0.為什么使用指標
假如我們定義了 char a=’A’ ,當需要使用 ‘A’ 時,除了直接呼叫變數 a ,還可以定義 char *p=&a ,呼叫 a 的地址,即指向 a 的指標 p ,變數 a( char 型別)只占了一個位元組,指標本身的大小由可尋址的字長來決定,指標 p 占用 4 個位元組,
程式員必備硬核資料,點擊下載
但如果要參考的是占用記憶體空間比較大東西,用指標也還是 4 個位元組即可,
使用指標型變數在很多時候占用更小的記憶體空間, 變數為了表示資料,指標可以更好的傳遞資料,舉個例子:
第一節課是 1 班語文, 2 班數學,第二節課顛倒過來, 1 班要上數學, 2 班要上語文,那么第一節課下課后需要怎樣作調整呢?方案一:課間 1 班學生全都去 2 班, 2 班學生全都來 1 班,當然,走的時候要攜帶上書本、筆紙、零食……場面一片狼藉;方案二:兩位老師課間互換教室,
顯然,方案二更好一些,方案二類似使用指標傳遞地址,方案一將記憶體中的內容重新“復制”了一份,效率比較低,
-
在資料傳遞時,如果資料塊較大,可以使用指標傳遞地址而不是實際資料,即提高傳輸速度,又節省大量記憶體,
一個資料緩沖區 char buf[100] ,如果其中 buf[0,1] 為命令號, buf[2,3] 為資料型別, buf[4~7] 為該型別的數值,型別為 int ,使用如下陳述句進行賦值:
*(short*)&buf[0]=DataId;
*(short*)&buf[2]=DataType;
*(int*)&buf[4]=DataValue;
-
資料轉換,利用指標的靈活的型別轉換,可以用來做資料型別轉換,比較常用于通訊緩沖區的填充,
-
指標的機制比較簡單,其功能可以被集中重新實作成更抽象化的參考資料形式
-
函式指標,形如: #define PMYFUN (void*)(int,int) ,可以用在大量分支處理的實體當中,如某通訊根據不同的命令號執行不同型別的命令,則可以建立一個函式指標陣列,進行散轉,
-
在資料結構中,鏈表、樹、圖等大量的應用都離不開指標,
1. 指標強化
1.1 指標是一種資料型別
作業系統將硬體和軟體結合起來,給程式員提供的一種對記憶體使用的抽象,這種抽象機制使得程式使用的是虛擬存盤器,而不是直接操作和使用真實存在的物理存盤器,所有的虛擬地址形成的集合就是虛擬地址空間,
記憶體是一個很大的線性的位元組陣列,每個位元組固定由 8 個二進制位組成,每個位元組都有唯一的編號,如下圖,這是一個 4G 的記憶體,他一共有 4x1024x1024x1024 = 4294967296 個位元組,那么它的地址范圍就是 0 ~ 4294967296 ,十六進制表示就是 0x00000000~0xffffffff ,當程式使用的資料載入記憶體時,都有自己唯一的一個編號,這個編號就是這個資料的地址,指標就是這樣形成的,
1.1.1 指標變數
指標是一種資料型別,占用記憶體空間,用來保存記憶體地址,
void test01(){
int* p1 = 0x1234;
int*** p2 = 0x1111;
printf("p1 size:%d\n",sizeof(p1));
printf("p2 size:%d\n",sizeof(p2));
//指標是變數,指標本身也占記憶體空間,指標也可以被賦值
int a = 10;
p1 = &a;
printf("p1 address:%p\n", &p1);
printf("p1 address:%p\n", p1);
printf("a address:%p\n", &a);
}
1.1.2 野指標和空指標
1.1.2.1 空指標
標準定義了NULL指標,它作為一個特殊的指標變數,表示不指向任何東西,要使一個指標為NULL,可以給它賦值一個零值,為了測驗一個指標百年來那個是否為NULL,你可以將它與零值進行比較,
對指標解參考操作可以獲得它所指向的值,但從定義上看,NULL指標并未指向任何東西,因為對一個NULL指標因參考是一個非法的操作,在解參考之前,必須確保它不是一個NULL指標,
如果對一個NULL指標間接訪問會發生什么呢?結果因編譯器而異, 不允許向NULL和非法地址拷貝記憶體:
void test(){
char *p = NULL;
//給p指向的記憶體區域拷貝內容
strcpy(p, "1111"); //err
char *q = 0x1122;
//給q指向的記憶體區域拷貝內容
strcpy(q, "2222"); //err
}
1.1.2.2 野指標
在使用指標時,要避免野指標的出現:
野指標指向一個已洗掉的物件或未申請訪問受限記憶體區域的指標,與空指標不同,野指標無法通過簡單地判斷是否為 NULL避免,而只能通過養成良好的編程習慣來盡力減少,對野指標進行操作很容易造成程式錯誤,
什么情況下會導致野指標?
