文章目錄
- (1)演算法效率
- (2)時間復雜度的計算
- 1)什么是時間復雜度
- 2)大O漸進表示法(估算)
- 3)時間復雜度計算實體
- 4)總結
- 5)一些思考
- (3)空間復雜度的計算
- (4)常見復雜度對比
本篇前言
在C語言階段,我們學過了一些排序和查找演算法,冒泡排序,快速排序,二分查找等等,哪種演算法更好呢,我們如何衡量一個演算法的好壞呢?本篇來學習演算法的時間復雜度和空間復雜度,相信學完后你就會明白了,
(1)演算法效率
演算法在撰寫成可執行程式后,運行時需要耗費時間資源和空間(記憶體)資源 ,因此衡量一個演算法的好壞,一般是從時間和空間兩個維度來衡量的,即時間復雜度和空間復雜度,
時間復雜度主要衡量一個演算法的運行快慢,而空間復雜度主要衡量一個演算法運行所需要的額外空間,
隨著計算機行業的高速發展,計算機儲存容量已經達到了很高的程式,已經不需要特別關注一個演算法的空間效率了,重點關注其時間復雜度,
(2)時間復雜度的計算
1)什么是時間復雜度
演算法中的基本操作的**執行次數**,為演算法的時間復雜度,
直接上實體來講解具體的計算方法吧
//計算Func1中++count陳述句總共執行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
演算法執行次數函式運算式:F(N) = N2 + 2 * N + 10
N = 10,F(N) = 130;N = 100,F(N) = 10210;N = 1000,F(N) = 1002010;
通過計算發現,N越大,對結果影響越小,所以在實際計算時間復雜度時,我們并不需要計算精確的執行次數,而只需要計算大概執行次數,使用大O漸進表示法(估算),只保留對結果影響最大的一項,
2)大O漸進表示法(估算)
1、推導大O階方法:
用常數1取代運行時間中的所有加法常數,
在修改后的運行次數函式中,只保留最高階項,
如果最高階項存在且不是1,則去除與這個專案相乘的常數,得到的結果就是大O階,
這些方法看起來有些許摸不著頭腦哈,我們來舉幾個例子說明,比如:
- 執行次數函式 F(N) = 10,使用大O漸進表示法后,時間復雜度為:O(1)
- 執行次數函式 F(N) = N2 + 2 * N + 10,使用大O漸進表示法后,時間復雜度為:O(N2)
- 執行次數函式 F(N) = 2 * N + 10,使用大O漸進表示法后,時間復雜度為:O(N)
2、有些演算法的時間復雜度存在最好、平均和最壞情況:
最壞情況:任意輸入規模的最大運行次數(上界)
平均情況:任意輸入規模的期望運行次數
最好情況:任意輸入規模的最小運行次數(下界)
例如:在一個長度為 N 陣列中搜索一個資料 X
最好情況:1次就找到
最壞情況:N次才找到(一般以最壞情況為準)
平均情況:N/2次找到
而在實際中一般情況關注的是演算法的最壞運行情況,是一種保底思維,沒有比這更差了哈哈,所以陣列中搜索資料時間復雜度為O(N)
3)時間復雜度計算實體
實體1:
// 計算Func2的時間復雜度
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
執行次數函式 F(N) = 2 * N + 10,使用大O漸進表示法后,時間復雜度為:O(N)
