前言
有個朋友業務需要存大量的流水資料, 還希望可以實時根據流水聚合統計, 需求計算的精度到小數點18位(Es和Doris就可以直接ps了), 正好可以看看很火的clickhouse
不看不知道, 一看嚇一跳, 查詢速度是真快啊, 資料壓縮也是香了一匹, 運維再也不怕磁盤報警了!
簡單操作一下
因為我要測精度, 就不用官方示例了, 有興趣的建議了解一下, 比較全
搭建
直接在 docker倉庫 上找到clickhouse的鏡像, 拉取就完事了
// 拉取鏡像
docker pull yandex/clickhouse-server
// 建一個掛載目錄
mkdir -p /data/clickhouse
// 啟動
docker run -d -p 8123:8123 -p 9000:9000 --name house --ulimit nofile=262144:262144 --volume=/data/clickhouse:/var/lib/clickhouse yandex/clickhouse-server
建庫建表
連接ck
docker exec -it house /bin/bash
clickhouse-client
建庫建表
create database if not exists house;
CREATE TABLE house.asset \
( \
`user_id` String, \
`order_id` String, \
`currency` String, \
`from_wallet` UInt16, \
`to_wallet` UInt16, \
`op_type` UInt16, \
`amount` Decimal128(18), \
`c_time` UInt32 \
) \
ENGINE = MergeTree() \
PARTITION BY toYYYYMM(toDateTime(c_time)) \
ORDER BY (c_time) \
SETTINGS index_granularity = 8192;
表結構
- ENGINE = MergeTree() MergeTree系串列引擎的基礎表引擎, 使用最為廣泛;
- PARTITION BY toYYYYMM(toDateTime(c_time)) 把時間戳轉成年月日格式按月進行磁區;
- ORDER BY (c_time) ck是支持在插入表時就按照排序存盤的; 注意, 如果沒有指定 PRIMARY KEY, 則默認用排序欄位作為主鍵;
- SETTINGS index_granularity = 8192 索引粒度, 按默認的8192就行;
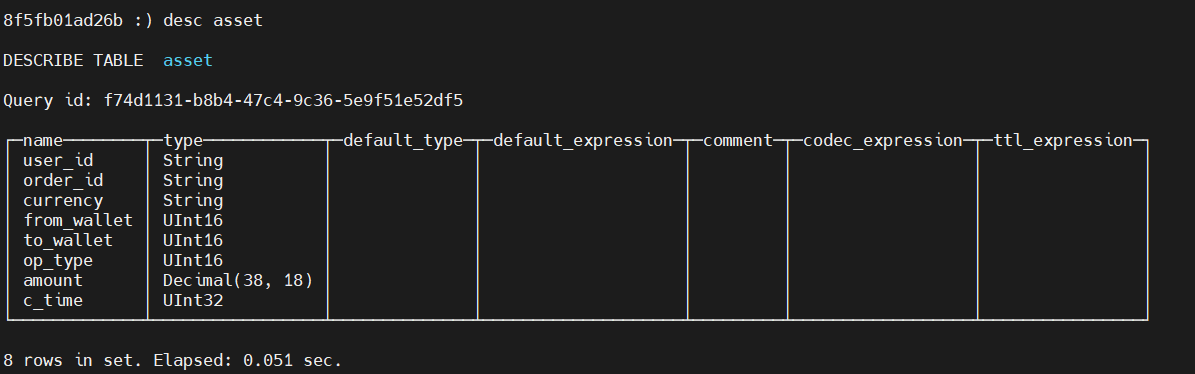
可以進入庫use house查看表的結構desc asset
準備資料
既然號稱PB資料存盤, 我這點欄位就以億為單位開始存吧, 一億資料也就 5.6G 的csv檔案;
使用命令列方式匯入
