這是我在b站上2021最新左神資料結構演算法全家桶這個視頻上學習的排序演算法,感覺挺不錯的
在這里和大家分享一下
1. 選擇排序
1.1 選擇排序的思想
參考左神畫的圖:
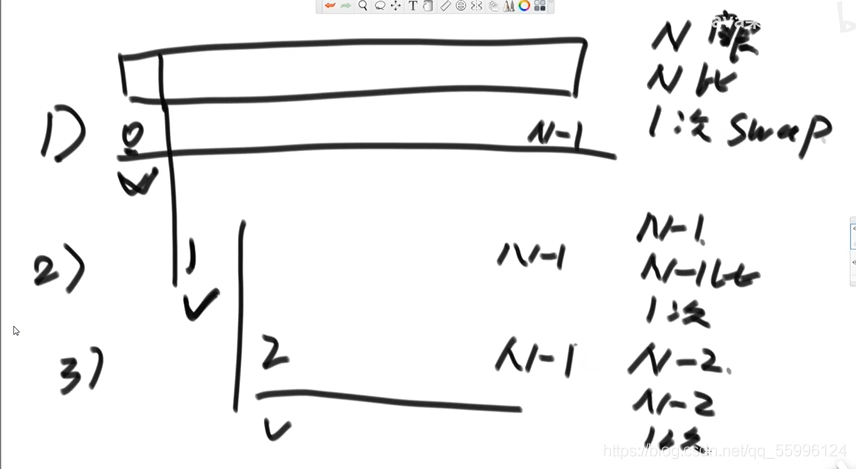
(1)從頭(下標0位置)遍歷一遍陣列找到最小值,和下標位0位置上的資料交換,此時0位置的資料就固定是最小值了
(2)從下標1位置開始(0位置已經固定就不用考慮了)再次遍歷一遍陣列,找到最小值,和下標為1位置上的資料交換,此時1位置的資料也就固定了
(3)從下標2位置開始(0、1位置都已經固定)再次遍歷一遍陣列,找到最小值,和下標為2位置上的資料交換,此時2位置的資料也就固定了......
一直這樣回圈直到最后一個值,此時就完成了排序
1.2 時間復雜度
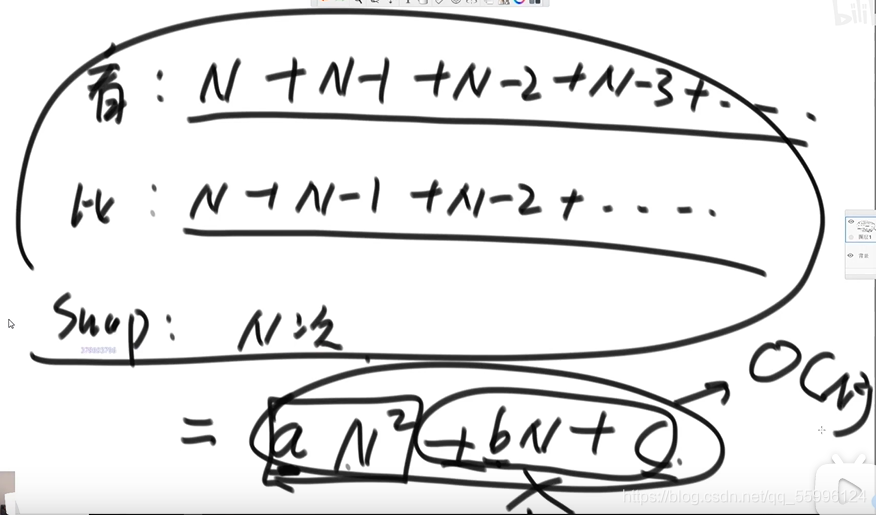
時間復雜度為O(N^2)
可以看出常數操作的次數為一個等引數列 aN^2 + bN +C 我們只考慮最高項就是N^2
一個操作如果和樣本的資料量沒有關系,每次都是固定時間內完成的操作,叫做常數操作,
空間復雜度:O(1) 開辟的額外空間:數i , j 變數minIndex(每次回圈都釋放)
1.3 代碼實作
左神的代碼:
public static void selectionSort(int arr[]){
//如果陣列為慷訓者陣列長度小于2,那么不需要排序直接回傳
if(arr == null || arr.length < 2){
return;
}
//陣列長度大于等于2則開始排序
for (int i = 0; i < arr.length -1; i++){ // 從i ~ N-1上依次給陣列重新賦值
int minIndex = i; //先假設i位置上最小
for (int j = i + 1; j < arr.length; j++){ // 從i ~ N-1上找最小值的下標
minIndex = arr[j] < arr[minIndex] ? j : minIndex;
}
// i和最小值下標交換,則i位置上就是最小值,此時i就固定了,i++從下個位置繼續
swap(arr, i, minIndex);
}
}
//交換資料
public static void swap(int[] arr, int i, int j){
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}代碼思想:
選擇排序是從前往后排序
(1)先假設 i 位置上最小,賦給minIndex
(2)【內層回圈】從(i ~ N-1)上找最小值,拿這個值和當前的minIndex比較 ,如果小則把這個值重新賦給minIndex,大則不動,再找下一個值,直到N-1
(3)【外層回圈】內回圈進行一次就確定了一個最小值,下一次就不用考慮這個值了,所以 i++
2. 冒泡排序
2.1 冒泡排序思想
依舊看左神畫的圖:
(1)陣列的值在橫線上面,索引在橫線下面
(2)從索引0開始,依次進行兩兩比較直到最后一個資料,前一個位置比后一個位置小則不動,大則交換,整個陣列比較完畢后,最后位置的值就是最大的,此時最后位置索引的值固定不變
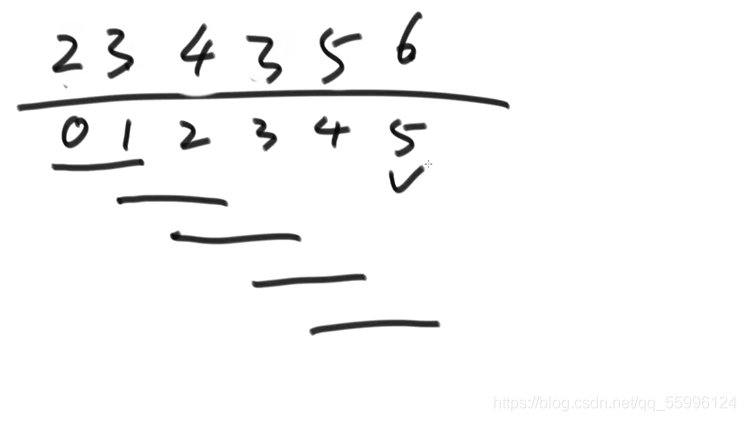
(3)再次從索引0開始,依次進行兩兩比較,直到倒數第二個資料,再次比較完后此時倒數第二個索引的值也固定不變......
