文章目錄
- 0 前言
- 1 RNN
- 1.1 RNN的基本框架
- 1.2 其他型別的RNN模型
- 1.2.1 Jordan Network
- 1.2.2 Bidirectional RNN
- 2 LSTM
- 2.1 簡介
- 2.2 LSTM的基本框架
- 2.3 LSTM的一些討論
- 2.3.1 LSTM和其他模型的關系
- 2.3.2 LSTM解決梯度消失
0 前言
RNN(Recurrent Neural Network)是一類用于處理序列資料的神經網路,它能挖掘資料中的時序資訊以及語意資訊,本文以李宏毅老師上課內容為基礎,介紹RNN和LSTM的模型框架,
1 RNN
1.1 RNN的基本框架
假設在一個自動售票機上需要自動獲知輸入的命令中的關鍵詞匯的詞義:
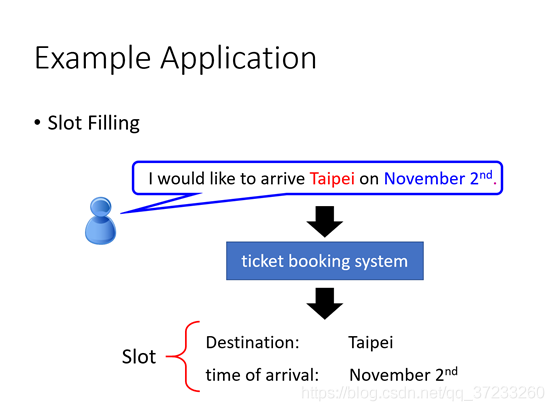
在使用神經網路之前要先考慮將詞匯表示為一個向量,比如使用獨熱編碼:

也可以用詞匯的字母來表示,如果詞匯中存在某個字母,則將對應字母位置置為1:
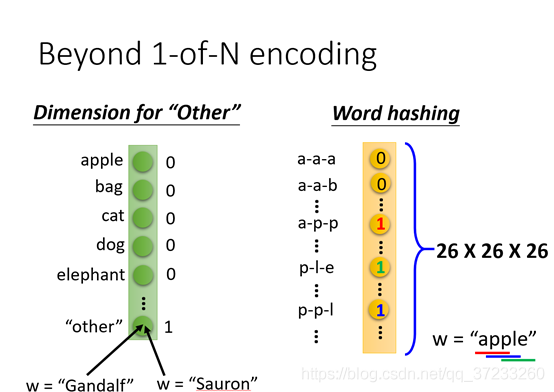
將詞匯向量輸入到網路中,由輸出判斷其詞義:
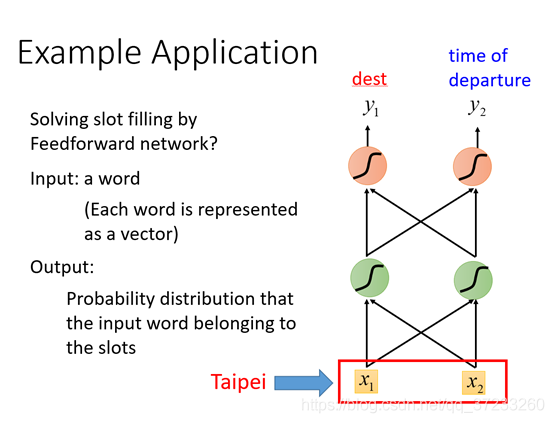
但是當輸入為一句話時,由于每次只能輸入一個詞,所以除了destination和time詞義的詞匯能夠判斷,其他詞匯都會被認為是other,這就會出現一個問題:如果不關心詞匯之間的背景關系,可能目標詞匯的詞義就會完全相反:
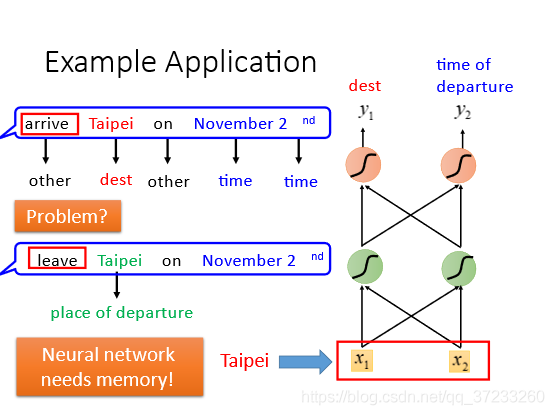
