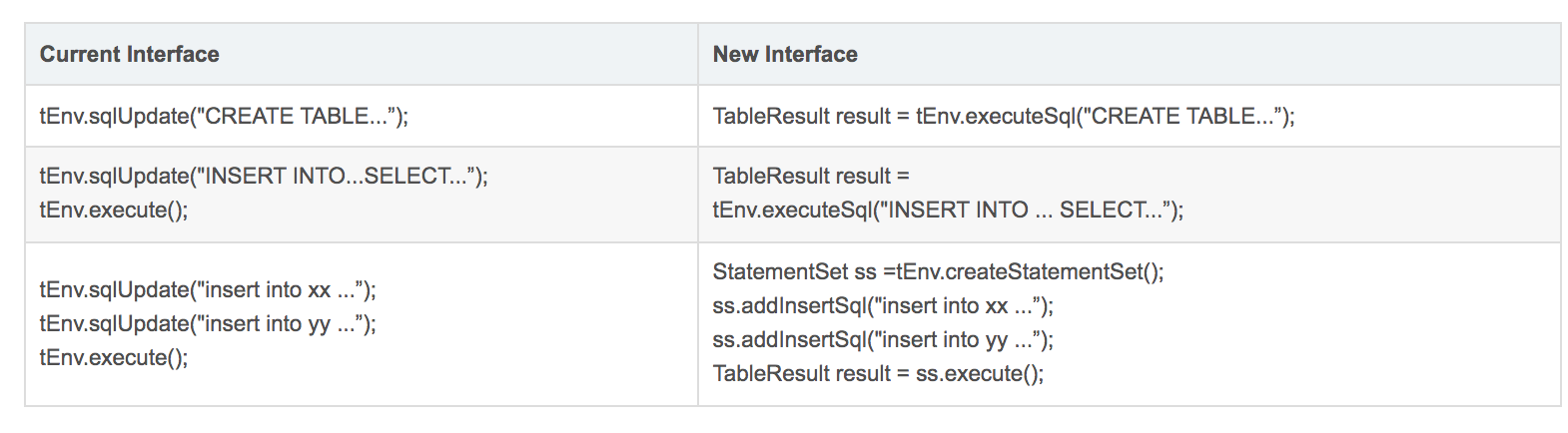
**FLIP-84:重構優化 TableEnvironment 介面**
Flink SQL 1.11 以前的 TableEnvironment 介面定義和行為有一些不夠清晰,比如:
TableEnvironment#sqlUpdate() 方法對于 DDL 會立即執行,但對于 INSERT INTO DML 陳述句卻是 buffer 住的,直到呼叫 TableEnvironment#execute() 才會被執行,所以在用戶看起來順序執行的陳述句,實際產生的效果可能會不一樣,
觸發作業提交有兩個入口,一個是 TableEnvironment#execute(),另一個是 StreamExecutionEnvironment#execute(),于用戶而言很難理解應該使用哪個方法觸發作業提交,
單次執行不接受多個 INSERT INTO 陳述句,
針對這些問題,Flink SQL 1.11 提供了新 API,即 TableEnvironment#executeSql(),它統一了執行 SQL 的行為, 無論接收 DDL、查詢 query 還是 INSERT INTO 都會立即執行,針對多 sink 場景提供了 StatementSet 和 TableEnvironment#createStatementSet() 方法,允許用戶添加多條 INSERT 陳述句一起執行,
除此之外,新的 execute 方法都有回傳值,用戶可以在回傳值上執行 print,collect 等方法,
新舊 API 對比如下表所示:
對于在 Flink 1.11 上使用新介面遇到的一些常見問題,云邪做了統一解答,可在 Appendix 部分查看,
FLIP-95:TableSource & TableSink 重構
開發者們在 Flink SQL 1.11 版本花了大量經歷對 TableSource 和 TableSink API 進行了重構,核心優化點如下:
- 移除型別相關介面,簡化開發,解決迷惑的型別問題,支持全型別
- 尋找 Factory 時,更清晰的報錯資訊
- 解決找不到 primary key 的問題
- 統一了流批 source,統一了流批 sink
- 支持讀取 CDC 和輸出 CDC
- 直接高效地生成 Flink SQL 內部資料結構 RowData
新 DynamicTableSink API 去掉了所有型別相關介面,因為所有的型別都是從 DDL 來的,不需要 TableSink 告訴框架是什么型別,而對于用戶來說,最直觀的體驗就是在老版本上遇到各種奇奇怪怪報錯的概率降低了很多,比如不支持的精度型別和找不到 primary key / table factory 的詭異報錯在新版本上都不復存在了,關于 Flink 1.11 是如何解決這些問題的詳細可以在附錄部分閱讀,
