目錄
- 一、Docker安全介紹
- 1.命名空間隔離的安全
- 2.控制組資源控制的安全
- 二、容器資源控制
- 1.記憶體限制
- 2.cpu限額
- 3.Block IO限制(磁盤IO)
- 三.docker安全加固
- 1.設定特權級運行的容器
- 2.設定容器白名單
一、Docker安全介紹
Docker容器的安全性,很大程度上依賴于Linux系統自身,評估Docker的安全性時,主要考慮以下幾個方面
Linux內核的命名空間機制提供的容器隔離安全
Linux控制組機制對容器資源的控制能力安全,
Linux內核的能力機制所帶來的操作權限安全
Docker程式(特別是服務端)本身的抗攻擊性,
其他安全增強機制對容器安全性的影響,
1.命名空間隔離的安全
就是當docker run啟動一個容器時,Docker將在后臺為容器創建一個獨立的命名空間,命名空間提供了最基礎也最直接的隔離,
與虛擬機方式相比,通過Linux namespace來實作的隔離不是那么徹底,
[root@server1 ~]# docker run -d --name demo nginx
[root@server1 ~]# docker inspect demo | grep Pid
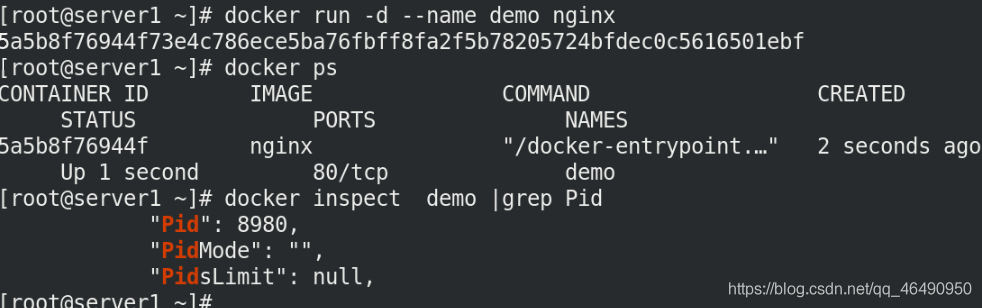
我們在系統行程里進入pid里查看一下資訊!
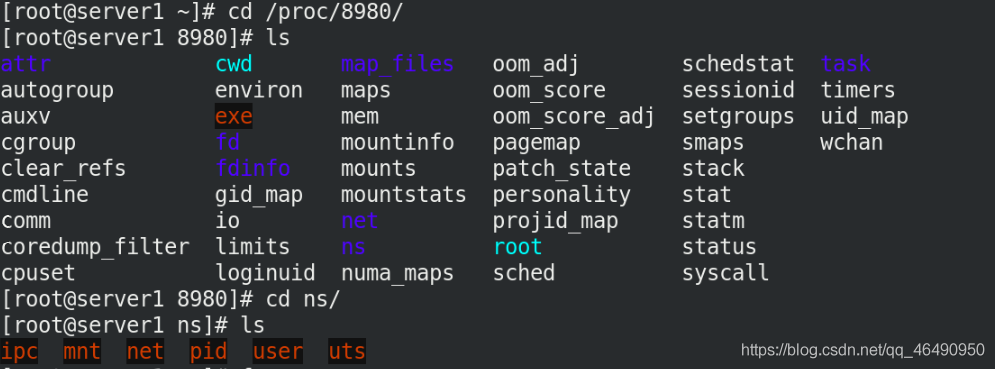
cd /proc/8980/
cd ns/
ls
2.控制組資源控制的安全
當docker啟動一個容器時,Docker將在后臺為容器創建一個獨立的控制組策略集合,
在 /sys/fs/cgroup 下面有很多諸如 cpuset、cpu、 memory 這樣的子目錄,也叫子系統,
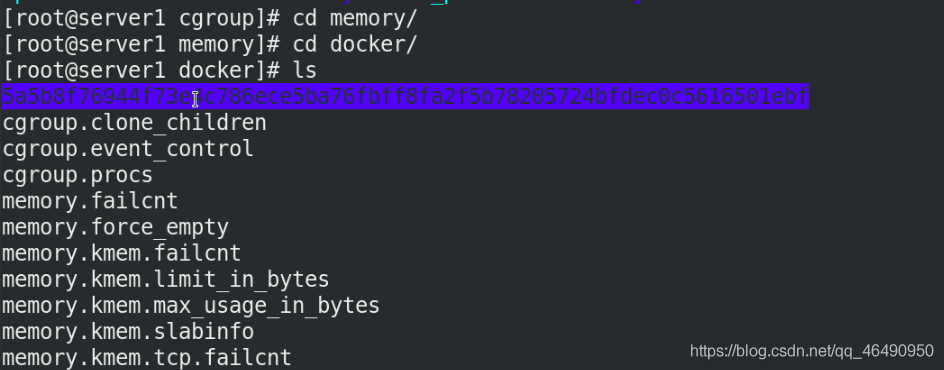
可以在memory記憶體看到運行的容器:
cd /sys/fs/cgroup/memory/docker/
ls