clickhouse-client --query "INSERT INTO house.asset FORMAT CSV" --max_insert_block_size=100000 < data.csv
確認下匯入數量
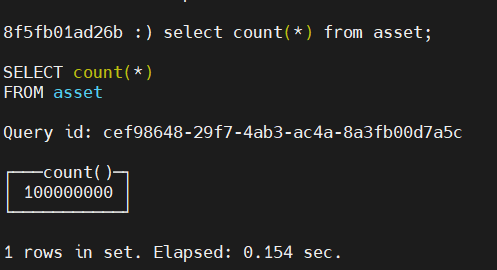
可以看到count 1億資料用了0.154s;
查詢性能
最通用的業務場景應該就是分組聚合了, 那就用下面兩條陳述句來進行測驗
select sum(amount) as amount, from_wallet from asset group by from_wallet;
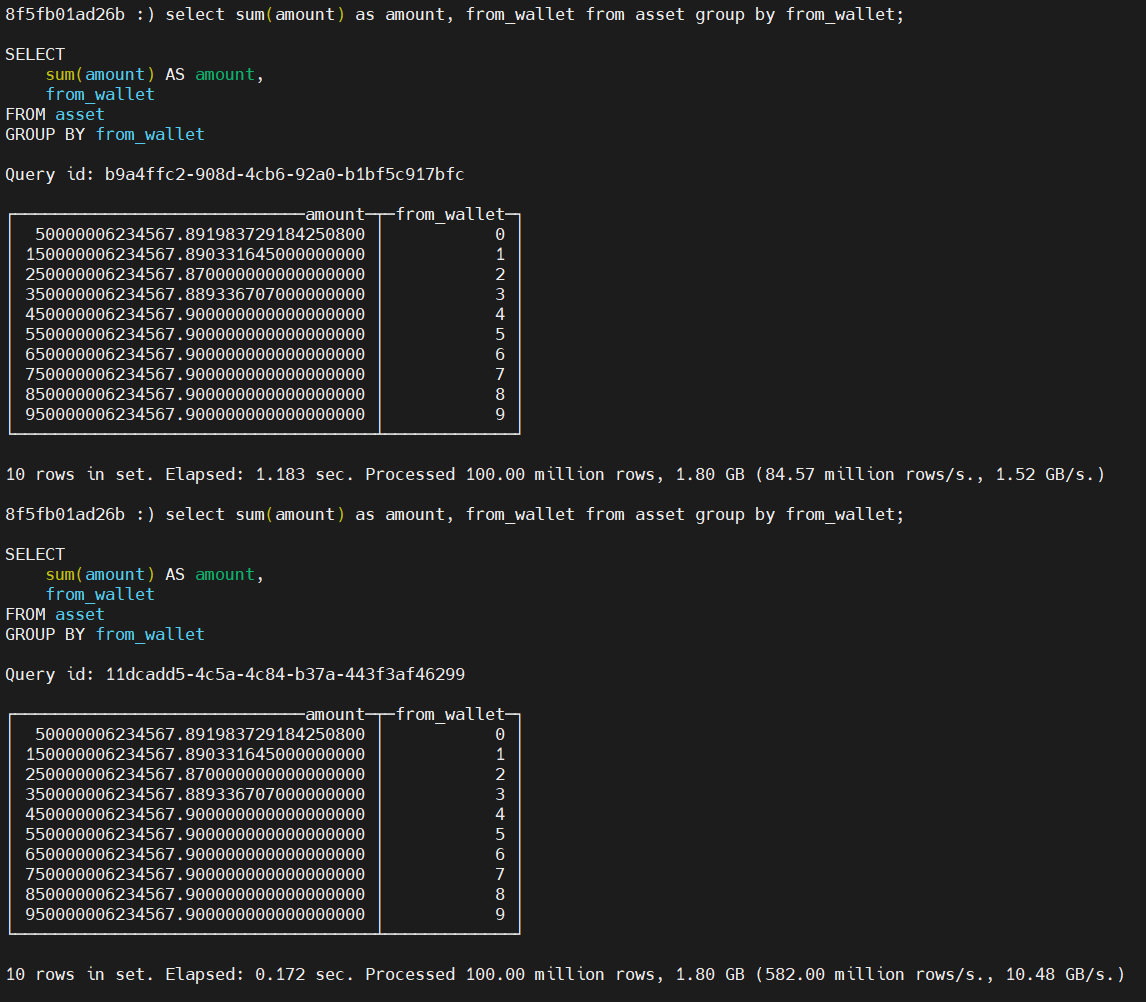
第一次1.183s, 第二次應該是有快取了 0.172s;
select sum(amount) as amount, from_wallet, to_wallet from asset group by from_wallet, to_wallet;
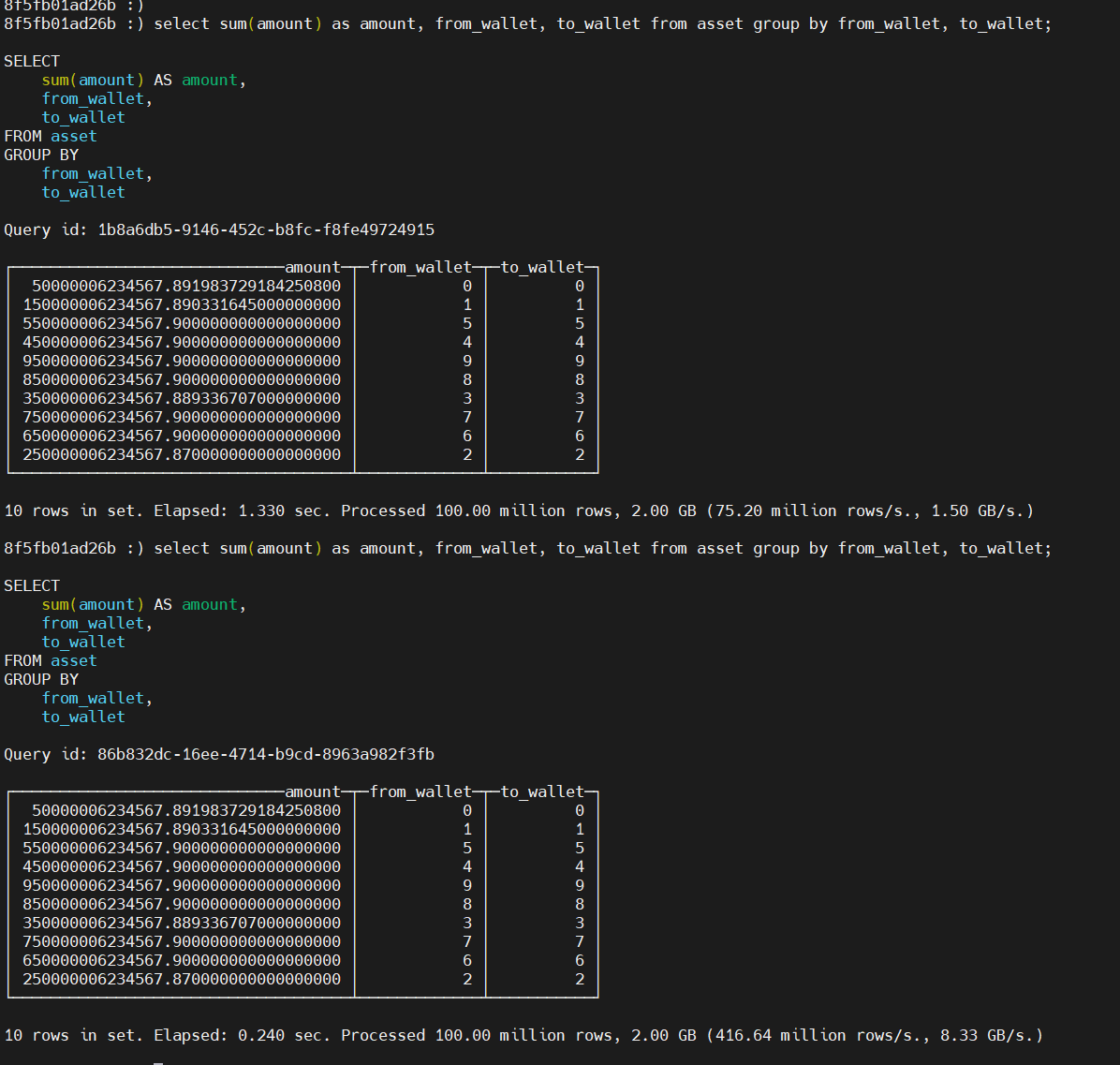
第一次1.33s, 第二次 0.24s;
那這個性能足以支撐業務了, 因為他們每天的流水資料是千萬級別的, 實時查詢可以每天做份留存, 然后統計當天實時流水就可以; 留存就每天預計算統計所有歷史流水, 保證準確性;
資料壓縮
最后值得一提的當然就是資料壓縮功能了, 進入資料目錄看一下大小

可以看到占用了1.3G的磁盤, 壓縮率≈23%!
