您可能之前看到過我寫的類似文章,為什么還要重復撰寫呢?只是想更好地幫助初學者了解病毒逆向分析和系統安全,更加成體系且不破壞之前的系列,因此,我重新開設了這個專欄,準備系統整理和深入學習系統安全、逆向分析和惡意代碼檢測,“系統安全”系列文章會更加聚焦,更加系統,更加深入,也是作者的慢慢成長史,換專業確實挺難的,逆向分析也是塊硬骨頭,但我也試試,看看自己未來四年究竟能將它學到什么程度,漫漫長征路,偏向虎山行,享受程序,一起加油~
前文從總結惡意代碼檢測技術,包括惡意代碼檢測的物件和策略、特征值檢測技術、校驗和檢測技術、啟發式掃描技術、虛擬機檢測技術和主動防御技術,這篇文章將介紹基于機器學習的惡意代碼檢測技術,主要參考鄭師兄的視頻總結,包括機器學習概述與演算法舉例、基于機器學習方法的惡意代碼檢測、機器學習演算法在工業界的應用,同時,我再結合自己的經驗進行擴充,詳細分享了基于機器學習的惡意代碼檢測技術,基礎性文章,希望對您有所幫助~
作者作為網路安全的小白,分享一些自學基礎教程給大家,主要是關于安全工具和實踐操作的在線筆記,希望您們喜歡,同時,更希望您能與我一起操作和進步,后續將深入學習網路安全和系統安全知識并分享相關實驗,總之,希望該系列文章對博友有所幫助,寫文不易,大神們不喜勿噴,謝謝!如果文章對您有幫助,將是我創作的最大動力,點贊、評論、私聊均可,一起加油喔!
文章目錄
- 一.機器學習概述與演算法舉例
- 1.機器學習概念
- 2.機器學習演算法舉例
- 3.特征工程-特征選取與設計
- 二.基于機器學習方法的惡意代碼檢測
- 1.惡意代碼的靜態動態檢測
- (1) 特征種類
- (2) 常見演算法
- 2.靜態特征設計舉例
- 3.經典的圖片特征舉例
- 4.動態特征設計舉例
- 5.深度學習靜態檢測舉例
- 6.優缺點
- 7.靜態分析和動態分析對比
- 三.機器學習演算法在工業界的應用
- 四.總結
作者的github資源:
- 逆向分析:https://github.com/eastmountyxz/SystemSecurity-ReverseAnalysis
- 網路安全:https://github.com/eastmountyxz/NetworkSecuritySelf-study
從2019年7月開始,我來到了一個陌生的專業——網路空間安全,初入安全領域,是非常痛苦和難受的,要學的東西太多、涉及面太廣,但好在自己通過分享100篇“網路安全自學”系列文章,艱難前行著,感恩這一年相識、相知、相趣的安全大佬和朋友們,如果寫得不好或不足之處,還請大家海涵!
接下來我將開啟新的安全系列,叫“系統安全”,也是免費的100篇文章,作者將更加深入的去研究惡意樣本分析、逆向分析、內網滲透、網路攻防實戰等,也將通過在線筆記和實踐操作的形式分享與博友們學習,希望能與您一起進步,加油~
- 推薦前文:網路安全自學篇系列-100篇
前文分析:
- [系統安全] 一.什么是逆向分析、逆向分析基礎及經典掃雷游戲逆向
- [系統安全] 二.如何學好逆向分析及呂布傳游戲逆向案例
- [系統安全] 三.IDA Pro反匯編工具初識及逆向工程解密實戰
- [系統安全] 四.OllyDbg動態分析工具基礎用法及Crakeme逆向
- [系統安全] 五.OllyDbg和Cheat Engine工具逆向分析植物大戰僵尸游戲
- [系統安全] 六.逆向分析之條件陳述句和回圈陳述句原始碼還原及流程控制
- [系統安全] 七.逆向分析之PE病毒原理、C++實作檔案加解密及OllyDbg逆向
- [系統安全] 八.Windows漏洞利用之CVE-2019-0708復現及藍屏攻擊
- [系統安全] 九.Windows漏洞利用之MS08-067遠程代碼執行漏洞復現及深度提權
- [系統安全] 十.Windows漏洞利用之SMBv3服務遠程代碼執行漏洞(CVE-2020-0796)復現
- [系統安全] 十一.那些年的熊貓燒香及PE病毒行為機理分析
- [系統安全] 十二.熊貓燒香病毒IDA和OD逆向分析(上)病毒初始化
- [系統安全] 十三.熊貓燒香病毒IDA和OD逆向分析(中)病毒釋放機理
- [系統安全] 十四.熊貓燒香病毒IDA和OD逆向分析–病毒釋放程序(下)
- [系統安全] 十五.Chrome瀏覽器保留密碼功能滲透決議、藍屏漏洞及某音樂軟體漏洞復現
- [系統安全] 十六.PE檔案逆向基礎知識(PE決議、PE編輯工具和PE修改)