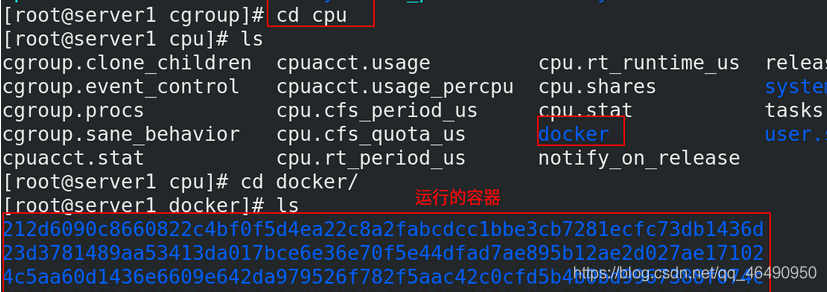
可以cpu中看到運行的容器:
二、容器資源控制
Linux Cgroups 的全稱是 Linux Control Group,
我們只能限制一個行程使用的資源上限:包括 CPU、記憶體、磁盤、網路帶寬等等,
Linux Cgroups 給用戶暴露出來的操作介面是檔案系統,
它以檔案和目錄的方式組織在作業系統的 /sys/fs/cgroup 路徑下,
在 /sys/fs/cgroup 下面有很多諸如 cpuset、cpu、 memory 這樣的子目錄,也叫子系統,
在每個子系統下面,為每個容器創建一個控制組(即創建一個新目錄),
控制組下面的資源檔案里填上什么值,就靠用戶執行 docker run 時的引數指定,
1.記憶體限制
容器可用記憶體包括兩個部分:物理記憶體和swap交換磁區,
–m 設定記憶體使用限額
docker run -it --m 200M -d --name demo nginx
cd /sys/fs/cgroup/memory/docker/ #可以看到打開的行程
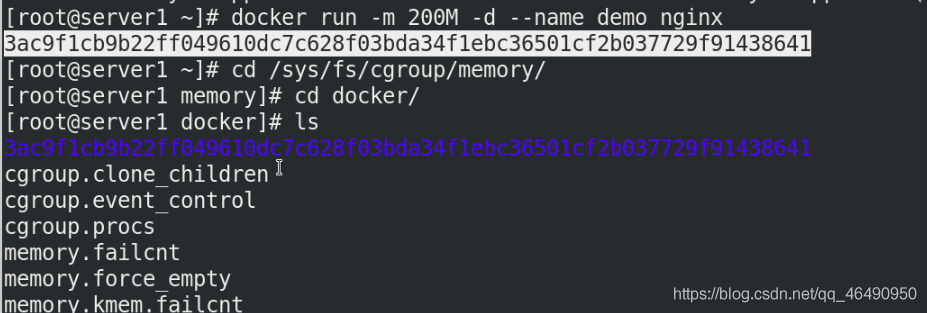
我們進入到剛才的容器中,看到memory.limit_in_bytes內容是記憶體限制
cd *************
cat memory.limit_in_bytes

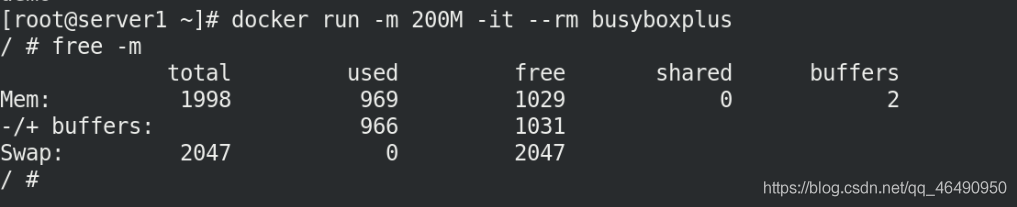
但是剛才的demo鏡像不能夠查看空間,所以我們需要換一個鏡像

docker run -m 200M -it --rm busyboxplus
free -m
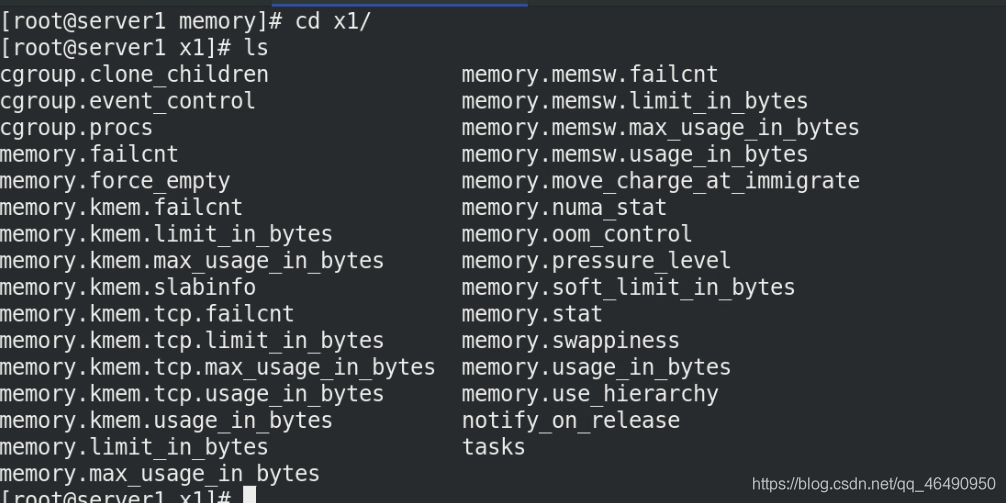
我們專門創建一個用來測驗記憶體的目錄x1
cd /sys/fs/cgroup/memory
mmkdir x1
cd x1/
ls
我們可以發現,創建好的目錄x1里面擁有很多組態檔,因為它直接繼承上級目錄下的所有檔案!
