本文為學習PaddlePaddle官方教程后的筆記與總結,資料集及代碼參考自PaddlePaddle官方教程,
PaddlePaddle官方教程鏈接:
飛槳PaddlePaddle-源于產業實踐的開源深度學習平臺
一,主要內容介紹
隨著深度學習不斷的發展,目前先后在CV領域常見的CNN網路模型種類主要有LeNet——AlexNet——VGG——GoogleNet——ResNet,本文先后使用了這幾種不同CNN網路來比較其在影像分類上的效果比較,
二,資料集介紹
iChallenge-PM是百度大腦和中山大學中山眼科中心聯合舉辦的iChallenge比賽中提供的關于病理性近視(Pathologic Myopia,PM)的醫療類資料集,包含1200個受試者的眼底視網膜圖片,訓練、驗證和測驗資料集各400張,
資料集的官方網址:
Baidu Research Open-Access Dataset - Introduction
三,不同CNN網路模型
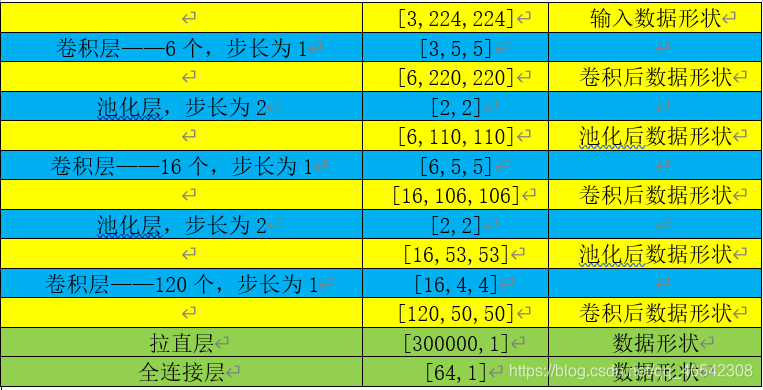
3.1 LeNet網路
LeNet網路結構主要是利用多個卷積核與池化層一直對原資料做多次計算,從而達到提取資料特征、減小原資料量的目的,
本程式搭建的網路結構對資料的卷積計算的程序見下表所示:
程式的主要框架依舊:加載影像——提取資料——搭建網路——配置訓練,直接上代碼,
import cv2
import random
import numpy as np
import os
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout
import paddle.nn.functional as F
import matplotlib.pyplot as plt
# 對讀入的影像資料進行預處理
def transform_img(img):
# 將圖片尺寸縮放道 224x224
img = cv2.resize(img, (224, 224))
# 讀入的影像資料格式是[H, W, C]
# 使用轉置操作將其變成[C, H, W]
img = np.transpose(img, (2,0,1)) # transpose作用是改變序列,(2,0,1)表示各個軸
img = img.astype('float32')
# 最大為225,將資料范圍調整到[-1.0, 1.0]之間
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定義訓練集資料讀取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 將datadir目錄下的檔案列出來,每條檔案都要讀入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 訓練時隨機打亂資料順序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H開頭的檔案名表示高度近似,N開頭的檔案名表示正常視力
# 高度近視和正常視力的樣本,都不是病理性的,屬于負樣本,標簽為0
label = 0
elif name[0] == 'P':
# P開頭的是病理性近視,屬于正樣本,標簽為1
label = 1
else:
raise('Not excepted file name')
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定義驗證集資料讀取器
def valid_data_loader(datadir, csvfile, batch_size=64, mode='valid'):
# 訓練集讀取時通過檔案名來確定樣本標簽,驗證集則通過csvfile來讀取每個圖片對應的標簽
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',') # 把每行的每個字符一個個分開,變成一個list
name = line[1]
label = int(line[2])
# 根據圖片檔案名加載圖片,并對影像資料作預處理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
DATADIR = 'D:/Pycharm 2020/Data set/Eye disease recognition/train/PALM-Training400/'
DATADIR2 = 'D:/Pycharm 2020/Data set/Eye disease recognition/validation/PALM-Validation400/'
CSVFILE = 'D:/Pycharm 2020/Data set/Eye disease recognition/labels.csv' # 必須是UTF-8編碼的CSV檔案
# 定義訓練程序
def train_pm(model, optimizer):
# 開啟0號GPU訓練
'''
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
'''
paddle.set_device('gpu:0')
print('start training ... ')
model.train()
epoch_num = 20
iter = 0
iters = []
train_losses = []
# 定義資料讀取器,訓練資料讀取器和驗證資料讀取器
train_loader = data_loader(DATADIR, batch_size=64, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE)
for epoch in range(epoch_num): # 回圈從0開始,到epoch_num-1,共 epoch_num 輪
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
loss = F.binary_cross_entropy_with_logits(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 2 == 0: # 回傳除法的余數
iters.append(iter)
train_losses.append(avg_loss.numpy())
iter = iter + 2
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向傳播,更新權重,清除梯度
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
# 二分類,sigmoid計算后的結果以0.5為閾值分兩個類別
# 計算sigmoid后的預測概率,進行loss計算
pred = F.sigmoid(logits)
loss = F.binary_cross_entropy_with_logits(logits, label)
# 計算預測概率小于0.5的類別
pred2 = pred * (-1.0) + 1.0
# 得到兩個類別的預測概率,并沿第一個維度級聯
pred = paddle.concat([pred2, pred], axis=1)
acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
paddle.save(model.state_dict(), 'palm.pdparams')
paddle.save(optimizer.state_dict(), 'palm.pdopt')
return iters, train_losses
# 定義評估程序
def evaluation(model, params_file_path):
# 開啟0號GPU預估
paddle.set_device('gpu:0')
print('start evaluation .......')