- [系統安全] 十七.Windows PE病毒概念、分類及感染方式詳解
- [系統安全] 十八.病毒攻防機理及WinRAR惡意劫持漏洞(腳本病毒、自啟動、定時關機、藍屏攻擊)
- [系統安全] 十九.宏病毒之入門基礎、防御措施、自發郵件及APT28宏樣本分析
- [系統安全] 二十.PE數字簽名之(上)什么是數字簽名及Signtool簽名工具詳解
- [系統安全] 二十一.PE數字簽名之(中)Signcode、PEView、010Editor、Asn1View工具用法
- [系統安全] 二十二.PE數字簽名之(下)微軟證書漏洞CVE-2020-0601復現及Windows驗證機制分析
- [系統安全] 二十三.逆向分析之OllyDbg動態除錯復習及TraceMe案例分析
- [系統安全] 二十四.逆向分析之OllyDbg除錯INT3斷點、反除錯、硬體斷點與記憶體斷點
- [系統安全] 二十五.WannaCry勒索病毒分析 (1)Python復現永恒之藍漏洞實作勒索加密
- [系統安全] 二十六.WannaCry勒索病毒分析 (2)MS17-010漏洞利用及病毒決議
- [系統安全] 二十七.WannaCry勒索病毒分析 (3)蠕蟲傳播機制決議及IDA和OD逆向
- [系統安全] 二十八.WannaCry勒索病毒分析 (4)全網"最"詳細的蠕蟲傳播機制解讀
- [系統安全] 二十九.深信服分享之外部威脅防護和勒索病毒對抗
- [系統安全] 三十.CS逆向分析 (1)你的游戲子彈用完了嗎?Cheat Engine工具入門普及
- [系統安全] 三十一.惡意代碼檢測(1)惡意代碼攻擊溯源及惡意樣本分析
- [系統安全] 三十二.惡意代碼檢測(2)常用技術詳解及總結
- [系統安全] 三十三.惡意代碼檢測(3)基于機器學習的惡意代碼檢測技術
宣告:本人堅決反對利用教學方法進行犯罪的行為,一切犯罪行為必將受到嚴懲,綠色網路需要我們共同維護,更推薦大家了解它們背后的原理,更好地進行防護,該樣本不會分享給大家,分析工具會分享,(參考文獻見后)
隨著互聯網的繁榮,現階段的惡意代碼也呈現出快速發展的趨勢,主要表現為變種數量多、傳播速度快、影響范圍廣,在這樣的形勢下,傳統的惡意代碼檢測方法已經無法滿足人們對惡意代碼檢測的要求,比如基于簽名特征碼的惡意代碼檢測,這種方法收集已知的惡意代碼,以一種固定的方式生成特定的簽名,維護這樣的簽名庫,當有新的檢測任務時,通過在簽名庫中檢索匹配的方法進行檢測,暫且不說更新、維護簽名庫的程序需要耗費大量的人力物力,惡意代碼撰寫者僅僅通過混淆、壓縮、加殼等簡單的變種方式便可繞過這樣的檢測機制,
為了應對上面的問題,基于機器學習的惡意代碼檢測方法一直是學界研究的熱點,由于機器學習演算法可以挖掘輸入特征之間更深層次的聯系,更加充分地利用惡意代碼的資訊,因此基于機器學習的惡意代碼檢測往往表現出較高的準確率,并且一定程度上可以對未知的惡意代碼實作自動化的分析,下面讓我們開始進行系統的介紹吧~
一.機器學習概述與演算法舉例
1.機器學習概念
首先介紹下機器學習的基本概念,如下圖所示,往分類模型中輸入某個樣本特征,分類模型輸出一個分類結果,這就是一個標準的機器學習檢測流程,機器學習技術主要研究的就是如何構建中間的分類模型,如何構造一組引數、構建一個分類方法,通過訓練得到模型與引數,讓它在部署后能夠預測一個正確的結果,
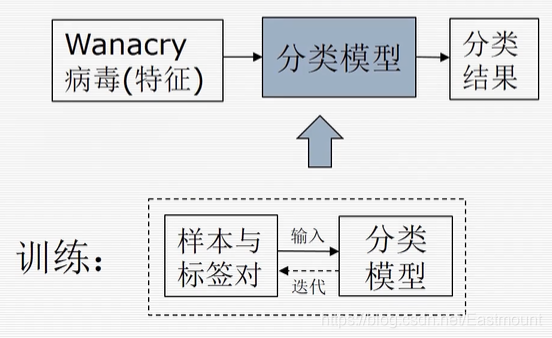
訓練是迭代樣本與標簽對的程序,如數學運算式 y=f(x) ,x表示輸入的樣本特征向量,y表示標簽結果,使用(x,y)對f進行一個擬合的操作,不斷迭代減小 y’ 和 y 的誤差,使得在下次遇到待測樣本x時輸出一致的結果,該程序也稱為學習的程序,
構造分類方法
構造分類方法是機器學習中比較重要的知識,如何設計一種分類模型將f(x)表達出來,比如:
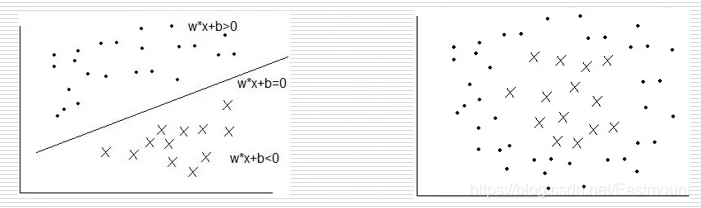
- 超平面(SVM)
在二維坐標軸中,可以設計一條直線將空間內分布的散點區分開來,如下圖所示, - softmax
另外一種方法是構造類別概率輸出(softmax),比如歸一化處理得到A+B=1,最后看A和B的概率,誰的概率大就屬于哪一類,該方法廣泛使用于神經網路的最后結果計算中,
2.機器學習演算法舉例
作者之前Python系列分享過非常多的機器學習演算法知識,也推薦大家去學習:機器學習系列文章(共48篇),
