目錄
前言
一、 Pytorch介紹
1.常見的深度學習框架
2.Pytorch框架的崛起
3.Pytorch與Tensorflow多方位比較
二、Tensors
1.Tensor的創建
2.Tensor的操作
3.Tensor與Numpy
三、Autograd的講解
1.模型中的前向傳播與反向傳播
2.利用autograd計算梯度
四、 構建神經網路模型
1.資料的構造
2.模型的構造
3.優化器選擇和配置
4.主函式
前言
工欲善其事,必先利其器,近幾年深度學習飛速發展讓人瞠目結舌,但它的崛起背后離不開最大的功臣——深度學習框架,如果沒有這些深度學習框架,深度學習絕對不會像現在一樣“平民化”,很多人可能陷入在茫茫的數學深淵中,有了便捷實用的深度學習框架,我們才可以把所有精力花在如何設計模型本身上,而不用再去關注模型優化的細節,所有的事情均由框架來負責,極大降低了深度學習使用的門檻,這也是為什么現在只要經過短期有效訓練的開發工程師也可以在使用深度學習模型身上得心應手的主要原因,
一、 Pytorch介紹
1.常見的深度學習框架
深度學習框架的發展也經歷了超過10年的時間,從早期比較流行的theano到現在比較火爆的框架如Pytorch, Tensorflow,經歷了幾個階段的發展和迭代,

圖中展示了幾個比較有代表性的深度學習框架,是不同時代的產物,比如圖里的Caffe來源于伯克利的一位博士生,框架本身效率高,但需要撰寫比較繁瑣的組態檔,在組態檔中會設定網路的層次、每一層的引數等所有細節,目前在工業界仍然是一個比較受歡迎的深度學習框架,另外,Keras的使用也比較廣泛,它一開始是建立在Tensorflow之上的,并封裝了很多的模塊,讓使用者可以更低門檻地去設計深度學習模型,目前也有大量的使用者,但缺點是,由于做了進一步的封裝,如果想做一些改動,靈活性上相比Tensorflow要差一些,
從這些框架中,如果讓我們選擇目前最火爆的,大多數人可能會毫無猶豫地選出Pytorch和TensorFlow,究其原因,還是因為它們的高效、靈活性以及低門檻的使用,Tensorflow作為Google公司一個重要的產品,在性能方面的表現也是可圈可點的,另一方面,Pytorch作為新的框架,這幾年展現出了超高的人氣和增長,主要源于它的低門檻且特別容易上手,