#加載模型引數
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
model.eval()
eval_loader = data_loader(DATADIR,batch_size=10, mode='eval')
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
y_data = y_data.astype(np.int64)
label_64 = paddle.to_tensor(y_data)
# 計算預測和精度
prediction, acc = model(img, label_64)
# 計算損失函式值
loss = F.binary_cross_entropy_with_logits(prediction, label)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
# 定義 LeNet 網路結構
class LeNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 創建卷積和池化層塊,每個卷積層使用Sigmoid激活函式,后面跟著一個2x2的池化
self.conv1 = Conv2D(in_channels=3, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 創建第3個卷積層
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
# 創建全連接層,第一個全連接層的輸出神經元個數為64
self.fc1 = Linear(in_features=300000, out_features=64)
# 第二個全連接層輸出神經元個數為分類標簽的類別數
self.fc2 = Linear(in_features=64, out_features=num_classes)
# 網路的前向計算程序
def forward(self, x, label=None):
x = self.conv1(x)
x = F.sigmoid(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.sigmoid(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.sigmoid(x)
x = paddle.reshape(x, [x.shape[0], -1]) # paddle.reshape(x, shape, name=None),拉直了
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
# 創建模型
model = LeNet(num_classes=1)
# 啟動訓練程序
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())
iters, train_losses = train_pm(model, optimizer=opt)
evaluation(model, params_file_path="palm.pdparams")
# 畫出訓練程序中Loss的變化曲線
plt.figure()
plt.title("LeNet-train loss", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(iters, train_losses, color='red', label='train loss')
plt.grid()
plt.show()3.2 AlexNet網路
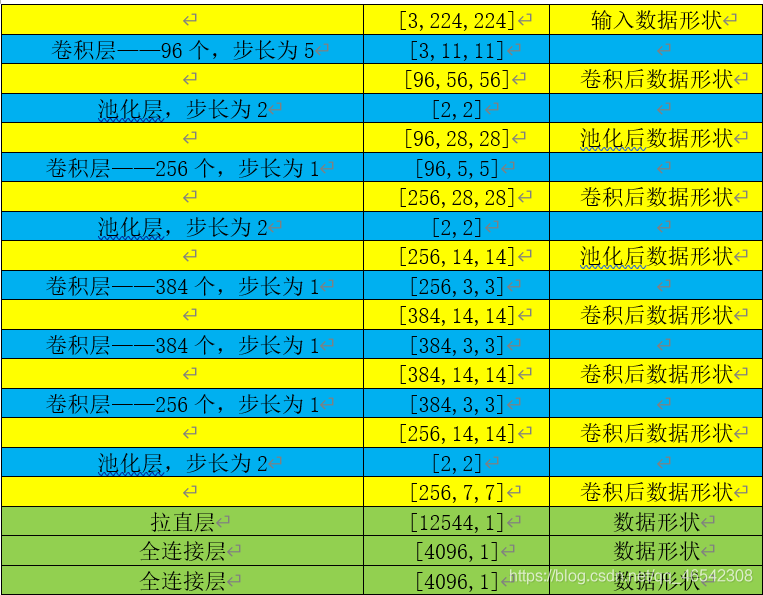
AlexNet網路相比于LeNet網路的改進主要體現在,加深了網路層數,激活函式使用relu,加入dropout層,做影像增強,
Alex網路結構對資料的卷積計算的程序見下表所示:
代碼如下:
import cv2
import random
import numpy as np
import os
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout
