東北某不知名雙非本科,四面成功上岸阿里巴巴,在這里把自己整理的面經分享出來,歡迎大家閱讀,
恰個飯——>《阿里巴巴 Java 開發手冊》,業界普遍遵循的開發規范
| 序號 | 文章名 | 超鏈接 |
|---|---|---|
| 1 | 作業系統面經大全——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門1 |
| 2 | 計算機網路面經大全——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門2 |
| 3 | Java并發編程面經大全——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門3 |
| 4 | Java虛擬機(JVM)面經大全——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門4 |
| 5 | MySQL資料庫面經大全——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門5 |
| 6 | Java集合面經大全——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門6 |
| 5 | 面試阿里,你必須知道的背景知識——雙非上岸阿里巴巴系列 | 2021最新版面經——>傳送門7 |
本博客內容持續維護,如有改進之處,還望各位大佬指出,感激不盡!
文章目錄
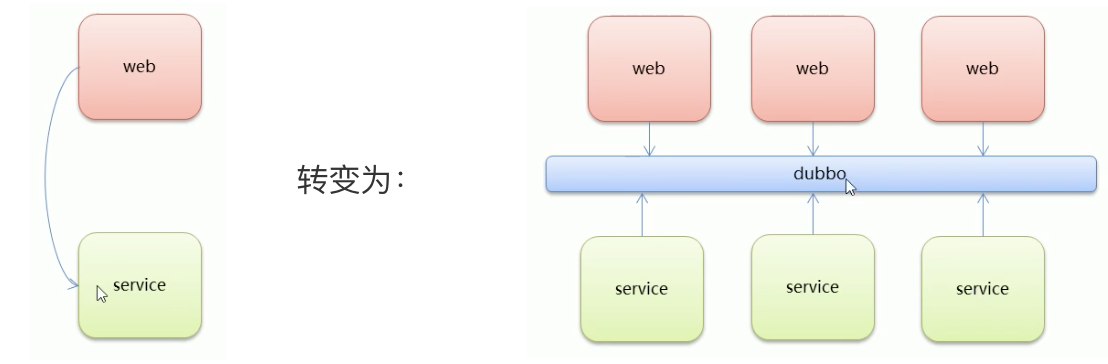
- Dubbo部分
- 第一章 分布式系統相關概念
- 1.1 大型互聯網專案架構目標
- 1.2 集群和分布式
- 1.3 架構演進
- 第二章 Dubbo概述
- 2.1 Dubbo概念
- 2.2 Dubbo架構
- 2.2.1 Dubbo架構及呼叫順序
- 2.2.2 Dubbo特點
- 第三章 Dubbo快速入門
- 3.1 Zookeeper
- 3.1.1 Zookeeper概述
- 3.1.2 Zookeeper安裝與配置
- 下載安裝
- 配置啟動
- 3.2 Dubbo快速入門
- 3.2.1 Spring和SpringMVC整合
- 3.2.2 服務提供者
- 3.2.3 服務消費者
- 第四章 Dubbo高級特性
- 4.1 Dubbo-admin管理平臺
- 4.1.1 dubbo-admin安裝
- 4.1.2 dubbo-admin簡單使用
- 4.2 Dubbo常用高級配置
- 4.2.1 序列化
- 4.2.2 地址快取
- 4.2.3 超時
- 4.2.4 重試
- 4.2.5 多版本
- 4.2.6 負載均衡
- 4.2.7 集群容錯
- 4.2.8 服務降級
- Zookeeper部分
- 第一章 初識Zookeeper
- 1.1 Zookeeper概念
- 第二章 Zookeeper安裝與配置
- 第三章 Zookeeper命令操作
- 3.1 Zookeeper命令操作資料型別
- 3.2 Zookeeper命令操作服務端命令
- 3.3 Zookeeper客戶端常用命令
- 3.4 客戶端命令-創建臨時有序節點
- 第四章 ZooKeeper JavaAPI 操作
- 4.1 Curator介紹
- 4.2 基本操作(配置管理)
- 操作-建立連接
- 操作-創建節點
- 操作-查詢節點
- 操作-修改節點
- 操作-洗掉節點
- 操作-Watch監聽概述
- 監聽-NodeCache
- 監聽-PathChildrenCache
- 監聽-TreeCache
- 4.3 Zookeeper分布式鎖
- 分布式鎖概念
- 分布式鎖原理
- 分布式鎖-模擬12306售票案例
- 4.4 ZooKeeper 集群搭建
- 集群介紹
- 搭建要求
- 準備作業
- 配置集群
- 啟動集群
- 故障測驗
- Zookeeper 核心理論
- 相關注解
- @Service
- @Reference
- 儲備知識
- QoS服務
- Node.js是干嘛的
- 專案打包的作用
- 序列化和反序列化
Dubbo部分
第一章 分布式系統相關概念
1.1 大型互聯網專案架構目標
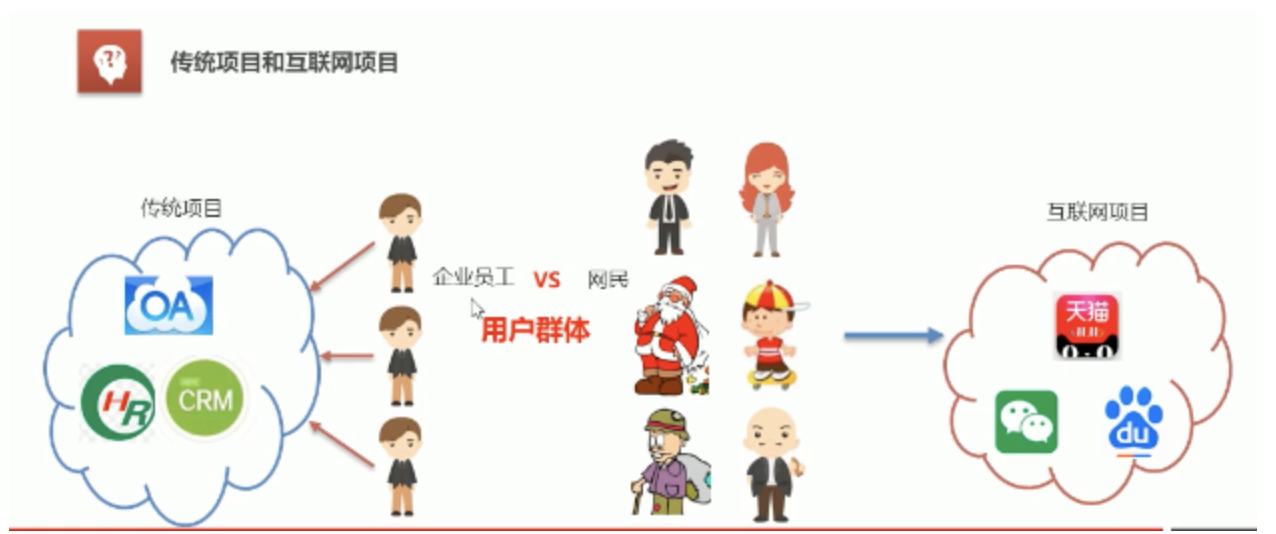
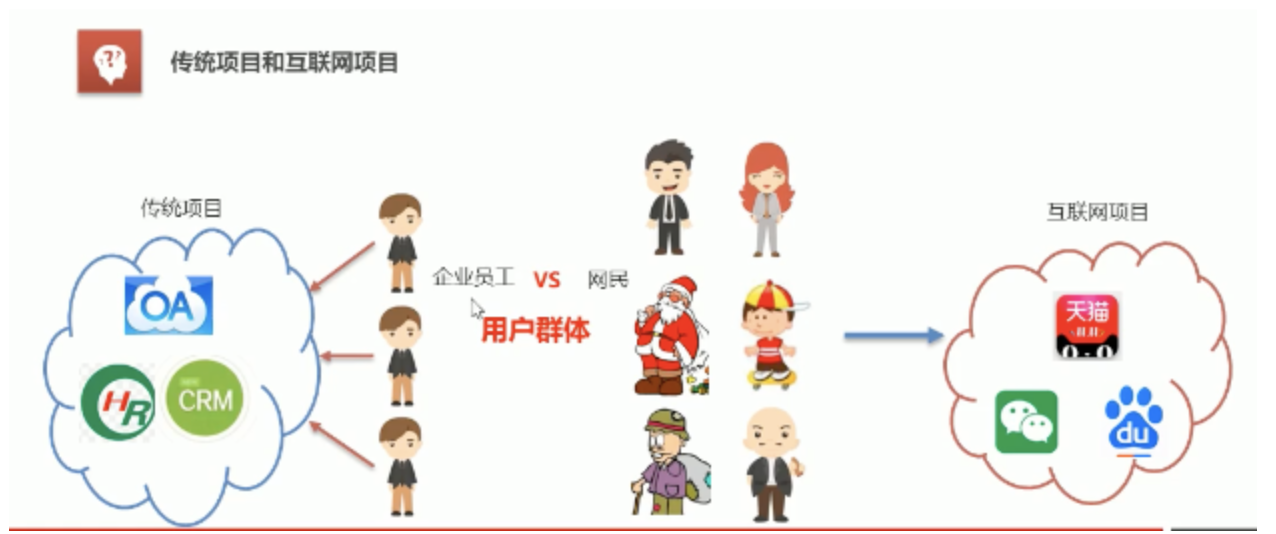
互聯網專案特點:用戶多、流量大、并發高、海量資料、易受攻擊、功能繁瑣、變更快
大型互聯網專案架構性能指標:回應時間、并發數、吞吐量
大型互聯網專案架構目標:高性能、高可用(網站一直可以正常訪問)、可伸縮(通過硬體增加/減少,提高/減低處理能力)、高可擴展(耦合低、方便通過新增/移除方式,增加/減少功能模塊)、安全性、敏捷性
1.2 集群和分布式
集群:一個業務模塊,部署在多臺服務器上,
分布式:一個大的業務系統,拆分成小的業務模塊,分別部署在不同的機器上,
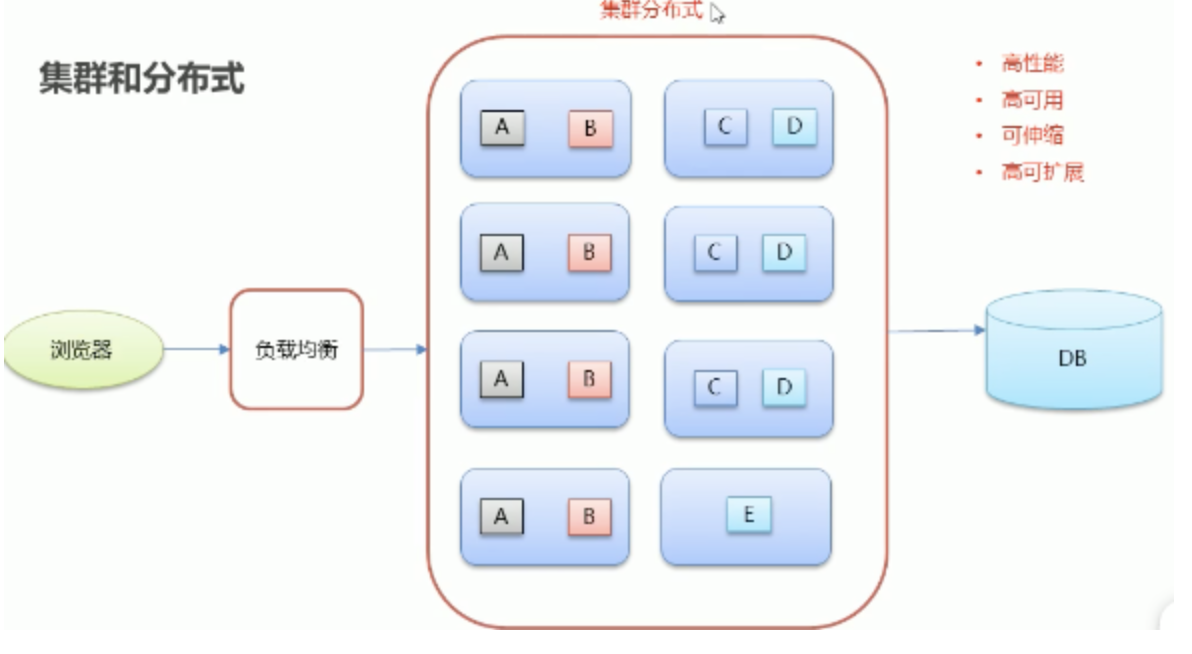
1.3 架構演進





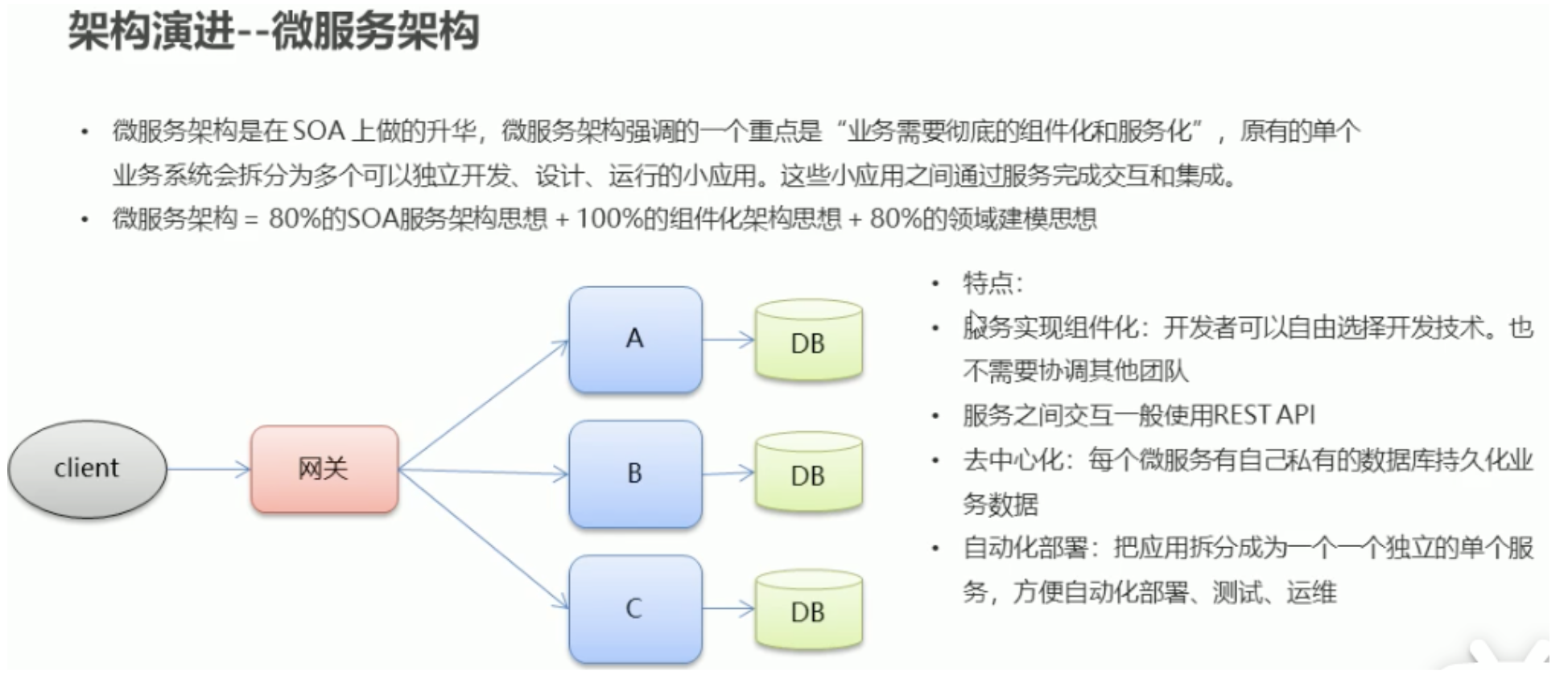
個人理解:微服務架構是對SOA架構的進一步拆分和細化
Dubbo是SOA時代的產物,SpringCloud是微服務時代的產物
