目錄
VisualDL可視化功能的使用
VisualDL可視化結果
預處理和后處理對齊
部署流程概括
準備環境,安裝好CMake、OpenCV等工具
準備PaddleLite推理庫
準備模型
構建并運行程式
總結
參考檸檬分類范例
兩點:
- 模型的輸入與輸出
- 模型的預處理與后處理
如果你想了解一個陌生模型的輸入與輸出該怎么做呢?可以使用VisualDL的模型可視化功能觀察模型的輸入與輸出,
如果你想了解一個陌生模型的預處理,后處理,該怎么做呢?以PaddleHub上的預訓練模型為例,我們可以去閱讀這個模型在Paddlehub上的源代碼來了解它的預處理,后處理,
如果你無法得知模型的輸入與輸出、預處理與后處理,那么你是無法進行模型部署的,
部署時預處理與后處理與訓練時對齊,這是部署時的難點,而不是部署框架使用的本身,
部署的原則,即與訓練對齊,
為了進行部署,我們首先需要了解模型的輸入與輸出,及他的預處理和后處理,這些仍可以通過PaddlePaddle進行,
VisualDL可視化功能的使用
在代碼中插入visualDL日志官方代碼:
from visualdl import LogWriter
if __name__ == '__main__':
value = [i/1000.0 for i in range(1000)]
# 初始化一個記錄器
with LogWriter(logdir="./log/scalar_test/train") as writer:
for step in range(1000):
# 向記錄器添加一個tag為`acc`的資料
writer.add_scalar(tag="acc", step=step, value=value[step])
# 向記錄器添加一個tag為`loss`的資料
writer.add_scalar(tag="loss", step=step, value=1/(value[step] + 1))點擊可視化板塊,選擇存盤日志目錄,選擇模型檔案,即可得到visualDL結果,
VisualDL可視化結果
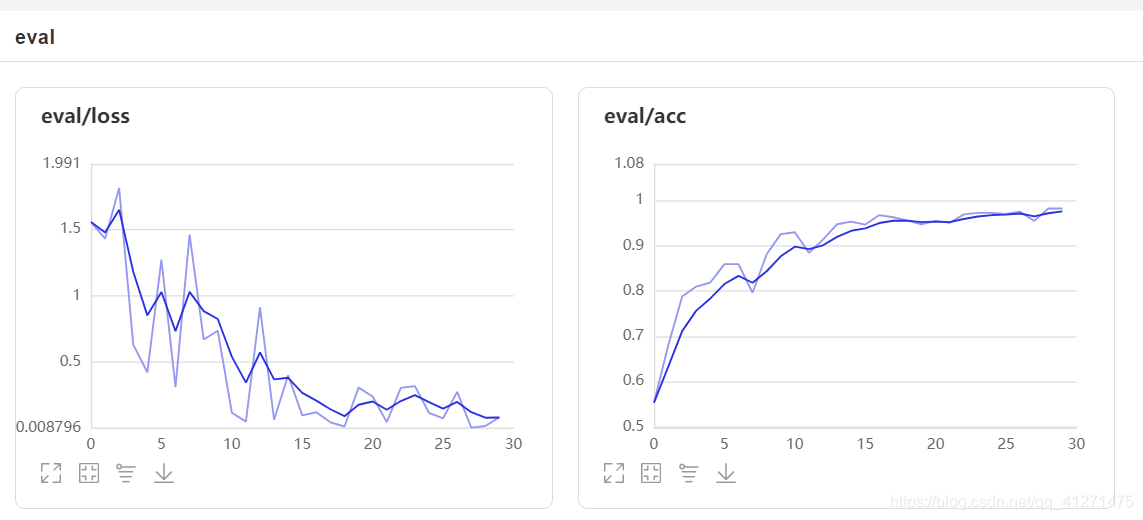
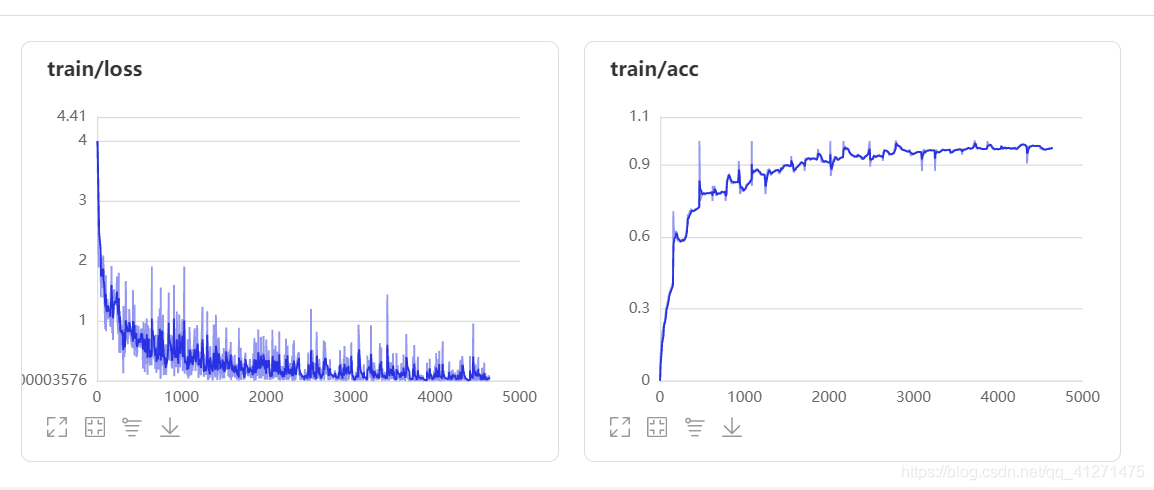
根據結果可以看到模型的訓練和測驗結果的準確率上升,超過0.9,且loss下降至0.1以下,可以判定模型是合適的,
使用visualDL的網路結構功能,可以看到模型的輸入和輸出,
