本文主要整理了深度學習相關演算法面試中經常問到的一些核心概念,并給出了細致的解答,分享給大家,
內容整理自網路,原文鏈接:https://github.com/HarleysZhang/2019_algorithm_intern_information/blob/master/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E9%9D%A2%E8%AF%95%E9%A2%98.md
感受野
后一層神經元在前一層神經元的感受空間,如下圖所示:
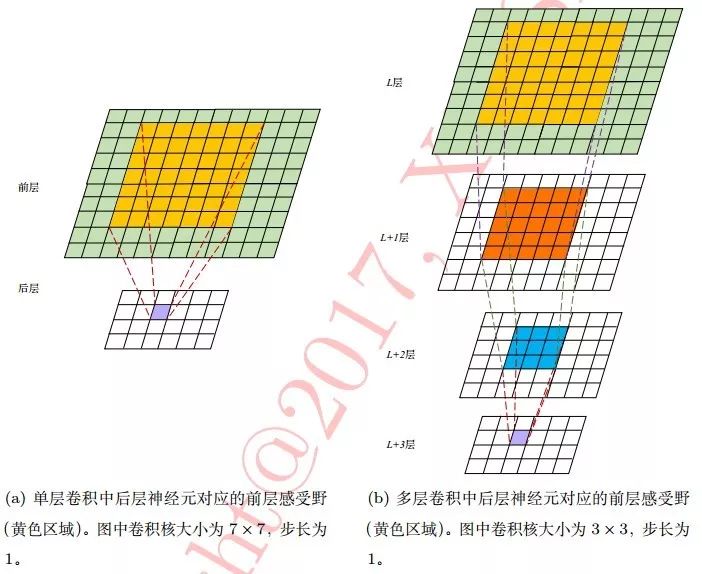
注意:小卷積核(如33)通過多層疊加可取得與大卷積核(如77)同等規模的感受野,此外采用小卷積核有兩個優勢:
1、小卷積核需多層疊加,加深了網路深度進而增強了網路容量(model capacity)和復雜度(model complexity)
2、增強了網路容量的同時減少了引數個數,
卷積操作作用
卷積網路中的卷積核引數是通過網路訓練出來的
通過卷積核的組合以及隨著網路后續操作的進行,卷積操作可獲取影像區域不同型別特征;基本而一般的模式會逐漸被抽象為具有高層語意的“概念”表示,也就是自動學習到影像的高層特征,
CNN權值共享問題
首先權值共享就是濾波器共享,濾波器的引數是固定的,即是用相同的濾波器去掃一遍影像,提取一次特征特征,得到feature map,在卷積網路中,學好了一個濾波器,就相當于掌握了一種特征,這個濾波器在影像中滑動,進行特征提取,然后所有進行這樣操作的區域都會被采集到這種特征,就好比上面的水平線,
CNN結構特點
區域連接,權值共享,池化操作,多層次結構,
1、區域連接使網路可以提取資料的區域特征
2、權值共享大大降低了網路的訓練難度,一個Filter只提取一個特征,在整個圖片(或者語音/文本) 中進行卷積
3、池化操作與多層次結構一起,實作了資料的降維,將低層次的區域特征組合成為較高層次的特征,從而對整個圖片進行表示,
pooling層作用
增加特征平移不變性,匯合可以提高網路對微小位移的容忍能力,
減小特征圖大小,匯合層對空間區域區域進行下采樣,使下一層需要的引數量和計算量減少,并降低過擬合風險,
最大匯合可以帶來非線性,這是目前最大匯合更常用的原因之一,
Reference
(二)計算機視覺四大基本任務(分類、定位、檢測、分割
深度特征的層次性
卷積操作可獲取影像區域不同型別特征,而匯合等操作可對這些特征進行融合和抽象,隨著若干卷積、匯合等操作的堆疊,各層得到的深度特征逐漸從泛化特征(如邊緣、紋理等)過渡到高層語意表示(軀干、頭部等模式),
什么樣的資料集不適合深度學習
資料集太小,資料樣本不足時,深度學習相對其它機器學習演算法,沒有明顯優勢,
資料集沒有區域相關特性,目前深度學習表現比較好的領域主要是影像/語音/自然語言處理等領域,這些領域的一個共性是區域相關性,影像中像素組成物體,語音信號中音位組合成單詞,文本資料中單詞組合成句子,這些特征元素的組合一旦被打亂,表示的含義同時也被改變,對于沒有這樣的區域相關性的資料集,不適于使用深度學習演算法進行處理,舉個例子:預測一個人的健康狀況,相關的引數會有年齡、職業、收入、家庭狀況等各種元素,將這些元素打亂,并不會影響相關的結果,
什么造成梯度消失問題
神經網路的訓練中,通過改變神經元的權重,使網路的輸出值盡可能逼近標簽以降低誤差值,訓練普遍使用BP演算法,核心思想是,計算出輸出與標簽間的損失函式值,然后計算其相對于每個神經元的梯度,進行權值的迭代,
梯度消失會造成權值更新緩慢,模型訓練難度增加,造成梯度消失的一個原因是,許多激活函式將輸出值擠壓在很小的區間內,在激活函式兩端較大范圍的定義域內梯度為0,造成學習停止,
Overfitting怎么解決
首先所謂過擬合,指的是一個模型過于復雜之后,它可以很好地“記憶”每一個訓練資料中隨機噪音的部分而忘記了去“訓練”資料中的通用趨勢,過擬合具體表現在:模型在訓練資料上損失函式較小,預測準確率較高;但是在測驗資料上損失函式比較大,預測準確率較低,
Parameter Norm Penalties(引數范數懲罰);Dataset Augmentation (資料集增強);Early Stopping(提前終止);Parameter Tying and Parameter Sharing (引數系結與引數共享);Bagging and Other Ensemble Methods(Bagging 和其他集成方法);dropout;regularization;batch normalizatin,是解決Overfitting的常用手段,
