文章目錄
- 1 能夠作為生成器的神經網路 GAN
- 2 動漫人物頭像生成
- 3 判別器(Discriminator)
- 4 從自然選擇看GAN的基本思想
- 5 GAN 的具體實作程序
- 步驟一: 固定 generator G 的引數,只更新discriminator D
- 步驟二: 固定 discriminator D 的引數,只更新generator G
- 6 動漫頭像生成的具體實驗結果
1 能夠作為生成器的神經網路 GAN
生成式對抗網路(GAN, Generative Adversarial Networks )是一種深度學習模型,是近年來復雜分布上無監督學習最具前景的方法之一,模型通過框架中(至少)兩個模塊:生成模型(Generative Model)和判別模型(Discriminative Model)的互相博弈學習產生相當好的輸出,
generative adversarial network,它的縮寫是GAN,中文名稱生成式對抗網路,這也是不少人在還沒有接觸機器學習之前都有聽說過的一個很出名的模型,它其實有很多各式各樣的變形,你可以在網路上找到一個GAN的動物園:

2 動漫人物頭像生成
直接通過一個例子來介紹什么是GAN,以及GAN要做什么,怎么實作的,假設我們現在的任務是讓機器生成二次元人物的頭像,假設現在是 unconditional generation,就是沒有輸入x,只有輸入的一個隨機變數z
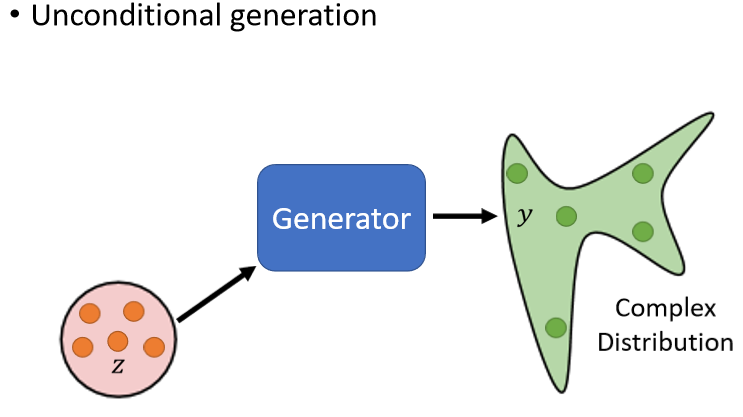
那之后我們在講到 conditional generation 的時候,我們會再把x加回來,那輸入的這個z是什么呢?
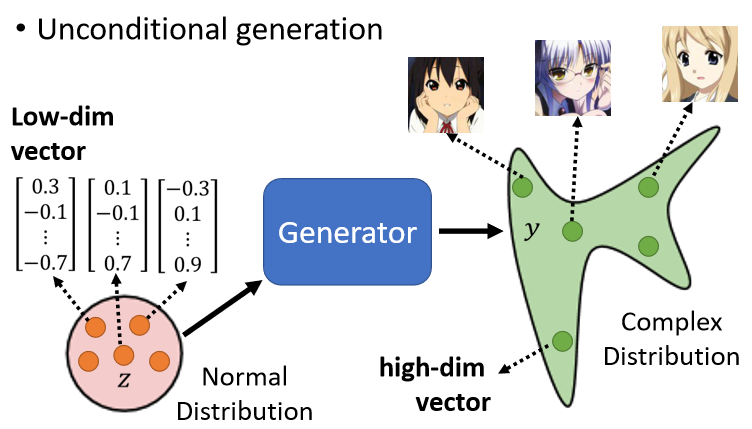
實際上我們可以假設z是從一個normal distribution里采樣出來的向量,這個向量通常會是一個 low-dimensional 的向量,一般定位50,100維,它的大小是由你自己決定的,
那現在我們從一個normal distribution里面采樣出一個向量z,然后輸入給GAN,GAN就給你一個對應的輸出,那我們希望對應的輸出就是一個二次元人物的臉,而一張圖片就是一個非常高維的向量,所以generator實際上做的就是產生一個非常高維的向量,
當你輸入的向量不同的時候,你的輸出就會跟著改變,所以你從這個normal distribution里面采樣到不同的z,那么每次輸出的y也就不一樣,但我們希望不管采樣到什么z,輸出來的都是動漫人物的臉,
3 判別器(Discriminator)
在GAN里面一個特別的地方就是,除了generator以外,我們要多訓練一個discriminator,discriminator的作用是,輸入一張圖片,輸出是一個數值,這個數值越大就代表現在輸入的這張圖片越像是真實的二次元人物的影像,
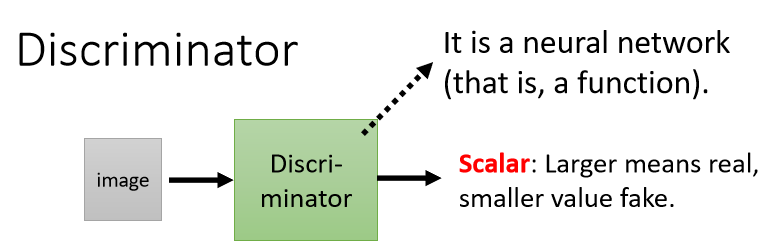
而discriminator的架構完全是你自己設計的,你可以用CNN,也可以用 transformer 等等,只要能夠產生出你想要的輸入輸出,就可以了,
在這個例子里面,因為discriminator的輸入是一張圖片,很顯然選擇CNN很比較有優勢,畢竟CNN在處理影像上有很多優點,
4 從自然選擇看GAN的基本思想
為什么除了生成器之外,我們還需要多訓練一個判別器呢,這里其實GAN的基本思想可以從生物進化的角度來看,我這里復述一下李宏毅老師舉的一個比較有趣的例子:

