表的Join是資料分析處理程序中必不可少的操作,Hive同樣支持Join的語法,Hive Join的底層還是通過MapReduce來實作的,Hive實作Join時,為了提高MapReduce的性能,提供了多種Join方案來實作,例如適合小表Join大表的Map Join,大表Join大表的Reduce Join,以及大表Join的優化方案Bucket Join等,
1 Map Join
- 應用場景
適合于小表join大表或者小表Join小表
- 原理
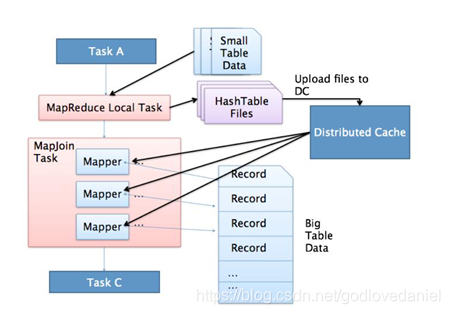
- 將小的那份資料給每個MapTask的記憶體都放一份完整的資料,大的資料每個部分都可以與小資料的完整資料進行join
- 底層不需要經過shuffle,需要占用記憶體空間存放小的資料檔案
- 使用
- 盡量使用Map Join來實作Join程序
- Hive中默認自動開啟了Map Join
| -- 默認已經開啟了Map Join hive.auto.convert.join=true |
Hive中判斷哪張表是小表及限制
- LEFT OUTER JOIN的左表必須是大表
- RIGHT OUTER JOIN的右表必須是大表
- INNER JOIN左表或右表均可以作為大表
- FULL OUTER JOIN不能使用MAPJOIN
- MAPJOIN支持小表為子查詢
- 使用MAPJOIN時需要參考小表或是子查詢時,需要參考別名
- 在MAPJOIN中,可以使用不等值連接或者使用OR連接多個條件
- 在MAPJOIN中最多支持指定6張小表,否則報語法錯誤
Hive中小表的大小限制
| -- 2.0版本之前的控制屬性 |
2 Reduce Join
應用場景
適合于大表Join大表
原理
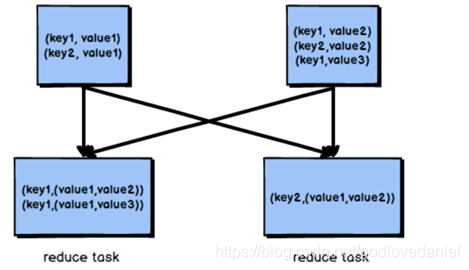
- 將兩張表的資料在shuffle階段利用shuffle的分組來將資料按照關聯欄位進行合并
- 必須經過shuffle,利用Shuffle程序中的分組來實作關聯
使用
Hive會自動判斷是否滿足Map Join,如果不滿足Map Join,則自動執行Reduce Join
3 Bucket Join
應用場景
適合于大表Join大表
原理
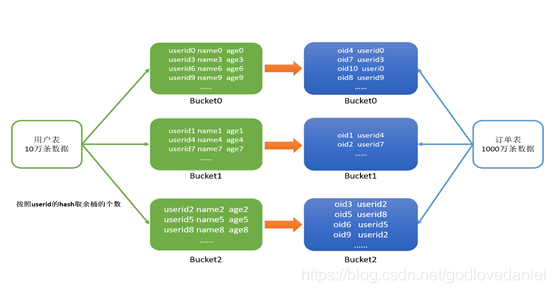
將兩張表按照相同的規則將資料劃分,根據對應的規則的資料進行join,減少了比較次數,提高了性能
- 使用
Bucket Join
- 語法:clustered by colName
- 引數
| -- 開啟分桶join |
2 要求
分桶欄位 = Join欄位 ,桶的個數相等或者成倍數
Sort Merge Bucket Join(SMB):基于有序的資料Join
- 語法:clustered by colName sorted by (colName)
- 引數
| -- 開啟分桶SMB join |
要求
分桶欄位 = Join欄位 = 排序欄位 ,桶的個數相等或者成倍數
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290602.html
標籤:其他
上一篇:zookeeper集群