一、zookeeper 與kafka保持資料一致性的不同點:
(1)zookeeper使用了ZAB(Zookeeper Atomic Broadcast)協議,保證了leader,follower的一致性,leader 負責資料的讀寫,而follower只負責資料的讀,如果follower遇到寫操作,會提交到leader;
當leader宕機的話,使用 Fast Leader Election 快速選舉出新的leader,節點在一開始都處于選舉階段,只要有一個節點得到超半數節點的票數,它就可以當選準 leader,
其客戶端根據鏈接的follower不同,可能讀取到不同的資料,這是由于副本沒有完全同步,存在時間差的原因,由于follower分擔了讀取資料的壓力,zookeeper只要保留全域leader即可,不再進行細分,
如下所示:leader==》讀寫,follower==>只負責讀;
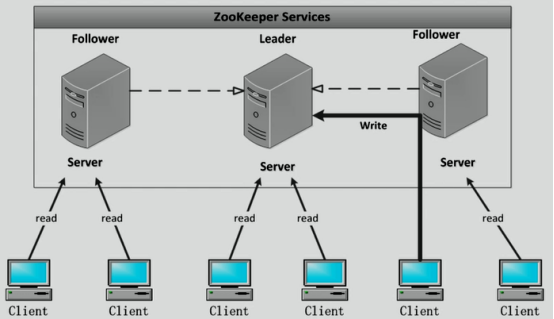
Zookeeper作業方式
》Zookeeper集群包含一個1個Leader,多個Follower
》所有的Follower都可提供讀服務
》所有的寫操作都會被forward到Leader
》Client與Server通過NIO通信
》全域串行化所有的寫操作
》保證同一客戶端的指令被FIFO執行
》保證訊息通知的FIFO
(2)kafka 不同,只有leader 負責讀寫,follower只負責備份,如果leader宕機的話,Kafaka動態維護了一個同步狀態的副本的集合(a set of in-sync replicas),簡稱ISR,ISR中有f+1個節點,就可以允許在f個節點down掉的情況下不會丟失訊息并正常提供服,ISR的成員是動態的,如果一個節點被淘汰了,當它重新達到“同步中”的狀態時,他可以重新加入ISR,因此如果leader宕了,直接從ISR中選擇一個follower就行,
kafka在引入Replication之后,同一個Partition可能會有多個Replica,而這時需要在這些Replication之間選出一個Leader,Producer和Consumer只與這個Leader互動,其它Replica作為Follower從Leader中復制資料,因為需要保證同一個Partition的多個Replica之間的資料一致性(其中一個宕機后其它Replica必須要能繼續服務并且即不能造成資料重復也不能造成資料丟失),如果沒有一個Leader,所有Replica都可同時讀/寫資料,那就需要保證多個Replica之間互相(N×N條通路)同步資料,資料的一致性和有序性非常難保證,大大增加了Replication實作的復雜性,同時也增加了出現例外的幾率,而引入Leader后,只有Leader負責資料讀寫,Follower只向Leader順序Fetch資料(N條通路),系統更加簡單且高效,
Kafka:由于kafka的使用場景決定,其讀取資料時更關注資料的一致性
從leader讀取和寫入可以保證所有客戶端都得到相同的資料,否則可能存在一些在ISR中注冊的節點(replication-factor大于min.insync.replicas),因未來得及更新副本而無法提供的資料,相應的為了規避都從leader上讀取帶來的資源競爭,可以根據不同topic和不同partition設定不同的leader,
如下所示:leader==>負責讀寫,follower 負責同步,只負責備份
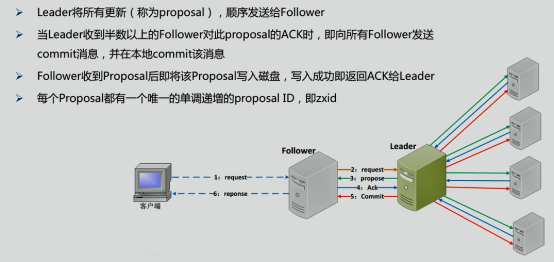
Zab協議-廣播模式
客戶端每發送一個更新請求,ZooKeeper都會生成一個全域唯一的遞增編號,這個編號反映了所有事務操作的先后順序,這個唯一編號就是事務ID(ZXID),只有更新請求才算是事務請求,