import paddle.nn.functional as F
import matplotlib.pyplot as plt
# 對讀入的影像資料進行預處理
def transform_img(img):
# 將圖片尺寸縮放道 224x224
img = cv2.resize(img, (224, 224))
# 讀入的影像資料格式是[H, W, C]
# 使用轉置操作將其變成[C, H, W]
img = np.transpose(img, (2,0,1)) # transpose作用是改變序列,(2,0,1)表示各個軸
img = img.astype('float32')
# 將資料范圍調整到[-1.0, 1.0]之間
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定義訓練集資料讀取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 將datadir目錄下的檔案列出來,每條檔案都要讀入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 訓練時隨機打亂資料順序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H開頭的檔案名表示高度近似,N開頭的檔案名表示正常視力
# 高度近視和正常視力的樣本,都不是病理性的,屬于負樣本,標簽為0
label = 0
elif name[0] == 'P':
# P開頭的是病理性近視,屬于正樣本,標簽為1
label = 1
else:
raise('Not excepted file name')
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定義驗證集資料讀取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 訓練集讀取時通過檔案名來確定樣本標簽,驗證集則通過csvfile來讀取每個圖片對應的標簽
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',') # 把每行的每個字符一個個分開,變成一個list
name = line[1]
label = int(line[2])
# 根據圖片檔案名加載圖片,并對影像資料作預處理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
DATADIR = 'D:/Pycharm 2020/Data set/Eye disease recognition/train/PALM-Training400/'
DATADIR2 = 'D:/Pycharm 2020/Data set/Eye disease recognition/validation/PALM-Validation400/'
CSVFILE = 'D:/Pycharm 2020/Data set/Eye disease recognition/labels.csv' # 必須是UTF-8編碼的CSV檔案
# 定義訓練程序
def train_pm(model, optimizer):
# 開啟0號GPU訓練
'''
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
'''
paddle.set_device('gpu:0')
print('start training ... ')
model.train()
epoch_num = 20
iter = 0
iters = []
train_losses = []
# 定義資料讀取器,訓練資料讀取器和驗證資料讀取器
train_loader = data_loader(DATADIR, batch_size=64, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE,batch_size=64)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