(保留影響最大的一項,去掉系數)
實體2:
// 計算Func3的時間復雜度
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++k)
{
++count;
}
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}
執行次數函式 F(M,N) = M + N,有兩個未知數 M 和 N,我們不知道誰大誰小,
所以時間復雜度可以寫成:O(M + N) 或 O(max(M,N))
如果有條件限定:
如果能說明 M 遠大于 N,則 O(M)
如果能說明 N 遠大于 M,則 O(N)
如果能說明 M 和 N 差不多大,則 O(M) 或 O(N)
(這道題要看具體的場景,看有沒有具體限定)
實體3:
// 計算Func4的時間復雜度
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}
執行次數函式 F(N) = 100,使用大O漸進表示法后,時間復雜度為:O(1)
(時間復雜度 O(1) 中的 1 不是代表 1 次,而是常數次)
實體4:
// 計算strchr的時間復雜度
// strchr - 定位字串中第一個出現的字符
const char* strchr(const char* str, int character);
// 函式內部大致邏輯
while(*str)
{
if(*str == character)
return str;
else
++str;
}
回圈中的 if 陳述句要比較 N 次,時間復雜度為:O(N)
實體5:
// 計算冒泡排序BubbleSort的時間復雜度
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1; //發生了交換,賦值為1
}
}
if (exchange == 0) //沒有發生交換,說明已經有序了
break;
}
}
若初始檔案是正序的,一趟掃描即可完成排序,所以冒泡排序最好的時間復雜度為:O(n)
若初始檔案是反序的,n 個數,需要進行 n-1 趟排序 ,每一趟重復地走訪過要排序的元素列,依次比較兩個相鄰的元素,在這種情況下,比較和交換次數均達到最大值:
第 1 趟比較 n-1 次,
第 2 趟比較 n-2 次,
第 3 趟比較 n-3 次,
…………,
第 n-2 趟比較 2 次,
第 n-1 趟比較 1 次,
共 n-1 趟,每一趟 if 陳述句執行次數累加為:
n-1 + n-2 + n-3 + n-4 + …… + 3 + 2 + 1 = (n - 1)(1 + n - 1) / 2 = n(n-1) / 2
(等引數列前 n 項和公式為:Sn = n * a1 + n(n - 1)d / 2 或 Sn = n(a1 + an) / 2)
所以冒泡排序最差的時間復雜度為:O(n2)
實體6:
// 計算二分查找BinarySearch的時間復雜度
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n - 1;