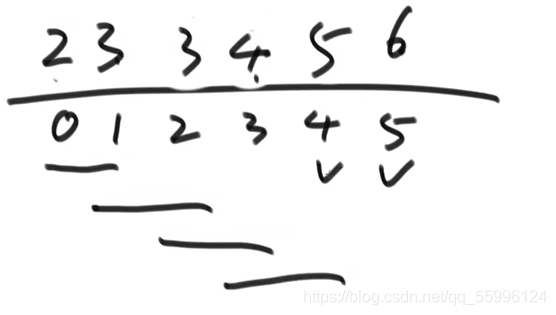
(4)一直回圈直到索引位置1的值也固定,此時就排序完畢了
2.2 時間復雜度
時間復雜度為O(N^2)
可以看出常數操作的次數為一個等引數列 aN^2 + bN +C 我們只考慮最高項就是N^2

2.3 代碼實作
左神的代碼:
public static void bubbleSort(int[] arr){
if(arr == null || arr.length < 2){
return;
}
for(int end = arr.length - 1; end > 0; end--){ // 從0~end進行排序,每次排序固定最后一個位置,end--
for(int i = 0; i < end; i++){ //每次從0~end進行兩兩比較
if (arr[i] > arr[i + 1]){ //前一個位置比后一個位置大則交換
swap(arr, i, i+1);
}
}
}
}
//交換arr的i和j位置上的值,利用異或機制
public static void swap(int[] arr, int i, int j){
arr[i] = arr[i] ^ arr [j];
arr[j] = arr[i] ^ arr [j];
arr[i] = arr[i] ^ arr [j];
}代碼思想:
冒泡排序是從后往前排序
(1)先初始化一個end來指向最后一個資料,保存陣列中值最大的資料
(2)【內層循換】找最大值,從(0~end)范圍內進行兩兩比較,前一個位置比后一個位置大則交換,一輪回圈完畢后end索引就保存的是最大值了
(3)【外層回圈】內回圈進行一次就確定了一個最大值,此時就不用考慮這個值了,所以給end--
2.4 利用異或機制交換陣列
其中交換陣列位置利用了異或機制(超級帥):
左神畫的圖解:
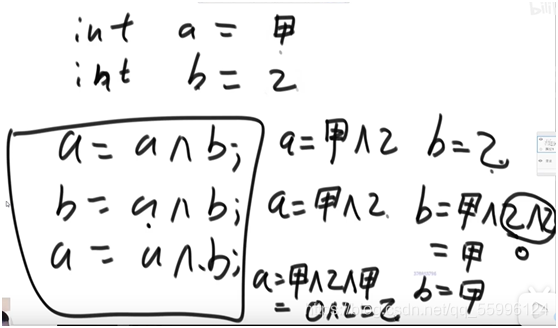
注:必須是兩塊不同記憶體的資料才可以用,相同記憶體異或會把資料洗為0
3. 插入排序
3.1 插入排序思想
(1)先做到0~0范圍上有序,自然做到了
(2)要做到0~1范圍上有序,指標指到索引1上,資料值和前面的依次比較,大則不動,小則交換,換到比前面數值都大或前面沒資料時停止,比較完畢后0~1范圍內就是有序的了
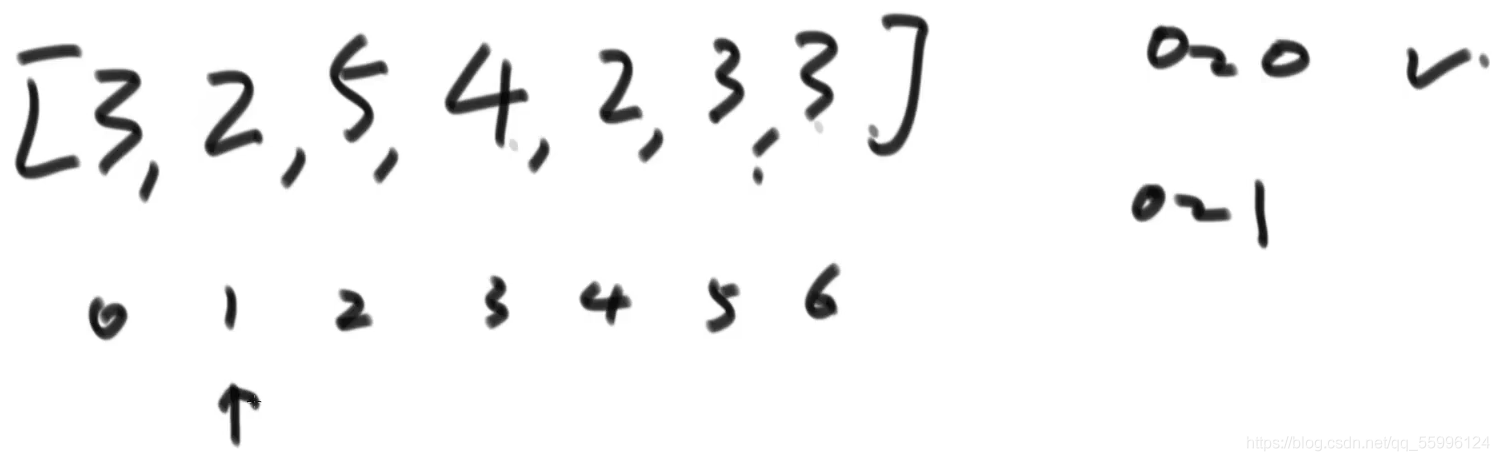
交換后:
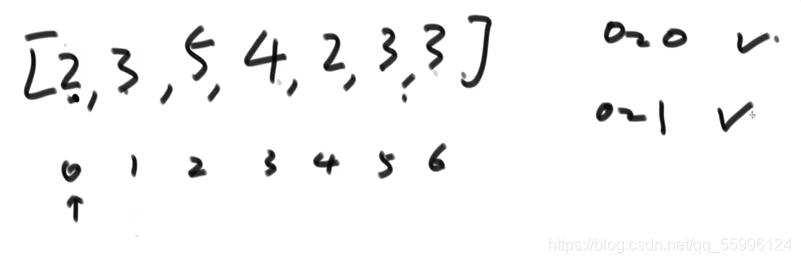
(3) 要做到0~2范圍上有序,指標指到索引2上,資料值和前面的依次比較,大則不動,小則交換,換到比前面數值都大或前面沒資料時停止,比較完畢后0~2范圍內就是有序的了
(4)要做到0~3范圍上有序,指標指到索引3上,資料值和前面的依次比較,大則不動,小則交換,換到比前面數值都大或前面沒資料時停止,比較完畢后0~3范圍內就是有序的了......