第二章 Dubbo概述
2.1 Dubbo概念
- Dubbo是阿里巴巴公司開源的一個高性能、輕量級的Java RPC框架
- 致力于提供高性能和透明化的RPC遠程服務呼叫方案,以及SOA服務治理方案,
- 官網:http://dubbo.apache.org
2.2 Dubbo架構
2.2.1 Dubbo架構及呼叫順序
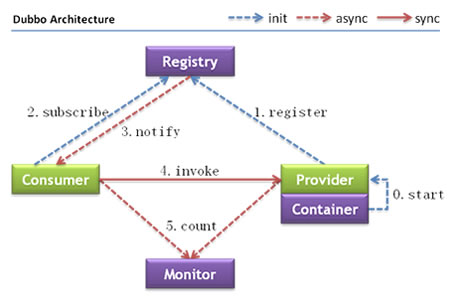
節點角色說明
| 節點 | 角色說明 |
|---|---|
Provider | 暴露服務的服務提供方 |
Consumer | 呼叫遠程服務的服務消費方 |
Registry | 服務注冊與發現的注冊中心 |
Monitor | 統計服務的呼叫次數和呼叫時間的監控中心 |
Container | 服務運行容器 |
呼叫關系說明參考檔案
- 服務容器負責啟動,加載,運行服務提供者,
- 服務提供者在啟動時,向注冊中心注冊自己提供的服務,
- 服務消費者在啟動時,向注冊中心訂閱自己所需的服務,
- 注冊中心回傳服務提供者地址串列給消費者,如果有變更,注冊中心將基于長連接推送變更資料給消費者,
- 服務消費者,從提供者地址串列中,基于軟負載均衡演算法,選一臺提供者進行呼叫,如果呼叫失敗,再選另一臺呼叫,
- 服務消費者和提供者,在記憶體中累計呼叫次數和呼叫時間,定時每分鐘發送一次統計資料到監控中心,
Dubbo 架構具有以下幾個特點,分別是連通性、健壯性、伸縮性、以及向未來架構的升級性
個人理解:Registry就相當于ESB,Consumer和Provider通過其連接
2.2.2 Dubbo特點
連通性
- 注冊中心負責服務地址的注冊與查找,相當于目錄服務,服務提供者和消費者只在啟動時與注冊中心互動,注冊中心不轉發請求,壓力較小
- 監控中心負責統計各服務呼叫次數,呼叫時間等,統計先在記憶體匯總后每分鐘一次發送到監控中心服務器,并以報表展示
- 服務提供者向注冊中心注冊其提供的服務,并匯報呼叫時間到監控中心,此時間不包含網路開銷
- 服務消費者向注冊中心獲取服務提供者地址串列,并根據負載演算法直接呼叫提供者,同時匯報呼叫時間到監控中心,此時間包含網路開銷
- 注冊中心,服務提供者,服務消費者三者之間均為長連接,監控中心除外
- 注冊中心通過長連接感知服務提供者的存在,服務提供者宕機,注冊中心將立即推送事件通知消費者
- 注冊中心和監控中心全部宕機,不影響已運行的提供者和消費者,消費者在本地快取了提供者串列
- 注冊中心和監控中心都是可選的,服務消費者可以直連服務提供者
健壯性
- 監控中心宕掉不影響使用,只是丟失部分采樣資料
- 資料庫宕掉后,注冊中心仍能通過快取提供服務串列查詢,但不能注冊新服務
- 注冊中心對等集群,任意一臺宕掉后,將自動切換到另一臺
- 注冊中心全部宕掉后,服務提供者和服務消費者仍能通過本地快取通訊
- 服務提供者無狀態,任意一臺宕掉后,不影響使用
- 服務提供者全部宕掉后,服務消費者應用將無法使用,并無限次重連等待服務提供者恢復
伸縮性
- 注冊中心為對等集群,可動態增加機器部署實體,所有客戶端將自動發現新的注冊中心
- 服務提供者無狀態,可動態增加機器部署實體,注冊中心將推送新的服務提供者資訊給消費者
升級性
當服務集群規模進一步擴大,帶動IT治理結構進一步升級,需要實作動態部署,進行流動計算,現有分布式服務架構不會帶來阻力,下圖是未來可能的一種架構:
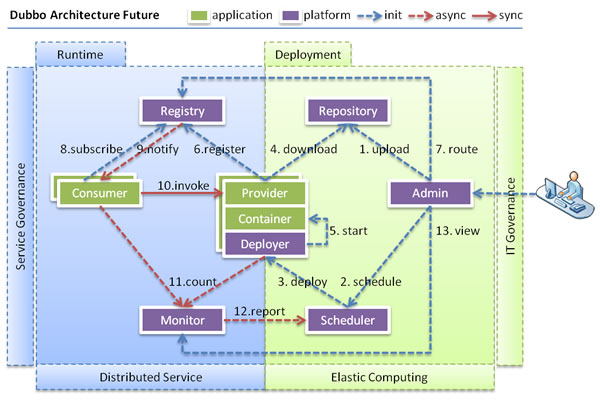
節點角色說明
| 節點 | 角色說明 |
|---|---|
Deployer | 自動部署服務的本地代理 |
Repository | 倉庫用于存盤服務應用發布包 |
Scheduler | 調度中心基于訪問壓力自動增減服務提供者 |
Admin | 統一管理控制臺 |
Registry | 服務注冊與發現的注冊中心 |
Monitor | 統計服務的呼叫次數和呼叫時間的監控中心 |
第三章 Dubbo快速入門
3.1 Zookeeper
3.1.1 Zookeeper概述
注冊中心:https://dubbo.apache.org/zh/docs/v2.7/user/references/registry/
Zookeeper是Apache Hadoop的子專案,是一個樹形的目錄服務,適合作為Dubbo服務的注冊中心,工業強度較高,可用于生產環境,并推薦使用,
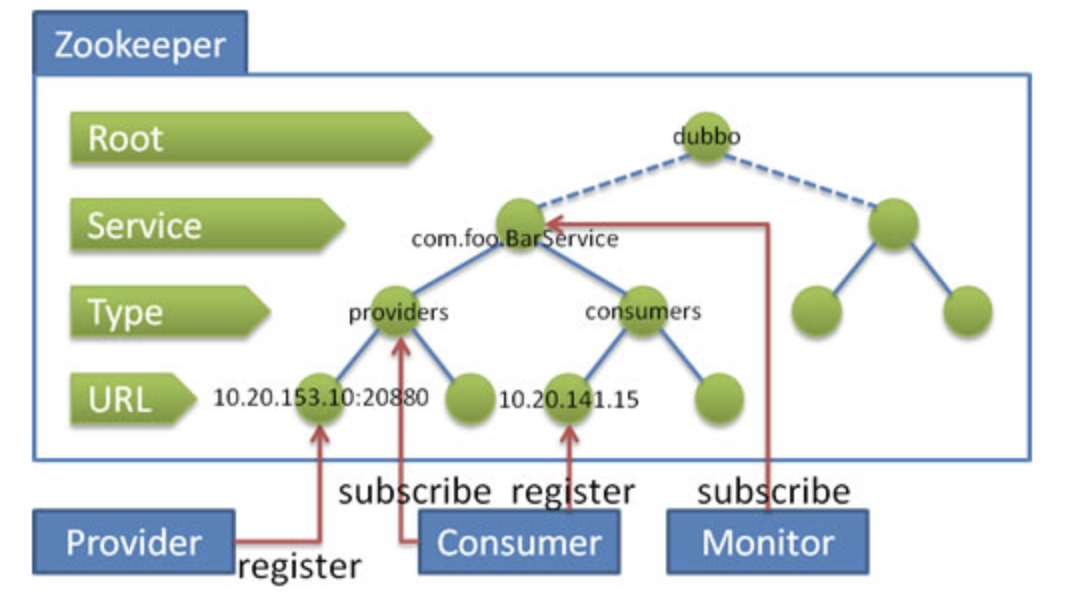
更詳細概述,見我的HSF筆記
3.1.2 Zookeeper安裝與配置
下載安裝
1、環境準備:Java1.7+
2、上傳:將下載的ZooKeeper放到/opt/ZooKeeper目錄下
#上傳zookeeper alt+p
put f:/setup/apache-zookeeper-3.5.6-bin.tar.gz
#打開 opt目錄
cd /opt
#創建zooKeeper目錄
mkdir zooKeeper
#將zookeeper安裝包移動到 /opt/zooKeeper
mv apache-zookeeper-3.5.6-bin.tar.gz /opt/zookeeper/
3、解壓:將tar包解壓到/opt/zookeeper目錄下