那如果資料再大點呢? 這塊就直接把當前資料在復制兩遍試一下
insert into house.asset select * from house.asset
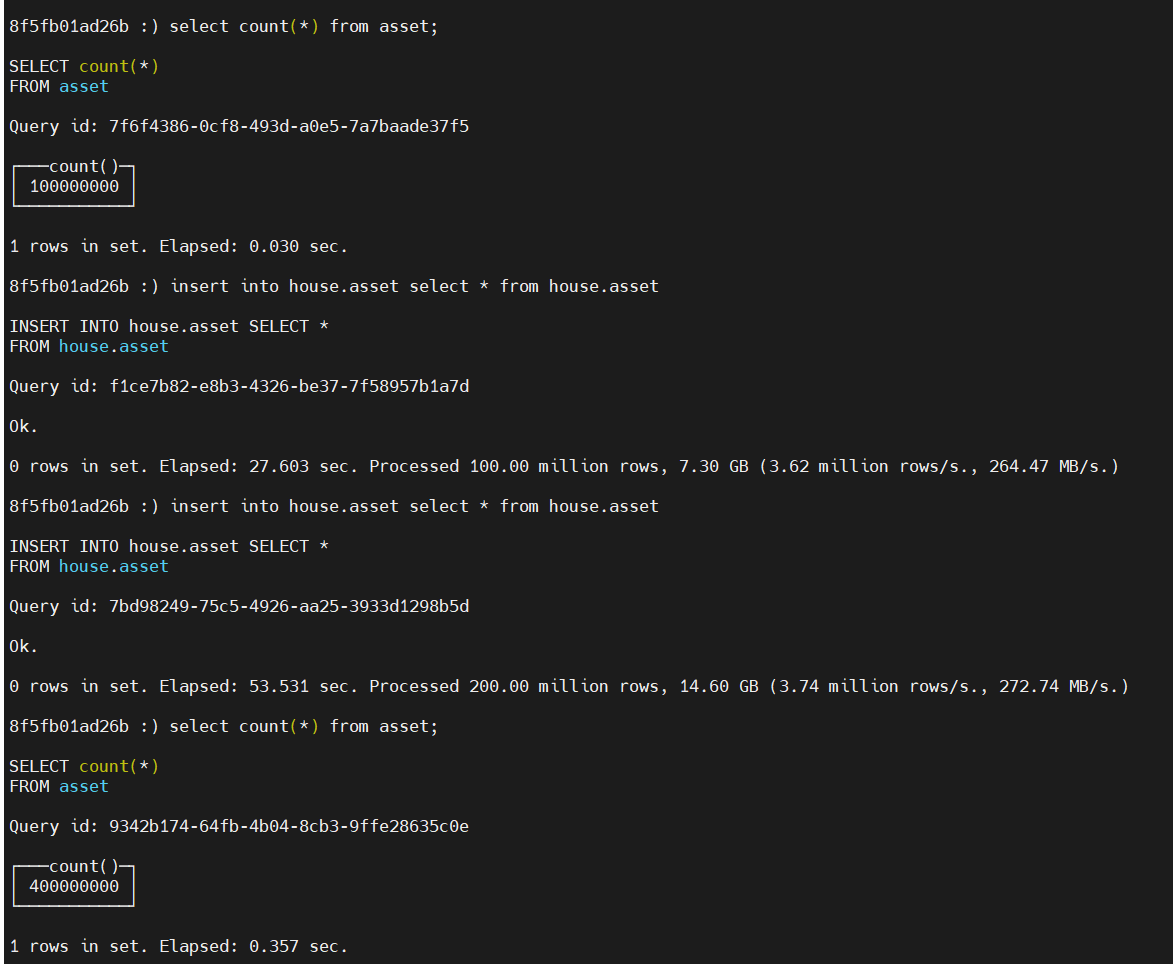

現在是4億的資料, 磁盤占用5G, 壓縮率≈22%!
