??什么是計算機視覺?計算機視覺,顧名思義,就是針對視覺資料的研究,在我們的世界,過去短短幾年里視覺資料爆炸式增長到夸張的地步,基于一項2015年的研究,預計到2017年,互聯網上80%的資料都是視頻,所以,如何用演算法來開發這些可以利用和理解的資料變得十分重要,但是視覺資料對于計算機非常難理解,有時我們把視覺資料稱為互聯網的暗物質,將它與物理學中的暗物質類比,物理學中講暗物質占宇宙質量的很大一部分,我們知道這是因為各種天體間存在萬有引力,但我們不能直接觀察到它,視覺資料也是一樣,它占據了互聯網資料的很大一部分,但是我們很難去探知并理解這些資料到底是什么,有一來自YouTube的實體統計,大概每秒鐘會有長達5小時的內容被上傳到YouTube,谷歌雖然有很多員工,但是沒有人可以坐下來一直觀看并給每個視頻打上注釋,所以如果他們想為觀眾推薦相關視頻,甚至想要通過投放廣告賺錢,開發一項技術至關重要,除此之外,計算機視徑訓是一個跨學科領域,與物理醫學生物等等緊緊融合,與我們的生活息息相關,
文章目錄
- 一、視覺發展歷史
- 1.物種大爆炸
- 2.人類讓機器獲得視覺
- 3.視徑訓理的研究
- 二、計算機視覺發展歷史
- 1.現實世界的表示
- 2.目標識別與目標分割
- 三、資料集
- 四、卷積神經網路的出現和發展
- 五、未來與挑戰
一、視覺發展歷史
1.物種大爆炸
??視覺的歷史可以追溯到很久很久以前,實際約5億4千3百萬年前,地球全部被水覆寫,少量的物種在海洋中游蕩,生物并不活躍,但是大約在5億4千年前發生了一件非凡的事,生物學家對化石研究發現,短短1千萬年里,動物物種數量爆炸式增長,這一現象被生物學家稱之為物種大爆炸(Evolution’s Big