上面這張圖似乎沒什么特別的哈?不就是一個樹枝和一篇枯葉嘛,但其實這不是一片枯葉,這是枯葉蝶的擬態,枯葉蝶長得跟枯葉非常像,因此它可以躲避天敵,但枯葉蝶的祖先其實并不是長得像枯葉一樣,也許他們原來也是五彩斑斕的,但為什么他們變成長得像枯葉一樣,是因為有天擇的壓力,

這個不是普通的麻雀,這個是波波(一種寶可夢),波波會吃枯葉蝶的祖先,在天擇的壓力之下,枯葉蝶就變成棕色的,因為波波它只會吃彩色的東西,它看到彩色的東西知道是蝴蝶,就把它吃掉,那看到棕色的東西,波波就不會去吃它,
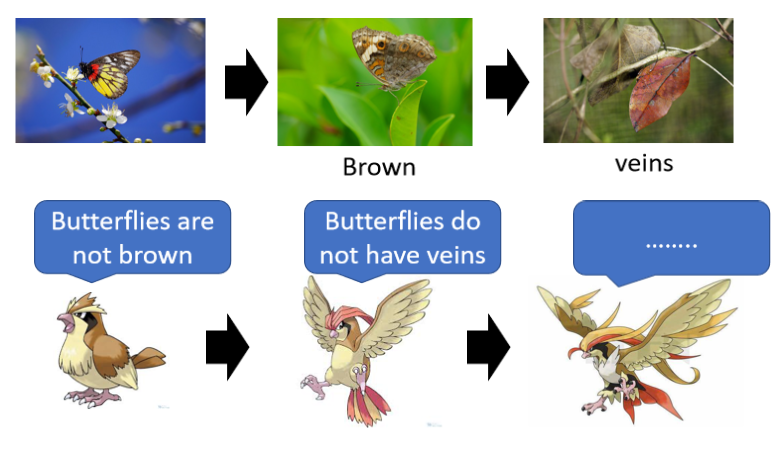
但是逐漸這樣下去,只會吃彩色蝴蝶的波波慢慢的找不到足夠的食物,也會被大自然淘汰了,在自然選擇中獲勝的波波都進化了,它們進化成了比比鳥,比比鳥在判斷一個蝴蝶能不能吃的時候不會只看顏色,它會看它的紋路,它知道說沒有葉脈的是蝴蝶,有葉脈的才是真正的枯葉,
在天擇的壓力之下,枯葉蝶就產生了擬態,產生了葉脈,想要騙過比比鳥,但是比比鳥它也有可能會再進化成大比鳥,那大比鳥可能可以分辨枯葉蝶跟枯葉的不同,
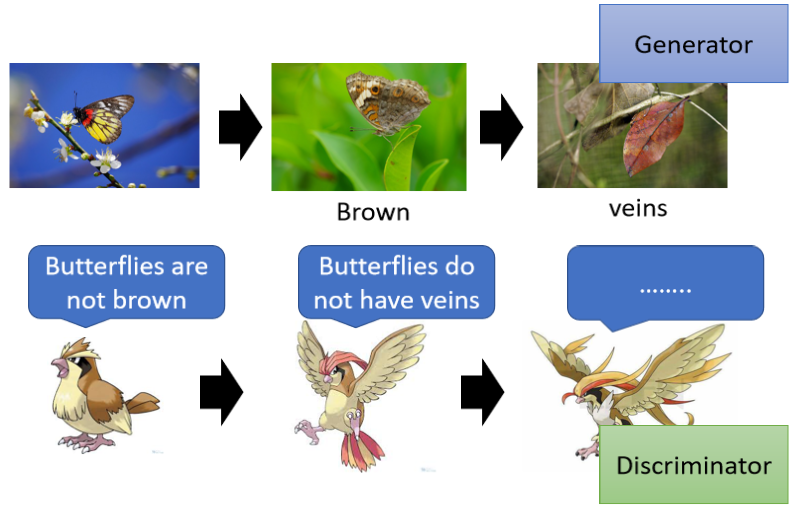
那這個是一個物種演化的故事,對應到GAN中的相關概念,枯葉蝶就是generator,那波波就是discriminator,
回到我們之前的例子中來,現在我們generator要做的事情,是畫出二次元的人物頭像,那generator學習畫出二次元人物頭像的程序是這樣的:
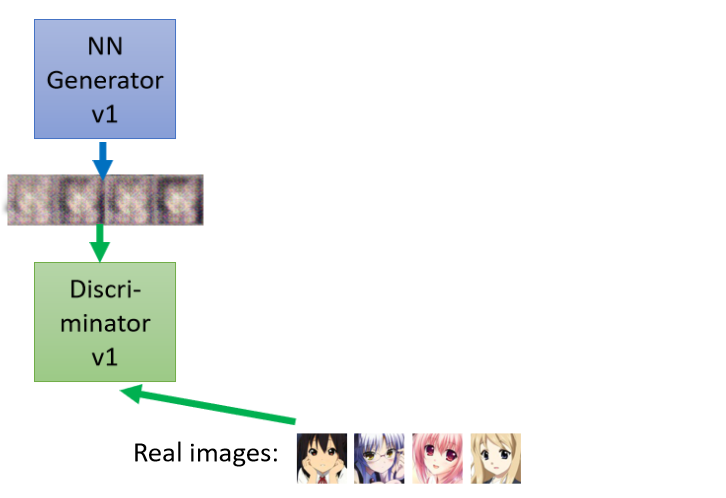
