zookeeper概述和部署
- zookeeper概述
- zookeeper定義
- zookeeper作業機制
- zookeeper特點
- zookeeper資料結構
- zookeeper應用場景
- zookeeper選舉機制
- 第一次啟動選舉機制(5臺)
- 非第一次啟動選舉機制
- zookeeper集群部署
zookeeper概述
zookeeper定義
zookeeper是一個開源的分布式的,為分布式框架提供協調服務的Apache專案
zookeeper作業機制
zookeeper從設計模式角度來理解:是一個基于觀察者模式設計的分布式服務管理框架,它負責存盤和管理大家都關心的資料,然后接收觀察者的注冊,一旦這些資料的狀態發生變化,zookeeper將負責通知已經在zookeeper上注冊的哪些觀察者做出相應的反應,也就是說zookeeper=檔案系統+通知機制
zookeeper特點
1.zookeeper:一個領導者(leader),多個跟隨者(follower)組成的集群
2.zookeeper集群中只要有半數以上節點存活,zookeeper集群就能正常服務,所以zookeeper適合安裝奇數臺服務器
3.全域資料一致:每個server保存一份相同的資料副本,client無論連接到哪個server,資料都是一致的
4.更新請求順序執行,來自同一個client的更新請求按其發送順序依次執行,即先進先出
5.資料更新原子性,一次資料更新要么成功,要么失敗
6.實時性,在一定時間范圍內,client能讀到最新資料
zookeeper資料結構
zookeeper資料模型與linux檔案系統很類似,整體上可以看做一棵樹,每個節點稱作一個znode,每一個znode默認能夠存盤1MB的資料,每個znode都可以通過其路徑唯一標識
zookeeper應用場景
提供的服務包括:統一命名服務,統一配置管理,統一集群管理,服務器節點動態上下線,軟負載均衡
| 統一命名服務 | 在分布式環境下,經常需要對應用服務進行統一命名,便于辨識,例如:IP不容易記住,而域名容易記住 , |
|---|---|
| 統一配置管理 | (1)在分布式環境下,組態檔同步非常常見,一般要求一個集群中,所有節點的配置資訊是一致的,比如kafka集群,對組態檔修改后,希望能夠快速同步到各個節點上 |