L1和L2區別
L1 范數(L1 norm)是指向量中各個元素絕對值之和,也有個美稱叫“稀疏規則算子”(Lasso regularization),比如 向量 A=[1,-1,3], 那么 A 的 L1 范數為 |1|+|-1|+|3|,簡單總結一下就是:
1、L1 范數: 為 x 向量各個元素絕對值之和,
2、L2 范數: 為 x 向量各個元素平方和的 1/2 次方,L2 范數又稱 Euclidean 范數或 Frobenius 范數
3、Lp 范數: 為 x 向量各個元素絕對值 p 次方和的 1/p 次方. 在支持向量機學習程序中,L1 范數實際是一種對于成本函式求解最優的程序,因此,L1 范數正則化通過向成本函式中添加 L1 范數,使得學習得到的結果滿足稀疏化,從而方便人類提取特征,
L1 范數可以使權值引數稀疏,方便特征提取,L2 范數可以防止過擬合,提升模型的泛化能力,
TensorFlow計算圖
Tensorflow 是一個通過計算圖的形式來表述計算的編程系統,計算圖也叫資料流圖,可以把計算圖看做是一種有向圖,Tensorflow 中的每一個計算都是計算圖上的一個節點,而節點之間的邊描述了計算之間的依賴關系,
BN(批歸一化)的作用
(1). 可以使用更高的學習率,如果每層的scale不一致,實際上每層需要的學習率是不一樣的,同一層不同維度的scale往往也需要不同大小的學習率,通常需要使用最小的那個學習率才能保證損失函式有效下降,Batch Normalization將每層、每維的scale保持一致,那么我們就可以直接使用較高的學習率進行優化,
(2). 移除或使用較低的dropout, dropout是常用的防止overfitting的方法,而導致overfit的位置往往在資料邊界處,如果初始化權重就已經落在資料內部,overfit現象就可以得到一定的緩解,論文中最后的模型分別使用10%、5%和0%的dropout訓練模型,與之前的40%-50%相比,可以大大提高訓練速度,
(3). 降低L2權重衰減系數,還是一樣的問題,邊界處的區域最優往往有幾維的權重(斜率)較大,使用L2衰減可以緩解這一問題,現在用了Batch Normalization,就可以把這個值降低了,論文中降低為原來的5倍,
(4). 取消Local Response Normalization層,由于使用了一種Normalization,再使用LRN就顯得沒那么必要了,而且LRN實際上也沒那么work,
(5). Batch Normalization調整了資料的分布,不考慮激活函式,它讓每一層的輸出歸一化到了均值為0方差為1的分布,這保證了梯度的有效性,可以解決反向傳播程序中的梯度問題,目前大部分資料都這樣解釋,比如BN的原始論文認為的緩解了Internal Covariate Shift(ICS)問題,
什么是梯度消失和爆炸,怎么解決?
當訓練較多層數的模型時,一般會出現梯度消失問題(gradient vanishing problem)和梯度爆炸問題(gradient exploding problem),注意在反向傳播中,當網路模型層數較多時,梯度消失和梯度爆炸是不可避免的,
深度神經網路中的梯度不穩定性,根本原因在于前面層上的梯度是來自于后面層上梯度的乘積,當存在過多的層次時,就出現了內在本質上的不穩定場景,前面的層比后面的層梯度變化更小,故變化更慢,故引起了梯度消失問題,前面層比后面層梯度變化更快,故引起梯度爆炸問題,
解決梯度消失和梯度爆炸問題,常用的有以下幾個方案:
預訓練模型 + 微調
梯度剪切 + 正則化
relu、leakrelu、elu等激活函式
BN批歸一化
CNN中的殘差結構
LSTM結構
RNN回圈神經網路理解
回圈神經網路(recurrent neural network, RNN), 主要應用在語音識別、語言模型、機器翻譯以及時序分析等問題上,在經典應用中,卷積神經網路在不同的空間位置共享引數,回圈神經網路是在不同的時間位置共享引數,從而能夠使用有限的引數處理任意長度的序列,RNN可以看做作是同一神經網路結構在時間序列上被復制多次的結果,這個被復制多次的結構稱為回圈體,如何設計回圈體的網路結構是RNN解決實際問題的關鍵,RNN的輸入有兩個部分,一部分為上一時刻的狀態,另一部分為當前時刻的輸入樣本,
訓練程序中模型不收斂,是否說明這個模型無效,致模型不收斂的原因有哪些?