loss = F.binary_cross_entropy_with_logits(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 2 == 0:
iters.append(iter)
train_losses.append(avg_loss.numpy())
iter = iter + 2
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向傳播,更新權重,清除梯度
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
# 二分類,sigmoid計算后的結果以0.5為閾值分兩個類別
# 計算sigmoid后的預測概率,進行loss計算
pred = F.sigmoid(logits)
loss = F.binary_cross_entropy_with_logits(logits, label)
# 計算預測概率小于0.5的類別
pred2 = pred * (-1.0) + 1.0
# 得到兩個類別的預測概率,并沿第一個維度級聯
pred = paddle.concat([pred2, pred], axis=1)
acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
paddle.save(model.state_dict(), 'palm.pdparams')
paddle.save(optimizer.state_dict(), 'palm.pdopt')
return iters, train_losses
# 定義評估程序
def evaluation(model, params_file_path):
# 開啟0號GPU預估
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
print('start evaluation .......')
#加載模型引數
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
model.eval()
eval_loader = data_loader(DATADIR,batch_size=64, mode='eval')
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
y_data = y_data.astype(np.int64)
label_64 = paddle.to_tensor(y_data)
# 計算預測和精度
prediction, acc = model(img, label_64)
# 計算損失函式值
loss = F.binary_cross_entropy_with_logits(prediction, label)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
# 定義 AlexNet 網路結構
class AlexNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(AlexNet, self).__init__()
# AlexNet與LeNet一樣也會同時使用卷積和池化層提取影像特征
# 與LeNet不同的是激活函式換成了‘relu’
self.conv1 = Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=5) # padding_height = padding_width = padding,默認值:0
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv4 = Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv5 = Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.max_pool5 = MaxPool2D(kernel_size=2, stride=2)
self.fc1 = Linear(in_features=12544, out_features=4096)