| (2)配置管理可交由zookeeper實作,可將配置資訊寫入zookeeper上的一個znode,各個客戶端服務器監聽這個znode,一旦znode中的資料被修改,zookeeper將通知各個客戶端服務器 | |
| 統一集群管理 | (1)分布式環境中,實作掌握每個節點的狀態是必要的,可根據節點實時狀態做出一些調整 |
| (2)zookeeper可以實作實時監控節點狀態變化,可將節點資訊寫入zookeeper上的一個znode,監聽這個znode可獲取它的實時狀態變化 | |
| 服務器動態上下線 | 客戶端能實時洞察到服務器上下線的變化 |
| 軟負載均衡 | 在zookeeper中記錄每天服務器的訪問數,讓訪問數最少的服務器去處理最新的客戶端請求 |
zookeeper選舉機制
第一次啟動選舉機制(5臺)
1.服務器1啟動,發起一次選舉,服務器1投自己一票,此時服務器1票數一票,不夠半數以上(3票),選舉無法完成,服務器1狀態保持為looking
2.服務器2啟動,再發起一次選舉,服務器1和服務器2分別投自己一票并交換選票資訊,此時服務器1發現服務器2的myid比自己目前投票推舉服務器1的大,更改選票為推舉服務器2.此時服務器1票數0票,服務器2票數2票,沒有半數以上,選舉無法完成,服務器1,2狀態保持looking
3.服務器3啟動,發起一次選舉,此時服務器1和2都會更改選票為服務器3.此時投票結果:服務器1為0票,服務器2為0票,服務器3為3票,此時服務器3的票數已經超過半數,服務器3當選為leader,服務器1,2更改狀態為following,服務器3更改狀態為leading
4.服務器4啟動,發起一次選舉,此時服務器1,2,3已經不是looking狀態,不會更改選票資訊,交換選票資訊結果:服務器3位3票,服務器4位1票,此時服務器4服從多數,更改選票資訊為服務器3,并更改狀態為following
5.服務器5啟動,同4一樣
非第一次啟動選舉機制
1.當zookeeper集群中的一臺服務器出現以下兩種情況之一時,就會開始進入leader選舉
1)服務器初始化啟動
2)服務器運行期間無法和leader保持連接
2.而當一臺機器進入leader選舉流程時,當前集群也可能會處于以下兩種狀態
1)集群中本來就已經存在一個leader