-
指標變數未初始化
任何指標變數剛被創建時不會自動成為NULL指標,它的預設值是隨機的,它會亂指一氣,所以,指標變數在創建的同時應當被初始化,要么將指標設定為NULL,要么讓它指向合法的記憶體,
-
指標釋放后未置空
有時指標在free或delete后未賦值 NULL,便會使人以為是合法的,別看free和delete的名字(尤其是delete),它們只是把指標所指的記憶體給釋放掉,但并沒有把指標本身干掉,此時指標指向的就是“垃圾”記憶體,釋放后的指標應立即將指標置為NULL,防止產生“野指標”,
-
指標操作超越變數作用域
不要回傳指向堆疊記憶體的指標或參考,因為堆疊記憶體在函式結束時會被釋放,
void test(){
int* p = 0x001; //未初始化
printf("%p\n",p);
*p = 100;
}
操作野指標是非常危險的操作,應該規避野指標的出現:
-
初始化時置 NULL
指標變數一定要初始化為NULL,因為任何指標變數剛被創建時不會自動成為NULL指標,它的預設值是隨機的,
-
釋放時置 NULL
當指標p指向的記憶體空間釋放時,沒有設定指標p的值為NULL,delete和free只是把記憶體空間釋放了,但是并沒有將指標p的值賦為NULL,通常判斷一個指標是否合法,都是使用if陳述句測驗該指標是否為NULL,
1.1.2.3 void*型別指標
void是一種特殊的指標型別,可以用來存放任意物件的地址,一個void指標存放著一個地址,這一點和其他指標類似,不同的是,我們對它到底儲存的是什么物件的地址并不了解,
double a=2.3;
int b=5;
void *p=&a;
cout<<p<<endl; //輸出了a的地址
p=&b;
cout<<p<<endl; //輸出了b的地址
//cout<<*p<<endl;這一行不可以執行,void*指標只可以儲存變數地址,不可以直接操作它指向的物件
由于void是空型別,只保存了指標的值,而丟失了型別資訊,我們不知道他指向的資料是什么型別的,只指定這個資料在記憶體中的起始地址,如果想要完整的提取指向的資料,程式員就必須對這個指標做出正確的型別轉換,然后再解指標,
1.1.2.4 void*陣列和指標
-
同型別指標變數可以相互賦值,陣列不行,只能一個一個元素的賦值或拷貝
-
陣列在記憶體中是連續存放的,開辟一塊連續的記憶體空間,陣列是根據陣列的下進行訪問的,指標很靈活,它可以指向任意型別的資料,指標的型別說明了它所指向地址空間的記憶體,
-
陣列所占存盤空間的記憶體:sizeof(陣列名) 陣列的大小:sizeof(陣列名)/sizeof(資料型別),在32位平臺下,無論指標的型別是什么,sizeof(指標名)都是 4 ,在 64 位平臺下,無論指標的型別是什么,sizeof(指標名)都是 8 ,
-
陣列名作為右值的時候,就是第一個元素的地址
int main(void)
{
int arr[5] = {1,2,3,4,5};
int *p_first = arr;
printf("%d",*p_first); //1
return 0;
}
-
指向陣列元素的指標 支持 遞增 遞減 運算,p= p+1意思是,讓p指向原來指向的記憶體塊的下一個相鄰的相同型別的記憶體塊,在陣列中相鄰記憶體就是相鄰下標元素,
1.1.3 間接訪問運算子
通過一個指標訪問它所指向的地址的程序叫做間接訪問,或者叫解參考指標,這個用于執行間接訪問的運算子是*,
注意:對一個int型別指標解參考會產生一個整型值,類似地,對一個float指標解參考會產生了一個float型別的值,
int arr[5];
int *p = * (&arr);
int arr1[5][3] arr1 = int(*)[3]&arr1
1)在指標宣告時,* 號表示所宣告的變數為指標
2)在指標使用時,* 號表示操作指標所指向的記憶體空間
-
*相當通過地址(指標變數的值)找到指標指向的記憶體,再操作記憶體
-
*放在等號的左邊賦值(給記憶體賦值,寫記憶體)
-
*放在等號的右邊取值(從記憶體中取值,讀記憶體)
//解參考
void test01(){
//定義指標
int* p = NULL;
//指標指向誰,就把誰的地址賦給指標
int a = 10;
p = &a;
*p = 20;//*在左邊當左值,必須確保記憶體可寫
//*號放右面,從記憶體中讀值
int b = *p;
//必須確保記憶體可寫
char* str = "hello world!";
*str = 'm';
printf("a:%d\n", a);
printf("*p:%d\n", *p);
printf("b:%d\n", b);
}
1.1.4 指標的步長
指標是一種資料型別,是指它指向的記憶體空間的資料型別,指標所指向的記憶體空間決定了指標的步長,指標的步長指的是,當指標+1時候,移動多少位元組單位,
思考如下問題:
int a = 0xaabbccdd;
unsigned int *p1 = &a;
unsigned char *p2 = &a;
//為什么*p1列印出來正確結果?
