
系列文章目錄
文章目錄
- 系列文章目錄
- 前言
- 一、內容安排說明
- 二、二叉搜索樹
- 1.二叉搜索樹概念
- 2.二叉搜索樹操作
- 1.二叉搜索樹的查找
- 2.二叉搜索樹的插入
- 3.二叉搜索樹的洗掉
- 4.二叉搜索樹的修改
- 3.二叉搜索樹實作
- 4.二叉搜索樹應用
- 5.二叉搜索樹的性能分析
- 總結
前言

一、內容安排說明
- 二叉樹在前面C資料結構階段已經講過,本節取名二叉樹進階是因為:
- map和set特性需要先鋪墊二叉搜索樹,而二叉搜索樹也是一種樹形結構,
- 二叉搜索樹的特性了解,有助于更好的理解map和set的特性,
- 二叉樹中部分面試題稍微有點難度,在前面講解大家不容易接受,且時間長容易忘,
- 有些OJ題使用C語言方式實作比較麻煩,
因此本節借二叉樹搜索樹,對二叉樹部分進行收尾總結,
二、二叉搜索樹
1.二叉搜索樹概念
- 二叉搜索樹又稱二叉排序樹,它或者是一棵空樹,或者是具有以下性質的二叉樹,
- 若它的左子樹不為空,則左子樹上所有節點的值都小于根節點的值,
- 若它的右子樹不為空,則右子樹上所有節點的值都大于根節點的值,
- 它的左右子樹也分別為二叉搜索樹,
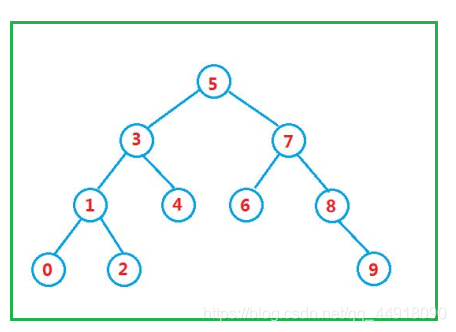
int a [] = {5,3,4,1,7,8,2,6,0,9};
2.二叉搜索樹操作
1.二叉搜索樹的查找
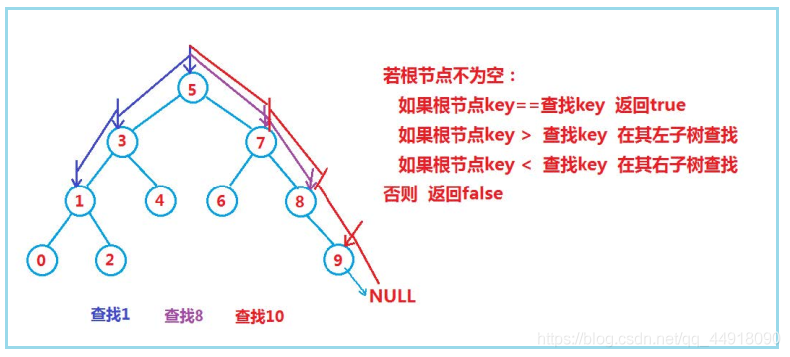

Node* Find(const K& key) //查找
{
Node* cur = _root;
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return cur;
}
2.二叉搜索樹的插入
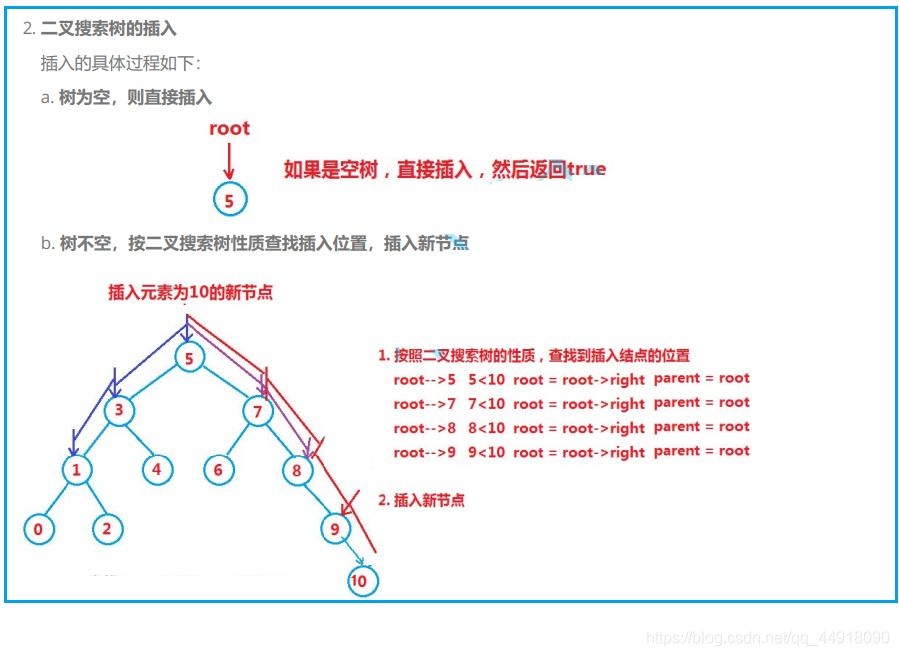

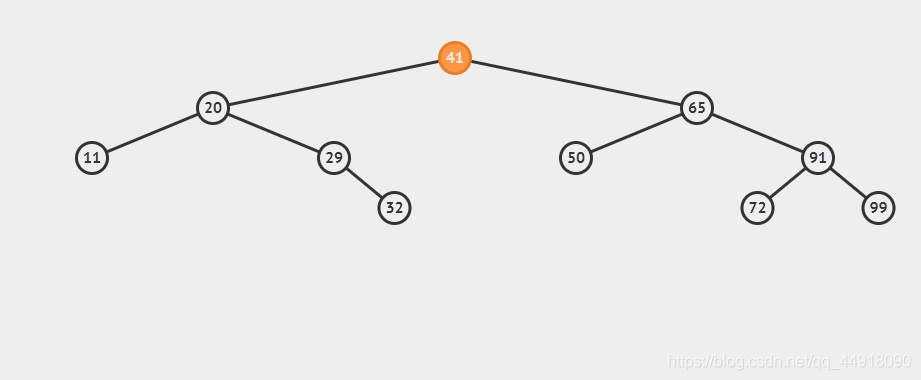
bool Insert(const K& key)
{
if (_root == nullptr) //空樹直接插入
{
_root = new Node(key);
return true;
}
//不是空樹找尋要插入的位置
Node* cur = _root;
Node* parent = nullptr; //記錄cur走過的上一個節點
while (cur)
{
parent = cur;
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key);
if (key < parent->_key) //把cur節點和父節點鏈接起來
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}
3.二叉搜索樹的洗掉