self.drop_ratio1 = 0.5
self.drop1 = Dropout(self.drop_ratio1)
self.fc2 = Linear(in_features=4096, out_features=4096)
self.drop_ratio2 = 0.5
self.drop2 = Dropout(self.drop_ratio2)
self.fc3 = Linear(in_features=4096, out_features=num_classes)
def forward(self, x, label=None):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.conv5(x)
x = F.relu(x)
x = self.max_pool5(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.relu(x)
# 在全連接之后使用dropout抑制過擬合
x = self.drop1(x)
x = self.fc2(x)
x = F.relu(x)
# 在全連接之后使用dropout抑制過擬合
x = self.drop2(x)
x = self.fc3(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
# 創建模型
model = AlexNet()
# 啟動訓練程序
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
iters, train_losses = train_pm(model, optimizer=opt)
# 畫出訓練程序中Loss的變化曲線
plt.figure()
plt.title("AlexNet-train loss", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(iters, train_losses, color='red', label='train loss')
plt.grid()
plt.show()3.3 VGG網路
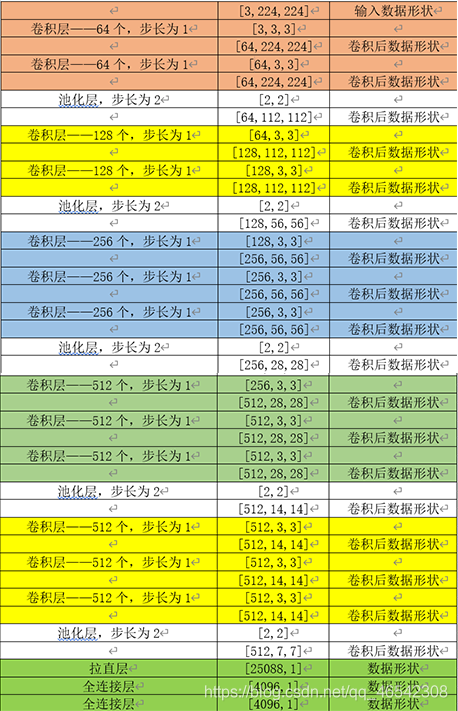
VGG網路的主要思想是重復使用簡單的卷積層(例如3×3),把模型做的非常深,加大感受野,
VGG網路結構對資料的卷積計算的程序見下表所示:
程式如下:
import cv2
import random
import numpy as np
import os
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, BatchNorm2D, Linear
import matplotlib.pyplot as plt
# 對讀入的影像資料進行預處理
def transform_img(img):
# 將圖片尺寸縮放道 224x224
img = cv2.resize(img, (224, 224))
# 讀入的影像資料格式是[H, W, C]
# 使用轉置操作將其變成[C, H, W]
img = np.transpose(img, (2,0,1)) # transpose作用是改變序列,(2,0,1)表示各個軸
img = img.astype('float32')
# 將資料范圍調整到[-1.0, 1.0]之間
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定義訓練集資料讀取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 將datadir目錄下的檔案列出來,每條檔案都要讀入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 訓練時隨機打亂資料順序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H開頭的檔案名表示高度近似,N開頭的檔案名表示正常視力
# 高度近視和正常視力的樣本,都不是病理性的,屬于負樣本,標簽為0
label = 0
elif name[0] == 'P':