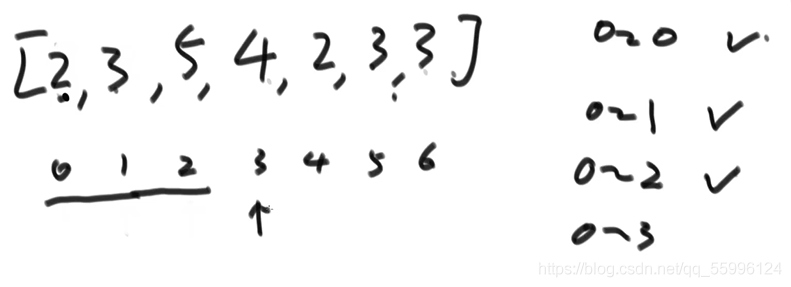
交換后:
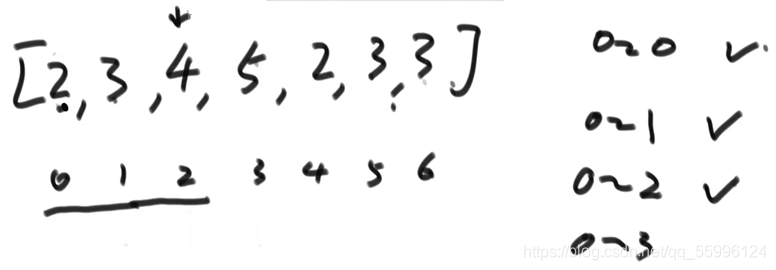
(5)重復回圈直到最后一個數也比較完畢并停止,此時0~n范圍內就是有序的,排序完畢
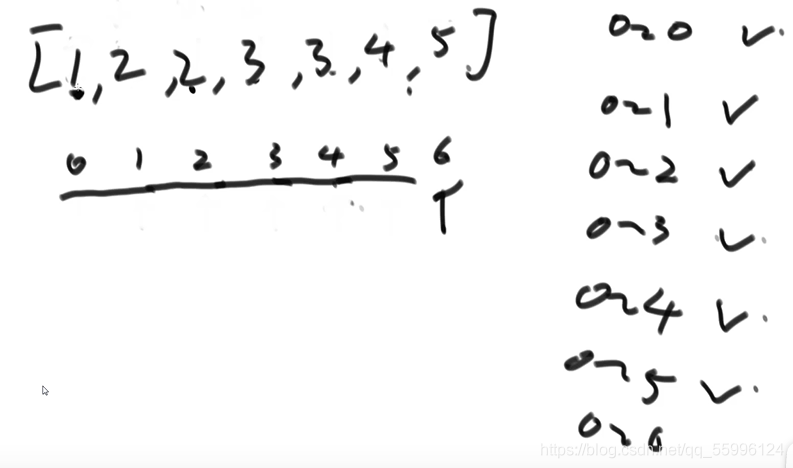
左神的抽象理解法:玩撲克牌
一副手牌按從左到右升序排列,抓到新的牌從右往左滑,滑到它前面的牌面都比它小則插入進去,再抓下一張牌繼續

3.2 時間復雜度
時間復雜度為O(N^2)
可以看出常數操作的次數為一個等引數列 aN^2 + bN +C 我們只考慮最高項就是N^2
3.3 代碼實作
public static void insertSort(int[] arr){
if(arr == null || arr.length < 2){
return;
}
//0~0是天然有序的
//0~1想有序
for (int i = 1; i < arr.length; i++){
for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--){
swap(arr, j, j + 1);
}
}
}
//交換資料
public static void swap(int[] arr, int i, int j){
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}左神圖解兩層回圈:
判斷的是 0~i 位置上的資料,那么(0~i-1)范圍內得資料就是之前排好的,i 相當于新來的數
令 j 取 i-1 上的數,那么當前數 i 就處在 j+1 位置上,此時進行比較若 [j]>[j+1] , 則交換
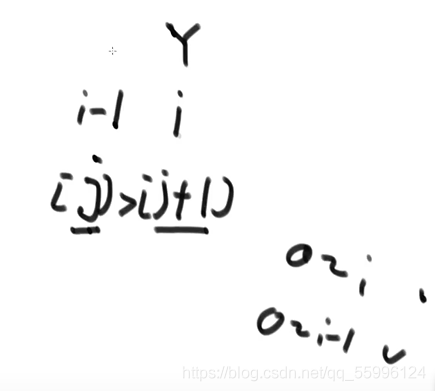
此時當前數 i 就交換到了 i-1 位置上 ,給j--則現在 j 取 i-2 上的數,而此時當前數 i 仍處于 j+1 位置上(事實是當前數永遠處于 j+1 位置上),再比較若 [j]>[j+1] , 則交換,直到當前數 i 大于前一個數或者 i 到索引0位置上停止回圈,此時 0~i 范圍內就有序了
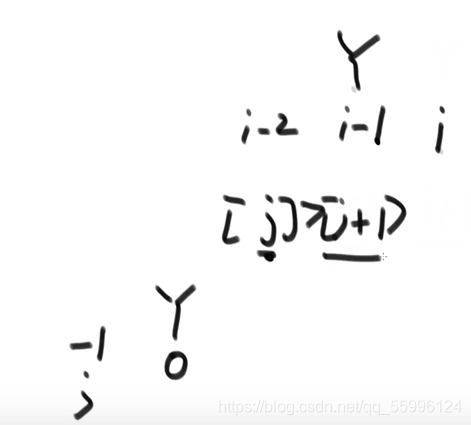
二分查找
1. 二分查找的三個使用策略
1.1在一個有序陣列中,找某個數是否存在
(1)先找出陣列的中間值mid,和目標值target進行比較
(2)若 mid > target ,說明陣列后一半肯定沒有目標值target,若 mid < target ,說明陣列前一半肯定沒有目標值target
(3)繼續二分找中間值mid再和目標值target比較直到 mid=target ,此時就找到了,否則陣列中沒有該資料
時間復雜度:O(logN)
