大家好,我是辣條,
之前有寫過一篇爬取微博熱評的文章,奈何最近吳某的瓜實在太大了,全網都關注著這件事,直到昨天官方【公安部門】出來說明,這一事件有了小句號,今天和大家聊聊抓取微博熱評,順便了解此次事件來龍去脈,

爬取目標
網址:微博
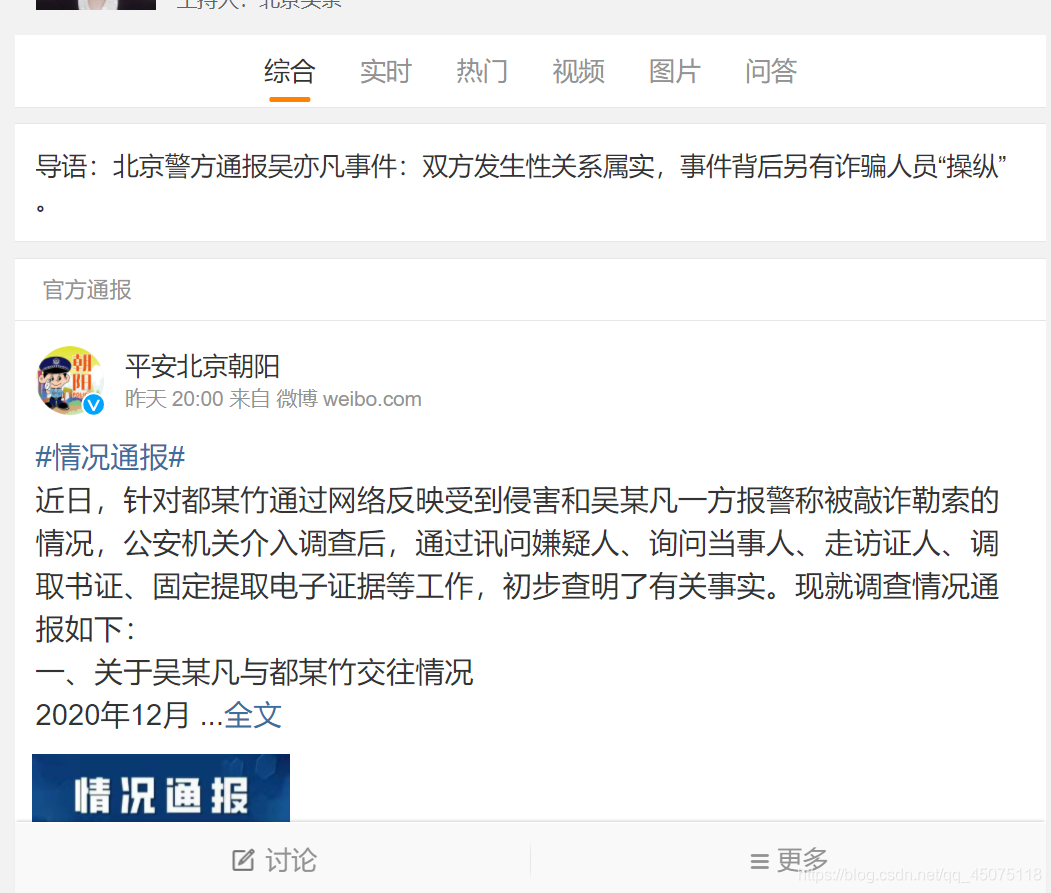
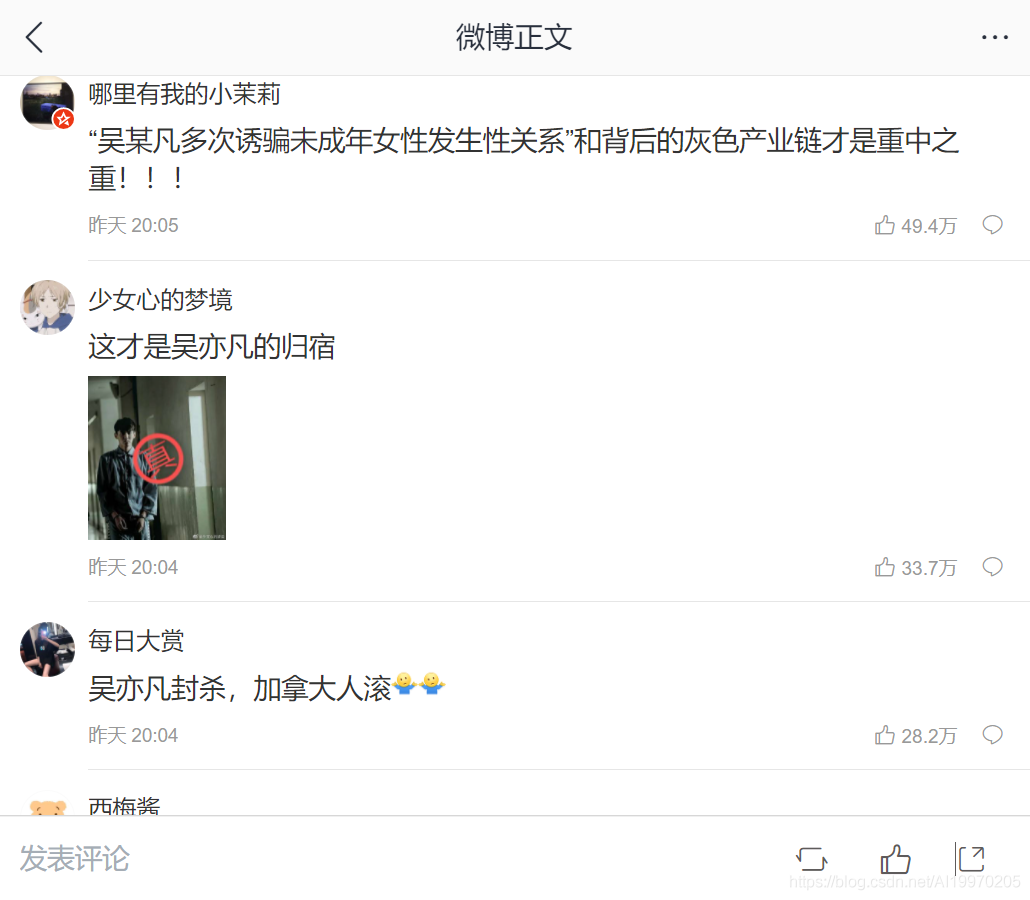
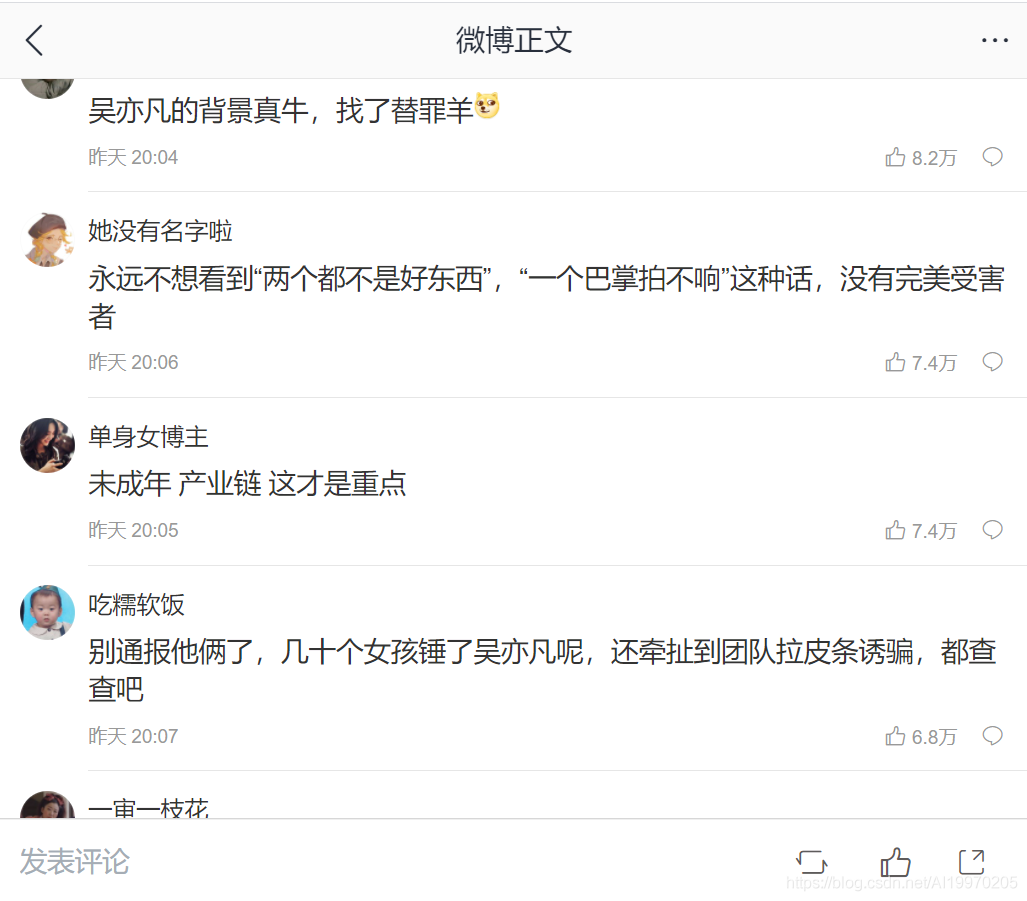
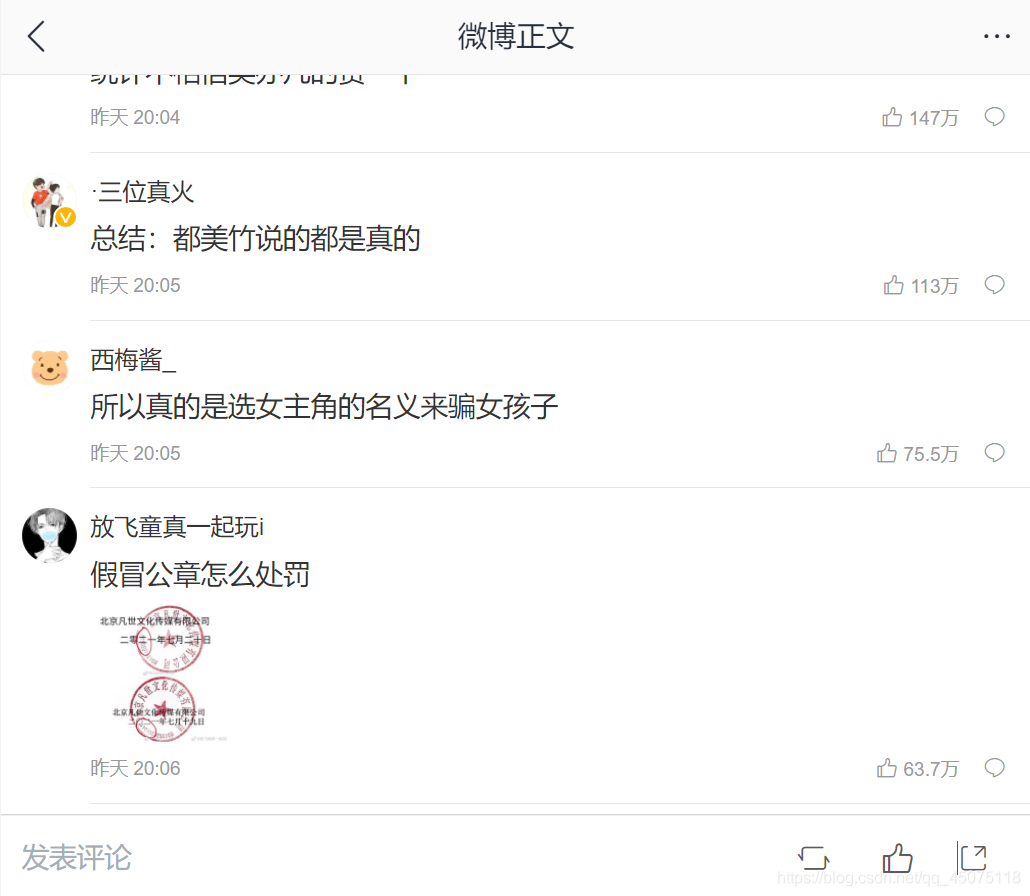
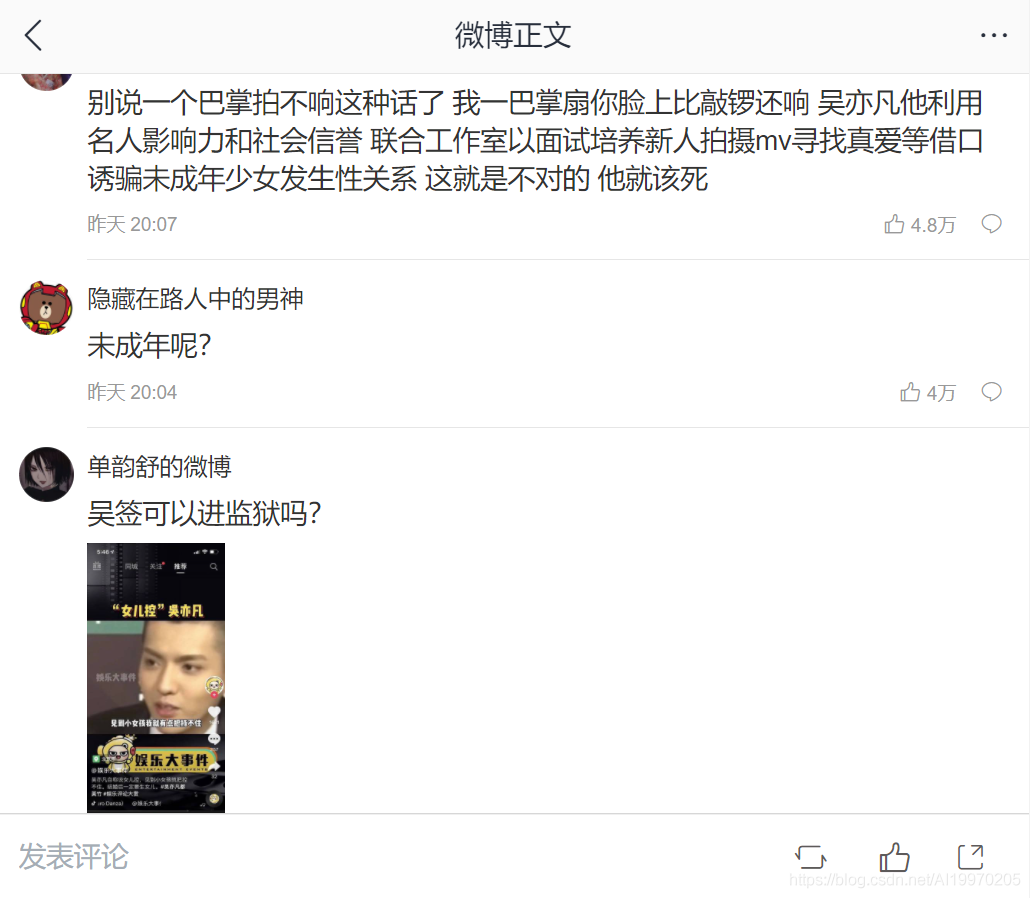
效果展示
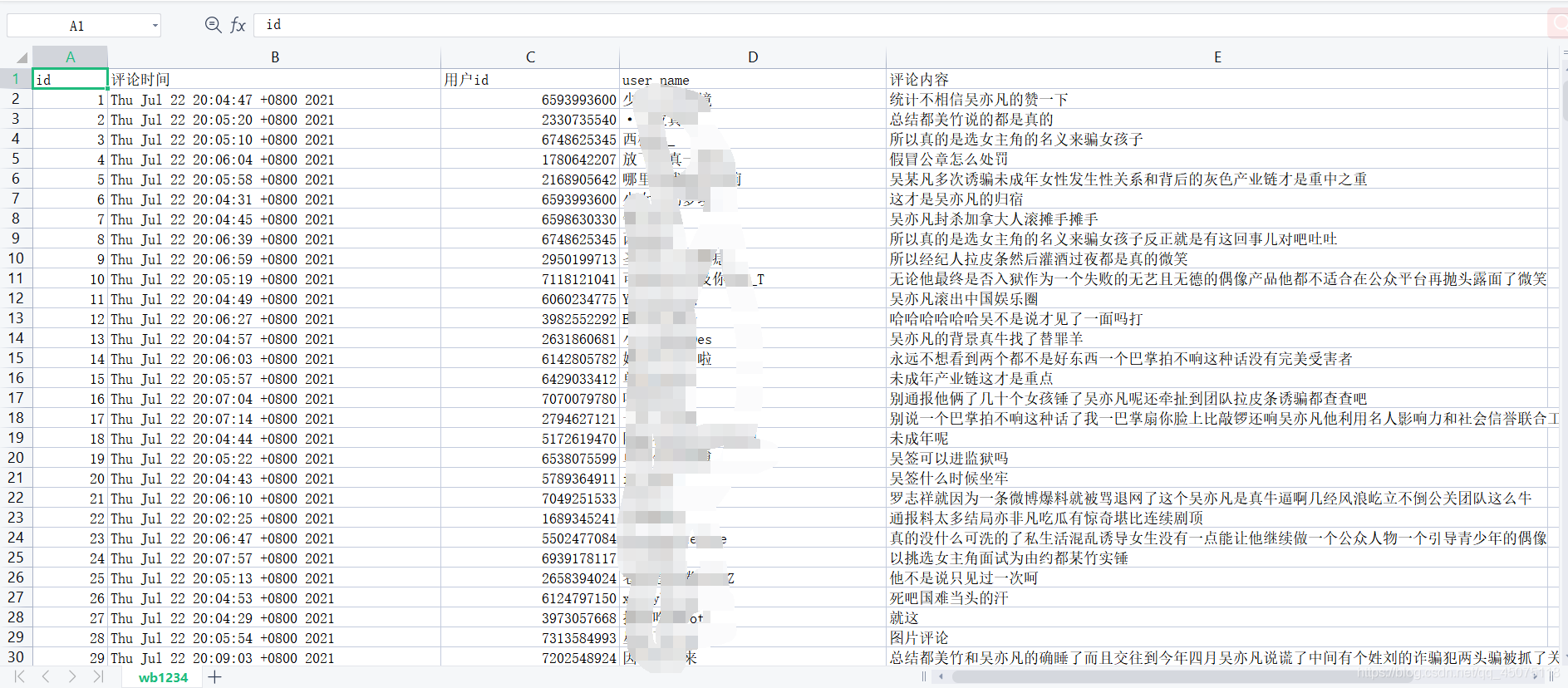
工具使用
開發環境:win10、python3.7
開發工具:pycharm、Chrome
