前言
MV3D-Net融合了視覺影像和激光雷達點云資訊;它只用了點云的俯視圖和前視圖,這樣既能減少計算量,又保留了主要的特征資訊,隨后生成3D候選區域,把特征和候選區域融合后輸出最終的目標檢測框,
論文地址:Multi-View 3D Object Detection Network for Autonomous Driving
開源代碼:https://github.com/bostondiditeam/MV3D
目錄
一、框架了解
1.1 網路的主體部分
1.2 網路的融合部分
二、MV3D的點云處理
2.1 提取點云俯視圖
2.2 提取點云前視圖
三、MV3D的影像處理
四、俯視圖計算候選區域
五、特征整合
六、特征融合
七、模型效果
八、模型代碼
一、框架了解
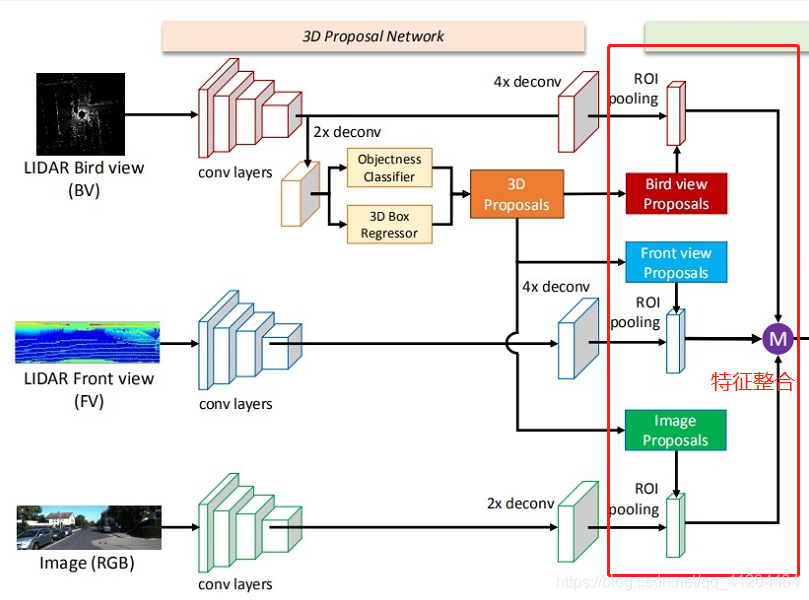
先看下總體網路結構:(可以點擊圖片放大查看)
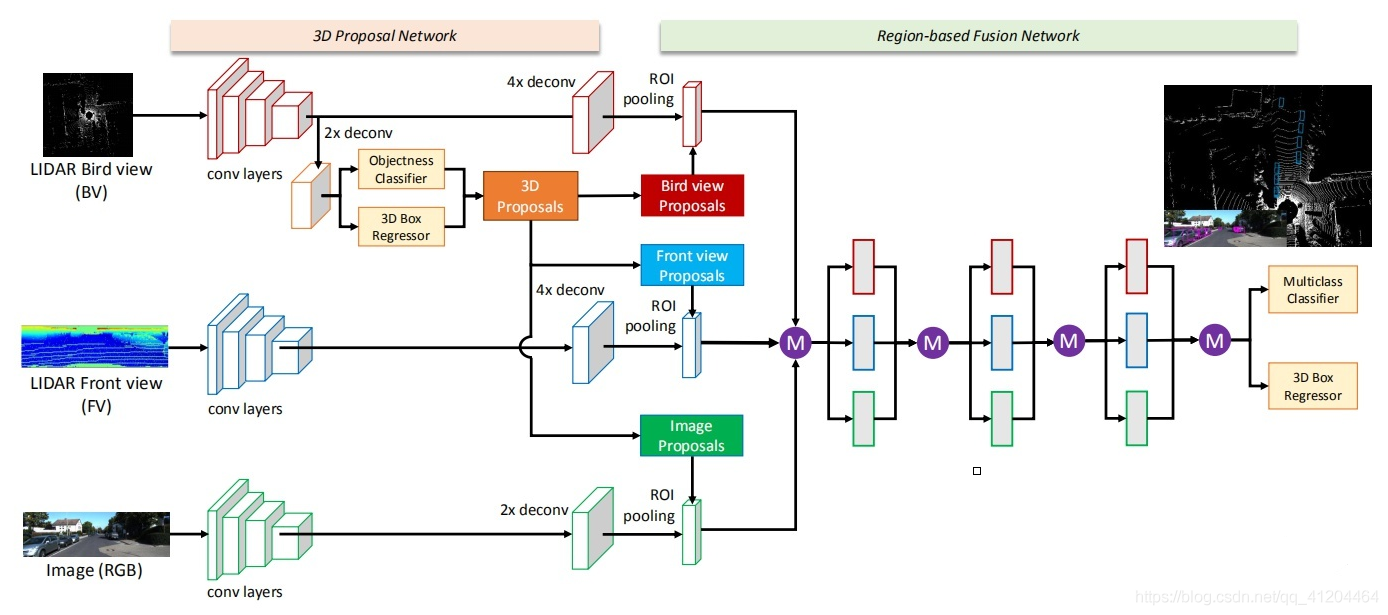
上圖中的紫色圓圈中M是表示 :基于元素的均值,
輸入的資料:有三種,分別是點云俯視圖、點云前視圖和二維RGB影像,“點云投影”,其實并非簡單地把三維壓成二維,而是提取了高程、密度、光強等特征,分別作為像素值,得到的二維投影圖片,
輸出資料:類別標簽、3D邊界框、時間戳,
1.1 網路的主體部分
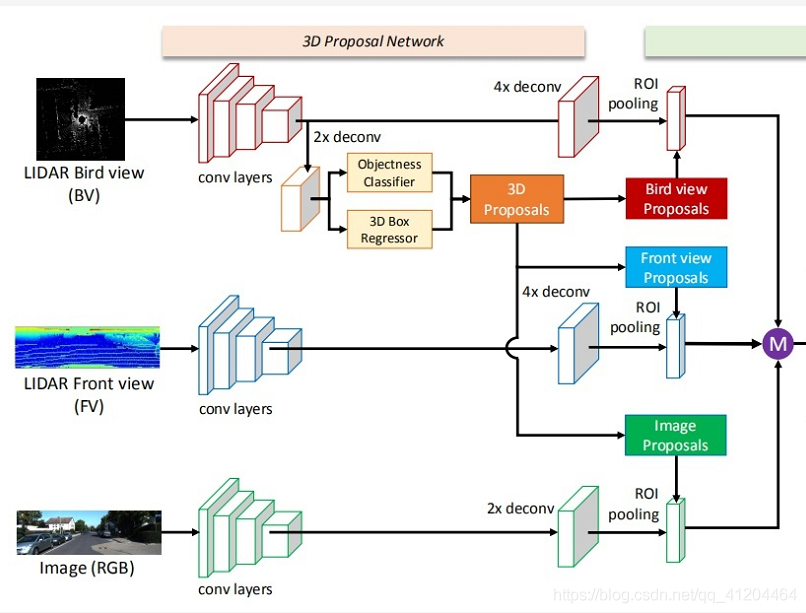
思路流程:
1)提取特征
- a. 提取點云俯視圖特征
- b. 提取點云前視圖特征
- c. 提取影像特征