可以看出每一次查找都是把陣列折一半,最差的情況就是折到陣列僅剩1個元素,一共需要折logN次(以二為底)
如陣列長度為8 那么 8-->4-->2-->1,需要3次,陣列為16 那么 16-->8-->4-->2-->1,需要4次
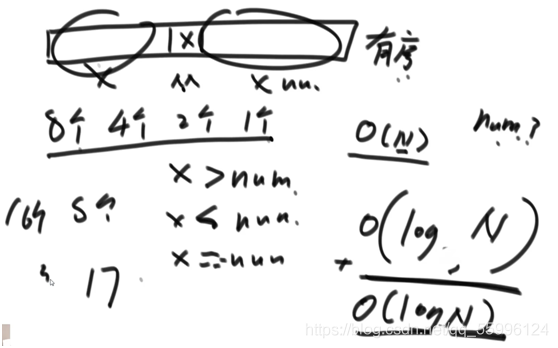
1.2 在一個有序陣列中,找>=某個數最左側的位置
(1)先找到陣列中間位置,和目標值num進行比較
(2)若中間值>=num,則說明目標值num在包括中間值的左邊,此時標記中間值的索引為r,
繼續在0~r上二分找中間點,若中間點< num,則說明目標值在右邊,標記中間值為l,
繼續在l~r上二分找中間點,若中間點 > num,則說明目標值在左邊,此時把新中間點賦給r
(3)一直回圈只要是中間點 > num,就把新中間點賦給r,一直縮進右邊界逼近到只剩下一個值此時就找到了目標值
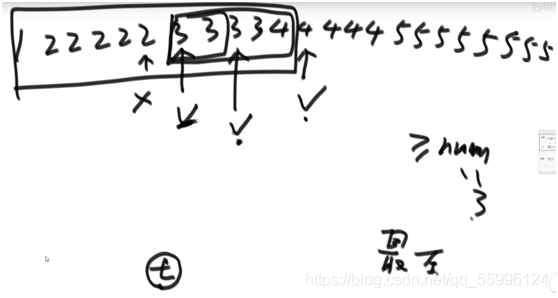
1.3 區域最小值問題(可以是無序陣列)
區域最小的定義:
(1)兩端點情況下,只要端點小于相鄰數(只有一個)就是區域最小數
(2)非端點情況下,必須同時小于左右兩個相鄰數時才是區域最小數
思路:
(1)若兩端點都不是區域最小時,此時可以模擬函式影像,兩端朝中間一定都是遞減的
(2)二分找到中間點,中間點左右兩端至少會有一個遞減的,此時兩個反向遞減的內部必有至少一個拐點,任意一個拐點就是區域最小值
(3)回圈進行二分直到找到拐點,此時就得到了區域最小值
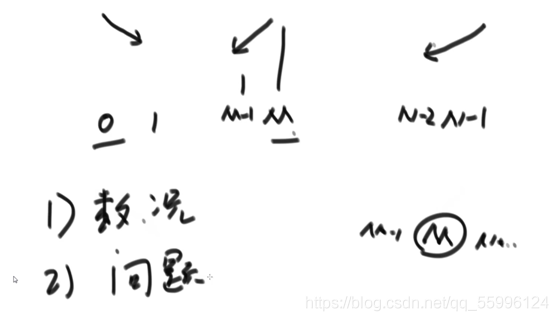
4. 歸并排序
4.1 歸并排序思想
(1)二分陣列找到中間點M
(2)先讓陣列左側資料(L~M)排好序,再讓陣列右側資料(M~R)排好序(遞回思想)
(3)最后把陣列左右兩側資料合并merge起來(整體排序)
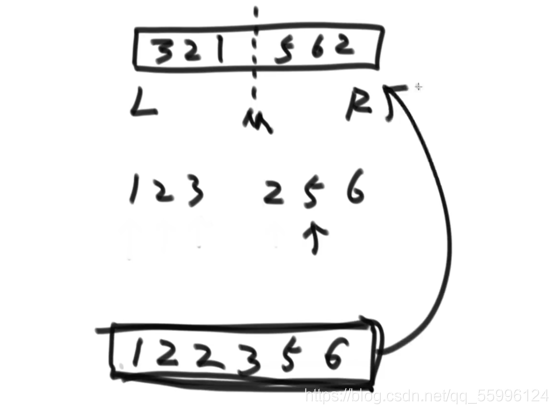
合并merge的方法:
(1)先給左右兩側的半陣列的首元素索引分別設為 p1、p2
(2)初始化一個輔助陣列help(用來存放排序好的元素),回圈比較 p1、p2 指向的元素,把較小的那個賦給輔助陣列help的 i 位置上,然后 i++ ,較小元素的索引++,進行下一次回圈
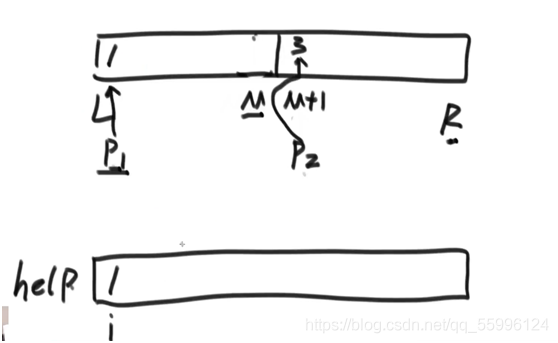
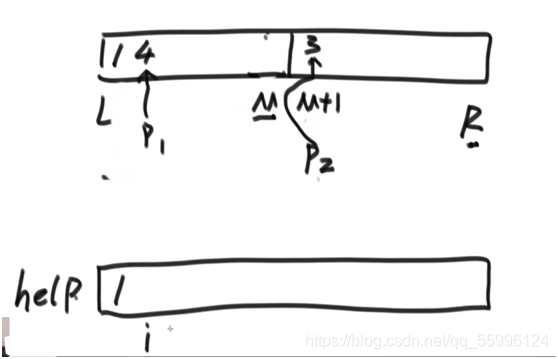
如上圖,p1指向的元素較小,則把p1指向的元素賦給help的索引 i 上,i++,p1++,p2不變
(3)回圈直到p1,p2其中一個越界(必然發生),沒越界的那一側把剩下的元素按順序(已排序好)賦給輔助陣列help
(4)最后把輔助陣列的元素依次賦給主陣列就完成了排序
4.2 時間復雜度
歸并排序的時間復雜度為:O(N*logN)
