在Hive explain獲得執行計劃時,經常會看到如下圖所示的表資料量統計:
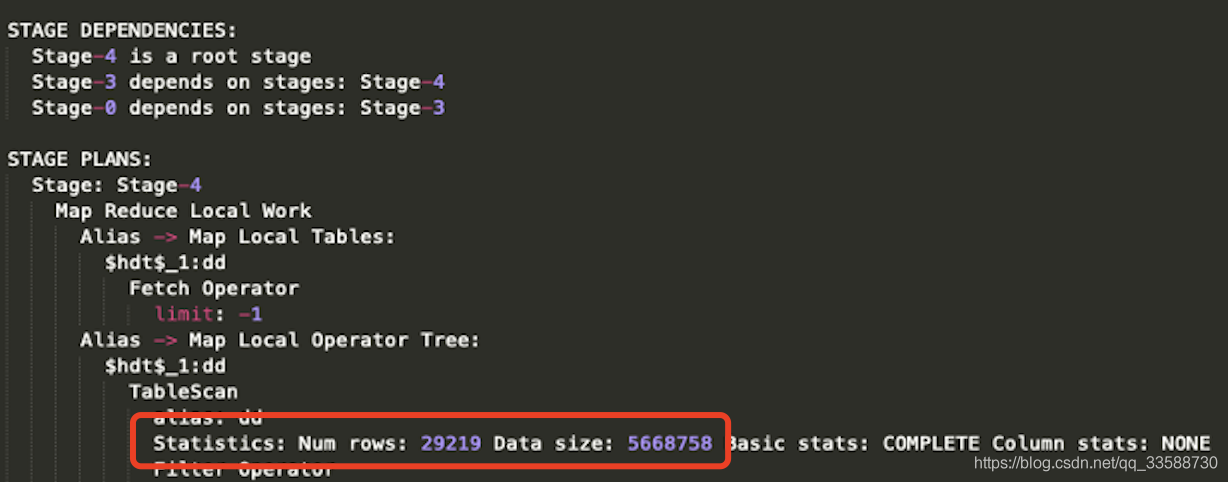
那么這個資料量,Hive是如何統計出來的呢?
一、Data size統計
1.1、Hive原始碼
在Hive通過Antlr語法決議器獲取到SQL的抽象語法樹(AST)并生成校驗過元資料的邏輯執行計劃后,在優化階段會使用Statistics統計的規則(rule),如下圖所示:
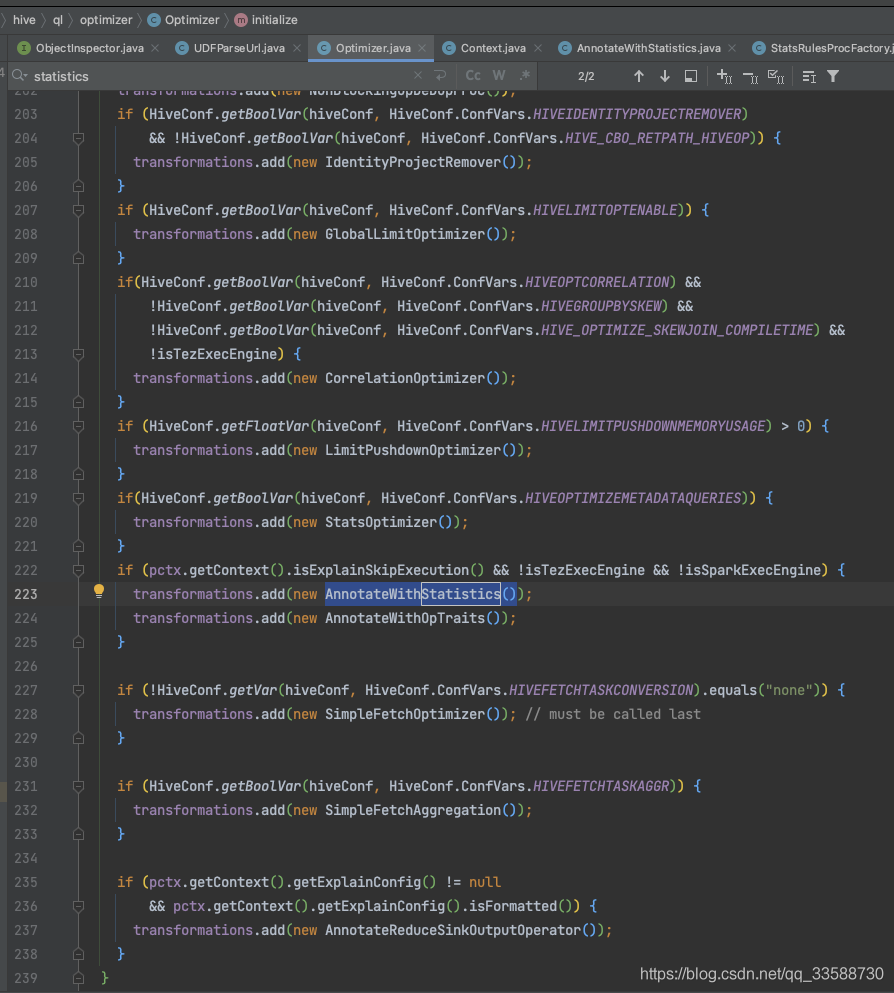