- 首先查找元素是否在二叉搜索樹中,如果不存在,則回傳, 否則要洗掉的結點可能分下面四種情況:
- 要洗掉的結點無孩子結點,
- 要洗掉的結點只有左孩子結點,
- 要洗掉的結點只有右孩子結點,
- 要洗掉的結點有左、右孩子結點,
- 看起來有待洗掉節點有4中情況,實際情況a可以與情況b或者c合并起來,因此真正的洗掉程序如下:
- 情況b:洗掉該結點且使被洗掉節點的雙親結點指向被洗掉節點的左孩子結點,
- 情況c:洗掉該結點且使被洗掉節點的雙親結點指向被洗掉結點的右孩子結點,
- 情況d:在它的右子樹中尋找中序下的第一個結點(關鍵碼最小),用它的值填補到被洗掉節點中,再來處理該結點的洗掉問題,

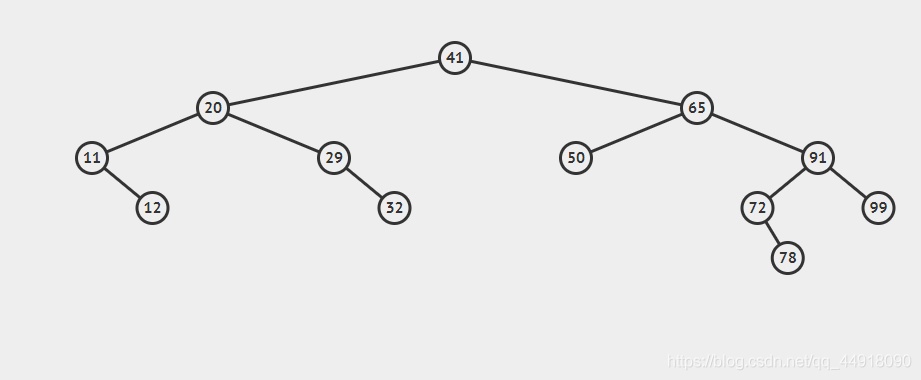

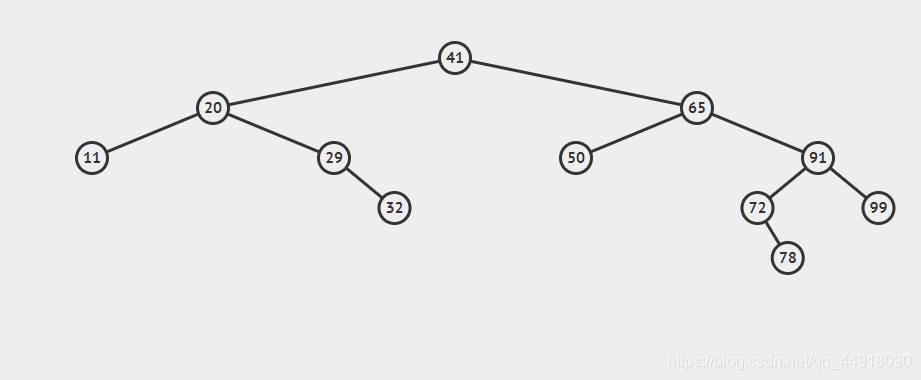

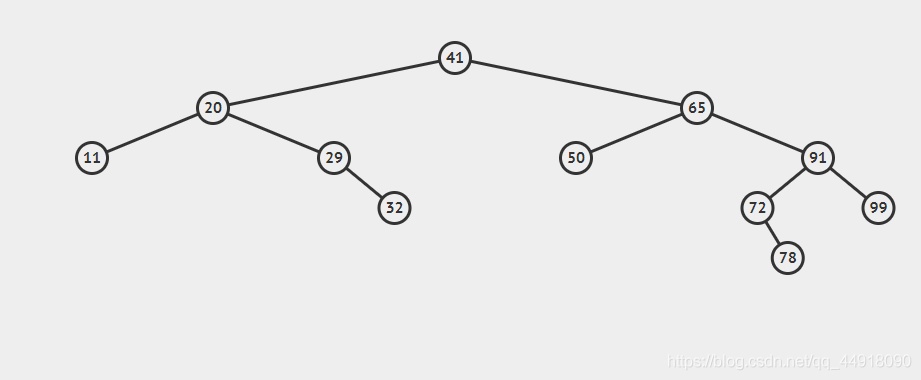

bool erase(const K& key)
{
if (_root == nullptr)
{
return false;
}
Node* cur = _root;
Node* parent = nullptr;
//先找到這個節點
while (cur)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if(key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
//1.左為空
//2.右為空
//3.左右都不為空
//找到了開始洗掉
if(cur->_left == nullptr) //左為空,父親的分情況指向我的右
{
if (cur == _root) //關鍵全部洗掉的時候
{
_root = cur->_right;
}
else
{
//parent->_right = cur->_right; 錯誤寫法
if (parent->_right == cur)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
delete cur;
//break;
}
else if (cur->_right == nullptr)//右為空,父親的分情況指向我的左
{
if (cur==_root) //關鍵,全部洗掉的時候
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
//break;
}
else
{
//這里找的右子樹最小的節點,也就是右子樹最左邊的節點
Node* RightMinParent = cur;
Node* RightMin = cur->_right;
//Node* RightMinParent = nullptr;
while (RightMin->_left)
{