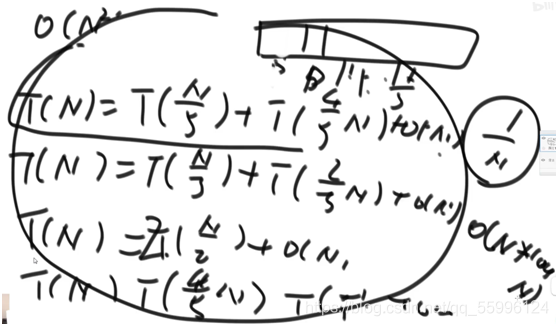
利用master公式:T(N) = aT(N/b) + O(N^d)
master公式
看左神畫的圖: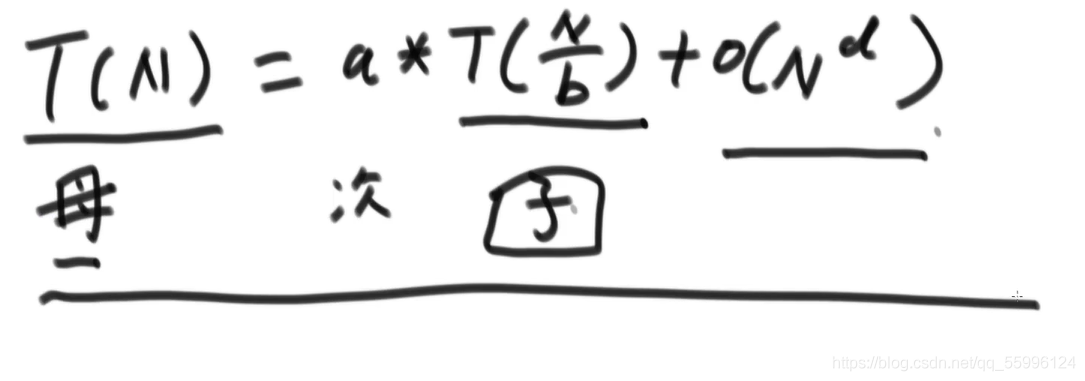
T(N):代表母問題有N個資料(規模是N)
a:代表子問題被呼叫的次數
T(N/b):代表每一個子問題都是(N/b)規模的子問題(子問題規模是等量的)
O(N^d):代表除了子問題的呼叫外,剩下程序的時間復雜度
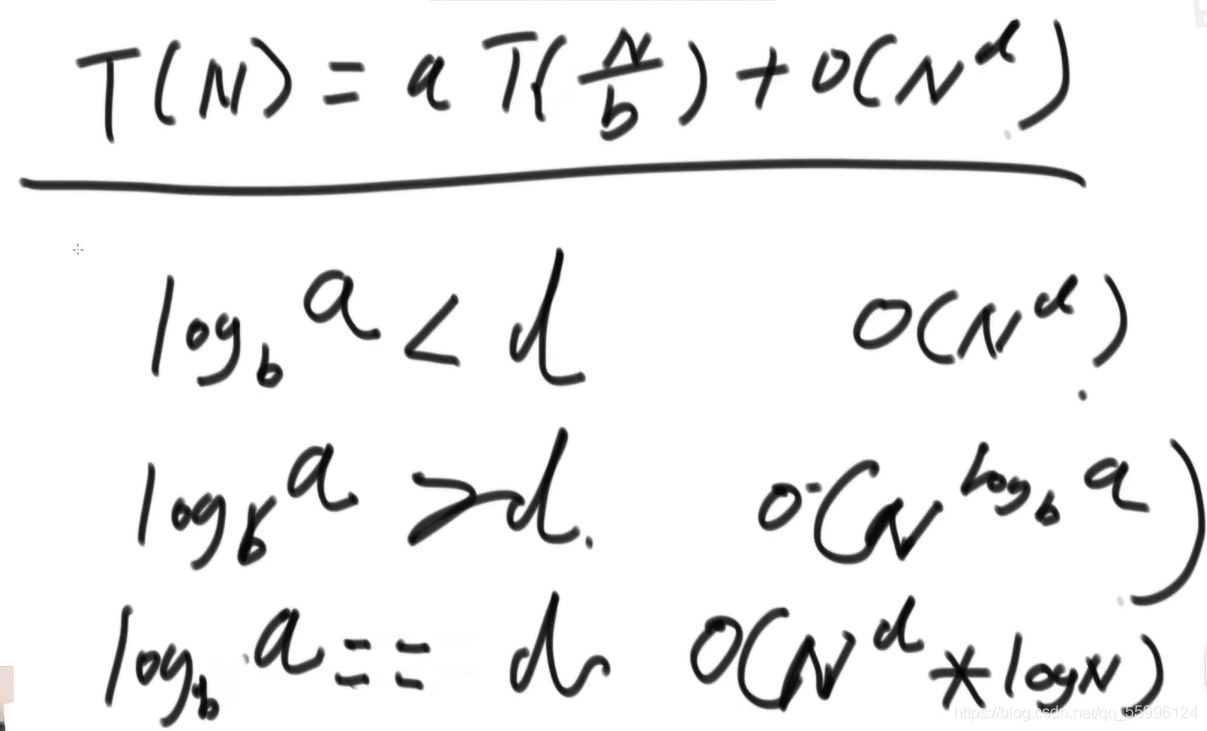
三種情況的復雜度(前人證明好的)
-----------------------------------------------------------------------------------------------------------
利用master公式:T(N) = aT(N/b) + O(N^d)
歸并排序中 子問題 一次處理 一半 母問題 的資料,因此子問題規模N/2,一次遞回執行兩次子問題,因此a=2,剩下都是常數操作為O(N),因此d=1
此時![]() ,符合
,符合![]() ,因此時間復雜度為O(N*logN)
,因此時間復雜度為O(N*logN)
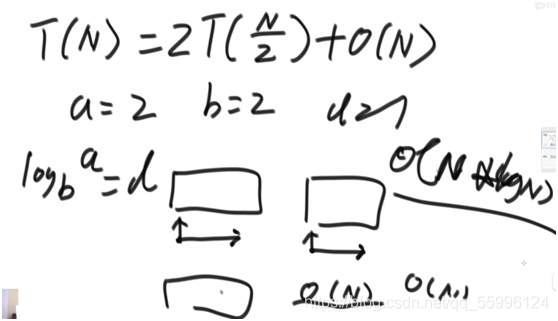
本質原理:
每一次進行的排序都是可重復利用的,每一次排序的結果都會作為下一次排序的部分內容再次進行排序,而且在merge方法中每一次進行比較都會確定一個元素的位置,不會造成浪費
4.3 代碼實作
public static void mergeSort(int[] arr){
if(arr == null || arr.length < 2){
return;
}
process(arr, 0, arr.length -1);
}
public static void process(int[] arr, int L, int R){
if(L == R){ //此時只有一個數直接跳出
return;
}
int mid = L + ((R - L) >> 1){ //不斷求中點逼近到最左端
process(arr, L, mid); //陣列左半側遞回
process(arr, mid + 1, R); //陣列右半側遞回
merge(arr, L, mid, R); //左右兩側合并
}
}
public static void merge(int[] arr, int L, int M, int R){
int[] help = new int[R - L +1]; //每一層遞回都有一個help,長度為左右端點索引的差+1
int i = 0; //輔助陣列從0開始
int p1 = L; //左半側陣列從原陣列左端L開始
int p2 = M + 1; //右半側陣列從中點M+1開始