然后我們限制上傳的記憶體最大為200M
echo 209715200 > memory.limit_in_bytes
cat memory.limit_in_bytes

下載libcgroup-tools工具
yum install -y libcgroup-tools.x86_64
 我們創建指定大小的空間,但是我們發現前面已經設定了最大記憶體為200M,但是為什么能創建300M的空間呢?
我們創建指定大小的空間,但是我們發現前面已經設定了最大記憶體為200M,但是為什么能創建300M的空間呢?
cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=300
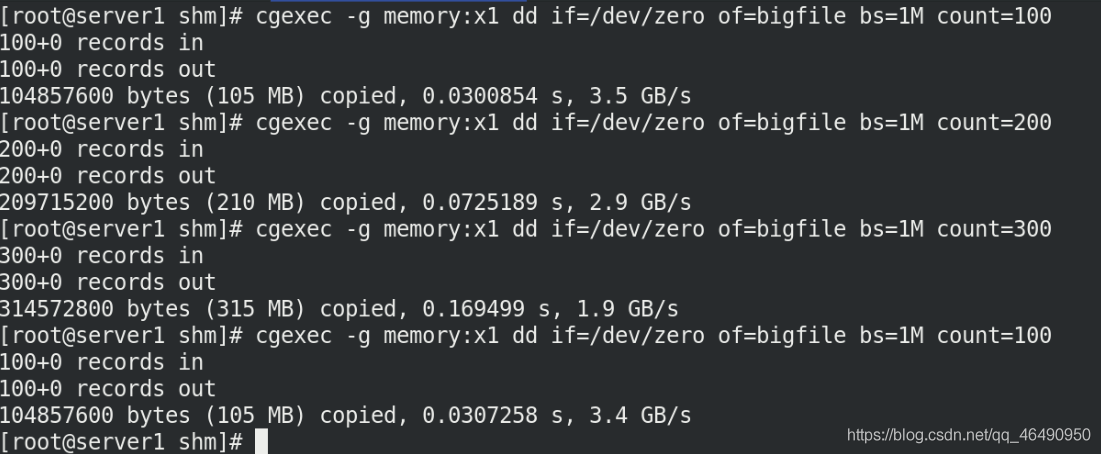
那是因為它占用了我們的swap磁區的大小!
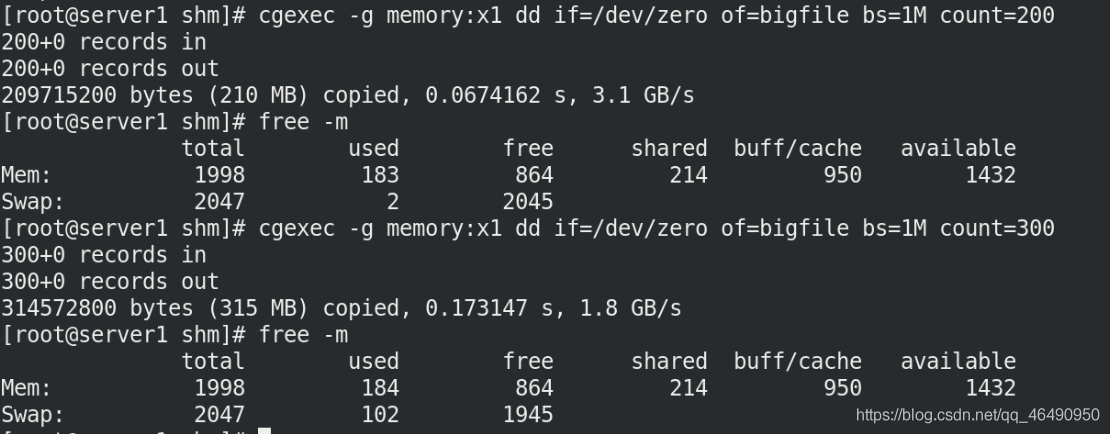
我們每次創建一定大小空間之后,用free -m查看一下記憶體情況就明白了!
我們的mem空間并沒有使用有效空間都是1432如下圖,但是swap空間使用多了100M,這下剛才的疑惑就解決了!!