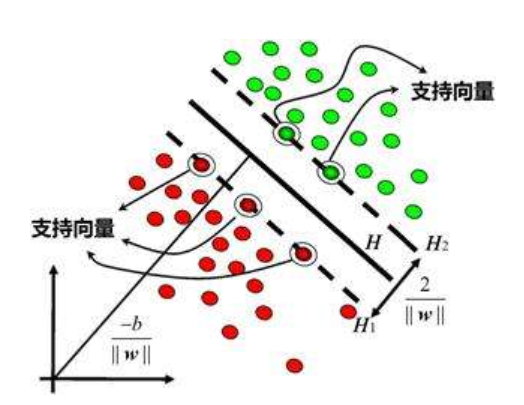
(1) 支持向量機(SVM)
首先存在很多訓練資料點,包括直線上方和下方兩個簇,支持向量機的方法是尋找這兩個簇分類的超平面,如何尋找這個超平面呢?支持向量機先求解每個簇離對面最近的點,然后通過擬合方法計算出兩邊簇的邊界,最終計算出中間的平面,其基本思路就是這樣,而這些點就是支持向量,支持向量機往往用來處理超高維的問題,也不一定是類似直線的平面,也可能是圓形的分類邊界,
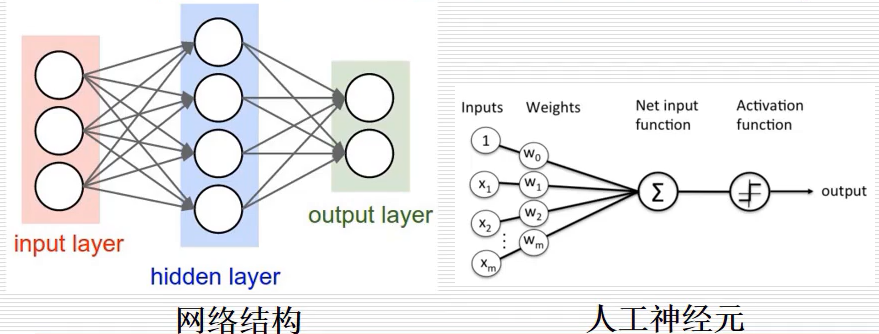
(2) 神經網路(Neural Network)
神經網路基本網路結構如下圖所示,包括三個常用層:輸入層、隱藏層、輸出層,在神經網路中,最基本的單位是人工神經元,其基本原理是將輸入乘以一個權重,然后將結果相加進行激活,最后得到一個概率的輸出,其輸出結果誰大就預測為對應的結果,推薦作者的文章:神經網路和機器學習基礎入門分享
(3) 深度卷積神經網路
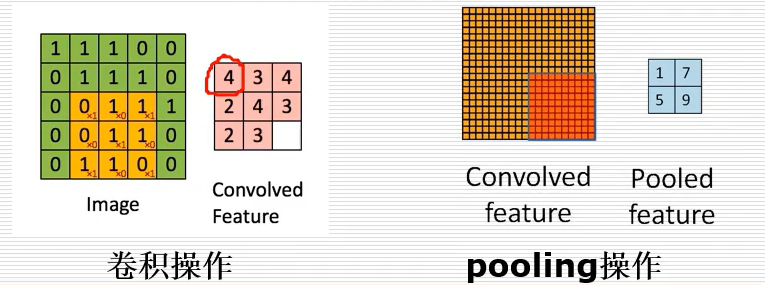
普通的神經網路通常只包括一個隱藏層,當超出之后可以稱為深度神經網路,現在比較流行的包括CNN、RNN、RCNN、GRU、LSTM、BiLSTM、Attention等等,其中,卷積神經網路常用于處理圖片,應用了卷積技術、池化技術,降低圖片維度得到很好的結果,
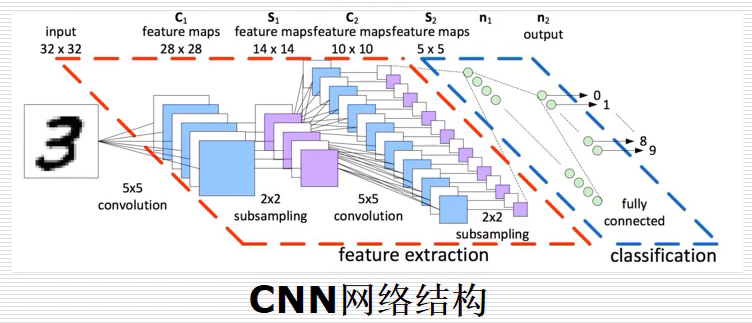
如上圖所示,將手寫數字“3”(32x32個像素)預測為最終的數字0-9的結果,模型首先使用了6個卷積核,對原始圖片進行固定的計算,如下5x5的影像卷積操作后變成了 3x3 的影像,其原理是將特征提取的程序放至神經網路中訓練,從而得到比較好的分類結果,卷積之后進行了一個2x2的下采樣程序,將圖片進一步變小(14x14),接著降維處理,一般采用平均池化或最大池化實作,選定一個固定區域,求取該區域的平均值或最大值,然后將向量進行組合,得到一個全連接網路,最終完成分類任務,
參考作者前文:[Python人工智能] 四.神經網路和深度學習入門知識
深度神經網路是深度學習中模型,它主要的一個特點是將特征提取的程序放入到真個訓練中,之前對于圖片問題是采用手工特征,而CNN讓在訓練中得到最優的特征提取,
3.特征工程-特征選取與設計
上面介紹了機器學習和深度學習方法,但是這些方法往往是該研究領域的學者所提出,而在惡意代碼檢測中,往往我們的主要作業量是一些特征的提取和特征的設計,這里面涉及一個特征工程的概念,
特征工程:選取特征,設計特征的程序,
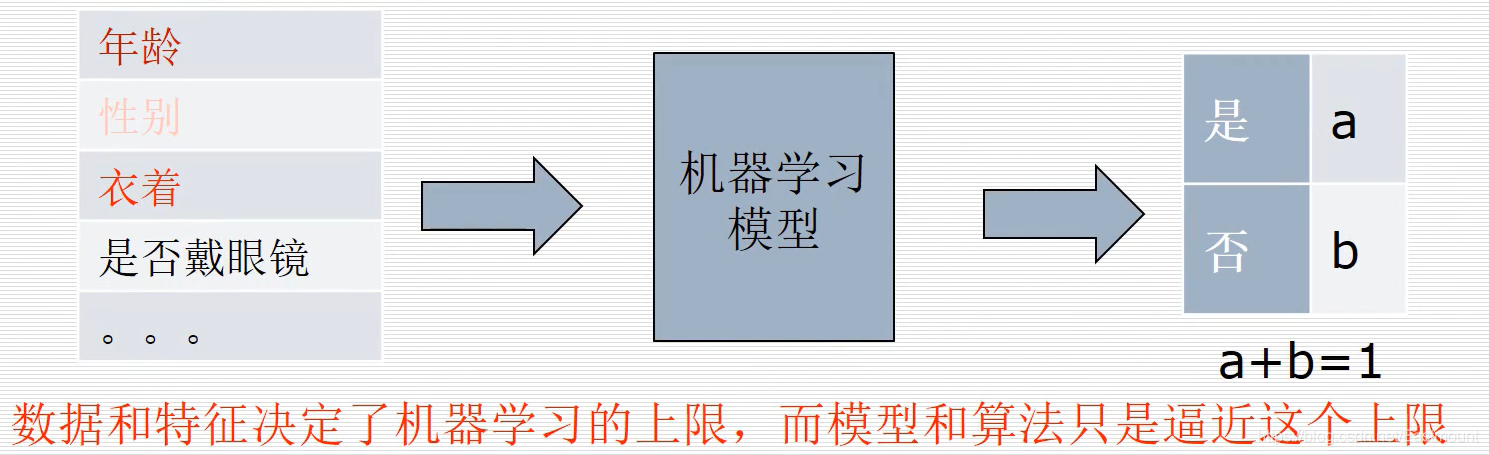
例如,在路邊預測一個人是否是學生,假設我們不能去詢問,只能通過外表去預測他是否是一個學生,包括:年齡(低于15歲就是學生)、性別(不影響學生)、衣著(穿著活潑年輕的可能是學生,如果穿著西裝可能性就小)等等,然后根據這些特征輸入機器學習模型,從而判斷是否是學生,
在這些特征中,顯然有些特征是非常重要的,比如年齡和衣著,資料和特征決定了機器學習的上限,而模型和演算法只是逼近這個上限,所以如何選取特征是機器學習的一個關鍵性因素,再比如淘寶的推薦系統,購買電腦推薦滑鼠、鍵盤等,
當然,上面僅僅是一個比較簡單的問題,當我們推廣到惡意代碼檢測等復雜問題時,如果不了解這個領域,可能就會導致模型的結果不理想,
特征設計——人臉識別
區域二值特征(Local Binary Pattern),再舉一個人臉識別例子,深度學習出來之前,圖片分類都是使用一些特征算子提取特征的,比如存在一個3x3的視窗,我們取閾值5,比5小的視窗置為0,其他的置為1,然后順時針轉換為一個8位的二進制數字,對應的十進制就是19,顯然,LBP特征進行了一個降維的操作,左邊的圖片顯示了人臉識別不應該受光照影響,不同光照的圖片進行LBP特征提取后,顯示結果都一樣,

該部分的最后,作者也推薦一些書籍供大家學習,
- 《統計學習方法》李航,數學理論較多
- 《機器學習》周志華,西瓜書,較通俗透徹
- 《Deep Learning》Ian Goodfellow,花書,深度學習內容全面
- 《精通特征工程》結合惡意代碼特征學習,包括如何向量化
再看看我的桌面,這些都是作者最近看的一些安全、AI類書籍,希望也您喜歡~

二.基于機器學習方法的惡意代碼檢測
1.惡意代碼的靜態動態檢測