在AnnotateWithStatistics這個類中,在對執行計劃進行轉化(transform)時會呼叫TableScanStatsRule這個規則,如下圖所示:
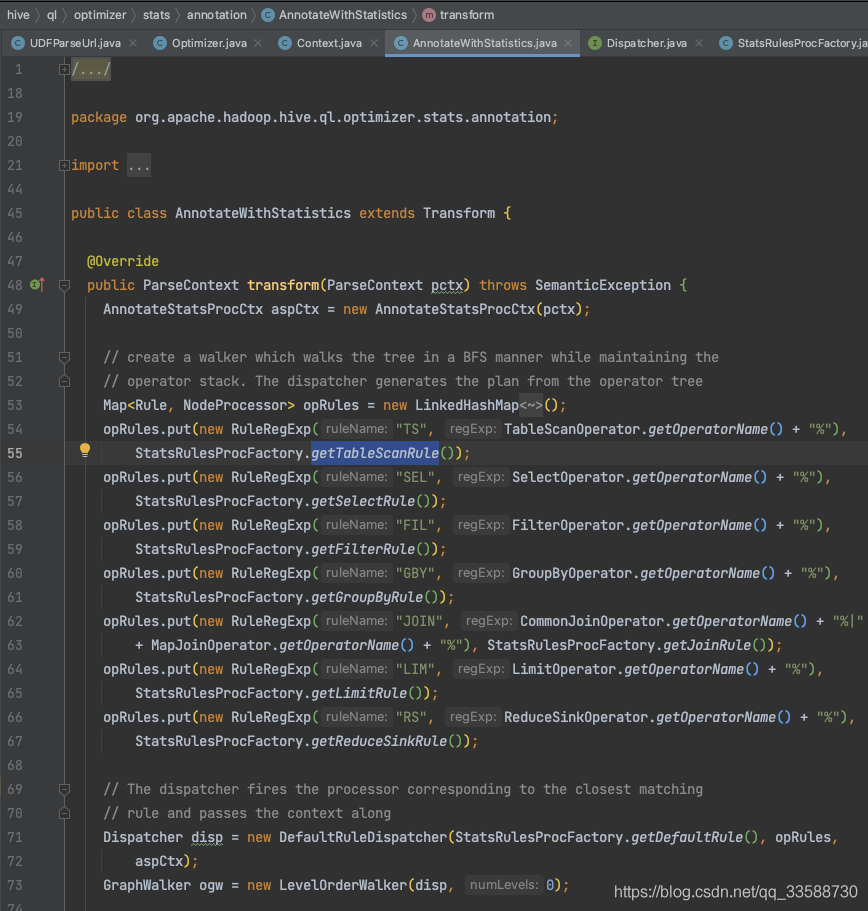
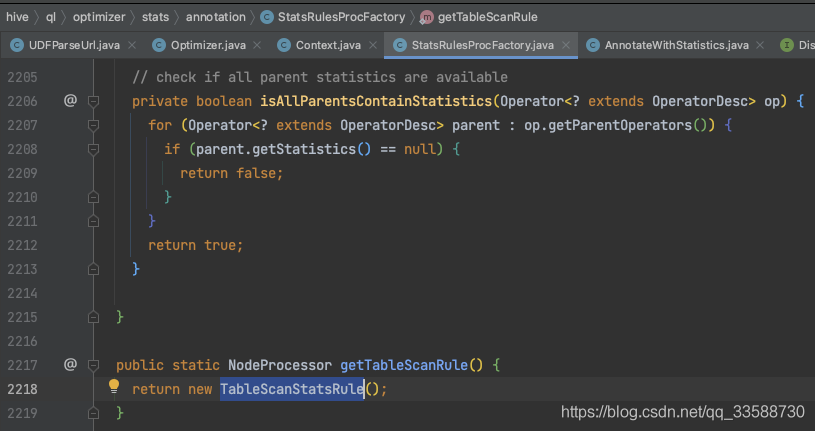
在TableScanStatsRule匹配規則中,在拿到裁剪后涉及的磁區范圍(PrunedPartitionList)后,會呼叫collectStatistics()方法開始正式統計表Statistics資訊,如下圖所示:
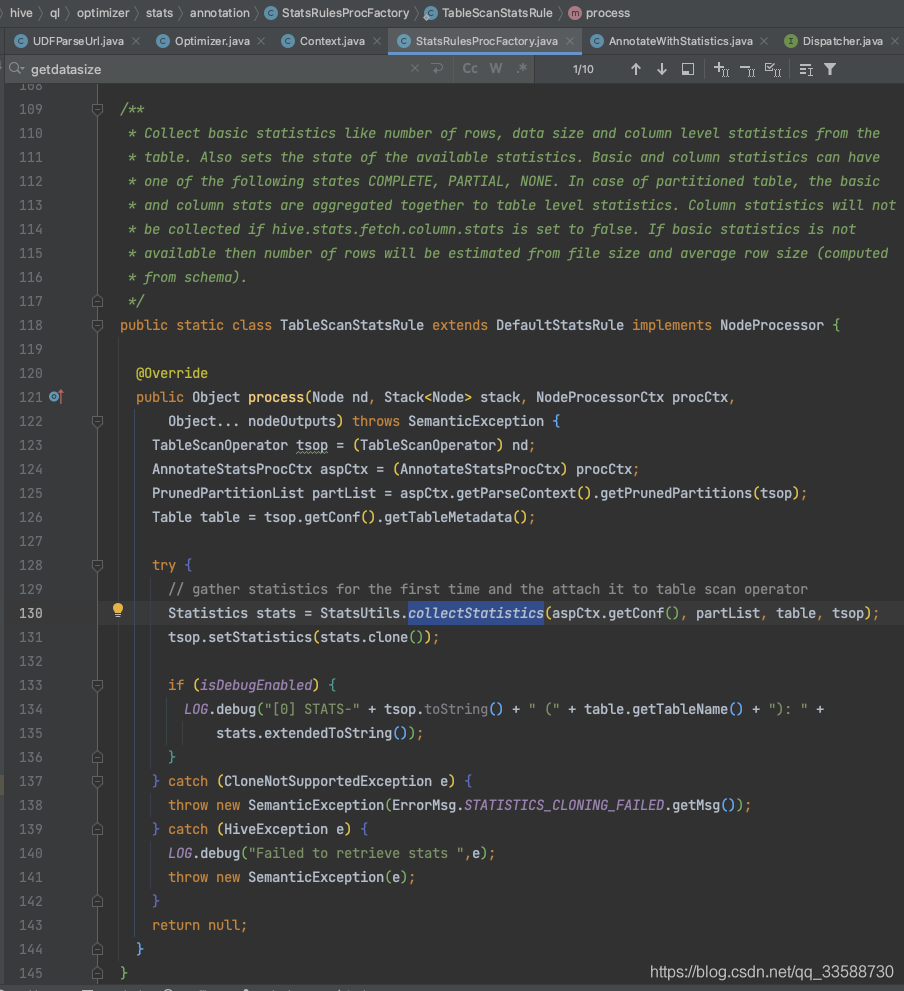
獲取到select陳述句等涉及的列資訊后,呼叫同名的多載方法,如下圖所示:
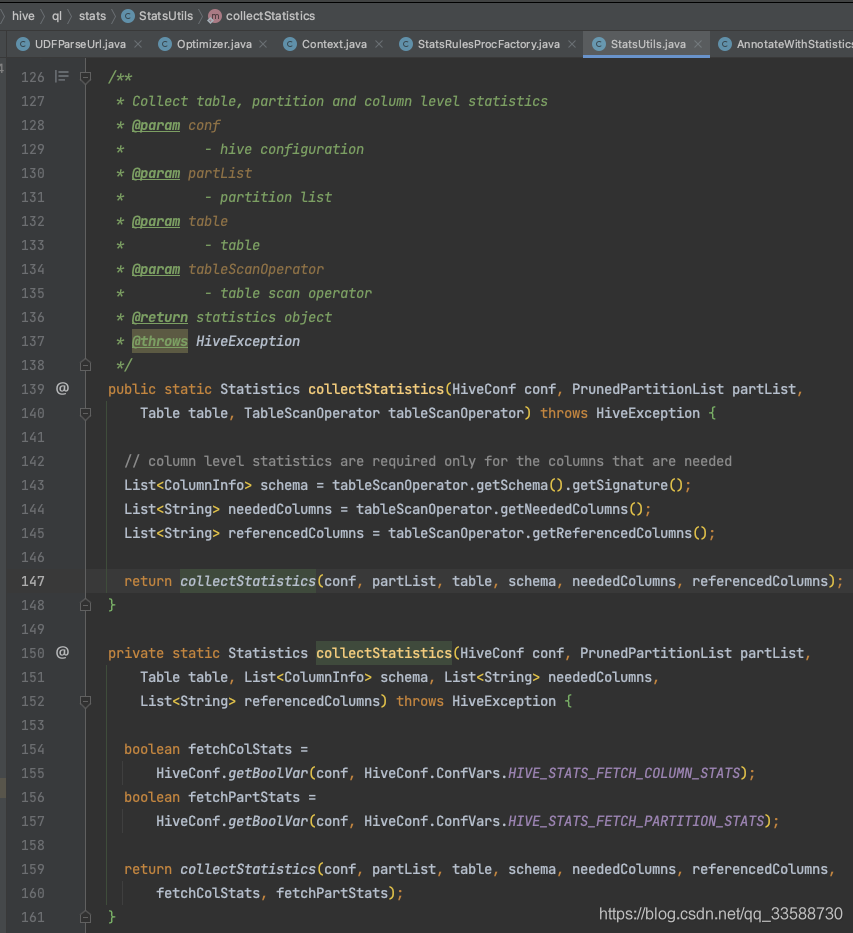
在最終多載的collectStatistics()方法中,會呼叫getDataSize()方法來統計資料量(當然也有統計行數的函式呼叫),如下圖所示:
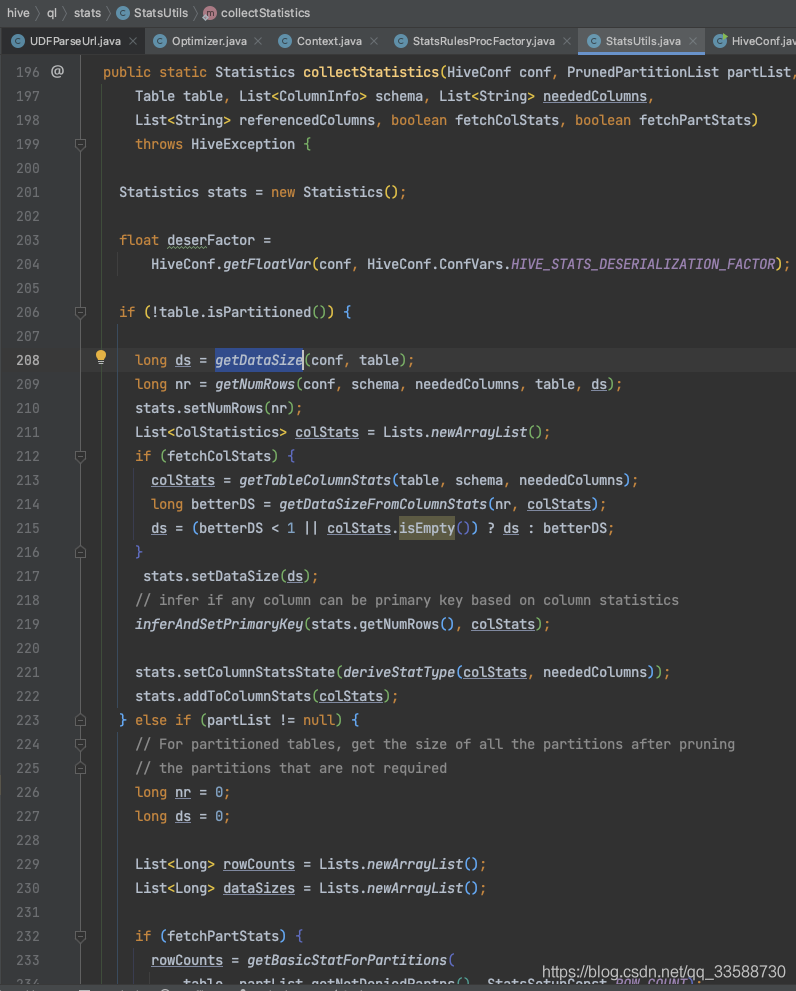
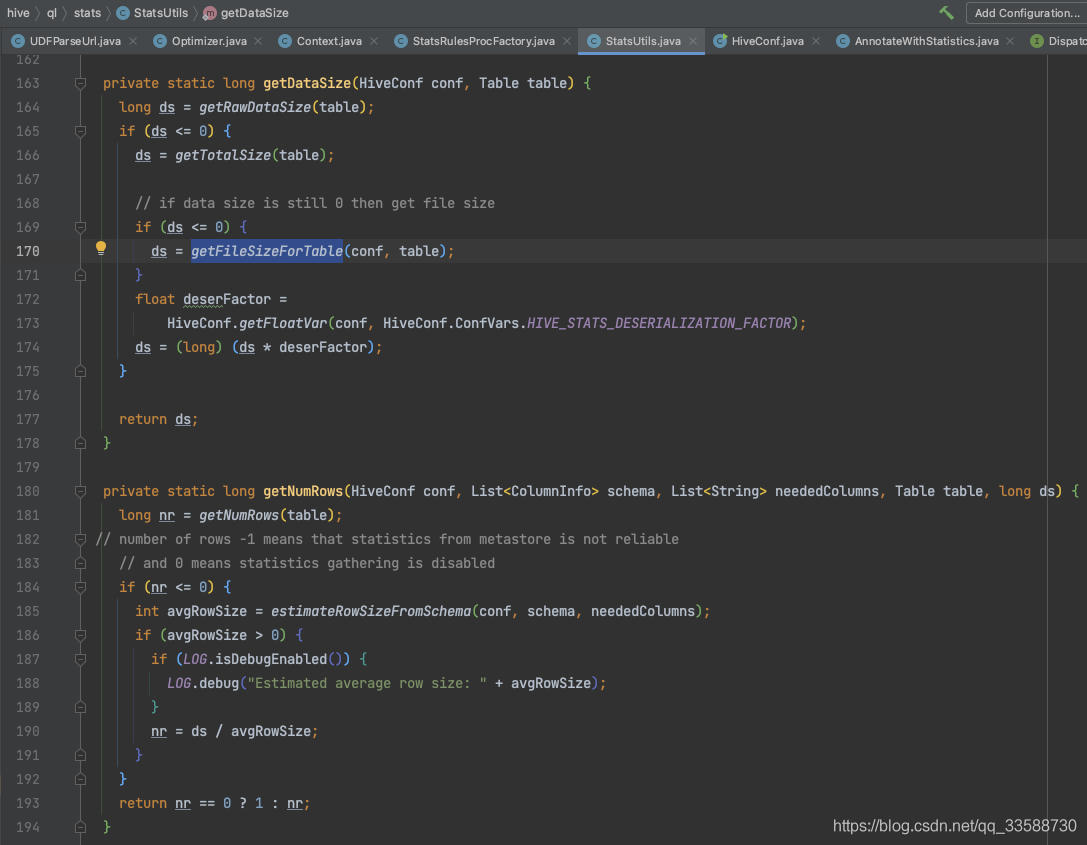