洗掉創建的bigfile檔案,那么我們是不是把swap磁區關閉,創建300M空間就會失敗呢?
rm -f bigfile
swapoff -a
free -m
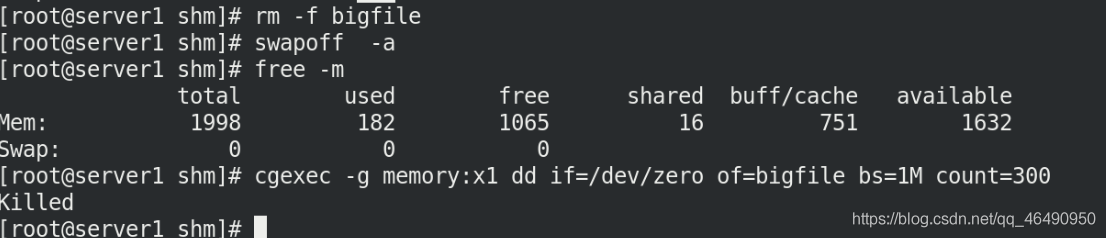
cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=300
果然沒有了swap磁區之后,創建300M磁區直接報錯!(killed)
但是在實際生產中,swap磁區會使用,不能夠關閉的!!
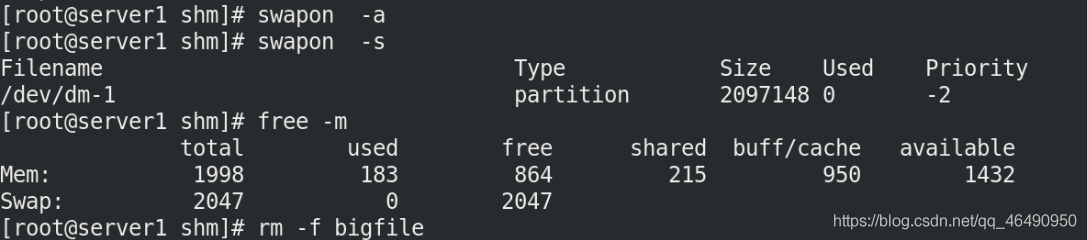
所以我們重新打開swap磁區,洗掉bigfile檔案!尋找別的方法來解決剛剛的問題:
swapon -a
swapon -s
free -m
rm -f bigfile
我們進入剛才的設定記憶體大小的路徑下:
我們把200M的限制給記憶體+swap一共200M ,剛才的問題不就解決了馬?
cd /sys/fs/cgroup/memory/x1
echo 209715200 > memory.memsw.limit_in_bytes %記憶體+swap一共給200M

cd /dev/shm
cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=300
cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=100
du -h *
cgexec -g memory:x1 dd if=/dev/zero of=bigfile bs=1M count=200
du -h *
我們可以看到創建300M空間直接失敗!

創建100M成功,創建200M也不行,只能創建199M!

2.cpu限額
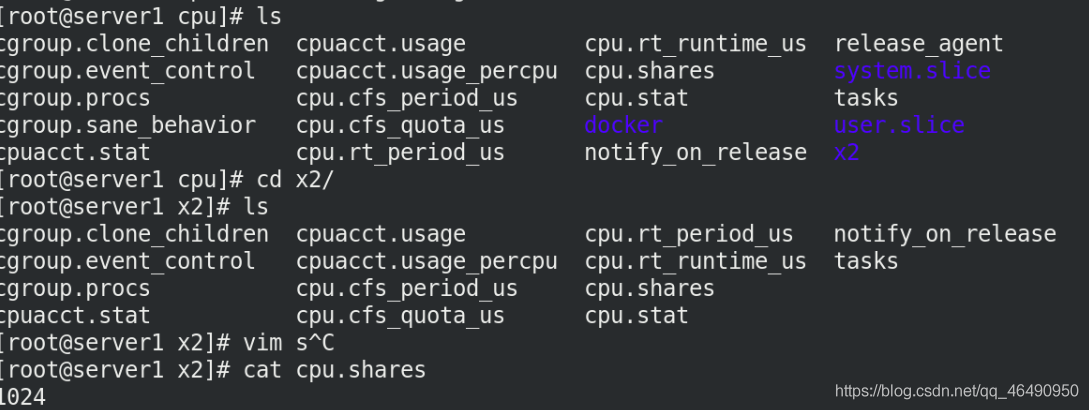
我們需要創建一個專門用于測驗cpu的目錄x2
cd /sys/fs/cgroup/cpu
mmkdir x2
cd x2/
ls
cpu.shares 不是限制行程能使用的絕對的 cpu 時間,而是控制各個組之間的配額!
cpu.shares,表示 CPU Cgroup 對于控制組之間的CPU 分配比例,預設值是1024
例如:
group3 中的cpu.shares 是1024,group4 中的 cpu.shares 是 3072,那么 group3:group4 = 1:3
我們先設定cpu.shares的配額為100,應該是10/100的cpu損耗!