(1) 特征種類
首先,特征種類如果按照惡意代碼是否在用戶環境或仿真環境中運行,可以劃分為靜態特征和動態特征,
- 靜態特征: 沒有真實運行的特征
– 位元組碼:二進制代碼轉換成了位元組碼,比較原始的一種特征,沒有進行任何處理
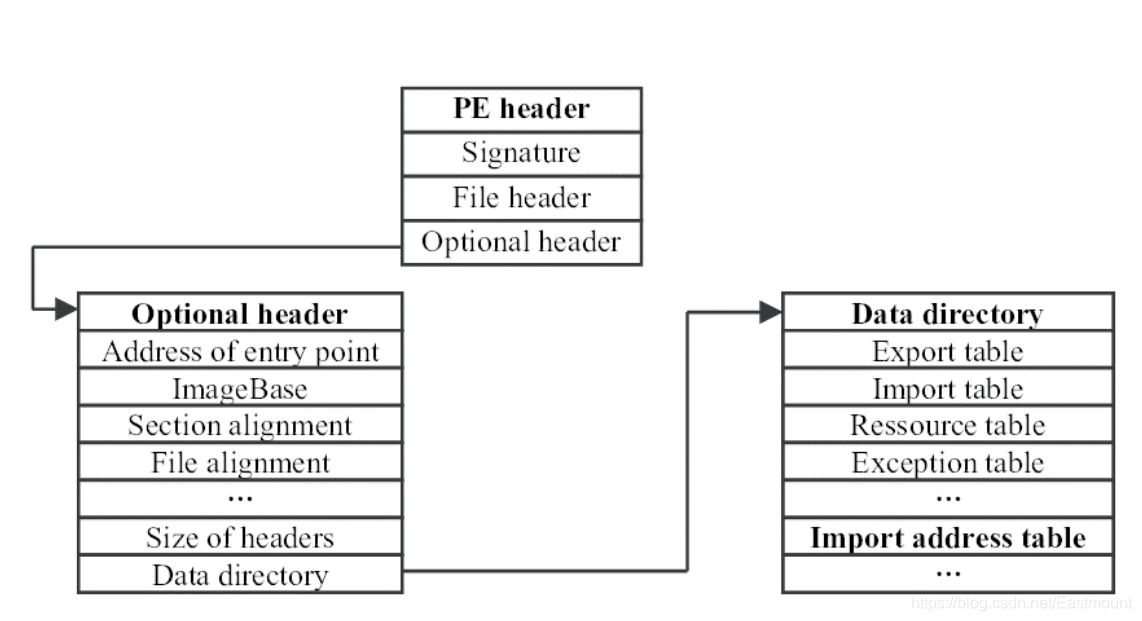
– IAT表:PE結構中比較重要的部分,宣告了一些函式及所在位置,便于程式執行時匯入,表和功能比較相關
– Android權限表:如果你的APP宣告了一些功能用不到的權限,可能存在惡意目的,如手機資訊
– 可列印字符:將二進制代碼轉換為ASCII碼,進行相關統計
– IDA反匯編跳轉塊:IDA工具除錯時的跳轉塊,對其進行處理作為序列資料或圖資料
- 動態特征: 相當于靜態特征更耗時,它要真正去執行代碼
– API呼叫關系:比較明顯的特征,呼叫了哪些API,表述對應的功能
– 控制流圖:軟體工程中比較常用,機器學習將其表示成向量,從而進行分類
– 資料流圖:軟體工程中比較常用,機器學習將其表示成向量,從而進行分類
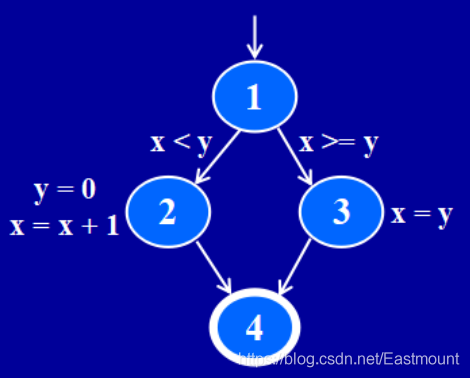
舉一個簡單的控制流圖(Control Flow Graph, CFG)示例,
if (x < y)
{
y = 0;
x = x + 1;
}
else
{
x = y;
}
(2) 常見演算法
普通機器學習方法和深度學習方法的區別是,普通機器學習方法的引數比較少,相對計算量較小,
- 普通機器學習方法(SVM支持向量機、RF隨機森林、NB樸素貝葉斯)
- 深度神經網路(Deep Neural Network)
- 卷積神經網路(Convolution Neural Network)
- 長短時記憶網路(Long Short-Term Memory Network)
針對序列模型進行建模,包含背景關系依賴關系,比如“我 是 一名 大學生”中的“我”和“是”前后出現的條件概率更高,廣泛應用于文本分類、語音識別中,同樣適用于惡意代碼檢測, - 圖卷積網路 (Graph Convolution Network)
比較新興的方法,將卷積應用到圖領域,圖這種資料型別比較通用,非圖資料比較容易轉換成圖資料,CCF論文中也已經應用到惡意代碼檢測中,,
2.靜態特征設計舉例
首先分享一個靜態特征的例子,該篇文章發表在2015年,是一篇CCF C類會議文章,
- Saxe J,Berlin K. Deep neural network based malware detection using two dimensional binary program features[C] // 2015 10th International Conference on Malicious and Unwanted Software(MALWARE). IEEE, 2015: 11-20

文章的主要方法流程如下所示:
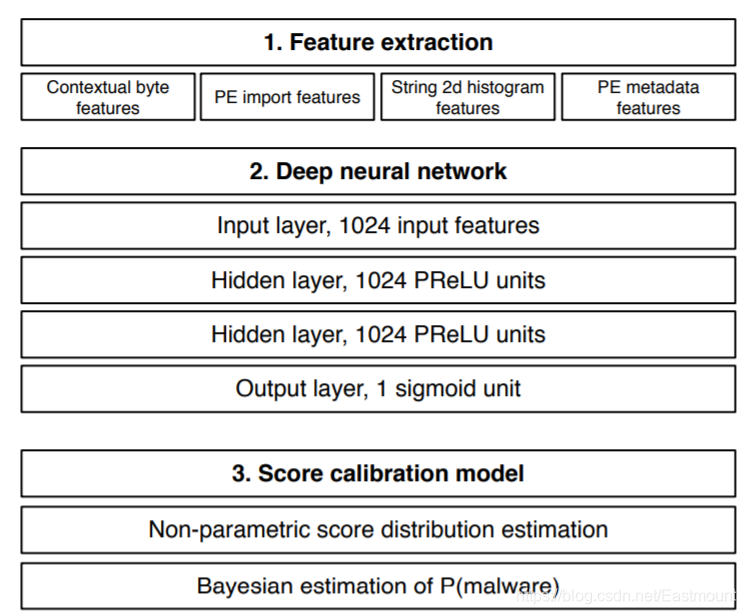
該模型包含三個步驟:
- 特征抽取
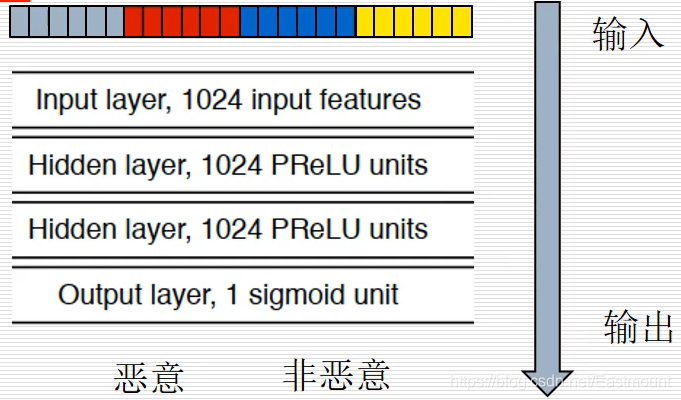
使用了四種特征 - 特征抽取輸入到深度神經網路
包含兩層隱含層的深度神經網路 - 分數校正
特征抽取
特征提取包括以下四種特征:

-
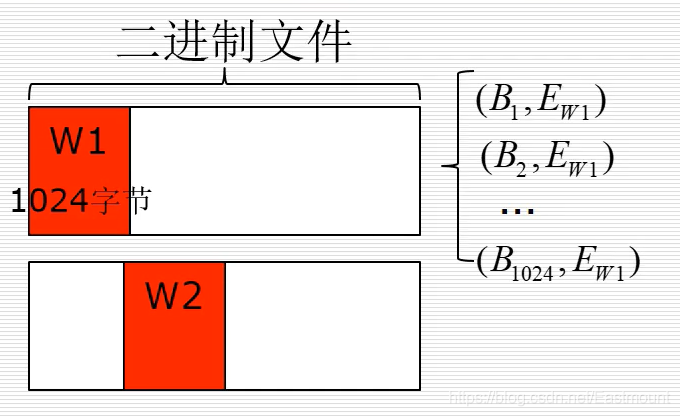
位元組-熵對統計特征:統計滑動視窗的(位元組,熵)對個數
在下圖中,假設白框是一個二進制檔案,其中紅色框W是滑動視窗,二進制檔案如果有100KB大小,每個滑動視窗是1024位元組,那么滑動100次可以將整個二進制檔案掃描完,如果對視窗內的數值進行計算,首先計算它的熵值,熵是資訊論的概念(下圖中的E),它描述了一個陣列的隨機性,熵越大其隨機性越大,在圖中,每一個滑動視窗都有固定的熵值,包含了1024位元組,標記為(Bi,Ewi),最后滑動得到100x1024的位元組熵對,
統計最后滑動得到100x1024的位元組熵對個數,得到如下圖所示的二維直方圖結果,橫坐標是熵值最小值到最大值的范圍,縱坐標是一個位元組轉換成10進制的范圍0-256,最終得到位元組熵對分布的范圍,再將16x16維的二維陣列轉換成1x256維的特征向量,
-
PE頭IAT特征:hashDLL檔案名與函式名為[0-255)范圍