FLIP-123:Hive Dialect
Flink 1.10 版本對 Hive connector 的支持達到了生產可用,但是老版本的 Flink SQL 不支持 Hive DDL 及使用 Hive syntax,這無疑限制了 Flink connectivity,在新版本中,開發者們為支持 HiveQL 引入了新 parser,用戶可以在 SQL client 的 yaml 檔案中指定是否使用 Hive 語法,也可以在 SQL client 中通過 set table.sql-dialect=hive/default 動態切換,更多資訊可以參考 FLIP-123[4],
以上簡要介紹了 Flink 1.11 在減少用戶不必要的輸入和操作方面對 connectivity 和 simplicity 方面做出的優化,下面會重點介紹在外部系統和資料生態方面對 connectivity 和 simplicity 的兩個核心優化,并附上最佳實踐介紹,
#### 3 Hive 數倉實時化 & Flink SQL + CDC 最佳實踐
Hive 數倉實時化
下圖是一張非常經典的 Lambda 數倉架構,在整個大資料行業從批處理逐步擁抱流計算的許多年里代表“最先進的生產力”,然而隨著業務發展和規模擴大,兩套單獨的架構所帶來的開發、運維、計算成本問題已經日益凸顯,
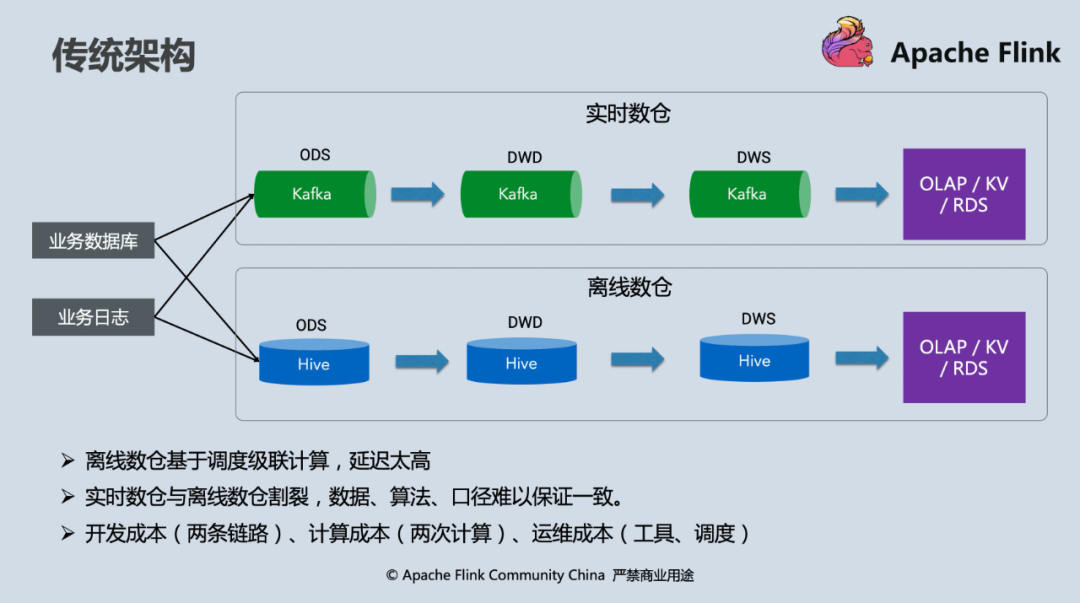
而 Flink 作為一個流批一體的計算引擎,在最初的設計上就認為“萬物本質皆是流”,批處理是流計算的特例,如果能夠在自身提供高效批處理能力的同時與現有的大資料生態結合,則能以最小侵入的方式改造現有的數倉架構使其支持流批一體,在新版本中,Flink SQL 提供了開箱即用的 “Hive 數倉同步”功能,即所有的資料加工邏輯由 Flink SQL 以流計算模式執行,在資料寫入端,自動將 ODS,DWD 和 DWS 層的已經加工好的資料實時回流到 Hive table,One size (sql) fits for all suites (tables) 的設計,使得在 batch 層不再需要維護任何計算 pipeline,
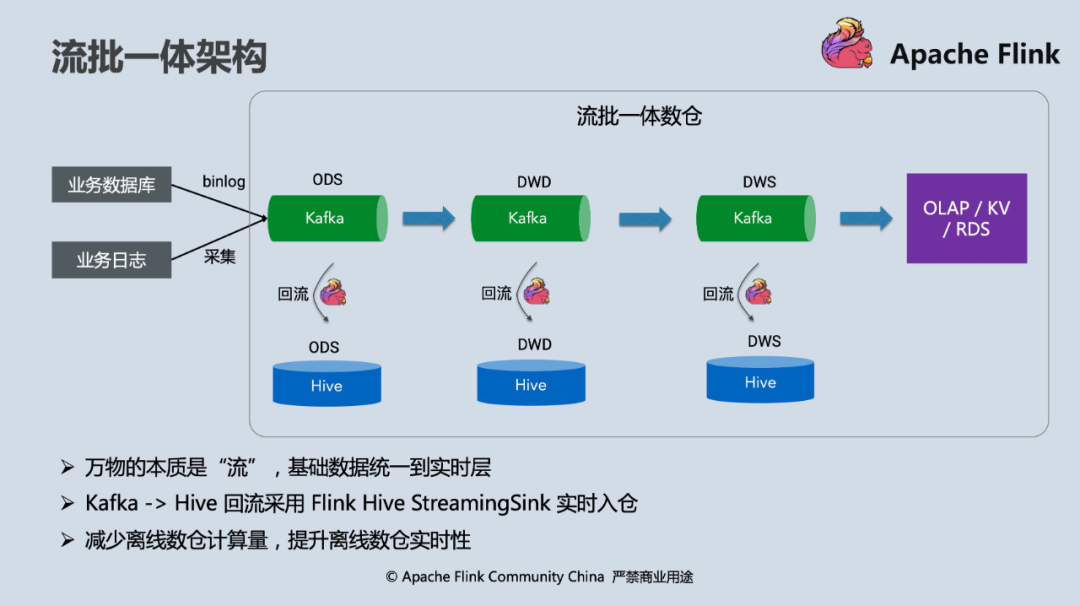
對比傳統架構,它帶來的好處和解決的問題有哪些呢?
- 計算口徑與處理邏輯統一,降低開發和運維成本