不一定,導致模型不收斂的原因有很多種可能,常見的有以下幾種:
沒有對資料做歸一化,
沒有檢查過你的結果,這里的結果包括預處理結果和最終的訓練測驗結果,
忘了做資料預處理,
忘了使用正則化,
Batch Size設的太大,
學習率設的不對,
最后一層的激活函式用的不對,
網路存在壞梯度,比如Relu對負值的梯度為0,反向傳播時,0梯度就是不傳播,
引數初始化錯誤,
網路太深,隱藏層神經元數量錯誤,
更多回答,參考此鏈接,
影像處理中平滑和銳化操作是什么?
平滑處理(smoothing)也稱模糊處理(bluring),主要用于消除影像中的噪聲部分,平滑處理常用的用途是用來減少影像上的噪點或失真,平滑主要使用影像濾波,在這里,我個人認為可以把影像平滑和影像濾波聯系起來,因為影像平滑常用的方法就是影像濾波器,在OpenCV3中常用的影像濾波器有以下幾種:
方框濾波——BoxBlur函式
均值濾波(鄰域平均濾波)——Blur函式
高斯濾波——GaussianBlur函式(高斯低通濾波是模糊,高斯高通濾波是銳化)
中值濾波——medianBlur函式
雙邊濾波——bilateralFilter函式 影像銳化操作是為了突出顯示影像的邊界和其他細節,而影像銳化實作的方法是通過各種算子和濾波器實作的——Canny算子、Sobel算子、Laplacian算子以及Scharr濾波器,
VGG使用2個3*3卷積的優勢在哪里?
(1). 減少網路層引數,用兩個33卷積比用1個55卷積擁有更少的引數量,只有后者的2?3?35?5=0.72,但是起到的效果是一樣的,兩個33的卷積層串聯相當于一個55的卷積層,感受野的大小都是5×5,即1個像素會跟周圍5*5的像素產生關聯,把下圖當成動態圖看,很容易看到兩個3×3卷積層堆疊(沒有空間池化)有5×5的有效感受野,
![]()
2個3*3卷積層
(2). 更多的非線性變換,2個33卷積層擁有比1個55卷積層更多的非線性變換(前者可以使用兩次ReLU激活函式,而后者只有一次),使得卷積神經網路對特征的學習能力更強,
paper中給出的相關解釋:三個這樣的層具有7×7的有效感受野,那么我們獲得了什么?例如通過使用三個3×3卷積層的堆疊來替換單個7×7層,首先,我們結合了三個非線性修正層,而不是單一的,這使得決策函式更具判別性,其次,我們減少引數的數量:假設三層3×3卷積堆疊的輸入和輸出有C個通道,堆疊卷積層的引數為3(32C2)=27C2個權重;同時,單個7×7卷積層將需要72C2=49C2個引數,即引數多81%,這可以看作是對7×7卷積濾波器進行正則化,迫使它們通過3×3濾波器(在它們之間注入非線性)進行分解,
此回答可以參考TensorFlow實戰p110,網上很多回答都說的不全,
Relu比Sigmoid效果好在哪里?
Sigmoid函式公式如下:$\sigma (x)=\frac{1}{1+exp(-x)}$
ReLU激活函式公式如下:
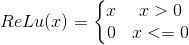
relu激活函式
relu函式方程 ReLU 的輸出要么是 0, 要么是輸入本身,雖然方程簡單,但實際上效果更好,在網上看了很多版本的解釋,有從程式實體分析也有從數學上分析,我找了個相對比較直白的回答,如下:
1、ReLU函式計算簡單,可以減少很多計算量,反向傳播求誤差梯度時,涉及除法,計算量相對較大,采用ReLU激活函式,可以節省很多計算量;
2、避免梯度消失問題,對于深層網路,sigmoid函式反向傳播時,很容易就會出現梯度消失問題(在sigmoid接近飽和區時,變換太緩慢,導數趨于0,這種情況會造成資訊丟失),從而無法完成深層網路的訓練,
3、可以緩解過擬合問題的發生,Relu會使一部分神經元的輸出為0,這樣就造成了網路的稀疏性,并且減少了引數的相互依存關系,緩解了過擬合問題的發生,
4、相比sigmoid型函式,ReLU函式有助于隨機梯度下降方法收斂,
參考鏈接
ReLU為什么比Sigmoid效果好
神經網路中權值共享的理解?
權值(權重)共享這個詞是由LeNet5模型提出來的,以CNN為例,在對一張圖偏進行卷積的程序中,使用的是同一個卷積核的引數,比如一個3×3×1的卷積核,這個卷積核內9個的引數被整張圖共享,而不會因為影像內位置的不同而改變卷積核內的權系數,說的再直白一些,就是用一個卷積核不改變其內權系數的情況下卷積處理整張圖片(當然CNN中每一層不會只有一個卷積核的,這樣說只是為了方便解釋而已),
參考資料
如何理解CNN中的權值共享
對fine-tuning(微調模型的理解),為什么要修改最后幾層神經網路權值?