第二種特征是PE頭IAT特征,它的計算工程是將PE頭的IAT表里面的檔案名和函式名hash到0到255范圍,如果某個檔案出現某個函式,就將該位置為1,當然每位對應表示的函式是固定的,最終得到256陣列, -
可列印字符:統計ASCII碼的個數特征
可列印字符和位元組熵對比較相似,這里推薦大家閱讀原文, -
PE元資訊:將PE資訊抽取出來組成256維陣列,例如編譯時間戳
PE元資訊是將PE資訊的數值型資訊抽取出來,組成256維陣列,每一個陣列的位置表示了一個固定的資訊種類,再資訊種類將對應的資訊填入到元素的位置,比如編譯時間戳,
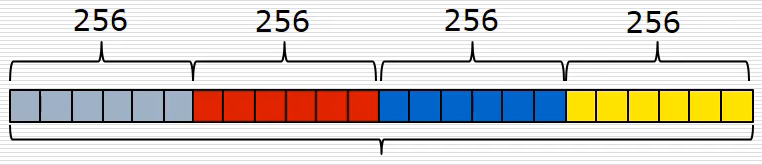
總共有上述四種特征,然后進行拼接得到4*256=1024維的陣列,這個陣列就代表一個樣本的特征向量,假設有10000個樣本,就有對應10000個特征向量,
得到特征向量之后,就開始進行模型的訓練和測驗,一般機器學習任務事先都有一個資料集,并且會分為訓練資料集和測驗資料集,按照4比1或9比1的比例進行隨機劃分,訓練會將資料集和標簽對輸入得到惡意和非惡意的結果,再輸入測驗集得到最終結果,
下面是衡量機器學習模型的性能指標,首先是一幅混淆矩陣的圖表,真實類別中1代表惡意樣本,0代表非惡意樣本,預測類別也包括1和0,然后結果分為:
- TP:本身是惡意樣本,并且預測識別為惡意樣本
- FP:本身是惡意樣本,然而預測識別為非惡意樣本,這是誤分類的情況
- FN:本身是非惡意樣本,然而預測識別為惡意樣本,這是誤分類的情況
- TN:本身是非惡意樣本,并且預測識別為非惡意樣本
然后是Accuracy(準確率)、Precision(查準率)、Recall(查全率)、F1等評價指標,

通常Accuracy是一個評價惡意代碼分類的重要指標,但本文選擇的是AUC指標,為什么呢?
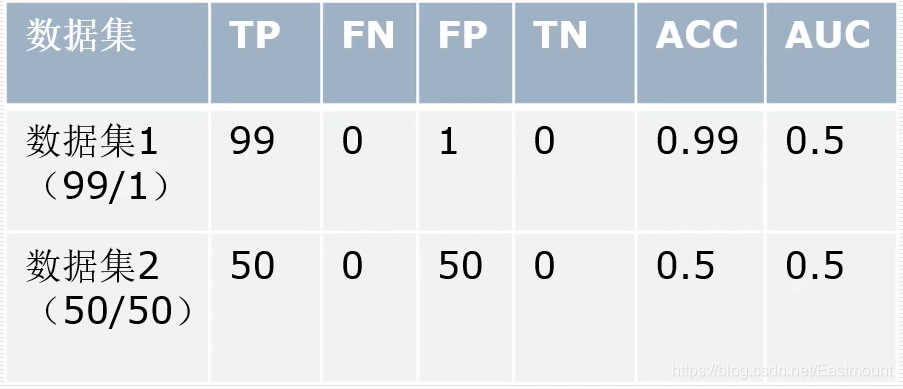
假設我們模型的效果非常差,它會將所有本測驗樣本標記為惡意樣本,這樣我有兩個資料集,一個樣本包括100個資料(99個惡意樣本、1個非惡意樣本),另一個樣本包括50個資料(50個惡意樣本、50個非惡意樣本),如果我單純的計算ACC,第一個樣本的結構是0.99,顯然不符合客觀的描述,不能用來評價性能高低的,并且這種情況是很容易產生的,所以論文中廣泛采用AUC指標,
AUC指標包括TPRate和FPRate,然后得到一個點,并計算曲線以下所包圍的面積即為AUC指標,其中,TPRate表示分類器識別出正樣本數量占所有正樣本數量的比值,FPRate表示負樣本數量站所有負樣本數量的比值,舉個例子,我們撒網打魚,一網下去,網中好魚的數量占池子中所有好魚的數量就是TPRate,而FPRate表示一網下去,壞魚的數量占整個池子中所有壞魚的數量比例,當然FPRate越小越好,最好的結果就是TPRate為1,而FPRate為0,此時全部分類預測正確,
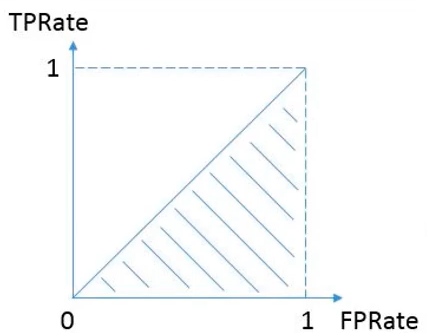
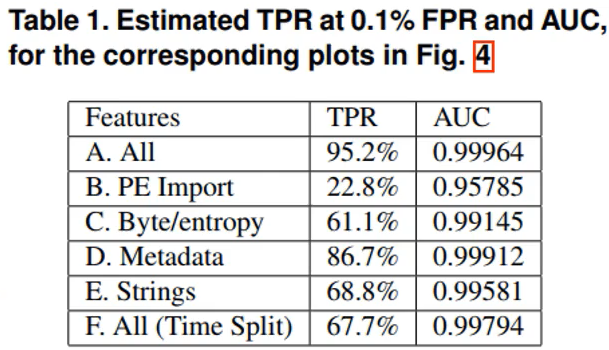
該論文測驗了六種特征集合,其計算的TPR和AUC值如下所示,
3.經典的圖片特征舉例
下面介紹另一種比較新興經典的方法,就是圖片特征,但一些安全界的人士會認為這種特征不太好,但其方法還是比較新穎的,
它的基本方法是按照每8位一個像素點將惡意軟體的二進制檔案轉換為灰度圖片,圖片通常分為R、G、B通道,每個8位像素點表示2^8,最終每隔8位生成一個像素點從而轉換為如下圖所示的灰度圖片,圖片分別為Obfuscator_ACY家族、Lolipop家族、ramnit家族惡意軟體樣例,這些樣例由微軟kaggle比賽公布的資料生成,
這是因為對于某些惡意樣本作者來說,他只是使用方法簡單的修改特征碼,從而每個家族的圖片比較相似,最終得到了較好的結果,

4.動態特征設計舉例
接下來分享一個動態特征的例子,該篇文章發表在2016年,文章的會議一般,但比較有代表性,
- Kolosnjaji B,Zarras A,Webster G,et al. Deep learning for classification of malware system call sequences[C] // Australasian Joint Conference on Artificial Intelligence. Springer,Cham,2016:137-149.