printf("%x\n", *p1);
//為什么*p2沒有列印出來正確結果?
printf("%x\n", *p2);
//為什么p1指標+1加了4位元組?
printf("p1 =%d\n", p1);
printf("p1+1=%d\n", p1 + 1);
//為什么p2指標+1加了1位元組?
printf("p2 =%d\n", p2);
printf("p2+1=%d\n", p2 + 1);
1.1.5 函式與指標
1.1.5.1 函式的引數和指標
C語言中,實參傳遞給形參,是按值傳遞的,也就是說,函式中的形參是實參的拷貝份,形參和實參只是在值上面一樣,而不是同一個記憶體資料物件,這就意味著:這種資料傳遞是單向的,即從呼叫者傳遞給被調函式,而被調函式無法修改傳遞的引數達到回傳的效果,
void change(int a)
{
a++; //在函式中改變的只是這個函式的區域變數a,而隨著函式執行結束,a被銷毀,age還是原來的age,紋絲不動,
}
int main(void)
{
int age = 60;
change(age);
printf("age = %d",age); // age = 60
return 0;
}
有時候我們可以使用函式的回傳值來回傳資料,在簡單的情況下是可以的,但是如果回傳值有其它用途(例如回傳函式的執行狀態量),或者要回傳的資料不止一個,回傳值就解決不了了,
傳遞變數的指標可以輕松解決上述問題,
void change(int* pa)
{
(*pa)++; //因為傳遞的是age的地址,因此pa指向記憶體資料age,當在函式中對指標pa解地址時,
//會直接去記憶體中找到age這個資料,然后把它增1,
}
int main(void)
{
int age = 160;
change(&age);
printf("age = %d",age); // age = 61
return 0;
}
比如指標的一個常見的使用例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void swap(int *,int *);
int main()
{
int a=5,b=10;
printf("a=%d,b=%d\n",a,b);
swap(&a,&b);
printf("a=%d,b=%d\n",a,b);
return 0;
}
void swap(int *pa,int *pb)
{
int t=*pa;*pa=*pb;*pb=t;
}
在以上的例子中,swap函式的兩個形參pa和pb可以接收兩個整型變數的地址,并通過間接訪問的方式修改了它指向變數的值,在main函式中呼叫swap時,提供的實參分別為&a,&b,這樣就實作了pa=&a,pb=&b的賦值程序,這樣在swap函式中就通過pa修改了 a 的值,通過pb修改了 b 的值,因此,如果需要在被調函式中修改主調函式中變數的值,就需要經過以下幾個步驟:
-
定義函式的形參必須為指標型別,以接收主調函式中傳來的變數的地址;
-
呼叫函式時實參為變數的地址;
-
在被調函式中使用*間接訪問形參指向的記憶體空間,實作修改主調函式中變數值的功能,
指標作為函式的形參的另一個典型應用是當函式有多個回傳值的情形,比如,需要在一個函式中統計一個陣列的最大值、最小值和平均值,當然你可以撰寫三個函式分別完成統計三個值的功能,但比較啰嗦,如:
int GetMax(int a[],int n)
{
int max=a[0],i;
for(i=1;i<n;i++)
{
if(max<a[i]) max=a[i];
}
return max;
}
int GetMin(int a[],int n)
{
int min=a[0],i;
for(i=1;i<n;i++)
{
if(min>a[i]) min=a[i];
}
return min;
}
double GetAvg(int a[],int n)
{
double avg=0;
int i;
for(i=0;i<n;i++)
{
avg+=a[i];
}
return avg/n;
}
其實我們完全可以在一個函式中完成這個功能,由于函式只能有一個回傳值,可以回傳平均值,最大值和最小值可以通過指標型別的形參來進行實作:
double Stat(int a[],int n,int *pmax,int *pmin)
{
double avg=a[0];
int i;
*pmax=*pmin=a[0];
for(i=1;i<n;i++)
{
avg+=a[i];
if(*pmax<a[i]) *pmax=a[i];
if(*pmin>a[i]) *pmin=a[i];
}
return avg/n;
}
1.1.5.2 函式的指標
一個函式總是占用一段連續的記憶體區域,函式名在運算式中有時也會被轉換為該函式所在記憶體區域的首地址,我們可以把函式的這個首地址賦予一個指標變數,使指標變數指向函式所在的記憶體區域,然后通過指標變數就可以找到并呼叫該函式,這種指標就是函式指標,
函式指標的定義形式為:
returnType (*pointerName)(param list);
returnType 為函式回傳值型別,pointerNmae 為指標名稱,param list 為函式引數串列,引數串列中可以同時給出引數的型別和名稱,也可以只給出引數的型別,省略引數的名稱,這一點和函式原型非常類似,
用指標來實作對函式的呼叫:
#include <stdio.h>
//回傳兩個數中較大的一個
int max(int a, int b)
{
return a>b ? a : b;
}
int main()
{
int x, y, maxval;
//定義函式指標
int (*pmax)(int, int) = max; //也可以寫作int (*pmax)(int a, int b)
printf("Input two numbers:");