while (p1 < M && p2 <= R){//回圈比較左右兩側元素,較小元素賦給i,i++,較小元素索引++
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
while (p1 <= M){ //若p1沒有越界,把剩下元素回圈賦給help
help[i++] = arr[p1++];
}
while (p2 <= R){ //若p2沒有越界,把剩下元素回圈賦給help
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++){ //把help元素依次回傳賦給arr
arr[L + i] = help[i];
}
}代碼遞回思想:
(1)process方法就是讓傳入的陣列有序,利用遞回行為不斷呼叫自身,一直二分取左半部分不斷逼近直到取到左端點
(2)此時遞回到底層,只剩1個資料因此L==R,跳出到遞回倒數第二層執行右半側遞回(倒數第二層必定只有2個元素因此右半側也會直接跳出),此時左右側遞回都跳出然后就可以執行merge方法了
(3)merge執行完倒數第二層遞回也就順序執行完畢,回傳倒數第三層遞回(倒數第三層只會有3個或4個元素),若是3個則右側只有一個元素直接跳出,若是4個則右側有兩個元素再次進入遞回直到回傳到該層(倒數第三層),此時左右兩側遞回都完畢(回傳上層時左側都是遞回完畢的只用考慮右側,因為每一層回傳的結果都是上層的左側)就可以執行merge方法了,繼續遞回直到跳出到最上層,此時左右兩側merge的結果就是整個陣列了
5. 快速排序
5.1 快速排序思想
快排1.0
(1)選擇陣列最后一個數(索引最大)作為劃分值,記為num
(2)讓陣列除去最后一個值的前一段區域中的值做到小于等于(<=)num的都放在num左邊, >(大于)num的都放在num右邊,把陣列分成兩部分
(3)把num和大于num區域的第一個資料做交換,此時相當于<=num區域擴充1個位置并且最后一個數一定是num(num也是最大的),剩下的都是>區域的,此時認為num這個位置就排好了
(4)num位置已經固定,<=num區域取最后一個位置作為劃分值,>num區域取最后一個值作為劃分值,不斷遞回這個程序,每一次遞回都會確定一個位置,所以遞回到最后就是有序的了
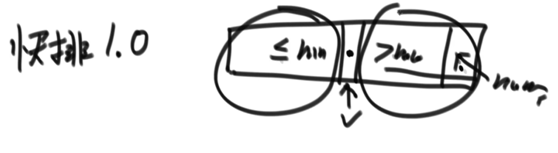
例子:
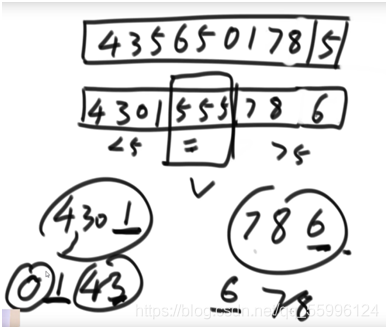
劃分值num為5,>5區域的第一個值設為6,5和6交換就可以確定出num的位置,左右兩側重復遞回
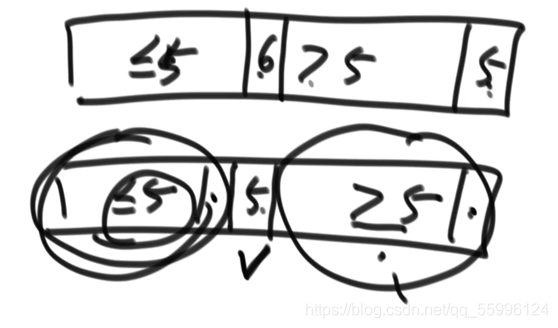
時間復雜度
快排1.0時間復雜度為:O(N^2)
最差的情況下是每一次的劃分值都是當前陣列最大值,劃分后只有左側資料沒有右側資料,相當于每一次都處理(n - i)個資料