2.Pytorch框架的崛起
本節,我們主要比較TensorFlow與Pytorch兩個框架的發展歷史以及趨勢,分別從搜索熱度、學術界的歡迎度等角度來剖析,之所以選擇這兩個框架,一方面的原因在于確實這倆是目前最火爆的框架,另外一方面的原因是也比較適合剛步入AI領域的人士去接觸和學習,
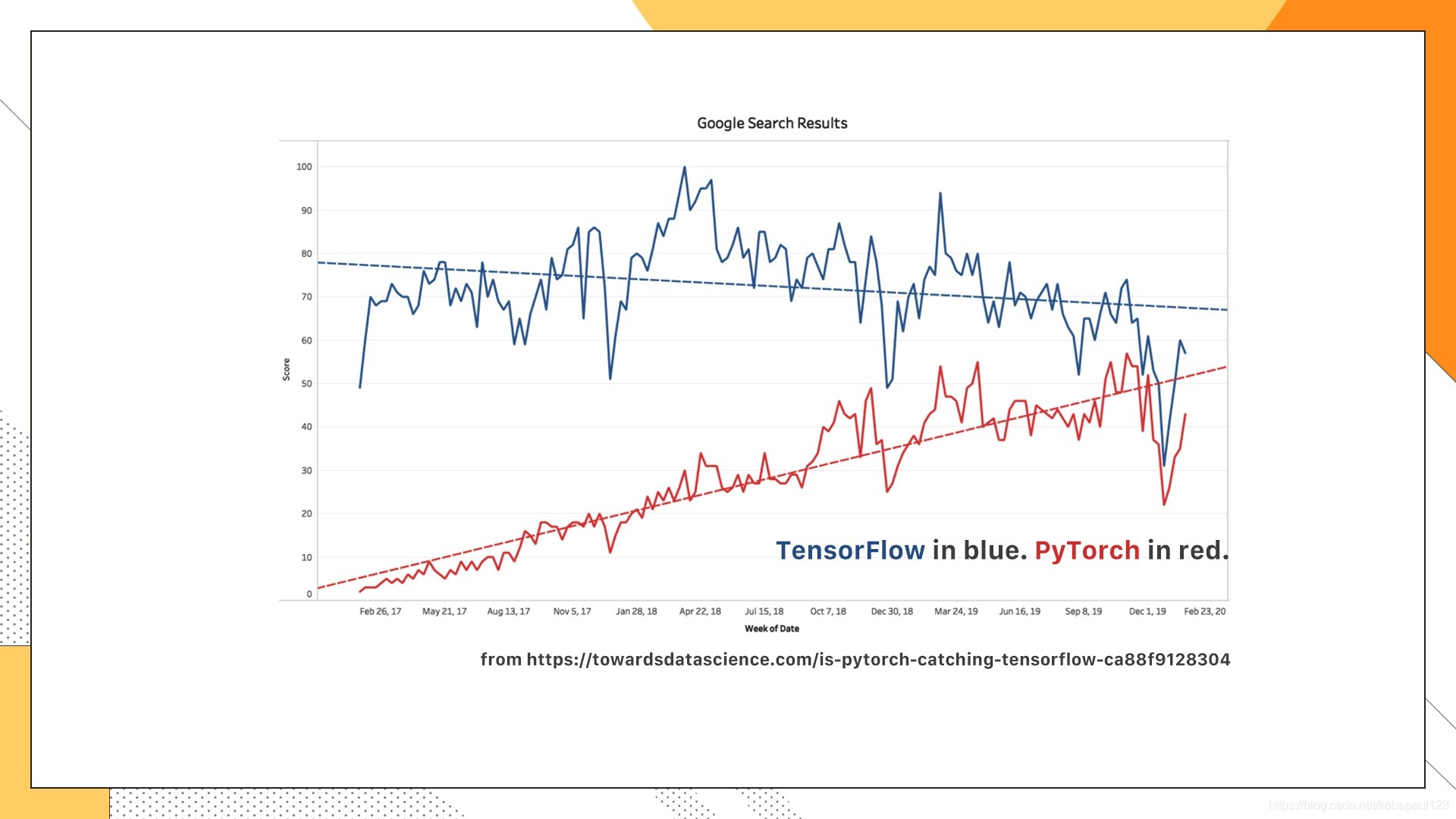
圖里展示的是Google搜索引擎上的搜索熱度,代表有多少人去搜索這兩個框架,從圖中可以很清楚地看到,17年的時候TensorFlow仍然占據著完全主導性的地位,但隨著時間的推移,Pytorch的增長越來越快,到了20年扯訓本上逼近了Tensorflow的熱度,而且這種增長趨勢仍在持續,
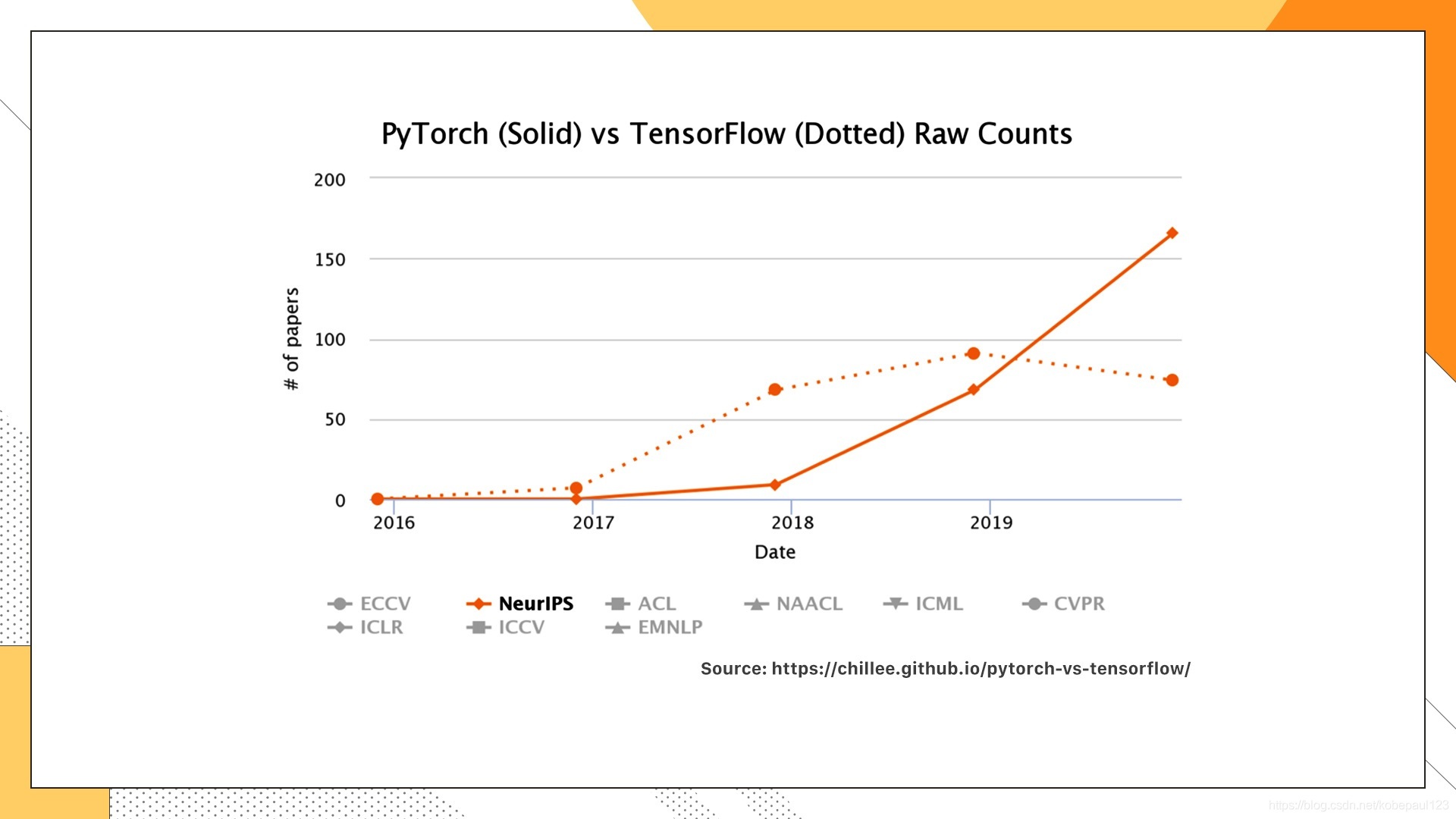
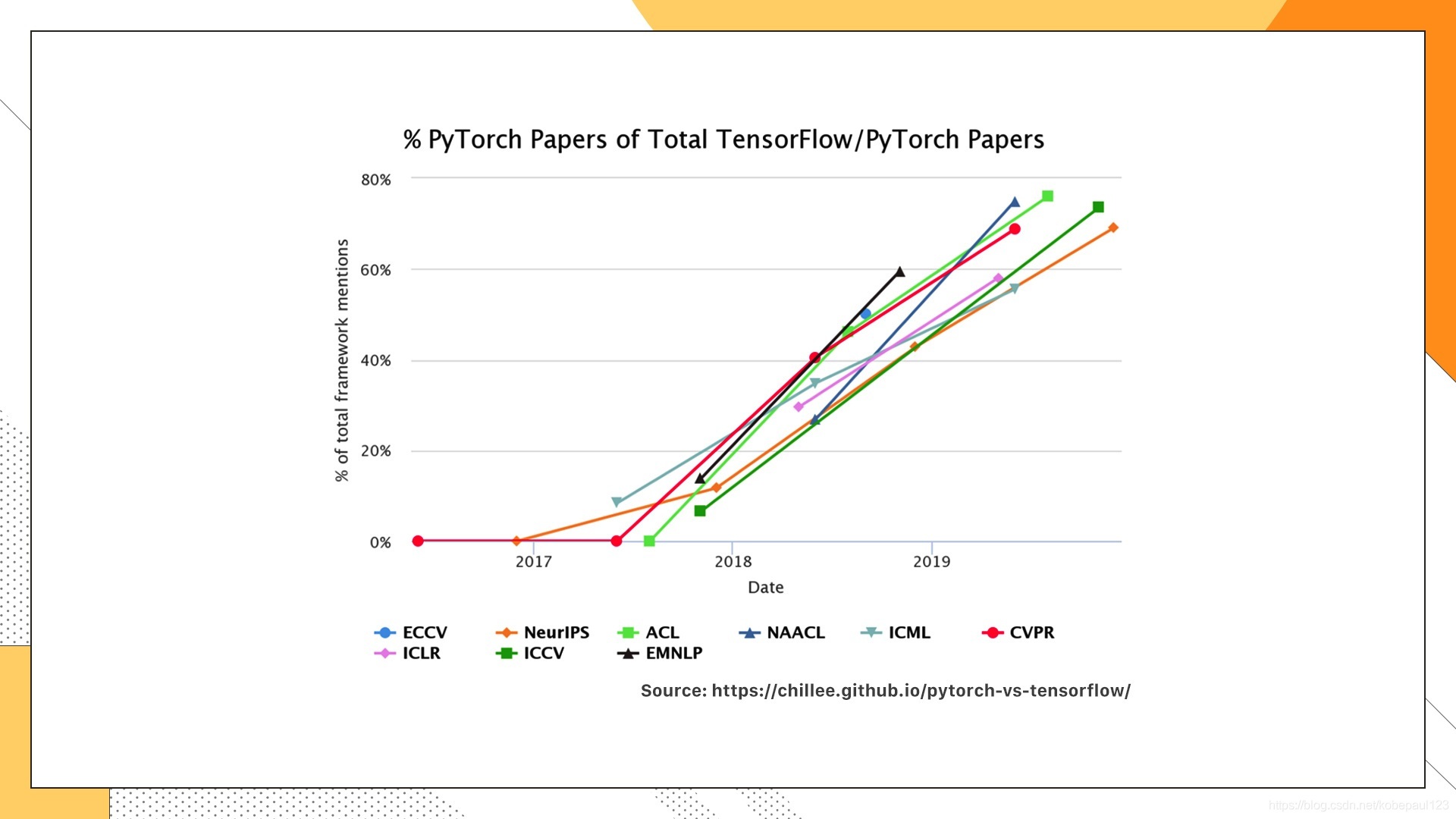
以上兩幅圖表示的是Pytorch和TensorFlow在學術界的使用情況,分別算出了每一年頂會中有多少篇文章的實驗用這兩個工具來做的,很容易發現,在學術界里Pytorch的優勢更加明顯,顯示出強勢的增長,那為什么會出現這種趨勢呢? 主要還是Pytorch用起來簡單,而且效率也不差,對于之前沒有接觸過深度學習框架的人,Pytorch無疑是首選,特別適合入門,
3.Pytorch與Tensorflow多方位比較
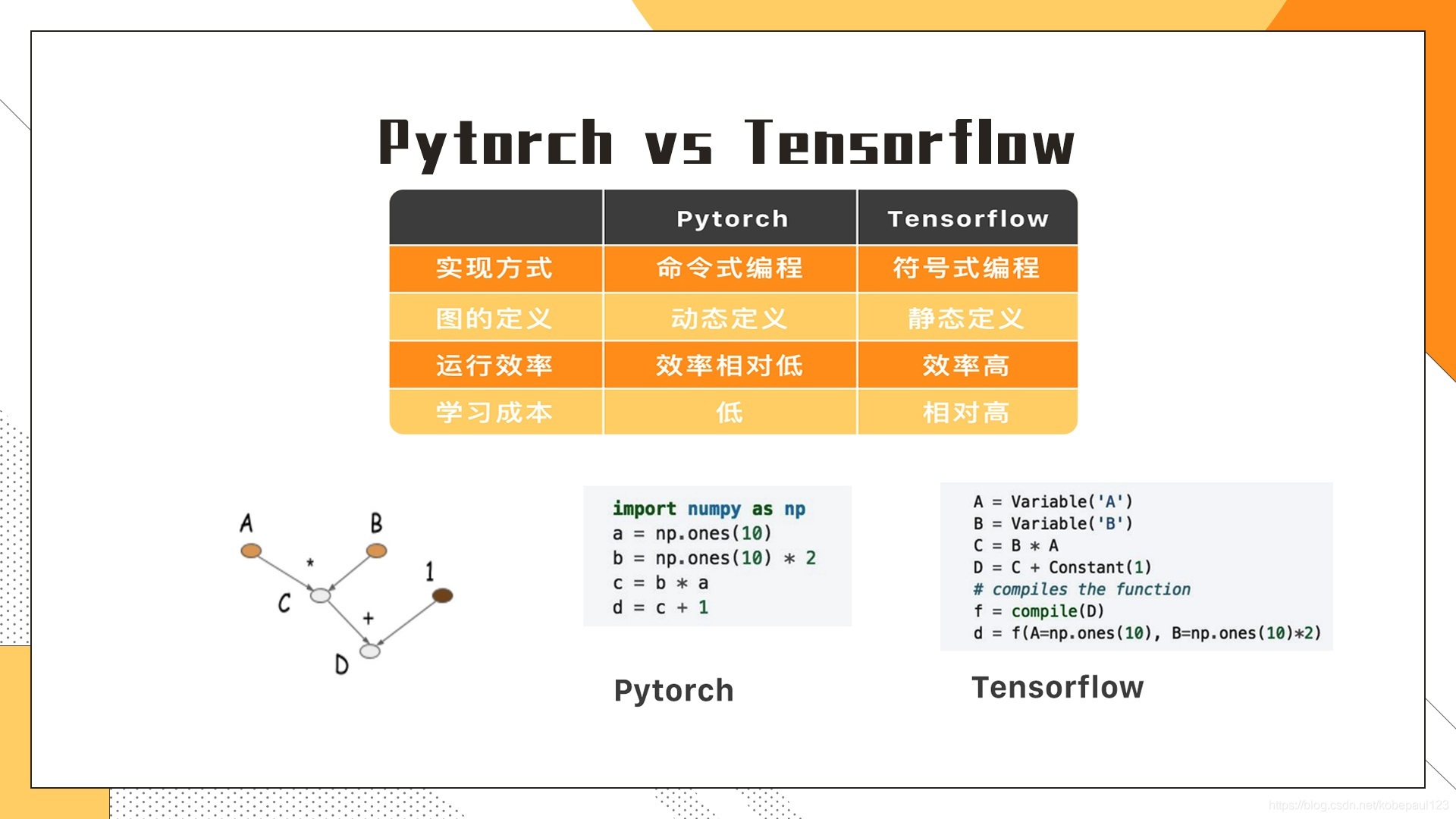
以上圖中給出了兩個框架之間具體的差異,其中最重要的差別在于Pytorch采用了命令式編程,TensorFlow則采用了符號式編程,實際上這是兩種完全不同的編程方式,命令式編程其實就是我們最熟悉的編程方式,比如使用Python, Java等等,然而,符號式編程就不一樣了,首選需要構建計算圖,然后再把資料灌到圖里做計算,
為了理解上述觀點,簡單看一下給出的幾行代碼, 左邊展示的是Pytorch框架下的程式,跟日常撰寫的程式沒什么差異,為了計算, 逐個去定義,并不斷地通過演算最終得出結果,