Bang),關于這一現象的成因,盡管有很多相關理論,但這件事多年來仍是未解之謎,幾年前,澳大利亞生物學家安德魯·帕克(Andrew Parker)提出了一種很有說服力的理論,通過對古化石的研究,他發現距今5億4千萬年前第一次有動物進化出了眼睛,視力功能的出現,促進了物種數量的爆炸,動物們可以看見東西了,一旦有了視力,生物開始變得積極主動,生物為了生存開始進化競賽,這就是動物擁有視覺的開端,
??現如今,視覺成為了動物,尤其是智慧動物最重要的感知器官,在人類大腦皮層中,幾乎一半的神經元與視覺有關,這項最重要的感知系統,使我們可以生存、運動、作業、操作器物、娛樂、溝通等等,

2.人類讓機器獲得視覺
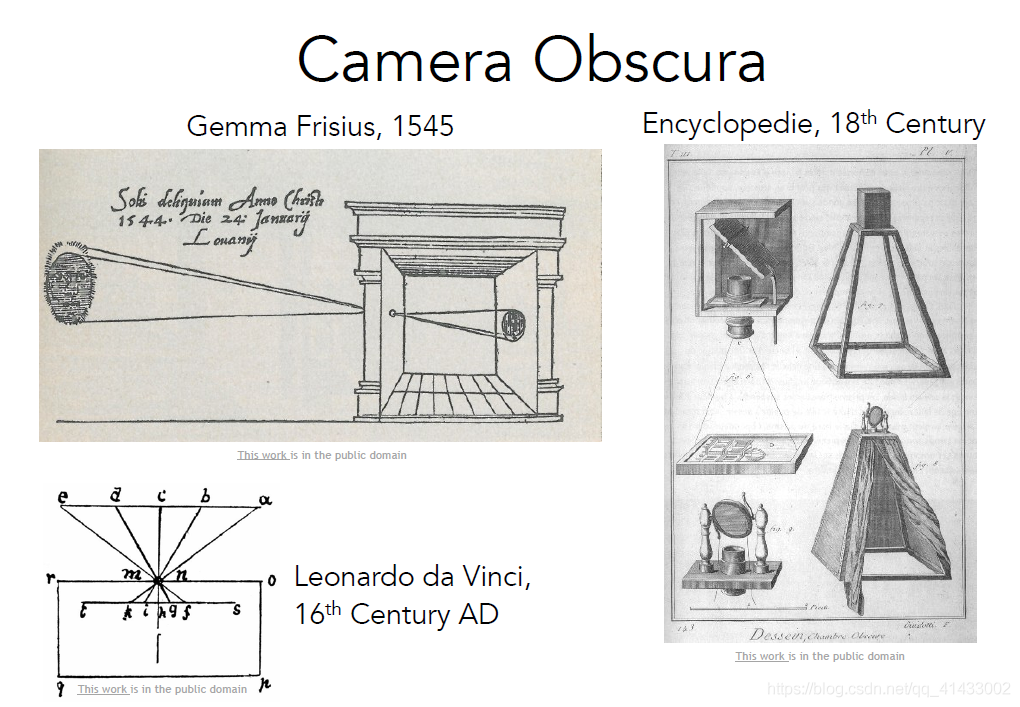
??前面講到了生物的視覺,那么人類讓機器獲得視覺,又或者說照相機的歷史又是怎樣的呢?我們現在已知最早的照相機要追溯到17世紀文藝復興時期的暗箱,這是一種通過小孔成像的相機,這和動物早期的眼睛非常相似,通過小孔接受光線,再到后面的平板收集資訊并且投影成像,隨著科技的發展,照相機如今已經非常普及,攝像頭已經成為手機或其他裝置上,最常用的傳感器之一,
3.視徑訓理的研究
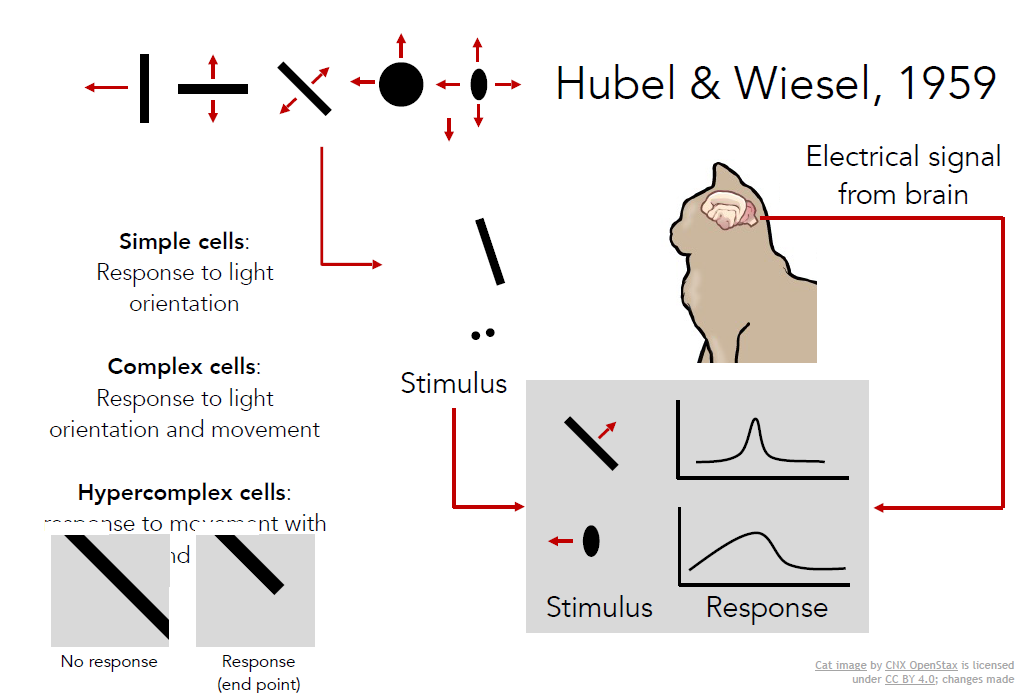
??生物學家早就開始研究視覺的機理,其中最具影響力、并啟發了計算機視覺研究的,要數五六十年代休伯爾(Hubel)和韋澤爾(Wiesl)使用電生理學的研究,他們的問題是“哺乳動物的視覺處理機制是怎樣的”,他們認為存在一種大腦視覺處理機制,利用與人類相似的貓做實驗進行研究,他們將電極插進主要控制貓視覺的后腦上初級視覺皮層,然后觀察何種刺激會引起視覺皮層神經的激烈反應,他們發