tar -zxvf apache-ZooKeeper-3.5.6-bin.tar.gz
配置啟動
1、配置zoo.cfg
進入conf目錄拷貝一個zoo_sample.cfg并完成配置(zoo_sample本質上不起配置作用,只是一個模板,需要自行創建zoo.cfg并修改配置內容,)
#進入到conf目錄
cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/conf/
#拷貝(將zoo_sample.cfg拷貝一份,名字是zoo.cfg)
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg
#打開目錄
cd /opt/zooKeeper/
#創建zooKeeper存盤目錄
mkdir zkdata
#修改zoo.cfg
vim /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/conf/zoo.cfg
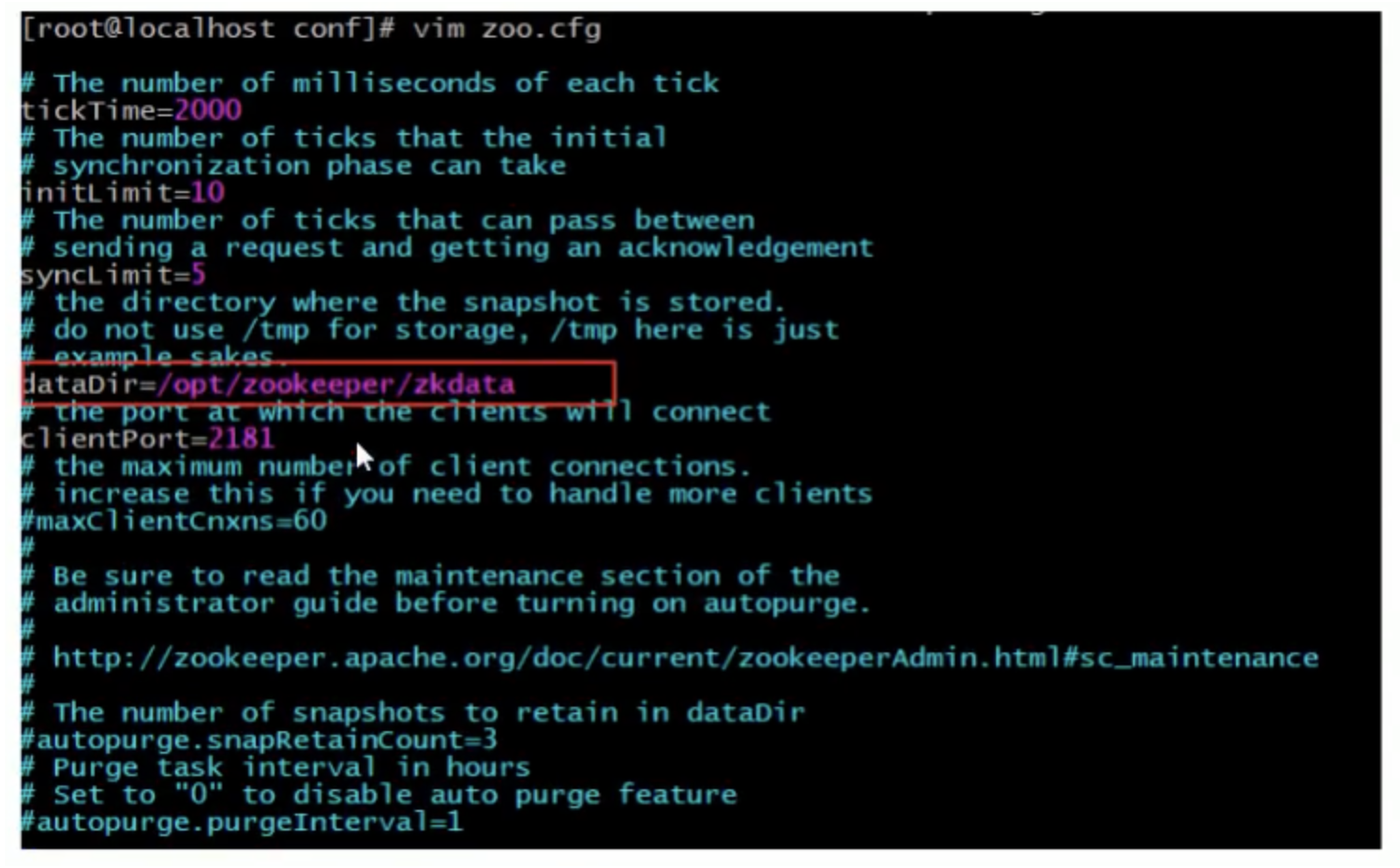
修改存盤目錄:dataDir = /opt/zookeeper/zkdata
2、啟動zookeeper
cd /opt/zooKeeper/apache-zooKeeper-3.5.6-bin/bin/
#啟動(.sh檔案一般為腳本執行檔案,zkServer是注冊中心的意思)
./zkServer.sh start

看到上圖表示zookeeper已經成功啟動,
3、查看zookeeper狀態
./zkServer.sh status
zookeeper啟動成功,standalone代表zk沒有搭建集群,現在是單節點

zookeeper沒有啟動成功

3.2 Dubbo快速入門
3.2.1 Spring和SpringMVC整合
代碼:1. spring和springmvc整合后代碼
實施步驟:
1、創建服務提供者Provider模塊
2、創建服務消費者Consumer模塊
3、在服務提供者模塊撰寫UserServiceImpl提供服務
4、在服務消費者中的UserController遠程呼叫(提供者是Service,消費者是Controller)
5、UserServiceImpl提供的服務
6、分別啟動兩服務,測驗,
Dubbo作為一個RPC框架,其最核心的功能就是要實作跨網路的遠程呼叫,本小節就是要創建兩個應用,一個作為服務的提供方,一個作為服務的消費方,通過Dubbo來實作服務消費方遠程呼叫服務提供方的方法,
0、創建專案、準備環境
首先創建空專案
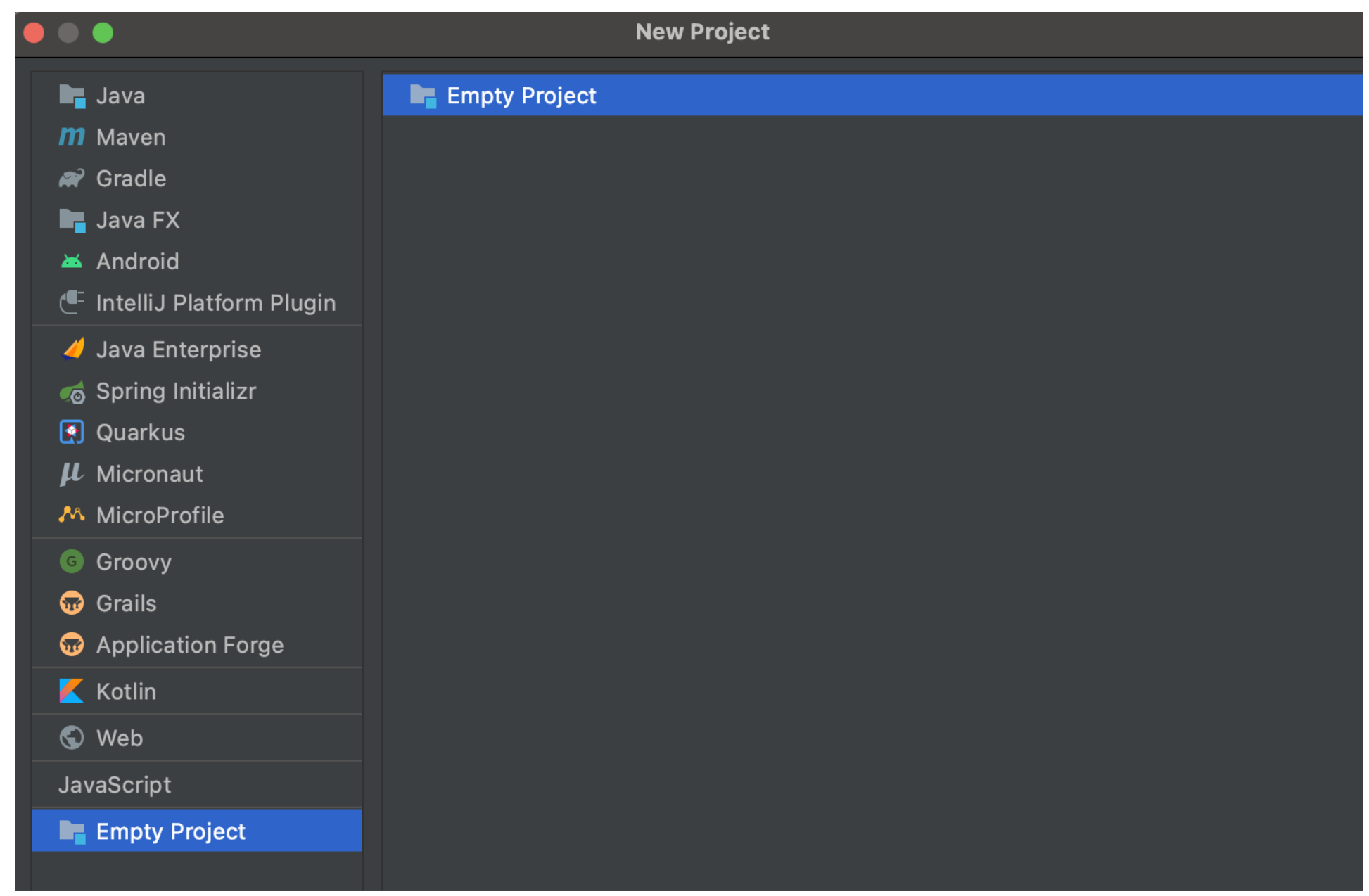
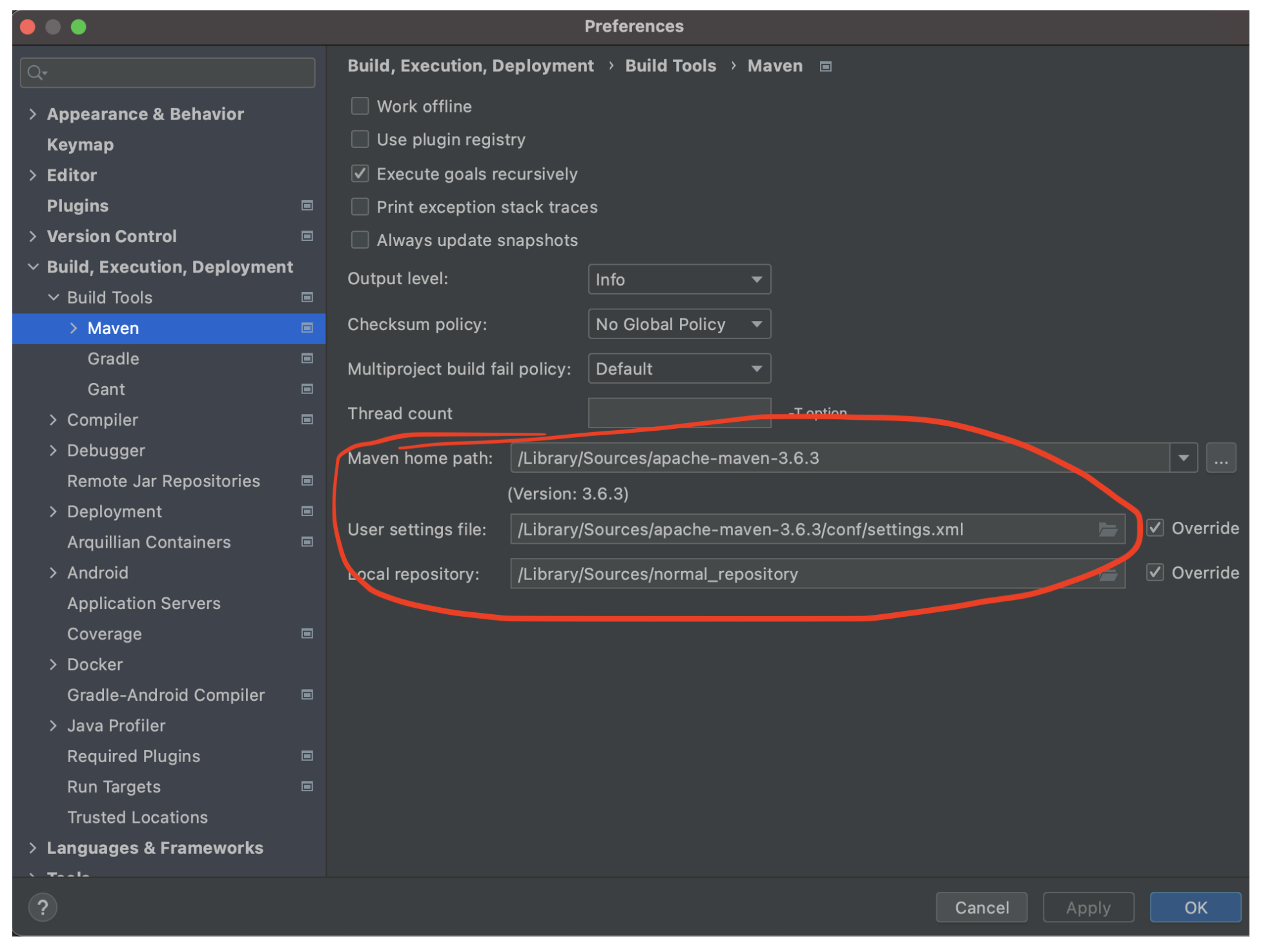
接下來配置Maven地址
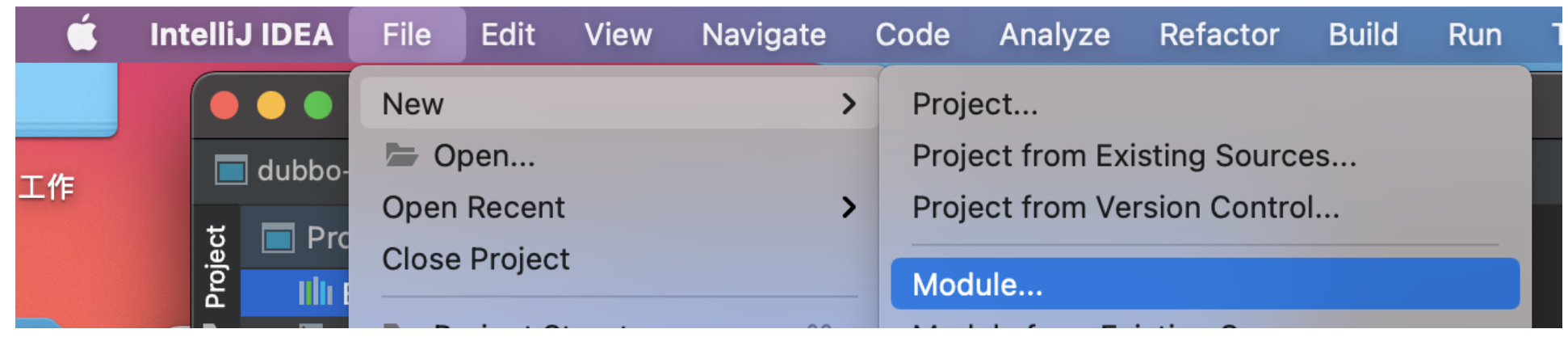
接下來創建Maven的Module
新建服務方:
新建消費方:
接下來就是撰寫邏輯代碼了,
核心原理:consumer中的pom.xml中添加了servicer的pom依賴,本質上并沒有用到dubbo
3.2.2 服務提供者
代碼見:2. dubbo快速入門
dubbo的作用:
服務提供者撰寫程序:
1、將Servicer的服務注冊到Zookeeper中(注冊中心)
2、在mvc的xml中撰寫dubbo的配置,包括配置項 目的名稱(唯一標識),配置注冊中心(zookeeper)的地址,配置dubbo包掃描的路徑
3、配置web.xml
3.2.3 服務消費者
服務消費者撰寫程序:
1、在Controller中遠程注入userService,即獲取其url(拋棄Autowired注解,使用Reference注解)
2、在mvc的xml中撰寫dubbo的配置,包括配置專案的名稱(唯一標識),配置注冊中心的地址(本機ip+埠),配置dubbo包掃描的路徑
3、配置web.xml
服務方和消費方都遵循上述配置,不同的是消費方配置的是Controller,并且不用放到注冊中心
**注意:當消費者呼叫提供者的Service方法時,消費者中也要定義相對應的Service類的介面,因此為了去冗余設計,新定義一個interface的module,來做代碼提取,**至于如何呼叫,直接在Servicer和Consumer的pom.xml中定義即可,
以上,完成了最最最最簡單的Dubbo的功能實作,
第四章 Dubbo高級特性
4.1 Dubbo-admin管理平臺
簡介:
- dubbo-admin管理平臺,是圖形化的服務管理頁面
- 從注冊中心獲取到所有提供者/消費者進行配置管理
- 路由規則、動態配置、服務降級、訪問控制、權重調整、負載均衡等管理功能
- dubbo-admin是一個前后端分離的專案,前端使用vue,后端使用springboot
- 安裝dubbo-admin其實就是部署該專案
4.1.1 dubbo-admin安裝
1、環境準備
dubbo-admin 是一個前后端分離的專案,前端使用vue,后端使用springboot,安裝 dubbo-admin 其實就是部署該專案,我們將dubbo-admin安裝到開發環境上,要保證開發環境有jdk,maven,nodejs
安裝node**(如果當前機器已經安裝請忽略)**
