📢歡迎關注博客主頁:https://blog.csdn.net/u013411339
📢歡迎點贊 👍 收藏 ?留言 📝 ,歡迎留言交流!
📢本文由【王知無】原創,首發于 CSDN博客!
📢本文首發CSDN論壇,未經過官方和本人允許,嚴禁轉載!
本文是對《【硬剛大資料之學習路線篇】2021年從零到大資料專家的學習指南(全面升級版)》的面試部分補充,
硬剛大資料系列文章鏈接:
-
2021年從零到大資料專家的學習指南(全面升級版)
-
2021年從零到大資料專家面試篇之Hadoop/HDFS/Yarn篇
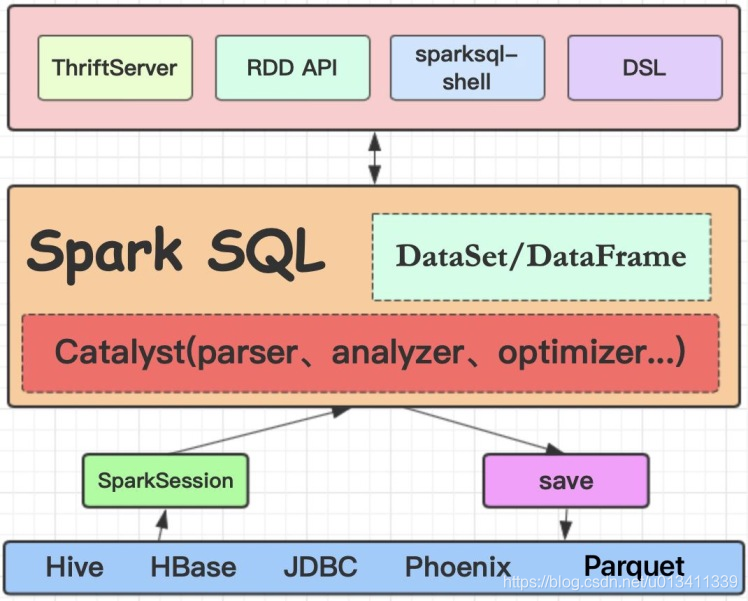
1.談談你對Spark SQL的理解
Spark SQL是一個用來處理結構化資料的Spark組件,前身是shark,但是shark過多的依賴于hive如采用hive的語法決議器、查詢優化器等,制約了Spark各個組件之間的相互集成,因此Spark SQL應運而生,
Spark SQL在汲取了shark諸多優勢如記憶體列存盤、兼容hive等基礎上,做了重新的構造,因此也擺脫了對hive的依賴,但同時兼容hive,除了采取記憶體列存盤優化性能,還引入了位元組碼生成技術、CBO和RBO對查詢等進行動態評估獲取最優邏輯計劃、物理計劃執行等,基于這些優化,使得Spark SQL相對于原有的SQL on Hadoop技術在性能方面得到有效提升,
同時,Spark SQL支持多種資料源,如JDBC、HDFS、HBase,它的內部組件,如SQL的語法決議器、分析器等支持重定義進行擴展,能更好的滿足不同的業務場景,與Spark Core無縫集成,提供了DataSet/DataFrame的可編程抽象資料模型,并且可被視為一個分布式的SQL查詢引擎,
2.談談你對DataSet/DataFrame的理解
DataSet/DataFrame都是Spark SQL提供的分布式資料集,相對于RDD而言,除了記錄資料以外,還記錄表的schema資訊,
DataSet是自Spark1.6開始提供的一個分布式資料集,具有RDD的特性比如強型別、可以使用強大的lambda運算式,并且使用Spark SQL的優化執行引擎,DataSet API支持Scala和Java語言,不支持Python,但是鑒于Python的動態特性,它仍然能夠受益于DataSet API(如,你可以通過一個列名從Row里獲取這個欄位 row.columnName),類似的還有R語言,
DataFrame是DataSet以命名列方式組織的分布式資料集,類似于RDBMS中的表,或者R和Python中的 data frame,DataFrame API支持Scala、Java、Python、R,在Scala API中,DataFrame變成型別為Row的Dataset:
type DataFrame = Dataset[Row],
DataFrame在編譯期不進行資料中欄位的型別檢查,在運行期進行檢查,但DataSet則與之相反,因為它是強型別的,此外,二者都是使用catalyst進行sql的決議和優化,為了方便,以下統一使用DataSet統稱,
DataSet創建
DataSet通常通過加載外部資料或通過RDD轉化創建,
- 1.加載外部資料
以加載json和mysql為例:
val ds = sparkSession.read.json("/路徑/people.json")
val ds = sparkSession.read.format("jdbc")
.options(Map("url" -> "jdbc:mysql://ip:port/db",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "tableName", "user" -> "root", "root" -> "123")).load()
- 2.RDD轉換為DataSet
通過RDD轉化創建DataSet,關鍵在于為RDD指定schema,通常有兩種方式(偽代碼):
1.定義一個case class,利用反射機制來推斷
1) 從HDFS中加載檔案為普通RDD
val lineRDD = sparkContext.textFile("hdfs://ip:port/person.txt").map(_.split(" "))
2) 定義case class(相當于表的schema)
case class Person(id:Int, name:String, age:Int)
3) 將RDD和case class關聯
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
4) 將RDD轉換成DataFrame
val ds= personRDD.toDF
2.手動定義一個schema StructType,直接指定在RDD上
val schemaString ="name age"
val schema = StructType(schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
val rowRdd = peopleRdd.map(p=>Row(p(0),p(1)))
val ds = sparkSession.createDataFrame(rowRdd,schema)
操作DataSet的兩種風格語法
DSL語法
1.查詢DataSet部分列中的內容
personDS.select(col("name"))
personDS.select(col("name"), col("age"))
2.查詢所有的name和age和salary,并將salary加1000
personDS.select(col("name"), col("age"), col("salary") + 1000)
personDS.select(personDS("name"), personDS("age"), personDS("salary") + 1000)
3.過濾age大于18的
personDS.filter(col("age") > 18)
4.按年齡進行分組并統計相同年齡的人數
personDS.groupBy("age").count()
注意:直接使用col方法需要import org.apache.spark.sql.functions._
SQL語法
如果想使用SQL風格的語法,需要將DataSet注冊成表
personDS.registerTempTable("person")
//查詢年齡最大的前兩名