現貓大腦皮層的初級視覺皮層,有各種各樣的細胞,其中最重要的細胞是當朝著某個特定方向運動時,對定向邊緣產生回應的細胞,他們發現視覺處理是始于視覺世界的簡單結構,面向邊緣,沿著視覺處理途徑的移動,資訊也在變化,大腦不斷建立復雜的視覺資訊,直到它可以識別更為復雜的視覺世界,
二、計算機視覺發展歷史
1.現實世界的表示
??計算機視覺的歷史要從60年代初開始,《Block World》是1963年Larry Roberts出版的一部作品,被認為是計算機視覺第一篇博士論文,其中視覺世界被簡化為簡單的集合形狀,其目的時能夠識別他們并重建這些形狀是什么,從那時起,計算機視覺領域蓬勃發展,現如今已經在全球范圍內已經擁有眾多的研究人員,雖然還沒有弄清楚人類視覺的原理,但是這個領域已經成為人工智能最重要和發展最快的領域之一,

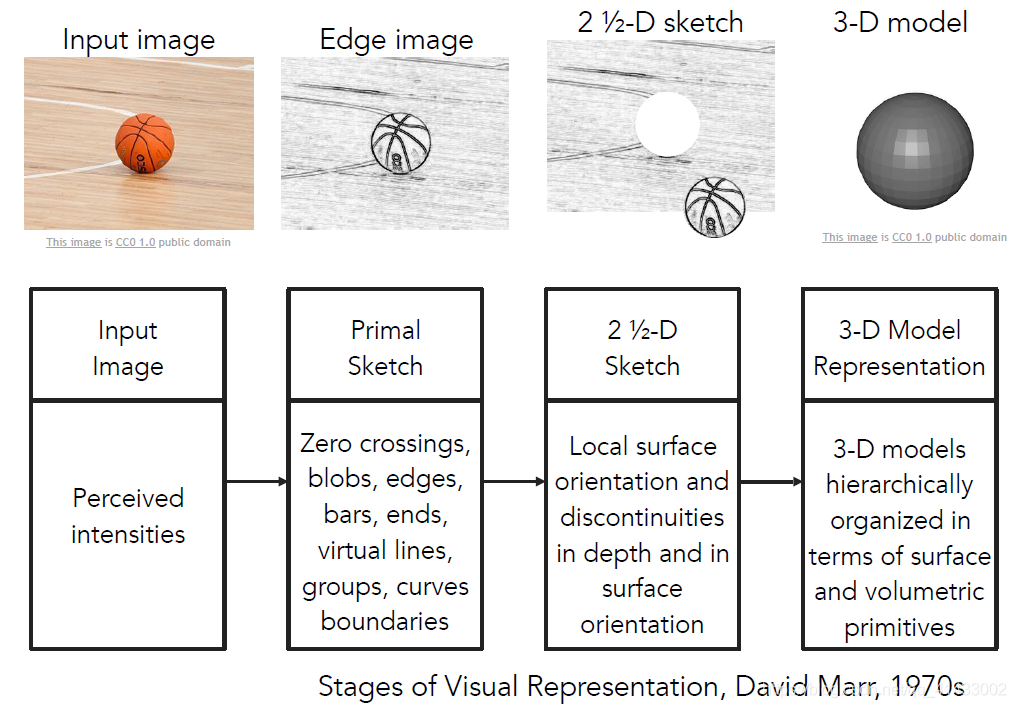
??David Marr,麻省理工學院視覺科學家,70年代后期撰寫著作 《VISION》,其中包括他是如何理解視覺的,我們應該如何處理計算機視覺開發,甚至如何可以使計算機識別視覺世界的演算法,他在書中指出為了拍攝一幅影像,并獲得視覺世界最終全面3D表現的程序,
??第一個程序就是原始草圖,大部分邊緣、端點、虛擬線條、曲線、邊界等都被用其他元素表示,這是受到了神經學家的啟發,休伯爾(Hubel)和韋澤爾(Wiesl)告訴我們視覺處理的早期階段與諸如邊緣之類的簡單結構有很大關系,
??邊緣和曲線的下一個階段是“2.5維草圖”,我們開始將表面、深度資訊、圖層或視覺場景不連續地拼湊在一起,
??然后最終將所有內容放在一起,并在表面和體積圖等分層組織了一個3d模型,