因為前端工程是用vue開發的,所以需要安裝node.js,node.js中自帶了npm,后面我們會通過npm啟動
把node.js理解成更牛逼的tomcat就行
下載地址
https://nodejs.org/en/
2、下載 Dubbo-Admin
進入github,搜索dubbo-admin
https://github.com/apache/dubbo-admin
下載:
3、把下載的zip包解壓到指定檔案夾(解壓到那個檔案夾隨意)
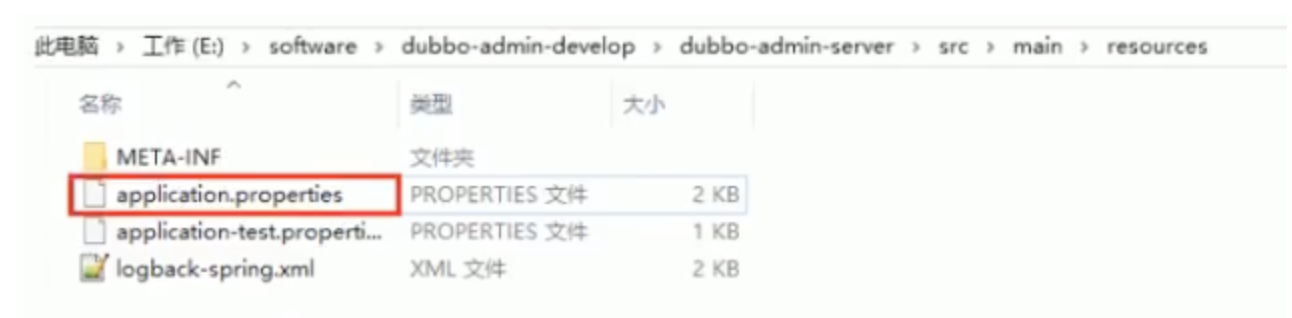
4、修改組態檔
解壓后我們進入…\dubbo-admin-develop\dubbo-admin-server\src\main\resources目錄,找到 application.properties 組態檔 進行配置修改
修改zookeeper地址

# centers in dubbo2.7
admin.registry.address=zookeeper://192.168.149.135:2181
admin.config-center=zookeeper://192.168.149.135:2181
admin.metadata-report.address=zookeeper://192.168.149.135:2181
admin.registry.address注冊中心(服務資訊的中介(非持久化))
admin.config-center 配置中心(存盤 Dubbo 服務的各種治理規則(持久化))
admin.metadata-report.address元資料中心(元資料是指 Dubbo服務對應的方法串列以及引數結構等資訊)
5、打包專案
在 dubbo-admin-develop 目錄執行打包命令
mvn clean package

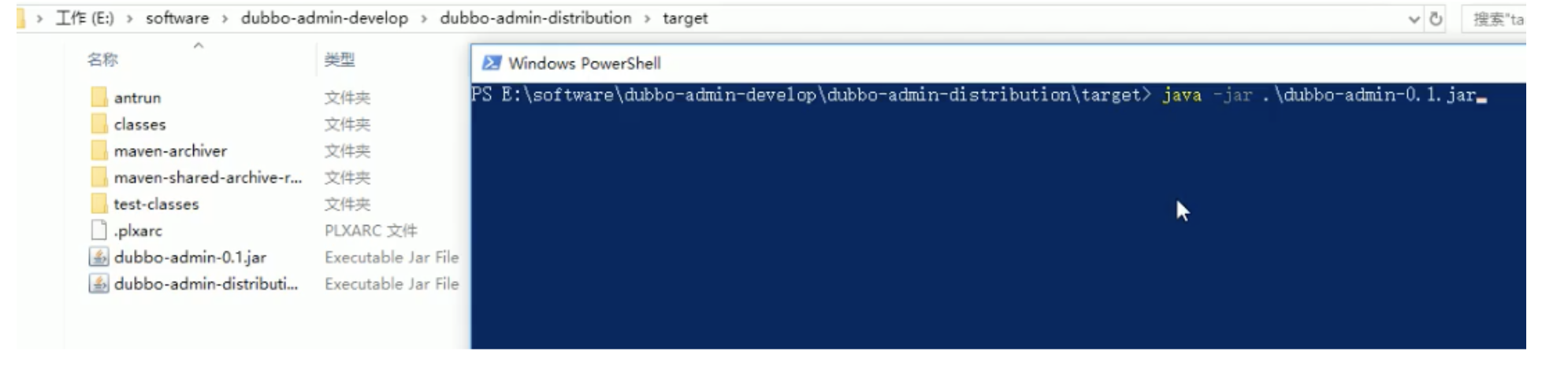
6、啟動后端
切換到目錄
dubbo-Admin-develop\dubbo-admin-distribution\target>
執行下面的命令啟動 dubbo-admin,dubbo-admin后臺由SpringBoot構建,
java -jar .\dubbo-admin-0.1.jar
7、前臺后端
dubbo-admin-ui 目錄下執行命令
npm run dev

8、訪問
瀏覽器輸入,用戶名密碼都是root
http://localhost:8081/
4.1.2 dubbo-admin簡單使用
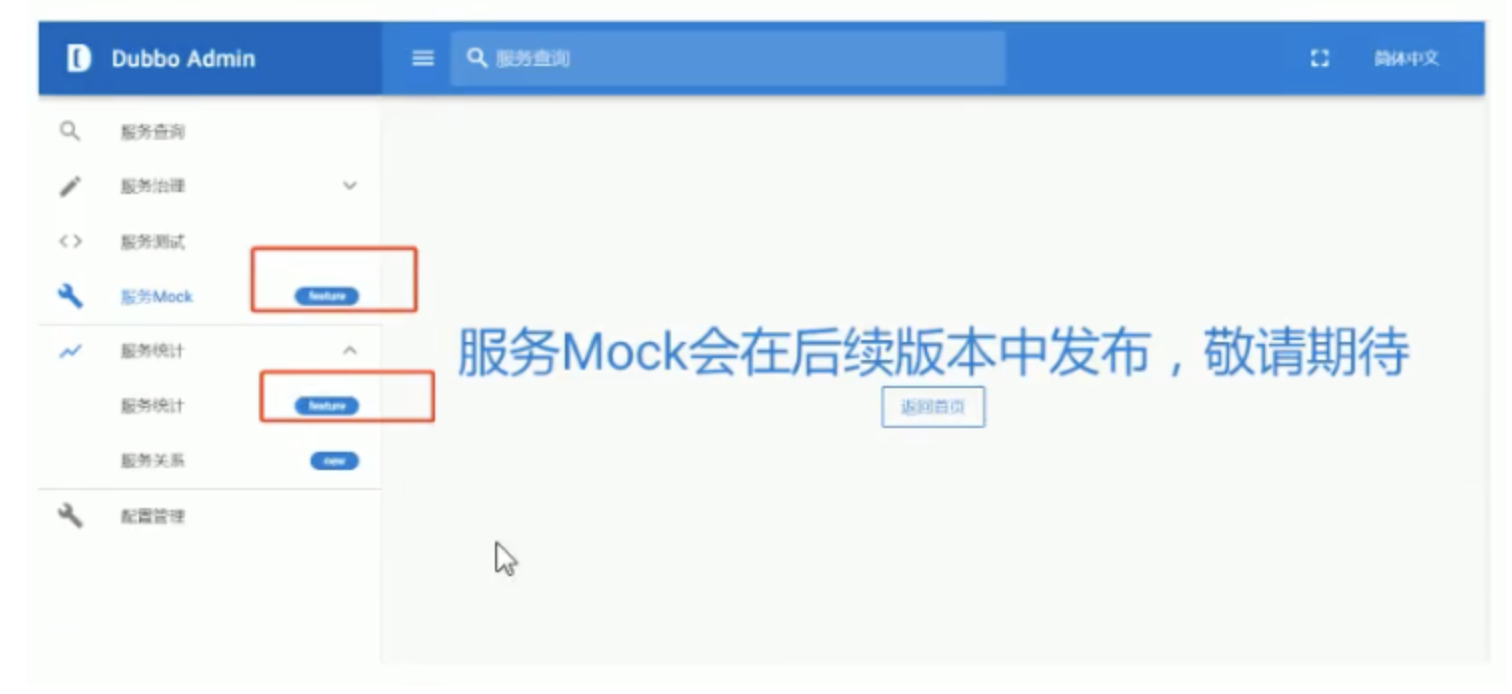
注意:Dubbo Admin【服務Mock】【服務統計】將在后續版本發布…
在上面的步驟中,我們已經進入了Dubbo-Admin的主界面,在【快速入門】章節中,我們定義了服務生產者、和服務消費者,下面我們從Dubbo-Admin管理界面找到這個兩個服務
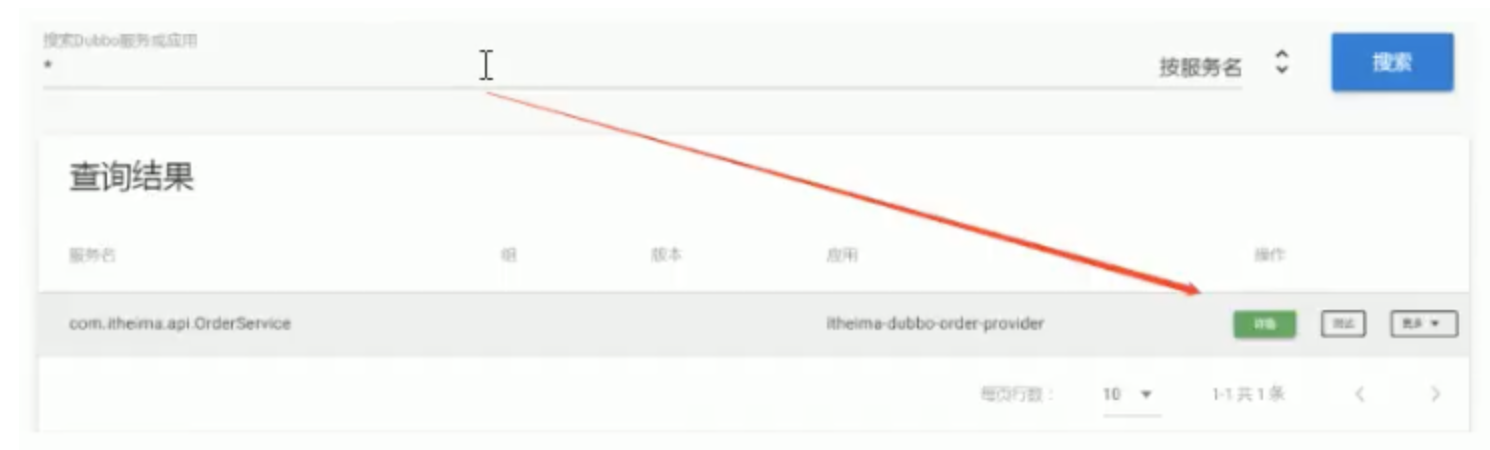
1、點擊服務查詢
2、查詢結果
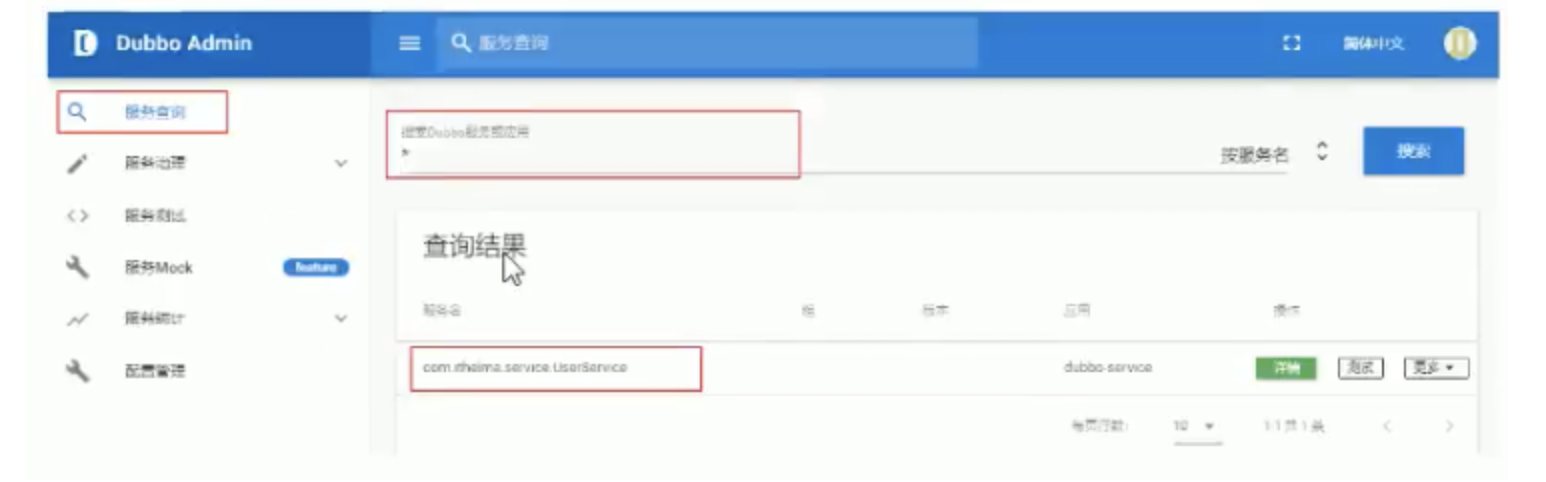
A:輸入的查詢條件com.itheima.service.UserService
B:搜索型別,主要分為【按服務名】【按IP地址】【按應用】三種型別查詢
C:搜索結果
3.1.4 dubo-admin查看詳情
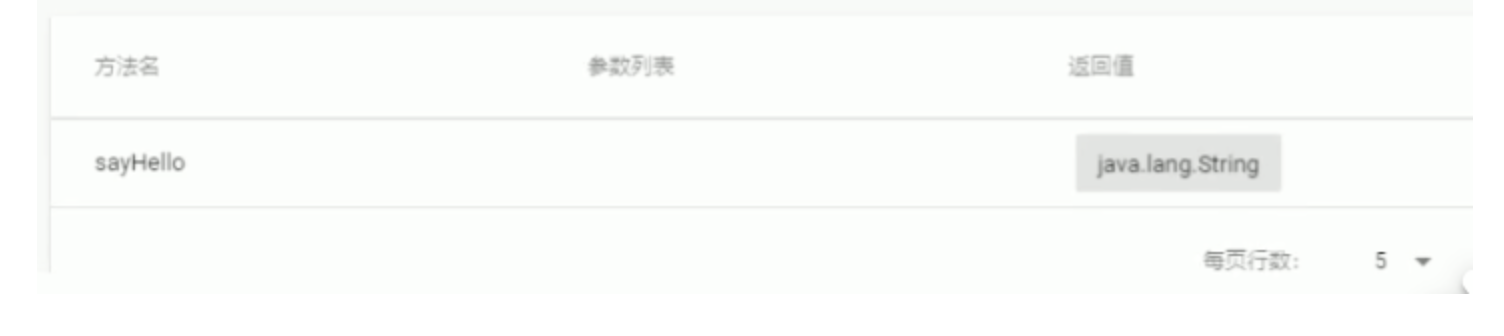
我們查看com.itheima.service.UserService (服務提供者)的具體詳細資訊,包含【元資料資訊】
1)點擊詳情
從【詳情】界面查看,主要分為3個區域
A區域:主要包含服務端 基礎資訊比如服務名稱、應用名稱等
B區域:主要包含了生產者、消費者一些基本資訊
C區域:是元資料資訊,注意看上面的圖,元資料資訊是空的
我們需要打開我們的生產者組態檔加入下面配置
<!-- 元資料配置 -->
<dubbo:metadata-report address="zookeeper://192.168.149.135:2181" />
重新啟動生產者,再次打開Dubbo-Admin
這樣我們的元資料資訊就出來了
4.2 Dubbo常用高級配置
4.2.1 序列化
注意!!!將來所有的pojo類都需要實作Serializable介面!
代碼實作見:3. dubbo高級特性-序列化
兩臺機器之間傳輸資料,通過序列化和反序列化傳輸Java物件
- dubbo 內部已經將序列化和反序列化的程序內部封裝了
- 我們只需要在定義pojo類時實作Serializable介面即可
- 一般會定義一 個公共的pojo模塊,讓生產者和消費者都依賴該模塊,
User物件未實作Serializable介面
錯誤資訊:
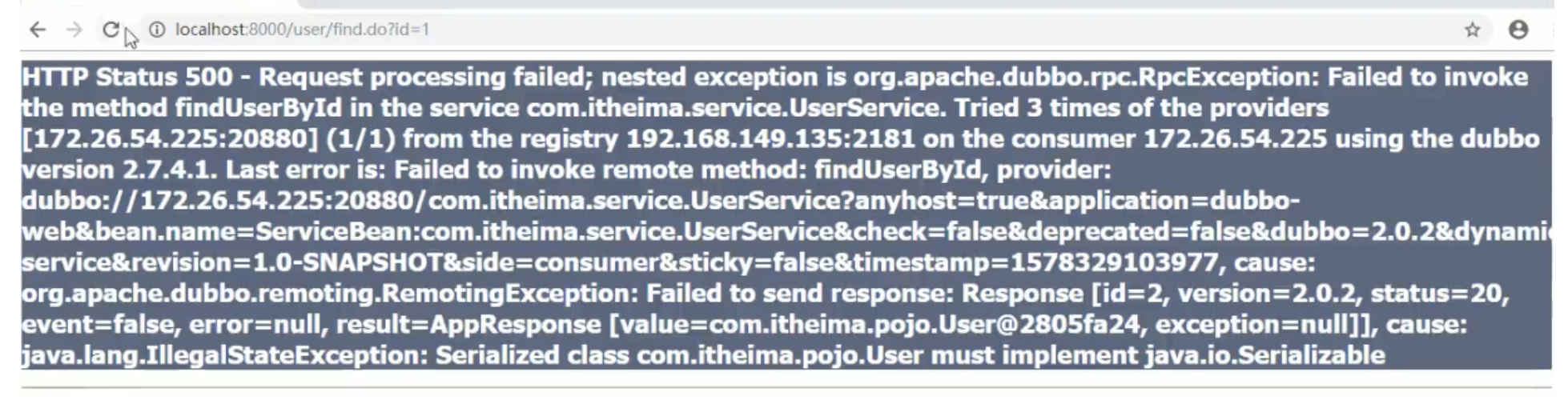
解決辦法:
User implements Serializable
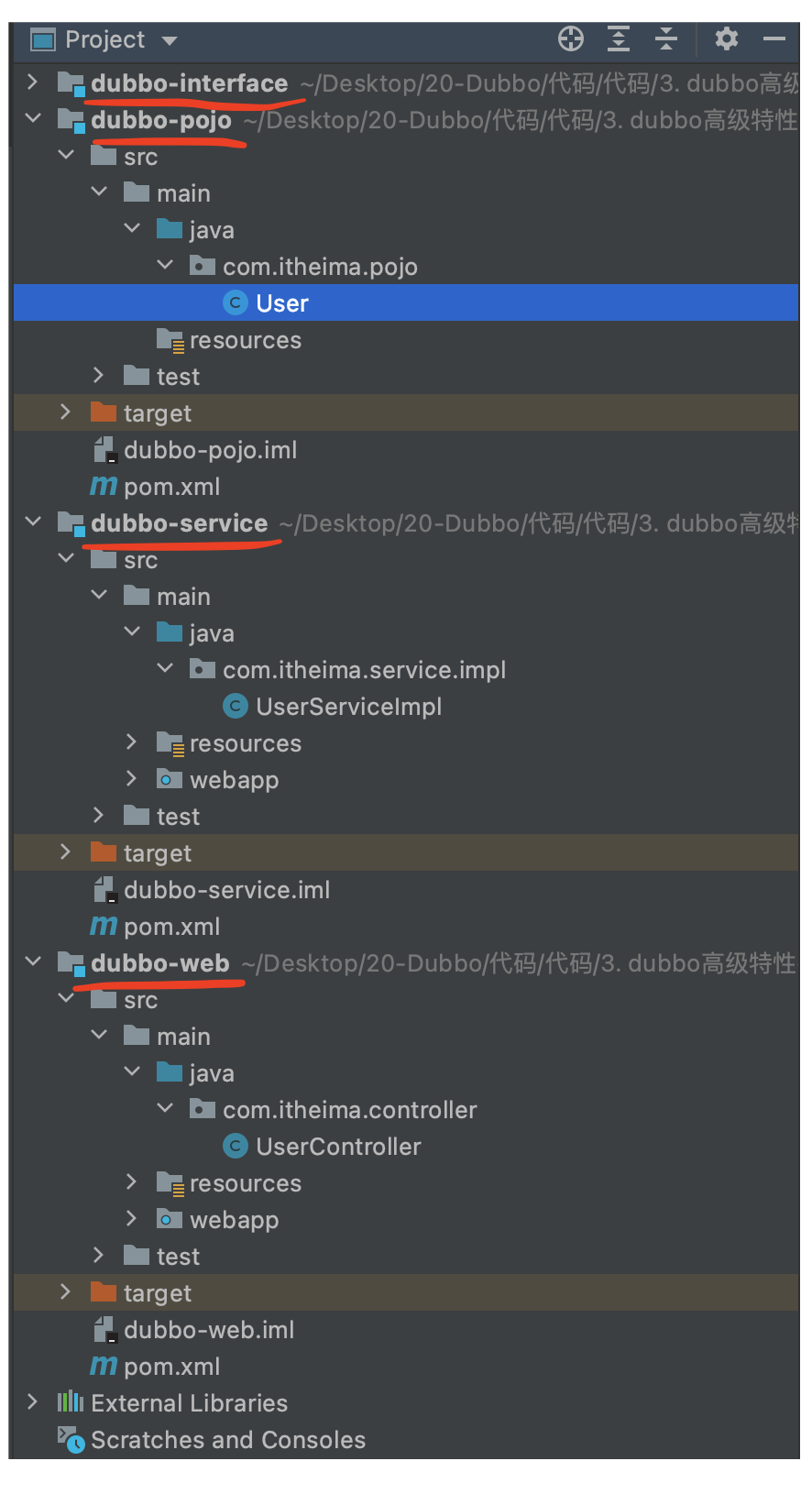
下圖為專案的基礎架構圖:
- interface的pom中寫入pojo的依賴,service和web的pom中寫入interface的依賴,
- User繼承了序列化介面
4.2.2 地址快取
注冊中心掛了,服務是否可以正常訪問?