# P開頭的是病理性近視,屬于正樣本,標簽為1
label = 1
else:
raise('Not excepted file name')
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定義驗證集資料讀取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 訓練集讀取時通過檔案名來確定樣本標簽,驗證集則通過csvfile來讀取每個圖片對應的標簽
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',') # 把每行的每個字符一個個分開,變成一個list
name = line[1]
label = int(line[2])
# 根據圖片檔案名加載圖片,并對影像資料作預處理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
DATADIR = 'D:/Pycharm 2020/Data set/Eye disease recognition/train/PALM-Training400/'
DATADIR2 = 'D:/Pycharm 2020/Data set/Eye disease recognition/validation/PALM-Validation400/'
CSVFILE = 'D:/Pycharm 2020/Data set/Eye disease recognition/labels.csv' # 必須是UTF-8編碼的CSV檔案
# 定義訓練程序
def train_pm(model, optimizer):
# 開啟0號GPU訓練
paddle.set_device('gpu:0')
# paddle.set_device('gpu:0')
print('start training ... ')
model.train()
epoch_num = 20
iter = 0
iters = []
train_losses = []
# 定義資料讀取器,訓練資料讀取器和驗證資料讀取器
train_loader = data_loader(DATADIR, batch_size=2, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE, batch_size=2)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
loss = F.binary_cross_entropy_with_logits(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 5 == 0:
iters.append(iter)
train_losses.append(avg_loss.numpy())
iter = iter + 5
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向傳播,更新權重,清除梯度
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
# 二分類,sigmoid計算后的結果以0.5為閾值分兩個類別
# 計算sigmoid后的預測概率,進行loss計算
pred = F.sigmoid(logits)
loss = F.binary_cross_entropy_with_logits(logits, label)
# 計算預測概率小于0.5的類別
pred2 = pred * (-1.0) + 1.0
# 得到兩個類別的預測概率,并沿第一個維度級聯
pred = paddle.concat([pred2, pred], axis=1)
acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
paddle.save(model.state_dict(), 'palm.pdparams')
paddle.save(optimizer.state_dict(), 'palm.pdopt')
return iters, train_losses
# 定義vgg網路
class VGG(paddle.nn.Layer):