??這是一個非常理性化的程序,這種思維方式實際上已經在計算機領域 影響了幾十年,這也是一個非常直觀的方式,直接地考慮如何解構視覺資訊,
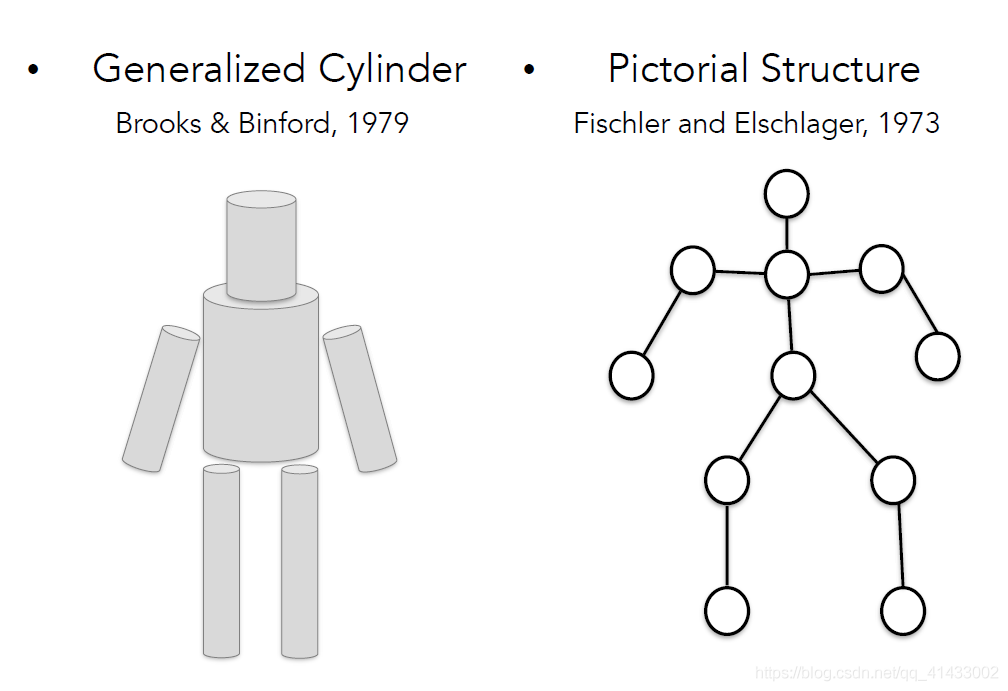
??七十年代另一個非常重要的開創性的問題被提出:我們如何越過簡單的塊狀世界,開始識別或表示現實世界的物件,70年代沒有可用的資料集,計算機速度非常慢,筆記本都還沒出現的時代,但計算機科學家們已經開始思考如何識別和表示物件,這時斯坦福大學的帕洛阿爾托以及斯里蘭卡提出了兩種類似的想法,一種被稱為廣義圓柱體,一另種被稱為圖形結構,他們的基本思想都是每個物件都由簡單的幾何圖單位組成,例如一個人可以通過廣義的圓柱形形狀拼接在一起,或者人也看可以由一些關鍵元素按照不同的間距組合在一起,
??80年代,David Lowe思考如何重建或者識別由簡單物體結構組成的視覺空間,這項研究是他嘗試識別剃須刀,他通過線和邊緣進行構建,其中大部分都是直線以及直線之間的組合,

2.目標識別與目標分割
??從60到80年代,計算機視覺要解決物體識別的問題非常難,目前所提到作業都是極具野心和腦洞的嘗試,但是他們僅僅停留在簡單樣本或少量樣本階段,沒有產生很大的進展,沒能輸出可以在現實世界有用的東西
??所以人們思考在思考解決視覺程序中出現的問題時,一個很重要的想法出現了:目標識別太難,我們首先該做的是目標分割,這個任務就是把一張圖中的像素點歸類到有意義的區域,我們可能不知道這些像素點組合到一起是一個人型,但是我們可以把這些屬于人的像素點從背景中摳出來,這個程序就叫影像分割,有一項早期非常具有開創性的作業,是由Berkeley的Jitendra Malik和他的學生Jianbo Shi所完成的,