可以看到統計資料量的邏輯是先從Hive metastore(存在MySQL中)的parameters資訊中拿到raw data size,如果沒拿到就還是從metastore中拿total data size資訊,再沒拿到就直接去統計HDFS目錄檔案的大小,并且乘以反序列化因子(因為表檔案可能被壓縮編碼和序列化過,實際容量大小比原來小),
1.2、Hadoop原始碼
那么Hive是如何去HDFS統計表目錄下的檔案大小的呢?在getDataSize()函式中,會呼叫Hadoop HDFS上的方法,如下圖所示:
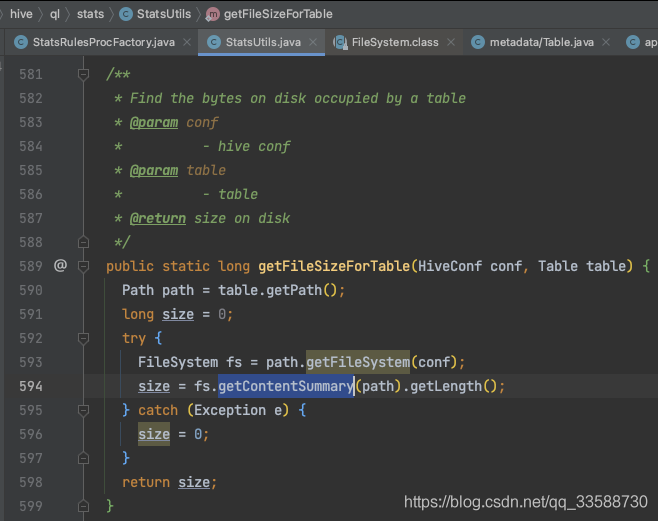
去Hadoop原始碼看看,可以看到如果是檔案就會直接計算檔案長度,如果是目錄就遞回統計,如下圖所示:
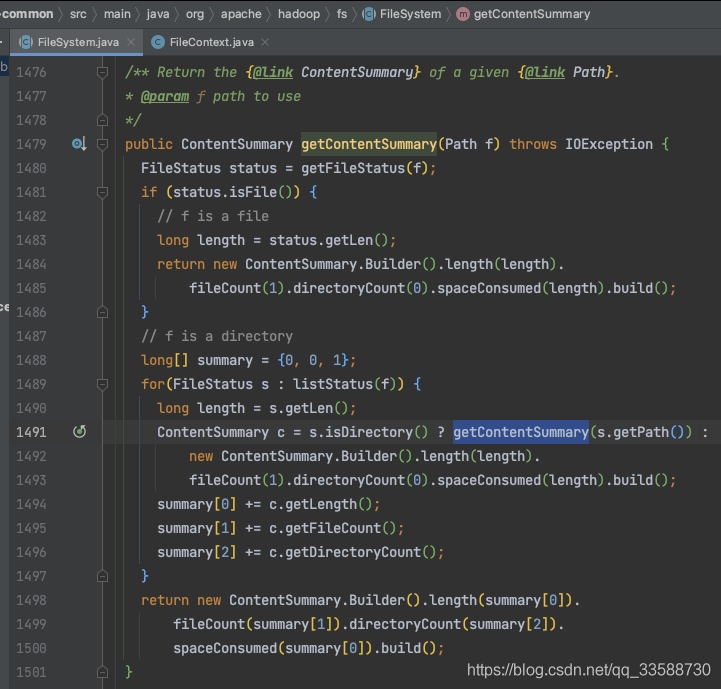
那么這個length是如何計算出來的?getLen()函式會用到一個length變數,這個變數最終是在這里被設定的:
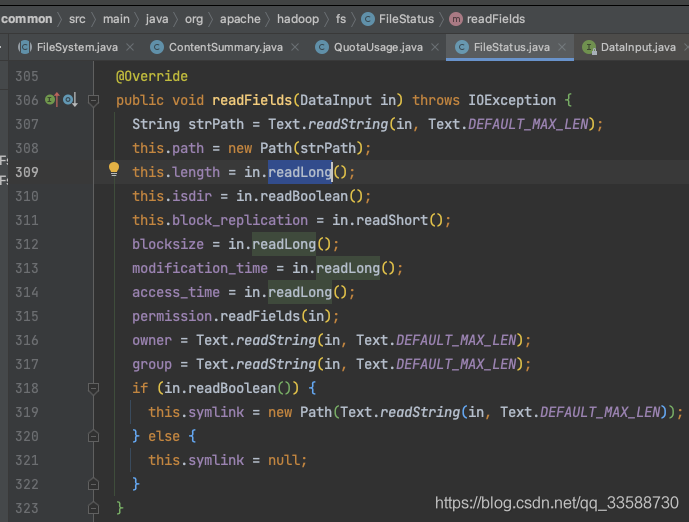
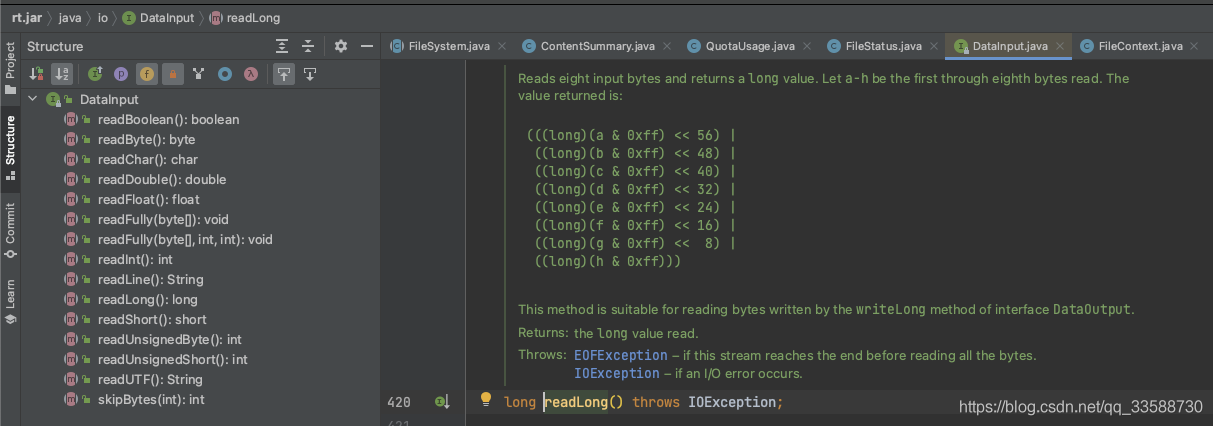