val result = sparkSession.sql("select * from person order by age desc limit 2")
//保存結果為json檔案,注意:如果不指定存盤格式,則默認存盤為parquet
result.write.format("json").save("hdfs://ip:port/res2")
3.說說Spark SQL的幾種使用方式
- 1.sparksql-shell互動式查詢
就是利用Spark提供的shell命令列執行SQL
- 2.編程
首先要獲取Spark SQL編程"入口":SparkSession(當然在早期版本中大家可能更熟悉的是SQLContext,如果是操作hive則為HiveContext),這里以讀取parquet為例:
val spark = SparkSession.builder()
.appName("example").master("local[*]").getOrCreate();
val df = sparkSession.read.format("parquet").load("/路徑/parquet檔案")
然后就可以針對df進行業務處理了,
- 3.Thriftserver
beeline客戶端連接操作
啟動spark-sql的thrift服務,sbin/start-thriftserver.sh,啟動腳本中配置好Spark集群服務資源、地址等資訊,然后通過beeline連接thrift服務進行資料處理,
hive-jdbc驅動包來訪問spark-sql的thrift服務
在專案pom檔案中引入相關驅動包,跟訪問mysql等jdbc資料源類似,示例:
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://ip:port", "root", "123");
try {
val stat = conn.createStatement()
val res = stat.executeQuery("select * from people limit 1")
while (res.next()) {
println(res.getString("name"))
}
} catch {
case e: Exception => e.printStackTrace()
} finally{
if(conn!=null) conn.close()
}
4.說說Spark SQL 獲取Hive資料的方式
Spark SQL讀取hive資料的關鍵在于將hive的元資料作為服務暴露給Spark,除了通過上面thriftserver jdbc連接hive的方式,也可以通過下面這種方式:
首先,配置 $HIVE_HOME/conf/hive-site.xml,增加如下內容:
<property>
<name>hive.metastore.uris</name>
<value>thrift://ip:port</value>
</property>
然后,啟動hive metastore
最后,將hive-site.xml復制或者軟鏈到 S P A R K H O M E / c o n f / , 如 果 h i v e 的 元 數 據 存 儲 在 m y s q l 中 , 那 么 需 要 將 m y s q l 的 連 接 驅 動 j a r 包 如 m y s q l ? c o n n e c t o r ? j a v a ? 5.1.12. j a r 放 到 SPARK_HOME/conf/,如果hive的元資料存盤在mysql中,那么需要將mysql的連接驅動jar包如mysql-connector-java-5.1.12.jar放到 SPARKH?OME/conf/,如果hive的元數據存儲在mysql中,那么需要將mysql的連接驅動jar包如mysql?connector?java?5.1.12.jar放到SPARK_HOME/lib/下,啟動spark-sql即可操作hive中的庫和表,而此時使用hive元資料獲取SparkSession的方式為:
val spark = SparkSession.builder()
.config(sparkConf).enableHiveSupport().getOrCreate()
5.分別說明UDF、UDAF、Aggregator
- UDF
UDF是最基礎的用戶自定義函式,以自定義一個求字串長度的udf為例:
val udf_str_length = udf{(str:String) => str.length}
spark.udf.register("str_length",udf_str_length)
val ds =sparkSession.read.json("路徑/people.json")
ds.createOrReplaceTempView("people")
sparkSession.sql("select str_length(address) from people")
- UDAF
定義UDAF,需要繼承抽象類UserDefinedAggregateFunction,它是弱型別的,下面的aggregator是強型別的,以求平均數為例:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
object MyAverage extends UserDefinedAggregateFunction {
// Data types of input arguments of this aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data types of values in the aggregation buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// The data type of the returned value
def dataType: DataType = DoubleType
// Whether this function always returns the same output on the identical input
def deterministic: Boolean = true
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculates the final result