scanf("%d %d", &x, &y);
maxval = (*pmax)(x, y);
printf("Max value: %d\n", maxval);
return 0;
}
1.1.5.3 結構體和指標
結構體指標有特殊的語法: -> 符號
如果p是一個結構體指標,則可以使用 p ->【成員】 的方法訪問結構體的成員
typedef struct
{
char name[31];
int age;
float score;
}Student;
int main(void)
{
Student stu = {"Bob" , 19, 98.0};
Student*ps = &stu;
ps->age = 20;
ps->score = 99.0;
printf("name:%s age:%d
",ps->name,ps->age);
return 0;
}
1.2 指標的意義_間接賦值
1.2.1 間接賦值的三大條件
通過指標間接賦值成立的三大條件:
-
2個變數(一個普通變數一個指標變數、或者一個實參一個形參)
-
建立關系
-
通過 * 操作指標指向的記憶體
void test(){
int a = 100; //兩個變數
int *p = NULL;
//建立關系
//指標指向誰,就把誰的地址賦值給指標
p = &a;
//通過*操作記憶體
*p = 22;
}
1.2.2 如何定義合適的指標變數
void test(){
int b;
int *q = &b; //0級指標
int **t = &q;
int ***m = &t;
}
1.2.3 間接賦值:從0級指標到1級指標
int func1(){ return 10; }
void func2(int a){
a = 100;
}
//指標的意義_間接賦值
void test02(){
int a = 0;
a = func1();
printf("a = %d\n", a);
//為什么沒有修改?
func2(a);
printf("a = %d\n", a);
}
//指標的間接賦值
void func3(int* a){
*a = 100;
}
void test03(){
int a = 0;
a = func1();
printf("a = %d\n", a);
//修改
func3(&a);
printf("a = %d\n", a);
}
1.2.4 間接賦值:從1級指標到2級指標
void AllocateSpace(char** p){
*p = (char*)malloc(100);
strcpy(*p, "hello world!");
}
void FreeSpace(char** p){
if (p == NULL){
return;
}
if (*p != NULL){
free(*p);
*p = NULL;
}
}
void test(){
char* p = NULL;
AllocateSpace(&p);
printf("%s\n",p);
FreeSpace(&p);
if (p == NULL){
printf("p記憶體釋放!\n");
}
}
1.2.4 間接賦值的推論
-
用1級指標形參,去間接修改了0級指標(實參)的值,
-
用2級指標形參,去間接修改了1級指標(實參)的值,
-
用3級指標形參,去間接修改了2級指標(實參)的值,
-
用n級指標形參,去間接修改了n-1級指標(實參)的值,
1.3 指標做函式引數
指標做函式引數,具備輸入和輸出特性:
-
輸入:主調函式分配記憶體
-
輸出:被呼叫函式分配記憶體
1.3.1 輸入特性
void fun(char *p /* in */)
{
//給p指向的記憶體區域拷貝內容
strcpy(p, "abcddsgsd");
}
void test(void)
{
//輸入,主調函式分配記憶體
char buf[100] = { 0 };
fun(buf);
printf("buf = %s\n", buf);
}
1.3.2 輸出特性
void fun(char **p /* out */, int *len)
{
char *tmp = (char *)malloc(100);
if (tmp == NULL)
{
return;
}
strcpy(tmp, "adlsgjldsk");
//間接賦值
*p = tmp;
*len = strlen(tmp);
}
void test(void)
{
//輸出,被呼叫函式分配記憶體,地址傳遞
char *p = NULL;
int len = 0;
fun(&p, &len);
if (p != NULL)
{
printf("p = %s, len = %d\n", p, len);
}
}
1.4 字串指標強化
1.4.1 字串指標做函式引數
1.4.1.1 字串基本操作
//字串基本操作
//字串是以0或者'\0'結尾的字符陣列,(數字0和字符'\0'等價)
void test01(){
//字符陣列只能初始化5個字符,當輸出的時候,從開始位置直到找到0結束
char str1[] = { 'h', 'e', 'l', 'l', 'o' };
printf("%s\n",str1);
//字符陣列部分初始化,剩余填0
char str2[100] = { 'h', 'e', 'l', 'l', 'o' };
printf("%s\n", str2);
//如果以字串初始化,那么編譯器默認會在字串尾部添加'\0'
char str3[] = "hello";
printf("%s\n",str3);
printf("sizeof str:%d\n",sizeof(str3));
printf("strlen str:%d\n",strlen(str3));
//sizeof計算陣列大小,陣列包含'\0'字符
//strlen計算字串的長度,到'\0'結束
//那么如果我這么寫,結果是多少呢?