工具包:requests、re,csv
專案思路決議
找到需要吃瓜的文章

請求頭需要帶上的基本配置資料
headers = {
"referer": "",
"cookie":"",
"user-agent": ""
}找到文章動態提交的評論資料
通過抓包工具找到對應的評論資料資訊
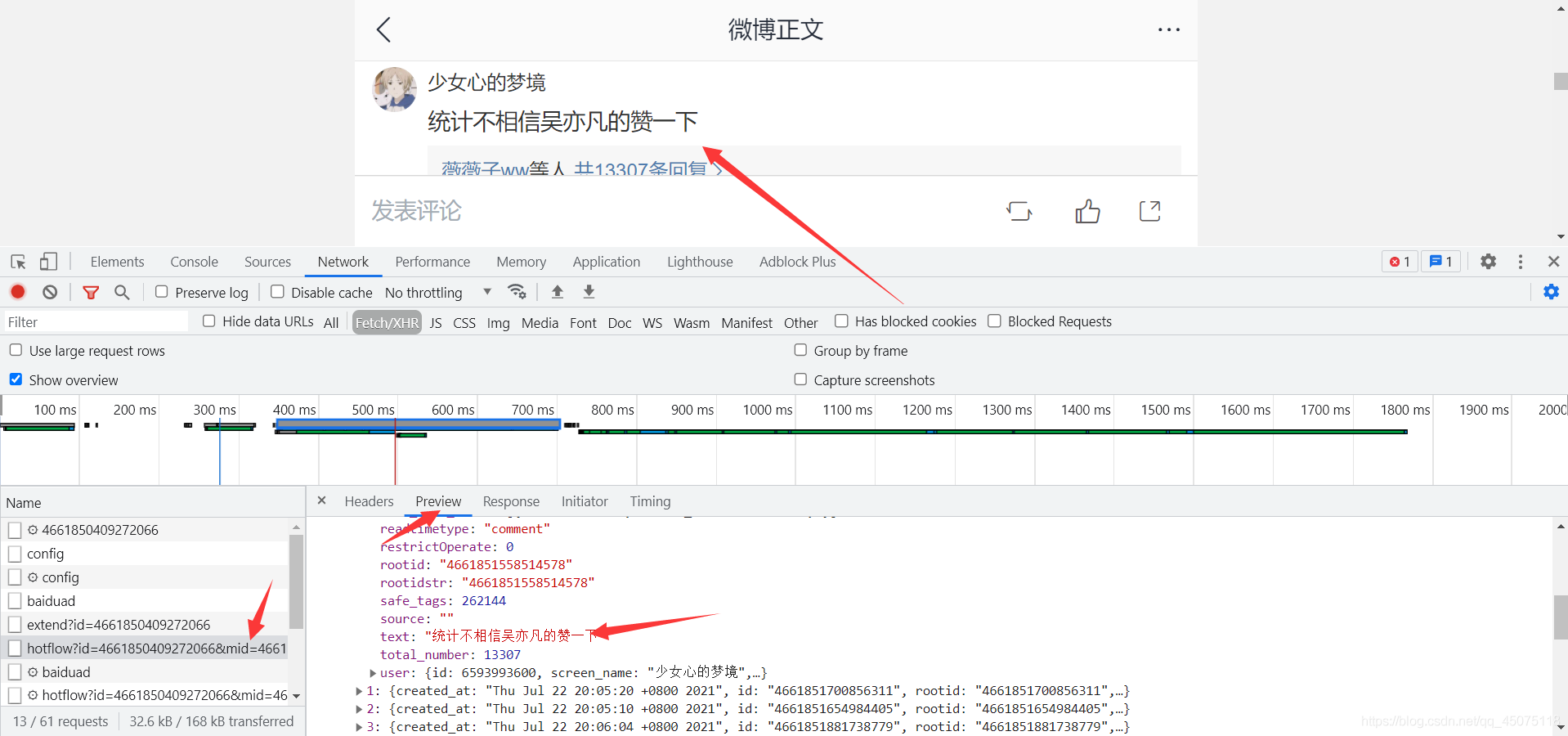
微博的url會有一個文章id,mid也是文章id, max_id是每個json資料里面的max_id,是沒有規律的
https://m.weibo.cn/comments/hotflow?id=4661850409272066&mid=4661850409272066&max_id=5640809315785878&max_id_type=0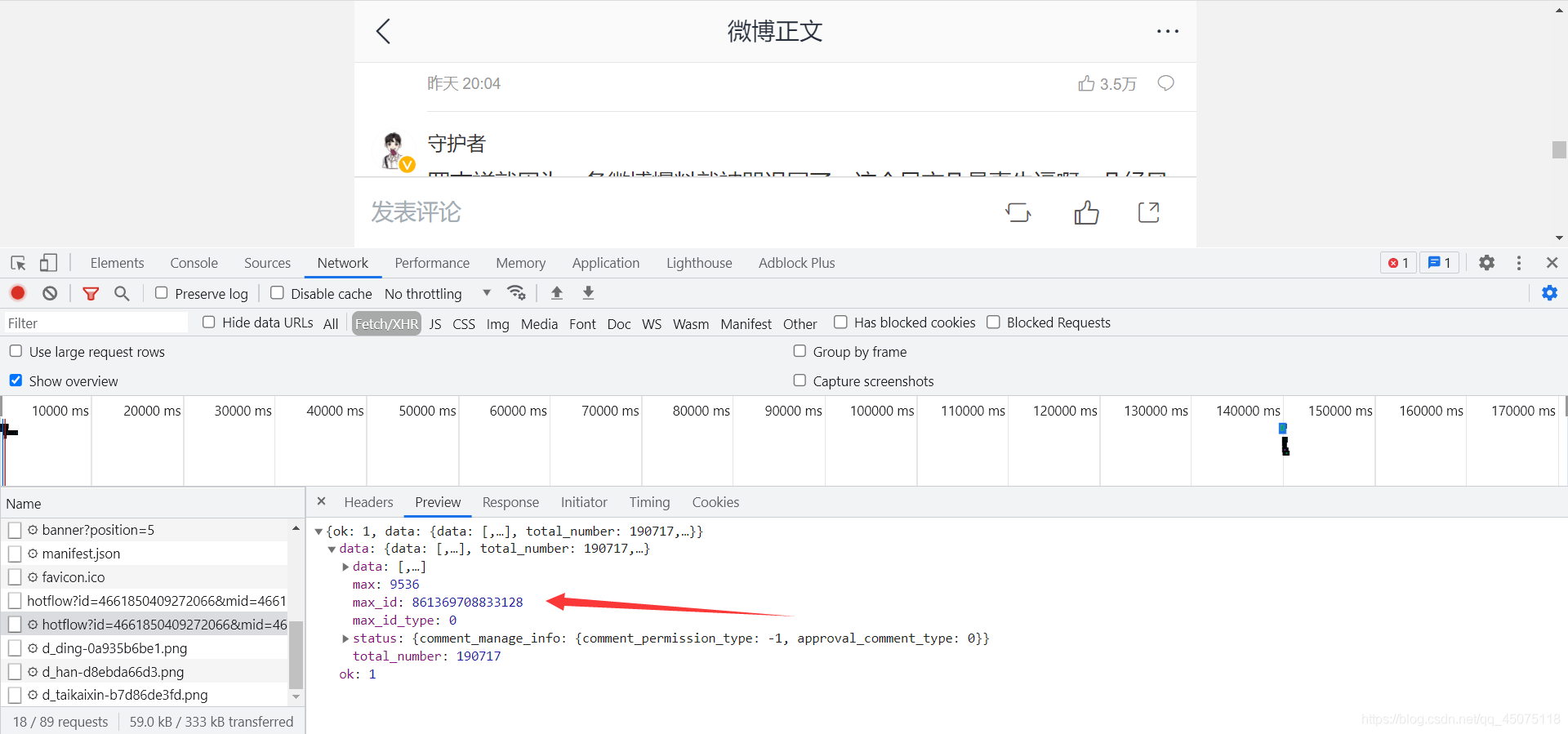