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
// Register the function to access it
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("examples/src/main/resources/employees.json")
df.createOrReplaceTempView("employees")
df.show()
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()
- Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
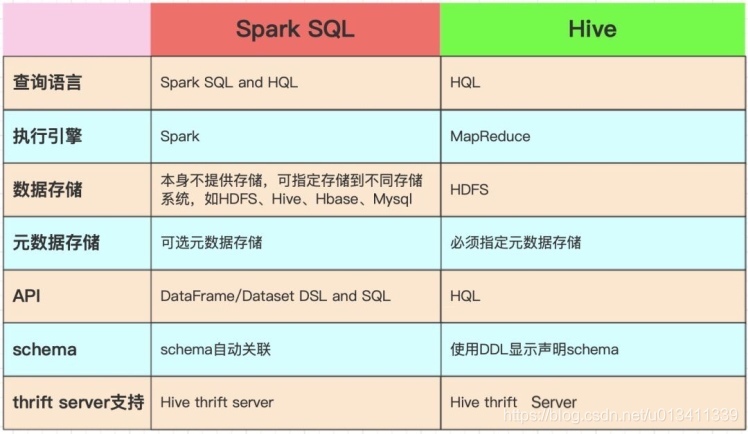
6.對比一下Spark SQL與HiveSQL
7.說說Spark SQL決議查詢parquet格式Hive表如何獲取磁區欄位和查詢條件
問題現象
sparksql加載指定Hive磁區表路徑,生成的DataSet沒有磁區欄位,
如,sparkSession.read.format("parquet").load(s"${hive_path}"),hive_path為Hive磁區表在HDFS上的存盤路徑,
hive_path的幾種指定方式會導致這種情況的發生(test_partition是一個Hive外部磁區表,dt是它的磁區欄位,磁區資料有dt為20200101和20200102):
1.hive_path為"/spark/dw/test.db/test_partition/dt=20200101"
2.hive_path為"/spark/dw/test.db/test_partition/*"
因為牽涉到的原始碼比較多,這里僅以示例的程式中涉及到的原始碼中的class、object和方法,繪制成xmind圖如下,想細心研究的可以參考該圖到spark原始碼中進行分析,
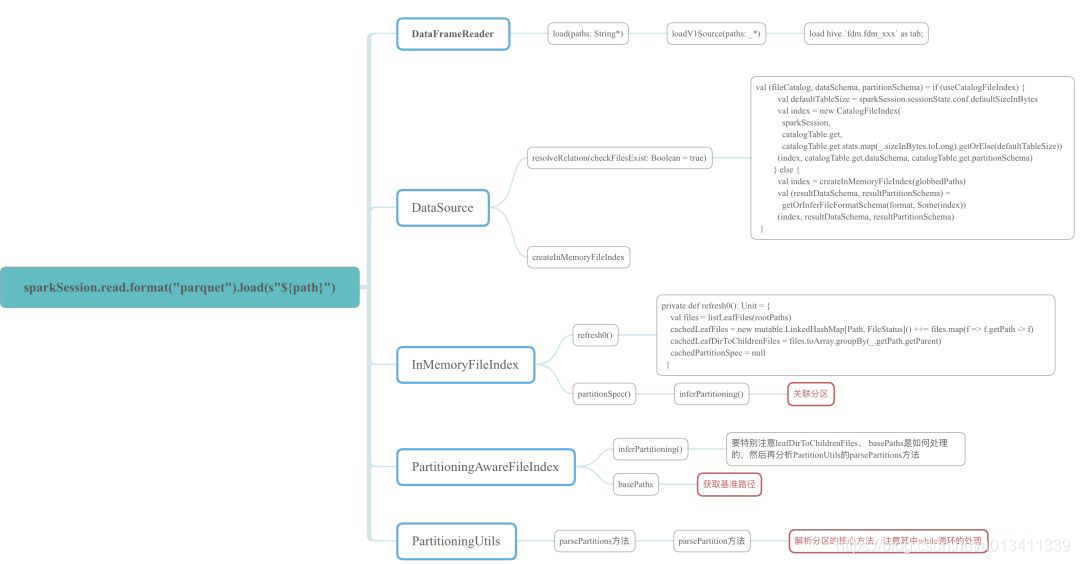
問題分析
這里主要給出幾個原始碼段,結合上述xmind圖理解:
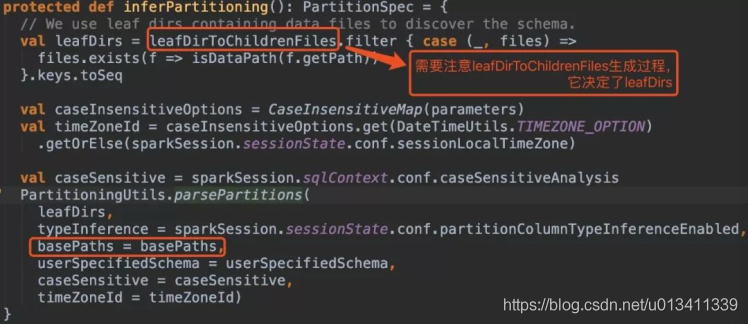
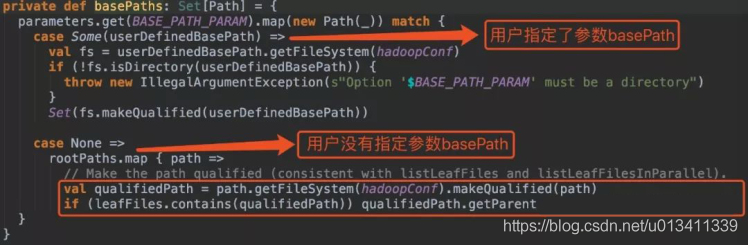
在沒有指定引數basePath的情況下:
1.hive_path為/spark/dw/test.db/test_partition/dt=20200101
sparksql底層處理后得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【偽代碼】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【偽代碼】
2.hive_path為/spark/dw/test.db/test_partition/*
sparksql底層處理后得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【偽代碼】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【偽代碼】
這兩種情況導致原始碼if(basePaths.contains(currentPath))為true,還沒有決議磁區就重置變數finished為true跳出回圈,因此最終生成的結果也就沒有磁區欄位:
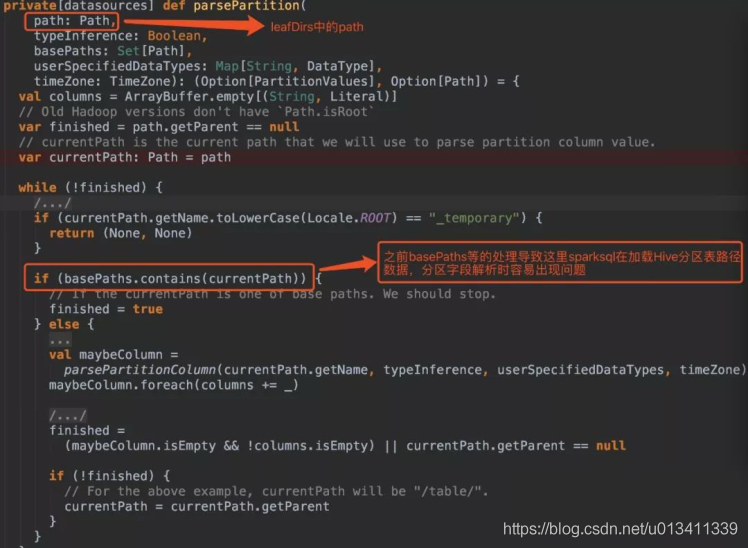
解決方案
-
1.在Spark SQL加載Hive表資料路徑時,指定引數basePath,如
sparkSession.read.option(“basePath”,"/spark/dw/test.db/test_partition") -
2.主要重寫basePaths方法和parsePartition方法中的處理邏輯,同時需要修改其他涉及的代碼,由于涉及需要改寫的代碼比較多,可以封裝成工具
8.說說你對Spark SQL 小檔案問題處理的理解
在生產中,無論是通過SQL陳述句或者Scala/Java等代碼的方式使用Spark SQL處理資料,在Spark SQL寫資料時,往往會遇到生成的小檔案過多的問題,而管理這些大量的小檔案,是一件非常頭疼的事情,
大量的小檔案會影響Hadoop集群管理或者Spark在處理資料時的穩定性:
1.Spark SQL寫Hive或者直接寫入HDFS,過多的小檔案會對NameNode記憶體管理等產生巨大的壓力,會影響整個集群的穩定運行
2.容易導致task數過多,如果超過引數spark.driver.maxResultSize的配置(默認1g),會拋出類似如下的例外,影響任務的處理
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of 478 tasks (2026.0 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
當然可以通過調大spark.driver.maxResultSize的默認配置來解決問題,但如果不能從源頭上解決小檔案問題,以后還可能遇到類似的問題,
此外,Spark在處理任務時,一個磁區分配一個task進行處理,多個磁區并行處理,雖然并行處理能夠提高處理效率,但不是意味著task數越多越好,如果資料量不大,過多的task運行反而會影響效率,
最后,Spark中一個task處理一個磁區從而也會影響最終生成的檔案數,
在數倉建設中,產生小檔案過多的原因有很多種,比如:
1.流式處理中,每個批次的處理執行保存操作也會產生很多小檔案
2.為了解決資料更新問題,同一份資料保存了不同的幾個狀態,也容易導致檔案數過多
那么如何解決這種小檔案的問題呢?
-
1.通過repartition或coalesce算子控制最后的DataSet的磁區數
注意repartition和coalesce的區別 -
2.將Hive風格的Coalesce and Repartition Hint 應用到Spark SQL
需要注意這種方式對Spark的版本有要求,建議在Spark2.4.X及以上版本使用,示例:
INSERT ... SELECT /*+ COALESCE(numPartitions) */ ...
INSERT ... SELECT /*+ REPARTITION(numPartitions) */ ...