使用預訓練模型的好處,在于利用訓練好的SOTA模型權重去做特征提取,可以節省我們訓練模型和調參的時間,
至于為什么只微調最后幾層神經網路權重,是因為:(1). CNN中更靠近底部的層(定義模型時先添加到模型中的層)編碼的是更加通用的可復用特征,而更靠近頂部的層(最后添加到模型中的層)編碼的是更專業業化的特征,微調這些更專業化的特征更加有用,它更代表了新資料集上的有用特征,(2). 訓練的引數越多,過擬合的風險越大,很多SOTA模型擁有超過千萬的引數,在一個不大的資料集上訓練這么多引數是有過擬合風險的,除非你的資料集像Imagenet那樣大,
參考資料
Python深度學習p127.
什么是dropout?
dropout可以防止過擬合,dropout簡單來說就是:我們在前向傳播的時候,讓某個神經元的激活值以一定的概率p停止作業,這樣可以使模型的泛化性更強,因為它不會依賴某些區域的特征,
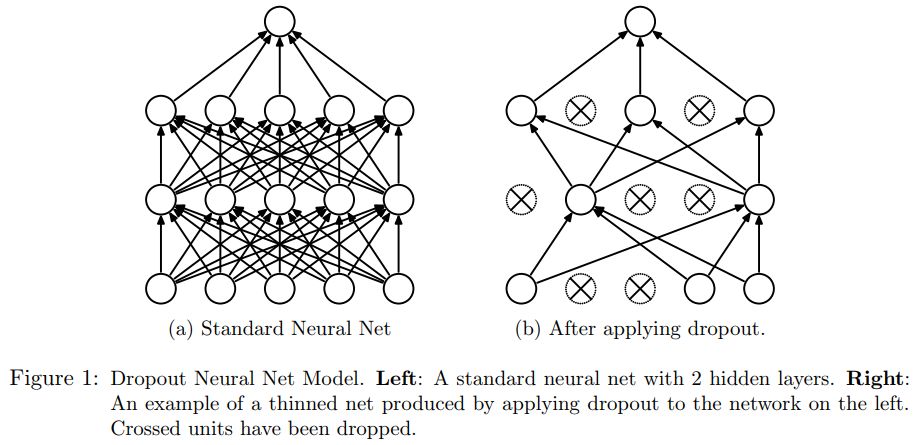
dropou直觀展示
dropout具體作業流程
以 標準神經網路為例,正常的流程是:我們首先把輸入資料x通過網路前向傳播,然后把誤差反向傳播一決定如何更新引數讓網路進行學習,使用dropout之后,程序變成如下:
(1). 首先隨機(臨時)刪掉網路中一半的隱藏神經元,輸入輸出神經元保持不變(圖3中虛線為部分臨時被洗掉的神經元);
(2). 然后把輸入x通過修改后的網路進行前向傳播計算,然后把得到的損失結果通過修改的網路反向傳播,一小批訓練樣本執行完這個程序后,在沒有被洗掉的神經元上按照隨機梯度下降法更新對應的引數(w,b);
(3). 然后重復這一程序:
1、恢復被刪掉的神經元(此時被洗掉的神經元保持原樣沒有更新w引數,而沒有被洗掉的神經元已經有所更新)
2、 從隱藏層神經元中隨機選擇一個一半大小的子集臨時洗掉掉(同時備份被洗掉神經元的引數),
3、對一小批訓練樣本,先前向傳播然后反向傳播損失并根據隨機梯度下降法更新引數(w,b) (沒有被洗掉的那一部分引數得到更新,洗掉的神經元引數保持被洗掉前的結果),
dropout在神經網路中的應用
(1). 在訓練模型階段
不可避免的,在訓練網路中的每個單元都要添加一道概率流程,標準網路和帶有dropout網路的比較圖如下所示:
![]()
dropout在訓練階段
(2). 在測驗模型階段
預測模型的時候,輸入是當前輸入,每個神經單元的權重引數要乘以概率p,
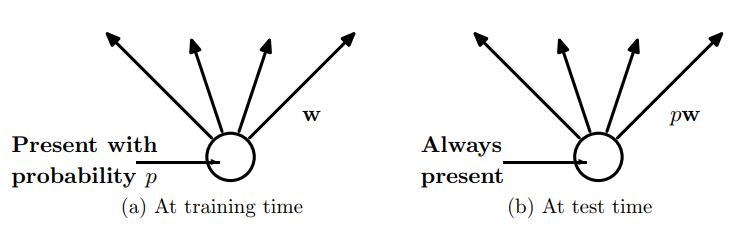
dropout在測驗模型時
如何選擇dropout 的概率
input 的dropout概率推薦是0.8, hidden layer 推薦是0.5, 但是也可以在一定的區間上取值,(All dropout nets use p = 0.5 for hidden units and p = 0.8 for input units.)