第一代的generator它的引數幾乎是完全隨機的,所以它根本就不知道到底要怎么畫二次元的人物,所以它畫出來的東西就是一些莫名其妙的東西,
那discriminator學習的目標是分辨generator的輸出與真正的動漫頭像的不同,在現在的狀況下可能非常的容易,對discriminator來說它只要看圖片里面有沒有兩個黑黑的圓球,有眼睛就是真正的二次元人物,沒有眼睛就是generator產生出來的東西,
接下來generator就調整它的里面的引數,Generator就進化了,它調整它里面的引數,調整的目標是為了騙過discriminator,假設discriminator判斷一張圖片是不是真實的依據是有沒有眼睛,那generator就產生眼睛出來,以期能夠騙過discriminator:
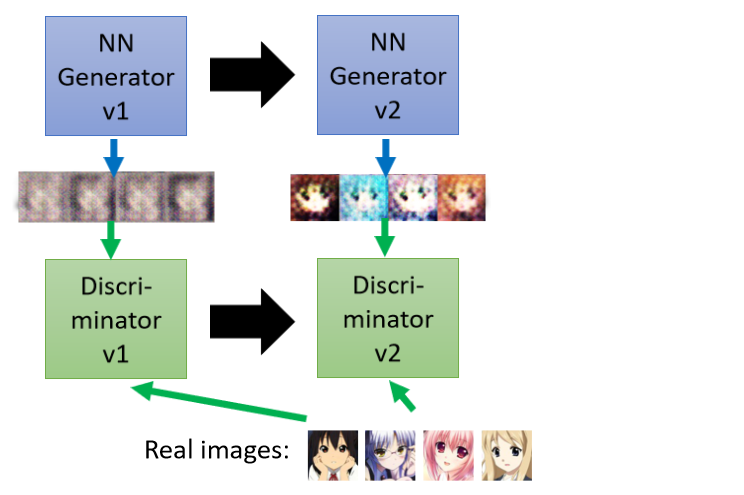
所以第二代的generator可以產生眼睛,這樣就可以騙過第一代的discriminator,但是discriminator也是會進化的,第二代的discriminator會試圖分辨generator產生的圖片,跟真實圖片之間的差異,它可能會發現說,generator產生的圖片都沒有頭發也沒有嘴巴,真實圖片是有頭發的也有嘴巴的,
接下來第三代的generator就會想辦法去騙過第二代的discriminator,既然第二代的discriminator是看有沒有頭發和嘴巴來判斷是不是真正的二次元人物,那第三代的generator就會把嘴巴加上去,
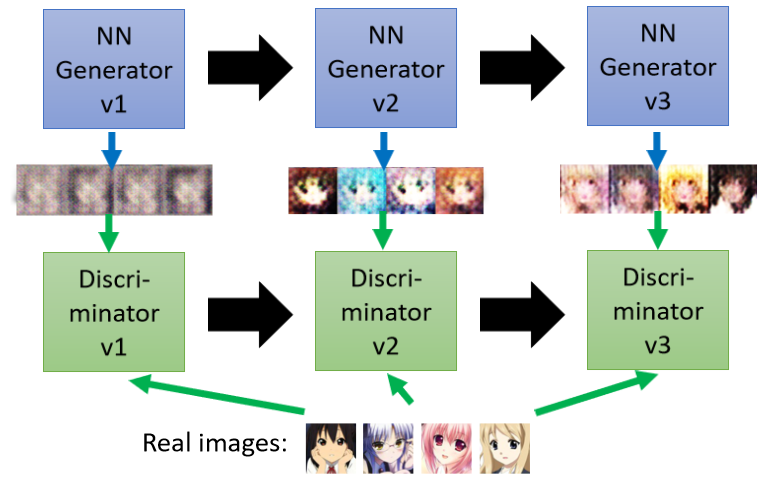