RightMinParent = RightMin;
RightMin = RightMin->_left;
}
cur->_key = RightMin->_key; //賦值給_root節點
//轉換洗掉RightMin(RightMin左為空,父親指向它的右)
//RightMinParent->_left = RightMin->_right;錯誤,只判斷一次
if (RightMin == RightMinParent->_left)
{
RightMinParent->_left = RightMin->_right;
}
else
{
RightMinParent->_right = RightMin->_right;
}
delete RightMin;
}
return true;
}
}
4.二叉搜索樹的修改

3.二叉搜索樹實作
#pragma once
#include<iostream>
template<class K>
struct BSTreeNode //節點
{
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
BSTreeNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
{}
};
template<class K>
class BSTree //BinarySearchTree
{
public:
typedef BSTreeNode<K> Node;
public:
bool Insert(const K& key)
{
if (_root == nullptr) //空樹直接插入
{
_root = new Node(key);
return true;
}
//不是空樹找尋要插入的位置
Node* cur = _root;
Node* parent = nullptr; //記錄cur走過的上一個節點
while (cur)
{
parent = cur;
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return false;
}
}
cur = new Node(key);
if (key < parent->_key) //把cur節點和父節點鏈接起來
{
parent->_left = cur;
}
else
{
parent->_right = cur;
}
return true;
}
bool erase(const K& key)
{
if (_root == nullptr)
{
return false;
}
Node* cur = _root;
Node* parent = nullptr;
//先找到這個節點