??還有另一個問題先于其他計算機視覺問題有進展,那就是面部檢測,大概在1999-2000年機器學習技術,特別是統計機器學習方法開始加速發展,涌現了大量方法,其中便出現了使用AdaBoost演算法進行實時面部檢測的做法,由Paul Viol和Michael Jones完成,這是在計算機芯片還非常非常慢的2001年完成的,在他們發表論文的五年后,2006年富士推出了第一個人臉檢測相機,這是基礎學科到實際應用的快速轉化,

??如何更好的目標識別,這是一個我們可以繼續研究的領域,90年代末到2000的前十年有一個非常由影響力的思想方法就是基于特征的目標識別,David Lowe完成了一個影響深遠的作業,叫SIFT特征匹配,例如這里一個stop表示去匹配另一個stop標識是非常難的,因為很多變化的因素,比如相機的角度,遮擋,視角,光線等等,但是有某些特征,他們往往能在變化中具有表現性和不變性,所以目標識別首要任務是在目標上確認這些關鍵特征,然后把這些特征與相似的目標進行匹配,比匹配整個目標要容易的多,

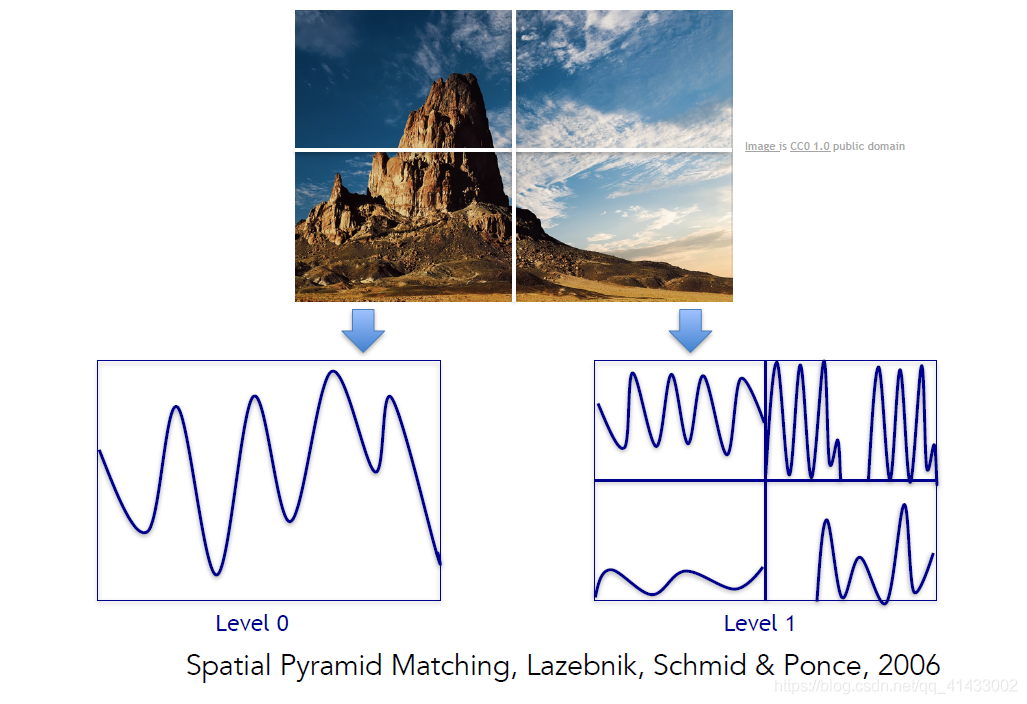
??使用相同的構成要素的圖片具有相似的表現特征,在這一領域的一項進展是識別整幅圖的場景,空間金字塔匹配(Spatial Pyramid Matching)是一個非常典型的例子,其背后的思想是圖片中有各種特征,這些特征可以告訴我們這是風景還是廚房或高速公路等,這個演算法從影像的各部分像素抽取特征,并把他們放在一起,作為一個特征描述符,在特征描述符上再做一個支持向量機,
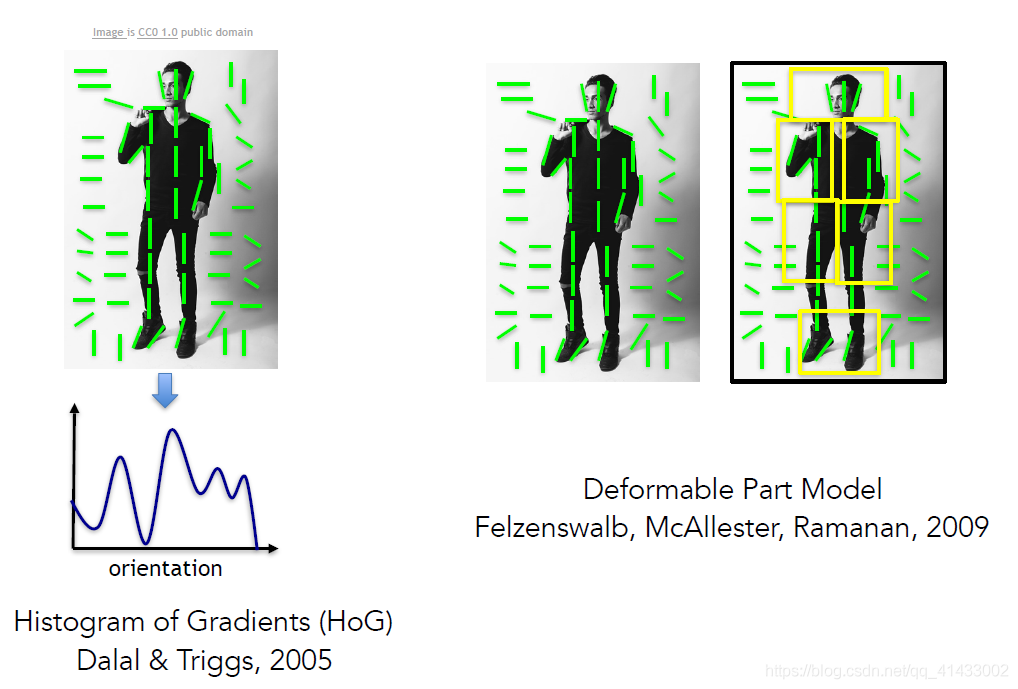