然后使用dd命令測驗cpu的負載情況
echo 100 > cpu.shares
dd if=/dev/zero of=/dev/null &
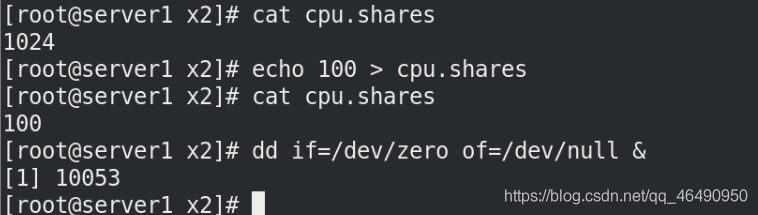
輸入top進入查看cpu消耗,是100,這不合適!是因為只有一個行程所以是100,所以我們還需要再創建一個壓力來測驗
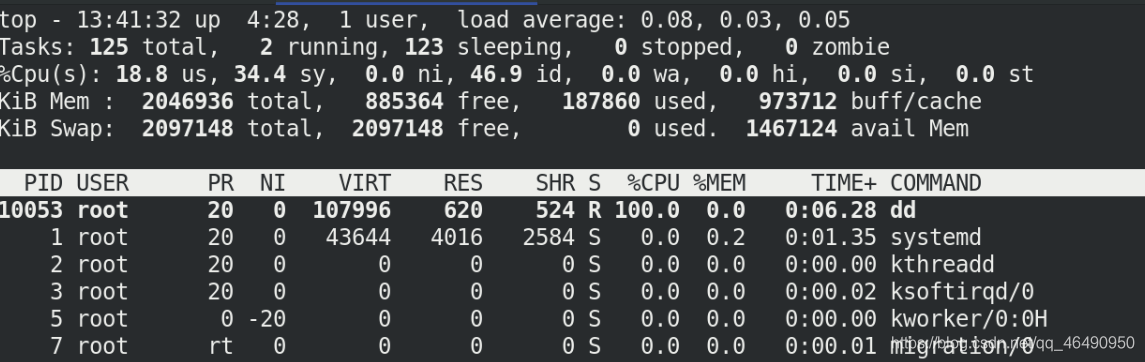
我們把cpu執行緒PID寫入tasks中
cat tasks
echo 10053 > tasks

我們再測驗使用一個損耗打入后臺
dd if=/dev/zero of=/dev/null &
 top 查看cpu消耗都是100,這還是不合適!
top 查看cpu消耗都是100,這還是不合適!
top
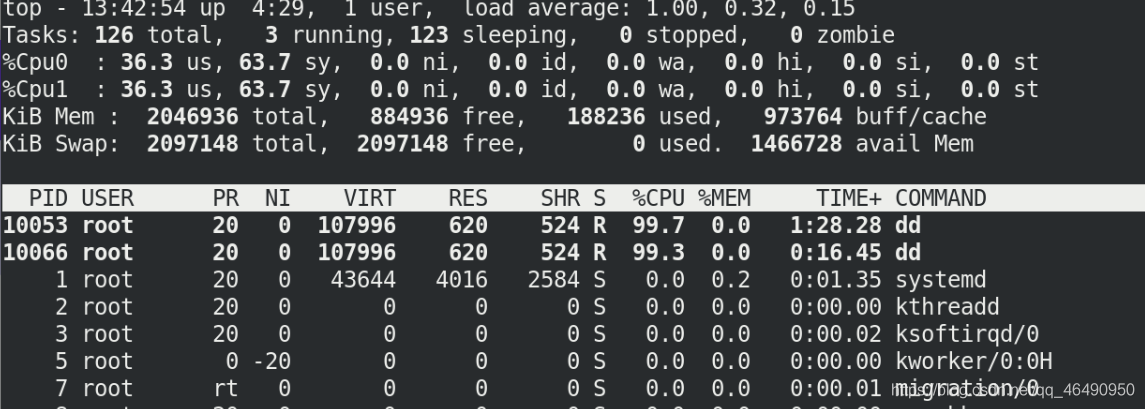
因為我們的虛擬機是雙cpu的可以獨立作業,所以可以關閉一個cpu
cd /sys/devices/system/cpu/cpu1
cat online
echo 0 > online
此時查看top
一個cpu穩定在10左右,另一個90左右
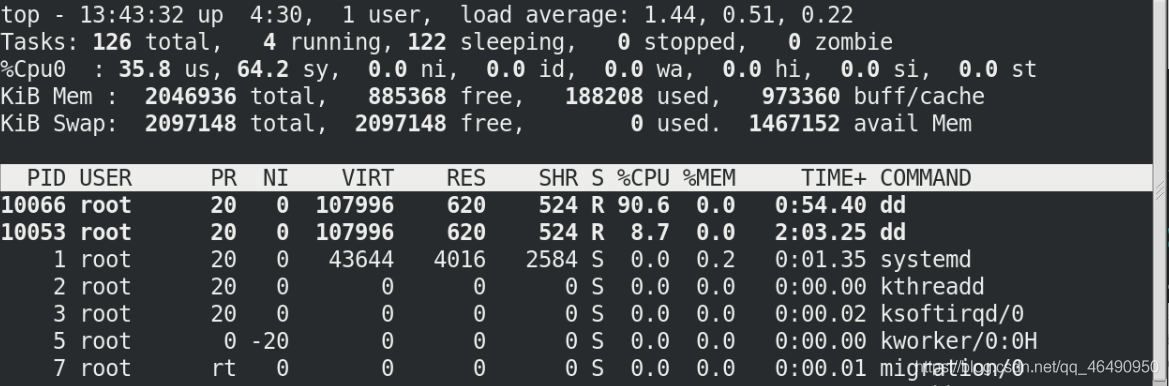
但是實際生產中不能關閉另一個cpu,行不通!