- 3.小檔案定期合并可以定時通過異步的方式針對Hive磁區表的每一個磁區中的小檔案進行合并操作
上述只是給出3種常見的解決辦法,并且要結合實際用到的技術和場景去具體處理,比如對于HDFS小檔案過多,也可以通過生成HAR 檔案或者Sequence File來解決,
9.SparkSQL讀寫Hive metastore Parquet遇到過什么問題嗎?
Spark SQL為了更好的性能,在讀寫Hive metastore parquet格式的表時,會默認使用自己的Parquet SerDe,而不是采用Hive的SerDe進行序列化和反序列化,該行為可以通過配置引數spark.sql.hive.convertMetastoreParquet進行控制,默認true,
這里從表schema的處理角度而言,就必須注意Hive和Parquet兼容性,主要有兩個區別:
1.Hive是大小寫敏感的,但Parquet相反
2.Hive會將所有列視為nullable,但是nullability在parquet里有獨特的意義
由于上面的原因,在將Hive metastore parquet轉化為Spark SQL parquet時,需要兼容處理一下Hive和Parquet的schema,即需要對二者的結構進行一致化,主要處理規則是:
1.有相同名字的欄位必須要有相同的資料型別,忽略nullability,兼容處理的欄位應該保持Parquet側的資料型別,這樣就可以處理到nullability型別了(空值問題)
2.兼容處理的schema應只包含在Hive元資料里的schema資訊,主要體現在以下兩個方面:
(1)只出現在Parquet schema的欄位會被忽略
(2)只出現在Hive元資料里的欄位將會被視為nullable,并處理到兼容后的schema中
關于schema(或者說元資料metastore),Spark SQL在處理Parquet表時,同樣為了更好的性能,會快取Parquet的元資料資訊,此時,如果直接通過Hive或者其他工具對該Parquet表進行修改導致了元資料的變化,那么Spark SQL快取的元資料并不能同步更新,此時需要手動重繪Spark SQL快取的元資料,來確保元資料的一致性,方式如下:
// 第一種方式應用的比較多
1. sparkSession.catalog.refreshTable(s"${dbName.tableName}")
2. sparkSession.catalog.refreshByPath(s"${path}")
10.說說Spark SQL如何選擇join策略
在了解join策略選擇之前,首先看幾個先決條件:
- 1. build table的選擇
Hash Join的第一步就是根據兩表之中較小的那一個構建哈希表,這個小表就叫做build table,大表則稱為probe table,因為需要拿小表形成的哈希表來"探測"它,原始碼如下:
/* 左表作為build table的條件,join型別需滿足:
1. InnerLike:實作目前包括inner join和cross join
2. RightOuter:right outer join
*/
private def canBuildLeft(joinType: JoinType): Boolean = joinType match {
case _: InnerLike | RightOuter => true
case _ => false
}
/* 右表作為build table的條件,join型別需滿足(第1種是在業務開發中寫的SQL主要適配的):
1. InnerLike、LeftOuter(left outer join)、LeftSemi(left semi join)、LeftAnti(left anti join)
2. ExistenceJoin:only used in the end of optimizer and physical plans, we will not generate SQL for this join type
*/
private def canBuildRight(joinType: JoinType): Boolean = joinType match {
case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => true
case _ => false
}
- 2. 滿足什么條件的表才能被廣播
如果一個表的大小小于或等于引數spark.sql.autoBroadcastJoinThreshold(默認10M)配置的值,那么就可以廣播該表,原始碼如下:
private def canBroadcastBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
: Boolean = {
val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
val buildRight = canBuildRight(joinType) && canBroadcast(right)
buildLeft || buildRight
}
private def canBroadcast(plan: LogicalPlan): Boolean = {
plan.stats.sizeInBytes >= 0 && plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold
}
private def broadcastSideBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
: BuildSide = {
val buildLeft = canBuildLeft(joinType) && canBroadcast(left)
val buildRight = canBuildRight(joinType) && canBroadcast(right)
// 最侄訓呼叫broadcastSide
broadcastSide(buildLeft, buildRight, left, right)
}
除了通過上述表的大小滿足一定條件之外,我們也可以通過直接在Spark SQL中顯示使用hint方式(/*+ BROADCAST(small_table) */),直接指定要廣播的表,原始碼如下:
private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
: Boolean = {
val buildLeft = canBuildLeft(joinType) && left.stats.hints.broadcast
val buildRight = canBuildRight(joinType) && right.stats.hints.broadcast
buildLeft || buildRight
}
private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan)
: BuildSide = {
val buildLeft = canBuildLeft(joinType) && left.stats.hints.broadcast
val buildRight = canBuildRight(joinType) && right.stats.hints.broadcast
// 最侄訓呼叫broadcastSide
broadcastSide(buildLeft, buildRight, left, right)
}
無論是通過表大小進行廣播還是根據是否指定hint進行表廣播,最終都會呼叫broadcastSide,來決定應該廣播哪個表:
private def broadcastSide(
canBuildLeft: Boolean,
canBuildRight: Boolean,
left: LogicalPlan,
right: LogicalPlan): BuildSide = {
def smallerSide =
if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeft
if (canBuildRight && canBuildLeft) {
// 如果左表和右表都能作為build table,則將根據表的統計資訊,確定physical size較小的表作為build table(即使兩個表都被指定了hint)
smallerSide
} else if (canBuildRight) {
// 上述條件不滿足,優先判斷右表是否滿足build條件,滿足則廣播右表,否則,接著判斷左表是否滿足build條件
BuildRight
} else if (canBuildLeft) {
BuildLeft
} else {
// 如果左表和右表都不能作為build table,則將根據表的統計資訊,確定physical size較小的表作為build table,目前主要用于broadcast nested loop join
smallerSide
}
}
從上述原始碼可知,即使用戶指定了廣播hint,實際執行時,不一定按照hint的表進行廣播,
- 3. 是否可構造本地HashMap
應用于Shuffle Hash Join中,原始碼如下:
// 邏輯計劃的單個磁區足夠小到構建一個hash表
// 注意:要求磁區數是固定的,如果磁區數是動態的,還需滿足其他條件
private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {
// 邏輯計劃的physical size小于spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions(默認200)時,即可構造本地HashMap
plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
}
SparkSQL目前主要實作了3種join:Broadcast Hash Join、ShuffledHashJoin、Sort Merge Join,那么Catalyst在處理SQL陳述句時,是依據什么規則進行join策略選擇的呢?
1. Broadcast Hash Join
主要根據hint和size進行判斷是否滿足條件,
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// broadcast hints were not specified, so need to infer it from size and configuration.