- 可以,因為dubbo服務消費者在第一-次呼叫時,會將服務提供方地址快取到本地,以后在呼叫則不會訪問注冊中心,
- 當服務提供者地址發生變化時,注冊中心會通知服務消費者,

運行后,發現還是可以繼續訪問的,

4.2.3 超時
參考代碼:4. 超時與重試
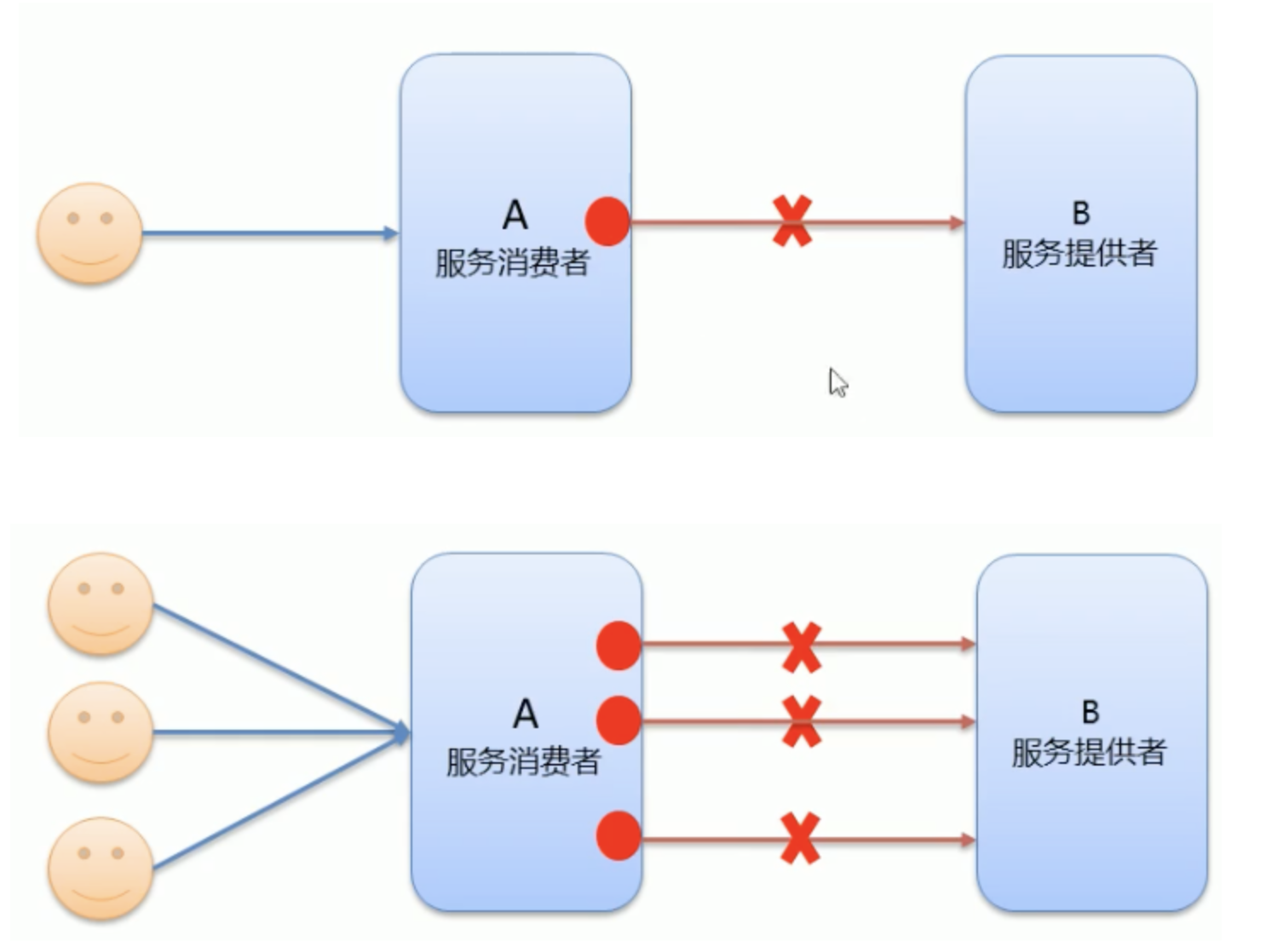
- 服務消費者在呼叫服務提供者的時候發生了阻塞、等待的情形,這個時候,服務消費者會直等待下去,
- 在某個峰值時刻,大量的請求都在同時請求服務消費者,會造成執行緒的大量堆積,勢必會造成雪崩,
- dubbo利用超時機制來解決這個問題,設定-個超時時間, 在這個時間段內,無法完成服務訪問,則自動斷開連接,
- 使用timeout屬性配置超時時間,默認值1000,單位毫秒
//timeout 超時時間 單位毫秒 retries 重試次數
@Service(timeout = 3000,retries=0)
代碼實作:用sleep模擬服務器查詢很慢:
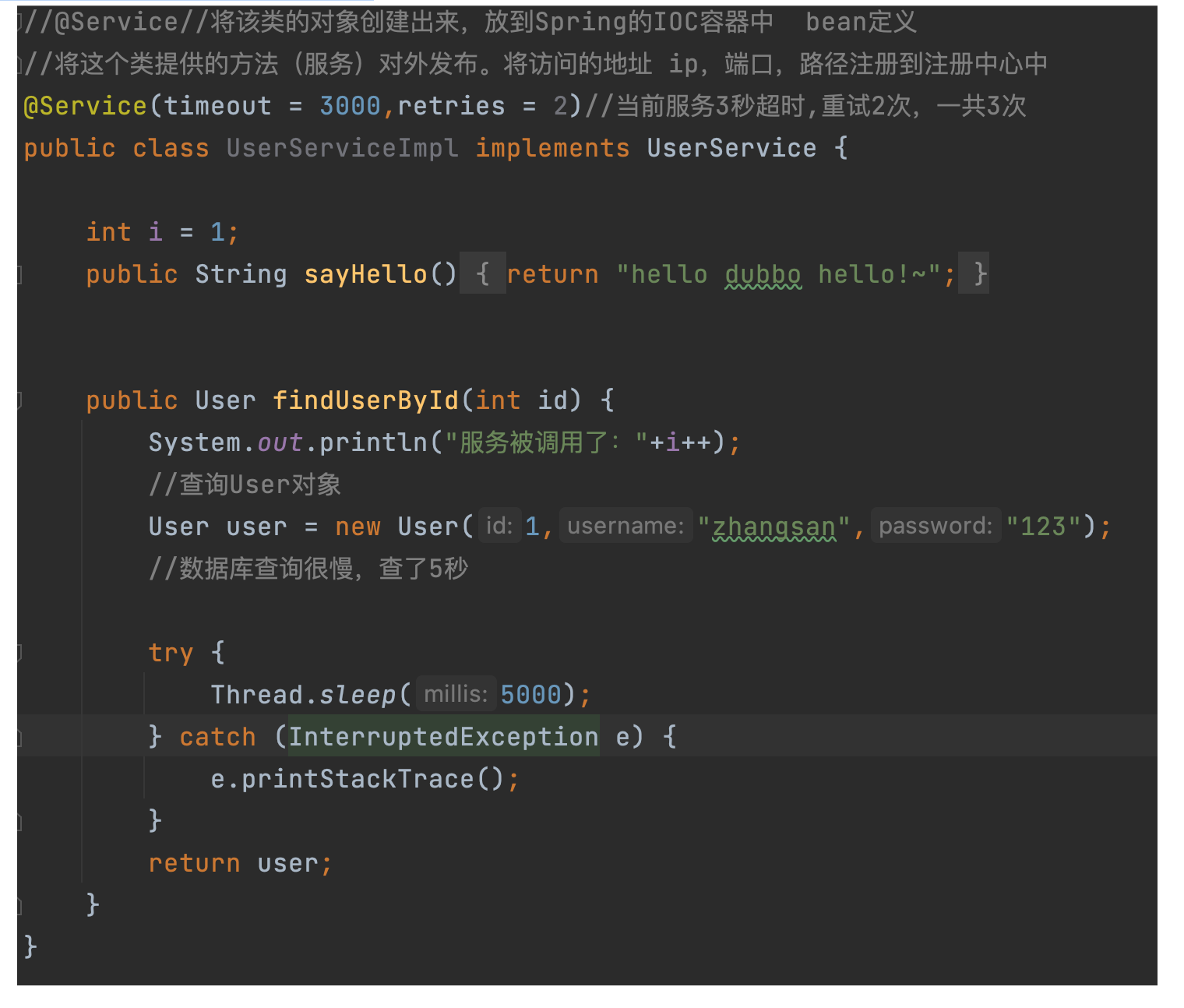
4.2.4 重試
- 設定了超時時間,在這個時間段內,無法完成服務訪問,則自動斷開連接,
- 如果出現網路抖動,則這一-次請求就會失敗,
- Dubbo提供重試機制來避免類似問題的發生,
- 通過retries屬性來設定重試次數,默認為2次
//timeout 超時時間 單位毫秒 retries 重試次數
@Service(timeout = 3000,retries=2)
4.2.5 多版本
參考代碼:5. 多版本
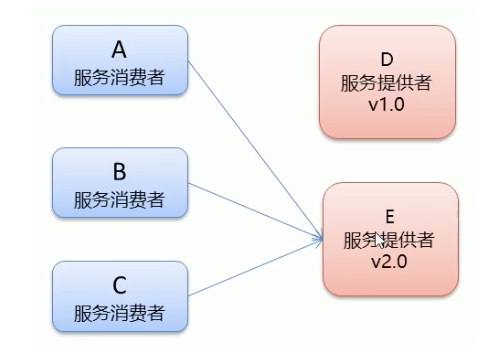
**灰度發布:**當出現新功能時,會讓一部分用戶先使用新功能,用戶反饋沒問題時,再將所有用戶遷移到新功能,
dubbo中使用version屬性來設定和呼叫同一個介面的不同版本
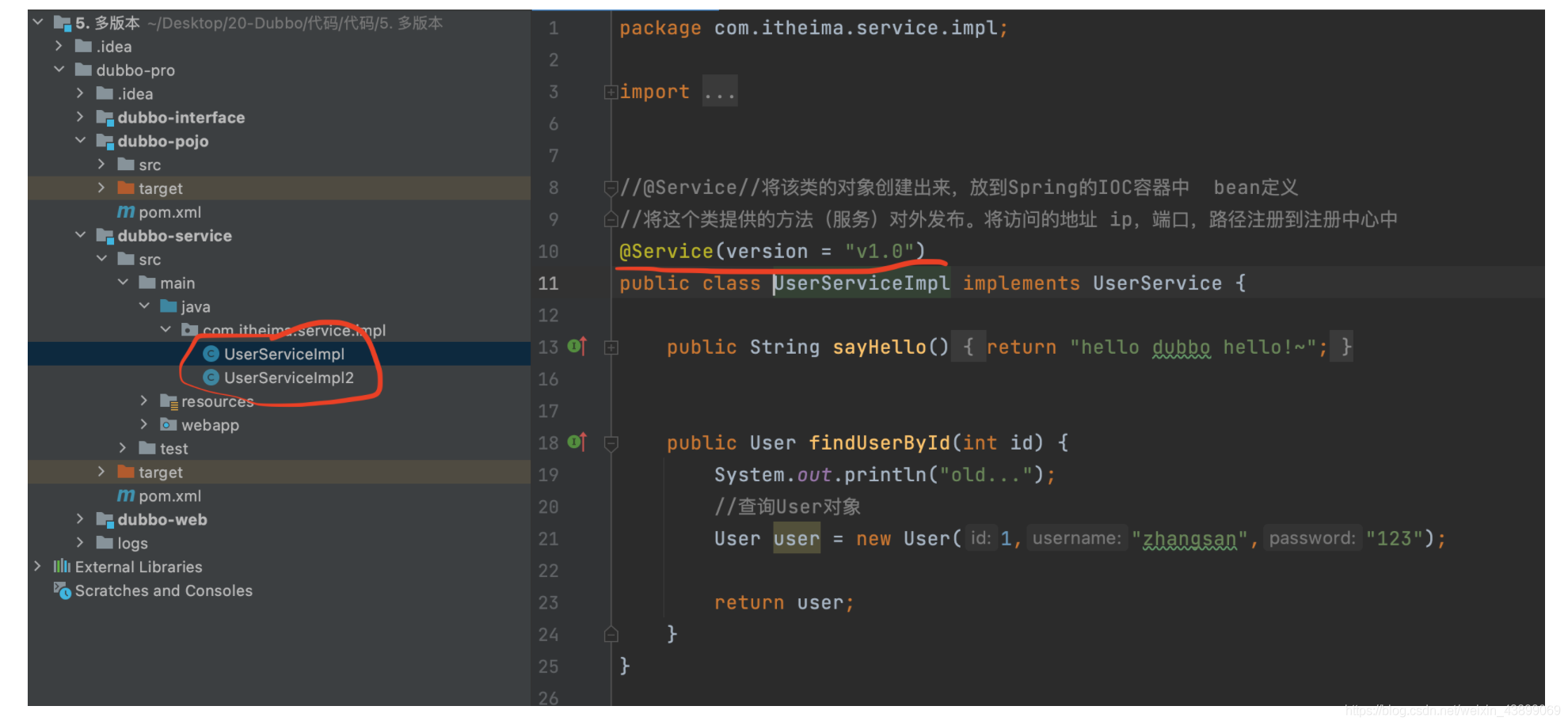
生產者配置(通過@Service注解)
@Service(version="v2.0")
public class UserServiceImp12 implements UserService {...}
消費者配置(通過@Reference注解)
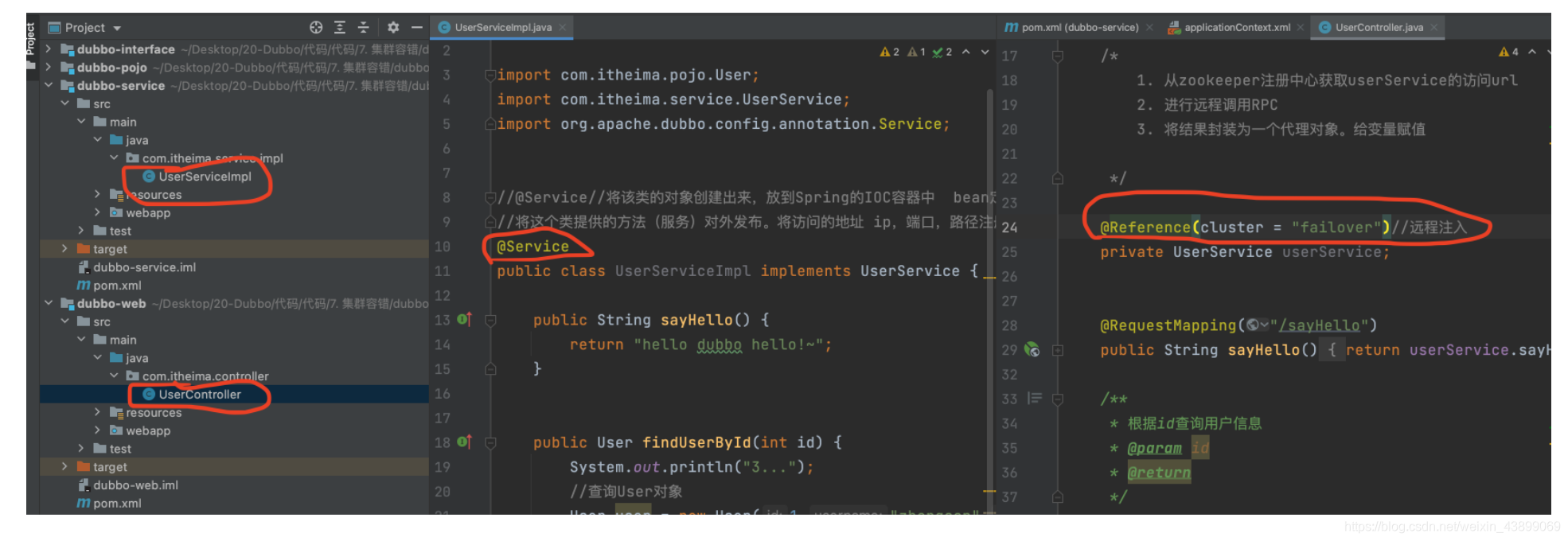
@Reference(version = "v2.0")//遠程注入
private UserService userService;
代碼示例:
4.2.6 負載均衡
解釋:當存在多個服務提供者時,消費者應該怎樣消費,才能使多個服務提供者的負載均衡,
負載均衡策略(4種) :
-
**Random:**按權重隨機,默認值,按權重設定隨機概率,
-
RoundRobin: 按權重輪詢,
-
LeastActive: 最少活躍呼叫數,相同活躍數的隨機,
-
**ConsistentHash: **一致性Hash,相同引數的請求總是發到同一提供者,
服務提供者配置
@Service(weight = 100)
public class UserServiceImp12 implements UserService {...}
application.xml 配置parameter key
消費者配置
//@Reference(loadbalance = "roundrobin")
//@Reference(loadbalance = "leastactive")
//@Reference(loadbalance = "consistenthash")
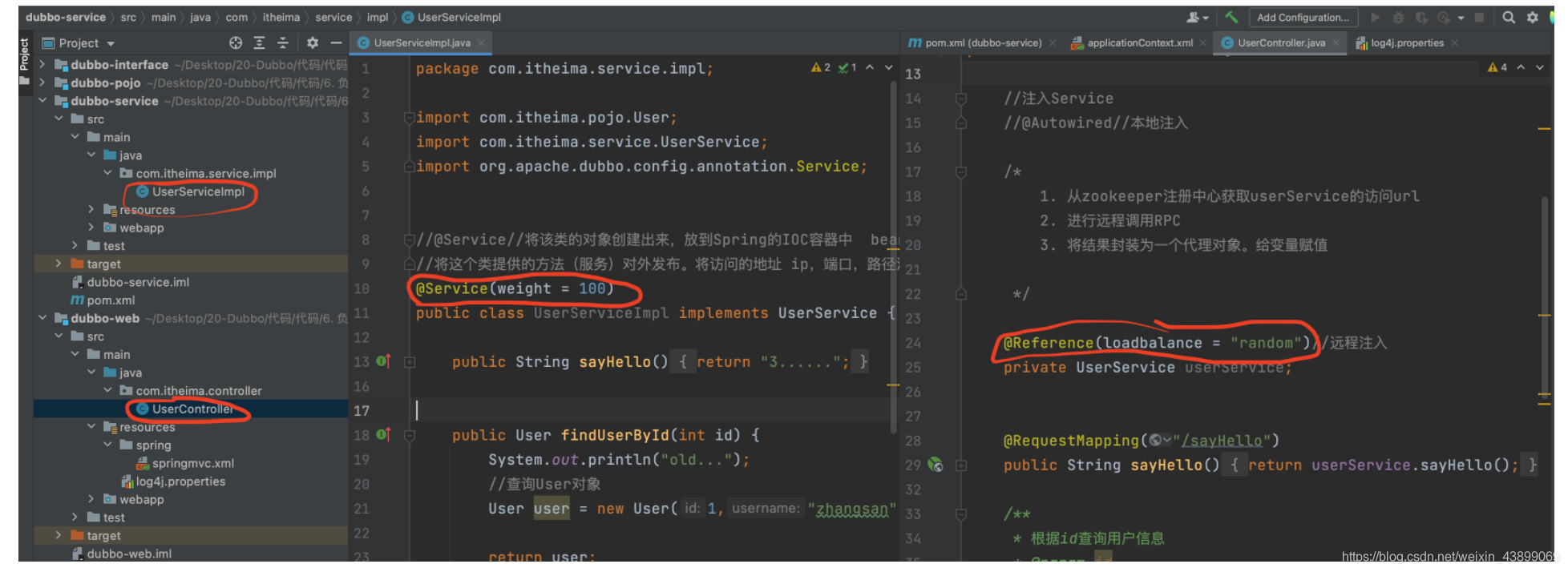
@Reference(loadbalance = "random")//默認 按權重隨機
private UserService userService;
代碼參考:
4.2.7 集群容錯
解釋:如果某一個服務器出錯了,則選擇執行什么策略,是換其他服務器重試,還是直接回傳失敗等等,
集群容錯模式:
**Failover Cluster:**失敗重試,默認值,當出現失敗,重試其它服務器,默認重試2次,使用retries配置,一般用于讀操作
**Failfast Cluster 😗*快速失敗,發起-次呼叫,失敗立即報錯,通常用于寫操作,
**Failsafe Cluster:**失敗安全,出現例外時,直接忽略,回傳一個空結果,
**Failback Cluster:**失敗自動恢復,后臺記錄失敗請求,定時重發,
**Forking Cluster 😗*并行呼叫多個服務器,只要一個成功即回傳,
Broadcast Cluster: 廣播呼叫所有提供者,逐個呼叫,任意一臺報錯則報錯,
消費者配置
@Reference(cluster = "failover")//遠程注入
private UserService userService;
代碼示例:
4.2.8 服務降級
服務降級:當服務器壓力劇增的情況下,根據實際業務情況及流量,對一些服務和頁面有策略的不處理或換種簡單的方式處理,從而釋放服務器資源以保證核心交易正常運作或高效運作
服務降級方式:
mock= force:return null:表示消費方對該服務的方法呼叫都直接回傳null值,不發起遠程呼叫,用來屏蔽不重要服務不可用時對呼叫方的影響,
mock=fail:return null:表示消費方對該服務的方法呼叫在失敗后,再回傳null值,不拋例外,用來容忍不重要服務不穩定時對呼叫方的影響
消費方配置
//遠程注入
@Reference(mock ="force :return null")//不再呼叫userService的服務
private UserService userService;
Zookeeper部分
第一章 初識Zookeeper
1.1 Zookeeper概念
-
Zookeeper 是 Apache Hadoop 專案下的一個子專案,是一個樹形目錄服務,
-
Zookeeper 翻譯過來就是 動物園管理員,他是用來管 Hadoop(大象)、Hive(蜜蜂)、Pig(小 豬)的管理員,簡稱zk
-
Zookeeper 是一個分布式的、開源的分布式應用程式的協調服務,
-
Zookeeper提供的功能主要包括
- 配置管理(增刪改查)
- 分布式鎖(常規鎖無效,因為是不同機器(常規鎖由JDK提供),不同集群,因此要采用分布式鎖)
- 集群管理
第二章 Zookeeper安裝與配置
見3.1
第三章 Zookeeper命令操作
3.1 Zookeeper命令操作資料型別
-
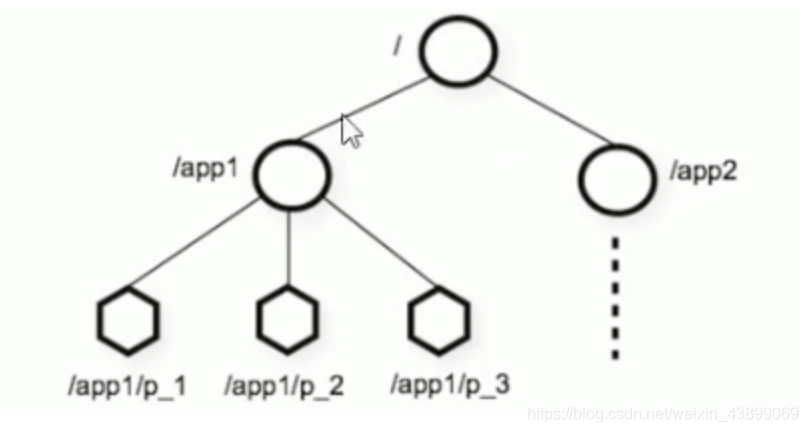
ZooKeeper 是一個樹形目錄服務,其資料模型和Unix的檔案系統目錄樹很類似,擁有一個層次化結構,
-
這里面的每一個節點都被稱為: ZNode,每個節點上都會保存自己的資料和節點資訊,
-
節點可以擁有子節點,同時也允許少量(1MB)資料存盤在該節點之下,
-
節點可以分為四大類:
- PERSISTENT 持久化節點
- EPHEMERAL 臨時節點 :-e (服務端關閉后就消失了)
- PERSISTENT_SEQUENTIAL 持久化順序節點 :-s (即節點后跟序號)
- EPHEMERAL_SEQUENTIAL 臨時順序節點 :-es
3.2 Zookeeper命令操作服務端命令
進入到Zookeeper/bin中,可執行如下操作
-
啟動 ZooKeeper 服務: ./zkServer.sh start
-
查看 ZooKeeper 服務狀態: ./zkServer.sh status
-
停止 ZooKeeper 服務: ./zkServer.sh stop
-
重啟 ZooKeeper 服務: ./zkServer.sh restart
3.3 Zookeeper客戶端常用命令
概述:連接上Server(服務端)后,操作節點,
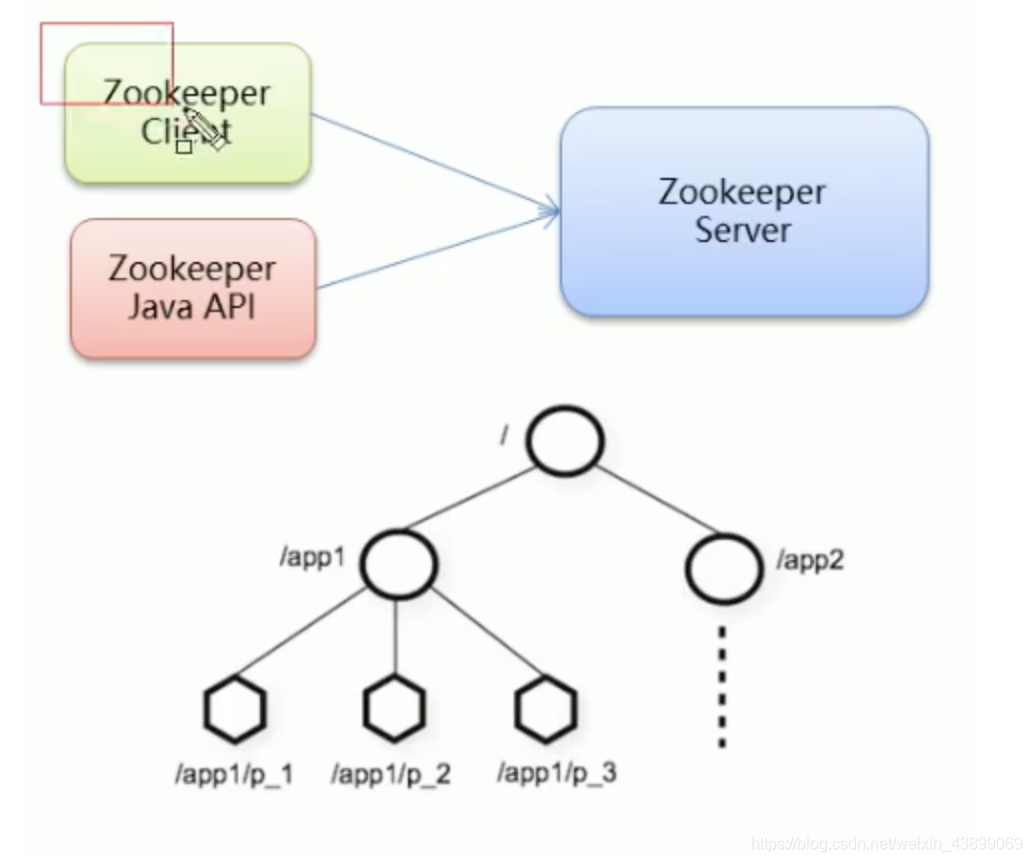
- 連接ZooKeeper服務端
./zkCli.sh –server ip:port
- 斷開連接
quit
- 查看命令幫助
help
- 顯示指定目錄下節點(如果目錄是/,則為根節點)
ls 目錄
- 創建節點(節點里面存放value)
create /節點path value
例子: create /app1
- 獲取節點值
get /節點path
- 設定節點值
set /節點path value
- 洗掉單個節點
delete /節點path
- 洗掉帶有子節點的節點
deleteall /節點path
3.4 客戶端命令-創建臨時有序節點
- 創建臨時節點
create -e /節點path value
- 創建順序節點
create -s /節點path value
- 查詢節點詳細資訊
ls –s /節點path
-
czxid:節點被創建的事務ID
-
ctime: 創建時間
-
mzxid: 最后一次被更新的事務ID
-
mtime: 修改時間
-
pzxid:子節點串列最后一次被更新的事務ID
-
cversion:子節點的版本號
-
dataversion:資料版本號
-
aclversion:權限版本號
-
ephemeralOwner:用于臨時節點,代表臨時節點的事務ID,如果為持久節點則為0
-
dataLength:節點存盤的資料的長度
-
numChildren:當前節點的子節點個數
以上的命令也側面體現出了Zookeeper的作用,即持久化or非持久化存盤資料、配置管理、分布式鎖、集群管理(節點儲存資訊,樹形結構、方便查找)
第四章 ZooKeeper JavaAPI 操作
4.1 Curator介紹
其核心就是對節點的操作,對節點的操作貫穿配置管理、分布式鎖、集群搭建三大模塊
-
Curator 是 Apache ZooKeeper 的Java客戶端庫,
-
常見的ZooKeeper Java API :
- 原生Java API
- ZkClient
- Curator
-
Curator 專案的目標是簡化 ZooKeeper 客戶端的使用,
-
Curator 最初是 Netfix 研發的,后來捐獻了 Apache 基金會,目前是 Apache 的頂級專案,
-
官網:http://curator.apache.org/
4.2 基本操作(配置管理)
操作-建立連接
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-kF4w6Jb7-1626871686069)(/Users/zhanglong/Library/Application Support/typora-user-images/image-20210720110747301.png)]
具體代碼見資料
1、搭建專案
創建專案curator-zk
引入pom和日志檔案
資料檔案夾下pom.xml和log4j.properties
2、創建測驗類,使用curator連接zookeeper
@Before
public void testConnect() {
//重試策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2.第二種方式