傳統架構維護兩套資料 pipeline 最大的問題在于需要保持它們處理邏輯的等價性,但由于使用了不同的計算引擎(比如離線使用 Hive,實時使用 Flink 或 Spark Streaming),SQL 往往不能直接套用,存在代碼上的差異性,經年累月下來,離線和實時處理邏輯很可能會完全 diverge,有些大的公司甚至會存在兩個團隊分別去維護實時和離線數倉,人力物力成本非常高,Flink 支持 Hive Streaming Sink 后,實時處理結果可以實時回流到 Hive 表,離線的計算層可以完全去掉,處理邏輯由 Flink SQL 統一維護,離線層只需要使用回流好的 ODS、DWD、DWS 表做進一步 ad-hoc 查詢即可,
- 離線對于“資料漂移”的處理更自然,離線數倉“實時化”
離線數倉 pipeline 非 data-driven 的調度執行方式,在跨磁區的資料邊界處理上往往需要很多 trick 來保證磁區資料的完整性,而在兩套數倉架構并行的情況下,有時會存在對 late event 處理差異導致資料對比不一致的問題,而實時 data-driven 的處理方式和 Flink 對于 event time 的友好支持本身就意味著以業務時間為磁區(window),通過 event time + watermark 可以統一定義實時和離線資料的完整性和時效性,Hive Streaming Sink 更是解決了離線數倉同步的“最后一公里問題”,
下面會以一個 Demo 為例,介紹 Hive 數倉實時化的最佳實踐,
■ 實時資料寫入 Hive 的最佳實踐
FLIP-105:支持 Change Data Capture (CDC)
除了對 Hive Streaming Sink 的支持,Flink SQL 1.11 的另一大亮點就是引入了 CDC 機制,CDC 的全稱是 Change Data Capture,用于 tracking 資料庫表的增刪改查操作,是目前非常成熟的同步資料庫變更的一種方案,在國內常見的 CDC 工具就是阿里開源的 Canal,在國外比較流行的有 Debezium,Flink SQL 在設計之初就提出了 Dynamic Table 和“流表二象性”的概念,并且在 Flink SQL 內部完整支持了 Changelog 功能,相對于其他開源流計算系統是一個重要優勢,本質上 Changelog 就等價于一張一直在變化的資料庫的表,Dynamic Table 這個概念是 Flink SQL 的基石, Flink SQL 的各個算子之間傳遞的就是 Changelog,完整地支持了 Insert、Delete、Update 這幾種訊息型別,
得益于 Flink SQL 運行時的強大,Flink 與 CDC 對接只需要將外部的資料流轉為 Flink 系統內部的 Insert、Delete、Update 訊息即可,進入到 Flink 內部后,就可以靈活地應用 Flink 各種 query 語法了,
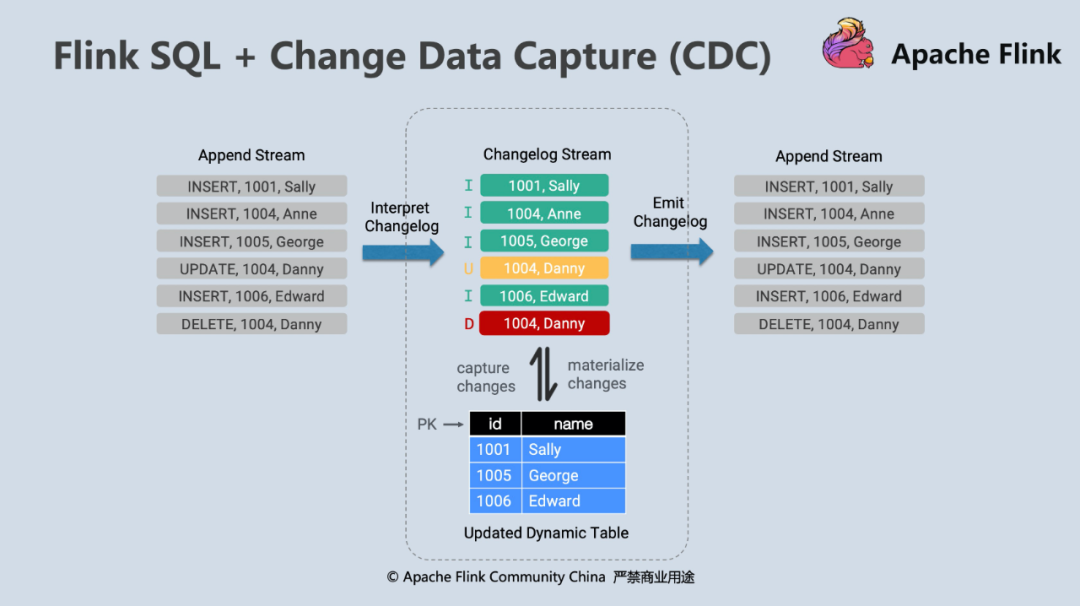