可以看出常數操作的次數為一個等引數列 aN^2 + bN +C 我們只考慮最高項就是N^2
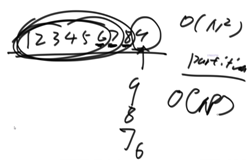
最好情況是劃分值打到幾乎中間的位置
使用master公式可以得出最佳時間復雜度是O(N*logN)
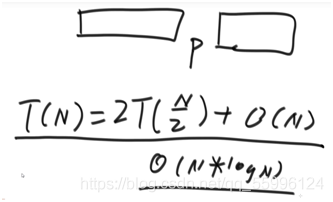
快排2.0
快排2.0比快排1.0稍快一些
在快排1.0的基礎上進行改進:
(1)把陣列分成三個部分,即左側放<num的區域,中間放=num的區域,右側放>num的區域
(2)>num區域的最后一個值作為劃分值,把num和大于num區域的第一個資料做交換,這樣等于num的資料就都靠在一起了,等于num的區域就固定了,相當于搞定了一批資料,
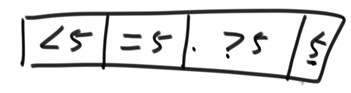
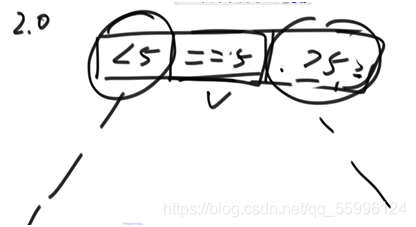
例子:
時間復雜度
和快排1.0是一樣的
快排2.0時間復雜度為:O(N^2)
最差的情況下是每一次的劃分值都是當前陣列最大值,劃分后只有左側資料沒有右側資料,相當于每一次都處理(n - i)個資料
可以看出常數操作的次數為一個等引數列 aN^2 + bN +C 我們只考慮最高項就是N^2
最好情況是劃分值打到幾乎中間的位置
使用master公式可以得出最佳時間復雜度是O(N*logN)
快排3.0
在快排1.0的基礎上進行優化:
在陣列中隨機取一個數和最后一個值交換,然后拿它作為劃分值

5.2 時間復雜度(快排3.0):
快排3.0的時間復雜度為:O(N*logN)
因為選取每一個位置都是等概率事件,所以每一個master公式出現也是等概率事件(權重1/N),
把所有mastr公式求概率累加再求數學上的長期期望得出時間復雜度為O(N*logN)
空間復雜度:
空間復雜度為O(N)
最差情況下一共開辟了n層遞回區域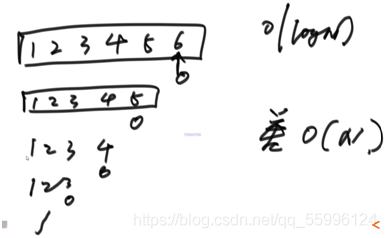
5.3 代碼實作(快排3.0):
public static void quickSort(int[] arr){
if(arr == null || arr.length < 2){
return;
}
quickSort(arr, 0, arr.length -1);
}
public static void quickSort(int[] arr, int L, int R){
if(L < R){
swap(arr, L + (int)(Math.random() * (R - L +1)), R);//在陣列中等概率選一個數,math.random左閉右開,所以R-L+1
int[] p = partition(arr, L ,R);//此時最后一個數R就是選出來的數作為劃分值,回傳值