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
2. Shuffle Hash Join
選擇Shuffle Hash Join需要同時滿足以下條件:
- spark.sql.join.preferSortMergeJoin為false,即Shuffle Hash Join優先于Sort Merge Join
- 右表或左表是否能夠作為build table
- 是否能構建本地HashMap
- 以右表為例,它的邏輯計劃大小要遠小于左表大小(默認3倍)
上述條件優先檢查右表,
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)
&& muchSmaller(right, left) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildLeft(joinType) && uildLocalHashMap(left)
&& muchSmaller(left, right) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))
private def muchSmaller(a: LogicalPlan, b: LogicalPlan): Boolean = {
a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
}
如果不滿足上述條件,但是如果參與join的表的key無法被排序,即無法使用Sort Merge Join,最終也會選擇Shuffle Hash Join,
!RowOrdering.isOrderable(leftKeys)
def isOrderable(exprs: Seq[Expression]): Boolean = exprs.forall(e => isOrderable(e.dataType))
3. Sort Merge Join
如果上面兩種join策略(Broadcast Hash Join和Shuffle Hash Join)都不符合條件,并且參與join的key是可排序的,就會選擇Sort Merge Join,
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if RowOrdering.isOrderable(leftKeys) =>
joins.SortMergeJoinExec(
leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil
4. Without joining keys
Broadcast Hash Join、Shuffle Hash Join和Sort Merge Join都屬于經典的ExtractEquiJoinKeys(等值連接條件),
對于非ExtractEquiJoinKeys,則會優先檢查表是否可以被廣播(hint或者size),如果可以,則會使用BroadcastNestedLoopJoin(簡稱BNLJ),熟悉Nested Loop Join則不難理解BNLJ,主要卻別在于BNLJ加上了廣播表,
原始碼如下:
// Pick BroadcastNestedLoopJoin if one side could be broadcast
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
如果表不能被廣播,又細分為兩種情況:
- 若join型別InnerLike(關于InnerLike上面已有介紹)對量表直接進行笛卡爾積處理若
- 上述情況都不滿足,最終方案是選擇兩個表中physical size較小的表進行廣播,join策略仍為BNLJ
原始碼如下:
// Pick CartesianProduct for InnerJoin
case logical.Join(left, right, _: InnerLike, condition) =>
joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nil
case logical.Join(left, right, joinType, condition) =>
val buildSide = broadcastSide(
left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)
// This join could be very slow or OOM
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
11.講講Spark SQL中Not in Subquery為何低效以及如何規避
首先看個Not in Subquery的SQL:
// test_partition1 和 test_partition2為Hive外部磁區表
select * from test_partition1 t1 where t1.id not in (select id from test_partition2);
對應的完整的邏輯計劃和物理計劃為:
== Parsed Logical Plan ==
'Project [*]
+- 'Filter NOT 't1.id IN (list#3 [])
: +- 'Project ['id]
: +- 'UnresolvedRelation `test_partition2`
+- 'SubqueryAlias `t1`
+- 'UnresolvedRelation `test_partition1`
== Analyzed Logical Plan ==
id: string, name: string, dt: string
Project [id#4, name#5, dt#6]
+- Filter NOT id#4 IN (list#3 [])
: +- Project [id#7]
: +- SubqueryAlias `default`.`test_partition2`
: +- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#7, name#8], [dt#9]
+- SubqueryAlias `t1`
+- SubqueryAlias `default`.`test_partition1`
+- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#4, name#5], [dt#6]
== Optimized Logical Plan ==
Join LeftAnti, ((id#4 = id#7) || isnull((id#4 = id#7)))
:- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#4, name#5], [dt#6]
+- Project [id#7]
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#7, name#8], [dt#9]
== Physical Plan ==
BroadcastNestedLoopJoin BuildRight, LeftAnti, ((id#4 = id#7) || isnull((id#4 = id#7)))
:- Scan hive default.test_partition1 [id#4, name#5, dt#6], HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#4, name#5], [dt#6]
+- BroadcastExchange IdentityBroadcastMode
+- Scan hive default.test_partition2 [id#7], HiveTableRelation `default
通過上述邏輯計劃和物理計劃可以看出,Spark SQL在對not in subquery處理,從邏輯計劃轉換為物理計劃時,會最終選擇BroadcastNestedLoopJoin(對應到Spark原始碼中BroadcastNestedLoopJoinExec.scala)策略,
提起BroadcastNestedLoopJoin,不得不提Nested Loop Join,它在很多RDBMS中得到應用,比如mysql,它的作業方式是回圈從一張表(outer table)中讀取資料,然后訪問另一張表(inner table,通常有索引),將outer表中的每一條資料與inner表中的資料進行join,類似一個嵌套的回圈并且在回圈的程序中進行資料的比對校驗是否滿足一定條件,
對于被連接的資料集較小的情況下,Nested Loop Join是個較好的選擇,但是當資料集非常大時,從它的執行原理可知,效率會很低甚至可能影響整個服務的穩定性,
而Spark SQL中的BroadcastNestedLoopJoin就類似于Nested Loop Join,只不過加上了廣播表(build table)而已,
BroadcastNestedLoopJoin是一個低效的物理執行計劃,內部實作將子查詢(select id from test_partition2)進行廣播,然后test_partition1每一條記錄通過loop遍歷廣播的資料去匹配是否滿足一定條件,
private def leftExistenceJoin(
// 廣播的資料
relation: Broadcast[Array[InternalRow]],
exists: Boolean): RDD[InternalRow] = {
assert(buildSide == BuildRight)
/* streamed對應物理計劃中:
Scan hive default.test_partition1 [id#4, name#5, dt#6], HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#4, name#5], [dt#6]
*/
streamed.execute().mapPartitionsInternal { streamedIter =>
val buildRows = relation.value
val joinedRow = new JoinedRow
// 條件是否定義,此處為Some(((id#4 = id#7) || isnull((id#4 = id#7))))
if (condition.isDefined) {
streamedIter.filter(l =>
// exists主要是為了根據joinType來進一步條件判斷資料的回傳與否,此處joinType為LeftAnti
buildRows.exists(r => boundCondition(joinedRow(l, r))) == exists
)
// else
} else if (buildRows.nonEmpty == exists) {
streamedIter
} else {
Iterator.empty
}
}
}
由于BroadcastNestedLoopJoin的低效率執行,可能導致長時間占用executor資源,影響集群性能,同時,因為子查詢的結果集要進行廣播,如果資料量特別大,對driver端也是一個嚴峻的考驗,極有可能帶來OOM的風險,因此,在實際生產中,要盡可能利用其他效率相對高的SQL來避免使用Not in Subquery,
雖然通過改寫Not in Subquery的SQL,進行低效率的SQL到高效率的SQL過渡,能夠避免上面所說的問題,但是這往往建立在我們發現任務執行慢甚至失敗,然后排查任務中的SQL,發現"問題"SQL的前提下,那么如何在任務執行前,就"檢查"出這樣的SQL,從而進行提前預警呢?