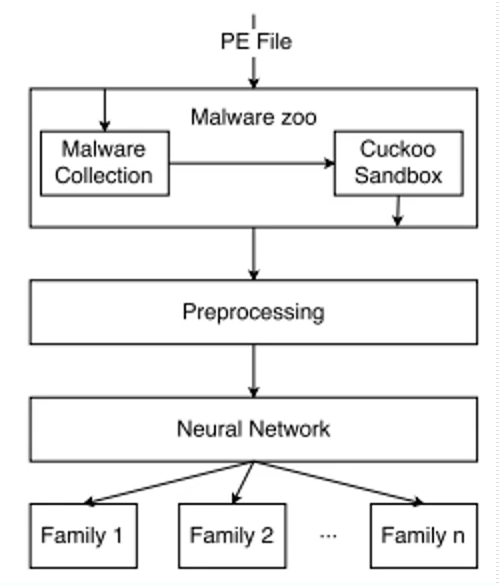
下圖展示了該方法的整體流程圖,PE檔案進入后,直接進入Cuckoo沙箱中,它是一個開源沙箱,在學術論文中提取動態特征比較通用;接著進行進行預處理操作,將文本轉換成向量表示的形式,比如提取了200個動態特征,可以使用200維向量表示,每個陣列的位置表示對應API,再將所得到的序列輸入卷積神經網路LSTM進行分類,最終得到家族分類的結構,
- Cuckoo沙箱
- LSTM
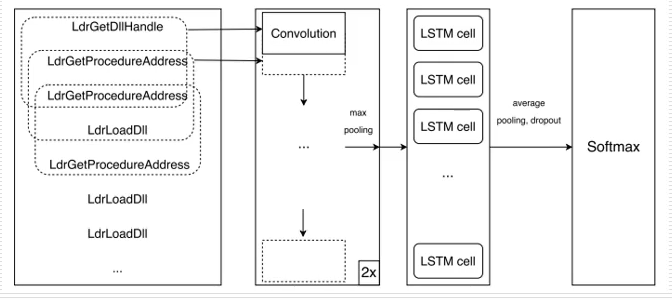
下圖展示了實驗的結構,其指標是高于單純的神經網路和卷積網路的效果更好,這是一篇比較基礎的文章,
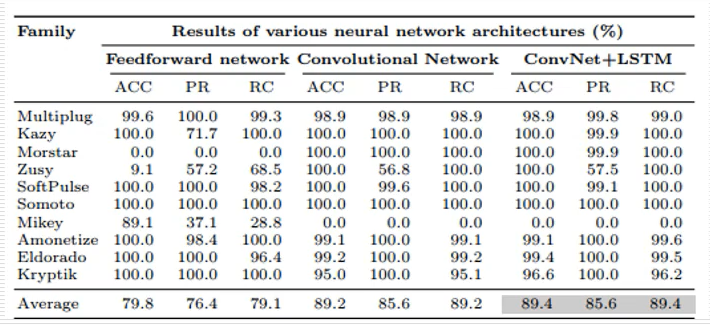
5.深度學習靜態檢測舉例
下面再看一個深度學習靜態檢測的文章,
- Coull S E,Gardner C. Activation Analysis of Byte-Based Deep Neural Network for Malware Classification[C] // 2019 IEEE Security and Privacy Workshops(SPW). IEEE,2019:21-27.
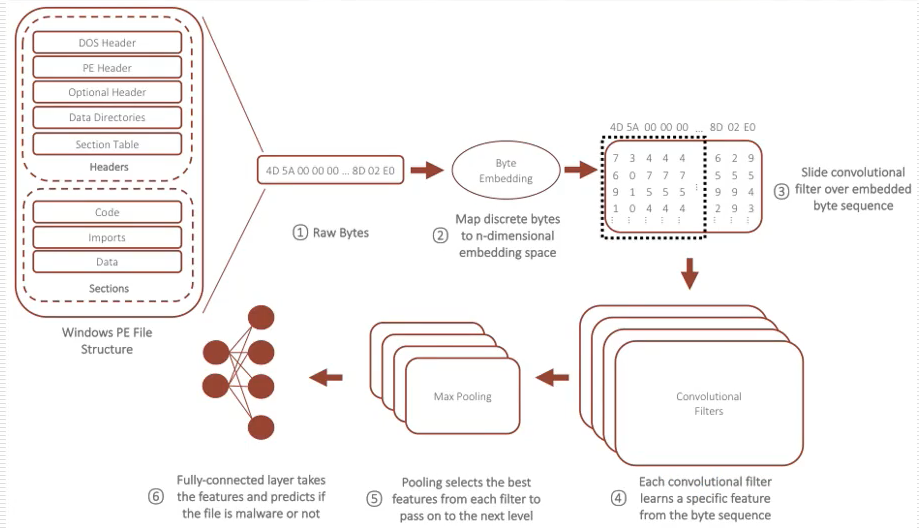
這篇文章是火眼公司的兩名員工發布的,所使用的也是靜態檢測特征,其流程如下所示,
- 首先,原始的位元組碼特征直接輸入一個Byte Embedding層(詞嵌入),對單個元素進行向量化處理,將位元組碼中的每個位元組表示成一個固定長度的向量,從而更好地將位元組標記在一個空間維度中,詞嵌入技術廣泛應用于自然語言處理領域,比如“女人”和“女王”關系比較緊密,這篇文章的目的也是想要在惡意代碼中達到類似的效果,
- 然后將矩陣輸入到卷積和池化層中,比如存在一個100K位元組的二進制檔案,得到100102410矩陣輸入卷積神經網路中,最后通過全連接層完成惡意和非惡意的分類任務,
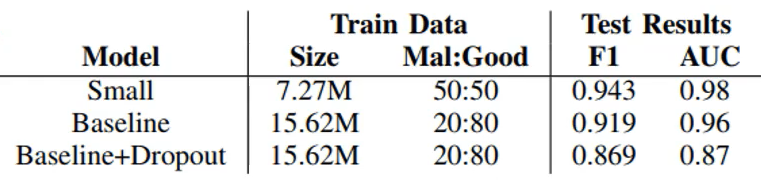
Fireeye使用了三個資料集進行訓練和測驗,其訓練的模型分類效果結果如下表所示,博客Small、Baseline、Baseline+Dropout模型,其網路結構是一樣的,其中Small表示使用小的資料集,Baseline表示使用大的資料集,Dropout表示對訓練好的神經網路中隨機丟棄一些神經元,從而抑制過擬合現象,也是比較常用的深度學習技術,
這篇文章的重點是對深度學習的解釋性,就是解釋深度學習是否能學習到惡意軟體的本質特性,下圖展示了不同特征對于分類結果的影響,橫坐標是Offset偏移,通常用Offset記錄位元組,從0到右邊也對應檔案大小,前面可能就是PE頭,中間有各種段,
它的橫縱坐標分別表示了某些特征對于惡意性分類比較重要,還是非惡意性比較重要,如果它的校驗和(CheckSum)是0,就對惡意性分類比較重要,這表示深度學習并沒有學習到惡意軟體為什么是惡意的,只是通過統計學去發現惡意軟體和非惡意軟體差別最大部分,以此進行資料建模,
深度學習進行惡意軟體檢測的問題:沒有學習到惡意和非惡意特征,而是學習到區別的統計差異,而這種差異如果被黑客利用是可以被規避的,

6.優缺點
靜態特征
- 優點
特征提取速度快
特征種類豐富,可以組合多種特征向量 - 缺點
易受加殼、加密、混淆干擾
無法防范無檔案攻擊,難以反映惡意軟體行為的惡意性
動態特征
- 優點
提供惡意軟體的動作,呼叫API
規避一些靜態的混淆對抗方法 - 缺點
反虛擬化,延時觸發等技術的對抗
測驗時間較長,單個樣本2-3分鐘(Cuckoo)
最后給出推薦資料:
- 404notfound實驗室總結的AI在安全領域應用
https://github.com/404notf0und/AI-for-Security-Learning - malware data science書籍
https://www.amazon.com/Malware-Data-Science-Detection-Attribution-ebook/dp/B077X1V9SY
7.靜態分析和動態分析對比
下面簡單總結靜態分析和動態分析與深度學習結合的知識,該部分內容源自文章:深度學習在惡意代碼檢測 - mbgxbz,在此感謝作者,覺得非常棒,故參考至此!謝謝~
惡意代碼的檢測本質上是一個分類問題,即把待檢測樣本區分成惡意或合法的程式,基于機器學習演算法的惡意代碼檢測技術步驟大致可歸結為如下范式:
- 采集大量的惡意代碼樣本以及正常的程式樣本作為訓練樣本;
- 對訓練樣本進行預處理,提取特征;
- 進一步選取用于訓練的資料特征;
- 選擇合適的機器學習演算法訓練分類模型;
- 通過訓練后的分類模型對未知樣本進行檢測,
深度學習作為機器學習的一個分支,由于其可以實作自動化的特征提取,近些年來在處理較大資料量的應用場景,如計算機視覺、語音識別、自然語言處理時可以取得優于傳統機器學習演算法的效果,隨著深度學習在影像處理等領域取得巨大的成功,許多人將深度學習的方法應用到惡意軟體檢測上來并取得了很好的成果,實際上就是用深度神經網路代替上面步驟中的人為的進一步特征提取和傳統機器學習演算法,根據步驟中對訓練樣本進行預處理的方式,可以將檢測分為靜態分析與動態分析:
- 靜態分析不運行待檢測代碼,而是通過直接對程式(如反匯編后的代碼)進行統計分析得到資料特征
- 動態分析則在虛擬機或沙箱中執行程式,獲取程式執行程序中所產生的資料(如行為特征、網路特征),進行檢測和判斷,
(1) 靜態分析
一般來說,在絕大部分情形下我們無法得到惡意程式的源代碼,因此,常用的靜態特征包括程式的二進制檔案、從使用IDA Pro等工具進行反匯編得到的匯編代碼中提取的匯編指令、函式呼叫等資訊,另外基于字串和基于API呼叫序列的特征也是比較常見的,文獻[i]提出一種對PE檔案的惡意程式檢測方法,提取PE檔案四個型別的特征:位元組頻率、二元字符頻率、PE Import Table以及PE元資料特征,采用包含兩個隱藏層的DNN作為分類模型,但是為了提取長度固定的輸入資料,他們丟棄了PE檔案中的大部分資訊,文獻[ii]使用CNN作為分類器,通過API呼叫序列來檢測惡意軟體,其準確率達到99.4%,遠高于傳統的機器學習演算法,然而,當惡意代碼存在混淆或加殼等情形時,對所選取的靜態特征具有較大的影響,因此靜態分析技術本身具有一定的局限性,
(2) 動態分析