while (begin < end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid - 1;
else
return mid;
}
return -1;
}
二分(折半)查找,從 n 個數中找,計算一共折半了多少次才找到該數,那么時間復雜度就是折半的次數
圖解說明:

注:對數時間復雜度記法,O(log2N),可以簡化寫成O(logN)
實體7:
// 計算階乘遞回Fac的時間復雜度
long long Fac(size_t N)
{
if (1 == N)
return 1;
return Fac(N - 1) * N;
}
遞回次數為 N 次,每一次遞回中運行次數為 1,所以時間復雜度為:O(N)

實體8:
// 計算斐波那契遞回Fib的時間復雜度
long long Fib(size_t N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}
圖解說明:
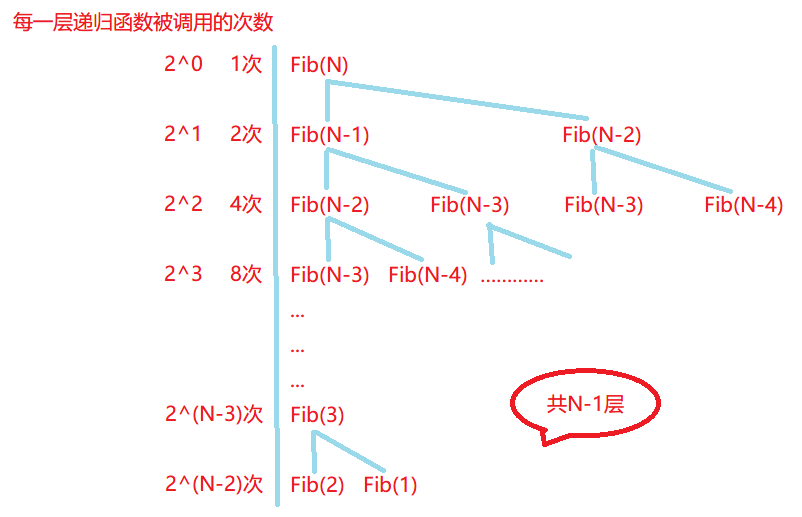
F(N) = 1 + 2 + 4 + 8 + …… + 2N-3 + 2N-2 = (1 - 2N-2 * 2)/ (1 - 2) = 2N-1 - 1
補充:
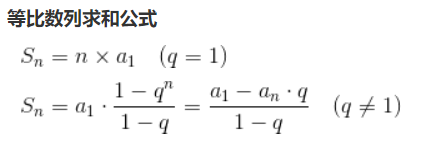
這個二叉樹的右邊其實是有缺失的,右邊沒有N - 1層,所以算出來的 F(N) 還要減去右邊缺的一些呼叫(常數)
使用大O漸進表示法后,所以時間復雜度為:O(2N)
4)總結
計算時間復雜度,
就是計算出該演算法中的基本操作的執行次數,
一般以演算法的最壞運行情況為準,
最終結果用大O漸進表示法(估算)書寫
5)一些思考
- 其實這個斐波那契數列遞回的演算法是非常慢的,重復計算特別多,時間復雜度 O(2N),成指數增長的
N = 10,2N = 1024
N = 20,2N = 100萬+
N = 30,2N = 10億+
N = 40,2N = 10000億+
N = 50,2N = 1000萬億+
所以盡量用非遞回的方式去算斐波那契數,用陣列,或者用三個變數倒的方法
三個變數f1、f2、f3,
f1 和 f2 存頭兩個斐波數Fib1和Fib2,
第三個變數 f3 算斐波數Fib3 = Fib1 + Fib2,
然后往前移動一下,f1 存 Fib2,f2 存 Fib3,然后再算出 Fib4 存到 f3 中
不斷回圈上述程序
- 二分(折半)查找時間復雜度是 O(log2N),效率是非常高的
N = 1000,log2N ≈ 10(210 = 1024)
N = 100萬,log2N ≈ 20(220 = 100萬+)
N = 10億,log2N ≈ 30(230 = 10億+)
N = 10000億,log2N ≈ 40(240 = 10000億+)
從這個角度分析,我們就能知道二分查找演算法是一個非常好的演算法,假設所有中國人的身份證號碼已排好序存起來(14億),查找一個人最多要找幾次?
log214億 ≈ 31次(因為230 = 10億+,231 = 20億+)
但二分查找也有一個致命的問題,就是必須要資料有序才行,而排序也是一個挺大的工程,所以實際中查找用得并沒有那么多,查找更多的是用后面回講到的一種資料結構:搜索樹