??有個在人類認知方面很類似的作業正處于風口浪尖,其做法是把這些特征放在一起之后,研究如何在實際圖片中比較合理地設計人體姿態和辨認人體姿態,這方面的作業有兩個,一個被稱為方向梯度直方圖(histogram of gradients),另一個被稱為可變形部件模型(deformable part models),
三、資料集
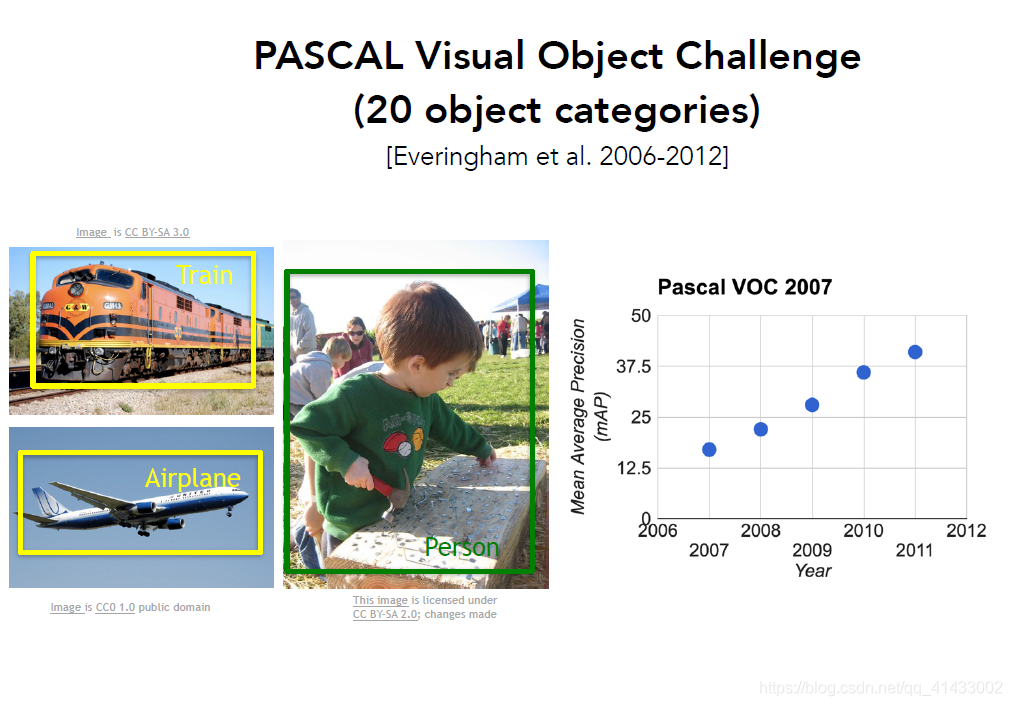
??從60到70到80年代一步步走到21世紀,有一件事一直在變化,那就是圖片的質量,隨著互聯網、數碼相機以及計算機視覺的發展,我們現在已經擁有了更好的資料,計算機視覺在21世紀早期指出了一個非常重要的基本問題,就是目標識別,但是21世紀才才開始擁有真正的標注資料集供我們衡量性能,其中很有影響力的資料集叫PASCAL Visual Object Challenge,這個資料集有20個類別,圖中展示3個火車、飛機和人,其他的還有牛、瓶子、貓等等類別,資料集中每個種類有成千上萬張圖片,
這里有一張圖表列舉了2007-2012年在基準資料集上檢測影像中20種目標的檢測效果,可以看到在穩步提升,
??在同一時期,普林斯頓和斯坦福的一批人開始向這個領域提出一個更難的問題——我們是否具備了識別真實世界中每一個或大部分物體的能力,這個問題也是由機器學習中一個現象驅動的,就是大部分的機器學習演算法,無論是圖模型,還是支持向量機,或是AdaBoost都很可能會在訓練程序中過擬合,部分原因是可視化資料非常復雜,正因為他們太復雜了,我們的模型往往維數比較高,輸入高維模型,還有一堆引數要調優,當我們尋來你資料量不夠時,很快就會產生過擬合現象,這樣我們就無法很好地泛化,