這里給出一個思路,就是決議Spark SQL計劃,根據Spark SQL的join策略匹配條件等,來判斷任務中是否使用了低效的Not in Subquery進行預警,然后通知業務方進行修改,同時,我們在實際完成資料的ETL處理等分析時,也要事前避免類似的低性能SQL,
12.說說SparkSQL中產生笛卡爾積的幾種典型場景以及處理策略
Spark SQL幾種產生笛卡爾積的典型場景
首先來看一下在Spark SQL中產生笛卡爾積的幾種典型SQL:
- join陳述句中不指定on條件
select * from test_partition1 join test_partition2;
- join陳述句中指定不等值連接
select * from test_partition1 t1 inner join test_partition2 t2 on t1.name <> t2.name;
- join陳述句on中用or指定連接條件
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id or t1.name = t2.name;
- join陳述句on中用||指定連接條件
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id || t1.name = t2.name;
除了上述舉的幾個典型例子,實際業務開發中產生笛卡爾積的原因多種多樣,
同時需要注意,在一些SQL中即使滿足了上述4種規則之一也不一定產生笛卡爾積,比如,對于join陳述句中指定不等值連接條件的下述SQL不會產生笛卡爾積:
--在Spark SQL內部優化程序中針對join策略的選擇,最侄訓通過SortMergeJoin進行處理,
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.i
此外,對于直接在SQL中使用cross join的方式,也不一定產生笛卡爾積,比如下述SQL:
-- Spark SQL內部優化程序中選擇了SortMergeJoin方式進行處理
select * from test_partition1 t1 cross join test_partition2 t2 on t1.id = t2.id;
但是如果cross join沒有指定on條件同樣會產生笛卡爾積,
那么如何判斷一個SQL是否產生了笛卡爾積呢?
Spark SQL是否產生了笛卡爾積
以join陳述句不指定on條件產生笛卡爾積的SQL為例:
-- test_partition1和test_partition2是Hive磁區表
select * from test_partition1 join test_partition2;
通過Spark UI上SQL一欄查看上述SQL執行圖,如下:
可以看出,因為該join陳述句中沒有指定on連接查詢條件,導致了CartesianProduct即笛卡爾積,
再來看一下該join陳述句的邏輯計劃和物理計劃:
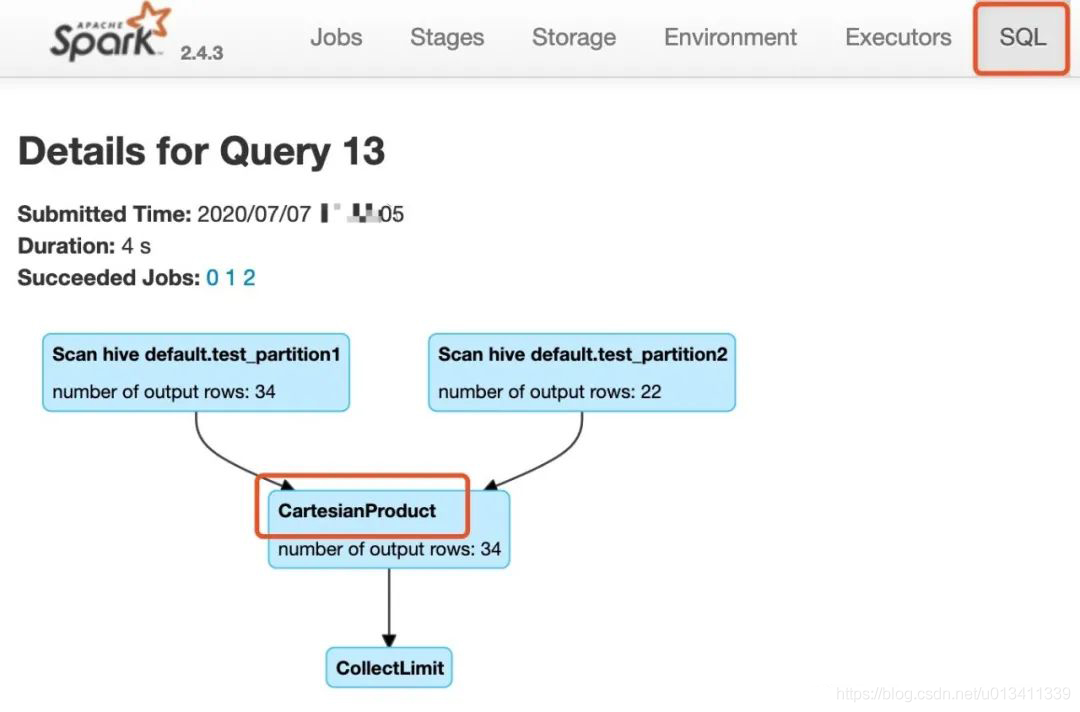
可以看出,因為該join陳述句中沒有指定on連接查詢條件,導致了CartesianProduct即笛卡爾積,
再來看一下該join陳述句的邏輯計劃和物理計劃:
== Parsed Logical Plan ==
'GlobalLimit 1000
+- 'LocalLimit 1000
+- 'Project [*]
+- 'UnresolvedRelation `t`
== Analyzed Logical Plan ==
id: string, name: string, dt: string, id: string, name: string, dt: string
GlobalLimit 1000
+- LocalLimit 1000
+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]
+- SubqueryAlias `t`
+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]
+- Join Inner
:- SubqueryAlias `default`.`test_partition1`
: +- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- SubqueryAlias `default`.`test_partition2`
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
== Optimized Logical Plan ==
GlobalLimit 1000
+- LocalLimit 1000
+- Join Inner
:- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
== Physical Plan ==
CollectLimit 1000
+- CartesianProduct
:- Scan hive default.test_partition1 [id#84, name#85, dt#86], HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]
+- Scan hive default.test_partition2 [id#87, name#88, dt#89], HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
通過邏輯計劃到物理計劃,以及最終的物理計劃選擇CartesianProduct,可以分析得出該SQL最終確實產生了笛卡爾積,
Spark SQL中產生笛卡爾積的處理策略
Spark SQL中主要有ExtractEquiJoinKeys(Broadcast Hash Join、Shuffle Hash Join、Sort Merge Join,這3種是我們比較熟知的Spark SQL join)和Without joining keys(CartesianProduct、BroadcastNestedLoopJoin)join策略,
那么,如何判斷SQL是否產生了笛卡爾積就迎刃而解,
- 在利用Spark SQL執行SQL任務時,通過查看SQL的執行圖來分析是否產生了笛卡爾積,如果產生笛卡爾積,則將任務殺死,進行任務優化避免笛卡爾積,【不推薦,用戶需要到Spark UI上查看執行圖,并且需要對Spark UI界面功能等要了解,需要一定的專業性,(注意:這里之所以這樣說,是因為Spark SQL是計算引擎,面向的用戶角色不同,用戶不一定對Spark本身了解透徹,但熟悉SQL,對于做平臺的小伙伴兒,想必深有感觸)】
- 分析Spark SQL的邏輯計劃和物理計劃,通程序式決議計劃推斷SQL最終是否選擇了笛卡爾積執行策略,如果是,及時提示風險,具體可以參考Spark SQL join策略選擇的原始碼:
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
// --- BroadcastHashJoin --------------------------------------------------------------------
// broadcast hints were specified
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// broadcast hints were not specified, so need to infer it from size and configuration.