//為劃分值==區域的左邊界和右邊界(一定是長度為2的
//陣列)
quickSort(arr, L, p[0] - 1);//<劃分值區域上的最后一個數
quickSort(arr, p[1] + 1, R);//>劃分值區域上的第一個數
}
}
//這是一個處理arr[l..r]的函式
//默認以arr[r]做劃分,arr[r] -> p <p ==p >p
//回傳等于區域(左邊界,右邊界),所以回傳一個長度為2的陣列res,res[0] res[1]
public static int[] partition(int[] arr, int L, int R){
int less = L - 1; // <劃分值區間的右邊界,從i的前一個數開始向右側逼近
int more = R; // >劃分值區間的左邊界,從r開始(考慮的是除去最后一個值的前一個區域中的值)向左逼近
while(L < more){ // L=more時當前數和>劃分值區間的左邊界碰到,此時L右側就都是>劃分值的數了
if(arr[L] < arr[R]){ // 當前數 < 劃分值
swap(arr, ++less, L++); //當前數和右邊界后一個位置交換,并且L++
}else if (arr[L] > arr[R]) { // 當前數 > 劃分值
swap(arr, --more, L); //當前數和左邊界前一個位置交換,此時L不變
}else {
L++; //當前數 = 劃分值,直接跳過,L++
}
}
// 回圈完畢后已經把劃分值前面的資料按三層(小等大)排好了,此時more指向>劃分值區間的第一個數
// 交換more和R(R指向劃分值),這時包括劃分值在內的整個陣列就排序完畢了,more指向的就是劃分值==區間最后一個數
swap(arr, more, R);
return new int[]{less + 1,more};//less+1就是左邊界前一個位置,也就是==區間第一個數(左邊界)
//more此時指向==區間最后一個數(more的值和R交換了)
}
public static void swap(int[] arr, int i, int j){
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}遞回思想:
(1)每一層遞回執行一次劃磁區間,每執行一次劃磁區間都會回傳當前層的劃分值==區間左右邊界的索引,
(2)然后不斷遞回向左逼近直到底層遞回的陣列長度為1(此時L=R),不符合if條件,跳出到遞回倒數第二層執行劃分值右側區域的遞回
(3)每一層都是排好序再回傳到上層遞回,最后到頂層遞回的時候陣列也就排序好了
6. 堆排序
6.1 堆排序的思想

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290265.html
標籤:其他