這樣最后就到JDK層面了,會回傳位元組大小,如下圖所示:
二、Num rows統計
上面Hive的collectStatistics()函式中,呼叫了getNumRows()統計表的行數,可以看到如果沒能從Hive metastore中拿到行數資訊,那么就采用估算的方式,如下圖所示:
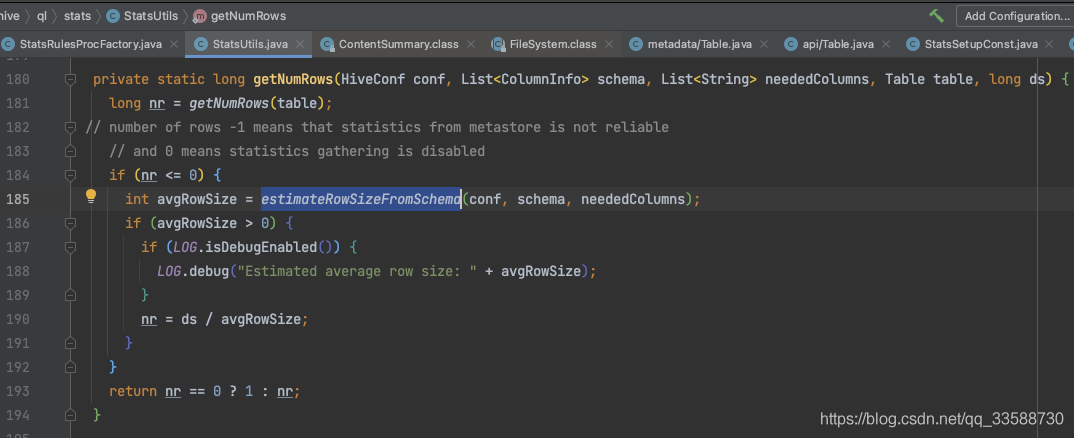
在estimateRowSizeFromSchema()函式中,Hive在拿到表的每一列的資訊后,會判斷該列的欄位型別,從而