參考資料
[Dropout:A Simple Way to Prevent Neural Networks from Overfitting]
深度學習中Dropout原理決議
HOG演算法原理描述
方向梯度直方圖(Histogram of Oriented Gradient, HOG)特征是一種在計算機視覺和影像處理中用來進行物體檢測的特征描述子,它通過計算和統計影像區域區域的梯度方向直方圖來構成特征,在深度學習取得成功之前,Hog特征結合SVM分類器被廣泛應用于影像識別中,在行人檢測中獲得了較大的成功,
HOG特征原理
HOG的核心思想是所檢測的區域物體外形能夠被光強梯度或邊緣方向的分布所描述,通過將整幅影像分割成小的連接區域(稱為cells),每個cell生成一個方向梯度直方圖或者cell中pixel的邊緣方向,這些直方圖的組合可表示出(所檢測目標的目標)描述子,為改善準確率,區域直方圖可以通過計算影像中一個較大區域(稱為block)的光強作為measure被對比標準化,然后用這個值(measure)歸一化這個block中的所有cells,這個歸一化程序完成了更好的照射/陰影不變性,與其他描述子相比,HOG得到的描述子保持了幾何和光學轉化不變性(除非物體方向改變),因此HOG描述子尤其適合人的檢測,
HOG特征提取方法就是將一個image:
1、灰度化(將影像看做一個x,y,z(灰度)的三維影像)
2、劃分成小cells(2*2)
3、計算每個cell中每個pixel的gradient(即orientation)
4、統計每個cell的梯度直方圖(不同梯度的個數),即可形成每個cell的descriptor,
HOG特征檢測步驟
![]()
HOG特征檢測步驟
顏色空間歸一化——–>梯度計算————->梯度方向直方圖———->重疊塊直方圖歸一化———–>HOG特征
參考資料
HOG特征檢測-簡述
移動端深度學習框架知道哪些,用過哪些?
知名的有TensorFlow Lite、小米MACE、騰訊的ncnn等,目前都沒有用過,
如何提升網路的泛化能力
和防止模型過擬合的方法類似,另外還有模型融合方法,
BN演算法,為什么要在后面加加伽馬和貝塔,不加可以嗎?
最后的“scale and shift”操作則是為了讓因訓練所需而“刻意”加入的BN能夠有可能還原最初的輸入,不加也可以,
激活函式的作用
激活函式實作去線性化,神經元的結構的輸出為所有輸入的加權和,這導致神經網路是一個線性模型,如果將每一個神經元(也就是神經網路的節點)的輸出通過一個非線性函式,那么整個神經網路的模型也就不再是線性的了,這個非線性函式就是激活函式,常見的激活函式有:ReLU函式、sigmoid函式、tanh函式,
ReLU函式:$f(x)=max(x,0)$
sigmoid函式:$f(x)=\frac{1}{1+e^{-x}}$
tanh函式:$f(x)=\frac{1+e^{-2x}}{1+e^{-2x}}$
卷積層和池化層有什么區別
1、卷積層有引數,池化層沒有引數
2、經過卷積層節點矩陣深度會改變,池化層不會改變節點矩陣的深度,但是它可以縮小節點矩陣的大小,
卷積層引數數量計算方法
假設輸入層矩陣維度是96963,第一層卷積層使用尺寸為55、深度為16的過濾器(卷積核尺寸為55、卷積核數量為16),那么這層卷積層的引數個數為553*16+16=1216個
卷積層輸出大小計算
卷積中的特征圖大小計算方式有兩種,分別是‘VALID’和‘SAME’,卷積和池化都適用,除不盡的結果都向下取整,公式:O = (W-F+2P)/S+1,輸入圖片(Input)大小為I=WW,卷積核(Filter)大小為FF,步長(stride)為S,填充(Padding)的像素數為P,
1、SAME填充方式:填充像素,conv2d函式常用,
2、VALID填充方式:不填充像素,Maxpooling2D函式常用,"SAME"卷積方式,對于輸入55影像,影像的每一個點都作為卷積核的中心,最后得到55的結果,通俗的來說:首先在原圖外層補一圈0,將原圖的第一點作為卷積核中心,若一圈0不夠,繼續補一圈0,如下圖所示:
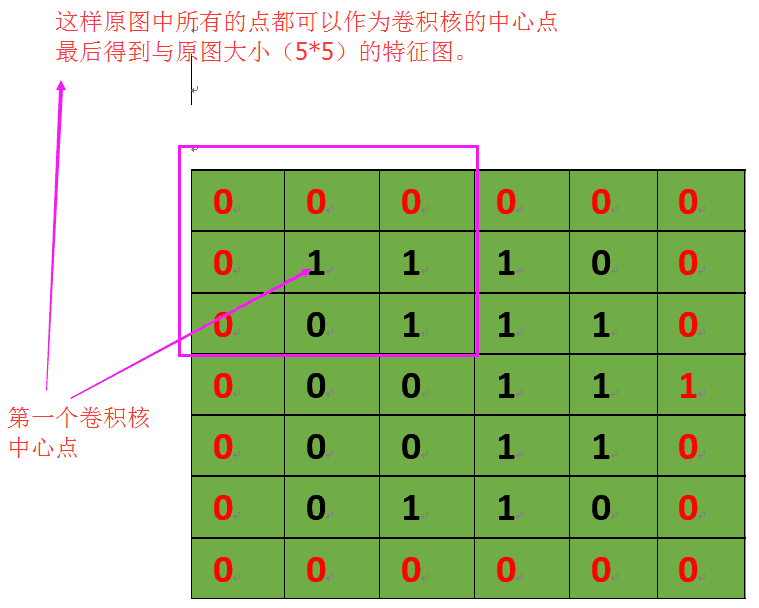
卷積填充方式
神經網路為什么用交叉熵損失函式
判斷一個輸出向量和期望的向量有多接近,交叉熵(cross entroy)是常用的評判方法之一,交叉熵刻畫了兩個概率分布之間的距離,是分類問題中使用比較廣泛的一種損失函式,給定兩個概率分布p和q,通過q來表示p的交叉熵公式為:H(p,q)=?∑p(x)logq(x)
softmax公式寫一下:
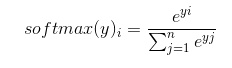
softmax(y){i} = \frac{e^{yi}}{\sum{j=1}^{n}e^{yj}} softmax公式
1*1卷積的主要作用有以下幾點
1、降維( dimension reductionality ),比如,一張500 * 500且厚度depth為100 的圖片在20個filter上做11的卷積,那么結果的大小為500500*20,
2、加入非線性,卷積層之后經過激勵層,1*1的卷積在前一層的學習表示上添加了非線性激勵( non-linear activation ),提升網路的表達能力;
目標檢測基本概念
準確率、召回率、F1
混淆矩陣:
True Positive(真正例, TP):將正類預測為正類數.
True Negative(真負例, TN):將負類預測為負類數.
False Positive(假正例, FP):將負類預測為正類數 → 誤報 (Type I error).
False Negative(假負例子, FN):將正類預測為負類數 → 漏報 (Type II error).
查準率(準確率)P = TP/(TP+FP) 查全率(召回率)R = TP/(TP+FN) 準確率描述了模型有多準,即在預測為正例的結果中,有多少是真正例;召回率則描述了模型有多全,即在為真的樣本中,有多少被我們的模型預測為正例,以查準率P為縱軸、查全率R為橫軸作圖,就得到了查準率-查全率曲線,簡稱**”P-R“曲線,顯示改該曲線的圖稱為”P-R“圖,查準率、查全率性能的性能度量,除了”平衡點“(BEP),更為常用的是F1度量**:$$F1 = \frac{2PR}{P+R} = \frac{2*TP}{樣例總數+TP-TN}$$
F1度量的一般形式:$F_{\beta}$,能讓我們表達出對查準率/查全率的偏見,公式如下:$$F_{\beta} = \frac{1+\beta ^{2}PR}{(\beta ^{2}*P)+R}$$ $\beta >1$對查全率有更大影響,$\beta < 1$對查準率有更大影響,
不同的計算機視覺問題,對兩類錯誤有不同的偏好,常常在某一類錯誤不多于一定閾值的情況下,努力減少另一類錯誤,在目標檢測中,mAP(mean Average Precision)作為一個統一的指標將這兩種錯誤兼顧考慮,
map指標解釋
具體來說就是,在目標檢測中,對于每張圖片檢測模型會輸出多個預測框(遠超真實框的個數),我們使用IoU(Intersection Over Union,交并比)來標記預測框是否預測準確,標記完成后,隨著預測框的增多,查全率R總會上升,在不同查全率R水平下對準確率P做平均,即得到AP,最后再對所有類別按其所占比例做平均,即得到mAP指標,
交并比IOU
交并比(Intersection-over-Union,IoU),目標檢測中使用的一個概念,是產生的候選框(candidate bound)與原標記框(ground truth bound)的交疊率,即它們的交集與并集的比值,最理想情況是完全重疊,即比值為1,計算公式如下:
代碼實作如下:
# candidateBound = [x1, y1, x2, y2]
def calculateIoU(candidateBound, groundTruthBound):
cx1 = candidateBound[0]
cy1 = candidateBound[1]
cx2 = candidateBound[2]
cy2 = candidateBound[3]
gx1 = groundTruthBound[0]
gy1 = groundTruthBound[1]
gx2 = groundTruthBound[2]
gy2 = groundTruthBound[3]
carea = (cx2 - cx1) * (cy2 - cy1) #C的面積
garea = (gx2 - gx1) * (gy2 - gy1) #G的面積
x1 = max(cx1, gx1)
y1 = min(cy1, gy1) # 原點為(0, 0),所以這里是min不是max
x2 = min(cx2, gx2)
y2 = max(cy2, gy2)
w = max(0, (x2 - x1))
h = max(0, (y2 - y1))
area = w * h #C∩G的面積
iou = area / (carea + garea - area)
return iou
資料增強方法,離線資料增強和在線資料增強有什么區別?