所以希望網路是有記憶的,可以根據背景關系來判別詞義,如圖,上一次隱藏層的結果會被存到memory里,下一次的輸出會受memory影響:
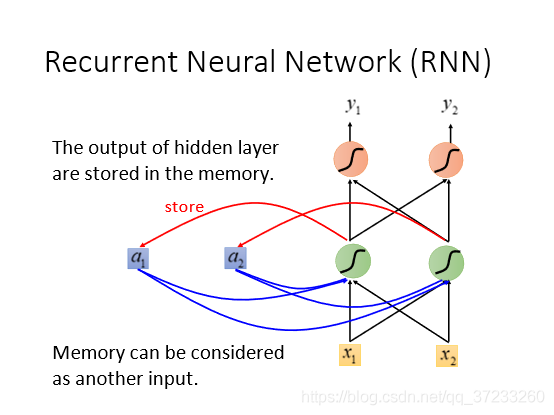
第一次輸入為:
[
1
1
]
[
1
1
]
[
2
2
]
\left[\begin{array}{l} 1 \\ 1 \end{array}\right]\left[\begin{array}{l} 1 \\ 1 \end{array}\right]\left[\begin{array}{l} 2 \\ 2 \end{array}\right]
[11?][11?][22?],給定memory的初始值為:[0 ,0],權重都為1,不設定bias,激勵函式為線性,可以得到輸出為[4, 4]:
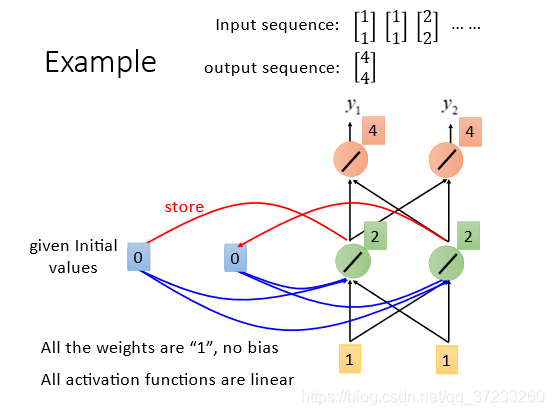
第二次輸入相同的
[
1
1
]
[
1
1
]
[
2
2
]
\left[\begin{array}{l} 1 \\ 1 \end{array}\right]\left[\begin{array}{l} 1 \\ 1 \end{array}\right]\left[\begin{array}{l} 2 \\ 2 \end{array}\right]
[11?][11?][22?],但是此時memory里已經存了上一次隱藏層的結果,那么最后的輸出就變為[12, 12]了:
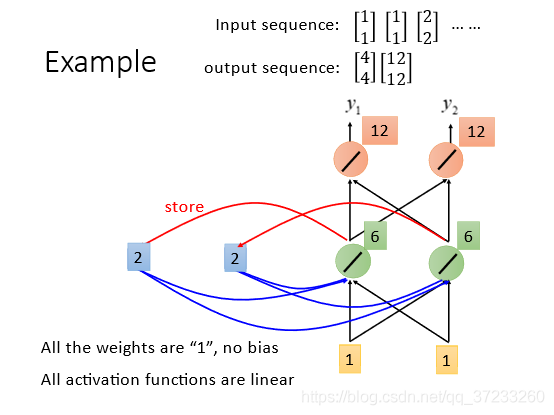
識別句子的時候,只需要將一個個詞匯按序丟入網路即可:
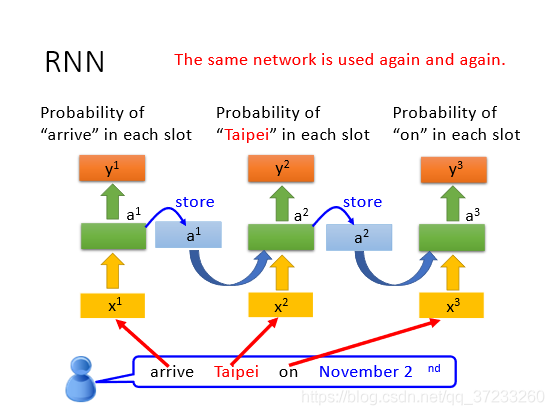
1.2 其他型別的RNN模型
1.2.1 Jordan Network