取出當前的max_id,就會獲取到下個頁面的請求介面
簡易原始碼分析
import csv
import re
import requests
import time
?
start_url = "https://m.weibo.cn/comments/hotflow?id=4661850409272066&mid=4661850409272066&max_id_type=0"
next_url = "https://m.weibo.cn/comments/hotflow?id=4638585665621278&mid=4661850409272066&max_id={}&max_id_type=0"
continue_url = start_url
headers = {
"referer": "https://m.weibo.cn/detail/4638585665621278",
"cookie": "SUB=_2A25Nq-BcDeRhGeBG7VUW-SnEyjyIHXVvV4AUrDV6PUJbkdAKLULFkW1NRhXYfC2JIAilAAFJ_-2diWZ1ZEACRZ5K; SCF=AgGUxHxg_ZjvVbYikCOVICTc-a4gDcEtR02fexDZstBq_XKr3s1Rp9CxdS4y4k4IvDQ2eIgTTyJg73pcUmvYRKc.; _T_WM=58609113785; WEIBOCN_FROM=1110006030; MLOGIN=1; M_WEIBOCN_PARAMS=oid%3D4638585665621278%26luicode%3D20000061%26lfid%3D4638585665621278%26uicode%3D20000061%26fid%3D4638585665621278; XSRF-TOKEN=06ed3f",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