while (cur)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if(key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
//1.左為空
//2.右為空
//3.左右都不為空
//找到了開始洗掉
if(cur->_left == nullptr) //左為空,父親的分情況指向我的右
{
if (cur == _root) //關鍵全部洗掉的時候
{
_root = cur->_right;
}
else
{
//parent->_right = cur->_right; 錯誤寫法
if (parent->_right == cur)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
delete cur;
//break;
}
else if (cur->_right == nullptr)//右為空,父親的分情況指向我的左
{
if (cur==_root) //關鍵,全部洗掉的時候
{
_root = cur->_left;
}
else
{
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
{
parent->_right = cur->_left;
}
}
delete cur;
//break;
}
else
{
//這里找的右子樹最小的節點,也就是右子樹最左邊的節點
Node* RightMinParent = cur;
Node* RightMin = cur->_right;
//Node* RightMinParent = nullptr;
while (RightMin->_left)
{
RightMinParent = RightMin;
RightMin = RightMin->_left;
}
cur->_key = RightMin->_key; //賦值給_root節點
//轉換洗掉RightMin(RightMin左為空,父親指向它的右)
//RightMinParent->_left = RightMin->_right;錯誤,只判斷一次
if (RightMin == RightMinParent->_left)
{
RightMinParent->_left = RightMin->_right;
}
else
{
RightMinParent->_right = RightMin->_right;
}
delete RightMin;
}
return true;
}
}
return false;
//有這個節點,就分情況討論
}
void _InOrder(Node* _root)
{
if (_root == nullptr)
{
return;
}
_InOrder(_root->_left);
std::cout << _root->_key << " ";