重新打開cpu1,恢復cpu的配額
echo 1 > online
echo 1024 > cpu.shares


cpu.cfs_period_us,它是CFS演算法的一個調度周期,一般值是 100000十萬,單位是微秒,就是 100ms
cpu.cfs_quota_us,它表示CFS演算法中,在一個調度周期里這個控制組被允許的運行時間,比如這個值為 50000時,就是 50ms,
如果用這個值cpu.cfs_quota_us除以調度周期cpu.cfs_period_us,50ms/100ms=0.5,表示這個控制組被允許使用的CPU最大配額就是0.5個CPU
cat cpu.cfs_quota_us
cat cpu.cfs_period_us
echo 20000 > cpu.cfs_quota_us
此時我們這樣設定就是允許使用的cpu為0.2個cpu!!
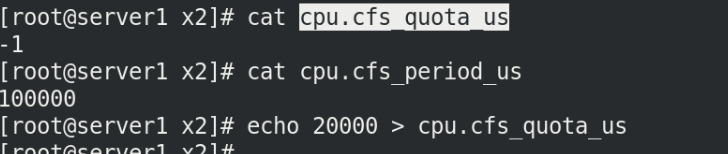
top
查看看到cpu使用為20和設定的效果一樣!
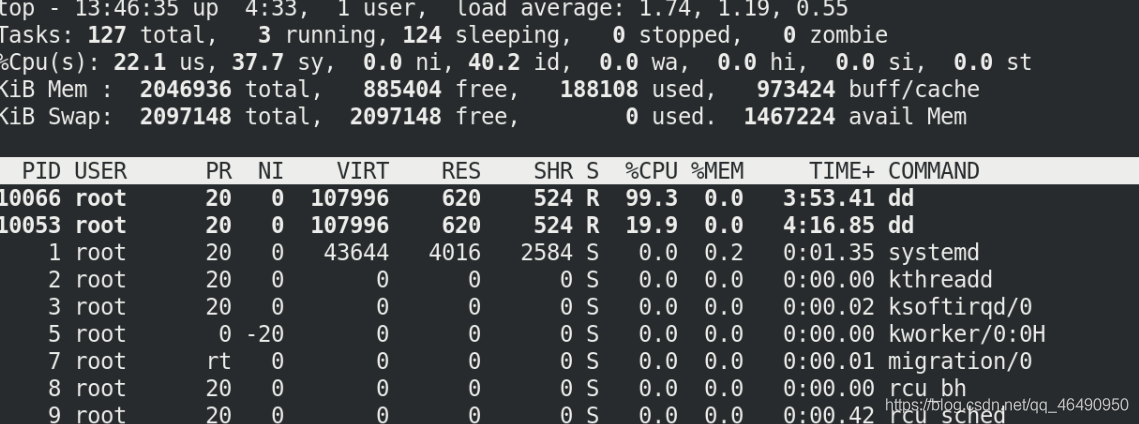 注意:追加是>>
注意:追加是>>
如果這個時候我們把另一個cpu也追加入到執行緒里面
echo 10066 >> tasks
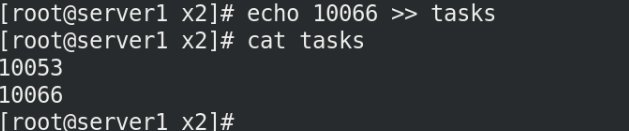
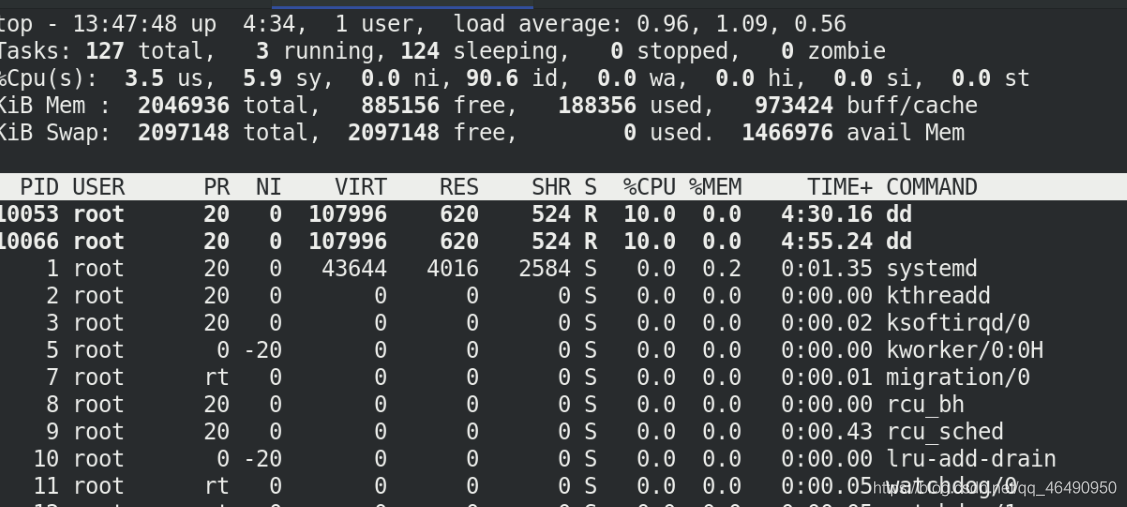
那么這個時候就是兩個行程去爭奪20的cpu配額
所以每個行程分的10!!如下圖:
3.Block IO限制(磁盤IO)
–device-write-bps限制寫設備的bps
目前的block IO限制只對direct IO有效,(不使用檔案快取)
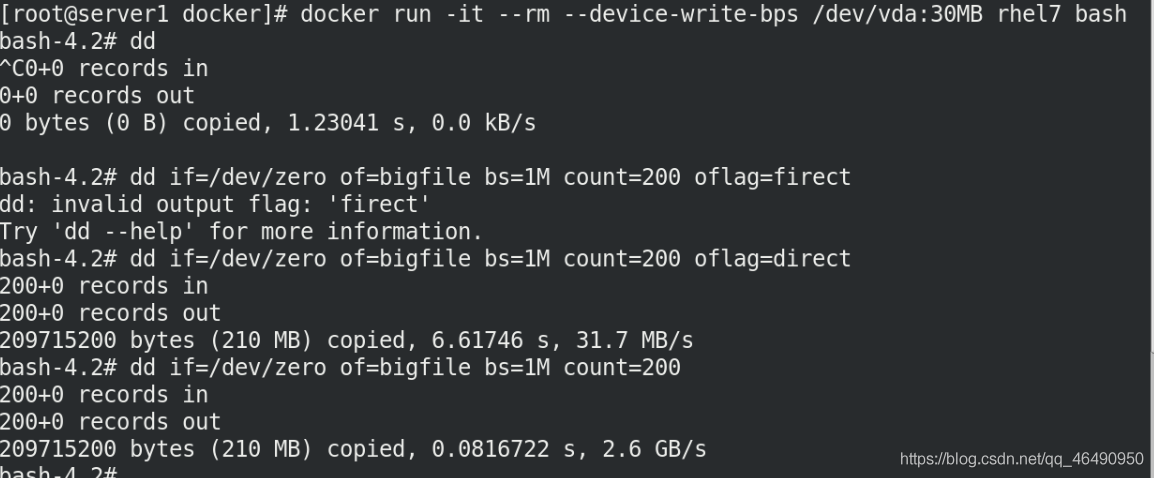
docker run -it --rm --device-write-bps /dev/vda:30MB rhel7 bash