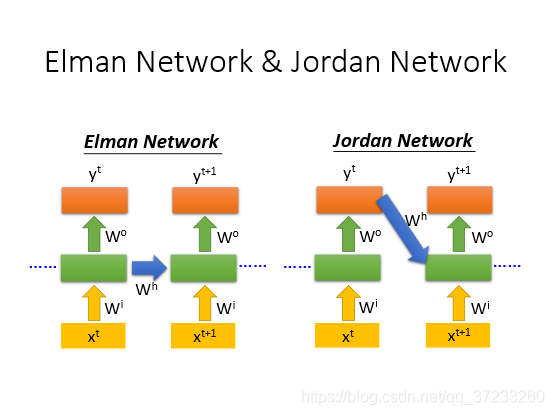
剛剛介紹的在memory存放隱藏層的值的網路結構被稱為 Elman network,還有一種結構是Jordan Network,區別是這種網路的memory里存放的是上一次的輸出:
1.2.2 Bidirectional RNN
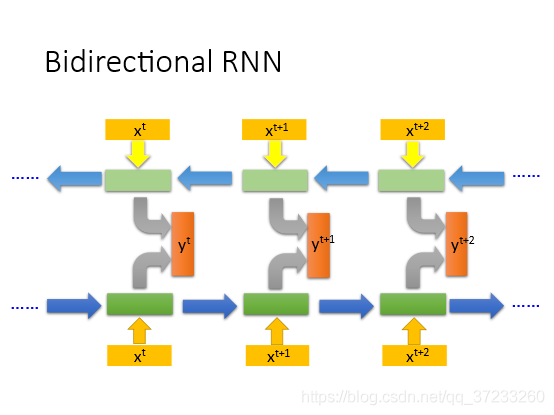
Bidirectional RNN 網路的讀取可以正向和反向同時進行,把雙方的隱藏層聯合起來用來產生輸出,好處是范圍比較廣,前后的資訊都可以參考:
2 LSTM
2.1 簡介
長短期記憶(Long short-term memory, LSTM)是一種特殊的RNN,主要是為了解決長序列訓練程序中的梯度消失和梯度爆炸問題,相比普通的RNN,LSTM能夠在更長的序列中有更好的表現,一般的編程演算法中使用RNN時默認是使用LSTM,
2.2 LSTM的基本框架
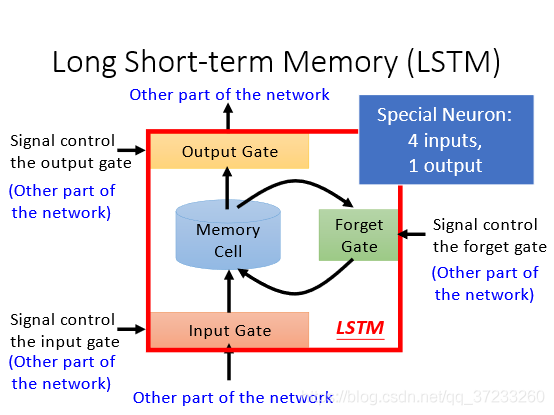
這是一個復雜的系統,比普通RNN增加了控制信號的輸入,每次都有四個輸入,其中只有一個是樣本,其他三個都是控制信號,如下圖所示,有三個控制門,Input Gate控制輸入,Forget Gate控制memory單元,Output Gate控制輸出:
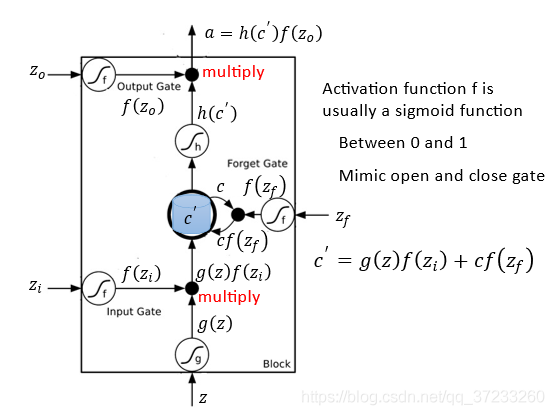
如下圖,當輸入信號z輸入時首先經過轉換函式
g
(
)
g()
g(),再與輸入控制信號相乘得到
g
(
z
)
f
(
z
i
)
g(z)f(z_i)
g(z)f(zi?),再讀取memory中的
c
c
c,這個