_InOrder(_root->_right);
}
void InOrder() //中序遍歷
{
_InOrder(_root); //類里面可以拿到_root
std::cout << std::endl;
}
Node* Find(const K& key) //查找
{
Node* cur = _root;
while (cur)
{
if (key > cur->_key)
{
cur = cur->_right;
}
else if (key < cur->_key)
{
cur = cur->_left;
}
else
{
return cur;
}
}
return cur;
}
private:
Node* _root = nullptr; //給預設值是用默認建構式初始化
};
void TestBSTree()
{
BSTree<int> BST;
int a[] = { 5, 3, 4, 1, 7, 8, 2, 6, 0, 9 };
for (size_t i = 0; i < sizeof(a) / sizeof(a[0]); i++)
{
BST.Insert(a[i]);
}
BST.InOrder();
std::cout << BST.Find(3) << std::endl;
for (auto e : a)
{
BST.InOrder();
BST.erase(e);
}
//BST.erase(8);
BST.InOrder();
//全部洗掉有問題,洗掉7也有問題
}
4.二叉搜索樹應用

- K模型:K模型即只有key作為關鍵碼,結構中只需要存盤Key即可,關鍵碼即為需要搜索到的值,比如:給一個單詞word,判斷該單詞是否拼寫正確,具體方式如下:
- 以單詞集合中的每個單詞作為key,構建一棵二叉搜索樹,
- 在二叉搜索樹中檢索該單詞是否存在,存在則拼寫正確,不存在則拼寫錯誤,
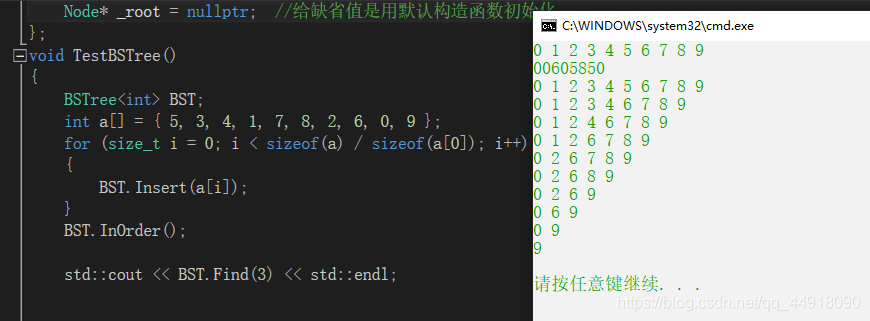
void TestBSTree()
{
BSTree<std::string, std::string> dict;
dict.Insert("sort", "排序");
dict.Insert("string", "字串");
dict.Insert("tree", "樹");
dict.Insert("vector", "順序表");
std::string str;
while (std::cin >> str)
{
BSTreeNode<std::string, std::string>* ret = dict.Find(str); //節點的指標
if (ret)
{
std::cout << ret->_value << std::endl;
}
else
{
std::cout << "沒有這個單詞" << std::endl;
}