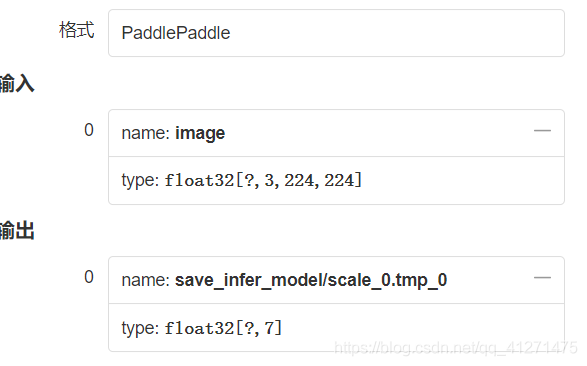
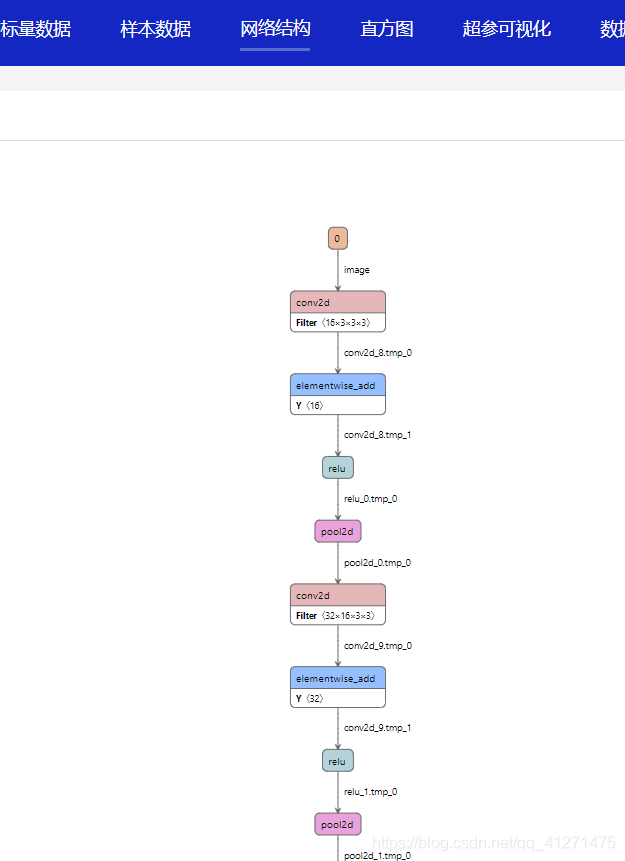
預處理和后處理對齊
對于影像的預處理部分,還有許多不解,比如資料庫的圖片大小設定錯了,嘗試在代碼上進行改動后,總是會有各種原因的報錯,而且專案里似乎并沒有后處理的部分,明天專門解決這部分的問題,
部署流程概括
準備環境,安裝好CMake、OpenCV等工具
- C++準備環境:
主要安裝OpenCV3.2.0(推薦3.2)與CMake3.10
sudo apt-get update sudo apt-get install gcc g++ make wget unzip libopencv-dev pkg-config wget https://www.cmake.org/files/v3.10/cmake-3.10.3.tar.gz tar -zxvf cmake-3.10.3.tar.gz cd cmake-3.10.3 ./configure make sudo make install
- Python環境準備:
主要是安裝,numpy(1.13.3),Pillow(8.1.0),matplotlib(2.1.1),OpenCV(3.2.0)(推薦3.2)
以上工具版本號僅供參考,非必須對齊,
優先推薦通過pip3 install xxx安裝numpy,Pillow,matplotlib,OpenCV,pip install numpy==1.13.3 pillow==8.1.0 matplotlib==2.1.1 opencv=3.2.0安裝matplotlib,OpenCV可能遇到報錯,無需慌張,可
apt install python3-dev后再次使用pip安裝,若依舊不成功可使用apt install python3-matplotlib,apt install python3-opencv安裝,配置好環境后稍后克隆一份部署Lemon原始碼,進入
cd ./lemon/wheels檔案夾后pip3 install paddlelite-2.8rc0-cp36-cp36m-linux_aarch64.whl(根據自己的Python版本選擇,提供了Python2.7,3.5,3.6,3.7的包)
部署代碼示例,這是接下來作業需要重點理解的地方,
git clone https://github.com/hang245141253/lemon.git