如果放在Tensorflow就不一樣了,我們首先構造了一個靜態的計算圖(computation graph),然后把變數之間的關系先確定好,在這里,變數為最后的輸出節點,定義好靜態計算圖之后,我們就可以把資料輸入給計算圖了,輸入資料接著會通過預先定義好的步驟最后能算出結果,
如果對上述概念比較難理解,你也可以想象一個這樣的場景,有一家公司現在試著去構建從城市A到B的管道,用來運輸一定量的石油,一種解決思路是,提前把管道全部制作完成,然后把石油輸入到管道中,之后通過一系列運輸程序最終可能會到達B城市,另外一種解決思路是,我們一邊制作管道,一邊運輸石油,在這種情況下管道的設計可以動態地改變,比如我們發現某個路徑不對勁,就可以換成另外一個路徑, 在這里例子中,前者對應的是符號式編程,后者對應的是命令式編程, 簡答來講,前者是靜態的,后者是動態的,動態的好處是靈活,但缺點是效率會低一些;相反,前者是靜態的,必須要提前準備好完整的計算圖(管道),之后才能使用,這種優勢在于使用時的效率高,但缺點是不好理解和debug,
因此,在之后的學習中,我們將采用Pytorch框架,也建議剛步入AI領域的人士使用Pytorch,會大大降低學習成本,下面我們主要來介紹Pytorch的常見的使用方法,
二、Tensors
1.Tensor的創建
首先需要理解Tensor這個關鍵詞,這是Pytorch中最基礎的資料結構,類似于Numpy庫中的array, matrix一樣,但在Pytorch我們把這些統一定義為Tensor,為什么要起這個名字呢? 這一點其實之前有講過,資料的表現形式通常為標量(scalar)、向量(vector)、矩陣(matrix)、張量(Tensor), 其中標量可以看作是0維的張量、向量看作是1維的張量、矩陣看作是2維的張量,依次類推,所以,最終我們可以把Tensor作為這些資料結構的統稱,這也是為什么像TensorFlow這種框架里包含Tensor關鍵詞的主要原因,
在Pytorch中,Tensor的使用非常類似于Numpy的用法,但區別于Numpy的資料,Tensor資料可以用在GPU等設備上去跑,可以大大提高演算法運行的效率,