累加該型別的一個欄位值所代表的不同容量大小,分為string、varchar、struct、map等可變長型別和int、double、boolean等固定長度型別兩種情況,如下圖所示:
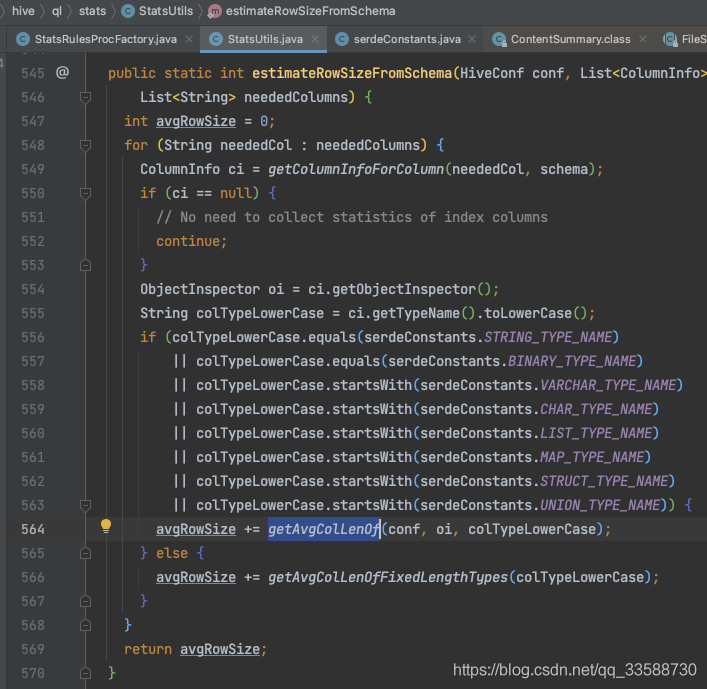
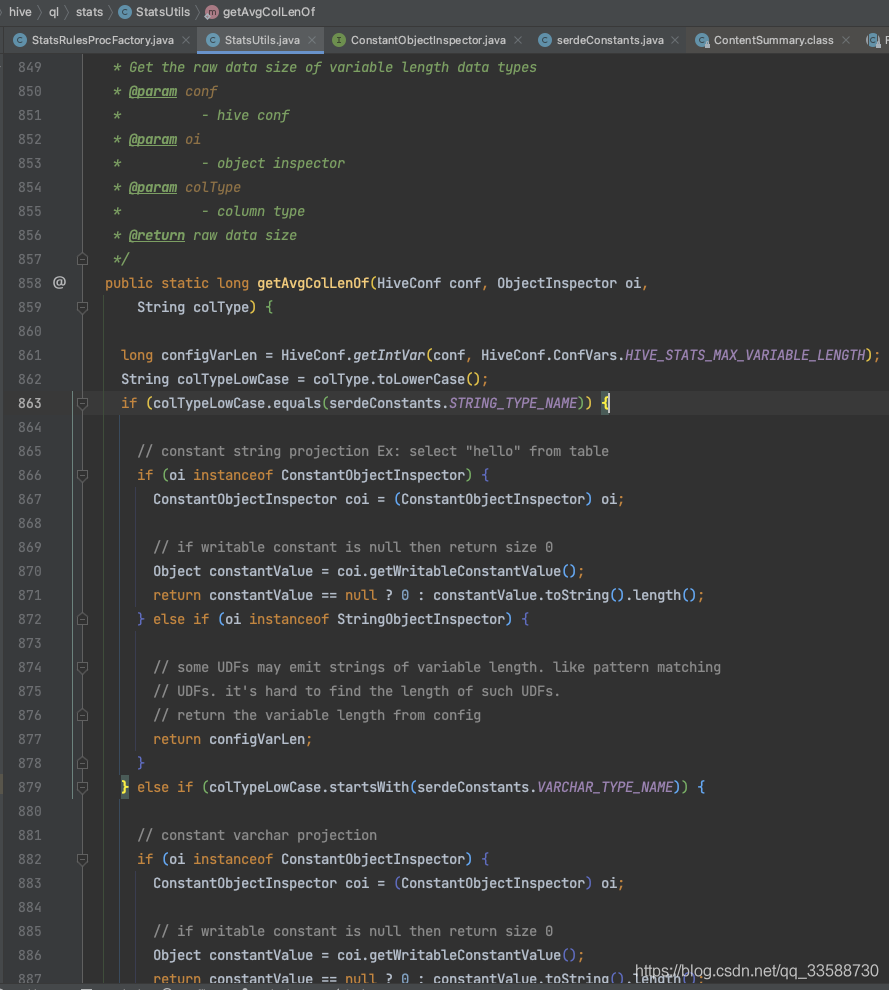
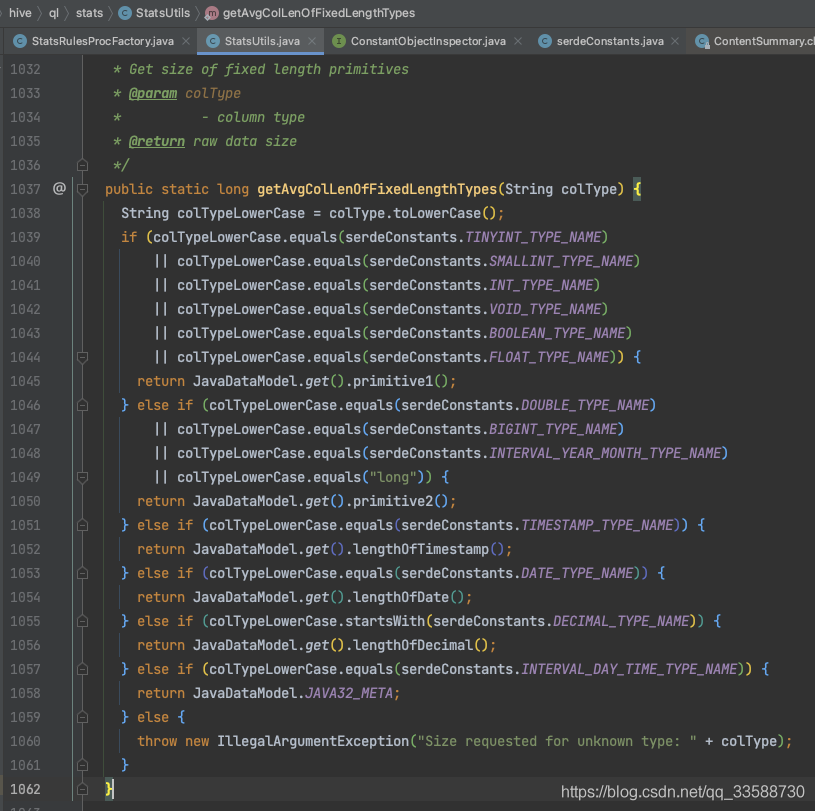
累加好表的所有列的一個欄位值的容量大小,即估算的一行容量大小后,回到一開始的getNumRows()