常用資料增強方法:
翻轉:Fliplr,Flipud,不同于旋轉180度,這是類似鏡面的翻折,跟人在鏡子中的映射類似,常用水平、上下鏡面翻轉,
旋轉:rotate,順時針/逆時針旋轉,最好旋轉90-180度,否則會出現邊緣缺失或者超出問題,如旋轉45度,
縮放:zoom,影像可以被放大或縮小,imgaug庫可用Scal函式實作,
裁剪:crop,一般叫隨機裁剪,操作步驟是:隨機從影像中選擇一部分,然后降這部分影像裁剪出來,然后調整為原影像的大小,
平移:translation,平移是將影像沿著x或者y方向(或者兩個方向)移動,我們在平移的時候需對背景進行假設,比如說假設為黑色等等,因為平移的時候有一部分影像是空的,由于圖片中的物體可能出現在任意的位置,所以說平移增強方法十分有用,
放射變換:Affine,包含:平移(Translation)、旋轉(Rotation)、放縮(zoom)、錯切(shear),
添加噪聲:過擬合通常發生在神經網路學習高頻特征的時候,為消除高頻特征的過擬合,可以隨機加入噪聲資料來消除這些高頻特征,imgaug庫使用GaussianBlur函式,
亮度、對比度增強:這是影像色彩進行增強的操作
銳化:Sharpen,imgaug庫使用Sharpen函式,
資料增強分兩類,一類是離線增強,一類是在線增強:
離線增強 : 直接對資料集進行處理,資料的數目會變成增強因子 x 原資料集的數目 ,這種方法常常用于資料集很小的時候
在線增強 : 這種增強的方法用于,獲得 batch 資料之后,然后對這個batch的資料進行增強,如旋轉、平移、翻折等相應的變化,由于有些資料集不能接受線性級別的增長,這種方法長用于大的資料集,很多機器學習框架已經支持了這種資料增強方式,并且可以使用GPU優化計算,
ROI Pooling替換為ROI Align
,及各自原理
faster rcnn將roi pooling替換為roi align效果有所提升
ROI Pooling原理
ROI Align原理
Reference
1.深度學習中的資料增強
Reference
1、《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》閱讀筆記與實作
2、深度學習中 Batch Normalization為什么效果好
3、詳解機器學習中的梯度消失、爆炸原因及其解決方法
Python/C/C++/計算機基礎/影像處理基礎
static關鍵字作用
在全域變數前加上關鍵字static,全域變數就定義為一個全域靜態變數,全域靜態變數在宣告它的檔案之外是不可見的,作用域范圍為從定義之處開始,到檔案結尾,
在函式回傳型別前加static,函式就變為靜態函式,靜態函式只在宣告它的檔案中使用,不被其他檔案所用,
C++指標和參考的區別
指標有自己的記憶體空間,而參考只是一個別名,類似于Python淺拷貝和深拷貝的區別
不存在空參考, 參考必須鏈接到一塊合法的記憶體地址;
一旦參考被初始化為一個物件,就不能指向另一個物件,指標可以在任何時候指向任何一個物件;
參考必須在創建時被初始化,指標可以在任何時間初始化,
C++中解構式的作用
解構式與建構式對應,類的解構式是類的一種特殊的成員函式,它會在每次洗掉所創建的物件時執行,解構式的名稱與類的名稱是完全相同的,只是在前面加了個波浪號(~)作為前綴,它不會回傳任何值,也不能帶有任何引數,解構式有助于在跳出程式(比如關閉檔案、釋放記憶體等)前釋放資源,
C++靜態函式和虛函式的區別
靜態函式在編譯的時候就已經確定運行時機,虛函式在運行的時候動態系結,虛函式因為用了虛函式表機制,呼叫的時候會增加一次記憶體開銷,
++i和i++區別
++i 先自增1,再回傳,i++,先回傳 i,再自增1.