2)從點云俯視圖特征中計算候選區域
3)把候選區域分別與1)中a、b、c得到的特征進行整合
- a. 把俯視圖候選區域投影到前視圖和影像中
- b. 經過ROI pooling整合成同一維度
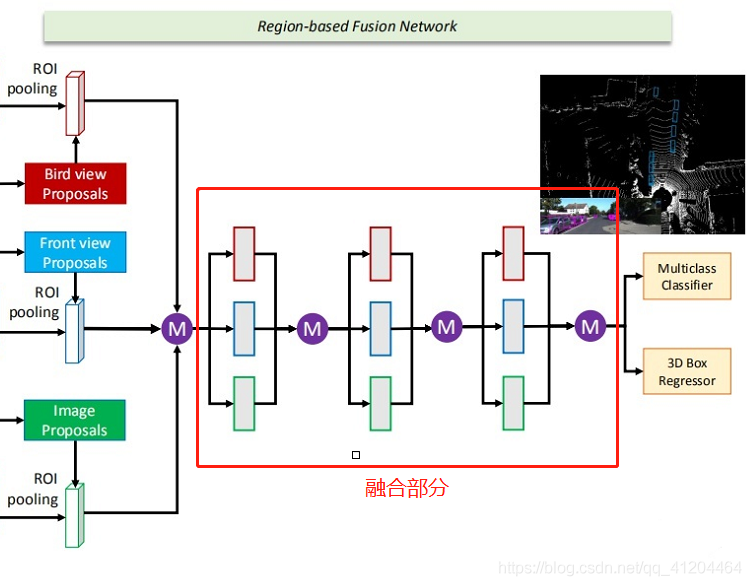
1.2 網路的融合部分
這部分網路主要是:把整合后的資料經過網路進行融合
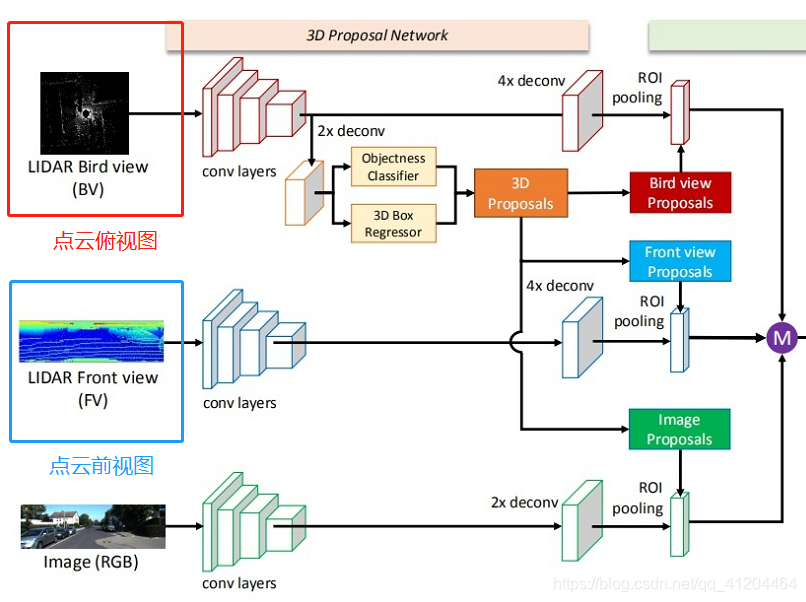
二、MV3D的點云處理
MV3D將點云和圖片資料映射到三個維度進行融合,從而獲得更準確的定位和檢測的結果,這三個維度分別為點云的俯視圖、點云的前視圖以及圖片,
2.1 提取點云俯視圖
點云俯視圖由高度、強度、密度組成;作者將點云資料投影到解析度為0.1的二維網格中,
高度圖的獲取方式為:將每個網格中所有點高度的最大值記做高度特征,為了編碼更多的高度特征,將點云被分為M塊,每一個塊都計算相應的高度圖,從而獲得了M個高度圖,
強度圖的獲取方式為:每個單元格中有最大高度的點的映射值,
密度圖的獲取方式為:統計每個單元中點云的個數,并且按照公式:
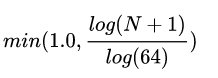
其中N為單元格中的點的數目,強度和密度特征計算的是整個點云,而高度特征是計算M切片,所以,總的俯視圖被編碼為(M + 2)個通道的特征,
2.2 提取點云前視圖
由于激光點云非常稀疏的時候,投影到2D圖上也會非常稀疏,相反,作者將它投影到一個圓柱面生成一個稠密的前視圖, 假設3D坐標為:
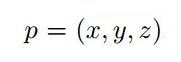