那discriminator也會逐漸的進步,它會越來越嚴苛,在這樣的左右互搏之后,我們期望Generator產生出來的圖片可以越來越像真實二次元的人物,
可以看到我們的generator跟discriminator中間有一個對抗的關系,所以就用了adversarial這個詞語,總而言之,generator跟discriminator既是對抗的,也是互相成就的,其中任何一方太弱的話,都會導致雙方都訓練不起來,
5 GAN 的具體實作程序
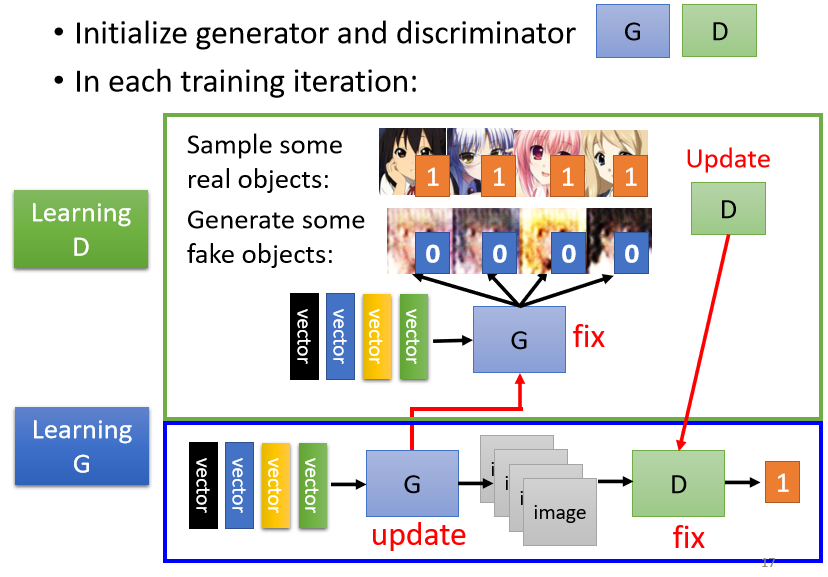
接下來介紹一下GAN的具體實作程序是怎樣的,generator和discriminator,他們就是兩個network,我們假設generator跟discriminator的引數都已經初始化過了,
步驟一: 固定 generator G 的引數,只更新discriminator D
初始化完以后,接下來訓練的第一步是,固定住你的generator的引數,只訓練你的discriminator,
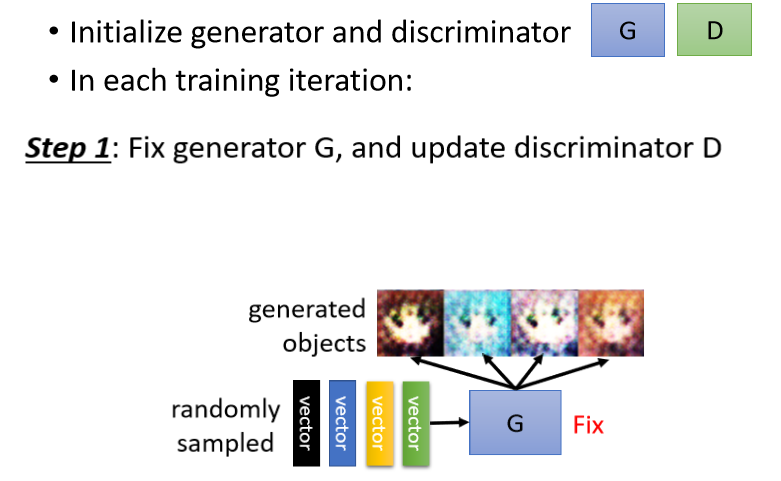
因為一開始generator的引數都是隨機初始化的,并且我們又固定住了generator的引數,那它的輸出完全都是亂七八糟的圖片,
那假設我們有一個database,這個database里面有很多二次元人物的頭像,從這個圖庫里面去sample一些二次元人物的頭像出來,用這些真正的二次元人物頭像,跟generator產生出來的結果,去訓練你的discriminator,

