全網最詳細的大資料HBase文章系列,強烈建議收藏加關注!
新文章都已經列出歷史文章目錄,幫助大家回顧前面的知識重點,
目錄
系列歷史文章
HBase的協處理器(Coprocessor)
一、起源
二、協處理器主要的分類
三、HBase的協處理器_ObServer
四、HBase的協處理器_Endpoint
五、概念總結
六、加載的方式
1、靜態加載
2、動態加載:
七、卸載的方式
1、禁用表:
2、修改表: 洗掉協處理器的配置資訊
3、啟動表
八、HBase的協處理器總結
系列歷史文章
2021年大資料HBase(十七):HBase的360度全面調優
2021年大資料HBase(十六):HBase的協處理器(Coprocessor)
2021年大資料HBase(十五):HBase的Bulk Load批量加載操作
2021年大資料HBase(十四):HBase的原理及其相關的作業機制
2021年大資料HBase(十三):HBase讀取和存盤資料的流程
2021年大資料HBase(十二):Apache Phoenix 二級索引
2021年大資料HBase(十一):Apache Phoenix的視圖操作
2021年大資料HBase(十):Apache Phoenix的基本入門操作
2021年大資料HBase(九):Apache Phoenix的安裝
2021年大資料HBase(八):Apache Phoenix的基本介紹
2021年大資料HBase(七):Hbase的架構!【建議收藏】
2021年大資料HBase(六):HBase的高可用!【建議收藏】
2021年大資料HBase(五):HBase的相關操作-JavaAPI方式!【建議收藏】
2021年大資料HBase(四):HBase的相關操作-客戶端命令式!【建議收藏】
2021年大資料HBase(三):HBase資料模型
2021年大資料HBase(二):HBase集群安裝操作
2021年大資料HBase(一):HBase基本簡介
HBase的協處理器(Coprocessor)
一、起源
Hbase 作為列族資料庫最經常被人詬病的特性包括:
- 無法輕易建立“二級索引”
- 難以執 行求和、計數、排序等操作
比如,在舊版本的(<0.92)Hbase 中,統計資料表的總行數,需要使用 Counter 方法,執行一次 MapReduce Job 才能得到,雖然 HBase 在資料存盤層中集成了 MapReduce,能夠有效用于資料表的分布式計算,然而在很多情況下,做一些簡單的相加或者聚合計算的時候, 如果直接將計算程序放置在 server 端,能夠減少通訊開銷,從而獲 得很好的性能提升
于是, HBase 在 0.92 之后引入了協處理器(coprocessors),實作一些激動人心的新特性:能夠輕易建立二次索引、復雜過濾器(謂詞下推)以及訪問控制等,
二、協處理器主要的分類
- ObServer
- Endpoint
三、HBase的協處理器_ObServer
ObServer 類似于傳統資料庫中的觸發器,當發生某些事件的時候這類協處理器會被 Server 端呼叫,
ObServer Coprocessor 就是一些散布在 HBase Server 端代碼中的 hook 鉤子, 在固定的事件發生時被呼叫,
比如: put 操作之前有鉤子函式 prePut,該函式在 put 操作 執行前會被 Region Server 呼叫;在 put 操作之后則有 postPut 鉤子函式
以 Hbase2.0.0 版本為例,它提供了三種觀察者介面:
- RegionObserver:提供客戶端的資料操縱事件鉤子: Get、 Put、 Delete、 Scan 等
- WALObserver:提供 WAL 相關操作鉤子,
- MasterObserver:提供 DDL-型別的操作鉤子,如創建、洗掉、修改資料表等,
- 到 0.96 版本又新增一個 RegionServerObserver
下面是以 RegionObserver 為例子講解 Observer 這種協處理器的原理:
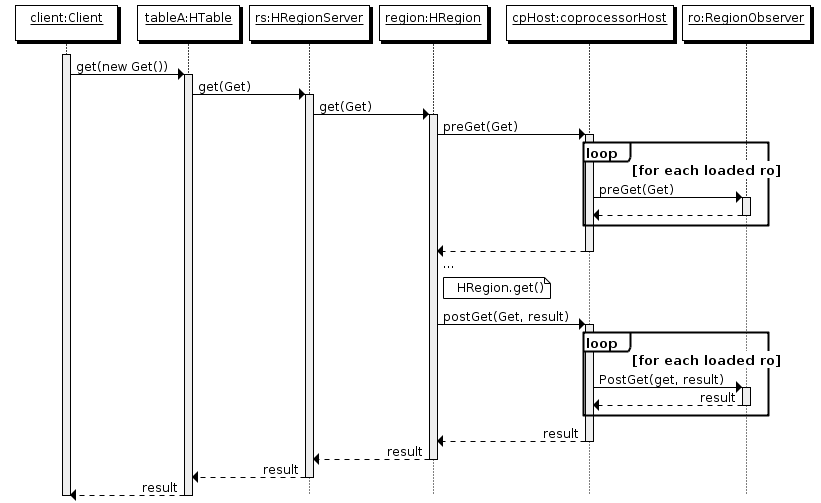
- 比如客戶端發起get請求
- 該請求被分派給合適的RegionServer和Region
- coprocessorHost攔截該請求,然后在該表上登記的每個RegionObserer上呼叫preGet()
- 如果沒有被preGet攔截,該請求繼續送到Region,然后進行處理