那么前視圖坐標:
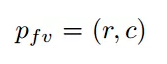
可以通過如下式子計算
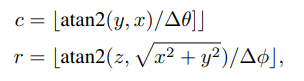
三、MV3D的影像處理
采用經典的VGG-16來提取影像特征,這里就不過多說明了,
四、俯視圖計算候選區域
物體投射到俯視圖時,保持了物體的物理尺寸,從而具有較小的尺寸方差,這在前視圖/影像平面的情況下不具備的,在俯視圖中,物體占據不同的空間,從而避免遮擋問題,
在道路場景中,由于目標通常位于地面平面上,并在垂直位置的方差較小,可以為獲得準確的3Dbounding box提供良好基礎,
候選區域網路就是熟悉的RPN,參考
五、特征整合
把候選區域分別與提取的特征進行整合
流程:
- a. 把俯視圖候選區域投影到前視圖和影像中
- b. 經過ROI pooling整合成同一維度
六、特征融合
有了整合后的資料,需要對特征進行融合,最終得到類別標簽、3D邊界框,
作者介紹了三種不同的融合方式,分別為
- a、Early Fusion 早期融合
- b、Late Fusion 后期融合
- c、Deep Fusion 深度融合,
各自的結構如下圖所示,
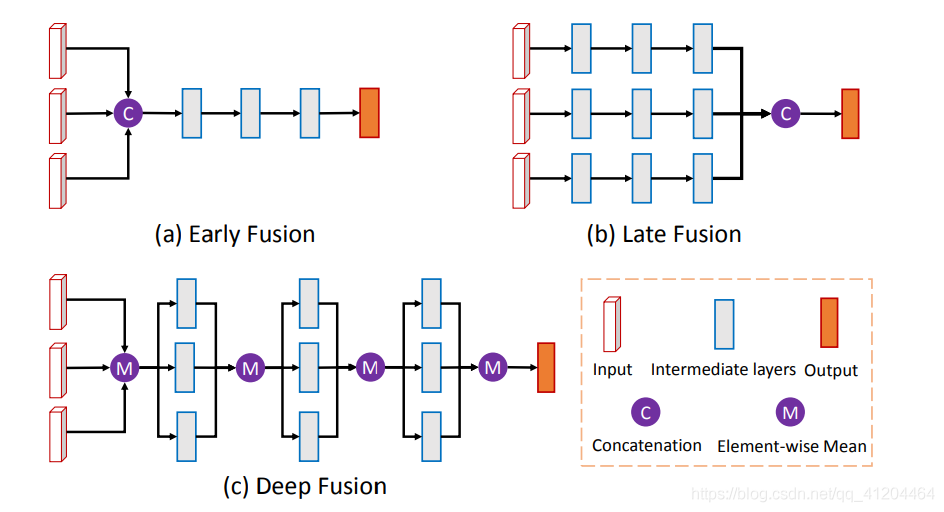
上圖中的紫色圓圈中M是表示 :基于元素的均值,C是表示:串接,
最終選擇了Deep Fusion 深度融合,融合的特征用作:分類任務(人/車/...)、更精細化的3D Box回歸(包含對物體朝向的估計),
七、模型效果