def __init__(self):
super(VGG, self).__init__()
in_channels = [3, 64, 128, 256, 512, 512]
# 定義第一個卷積塊,包含兩個卷積
self.conv1_1 = Conv2D(in_channels=in_channels[0], out_channels=in_channels[1], kernel_size=3, padding=1, stride=1)
self.conv1_2 = Conv2D(in_channels=in_channels[1], out_channels=in_channels[1], kernel_size=3, padding=1, stride=1)
# 定義第二個卷積塊,包含兩個卷積
self.conv2_1 = Conv2D(in_channels=in_channels[1], out_channels=in_channels[2], kernel_size=3, padding=1,stride=1)
self.conv2_2 = Conv2D(in_channels=in_channels[2], out_channels=in_channels[2], kernel_size=3, padding=1,stride=1)
# 定義第三個卷積塊,包含三個卷積
self.conv3_1 = Conv2D(in_channels=in_channels[2], out_channels=in_channels[3], kernel_size=3, padding=1,stride=1)
self.conv3_2 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[3], kernel_size=3, padding=1,stride=1)
self.conv3_3 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[3], kernel_size=3, padding=1,stride=1)
# 定義第四個卷積塊,包含三個卷積
self.conv4_1 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[4], kernel_size=3, padding=1,stride=1)
self.conv4_2 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[4], kernel_size=3, padding=1,stride=1)
self.conv4_3 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[4], kernel_size=3, padding=1,stride=1)
# 定義第五個卷積塊,包含三個卷積
self.conv5_1 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[5], kernel_size=3, padding=1,stride=1)
self.conv5_2 = Conv2D(in_channels=in_channels[5], out_channels=in_channels[5], kernel_size=3, padding=1,stride=1)
self.conv5_3 = Conv2D(in_channels=in_channels[5], out_channels=in_channels[5], kernel_size=3, padding=1,stride=1)
# 使用Sequential 將全連接層和relu組成一個線性結構(fc + relu)
# 當輸入為224x224時,經過五個卷積塊和池化層后,特征維度變為[512x7x7]
self.fc1 = paddle.nn.Sequential(paddle.nn.Linear(512 * 7 * 7, 4096), paddle.nn.ReLU())
self.drop1_ratio = 0.5