- Region產生的結果再次被coprocessorHost攔截,呼叫postGet()處理
- 加入沒有postGet()攔截該回應,最終結果被回傳給客戶端
四、HBase的協處理器_Endpoint
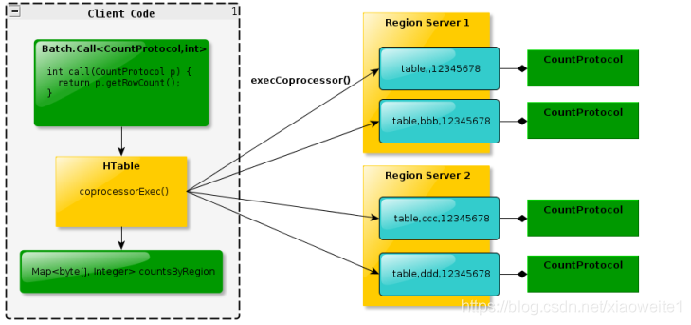
- Endpoint 協處理器類似傳統資料庫中的存盤程序,客戶端可以呼叫這些 Endpoint 協處理器執行一段 Server 端代碼,并將 Server 端代碼的結果回傳給客戶端進一步處理,最常見的用法就是進行聚集操作
- 如果沒有協處理器,當用戶需要找出一張表中的最大資料,即max 聚合操作,就必須進行全表掃描,在客戶端代碼內遍歷掃描結果,并執行求最大值的操作,這樣的方法無法利用底層集群的并發能力,而將所有計算都集中到 Client 端統一執 行,勢必效率低下,
- 利用 Coprocessor,用戶可以將求最大值的代碼部署到 HBase Server 端,HBase 將利用底層 cluster 的多個節點并發執行求最大值的操作,即在每個 Region 范圍內 執行求最大值的代碼,將每個 Region 的最大值在 Region Server 端計算出,僅僅將該 max 值回傳給客戶端,在客戶端進一步將多個 Region 的最大值進一步處理而找到其中的最大值,這樣整體的執行效率就會提高很多
下圖是 EndPoint 的作業原理:
五、概念總結
- observer 允許集群在正常的客戶端操作程序中可以有不同的行為表現
- endpoint 允許擴展集群的能力,對客戶端應用開放新的運算命令
- observer 類似于 RDBMS 中的觸發器,主要在服務端作業
- endpoint 類似于 RDBMS 中的存盤程序,主要在 服務器端、client 端作業
- observer 可以實作權限管理、優先級設定、監控、 ddl 控制、 二級索引等功能
- endpoint 可以實作 min、 max、 avg、 sum、 distinct、 group by 等功能
六、加載的方式
1、靜態加載
- 通過修改 hbase-site.xml 這個檔案來實作
- 啟動全域 aggregation,能過操縱所有的表上的資料,只需要添加如下代碼:

注意: 為所有 table 加載了一個 cp class,可以用” ,”分割加載多個 class
2、動態加載:
- 啟用表 aggregation,只對特定的表生效
- 通過 HBase Shell 來實作,disable 禁用表
- 添加 aggregation , 添加后啟用表即可
hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||'
七、卸載的方式
1、禁用表:
disable 'test' 2、修改表: 洗掉協處理器的配置資訊
alter ‘test’, METHOD => 'table_att_unset', NAME => 'coprocessor$1’ 3、啟動表
enable 'test'八、HBase的協處理器總結
Hbase的協處理器主要有二大類: ObServer 和 Endpoint
-
ObServer: 可以將其看做是攔截器(過濾器 觸發器), 可以基于這種協處理器對Hbase相關操作進行監控(鉤子 Hook)
-
例如: 監控用戶插入到某個表操作, 插入之前要列印一句話
-
ObServer所提供一些類, 這些類可以監控到HBase中各種操作: 對資料的CURD 對表的CURD 對region的操作 對日志操作
-
ObServer能做什么事情?
-
1) 記錄操作日志
-
2) 權限的管理
-
-
-
Endpoint: 可以看做資料庫中存盤程序,也可以看做在java代碼中封裝一個方法(功能), 將這個方法放置服務端, 讓服務器進行執行操作, 客戶端只需要拿到服務端執行結果即可
-
作用: 執行一些聚合操作: 求和 求差 求最大 ....
-
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢大資料系列文章會每天更新,停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290830.html
標籤:其他
上一篇:2021年大資料HBase(十七):??HBase的360度全面調優??
下一篇:微信小程式集成WeUI組件庫