準備PaddleLite推理庫
樹莓派3blinux64位使用如下推理庫,extra.tar含有模型的flatten算子,
下載網址https://github.com/PaddlePaddle/Paddle-Lite/releases/

uname -a 命令可知系統位數,
準備模型
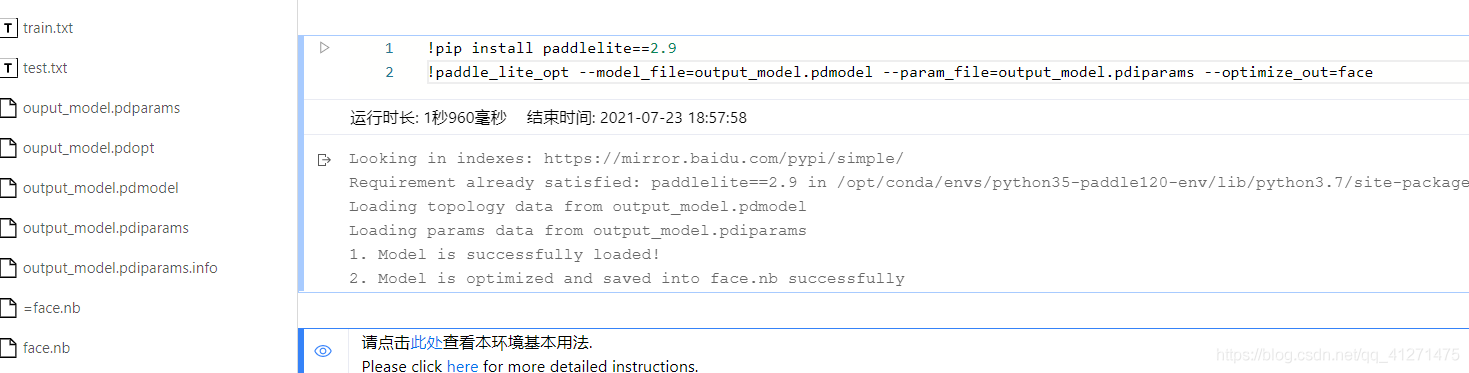
- 使用opt工具將Paddle模型轉化成Paddle Lite nb模型 這里已經將opt工具作為資料集形式上傳到了Notebook中,只需執行如下代碼即可完成模型轉化,
!pip install paddlelite==2.9
!paddle_lite_opt --model_file=output.pdmodel --param_file=output.pdiparams --optimize_out==face一開始會報錯
Check failed: (idx < BlocksSize()): 0!<0 idx >= blocks.size() Aborted (core dumped)
后來發現model保存的是用于預測的而沒有save用來部署的模型,
model.save('infer/zodiac')#模型用來預測
model_2.save('infer/zodiac', training=False)#模型用來部署重新保存一份模型,得到需要的Paddle Lite nb 模型,
構建并運行程式
這一步因為C++會直接在暫存器上進行操作,比python封裝好的各種函式運行速度更快,我們選擇C++進行部署,接下來需要學習C++的基本知識,
總結
雖然模型達到了較好的準確率,但是經過這幾天的學習,我們發現整個學習的重點,即資料的預處理和后處理,仍然沒有研究明白,這會在部署的時候給我們帶來阻礙,
接下來首先要在模型的預處理上作出改變,確定后處理與其對齊,
另外則需要進行C++的學習,為部署做準備,
參考檸檬分類范例
https://aistudio.baidu.com/aistudio/projectdetail/1592283
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290196.html
標籤:其他
上一篇:最新Pycharm安裝呼叫opencv-python步驟,以及遇到的問題: opencv已經安裝成功;cmd環境下python可以import cv2 ;但pycharm下會出錯