Tensor庫的匯入
為了使用Pytorch的資料結構與功能,首先需要匯入相應的庫,這類似于當使用Numpy的時候匯入numpy庫一樣,對于Pytorch,我們可以匯入torch庫,
import torch
import numpy as np從已有資料直接構建Tensor
第一步是構建Tensor型別的資料,其中一個方法是直接利用已有的資料來初始化Tensor,如下所示:
data = [[1,3],[3,4]]
t_data = torch.tensor(data)把Numpy資料轉換成Tensor型別
如果資料已經表示為Numpy型別,我們也可以直接把它轉換為Tensor型別的資料,這種操作在實際專案中非常實用,
np_data = np.array(data)
t_data = torch.from_numpy(np_array)直接利用Tensor庫來創建Tensor資料
另外一種方式是直接使用Tensor所提供的方法來構造Tensor資料,這類似于我們呼叫numpy,zeors()函式來創建numpy型資料一樣,請看如下幾行代碼:
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)Tensor的屬性(attributes)
構建好Tensor之后,我們可以查看它的一些屬性如大小、型別、以及存放在cpu還是在gpu等資訊,以上屬性依次通過shape, dtype, device關鍵詞來獲取,
import torch
import numpy as np
data = torch.rand(3,4)
print(f"Shape of data: {data.shape}")
print(f"Datatype of data: {data.dtype}")
print(f"Device data is stored on: {data.device}")2.Tensor的操作
Tensor也像Numpy array支持各種各樣的運算操作,比如矩陣乘法、加法、采樣等等,而且這些運算均可以在GPU上進行,如果想把 Tensor在GPU做計算,需要把它先挪到GPU記憶體中,通過以下幾行代碼就可以實作:
if torch.cuda.is_available():
tensor = tensor.to('cuda')Tensor的索引
對于Tensor, 我們可以很方便的提取它的某一行、某一列、或者多行、多列,使用方法跟numpy幾乎一模一樣,
data = torch.ones(4,4)
data[:,1] = 0多個Tensor的拼接
很多時候,我們需要把多個Tensor做拼接,并轉換為更大的Tensor, 這種操作可以通過自帶的torch.cat()來完成,具體以哪個方向做拼接由dim引數來設定,
t1 = torch.cat([data, data, data], dim =1)Tensor的乘法
給定兩個Tensor也可以方便地完成乘法運算,這里需要注意的一點是,一種乘法運算可以是我們所熟知的正常的矩陣乘法運算,另外一種乘法運算是按照每一個位置的乘法運算,
data1 = torch.ones(2,2)
data2 = torch.ones(2,2)
mul_res1 = torch.matmul(data1, data2)
mul_res2 = data1 * data23.Tensor與Numpy
從Tensor到Numpy
在CPU上,Tensor和Numpy變數可以共享一個記憶體空間,改變其中一個會自動改變另外一個,從Tensor到numpy型別的轉化通過函式numpy()即可以實作,
t = torch.ones(5)
n = t.numpy()從Numpy到Tensor的轉換
另一個方向的轉換也極其簡單,可通過from_numpy()函式來完成,這種情況下兩個變數會共享一個記憶體,改變其中一個也會改變另外一個變數,這一點需要留意一下,
n = np.ones(5)
t = torch.from_numpy(n)三、Autograd的講解
1.模型中的前向傳播與反向傳播
之前已經介紹過神經網路中的前向傳播和反向傳播的概念,在這做一個簡單的回顧,對于神經網路的優化,一般分為兩個步驟:第一步為前向傳播,也就是給定訓練資料,通過前向傳播計算出模型中每個節點的輸出;第二步則為反向傳播,通過這一步計算出每一個引數的梯度,最后做引數的更新,實際上,Pytorch中的autograd模塊可以完成這些事情,