//CuratorFrameworkFactory.builder();
client = CuratorFrameworkFactory.builder()
.connectString("192.168.200.130:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.namespace("itheima")
.build();
//開啟連接
client.start();
}
操作-創建節點
/**
* 創建節點:create 持久 臨時 順序 資料
* 1. 基本創建 :create().forPath("")
* 2. 創建節點 帶有資料:create().forPath("",data)
* 3. 設定節點的型別:create().withMode().forPath("",data)
* 4. 創建多級節點 /app1/p1 :create().creatingParentsIfNeeded().forPath("",data)
*/
@Test
public void testCreate() throws Exception {
//2. 創建節點 帶有資料
//如果創建節點,沒有指定資料,則默認將當前客戶端的ip作為資料存盤
String path = client.create().forPath("/app2", "hehe".getBytes());
System.out.println(path);
}
@Test
public void testCreate2() throws Exception {
//1. 基本創建
//如果創建節點,沒有指定資料,則默認將當前客戶端的ip作為資料存盤
String path = client.create().forPath("/app1");
System.out.println(path);
}
@Test
public void testCreate3() throws Exception {
//3. 設定節點的型別
//默認型別:持久化
String path = client.create().withMode(CreateMode.EPHEMERAL).forPath("/app3");
System.out.println(path);
}
@Test
public void testCreate4() throws Exception {
//4. 創建多級節點 /app1/p1
//creatingParentsIfNeeded():如果父節點不存在,則創建父節點
String path = client.create().creatingParentsIfNeeded().forPath("/app4/p1");
System.out.println(path);
}
操作-查詢節點
/**
* 查詢節點:
* 1. 查詢資料:get: getData().forPath()
* 2. 查詢子節點: ls: getChildren().forPath()
* 3. 查詢節點狀態資訊:ls -s:getData().storingStatIn(狀態物件).forPath()
*/
@Test
public void testGet1() throws Exception {
//1. 查詢資料:get
byte[] data = client.getData().forPath("/app1");
System.out.println(new String(data));
}
@Test
public void testGet2() throws Exception {
// 2. 查詢子節點: ls
List<String> path = client.getChildren().forPath("/");
System.out.println(path);
}
@Test
public void testGet3() throws Exception {
Stat status = new Stat();
System.out.println(status);
//3. 查詢節點狀態資訊:ls -s
client.getData().storingStatIn(status).forPath("/app1");
System.out.println(status);
}
操作-修改節點
/**
* 修改資料
* 1. 基本修改資料:setData().forPath()
* 2. 根據版本修改: setData().withVersion().forPath()
* * version 是通過查詢出來的,目的就是為了讓其他客戶端或者執行緒不干擾我,
*
* @throws Exception
*/
@Test
public void testSet() throws Exception {
client.setData().forPath("/app1", "itcast".getBytes());
}
@Test
public void testSetForVersion() throws Exception {
Stat status = new Stat();
//3. 查詢節點狀態資訊:ls -s
client.getData().storingStatIn(status).forPath("/app1");
int version = status.getVersion();//查詢出來的 3
System.out.println(version);
client.setData().withVersion(version).forPath("/app1", "hehe".getBytes());
}
操作-洗掉節點
/**
* 洗掉節點: delete deleteall
* 1. 洗掉單個節點:delete().forPath("/app1");
* 2. 洗掉帶有子節點的節點:delete().deletingChildrenIfNeeded().forPath("/app1");
* 3. 必須成功的洗掉:為了防止網路抖動,本質就是重試, client.delete().guaranteed().forPath("/app2");
* 4. 回呼:inBackground
* @throws Exception
*/
@Test
public void testDelete() throws Exception {
// 1. 洗掉單個節點
client.delete().forPath("/app1");
}
@Test
public void testDelete2() throws Exception {
//2. 洗掉帶有子節點的節點
client.delete().deletingChildrenIfNeeded().forPath("/app4");
}
@Test
public void testDelete3() throws Exception {
//3. 必須成功的洗掉
client.delete().guaranteed().forPath("/app2");
}
@Test
public void testDelete4() throws Exception {
//4. 回呼
client.delete().guaranteed().inBackground(new BackgroundCallback(){
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("我被洗掉了~");
System.out.println(event);
}
}).forPath("/app1");
}
操作-Watch監聽概述
-
ZooKeeper 允許用戶在指定節點上注冊一些Watcher,并且在一些特定事件觸發的時候,ZooKeeper 服務端會將事件通知到感興趣的客戶端上去,該機制是 ZooKeeper 實作分布式協調服務的重要特性,
-
ZooKeeper 中引入了Watcher機制來實作了發布/訂閱功能能,能夠讓多個訂閱者同時監聽某一個物件,當一個物件自身狀態變化時,會通知所有訂閱者,
-
ZooKeeper 原生支持通過注冊Watcher來進行事件監聽,但是其使用并不是特別方便
? 需要開發人員自己反復注冊Watcher,比較繁瑣,
-
Curator引入了 Cache 來實作對 ZooKeeper 服務端事件的監聽,
-
ZooKeeper提供了三種Watcher:
- NodeCache : 只是監聽某一個特定的節點
- PathChildrenCache : 監控一個ZNode的子節點.
- TreeCache : 可以監控整個樹上的所有節點,類似于PathChildrenCache和NodeCache的組合
監聽-NodeCache
/**
* 演示 NodeCache:給指定一個節點注冊監聽器
*/
@Test
public void testNodeCache() throws Exception {
//1. 創建NodeCache物件
final NodeCache nodeCache = new NodeCache(client,"/app1");
//2. 注冊監聽
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("節點變化了~");
//獲取修改節點后的資料
byte[] data = nodeCache.getCurrentData().getData();
System.out.println(new String(data));
}
});
//3. 開啟監聽.如果設定為true,則開啟監聽是,加載緩沖資料
nodeCache.start(true);
while (true){
}
}
監聽-PathChildrenCache
@Test
public void testPathChildrenCache() throws Exception {
//1.創建監聽物件
PathChildrenCache pathChildrenCache = new PathChildrenCache(client,"/app2",true);
//2. 系結監聽器
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() { @Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
System.out.println("子節點變化了~");
System.out.println(event);
//監聽子節點的資料變更,并且拿到變更后的資料
//1.獲取型別
PathChildrenCacheEvent.Type type = event.getType();
//2.判斷型別是否是update
if(type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){
System.out.println("資料變了!!!");
byte[] data = event.getData().getData();
System.out.println(new String(data));
}