discriminator訓練的目標是要分辨真正的二次元人物跟generator產生出來的二次元人物之間的差異,具體一點來說,實際上我們可能會把這些真正的人物都標1,Generator產生出來的圖片都標0,
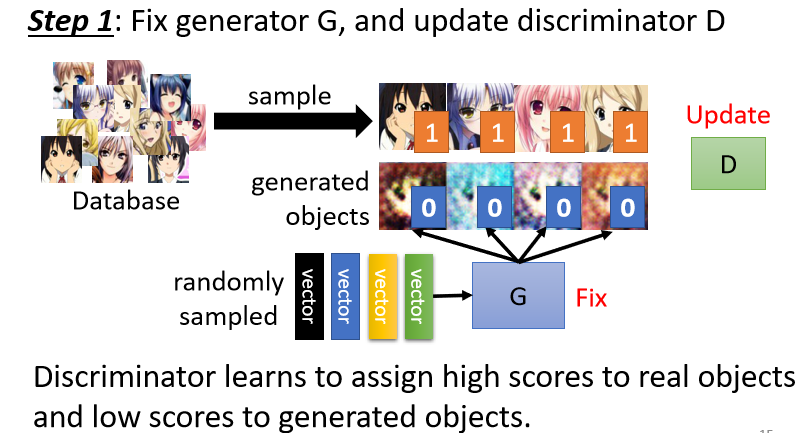
接下來對于discriminator來說,這就是一個分類的問題,你就把真正的人臉當作類別1,Generator產生出來的圖片當作類別2,然后訓練一個classifier就結束了,或者看做一個回歸的問題,輸出的值越接近1,就代表越接近真實圖片;而越接近1,就代表越接近假的圖片,這兩種辦法都可以,
步驟二: 固定 discriminator D 的引數,只更新generator G
我們訓練完discriminator以后,接下來固定住discriminator,改為訓練generator,
我們要讓generator想辦法去騙過discriminator,因為剛才discriminator已經學會分辨真圖跟假圖的差異,generator產生的圖片如果可以騙過discriminator,那在discriminator足夠強大的情況下,生成的圖片就可以假亂真了,
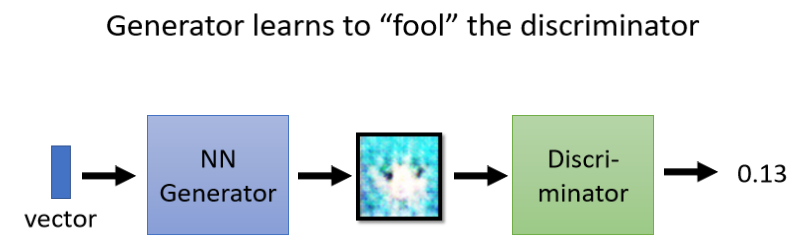
實際的操作方法是這樣的,你有一個generator,generator從gaussian distribution sample出來一個向量作為輸入,然后輸出一個圖片的向量,
接下來我們把這個圖片輸入到Discriminator里面,Discriminator會給這個圖片一個分數,分數越高表示越接近真實圖片,
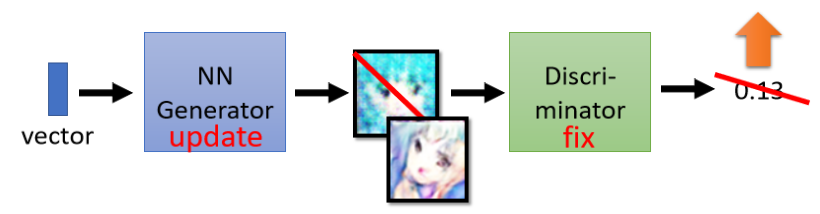
那Generator訓練的目標就是要Discriminator輸出的值越大越好,如果Generator調整引數之后輸出的圖片可以蒙騙Discriminator,也就是Discriminator會給予高分,那意味著Generator產生出來的圖片是比較真實的,
所以現在講了兩個步驟
- 第一個步驟:固定generator,訓練discriminator
- 第二個步驟:固定discriminator,訓練generator
接下來就是重復這兩個步驟反復的訓練discriminator和generator,期待discriminator跟generator都可以做得越來越好,直到generator產生圖片的效果能讓我們比較滿意,
6 動漫頭像生成的具體實驗結果
以下的結果是李宏毅老師在17年的時候做的, dataset的地址: https://zhuanlan.zhihu.com/p/24767059,訓練了100個來回之后的結果如下:

這時generator還不知道在做些什么,但訓練了1000個回合后的結果如下:

discriminator 和 generator 各自訓練這樣反復一千次以后,機器就產生了眼睛,機器知道說人臉就是要有兩個眼睛,所以它就把眼睛標上去,訓練到兩千次的時候,你發現嘴巴就出來了:

訓練到五千次的時候,已經開始有一點人臉的樣子了,而且你發現說機器學到了影片人物啊,就是要有那個水汪汪的大眼睛,所以它給每個人的眼睛呢都涂得非常的大:

接下來是訓練兩萬個回合的結果:

然后是訓練五萬個回合的結果:

那你會發現這些生成的動漫人物大體上還不錯,只是有一些比較崩壞,如果你有真的非常好的資料的話,也許你可以做出真的很好的結果,
這里有一個鏈接:
https://www.gwern.net/images/gan/stylegan/2019-02-11-stylegan-danbooru2017faces-interpolation.mp4
這個是用StyleGAN做的,那用StyleGAN可以做到這個地步:

可以看到效果已經相當好了,完全辨別不出來是機器自己產生的,這個結果還是很驚人的,
除了產生影片人物以外,當然也可以產生真實的人臉,有一個技術叫做progressive GAN,它可以產非常高清的人臉,你可能會問產生人臉有什么用呢,我去路邊拍一個人產生出來的照片不是更像真的嗎?
但是用GAN你可以產生你沒有看過的人臉,甚至根本不存在的人臉,這就是GAN的神奇之處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289820.html
標籤:AI
下一篇:【史詩級干貨長文】集成學習演算法