count = 0
?
def csv_data(fileheader):
with open("wb1234.csv", "a", newline="")as f:
write = csv.writer(f)
write.writerow(fileheader)
?
?
def get_data(start_url):
print(start_url)
try:
response = requests.get(start_url, headers=headers).json()
max_id = response['data']['max_id']
except Exception as e:
get_data(start_url.split("type")[0] + "type=1")
?
else:
# max_id = response['data']['max_id']
content_list = response.get("data").get('data')
for item in content_list:
global count
count += 1
create_time = item['created_at']
text = "".join(re.findall('[\u4e00-\u9fa5]', item["text"]))
user_id = item.get("user")["id"]
user_name = item.get("user")["screen_name"]
# print([count, create_time, user_id, user_name, text])
csv_data([count, create_time, user_id, user_name, text])
?
global next_url
continue_url = next_url.format(max_id)
time.sleep(2)
get_data(continue_url)
?
?
if __name__ == "__main__":
fileheader = ["id", "評論時間", "用戶id", "user_name", "評論內容"]
csv_data(fileheader)
get_data(start_url)往期推送:
我用Python修改了班花的開機密碼,重新登錄后竟然發現了她的秘密!
我用Python采集了班花的空間資料集,除了美照竟然再一次發現了她另外的秘密!
室友單戀班花失敗,我爬了一個網站發給他瞬間治愈,男人的快樂就這么簡單【每天一遍,忘記初戀】
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289847.html
標籤:其他