}
});
//3. 開啟
pathChildrenCache.start();
while (true){
}
}
監聽-TreeCache
/**
* 演示 TreeCache:監聽某個節點自己和所有子節點們
*/
@Test
public void testTreeCache() throws Exception {
//1. 創建監聽器
TreeCache treeCache = new TreeCache(client,"/app2");
//2. 注冊監聽
treeCache.getListenable().addListener(new TreeCacheListener() {
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
System.out.println("節點變化了");
System.out.println(event);
}
});
//3. 開啟
treeCache.start();
while (true){
}
}
4.3 Zookeeper分布式鎖
核心實作原理:臨時順序節點,
分布式鎖概念
-
在我們進行單機應用開發,涉及并發同步的時候,我們往往采用synchronized或者Lock的方式來解決多執行緒間的代碼同步問題,這時多執行緒的運行都是在同一個JVM之下,沒有任何問題,
-
但當我們的應用是分布式集群作業的情況下,屬于多JVM下的作業環境,跨JVM之間已經無法通過多執行緒的鎖解決同步問題,
-
那么就需要一種更加高級的鎖機制,來處理種跨機器的行程之間的資料同步問題——這就是分布式鎖,
不同架構層面的分布式鎖實作
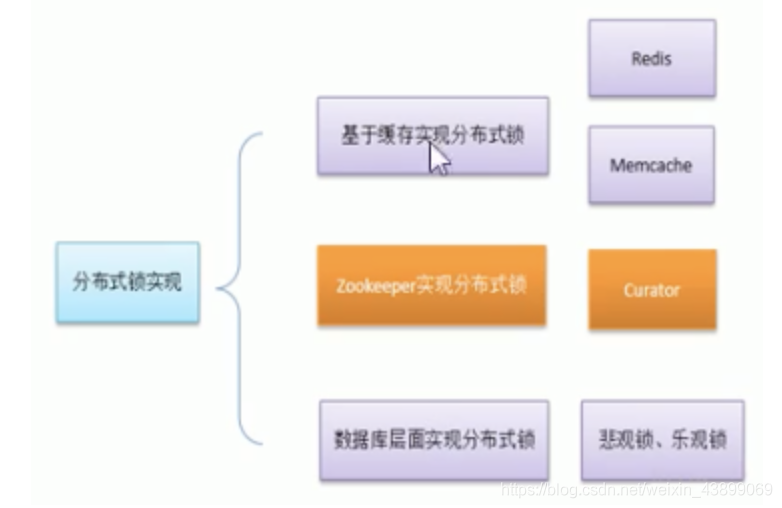
分布式鎖原理
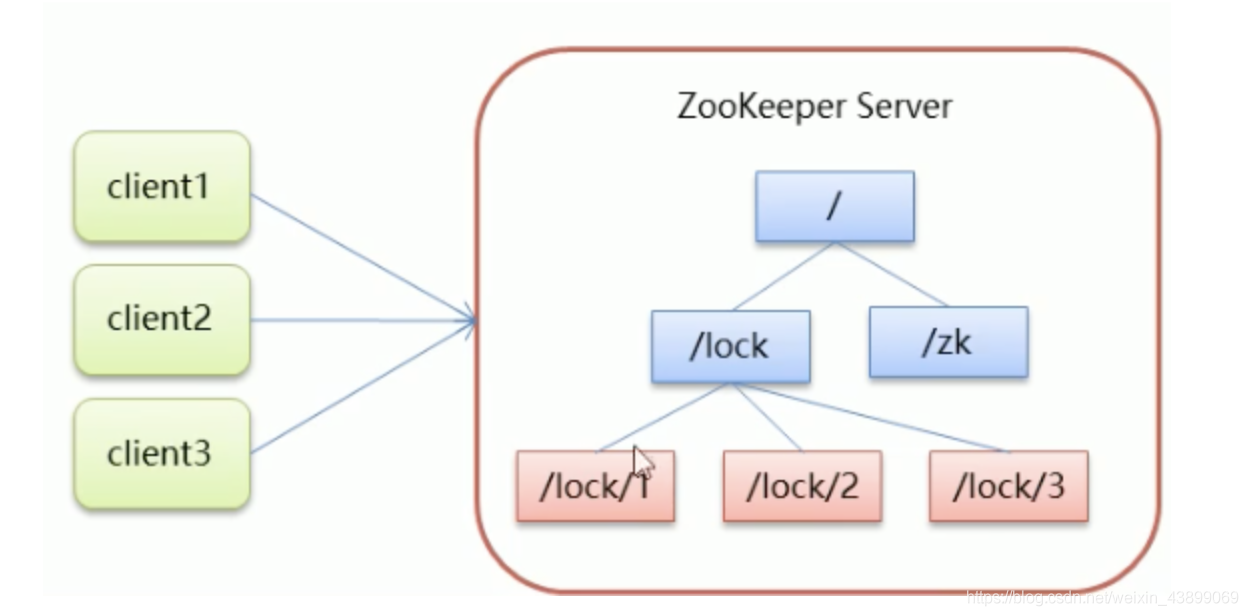
- 核心思想:當客戶端要獲取鎖,則創建節點,使用完鎖,則洗掉該節點,
- 客戶端獲取鎖時,在lock節點下創建臨時順序節點,
- 然后獲取lock下面的所有子節點,客戶端獲取到所有的子節點之后,如果發現自己創建的子節點序號最小,那么就認為該客戶端獲取到了鎖,使用完鎖后,將該節點洗掉,
- 如果發現自己創建的節點并非lock所有子節點中最小的,說明自己還沒有獲取到鎖,此時客戶端需要找到比自己小的那個節點,同時對其注冊事件監聽器,監聽洗掉事件,
- 如果發現比自己小的那個節點被洗掉,則客戶端的Watcher會收到相應通知,此時再次判斷自己創建的節點是否是lock子節點中序號最小的,如果是則獲取到了鎖,如果不是則重復以上步驟繼續獲取到比自己小的一個節點并注冊監聽,
原理:以判斷是否獲取到最后一個節點來決定獲取順序,或者是否可以獲取,這樣就可以保證在同一時間該資料只被一個行程使用
分布式鎖-模擬12306售票案例
總結一下:和正常鎖的用法一樣,不過呼叫了不同方法,因為它都為我們封裝好了,
Curator實作分布式鎖API
-
在Curator中有五種鎖方案:
-
InterProcessSemaphoreMutex:分布式排它鎖(非可重入鎖)
-
InterProcessMutex:分布式可重入排它鎖
-
InterProcessReadWriteLock:分布式讀寫鎖
-
InterProcessMultiLock:將多個鎖作為單個物體管理的容器(單獨設定一個容器,把多個鎖放到這個容器里管理)
-
InterProcessSemaphoreV2:共享信號量(如信號量設為多少,就允許多少人同時訪問)
-
1、創建執行緒進行加鎖設定
public class Ticket12306 implements Runnable{
private int tickets = 10;//資料庫的票數
private InterProcessMutex lock ;
@Override
public void run() {
while(true){
//獲取鎖
try {
lock.acquire(3, TimeUnit.SECONDS);
if(tickets > 0){
System.out.println(Thread.currentThread()+":"+tickets);
Thread.sleep(100);
tickets--;
}
} catch (Exception e) {
e.printStackTrace();
}finally {
//釋放鎖
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
2、創建連接,并且初始化鎖
public Ticket12306(){
//重試策略
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000, 10);
//2.第二種方式
//CuratorFrameworkFactory.builder();
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.149.135:2181")
.sessionTimeoutMs(60 * 1000)
.connectionTimeoutMs(15 * 1000)
.retryPolicy(retryPolicy)
.build();
//開啟連接
client.start();
lock = new InterProcessMutex(client,"/lock");
}
3、運行多個執行緒進行測驗
public class LockTest {
public static void main(String[] args) {
Ticket12306 ticket12306 = new Ticket12306();
//創建客戶端
Thread t1 = new Thread(ticket12306,"攜程");
Thread t2 = new Thread(ticket12306,"飛豬");
t1.start();
t2.start();
}
}
4.4 ZooKeeper 集群搭建
集群介紹
Leader選舉:
-
Serverid:服務器ID
比如有三臺服務器,編號分別是1,2,3,
編號越大在選擇演算法中的權重越大,
-
Zxid:資料ID
服務器中存放的最大資料ID,值越大說明資料越新,在選舉演算法中資料越新權重越大,
-
在Leader選舉的程序中,如果某臺ZooKeeper獲得了超過半數的選票,則此ZooKeeper就可以成為Leader了,
搭建要求
真實的集群是需要部署在不同的服務器上的,但是在我們測驗時同時啟動很多個虛擬機記憶體會吃不消,所以我們通常會搭建偽集群,也就是把所有的服務都搭建在一臺虛擬機上,用埠進行區分,
我們這里要求搭建一個三個節點的Zookeeper集群(偽集群),
準備作業
重新部署一臺虛擬機作為我們搭建集群的測驗服務器,
(1)安裝JDK 【此步驟省略】,
(2)Zookeeper壓縮包上傳到服務器(put命令)
(3)將Zookeeper解壓 ,建立/usr/local/zookeeper-cluster目錄,將解壓后的Zookeeper復制到以下三個目錄
/usr/local/zookeeper-cluster/zookeeper-1
/usr/local/zookeeper-cluster/zookeeper-2
/usr/local/zookeeper-cluster/zookeeper-3
[root@localhost ~]# mkdir /usr/local/zookeeper-cluster
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-1
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-2
[root@localhost ~]# cp -r apache-zookeeper-3.5.6-bin /usr/local/zookeeper-cluster/zookeeper-3
(4)創建data目錄 ,并且將 conf下zoo_sample.cfg 檔案改名為 zoo.cfg
mkdir /usr/local/zookeeper-cluster/zookeeper-1/data
mkdir /usr/local/zookeeper-cluster/zookeeper-2/data
mkdir /usr/local/zookeeper-cluster/zookeeper-3/data
mv /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
mv /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo_sample.cfg /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
(5) 配置每一個Zookeeper 的dataDir 和 clientPort 分別為2181 2182 2183
修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
clientPort=2181
dataDir=/usr/local/zookeeper-cluster/zookeeper-1/data
修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
clientPort=2182
dataDir=/usr/local/zookeeper-cluster/zookeeper-2/data
修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
clientPort=2183
dataDir=/usr/local/zookeeper-cluster/zookeeper-3/data
配置集群
(1)在每個zookeeper的 data 目錄下創建一個 myid 檔案,內容分別是1、2、3 ,這個檔案就是記錄每個服務器的ID
echo 1 >/usr/local/zookeeper-cluster/zookeeper-1/data/myid
echo 2 >/usr/local/zookeeper-cluster/zookeeper-2/data/myid
echo 3 >/usr/local/zookeeper-cluster/zookeeper-3/data/myid
(2)在每一個zookeeper 的 zoo.cfg配置客戶端訪問埠(clientPort)和集群服務器IP串列,
集群服務器IP串列如下
vim /usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
vim /usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
server.1=192.168.149.135:2881:3881
server.2=192.168.149.135:2882:3882
server.3=192.168.149.135:2883:3883
解釋:server.服務器ID=服務器IP地址:服務器之間通信埠:服務器之間投票選舉埠(根據ip地址來判斷是否是同一個集群)