Go Demo
package main
import (
"fmt"
"github.com/mailru/dbr"
_ "github.com/mailru/go-clickhouse"
"github.com/shopspring/decimal"
"log"
"time"
)
type (
asset struct {
UserId string
OrderId string
Currency string
FromWallet int
ToWallet int
OpType int
Amount decimal.Decimal
CTime int64
}
)
func main() {
connect, err := dbr.Open("clickhouse", "http://127.0.0.1:8123/house", nil)
if err != nil {
log.Fatal(err)
}
sess := connect.NewSession(nil)
_, err = sess.Exec("CREATE TABLE asset (`user_id` String, `order_id` String, `currency` String, " +
"`from_wallet` UInt16, `to_wallet` UInt16, `op_type` UInt16, `amount` Decimal128(18), `c_time` UInt32) " +
"ENGINE = MergeTree() PARTITION BY toYYYYMM(toDateTime(c_time)) ORDER BY (c_time) " +
"SETTINGS index_granularity = 8192;")
if err != nil {
log.Fatal("create table err: " + err.Error())
}
add := sess.InsertInto("asset").Columns("user_id", "order_id", "currency", "from_wallet", "to_wallet",
"op_type", "amount", "c_time")
amount, _ := decimal.NewFromString("0.123456789123456789")
for i := 0; i < 10000; i++ {
add.Record(asset{
UserId: fmt.Sprintf("%d", i),
OrderId: fmt.Sprintf("%d", time.Now().UnixNano()),
Currency: "USD",
FromWallet: 1,
ToWallet: 1,
OpType: 1,
Amount: amount.Add(decimal.NewFromInt(int64(i))),
CTime: time.Now().Unix(),
})
}
res, err := add.Exec()
log.Printf("res: %+v, err: %v", res, err)
countQ := sess.SelectBySql("select count(*) as total from asset")
var total int
_, err = countQ.Load(&total)
log.Printf("err: %v, total: %d", err, total)
var items []struct {
Amount decimal.Decimal `json:"amount"`
FromWallet int `json:"fromWallet"`
}
query := sess.SelectBySql("select sum(amount) as amount, from_wallet from asset group by from_wallet")
if _, err := query.Load(&items); err != nil {
log.Fatal(err)
}
for _, item := range items {
log.Printf("amount: %v, fromWallet: %v", item.Amount, item.FromWallet)
}
}
總結
ck的優劣勢百度一搜一大堆, 大家就根據自己的業務場景來選擇是否用它吧, 用了就是真香!
官方檔案
資料查詢
時間操作
可視化工具下載
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289798.html
標籤:其他
上一篇:STM32H750獲取OV2640攝像頭影像及上位機解碼(一維碼&二維碼)
下一篇:運維巡檢參考手冊