??ImageNet這一專案也由此而生,該專案匯集所有能找到的圖片,包含世界萬物,組建一個盡可能大的資料集,約耗時三年完成,使用WordNet字典進行排序,這個字典里有上萬個物體類別,最終完成擁有22000類,14000萬張圖的資料集,這應該時當時AI領域最大的資料集,它將目標檢測演算法推到一個新的高度,

??為了更好地推動目標檢測的發展,從2009年開始,ImageNet團隊組織了一場國際比賽,叫做ImageNet大規模視覺識別競賽(ImageNet Large Scale Visual Recognition Challenge),其測驗集共有140萬目標影像,1000種類別,下面是示例圖片和演算法,如果一個演算法能輸出概率最大的5個類別,其中有正確的物件,就被認為是識別成功,

四、卷積神經網路的出現和發展
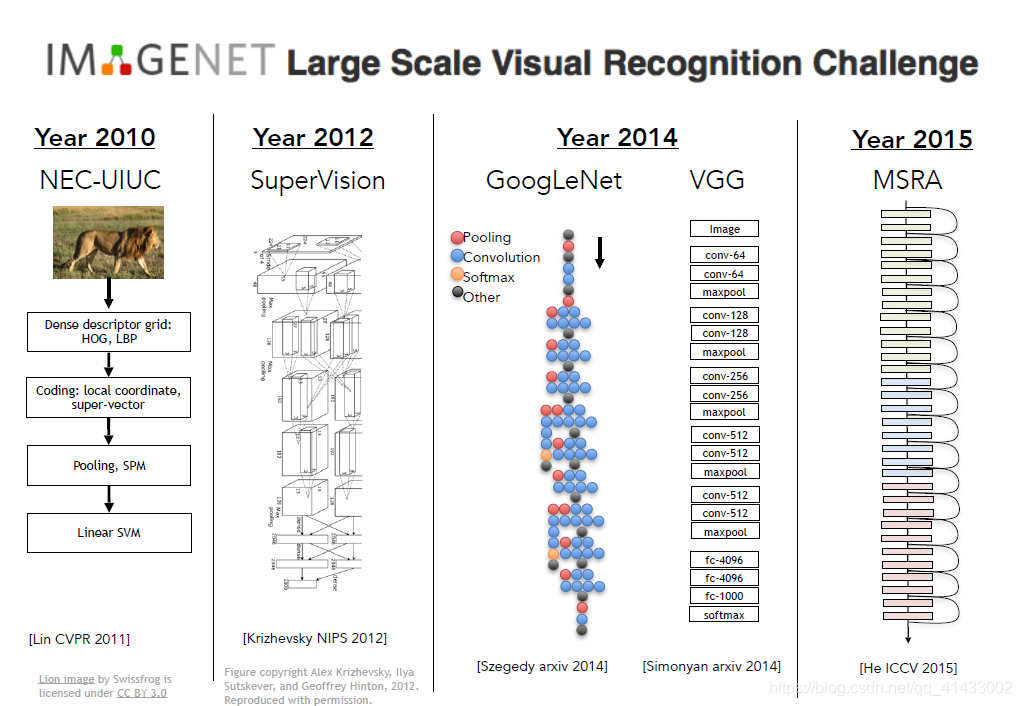
??ImageNet挑戰賽從2010到2015年的影像分類結果如下圖所示,其中X軸表示年份,Y軸表示錯誤率,到2012時年錯誤率已經低到與人類一樣,這是一個很大的進步,有一個很特別的時刻,就是在2012年,前兩年錯誤率都在25%左右,但是2012年突然下降了10%達到16%,那年的獲獎演算法是一種卷積神經網路模型,擊敗當時所有其他的演算法,從那年開始神經網路包攬比賽冠軍,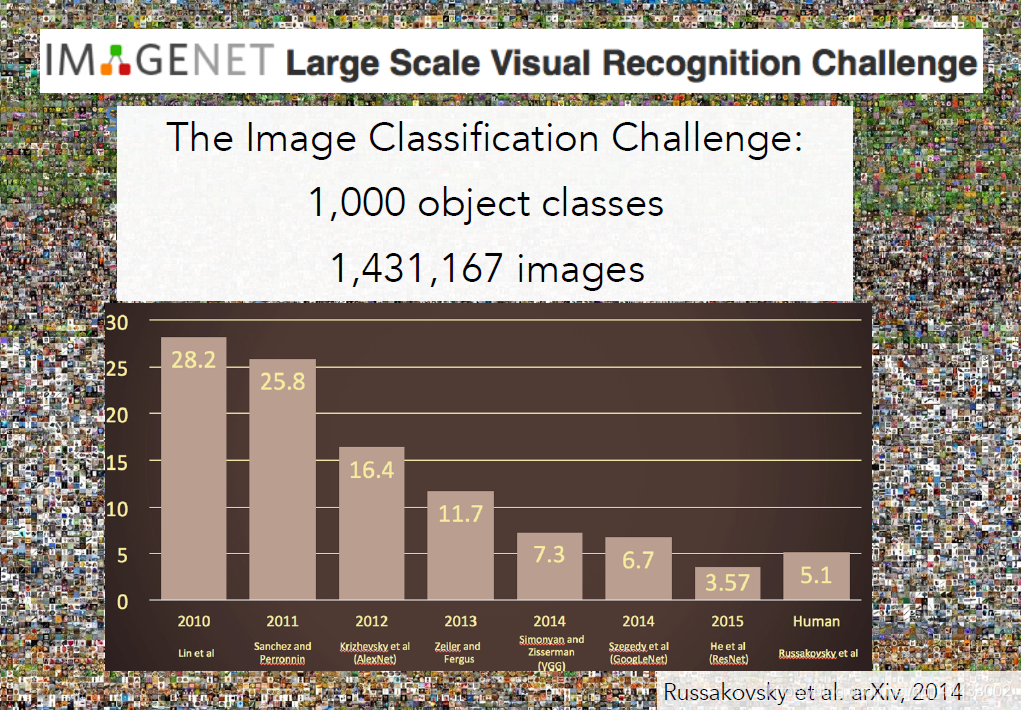
??讓我們來看看過去幾年在ImageNet中獲勝的演算法,
??2011年,Lin et al提出的方法首先計算特征,然后計算區域不變特征,經過一些池化操作和多層處理,最后的結果傳給線性SVM,