利用虛擬機或沙箱執行待測程式,監控并收集程式運行時顯現的行為特征,并根據這些較為高級的特征資料實作惡意代碼的分類,一般來講,行為特征主要包括以下幾個方面:檔案的操作行為;注冊表鍵值的操作行為;元件的加載行為;行程訪問的操作行為;系統服務行為;網路訪問請求;API呼叫,文獻[iii]通過API呼叫序列記錄行程行為,使用RNN提取特征向量,隨后將其轉化為特征影像使用CNN進行進一步的特征提取,提取其可能包含的區域特征并進行分類,文獻[iv]提出了一個基于動態分析的2層架構的惡意軟體檢測系統:第1層是RNN,用于學習API事件的特征表示;第2層是邏輯回歸分類器,對RNN學習的特征進行分類,然而這種方法的誤報率較高,文獻[v]提出了用LSTM和GRU代替傳統RNN進行特征的提取,并提出了使用CNN的字符級別的檢測方案,文獻[vi]提出在惡意軟體運行的初期對其進行惡意行為的預測,他們使用RNN進行PE檔案檢測,根據惡意代碼前4秒的運行行為,RNN對惡意軟體的預測準確率是91%,隨著觀察的運行時間的增長,RNN的預測準確率也隨之提高,可以看到,相對于靜態分析,動態分析的程序更加復雜耗時,相對而言采用了較高層次的特征,因此可解釋性也較差,
在網路攻擊趨于精細化、惡意代碼日新月異的今天,基于深度學習演算法的惡意代碼檢測中越來越受到學術界和眾多安全廠商的關注,但這種檢測技術在現實應用中還有很多尚未解決的問題,例如上面提到的靜態分析與動態分析存在的不足,現在發展的主流方向是將靜態、動態分析技術進行結合,使用相同樣本的不同層面的特征相對獨立地訓練多個分類器,然后進行集成,以彌補彼此的不足之處,
除此之外,深度學習演算法的可解釋性也是制約其發展的一個問題,當前的分類模型一般情況下作為黑盒被加以使用,其結果無法為安全人員進一步分析溯源提供指導,我們常說攻防是息息相關的,螺旋上升的狀態,既然存在基于深度學習的惡意代碼檢測技術,那么自然也有基于深度學習的或者是針對深度學習的惡意代碼檢測繞過技術,這也是近年來研究的熱點問題,那么如何提高模型的穩健性,防止這些定制化的干擾項對我們的深度學習演算法產生不利的影響,對抗生成網路的提出或許可以給出答案,
三.機器學習演算法在工業界的應用
首先普及一個概念——NGAV,NGAV(Next-Gen AntiVirus)是下一代反病毒軟體簡稱,它是一些廠商提出來的新的病毒檢測概念,旨在用新技術彌補傳統惡意軟體檢測的短板,
- 多家殺毒引擎廠商將機器學習視作NGAV的重要技術,包括McAfee[11], Vmware[9], CrowdStrike[10], Avast[6]
- 越來越多的廠商開始關注機器學習技術,并發表相關的研究(卡巴斯基[7],火眼[8]),火眼還是用機器學習技術對APT進行分析(組織相似度溯源)
越來越多的安全廠商將機器學習視為反病毒軟體的一個關鍵技術,但需要注意,NGAV并不是一個清晰的定義,你沒法去界定一個反病毒軟體是上一代產品還是下一代產品,衡量反病毒軟體的性能只有對惡意軟體的檢測率、計算消耗、誤報率等,我們只是從現狀分析得到越來越多安全領域結合了機器學習,
作為安全從業人員或科研人員,機器學習技術也是我們必須要關注的一個技術,

機器學習演算法需要解決的問題如下:
-
算力問題
機器學習和深度學習演算法需要大量的算力,如果我們在本地部署還需要GPU的支持,這樣就帶來了一個硬體配置問題,所以如何減小模型的size及提升模型的檢測能力是一個關鍵性的問題, -
大規模的特征資料
特征對于分類訓練非常關鍵,如何抽取這些資料特征呢? -
訓練的模型是可解釋的
這個問題可以說是機器學習演算法和深度學習演算法在反病毒軟體應用中最關鍵的一個問題,病毒的對抗是黑客與安全從業人員的對抗的前線,如果我們訓練的模型是不可解釋的,那么一旦被黑客發現某些規則存在的弱點,他們就可以針對這些弱點設計免殺方法,從而繞過造成重大安全隱患,另一方面,如果機器學習演算法是不可解釋黑盒的,用戶他也是不可接受的,難以起到保護重要, -
誤報需要維持極度的低水平
誤報是反病毒軟體用戶體驗的一個重要指標,傳統的特征碼技術、主動防御技術都具有誤報低的特性,而機器學習是一個預測技術,會存在一些誤報,如何避免這些誤報并且提高檢測的查全率也是重要的問題, -
演算法需要根據惡意軟體作者的變化快速適應新的檢測特征
這也是關鍵性問題,在機器學習模型應用中,惡意軟體是不斷變化的,而機器學習演算法部署到本地中,它的引數是不變的,所以在長時間的惡意演化中其模型或引數不再適用,其檢測結果會有影響,目前,云沙箱、在線更新病毒庫特征是一些解決方法,
最后作者總結下機器學習演算法的優勢,具體如下:
(1) 傳統方法
- 優點:速度快,消耗計算資源少
只需要將特征碼提取出來,上傳至云端進行檢測;相對于機器學習大量的矩陣計算,其計算資源消耗少, - 缺點:容易繞過,對于未知惡意軟體檢出率低
使用加殼、加密、混淆容易繞過,對于未知軟體不知道其特征碼,只能通過啟發式方法、主動防御濟寧檢測,相對于機器學習檢測率要低,
(2) 機器學習方法
- 優點:能夠建立專家難以發現的規則與特征
發現的規則和特征很可能是統計學特征,而不是惡意和非惡意的特征,所以這些特征很容易被黑客進行規避,這既是優點也是缺點,雖然有缺陷,但也能發現惡意樣本的關聯和行為, - 缺點:資源消耗大,面臨漂移問題,需要不斷更新引數
四.總結
寫到這里,這篇文章就介紹完畢,希望對您有所幫助,最后進行簡單的總結:
- 機器學習方法與傳統方法不是取代與被取代的關系,而是相互補充,好的防御系統往往是多種技術方法的組合,
- 機器學習的檢測方法研究還不充分,安全領域的專有瓶頸與人工智能研究的共有瓶頸均存在、
- 機器學習演算法本身也面對一些攻擊方法的威脅,比如對應抗本,
對抗樣本指的是一個經過微小調整就可以讓機器學習演算法輸出錯誤結果的輸入樣本,在影像識別中,可以理解為原來被一個卷積神經網路(CNN)分類為一個類(比如“熊貓”)的圖片,經過非常細微甚至人眼無法察覺的改動后,突然被誤分成另一個類(比如“長臂猿”),再比如無人駕駛的模型如果被攻擊,Stop標志可能被汽車識別為直行、轉彎,


學安全一年,認識了很多安全大佬和朋友,希望大家一起進步,這篇文章中如果存在一些不足,還請海涵,作者作為網路安全初學者的慢慢成長路吧!希望未來能更透徹撰寫相關文章,同時非常感謝參考文獻中的安全大佬們的文章分享,感謝師傅、師兄師弟、師姐師妹們的教導,深知自己很菜,得努力前行,

《珈國情》
明月千里兩相思,
清風縷縷寄離愁,
燕歸珞珈花已謝,
情滿景逸映深秋,
最感恩的永遠是家人的支持,知道為啥而來,知道要做啥,知道努力才能回去,
夜已深,雖然笨,但還得奮斗,
歡迎大家討論,是否覺得這系列文章幫助到您!任何建議都可以評論告知讀者,共勉,