在實際應用中,把 Debezium Kafka Connect Service 注冊到 Kafka 集群并帶上想同步的資料庫表資訊,Kafka 則會自動創建 topic 并監聽 Binlog,把變更同步到 topic 中,在 Flink 端想要消費帶 CDC 的資料也很簡單,只需要在 DDL 中宣告 format = debezium-json 即可,

在 Flink 1.11 上開發者們還做了一些有趣的探索,既然 Flink SQL 運行時能夠完整支持 Changelog,那是否有可能不需要 Debezium 或者 Canal 的服務,直接通過 Flink 獲取 MySQL 的變更呢?答案當然是可以,Debezium 類別庫的良好設計使得它的 API 可以被封裝為 Flink 的 Source Function,不需要再起額外的 Service,目前這個專案已經開源,支持了 MySQL 和 Postgres 的 CDC 讀取,后續也會支持更多型別的資料庫,可移步到下方鏈接解鎖更多使用姿勢,
https://github.com/ververica/flink-cdc-connectors
下面的 Demo 會介紹如何使用 flink-cdc-connectors 捕獲 MySQL 和 Postgres 的資料變更,并利用 Flink SQL 做多流 join 后實時同步到 Elasticsearch 中,

假設你在一個電商公司,訂單和物流是你最核心的資料,你想要實時分析訂單的發貨情況,因為公司已經很大了,所以商品的資訊、訂單的資訊、物流的資訊,都分散在不同的資料庫和表中,我們需要創建一個流式 ETL,去實時消費所有資料庫全量和增量的資料,并將他們關聯在一起,打成一個大寬表,從而方便資料分析師后續的分析,
■ 使用 Flink SQL CDC 的最佳實踐展示
#### 4 Flink SQL 1.12 未來規劃
以上介紹了 Flink SQL 1.11 的核心功能與最佳實踐,對于下個版本,云邪也給出了一些 ongoing 的計劃,并歡迎大家在社區積極提出意見 & 建議,
- FLIP-132[5]:Temporal Table DDL (Binlog 模式的維表關聯)
- FLIP-129[6]:重構 Descriptor API (Table API 的 DDL)
- 支持 Schema Registry Avro 格式
- CDC 更完善的支持(批處理,upsert 輸出到 Kafka 或 Hive)
- 優化 Streaming File Sink 小檔案問題
- N-ary input operator (Batch 性能提升)
#### 5 附錄
使用新版本 TableEnvironment 遇到的常見報錯及原因