c
c
c也會受控制,隱藏層的輸出為
c
′
=
g
(
z
)
f
(
z
i
)
+
c
f
(
z
f
)
c^{\prime}=g(z) f\left(z_{i}\right)+c f\left(z_{f}\right)
c′=g(z)f(zi?)+cf(zf?),再由控制信號
z
o
z_o
zo?決定是否輸出,即最后輸出為
a
=
h
(
c
′
)
f
(
z
o
)
a=h\left(c^{\prime}\right) f\left(z_{o}\right)
a=h(c′)f(zo?),
舉一個實際資料的例子,這里的輸入是一個三維的向量,注意
x
1
x_1
x1?是輸入,
x
2
x_2
x2?的兩種狀態為
±
1
±1
±1,代表input gate和forget gate 的信號控制,
x
3
x_3
x3?控制output gate的狀態,可以根據從左往右的順序推斷最后的輸出
y
y
y的情況:
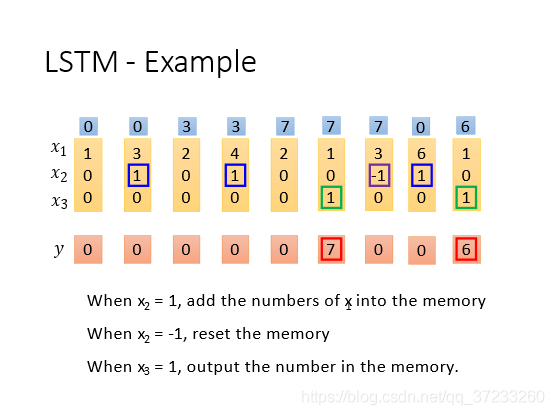
通常各個門的輸入前會預置bias,平常沒有輸入的時候有一定的默認值,表示是關倍訓是開啟的,一般在input gate和output gate都默認關閉,而forget gate默認開啟,
2.3 LSTM的一些討論
2.3.1 LSTM和其他模型的關系
你覺得這個模型有些復雜,那跟全連接神經網路有什么關系呢?
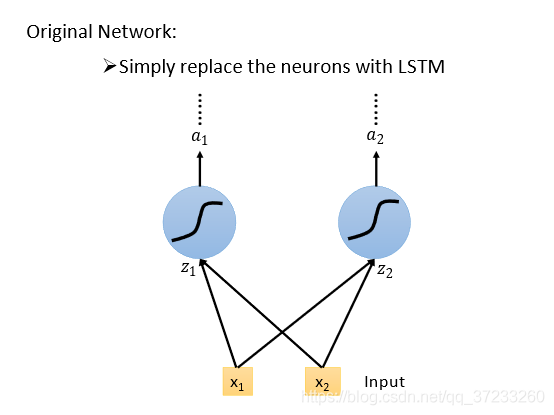
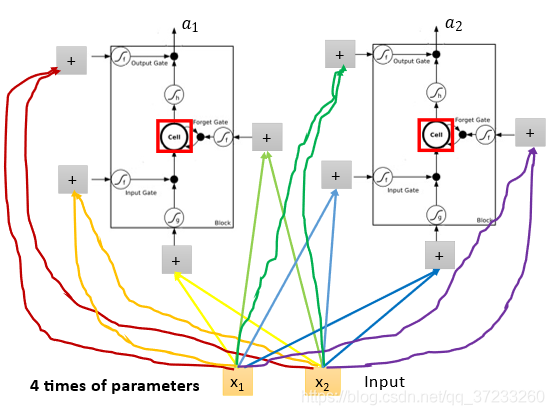
只需要把結點換成一個基本框,直觀看就是增加了權值,比全連接多了4倍的引數:
那么和RNN的關系是什么呢?