函式,會把統計的表容量大小除以估算的一行資料的容量大小,最終得到估算的行數,如下圖所示:
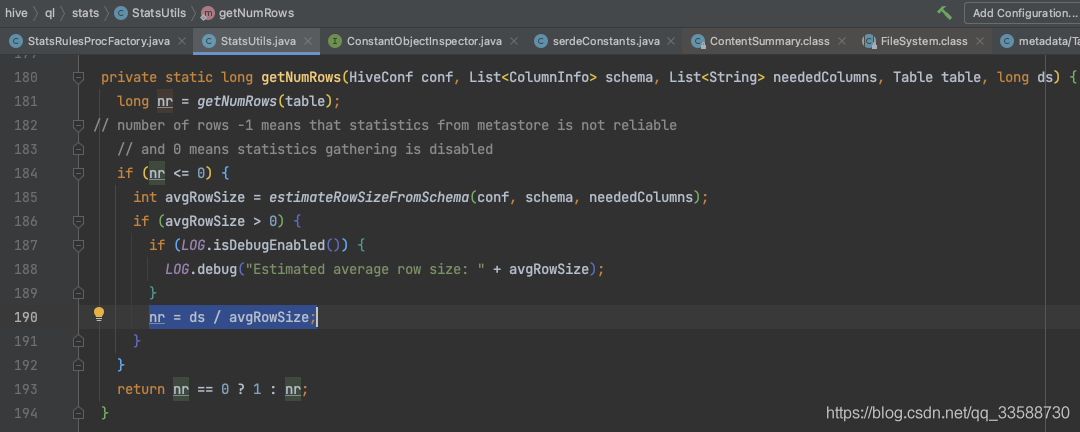
如果這樣都沒拿到行數統計(比如之前沒拿到表容量等),就回傳行數是一行,可以看到Hive的統計方法是有較嚴謹的回應速度(優先從metastore拿)和容錯(萬一統計不出來)考慮的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289523.html
標籤:其他
下一篇:Hive之數倉的分層及建模理論