char str4[100] = "hello";
printf("sizeof str:%d\n", sizeof(str4));
printf("strlen str:%d\n", strlen(str4));
//請問下面輸入結果是多少?sizeof結果是多少?strlen結果是多少?
char str5[] = "hello\0world";
printf("%s\n",str5);
printf("sizeof str5:%d\n",sizeof(str5));
printf("strlen str5:%d\n",strlen(str5));
//再請問下面輸入結果是多少?sizeof結果是多少?strlen結果是多少?
char str6[] = "hello\012world";
printf("%s\n", str6);
printf("sizeof str6:%d\n", sizeof(str6));
printf("strlen str6:%d\n", strlen(str6));
}
八進制和十六進制轉義字符:
在C中有兩種特殊的字符,八進制轉義字符和十六進制轉義字符,八進制字符的一般形式是'\ddd',d是0-7的數字,十六進制字符的一般形式是'\xhh',h是0-9或A-F內的一個,八進制字符和十六進制字符表示的是字符的ASCII碼對應的數值,
比如 :
-
'\063'表示的是字符'3',因為'3'的ASCII碼是30(十六進制),48(十進制),63(八進制), -
'\x41'表示的是字符'A',因為'A'的ASCII碼是41(十六進制),65(十進制),101(八進制),
1.4.1.2 字串拷貝功能實作
//拷貝方法1
void copy_string01(char* dest, char* source ){
for (int i = 0; source[i] != '\0';i++){
dest[i] = source[i];
}
}
//拷貝方法2
void copy_string02(char* dest, char* source){
while (*source != '\0' /* *source != 0 */){
*dest = *source;
source++;
dest++;
}
}
//拷貝方法3
void copy_string03(char* dest, char* source){
//判斷*dest是否為0,0則退出回圈
while (*dest++ = *source++){}
}
程式員必備硬核資料,點擊下載
1.4.1.3 字串反轉模型
void reverse_string(char* str){
if (str == NULL){
return;
}
int begin = 0;
int end = strlen(str) - 1;
while (begin < end){
//交換兩個字符元素
char temp = str[begin];
str[begin] = str[end];
str[end] = temp;
begin++;
end--;
}
}
void test(){
char str[] = "abcdefghijklmn";
printf("str:%s\n", str);
reverse_string(str);
printf("str:%s\n", str);
}
1.4.2 字串的格式化
1.4.2.1 sprintf
#include <stdio.h>
int sprintf(char *str, const char *format, ...);
功能:根據引數format字串來轉換并格式化資料,然后將結果輸出到str指定的空間中,直到 出現字串結束符 '\0' 為止,
引數:
-
str:字串首地址
-
format:字串格式,用法和printf()一樣
回傳值:
-
成功:實際格式化的字符個數
-
失敗: - 1
void test(){
//1. 格式化字串
char buf[1024] = { 0 };
sprintf(buf, "你好,%s,歡迎加入我們!", "John");
printf("buf:%s\n",buf);
memset(buf, 0, 1024);
sprintf(buf, "我今年%d歲了!", 20);
printf("buf:%s\n", buf);
//2. 拼接字串
memset(buf, 0, 1024);
char str1[] = "hello";
char str2[] = "world";
int len = sprintf(buf,"%s %s",str1,str2);
printf("buf:%s len:%d\n", buf,len);
//3. 數字轉字串
memset(buf, 0, 1024);
int num = 100;
sprintf(buf, "%d", num);
printf("buf:%s\n", buf);
//設定寬度 右對齊
memset(buf, 0, 1024);
sprintf(buf, "%8d", num);
printf("buf:%s\n", buf);
//設定寬度 左對齊
memset(buf, 0, 1024);
sprintf(buf, "%-8d", num);
printf("buf:%s\n", buf);
//轉成16進制字串 小寫
memset(buf, 0, 1024);
sprintf(buf, "0x%x", num);
printf("buf:%s\n", buf);
//轉成8進制字串
memset(buf, 0, 1024);
sprintf(buf, "0%o", num);