對于已經leader的情況,機器試圖去選舉leader時,會被告知當前服務器的leader,對于該機器來說,僅僅需要和leader機器建立連接,并進行狀態同步即可
2)集群中確定不存在leader
假設zookeeper由5臺服務器組成,SID分別為1,2,3,4,5,zxid分別為8,8,8,7,7,并且此時sid為3的服務器為leader,某一時刻,3和5服務器出現故障,因此開始進行leader選舉
選舉leader規則:
1.epoch大的直接勝出
2.epoch相同,事務id大的勝出
3.事務id相同,服務器id大的勝出
所以,3和5故障后,2會成為leader
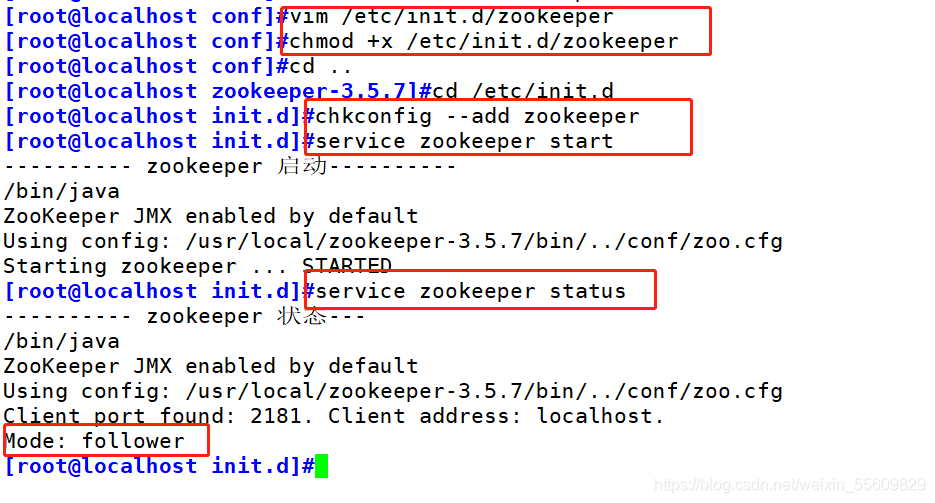
zookeeper集群部署
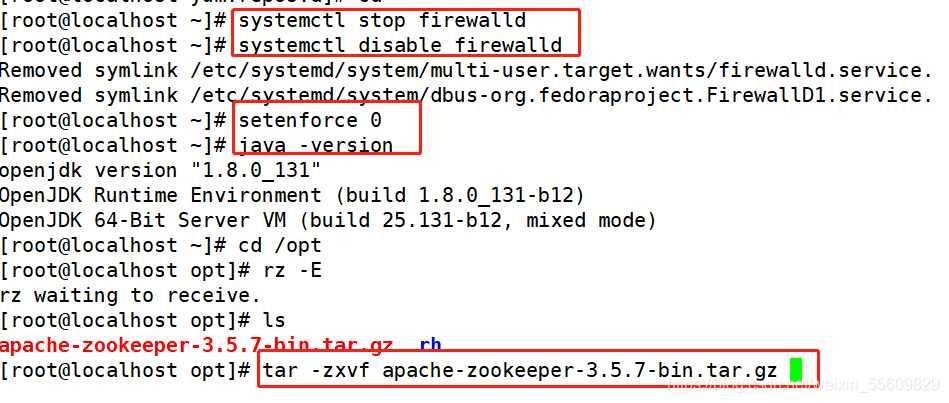
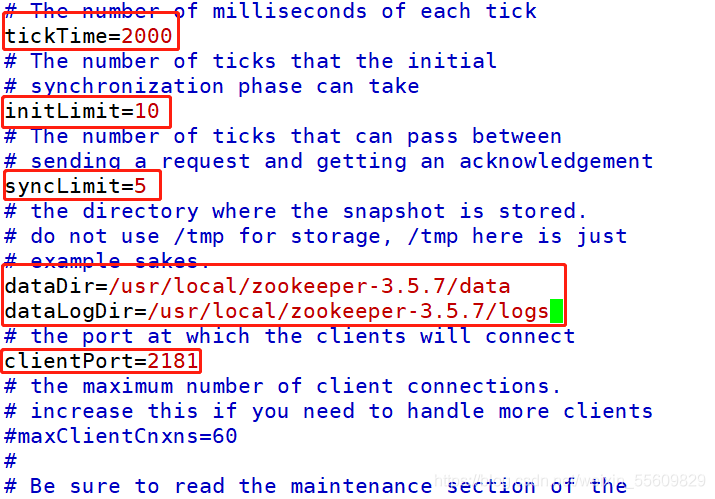
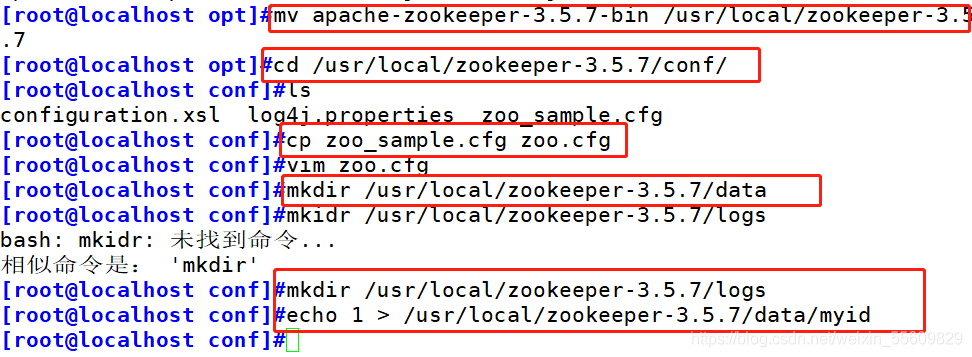
環境準備:
3臺服務器做zookeeper集群
192.168.146.41
192.168.146.10
192.168.146.11

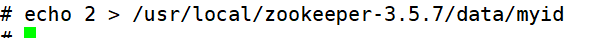

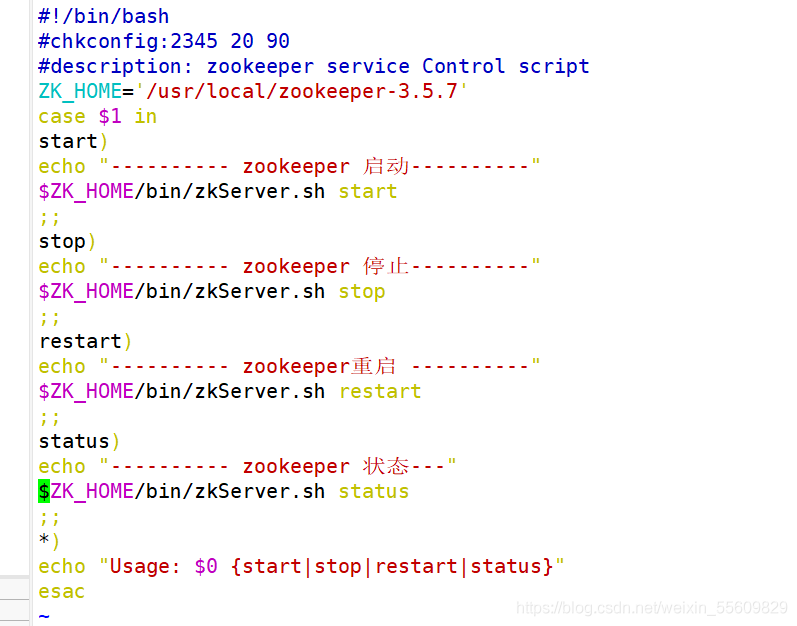
#!/bin/bash
#chkconfig:2345 20 90
#description: zookeeper service Control script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 啟動----------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止----------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper重啟 ----------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 狀態---"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289525.html
標籤:其他
上一篇:Hive之數倉的分層及建模理論