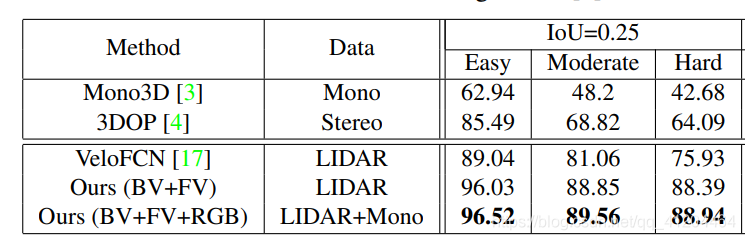
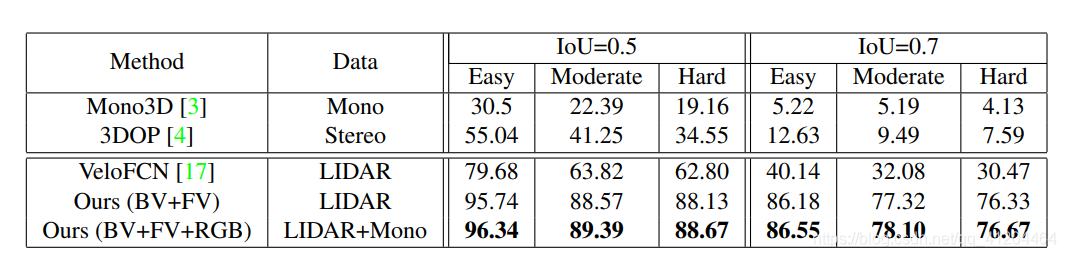
和其他模型對比的資料:
檢測效果:

八、模型代碼
代碼地址:https://github.com/bostondiditeam/MV3D
作者使用KITTI提供的原始資料,點擊鏈接

上圖是用于原型制作的資料集 ,
我們使用了[同步+校正資料] + [校準](校準矩陣)+ [軌跡]()
所以輸入資料結構是這樣的:
![]()
運行 src/data.py 后,我們獲得了 MV3D 網路所需的輸入,它保存在kitti中,

上圖是激光雷達俯視圖(data.py后)

上圖是將 3D 邊界框投影回相機影像中,
輸入具體資料格式可以參考'data.py' 'data.py' 網址
本文參考:https://zhuanlan.zhihu.com/p/86312623、https://zhuanlan.zhihu.com/p/353955895
https://cloud.tencent.com/developer/news/223860

論文地址:Multi-View 3D Object Detection Network for Autonomous Driving
代碼地址:https://github.com/bostondiditeam/MV3D
本文只提供參考學習,謝謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/289957.html
標籤:其他