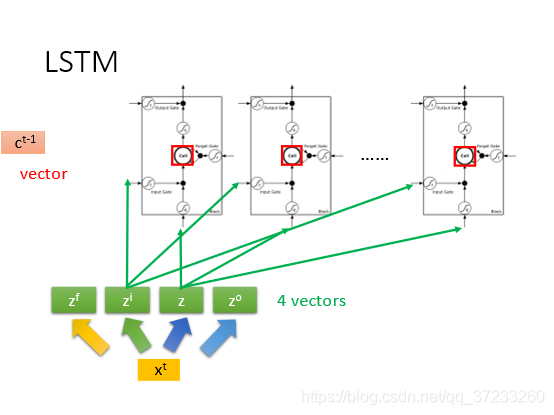
即輸入x會拆開變成四種的資料,都會用到memory單元,
2.3.2 LSTM解決梯度消失
普通的RNN會出現梯度消失問題(gradient vanishing problem)和梯度爆炸問題(gradient exploding problem)的問題,當輸入發生輕微變化時,輸出改變劇烈,而且很快收斂:
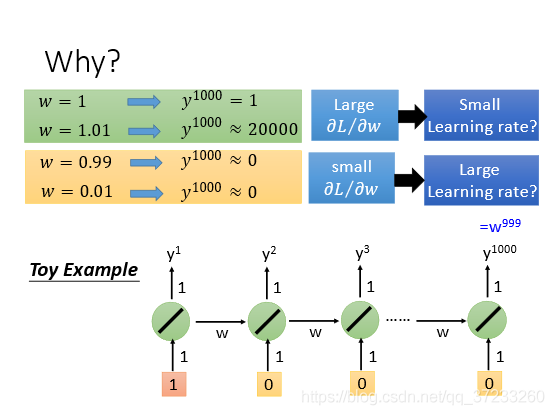
為什么會出現這種問題呢?這并非是激勵函式導致的,而是因為訓練RNN時會把memory往后傳遞,這樣每一次w在不同時間點會反復被使用,
而LSTM可以解決梯度消失的問題,是因為處理memory的方法是不一樣的,RNN隨時都會用到memory,而LSTM是可以控制的其使用的,因為永遠都會有forget gate存在,如果不需要的時候可以一直關閉:
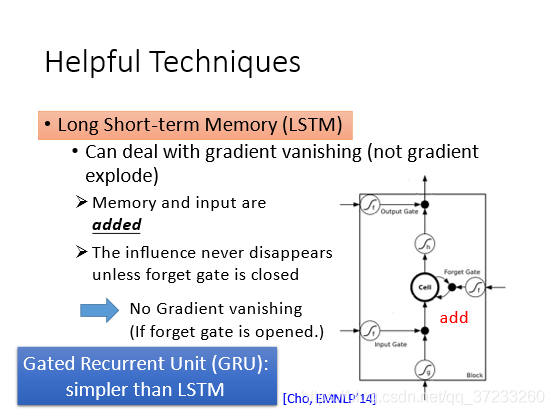
GRU是LSTM的簡化版本,比起LSTM少了一個門,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290562.html
標籤:AI
上一篇:opencv-2、小案例集合
下一篇:【李宏毅深度學習】階段性小結