為保證按照事務的ZXID先后順序來處理,Leader服務器會分別為每個Follower服務器創建一個佇列,并將事務的先后順序放入佇列中,并按照FIFO的策略進行訊息發送,收到需要處理的事務后,Follower服務器會首先以事務日志的形式寫入服務器的磁盤中,寫入成功后會向Leader服務器發送ACK回應,當Leader服務器收到超過一半的Follower服務器的ACK回應后,會向所有Follower服務器廣播Commit訊息,收到Commit訊息的Follower服務器也會完成對事務的提交,
如果接收到事務請求的是Follower服務器,它會將請求轉發給Leader服務器處理,
二、相同點:
在資料寫入程序中,leader與follower都具有相同的先后關系,即資料先寫入leader,而后按照一定的規則完成在follower上的最少副本數寫入,即可回傳呼叫客戶端,該資料寫入成功過,
kafka的最少副本數量有min.insync.replicas控制;zookeeper的最少副本數是半數以上節點,
此處的設定都是優先保證可用性,而犧牲一定的資料一致性,
三、具體的Kafka的leader選舉機制如下:
Kafka的Leader是什么
??首先Kafka會將接收到的訊息磁區(partition),每個主題(topic)的訊息有不同的磁區,這樣一方面訊息的存盤就不會受到單一服務器存盤空間大小的限制,另一方面訊息的處理也可以在多個服務器上并行,
??其次為了保證高可用,每個磁區都會有一定數量的副本(replica),這樣如果有部分服務器不可用,副本所在的服務器就會接替上來,保證應用的持續性,
但是,為了保證較高的處理效率,訊息的讀寫都是在固定的一個副本上完成,這個副本就是所謂的Leader,而其他副本則是Follower,而Follower則會定期地到Leader上同步資料,
Leader選舉
??如果某個磁區所在的服務器除了問題,不可用,kafka會從該磁區的其他的副本中選擇一個作為新的Leader,之后所有的讀寫就會轉移到這個新的Leader上,現在的問題是應當選擇哪個作為新的Leader,顯然,只有那些跟Leader保持同步的Follower才應該被選作新的Leader,
??Kafka會在Zookeeper上針對每個Topic維護一個稱為ISR(in-sync replica,已同步的副本)的集合,該集合中是一些磁區的副本,只有當這些副本都跟Leader中的副本同步了之后,kafka才會認為訊息已提交,并反饋給訊息的生產者,如果這個集合有增減,kafka會更新zookeeper上的記錄,
如果某個磁區的Leader不可用,Kafka就會從ISR集合中選擇一個副本作為新的Leader,
??顯然通過ISR,kafka需要的冗余度較低,可以容忍的失敗數比較高,假設某個topic有f+1個副本,kafka可以容忍f個服務器不可用,
為什么不用少數服從多數的方法
??少數服從多數是一種比較常見的一致性演算法和Leader選舉法,它的含義是只有超過半數的副本同步了,系統才會認為資料已同步;選擇Leader時也是從超過半數的同步的副本中選擇,這種演算法需要較高的冗余度,譬如只允許一臺機器失敗,需要有三個副本;而如果只容忍兩臺機器失敗,則需要五個副本,而kafka的ISR集合方法,分別只需要兩個和三個副本,
如果所有的ISR副本都失敗了怎么辦
??此時有兩種方法可選,一種是等待ISR集合中的副本復活,一種是選擇任何一個立即可用的副本,而這個副本不一定是在ISR集合中,這兩種方法各有利弊,實際生產中按需選擇,
??如果要等待ISR副本復活,雖然可以保證一致性,但可能需要很長時間,而如果選擇立即可用的副本,則很可能該副本并不一致,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290826.html
標籤:其他
上一篇:都 2021 年了,你還在用 Kafka?快試試這個全新平臺吧
下一篇:Kafka 的簡介與架構