第一個常見報錯是 No operators defined in streaming topolog,遇到這個問題的原因是在老版本中執行 INSERT INTO 陳述句的下面兩個方法:
TableEnvironment#sqlUpdate()
TableEnvironment#execute()
在新版本中沒有完全向前兼容(方法還在,執行邏輯變了),如果沒有將 Table 轉換為 AppendedStream/RetractStream 時(通過StreamExecutionEnvironment#toAppendStream/toRetractStream),上面的代碼執行就會出現上述錯誤;與此同時,一旦做了上述轉換,就必須使用 StreamExecutionEnvironment#execute() 來觸發作業執行,所以建議用戶還是遷移到新版本的 API 上面,語意上也會更清晰一些,

第二個問題是呼叫新的 TableEnvironemnt#executeSql() 后 print 沒有看到回傳值,原因是因為目前 print 依賴了 checkpoint 機制,開啟 exactly-onece 后就可以了,新版本會優化此問題,

老版本的 StreamTableSource、StreamTableSink 常見報錯及新版本優化
第一個常見報錯是不支持精度型別,經常出現在 JDBC 或者 HBase 資料源上 ,在新版本上這個問題就不會再出現了,

第二個常見報錯是 Sink 時找不到 PK,因為老的 StreamSink 需要通過 query 去推匯出 PK,當 query 變得復雜時有可能會丟失 PK 資訊,但實際上 PK 資訊在 DDL 里就可以獲取,沒有必要通過 query 去推導,所以新版本的 Sink 就不會再出現這個錯誤啦,

第三個常見報錯是在決議 Source 和 Sink 時,如果用戶少填或者填錯了引數,框架回傳的報錯資訊很模糊,“找不到 table factory”,用戶也不知道該怎么修改,這是因為老版本 SPI 設計得比較通用,沒有對 Source 和 Sink 決議的邏輯做單獨處理,當匹配不到完整引數串列的時候框架已經默認當前的 table factory 不是要找的,然后遍歷所有的 table factories 發現一個也不匹配,就報了這個錯,在新版的加載邏輯里,Flink 會先判斷 connector 型別,再匹配剩余的引數串列,這個時候如果必填的引數缺失或填錯了,框架就可以精準報錯給用戶,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289519.html
標籤:其他
上一篇:13.RabbitMQ 訊息可靠性投遞confirm確認模式
下一篇:微服務原理學習小結(二)