}
}
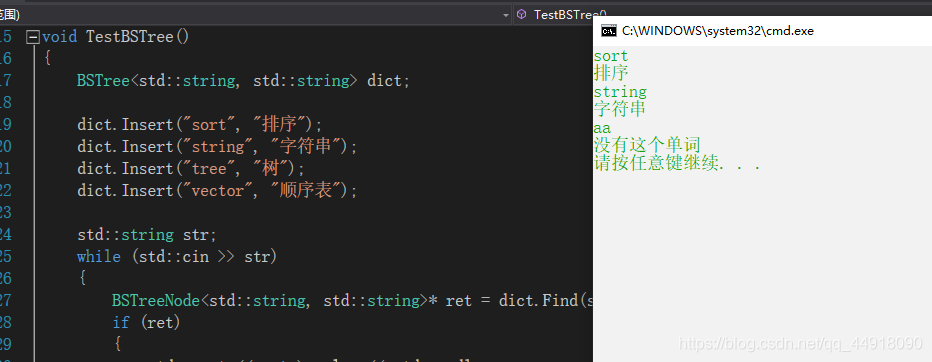
- KV模型:每一個關鍵碼key,都有與之對應的值Value,即<Key, Value>的鍵值對,該種方式在現實生活中非常常見:比如英漢詞典就是英文與中文的對應關系,通過英文可以快速找到與其對應的中文,英文單詞與其對應的中文<word, chinese>就構成一種鍵值對;再比如統計單詞次數,統計成功后,給定單詞就可快速找到其出現的次數,單詞與其出現次數就是<word, count>就構成一種鍵值對,比如:實作一個簡單的英漢詞典dict,可以通過英文找到與其對應的中文,具體實作方式如下:
- <單詞,中文含義>為鍵值對構造二叉搜索樹,注意:二叉搜索樹需要比較,鍵值對比較時只比較Key,
- 查詢英文單詞時,只需給出英文單詞,就可快速找到與其對應的key,
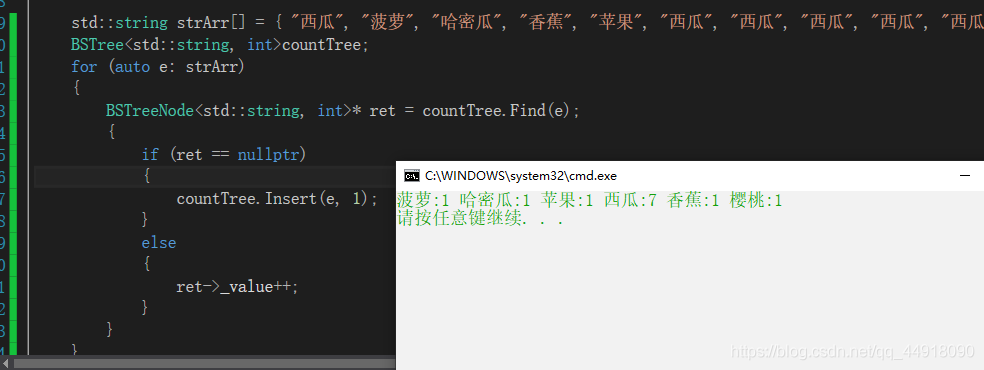
void TestBSTree()
{
std::string strArr[] = { "西瓜", "菠蘿", "哈密瓜", "香蕉", "蘋果", "西瓜", "西瓜", "西瓜", "西瓜", "西瓜", "西瓜", "櫻桃" };
BSTree<std::string, int>countTree;
for (auto e: strArr)
{
BSTreeNode<std::string, int>* ret = countTree.Find(e);
{
if (ret == nullptr)
{
countTree.Insert(e, 1);
}
else
{
ret->_value++;
}
}
}
countTree.InOrder();
}
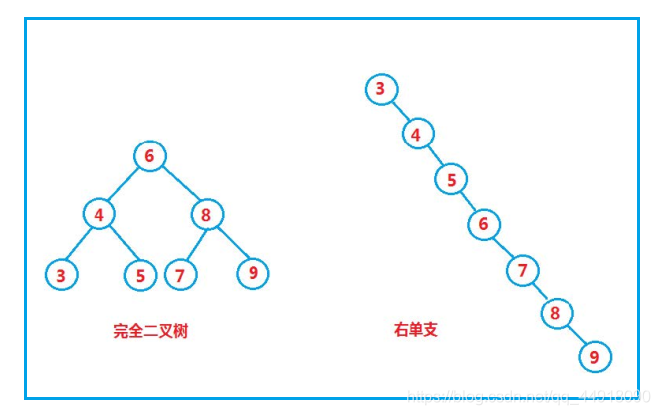
5.二叉搜索樹的性能分析
插入和洗掉操作都必須先查找,查找效率代表了二叉搜索樹中各個操作的性能,
對有n個結點的二叉搜索樹,若每個元素查找的概率相等,則二叉搜索樹平均查找長度是結點在二叉搜索樹的深度的函式,即結點越深,則比較次數越多,
但對于同一個關鍵碼集合,如果各關鍵碼插入的次序不同,可能得到不同結構的二叉搜索樹:


總結
以上就是今天要講的內容,本文介紹了二叉搜索樹的使用,而二叉搜索樹查找提供了大量能使我們快速便捷地處理資料的函式和方法,我們務必掌握,另外如果上述有任何問題,請懂哥指教,不過沒關系,主要是自己能堅持,更希望有一起學習的同學可以幫我指正,但是如果可以請溫柔一點跟我講,愛與和平是永遠的主題,愛各位了,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290087.html
標籤:其他
上一篇:LINUX03_磁盤情況查詢、ps -ef、centos7查看服務、netstat查看網路、grep、重定向、管道、yum、用戶權限