下面,來介紹一個具體的例子,首先,匯入已經訓練好的restnet模型,同時也構建一個隨機樣本,這個樣本為一張64*64的圖片且每一個像素由RGB來表示,對應的標簽為一個整數,
import torch, torchvision
model = torchvision.models.resnet18(pretrained=True)
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)2.利用autograd計算梯度
對于autograd再看一個例子,用來加深對它的理解,假如有兩個Tensor分別為a和b, 同時設定requires_grad=True, 這樣的結果就是autograd會保存對于相應變數的操作,
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(6.0, requires_grad=True)四、 構建神經網路模型
1.資料的構造
搭建的程序主要分為以下幾步:
- 資料的構造,這部分一般需要通過一些處理,跟之前的做法沒什么區別,如果有區別,就是需要把資料做成Tensor型別,
- 模型的構造,這是核心,也是Pytorch提供給我們的便捷的地方,
- 優化相關的設定,這一塊主要設定optimizer的選擇以及配置等資訊,
- 訓練模型,這一部分需要回圈我們的訓練資料,并一步步通過optimizer來優化模型的引數,
資料的構造
至于資料這塊,為了簡單期間,先用一個模擬的資料來代替,而且這并不影響我們對后續環節的理解,
# make fake data
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
2.模型的構造
對于模型這部分,需要設計的是前向傳播部分(forward),因為這部分其實決定了整個模型的細節,比如一個資料進入模型之后,如何一步步轉換成最終的輸出,轉換細節實際上就是模型的細節, 在構建模型時,我們通常會創建一個新的類(class),并起一個合適的名字給到神經網路,之后在初始化階段定義模型中所使用的引數和部件,接著在forward()函式中設計輸入到輸出中所經歷的所有的程序,
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.out = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2) # define the network3.優化器選擇和配置
設計好了模型之后,剩下的作業就是設計loss和配置優化器,在模型中我們定義了forward()函式內容,通過這個函式就可以得到對于輸入的預測,有了預測就可以跟真實值做比較來計算損失了,所以首先要定義損失函式的形態,是使用MSE還是交叉熵損失,還是Hinge Loss? 當然,這些取決于問題本身,在上述例子中,由于問題是二分類問題,我們決定選擇交叉熵損失(entropy loss),
loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hotted4.主函式
完成了所有上述步驟之后,剩下的就是主函式部分了,在這里需要定義要回圈多少次(epoch),如何保存中間結果,如何輸出準確率等內容,
for t in range(50):
out = net(x)
loss = loss_func(out, y)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if t % 2 == 0:
prediction = torch.max(out, 1)[1]
pred_y = prediction.data.numpy()
target_y = y.data.numpy()
accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
print ('Accuracy=%.2f' % accuracy)
plt.pause(0.1)參考:
貪心學院nlp
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290564.html
標籤:AI
上一篇:【李宏毅深度學習】階段性小結