dd if=/dev/zero of bigfile bs=1M count=200 oflag=direct
dd if=/dev/zero of bigfile bs=1M count=200
我們可以看到加上oflag=direct引數速度為30MB左右,不加引數,速度為2,6G就差別很大!!
三.docker安全加固
利用LXCFS增強docker容器隔離性和資源可見性
[root@server1 ~]# yum install lxcfs-2.0.5-3.el7.centos.x86_64.rpm -y
[root@server1 ~]#docker pull ubuntu
[root@server1 ~]# lxcfs /var/lib/lxcfs & ##運行
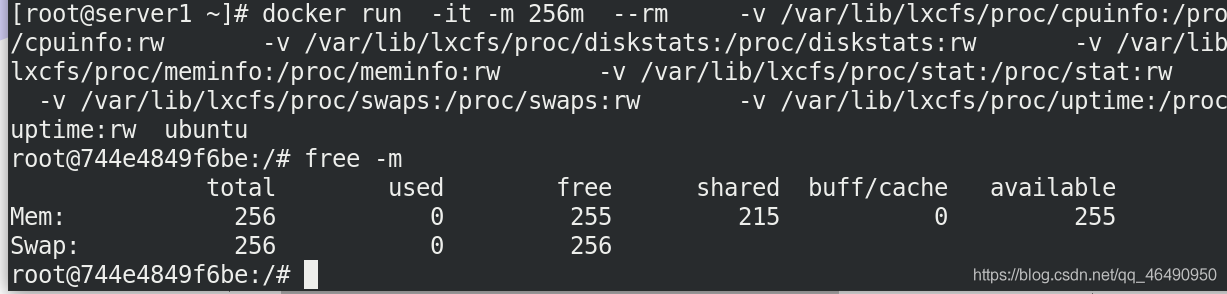
[root@server1 lxcfs]# docker run -it -m 256m \
> -v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw \
> -v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw \
> -v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw \
> -v /var/lib/lxcfs/proc/stat:/proc/stat:rw \
> -v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw \
> -v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw \
> ubuntu


我們可以看到mem和swap的大小一致!