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
Seq(joins.BroadcastHashJoinExec(
leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
// --- ShuffledHashJoin ---------------------------------------------------------------------
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)
&& muchSmaller(right, left) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)
&& muchSmaller(left, right) ||
!RowOrdering.isOrderable(leftKeys) =>
Seq(joins.ShuffledHashJoinExec(
leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))
// --- SortMergeJoin ------------------------------------------------------------
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
if RowOrdering.isOrderable(leftKeys) =>
joins.SortMergeJoinExec(
leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil
// --- Without joining keys ------------------------------------------------------------
// Pick BroadcastNestedLoopJoin if one side could be broadcast
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastByHints(joinType, left, right) =>
val buildSide = broadcastSideByHints(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
case j @ logical.Join(left, right, joinType, condition)
if canBroadcastBySizes(joinType, left, right) =>
val buildSide = broadcastSideBySizes(joinType, left, right)
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
// Pick CartesianProduct for InnerJoin
case logical.Join(left, right, _: InnerLike, condition) =>
joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nil
case logical.Join(left, right, joinType, condition) =>
val buildSide = broadcastSide(
left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)
// This join could be very slow or OOM
joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
// --- Cases where this strategy does not apply ---------------------------------------------
case _ => Nil
}
13.具體講講Spark SQL/Hive中的一些實用函式
字串函式
1. concat
對字串進行拼接:concat(str1, str2, …, strN) ,引數:str1、str2…是要進行拼接的字串,
-- return the concatenation of str1、str2、..., strN
-- SparkSQL
select concat('Spark', 'SQL');
2. concat_ws
在拼接的字串中間添加某種分隔符:concat_ws(sep, [str | array(str)]+),
引數1:分隔符,如 - ;引數2:要拼接的字串(可多個)
-- return the concatenation of the strings separated by sep
-- Spark-SQL
select concat_ws("-", "Spark", "SQL");
3. encode
設定編碼格式:encode(str, charset),
引數1:要進行編碼的字串 ;引數2:使用的編碼格式,如UTF-8
-- encode the first argument using the second argument character set
select encode("HIVE", "UTF-8");
4. decode
轉碼:decode(bin, charset),
引數1:進行轉碼的binary ;引數2:使用的轉碼格式,如UTF-8
-- decode the first argument using the second argument character set
select decode(encode("HIVE", "UTF-8"), "UTF-8");
5. format_string / printf
格式化字串:format_string(strfmt, obj, …)
-- returns a formatted string from printf-style format strings
select format_string("Spark SQL %d %s", 100, "days");
6. initcap / lower / upper
initcap:將每個單詞的首字母轉為大寫,其他字母小寫,單詞之間以空白分隔,
upper:全部轉為大寫,
lower:全部轉為小寫,
-- Spark Sql
select initcap("spaRk sql");
-- SPARK SQL
select upper("sPark sql");
-- spark sql
select lower("Spark Sql");
7. length
回傳字串的長度,
-- 回傳4
select length("Hive");
8. lpad / rpad
回傳固定長度的字串,如果長度不夠,用某種字符進行補全,
lpad(str, len, pad):左補全
rpad(str, len, pad):右補全
注意:如果引數str的長度大于引數len,則回傳的結果長度會被截取為長度為len的字串
-- vehi
select lpad("hi", 4, "ve");
-- hive
select rpad("hi", 4, "ve");
-- spar
select lpad("spark", 4, "ve");
9. trim / ltrim / rtrim
去除空格或者某種字符,
trim(str) / trim(trimStr, str):首尾去除,
ltrim(str) / ltrim(trimStr, str):左去除,
rtrim(str) / rtrim(trimStr, str):右去除,
-- hive
select trim(" hive ");
-- arkSQLS
SELECT ltrim("Sp", "SSparkSQLS") as tmp;
10. regexp_extract
正則提取某些字串
-- 2000
select regexp_extract("1000-2000", "(\\d+)-(\\d+)", 2);
11. regexp_replace
正則替換
-- r-r
select regexp_replace("100-200", "(\\d+)", "r");
12. repeat
repeat(str, n):復制給定的字串n次
-- aa
select repeat("a", 2);
13. instr / locate
回傳截取字串的位置,如果匹配的字串不存在,則回傳0
-- returns the (1-based) index of the first occurrence of substr in str.
-- 6
select instr("SparkSQL", "SQL");
-- 0
select locate("A", "fruit");
14. space
在字串前面加n個空格
select concat(space(2), "A");
15. split
split(str, regex):以某字符拆分字串 split(str, regex)
-- ["one","two"]
select split("one two", " ");
16. substr / substring_index
-- k SQL
select substr("Spark SQL", 5);
-- 從后面開始截取,回傳SQL
select substr("Spark SQL", -3);
-- k
select substr("Spark SQL", 5, 1);
-- org.apache,注意:如果引數3為負值,則從右邊取值
select substring_index("org.apache.spark", ".", 2);
17. translate
替換某些字符為指定字符
-- The translate will happen when any character in the string matches the character in the `matchingString`
-- A1B2C3
select translate("AaBbCc", "abc", "123");
JSON函式
- get_json_object
-- v2
select get_json_object('{"k1": "v1", "k2": "v2"}', '$.k2');
- from_json
select tmp.k from (
select from_json('{"k": "fruit", "v": "apple"}','k STRING, v STRING', map("","")) as tmp
);
- to_json
-- 可以把所有欄位轉化為json字串,然后表示成value欄位
select to_json(struct(*)) AS value;
時間函式
- current_date / current_timestamp
獲取當前時間
select current_date;
select current_timestamp;
- 從日期時間中提取欄位/格式化時間
1)year、month、day、dayofmonth、hour、minute、second
-- 20
select day("2020-12-20");
2)dayofweek(1 = Sunday, 2 = Monday, …, 7 = Saturday)、dayofye
-- 7
select dayofweek("2020-12-12");
3)weekofyear(date)
/**
* Extracts the week number as an integer from a given date/timestamp/string.