printf("buf:%s\n", buf);
}
1.4.2.2 sscanf
#include <stdio.h>
int sscanf(const char *str, const char *format, ...);
功能:從str指定的字串讀取資料,并根據引數format字串來轉換并格式化資料,
引數:
-
str:指定的字串首地址
-
format:字串格式,用法和scanf()一樣
回傳值:
-
成功:成功則回傳引數數目,失敗則回傳-1
-
失敗: - 1
//1. 跳過資料
void test01(){
char buf[1024] = { 0 };
//跳過前面的數字
//匹配第一個字符是否是數字,如果是,則跳過
//如果不是則停止匹配
sscanf("123456aaaa", "%*d%s", buf);
printf("buf:%s\n",buf);
}
//2. 讀取指定寬度資料
void test02(){
char buf[1024] = { 0 };
//跳過前面的數字
sscanf("123456aaaa", "%7s", buf);
printf("buf:%s\n", buf);
}
//3. 匹配a-z中任意字符
void test03(){
char buf[1024] = { 0 };
//跳過前面的數字
//先匹配第一個字符,判斷字符是否是a-z中的字符,如果是匹配
//如果不是停止匹配
sscanf("abcdefg123456", "%[a-z]", buf);
printf("buf:%s\n", buf);
}
//4. 匹配aBc中的任何一個
void test04(){
char buf[1024] = { 0 };
//跳過前面的數字
//先匹配第一個字符是否是aBc中的一個,如果是,則匹配,如果不是則停止匹配
sscanf("abcdefg123456", "%[aBc]", buf);
printf("buf:%s\n", buf);
}
//5. 匹配非a的任意字符
void test05(){
char buf[1024] = { 0 };
//跳過前面的數字
//先匹配第一個字符是否是aBc中的一個,如果是,則匹配,如果不是則停止匹配
sscanf("bcdefag123456", "%[^a]", buf);
printf("buf:%s\n", buf);
}
//6. 匹配非a-z中的任意字符
void test06(){
char buf[1024] = { 0 };
//跳過前面的數字
//先匹配第一個字符是否是aBc中的一個,如果是,則匹配,如果不是則停止匹配
sscanf("123456ABCDbcdefag", "%[^a-z]", buf);
printf("buf:%s\n", buf);
}
1.5 一級指標易錯點
1.5.1 越界
void test(){
char buf[3] = "abc";
printf("buf:%s\n",buf);
}
1.5.2 指標疊加會不斷改變指標指向
void test(){
char *p = (char *)malloc(50);
char buf[] = "abcdef";
int n = strlen(buf);
int i = 0;
for (i = 0; i < n; i++)
{
*p = buf[i];
p++; //修改原指標指向
}
free(p);
}
1.5.3 回傳區域變數地址
char *get_str()
{
char str[] = "abcdedsgads"; //堆疊區,
printf("[get_str]str = %s\n", str);
return str;
}
1.5.4 同一塊記憶體釋放多次(不可以釋放野指標)
void test(){
char *p = NULL;
p = (char *)malloc(50);
strcpy(p, "abcdef");
if (p != NULL)
{
//free()函式的功能只是告訴系統 p 指向的記憶體可以回收了
// 就是說,p 指向的記憶體使用權交還給系統
//但是,p的值還是原來的值(野指標),p還是指向原來的記憶體
free(p);
}
if (p != NULL)
{
free(p);
}
}
1.6 const使用
//const修飾變數
void test01(){
//1. const基本概念
const int i = 0;
//i = 100; //錯誤,只讀變數初始化之后不能修改
//2. 定義const變數最好初始化
const int j;
//j = 100; //錯誤,不能再次賦值
//3. c語言的const是一個只讀變數,并不是一個常量,可通過指標間接修改
const int k = 10;
//k = 100; //錯誤,不可直接修改,我們可通過指標間接修改
printf("k:%d\n", k);
int* p = &k;
*p = 100;
printf("k:%d\n", k);
}
//const 修飾指標
void test02(){
int a = 10;
int b = 20;
//const放在*號左側 修飾p_a指標指向的記憶體空間不能修改,但可修改指標的指向
const int* p_a = &a;
//*p_a = 100; //不可修改指標指向的記憶體空間
p_a = &b; //可修改指標的指向
//const放在*號的右側, 修飾指標的指向不能修改,但是可修改指標指向的記憶體空間
int* const p_b = &a;
//p_b = &b; //不可修改指標的指向