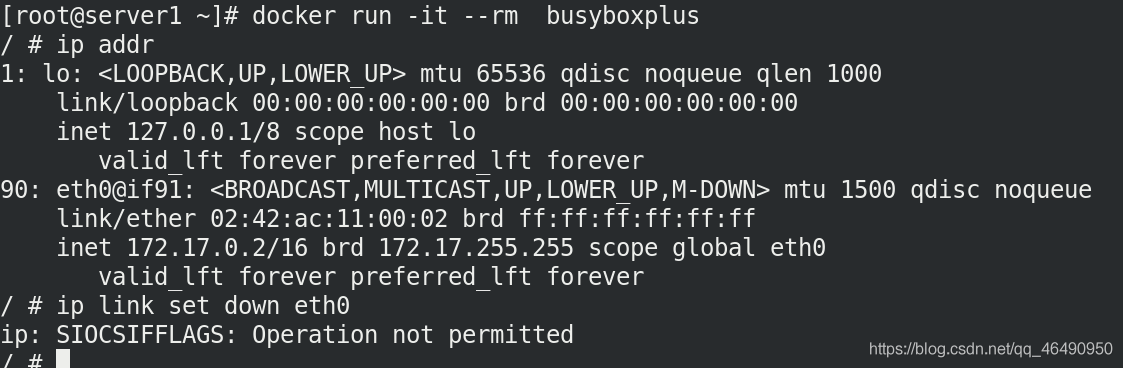
我們先運行一個普通的容器
發現控制網路的時候,被拒絕了!
docker run -it --rm busyboxplus
ip link set down eth0
1.設定特權級運行的容器
–privileged=true
有的時候我們需要容器具備更多的權限,比如操作內核模塊,控制swap交換磁區,掛載USB磁盤,修改MAC地址等,
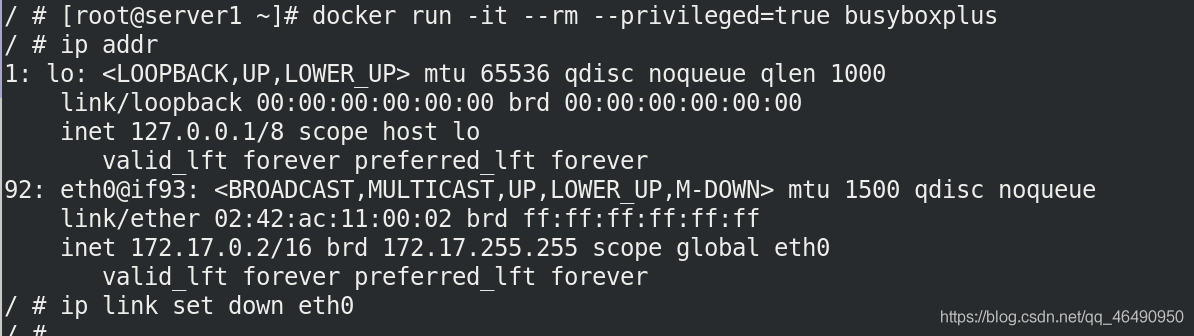
docker run -it --rm --privileged=true busyboxplus
ip link set down eth0
這次控制網路eth0成功了!
2.設定容器白名單
–cap-add
–privileged=true 的權限非常大,接近于宿主機的權限,為了防止用戶的濫用,需要增加限制,只提供給容器必須的權限,此時Docker 提供了權限白名單的機制,使用–cap-add添加必要的權限,
當我們運行容器給他一定的白名單時候,發現可以進行添加IP,洗掉IP操作!
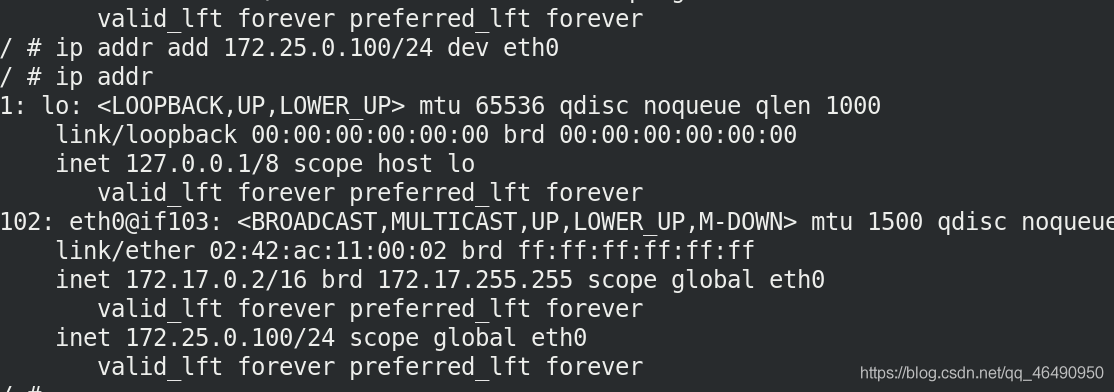
docker run -it --rm --cap-add=NET_ADMIN busybox
/ # ip addr add 172.25.0.100/24 dev eth0
/ # ip addr del 172.25.0.100/24 dev eth0

進行添加IP:172.25.0.100
洗掉ip

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290083.html
標籤:其他
上一篇:Windows實作流媒體服務器搭建 ngnix+rtmp+ffmpg+hls實作播放rtmp和HLS/m3u8直播流