(By:Eastmount 2020-07-24 星期六 夜于東西湖 http://blog.csdn.net/eastmount/ )
參考文獻:
-
[1] Saxe J, Berlin K. Deep neural network based malware detection using two dimensional binary program features[C]//2015 10th International Conference on Malicious and Unwanted Software (MALWARE). IEEE, 2015: 11-20.
-
[2] https://www.kaggle.com/c/malware-classification
-
[3] https://www.fireeye.com/blog/threat-research/2018/12/what-are-deep-neural-networks-learning-about-malware.html
-
[4]Kolosnjaji B, Zarras A, Webster G, et al. Deep learning for classification of malware system call sequences[C]//Australasian Joint Conference on Artificial Intelligence. Springer, Cham, 2016: 137-149.
-
[5] Wüchner T, Cis?ak A, Ochoa M, et al. Leveraging compression-based graph mining for behavior-based malware detection[J]. IEEE Transactions on Dependable and Secure Computing, 2017, 16(1): 99-112.
-
[6]https://www.avast.com/technology/malware-detection-and-blocking
-
[7] https://media.kaspersky.com/en/enterprise-security/Kaspersky-Lab-Whitepaper-Machine-Learning.pdf
-
[8] https://www.fireeye.com/blog/threat-research/2019/03/clustering-and-associating-attacker-activity-at-scale.html
-
[9] https://www.carbonblack.com/resources/definitions/what-is-next-generation-antivirus/
-
[10] https://www.crowdstrike.com/epp-101/next-generation-antivirus-ngav/
-
[11] https://www.mcafee.com/enterprise/en-us/security-awareness/endpoint/what-is-next-gen-endpoint-protection.html
-
[i] Saxe, J., & Berlin, K. (2015, October). Deep neural network-based malware detection using two-dimensional binary program features. In 2015 10th International Conference on Malicious and Unwanted Software (MALWARE) (pp. 11-20). IEEE.
-
[ii] Nix, R., & Zhang, J. (2017, May). Classification of Android apps and malware using deep neural networks. In 2017 International joint conference on neural networks (IJCNN) (pp. 1871-1878). IEEE.
-
[iii] Tobiyama, S., Yamaguchi, Y., Shimada, H., Ikuse, T., & Yagi, T. (2016, June). Malware detection with deep neural network using process behavior. In 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC) (Vol. 2, pp. 577-582). IEEE.
-
[iv] Pascanu, R., Stokes, J. W., Sanossian, H., Marinescu, M., & Thomas, A. (2015, April). Malware classification with recurrent networks. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1916-1920). IEEE.
-
[v] Athiwaratkun, B., & Stokes, J. W. (2017, March). Malware classification with LSTM and GRU language models and a character-level CNN. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2482-2486). IEEE.
-
[vi] Athiwaratkun, B., & Stokes, J. W. (2017, March). Malware classification with LSTM and GRU language models and a character-level CNN. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2482-2486). IEEE.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290007.html
標籤:其他
上一篇:實訓第三天記錄-sqli-lab7-11+upload-lab1-3
下一篇:Java執行緒