*p_b = 100; //可修改指標指向的記憶體空間
//指標的指向和指標指向的記憶體空間都不能修改
const int* const p_c = &a;
}
//const指標用法
struct Person{
char name[64];
int id;
int age;
int score;
};
//每次都對物件進行拷貝,效率低,應該用指標
void printPersonByValue(struct Person person){
printf("Name:%s\n", person.name);
printf("Name:%d\n", person.id);
printf("Name:%d\n", person.age);
printf("Name:%d\n", person.score);
}
//但是用指標會有副作用,可能會不小心修改原資料
void printPersonByPointer(const struct Person *person){
printf("Name:%s\n", person->name);
printf("Name:%d\n", person->id);
printf("Name:%d\n", person->age);
printf("Name:%d\n", person->score);
}
void test03(){
struct Person p = { "Obama", 1101, 23, 87 };
//printPersonByValue(p);
printPersonByPointer(&p);
}
2. 指標的指標(二級指標)
2.1 二級指標基本概念
這里讓我們花點時間來看一個例子,揭開這個即將開始的序幕,考慮下面這些宣告:
int a = 12;
int *b = &a;
它們如下圖進行記憶體分配: 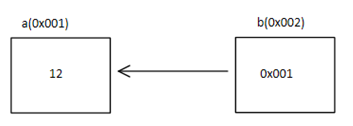
假定我們又有了第3個變數,名叫c,并用下面這條陳述句對它進行初始化:
c = &b;
它在記憶體中的大概模樣大致如下:

c的型別是什么?顯然它是一個指標,但它所指向的是什么?
變數b是一個“指向整型的指標”,所以任何指向b的型別必須是指向“指向整型的指標”的指標,更通俗地說,是一個指標的指標,
它合法嗎?
是的!指標變數和其他變數一樣,占據記憶體中某個特定的位置,所以用&運算子取得它的地址是合法的,
那么這個變數的宣告是怎樣的宣告的呢?
int **c = &b;
那么這個**c如何理解呢?運算子具有從右想做的結合性,所以這個運算式相當于(*c),我們從里向外逐層求職,*c訪問c所指向的位置,我們知道這是變數b.第二個間接訪問運算子訪問這個位置所指向的地址,也就是變數a.指標的指標并不難懂,只需要留心所有的箭頭,如果運算式中出現了間接訪問運算子,你就要隨箭頭訪問它所指向的位置,
2.2 二級指標做形參輸出特性
二級指標做引數的輸出特性是指由被調函式分配記憶體,
//被調函式,由引數n確定分配多少個元素記憶體
void allocate_space(int **arr,int n){
//堆上分配n個int型別元素記憶體
int *temp = (int *)malloc(sizeof(int)* n);
if (NULL == temp){
return;
}
//給記憶體初始化值
int *pTemp = temp;
for (int i = 0; i < n;i ++){
//temp[i] = i + 100;
*pTemp = i + 100;
pTemp++;
}
//指標間接賦值
*arr = temp;
}
//列印陣列
void print_array(int *arr,int n){
for (int i = 0; i < n;i ++){
printf("%d ",arr[i]);
}
printf("\n");
}
//二級指標輸出特性(由被調函式分配記憶體)
void test(){
int *arr = NULL;
int n = 10;
//給arr指標間接賦值
allocate_space(&arr,n);
//輸出arr指向陣列的記憶體
print_array(arr, n);
//釋放arr所指向記憶體空間的值
if (arr != NULL){
free(arr);
arr = NULL;
}
}
2.3 二級指標做形參輸入特性
二級指標做形參輸入特性是指由主調函式分配記憶體,
//列印陣列
void print_array(int **arr,int n){
for (int i = 0; i < n;i ++){
printf("%d ",*(arr[i]));
}
printf("\n");
}
//二級指標輸入特性(由主調函式分配記憶體)
void test(){
int a1 = 10;
int a2 = 20;
int a3 = 30;
int a4 = 40;
int a5 = 50;
int n = 5;
int** arr = (int **)malloc(sizeof(int *) * n);
arr[0] = &a1;
arr[1] = &a2;
arr[2] = &a3;
arr[3] = &a4;
arr[4] = &a5;
print_array(arr,n);
free(arr);
arr = NULL;
}
2.4 強化訓練_畫出記憶體模型圖
void mian()
{
//堆疊區指標陣列
char *p1[] = { "aaaaa", "bbbbb", "ccccc" };
//堆區指標陣列
char **p3 = (char **)malloc(3 * sizeof(char *)); //char *array[3];