啟動集群
啟動集群就是分別啟動每個實體,
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
啟動后我們查詢一下每個實體的運行狀態
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
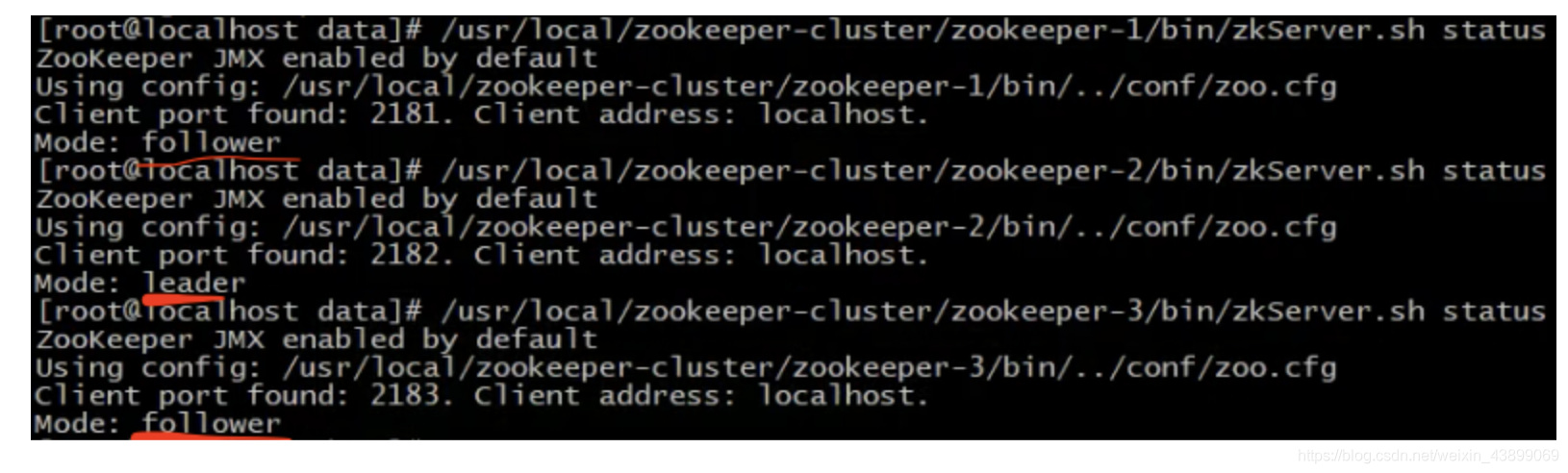
先查詢第一個服務
Mode為follower表示是跟隨者(從)
再查詢第二個服務Mod 為leader表示是領導者(主)
查詢第三個為跟隨者(從)
故障測驗
(1)首先我們先測驗如果是從服務器掛掉,會怎么樣
把3號服務器停掉,觀察1號和2號,發現狀態并沒有變化
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
由此得出結論,3個節點的集群,從服務器掛掉,集群正常
(2)我們再把1號服務器(從服務器)也停掉,查看2號(主服務器)的狀態,發現已經停止運行了,
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
由此得出結論,3個節點的集群,2個從服務器都掛掉,主服務器也無法運行,因為可運行的機器沒有超過集群總數量的半數,
(3)我們再次把1號服務器啟動起來,發現2號服務器又開始正常作業了,而且依然是領導者,
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
(4)我們把3號服務器也啟動起來,把2號服務器停掉,停掉后觀察1號和3號的狀態,
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh stop
/usr/local/zookeeper-cluster/zookeeper-1/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
發現新的leader產生了~
由此我們得出結論,當集群中的主服務器掛了,集群中的其他服務器會自動進行選舉狀態,然后產生新得leader
(5)我們再次測驗,當我們把2號服務器重新啟動起來啟動后,會發生什么?2號服務器會再次成為新的領導嗎?我們看結果
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh start
/usr/local/zookeeper-cluster/zookeeper-2/bin/zkServer.sh status
/usr/local/zookeeper-cluster/zookeeper-3/bin/zkServer.sh status
我們會發現,2號服務器啟動后依然是跟隨者(從服務器),3號服務器依然是領導者(主服務器),沒有撼動3號服務器的領導地位,
由此我們得出結論,當領導者產生后,再次有新服務器加入集群,不會影響到現任領導者,
Zookeeper 核心理論
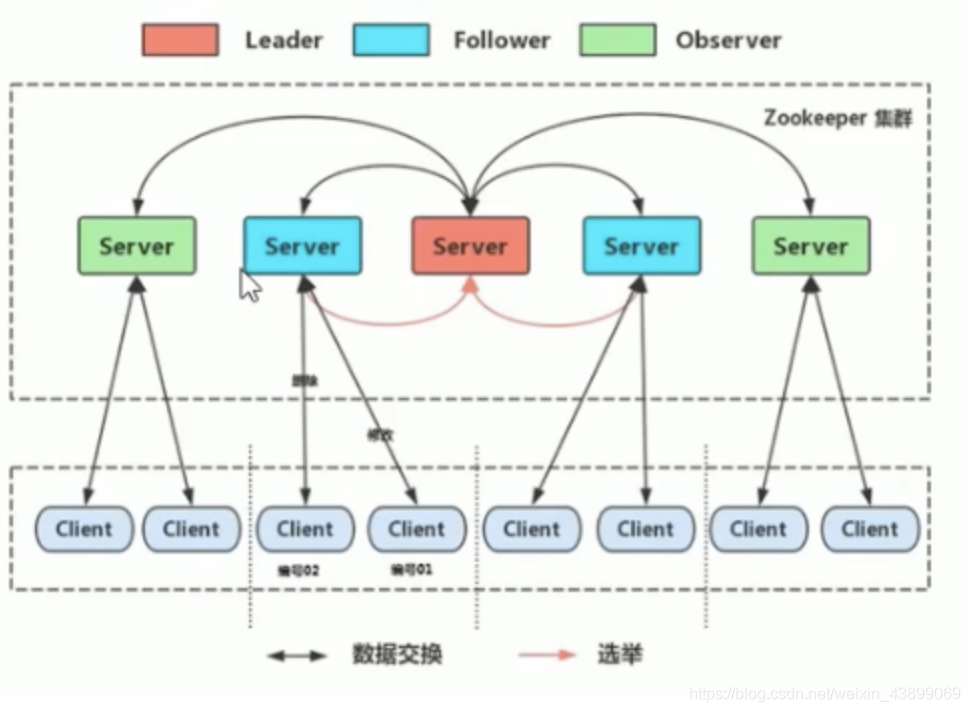
Zookeepe集群角色
在ZooKeeper集群服中務中有三個角色:
-
Leader 領導者 :
- 處理事務請求
- 集群內部各服務器的調度者
-
Follower 跟隨者 :
- 處理客戶端非事務請求,轉發事務請求給Leader服務器
- 參與Leader選舉投票
-
Observer 觀察者:
- 處理客戶端非事務請求,轉發事務請求給Leader服務器
示意圖如下:
相關注解
@Service
引入路徑:import org.apache.dubbo.config.annotation.Service;
作用:將這個類提供的方法對外發布,將訪問的地址、ip、埠、路徑注冊到注冊中心里,
@Reference
翻譯:參考的,涉及的,
代替@Autowired,
@Autowired為本地注入,@Reference為遠程注入,
儲備知識
QoS服務
QoS(Quality of Service,服務質量)指一個網路能夠利用各種基礎技術,為指定的網路通信提供更好的服務能力,是網路的一種安全機制, 是用來解決網路延遲和阻塞等問題的一種技術,dubbo為用戶提供類似的網路服務用來online和offline service來解決網路延遲,阻塞等問題,
QoS配置:
dubbo的QoS是默認開啟的,埠為22222,可以通過配置修改埠
<dubbo:application name="demo-provider">
<dubbo:parameter key="qos.port" value="33333"/>
</dubbo:application>
或者關閉服務
<dubbo:application name="demo-provider">
<dubbo:parameter key="qos.enable" value="false"/>
</dubbo:application>
為了安全考慮,dubbo的qos默認是只支持本地連接的,如果要開啟任意ip可連接,需做如下配置
<dubbo:application name="demo-provider">
<dubbo:parameter key="qos.port" value="33333"/>
<dubbo:parameter key="qos.accept.foreign.ip" value="false"/>
</dubbo:application>
Node.js是干嘛的
如果你去年注意過技術方面的新聞,我敢說你至少看到node.js不下一兩次,那么問題來了“node.js是什么?”,有些人沒準會告訴你“這是一種通過JavaScript語言開發web服務端的東西”,如果這種晦澀解釋還沒把你搞暈,你沒準會接著問:“為什么我們要用node.js?”,別人一般會告訴你:node.js有非阻塞,事件驅動I/O等特性,從而讓高并發(high concurrency)在的輪詢(Polling)和comet構建的應用中成為可能,
當你看完這些解釋覺得跟看天書一樣的時候,你估計也懶得繼續問了,不過沒事,我這篇文章就是在避開高端術語的同時,幫助你你理解node.js的,
瀏覽器給網站發請求的程序一直沒怎么變過,當瀏覽器給網站發了請求,服務器收到了請求,然后開始搜尋被請求的資源,如果有需要,服務器還會查詢一下資料庫,最后把回應結果傳回瀏覽器,不過,在傳統的web服務器中(比如Apache),每一個請求都會讓服務器創建一個新的行程來處理這個請求,
后來有了Ajax,有了Ajax,我們就不用每次都請求一個完整的新頁面了,取而代之的是,每次只請求需要的部分頁面資訊就可以了,這顯然是一個進步,但是比如你要建一個FriendFeed這樣的社交網站(類似人人網那樣的刷朋友新鮮事的網站),你的好友會隨時的推送新的狀態,然后你的新鮮事會實時自動重繪,要達成這個需求,我們需要讓用戶一直與服務器保持一個有效連接,目前最簡單的實作方法,就是讓用戶和服務器之間保持長輪詢(long polling),
HTTP請求不是持續的連接,你請求一次,服務器回應一次,然后就完了,長輪訓是一種利用HTTP模擬持續連接的技巧,具體來說,只要頁面載入了,不管你需不需要服務器給你回應資訊,你都會給服務器發一個Ajax請求,這個請求不同于一般的Ajax請求,服務器不會直接給你回傳資訊,而是它要等著,直到服務器覺得該給你發資訊了,它才會回應,比如,你的好友發了一條新鮮事,服務器就會把這個新鮮事當做回應發給你的瀏覽器,然后你的瀏覽器就重繪頁面了,瀏覽器收到回應重繪完之后,再發送一條新的請求給服務器,這個請求依然不會立即被回應,于是就開始重復以上步驟,利用這個方法,可以讓瀏覽器始終保持等待回應的狀態,雖然以上程序依然只有非持續的Http參與,但是我們模擬出了一個看似持續的連接狀態
我們再看傳統的服務器(比如Apache),每次一個新用戶連到你的網站上,你的服務器就得開一個連接,每個連接都需要占一個行程,這些行程大部分時間都是閑著的(比如等著你好友發新鮮事,等好友發完才給用戶回應資訊,或者等著資料庫回傳查詢結果什么的),雖然這些行程閑著,但是照樣占用記憶體,這意味著,如果用戶連接數的增長到一定規模,你服務器沒準就要耗光記憶體直接癱了,
這種情況怎么解決?解決方法就是剛才上邊說的:非阻塞和事件驅動,這些概念在我們談的這個情景里面其實沒那么難理解,你把非阻塞的服務器想象成一個loop回圈,這個loop會一直跑下去,一個新請求來了,這個loop就接了這個請求,把這個請求傳給其他的行程(比如傳給一個搞資料庫查詢的行程),然后回應一個回呼(callback),完事了這loop就接著跑,接其他的請求,這樣下來,服務器就不會像之前那樣傻等著資料庫回傳結果了,
如果資料庫把結果回傳來了,loop就把結果傳回用戶的瀏覽器,接著繼續跑,在這種方式下,你的服務器的行程就不會閑著等著,從而在理論上說,同一時刻的資料庫查詢數量,以及用戶的請求數量就沒有限制了,服務器只在用戶那邊有事件發生的時候才回應,這就是事件驅動,
FriendFeed是用基于Python的非阻塞框架Tornado (知乎也用了這個框架) 來實作上面說的新鮮事功能的,不過,Node.js就比前者更妙了,Node.js的應用是通過javascript開發的,然后直接在Google的變態V8引擎上跑,用了Node.js,你就不用擔心用戶端的請求會在服務器里跑了一段能夠造成阻塞的代碼了,因為javascript本身就是事件驅動的腳本語言,你回想一下,在給前端寫javascript的時候,更多時候你都是在搞事件處理和回呼函式,javascript本身就是給事件處理量身定制的語言,
Node.js還是處于初期階段,如果你想開發一個基于Node.js的應用,你應該會需要寫一些很底層代碼,但是下一代瀏覽器很快就要采用WebSocket技術了,從而長輪詢也會消失,在Web開發里,Node.js這種型別的技術只會變得越來越重要,
總結:
Apache:行程獨立,每個行程占用一定資源,無法釋放,
ajax:長輪詢
node.js:非阻塞、事件驅動,
專案打包的作用
如果用Linux陳述句運行專案,就一定要先打包,因為我們沒有像Idea一樣把項目整合在一起的工具, 因此只能把它打成一個Jar包,再運行,
序列化和反序列化
序列化是指將Java物件轉換為位元組序列的程序,而反序列化則是將位元組序列轉換為Java物件的程序,
Java物件序列化是將實作了Serializable介面的物件轉換成一個位元組序列,能夠通過網路傳輸、檔案存盤等方式傳輸 ,傳輸程序中卻不必擔心資料在不同機器、不同環境下發生改變,也不必關心位元組的順序或其他任何細節,并能夠在以后將這個位元組序列完全恢復為原來的物件(恢復這一程序稱之為反序列化),
物件的序列化是非常有趣的,因為利用它可以實作輕量級持久性,“持久性”意味著一個物件的生存周期不單單取決于程式是否正在運行,它可以生存于程式的呼叫之間,通過將一個序列化物件寫入磁盤,然后在重新呼叫程式時恢復該物件,從而達到實作物件的持久性的效果,
本質上講,序列化就是把物體物件狀態按照一定的格式寫入到有序位元組流,反序列化就是從有序位元組流重建物件,恢復物件狀態,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290042.html
標籤:其他