*
* A week is considered to start on a Monday and week 1 is the first week with more than 3 days,
* as defined by ISO 8601
*
* @return An integer, or null if the input was a string that could not be cast to a date
* @group datetime_funcs
* @since 1.5.0
*/
def weekofyear(e: Column): Column = withExpr { WeekOfYear(e.expr) }
-- 50
select weekofyear("2020-12-12");
4)trunc
截取某部分的日期,其他部分默認為01,第二個引數: YEAR、YYYY、YY、MON、MONTH、MM
-- 2020-01-01
select trunc("2020-12-12", "YEAR");
-- 2020-12-01
select trunc("2020-12-12", "MM");
5)date_trunc
引數:YEAR、YYYY、YY、MON、MONTH、MM、DAY、DD、HOUR、MINUTE、SECOND、WEEK、QUARTER
-- 2012-12-12 09:00:00
select date_trunc("HOUR" ,"2012-12-12T09:32:05.359");
6)date_format
按照某種格式格式化時間
-- 2020-12-12
select date_format("2020-12-12 12:12:12", "yyyy-MM-dd");
3. 日期時間轉換
1)unix_timestamp
回傳當前時間的unix時間戳,
select unix_timestamp();
-- 1609257600
select unix_timestamp("2020-12-30", "yyyy-MM-dd");
2)from_unixtime
將unix epoch(1970-01-01 00:00:00 UTC)中的秒數轉換為以給定格式表示當前系統時區中該時刻的時間戳的字串,
select from_unixtime(1609257600, "yyyy-MM-dd HH:mm:ss");
3)to_unix_timestamp
將時間轉化為時間戳,
-- 1609257600
select to_unix_timestamp("2020-12-30", "yyyy-MM-dd");
4)to_date / date
將時間字串轉化為date,
-- 2020-12-30
select to_date("2020-12-30 12:30:00");
select date("2020-12-30");
5)to_timestamp
將時間字串轉化為timestamp,
select to_timestamp("2020-12-30 12:30:00");
6)quarter
從給定的日期/時間戳/字串中提取季度,
-- 4
select quarter("2020-12-30");
4. 日期、時間計算
1)months_between(end, start)
回傳兩個日期之間的月數,引數1為截止時間,引數2為開始時間
-- 3.94959677
select months_between("1997-02-28 10:30:00", "1996-10-30");
2)add_months
回傳某日期后n個月后的日期,
-- 2020-12-28
select add_months("2020-11-28", 1);
3)last_day(date)
回傳某個時間的當月最后一天
-- 2020-12-31
select last_day("2020-12-01");
4)next_day(start_date, day_of_week)
回傳某時間后the first date基于specified day of the week,
引數1:開始時間,
引數2:Mon、Tue、Wed、Thu、Fri、Sat、Sun,
-- 2020-12-07
select next_day("2020-12-01", "Mon");
5)date_add(start_date, num_days)
回傳指定時間增加num_days天后的時間
-- 2020-12-02
select date_add("2020-12-01", 1);
6)datediff(endDate, startDate)
兩個日期相差的天數
-- 3
select datediff("2020-12-01", "2020-11-28");
7)關于UTC時間
-- to_utc_timestamp(timestamp, timezone) - Given a timestamp like '2017-07-14 02:40:00.0', interprets it as a time in the given time zone, and renders that time as a timestamp in UTC. For example, 'GMT+1' would yield '2017-07-14 01:40:00.0'.
select to_utc_timestamp("2020-12-01", "Asia/Seoul") ;
-- from_utc_timestamp(timestamp, timezone) - Given a timestamp like '2017-07-14 02:40:00.0', interprets it as a time in UTC, and renders that time as a timestamp in the given time zone. For example, 'GMT+1' would yield '2017-07-14 03:40:00.0'.
select from_utc_timestamp("2020-12-01", "Asia/Seoul");
常用的開窗函式
開窗函式格式通常滿足:
function_name([argument_list])
OVER (
[PARTITION BY partition_expression,…]
[ORDER BY sort_expression, … [ASC|DESC]])
function_name: 函式名稱,比如SUM()、AVG()
partition_expression:磁區列
sort_expression:排序列
注意:以下舉例涉及的表employee中欄位含義:name(員工姓名)、dept_no(部門編號)、salary(工資)
- cume_dist
如果按升序排列,則統計:小于等于當前值的行數/總行數(number of rows ≤ current row)/(total number of rows),如果是降序排列,則統計:大于等于當前值的行數/總行數,用于累計統計,
- lead(value_expr[,offset[,default]])
用于統計視窗內往下第n行值,第一個引數為列名,第二個引數為往下第n行(可選,默認為1),第三個引數為默認值(當往下第n行為NULL時候,取默認值,如不指定,則為NULL),
- lag(value_expr[,offset[,default]])
與lead相反,用于統計視窗內往上第n行值,第一個引數為列名,第二個引數為往上第n行(可選,默認為1),第三個引數為默認值(當往上第n行為NULL時候,取默認值,如不指定,則為NULL),
- first_value
取分組內排序后,截止到當前行,第一個值,
- last_value
取分組內排序后,截止到當前行,最后一個值,
- rank
對組中的資料進行排名,如果名次相同,則排名也相同,但是下一個名次的排名序號會出現不連續,比如查找具體條件的topN行,RANK() 排序為 (1,2,2,4),
- dense_rank
dense_rank函式的功能與rank函式類似,dense_rank函式在生成序號時是連續的,而rank函式生成的序號有可能不連續,當出現名次相同時,則排名序號也相同,而下一個排名的序號與上一個排名序號是連續的,
DENSE_RANK() 排序為 (1,2,2,3),
- SUM/AVG/MIN/MAX
資料:
id time pv
1 2015-04-10 1
1 2015-04-11 3
1 2015-04-12 6
1 2015-04-13 3
1 2015-04-14 2
2 2015-05-15 8
2 2015-05-16 6
結果:
SELECT id,
time,
pv,
SUM(pv) OVER(PARTITION BY id ORDER BY time) AS pv1, -- 默認為從起點到當前行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --從起點到當前行,結果同pv1
SUM(pv) OVER(PARTITION BY id) AS pv3, --分組內所有行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4, --當前行+往前3行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv5, --當前行+往前3行+往后1行
SUM(pv) OVER(PARTITION BY id ORDER BY time ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv6 ---當前行+往后所有行
FROM data;
- NTILE
NTILE(n),用于將分組資料按照順序切分成n片,回傳當前切片值,
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW),
如果切片不均勻,默認增加第一個切片的分布,
- ROW_NUMBER
從1開始,按照順序,生成分組內記錄的序列,
比如,按照pv降序排列,生成分組內每天的pv名次
ROW_NUMBER() 的應用場景非常多,比如獲取分組內排序第一的記錄,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290814.html
標籤:其他