int i = 0;
for (i = 0; i < 3; i++)
{
p3[i] = (char *)malloc(10 * sizeof(char)); //char buf[10]
sprintf(p3[i], "%d%d%d", i, i, i);
}
}
2.4 多級指標
將堆區陣列指標案例改為三級指標案例:
//分配記憶體
void allocate_memory(char*** p, int n){
if (n < 0){
return;
}
char** temp = (char**)malloc(sizeof(char*)* n);
if (temp == NULL){
return;
}
//分別給每一個指標malloc分配記憶體
for (int i = 0; i < n; i++){
temp[i] = malloc(sizeof(char)* 30);
sprintf(temp[i], "%2d_hello world!", i + 1);
}
*p = temp;
}
//列印陣列
void array_print(char** arr, int len){
for (int i = 0; i < len; i++){
printf("%s\n", arr[i]);
}
printf("----------------------\n");
}
//釋放記憶體
void free_memory(char*** buf, int len){
if (buf == NULL){
return;
}
char** temp = *buf;
for (int i = 0; i < len; i++){
free(temp[i]);
temp[i] = NULL;
}
free(temp);
}
void test(){
int n = 10;
char** p = NULL;
allocate_memory(&p, n);
//列印陣列
array_print(p, n);
//釋放記憶體
free_memory(&p, n);
}
2.5 深拷貝和淺拷貝
如果2個程式單元(例如2個函式)是通過拷貝 他們所共享的資料的 指標來作業的,這就是淺拷貝,因為真正要訪問的資料并沒有被拷貝,如果被訪問的資料被拷貝了,在每個單元中都有自己的一份,對目標資料的操作相互 不受影響,則叫做深拷貝,
#include <iostream>
using namespace std;
class CopyDemo
{
public:
CopyDemo(int pa,char *cstr) //建構式,兩個引數
{
this->a = pa;
this->str = new char[1024]; //指標陣列,動態的用new在堆上分配存盤空間
strcpy(this->str,cstr); //拷貝過來
}
//沒寫,C++會自動幫忙寫一個復制建構式,淺拷貝只復制指標,如下注釋部分
//CopyDemo(CopyDemo& obj)
//{
// this->a = obj.a;
// this->str = obj.str; //這里是淺復制會出問題,要深復制
//}
CopyDemo(CopyDemo& obj) //一般資料成員有指標要自己寫復制建構式,如下
{
this->a = obj.a;
// this->str = obj.str; //這里是淺復制會出問題,要深復制
this->str = new char[1024];//應該這樣寫
if(str != 0)
strcpy(this->str,obj.str); //如果成功,把內容復制過來
}
~CopyDemo() //解構式
{
delete str;
}
public:
int a; //定義一個整型的資料成員
char *str; //字串指標
};
int main()
{
CopyDemo A(100,"hello!!!");
CopyDemo B = A; //復制建構式,把A的10和hello!!!復制給B
cout <<"A:"<< A.a << "," <<A.str << endl;
//輸出A:100,hello!!!
cout <<"B:"<< B.a << "," <<B.str << endl;
//輸出B:100,hello!!!
//修改后,發現A,B都被改變,原因就是淺復制,A,B指標指向同一地方,修改后都改變
B.a = 80;
B.str[0] = 'k';
cout <<"A:"<< A.a << "," <<A.str << endl;
//輸出A:100,kello!!!
cout <<"B:"<< B.a << "," <<B.str << endl;
//輸出B:80,kello!!!
return 0;
}
根據上面實體可以看到,淺復制僅復制物件本身(其中包括是指標的成員),這樣不同被復制物件的成員中的對應非空指標會指向同一物件,被成員指標參考的物件成為共享的,無法直接通過指標成員安全地洗掉(因為若直接洗掉,另外物件中的指標就會無效,形成所謂的野指標,而訪問無效指標是危險的;
除非這些指標有參考計數或者其它手段確保被指物件的所有權);而深復制在淺復制的基礎上,連同指標指向的物件也一起復制,代價比較高,但是相對容易管理,
程式員必備硬核資料,點擊下載
參考資料
-
C Primer Plus(第五版)中文版
-
https://www.cnblogs.com/lulipro/p/7460206.html
歡迎一鍵三連!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290025.html
標籤:其他