??2012年出現了真正的突破,來自多倫多大學的Jeff Hinton小組和他當時的博士生Alex Krizhevsky和Ilya Sutskever創造了這個7層神經網路,AlexNET,從那年開始神經網路包攬比賽冠軍,而這些網路的趨勢也是每年都變得越來越深,
??2014年,有了更深的網路,來自谷歌的GoogLeNET和來自牛津大學的VGG網路,有19層網路,
??2015年這一現象更加瘋狂,微軟亞洲研究院的殘差網路有152層,
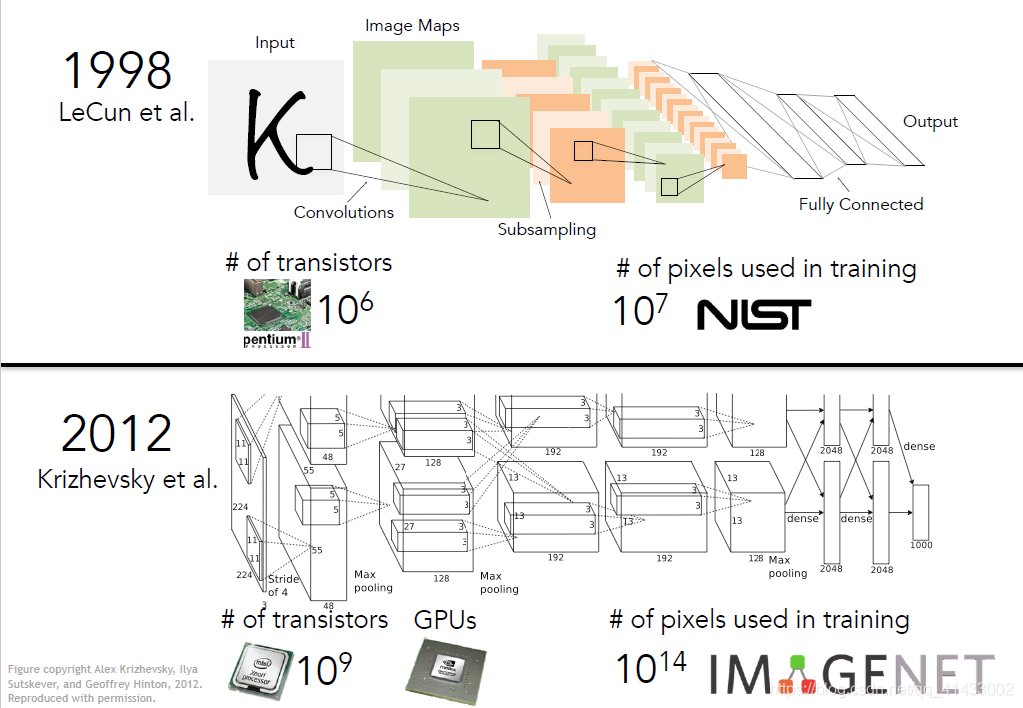
??神經網路的突破在2012年,但是其發明可以追溯到更早之前,1998年,Yann LeCun 和他的伙伴在Bell實驗室利用卷積神經網路進行數字識別,該網路的結構和2012年的AlexNet十分相似,
??為什么神經網路僅僅在最近幾年才開始流行?一是因為計算能力的提升,由于摩爾定理,計算機速度每年提高,芯片上晶體管數量90年代至今已經增長了好幾個數量級,如今我們有了GPU這樣的影像處理單元,他們具有超高的并行計算能力,非常適合卷積神經網路這類高強度計算,很多時候只是計算模型的擴展,就能得到更好的結果,另一個關鍵的原因就是資料,這些演算法需要大量的資料,90年代并沒有資料,而如今,2010后我們擁有了像PASCAL和ImageNet這樣的高質量資料集合,
五、未來與挑戰
??在計算機視覺領域,我們正嘗試制造一個和人擁有一樣視覺能力的機器,這是個非常神奇有趣的領域,很多的問題等待著被挑戰,諸如語意分割、知覺分組、動作識別、增強虛擬現實等等,隨著感知器的發展,也將出現更多個有趣的問題,
??毫無疑問,計算機視覺正在帶領人類開創一個偉大的時代,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/290980.html
標籤:其他