const關鍵字作用
const型別的物件在程式執行期間不能被修改改變,
Python裝飾器解釋
裝飾器本質上是一個 Python 函式或類,它可以讓其他函式或類在不需要做任何代碼修改的前提下增加額外功能,裝飾器的回傳值也是一個函式/類物件,它經常用于有切面需求的場景,比如:插入日志、性能測驗、事務處理、快取、權限校驗等場景,裝飾器是解決這類問題的絕佳設計,有了裝飾器,我們就可以抽離出大量與函式功能本身無關的雷同代碼到裝飾器中并繼續重用,概括的講,裝飾器的作用就是為已經存在的物件添加額外的功能,
多行程與多執行緒區別
執行緒是行程的一部分,一個行程至少有一個執行緒;
對于作業系統來說,一個任務就是一個行程,行程內的“子任務”稱為執行緒;
多執行緒和多行程最大的不同在于,多行程中,同一個變數,各自有一份拷貝存在于每個行程中,互不影響,而多執行緒中,所有變數都由所有執行緒共享,所以,任何一個變數都可以被任何一個執行緒修改,因此,執行緒之間共享資料最大的危險在于多個執行緒同時改一個變數,把內容給改亂了,
行程間呼叫、通訊和切換開銷均比多執行緒大,單個執行緒的崩潰會導致整個應用的退出,
存在大量IO,網路耗時或者需要和用戶互動等操作時,使用多執行緒有利于提高系統的并發性和用戶界面快速回應從而提高友好性,
map與reduce函式用法解釋下
1、 map函式接收兩個引數,一個是函式,一個是Iterable,map將傳入的函式依次作用到序列的每個元素,并將結果作為新的Iterator回傳,簡單示例代碼如下:
# 示例1
def square(x):
return x ** 2
r = map(square, [1, 2, 3, 4, 5, 6, 7])
squareed_list = list(r)
print(squareed_list) # [1, 4, 9, 16, 25, 36, 49]
# 使用lambda匿名函式簡化為一行代碼
list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
# 示例2
list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])) # ['1', '2', '3', '4', '5', '6', '7', '8', '9']
注意map函式回傳的是一個Iterator(惰性序列),要通過list函式轉化為常用串列結構,map()作為高階函式,事實上它是把運算規則抽象了,
2、reduce()函式也接受兩個引數,一個是函式(兩個引數),一個是序列,與map不同的是reduce把結果繼續和序列的下一個元素做累積計算,效果如下:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4) 示例代碼如下:
from functools import reduce
CHAR_TO_INT = {
'0': 0,
'1': 1,
'2': 2,
'3': 3,
'4': 4,
'5': 5,
'6': 6,
'7': 7,
'8': 8,
'9': 9
}
def str2int(str):
ints = map(lambda x:CHAR_TO_INT[x], str) # str物件是Iterable物件
return reduce(lambda x,y:10*x + y, ints)
print(str2int('0'))
print(str2int('12300'))
print(str2int('0012345')) # 0012345
Python深拷貝、淺拷貝區別
1、直接賦值:其實就是物件的參考(別名),
2、淺拷貝(copy):拷貝父物件,不會拷貝物件的內部的子物件,copy淺拷貝,沒有拷貝子物件,所以原始資料改變,子物件會改變,
3、深拷貝(deepcopy):copy 模塊的 deepcopy 方法,完全拷貝了父物件及其子物件,兩者是完全獨立的,深拷貝,包含物件里面的自物件的拷貝,所以原始物件的改變不會造成深拷貝里任何子元素的改變,看一個示例程式,就能明白淺拷貝與深拷貝的區別了:
#!/usr/bin/Python3
# -*-coding:utf-8 -*-
import copy
a = [1, 2, 3, ['a', 'b', 'c']]
b = a # 賦值,傳物件的參考
c = copy.copy(a) # 淺拷貝
d = copy.deepcopy(a) # 深拷貝
a.append(4)
a[3].append('d')
print('a = ', a)
print('b = ', b)
print('c = ', c)
print('d = ', d) # [1, 2, 3, ['a', 'b', 'c']]
程式輸出如下:
a = [1, 2, 3, ['a', 'b', 'c', 'd'], 4] b = [1, 2, 3, ['a', 'b', 'c', 'd'], 4] c = [1, 2, 3, ['a', 'b', 'c', 'd']] d = [1, 2, 3, ['a', 'b', 'c']]
影像銳化方法
銳化主要影響影像中的低頻分量,不影響影像中的高頻分量像銳化的主要目的有兩個:
1、增強影像邊緣,使模糊的影像變得更加清晰,顏色變得鮮明突出,影像的質量有所改善,產生更適合人眼觀察和識別的影像;
2、過銳化處理后,目標物體的邊緣鮮明,以便于提取目標的邊緣、對影像進行分割、目標區域識別、區域形狀提取等,進一步的影像理解與分析奠定基礎,
影像銳化一般有兩種方法:
1、微分法
2、高通濾波法
一般來說,影像的能量主要集中在其低頻部分,噪聲所在的頻段主要在高頻段,同時影像邊緣資訊也主要集中在其高頻部分,這將導致原始影像在平滑處理之后,影像邊緣和影像輪廓模糊的情況出現,為了減少這類不利效果的影響,就需要利用影像銳化技術,使影像的邊緣變得清晰,影像銳化處理的目的是為了使影像的邊緣、輪廓線以及影像的細節變得清晰,經過平滑的影像變得模糊的根本原因是因為影像受到了平均或積分運算,因此可以對其進行逆運算(如微分運算)就可以使影像變得清晰,微分運算是求信號的變化率,由傅立葉變換的微分性質可知,微分運算具有較強高頻分量作用,從頻率域來考慮,影像模糊的實質是因為其高頻分量被衰減,因此可以用高通濾波器來使影像清晰,但要注意能夠進行銳化處理的影像必須有較高的性噪比,否則銳化后影像性噪比反而更低,從而使得噪聲增加的比信號還要多,因此一般是先去除或減輕噪聲后再進行銳化處理,
Reference
影像增強-影像銳化
numpy手撕代碼
人臉識別的場景下,輸入10512的feature map,用這個在1000512的特征庫當中用歐氏距離去匹配10512的feature map,用這個在1000512的特征庫當中用歐氏距離去匹配101000的特征,得到這個output,
機器學習
Focal Loss 介紹一下
資料不平衡怎么辦?
AUC的理解
AUC的計算公式
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290378.html
標籤:其他