(3)空間復雜度的計算
空間復雜度是對一個**演算法在運行程序中臨時占用存盤空間大小**的量度 ,
空間復雜度不是程式占用了多少位元組的空間,因為這個也沒太大意義,空間復雜度算的是變數的個數,
空間復雜度計算規則基本跟時間復雜度類似,也使用大O漸進表示法,
注意:函式運行時所需要的堆疊空間(存盤引數、區域變數、一些暫存器資訊等)在編譯期間已經確定好了,因此空間復雜度主要通過函式在運行時候向外申請的額外空間來確定,
實體1:
// 計算BubbleSort的空間復雜度
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
陣列 a 不是因為這個演算法而開辟的,所以它是不參與計算的,該演算法在運行時,定義了變數(end、exchange、i),臨時占用了常數個儲存空間的,所以空間復雜度是:O(1)
這時可能有人會有疑問:每次回圈中 exchange 都被重新定義了,為啥只占用了常數個空間呀
因為空間是可以重復利用的,每個函式呼叫,都會開辟一個堆疊幀,里面存放函式運行時所需的區域變數、引數等

實體2:
// 計算Fibonacci的空間復雜度
// 回傳斐波那契數列的前n項
long long* Fibonacci(size_t n)
{
if (n == 0)
return NULL;
long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}
演算法在運行時,使用了 malloc 動態開辟并臨時占用了 N 個儲存空間,空間復雜度為:O(N)
實體3:
// 計算階乘遞回Fac的空間復雜度
long long Fac(size_t N)
{
if (N == 1)
return 1;
return Fac(N - 1) * N;
}
遞回呼叫了N次,最多遞回了N - 1層,開辟了N個堆疊幀,每個堆疊幀使用了常數個空間,空間復雜度為:O(N)
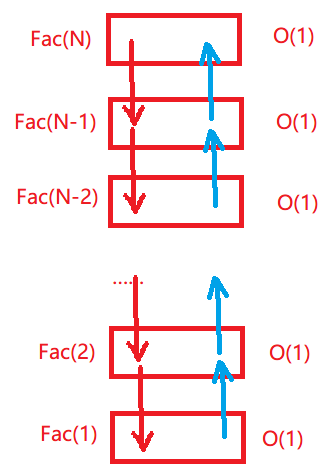
思考這道題:
// 計算斐波那契遞回Fib的空間復雜度
long long Fib(size_t N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}
空間是可以重復利用的,堆疊幀被開辟,回傳時又會被銷毀,最多遞回了N - 1層,開辟了N - 1個堆疊幀,每個堆疊幀使用了常數個空間,空間復雜度為:O(N)
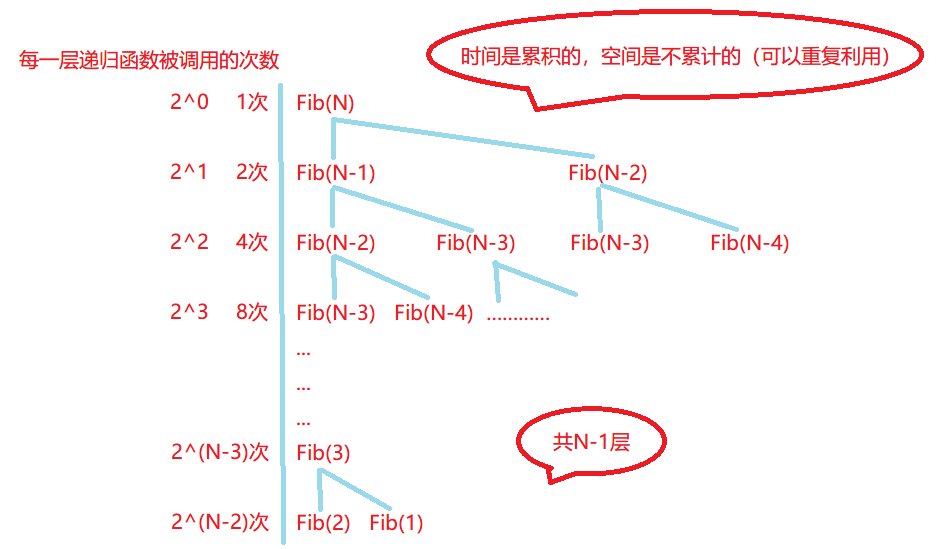
(4)常見復雜度對比
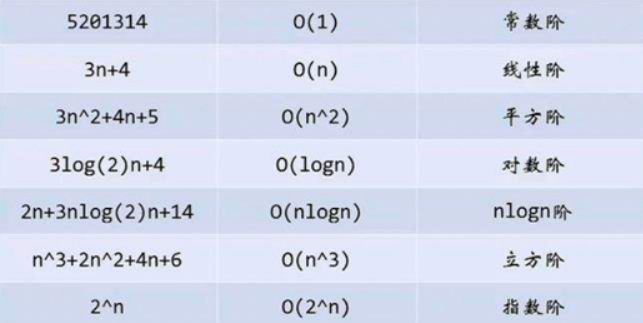
時間復雜度大小比較:O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n)
復雜度介紹完啦,下次再見!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290876.html
標籤:其他
上一篇:【Python資料結構系列】《線性表》——知識點講解+代碼實作
下一篇:資料結構和演算法(初涉)