self.dropout1 = paddle.nn.Dropout(self.drop1_ratio, mode='upscale_in_train')
# 使用Sequential 將全連接層和relu組成一個線性結構(fc + relu)
self.fc2 = paddle.nn.Sequential(paddle.nn.Linear(4096, 4096), paddle.nn.ReLU())
self.drop2_ratio = 0.5
self.dropout2 = paddle.nn.Dropout(self.drop2_ratio, mode='upscale_in_train')
self.fc3 = paddle.nn.Linear(4096, 1)
self.relu = paddle.nn.ReLU()
self.pool = MaxPool2D(stride=2, kernel_size=2)
def forward(self, x):
x = self.relu(self.conv1_1(x))
x = self.relu(self.conv1_2(x))
x = self.pool(x)
x = self.relu(self.conv2_1(x))
x = self.relu(self.conv2_2(x))
x = self.pool(x)
x = self.relu(self.conv3_1(x))
x = self.relu(self.conv3_2(x))
x = self.relu(self.conv3_3(x))
x = self.pool(x)
x = self.relu(self.conv4_1(x))
x = self.relu(self.conv4_2(x))
x = self.relu(self.conv4_3(x))
x = self.pool(x)
x = self.relu(self.conv5_1(x))
x = self.relu(self.conv5_2(x))
x = self.relu(self.conv5_3(x))
x = self.pool(x)
x = paddle.flatten(x, 1, -1)
x = self.dropout1(self.relu(self.fc1(x)))
x = self.dropout2(self.relu(self.fc2(x)))
x = self.fc3(x)
return x
# 創建模型
model = VGG()
# 啟動訓練程序
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())
iters, train_losses = train_pm(model, optimizer=opt)
# 畫出訓練程序中Loss的變化曲線
plt.figure()
plt.title("VGG-train loss", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(iters, train_losses, color='red', label='train loss')
plt.grid()
plt.show()
3.4 GoogleNet網路
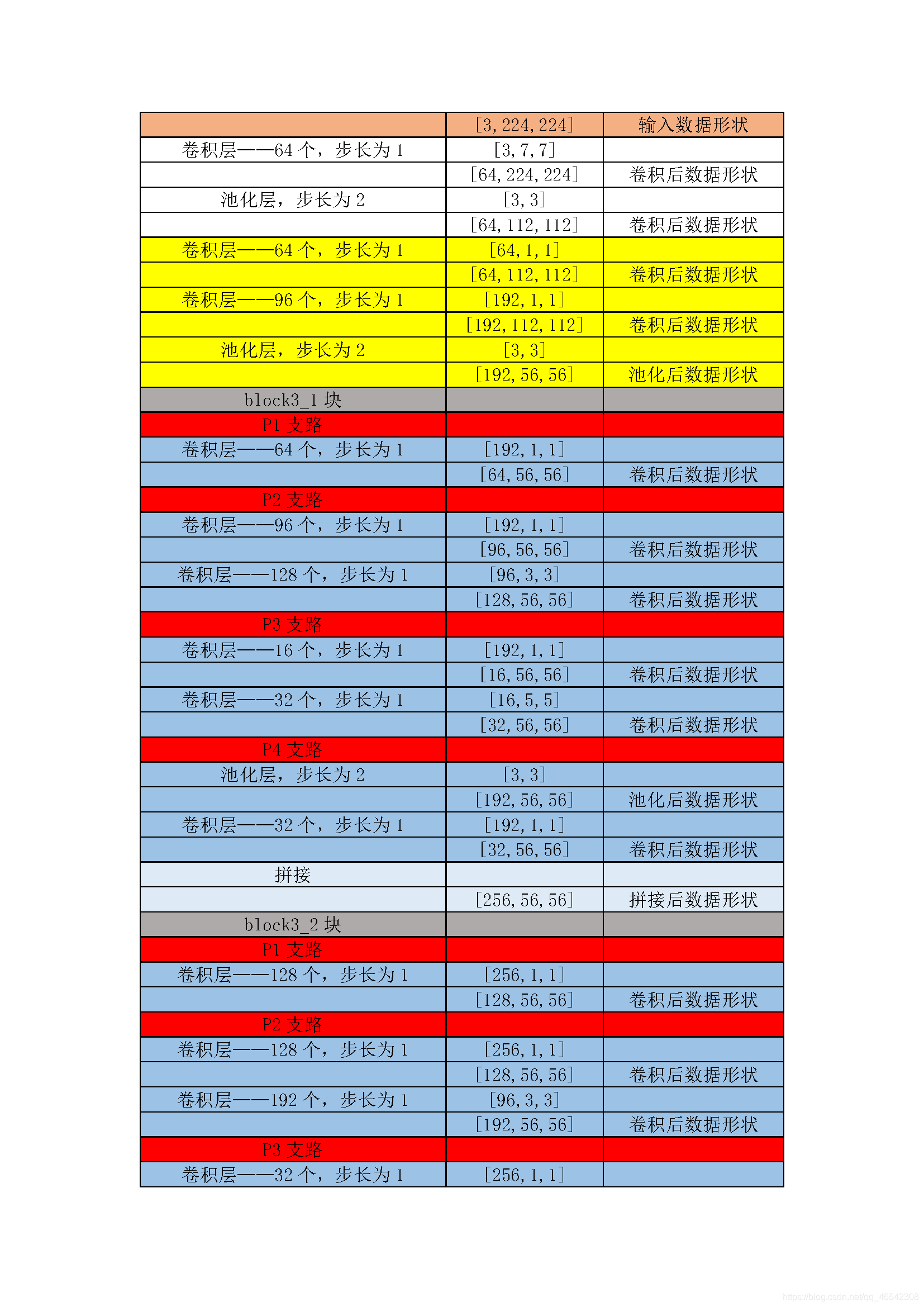
以上的CNN模型都是輸入影像有多少個通道數,使用相同的out_channels個的卷積核對每一個逐一通道做相同的卷積計算,GoogleNet網路的思想是每一個通道都做使用不再相同的卷積核做不同的卷積計算,
通俗點來說就是,例如在VGG中,[3×224×224]資料做卷積計算時,沿著第一個維度,在3個通道上都是用10個[5×5]的卷積核做計算,而在GoogleNet中,沿著第一個維度,其維度數為3,分別用8個[5×5],16個[3×3]與18個[3×3],32個[5×5]與12個[3×3],做計算,就是每個通道上的卷積核形狀,卷積層數,卷積核個數都不再相同,
GoogleNet網路對資料的卷積計算程序本人粗略整理了一下,見下表:
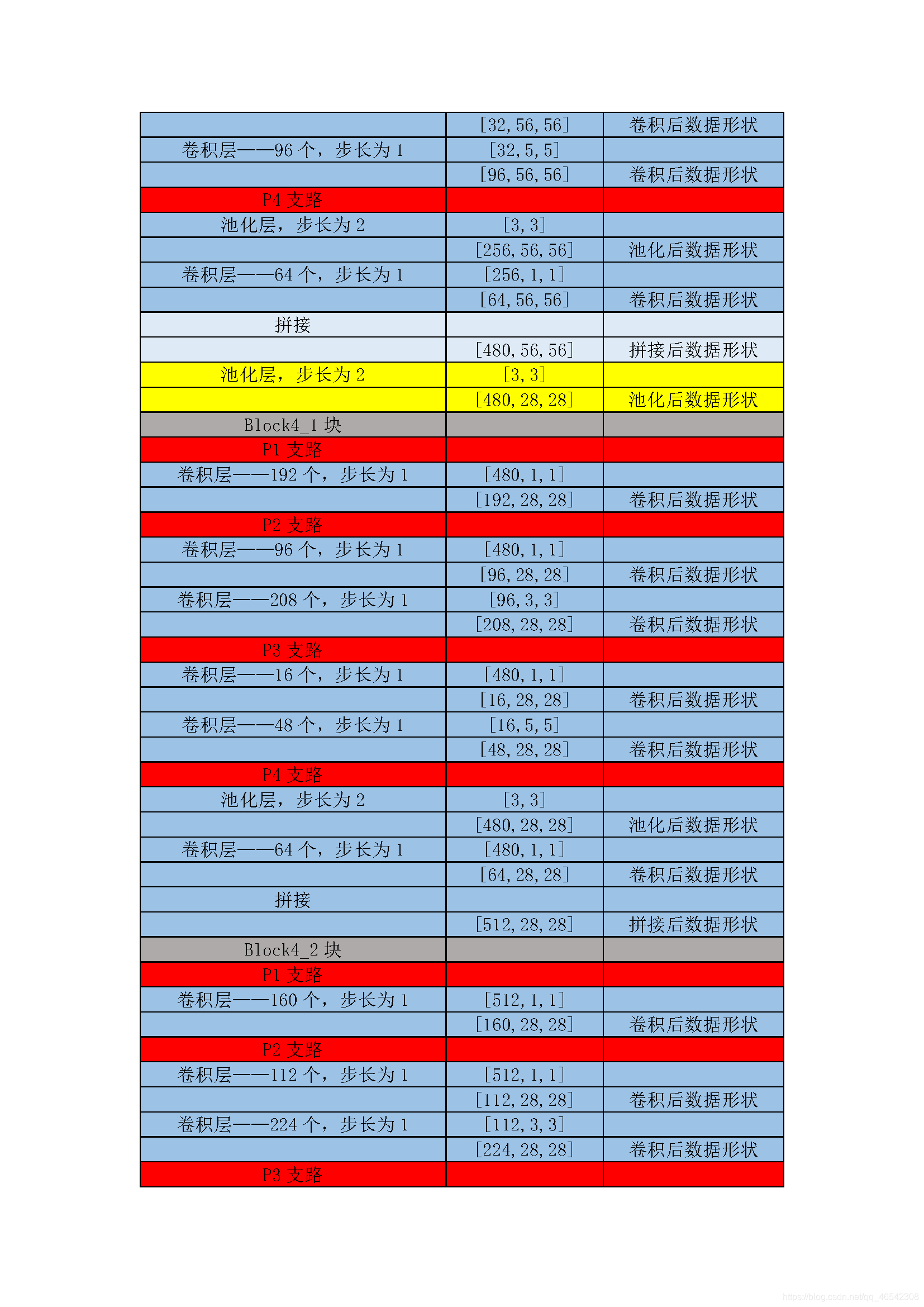
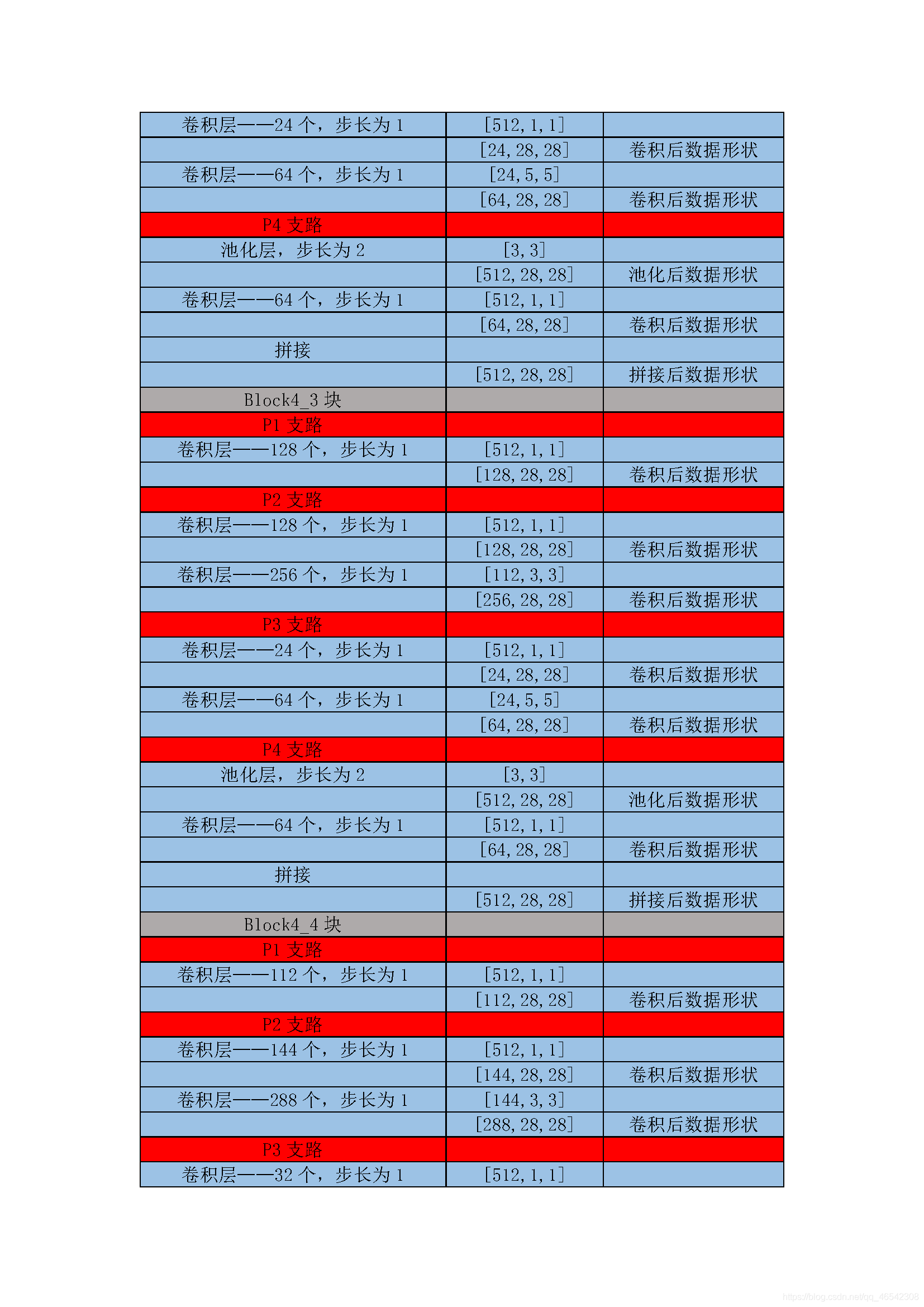
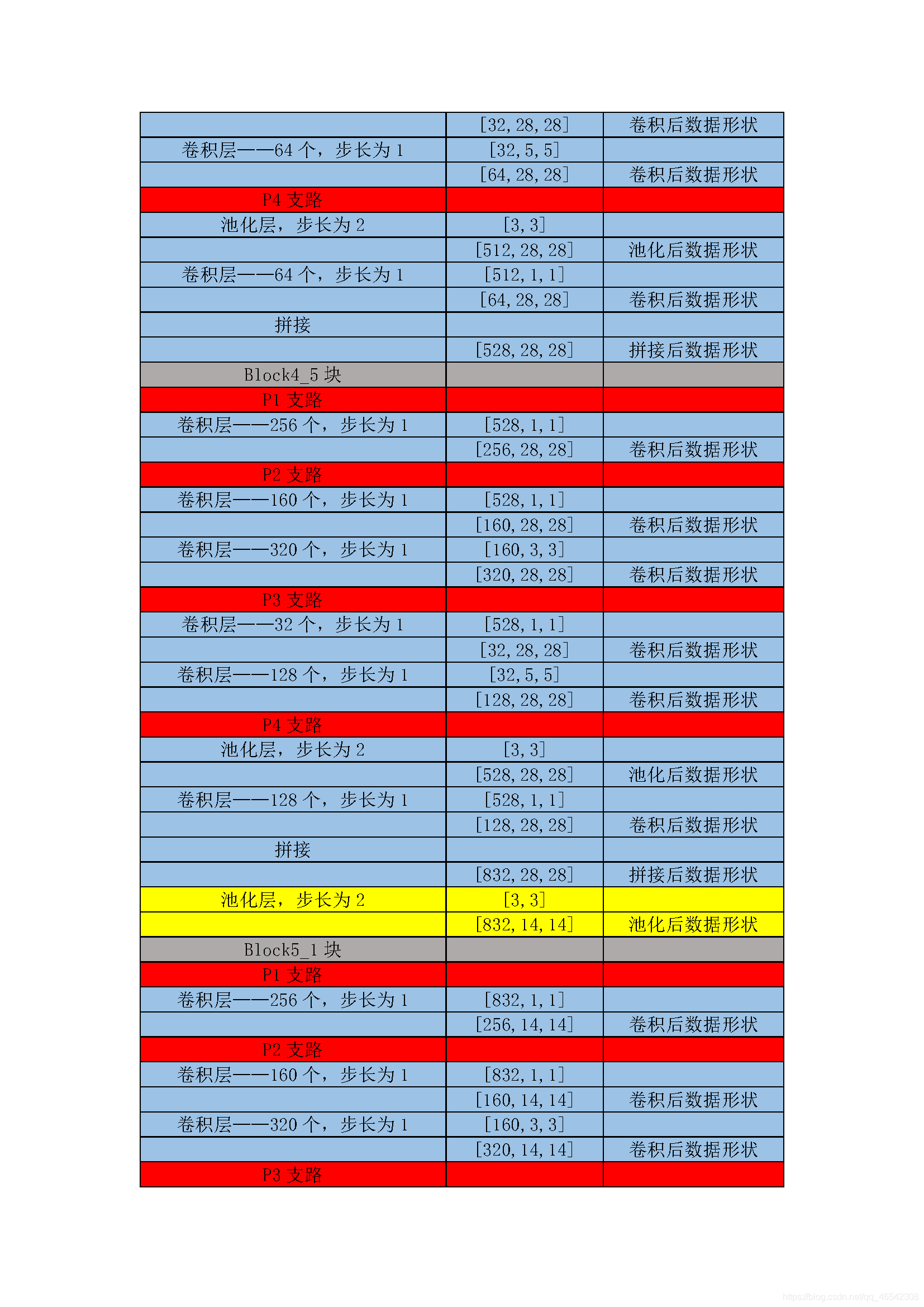
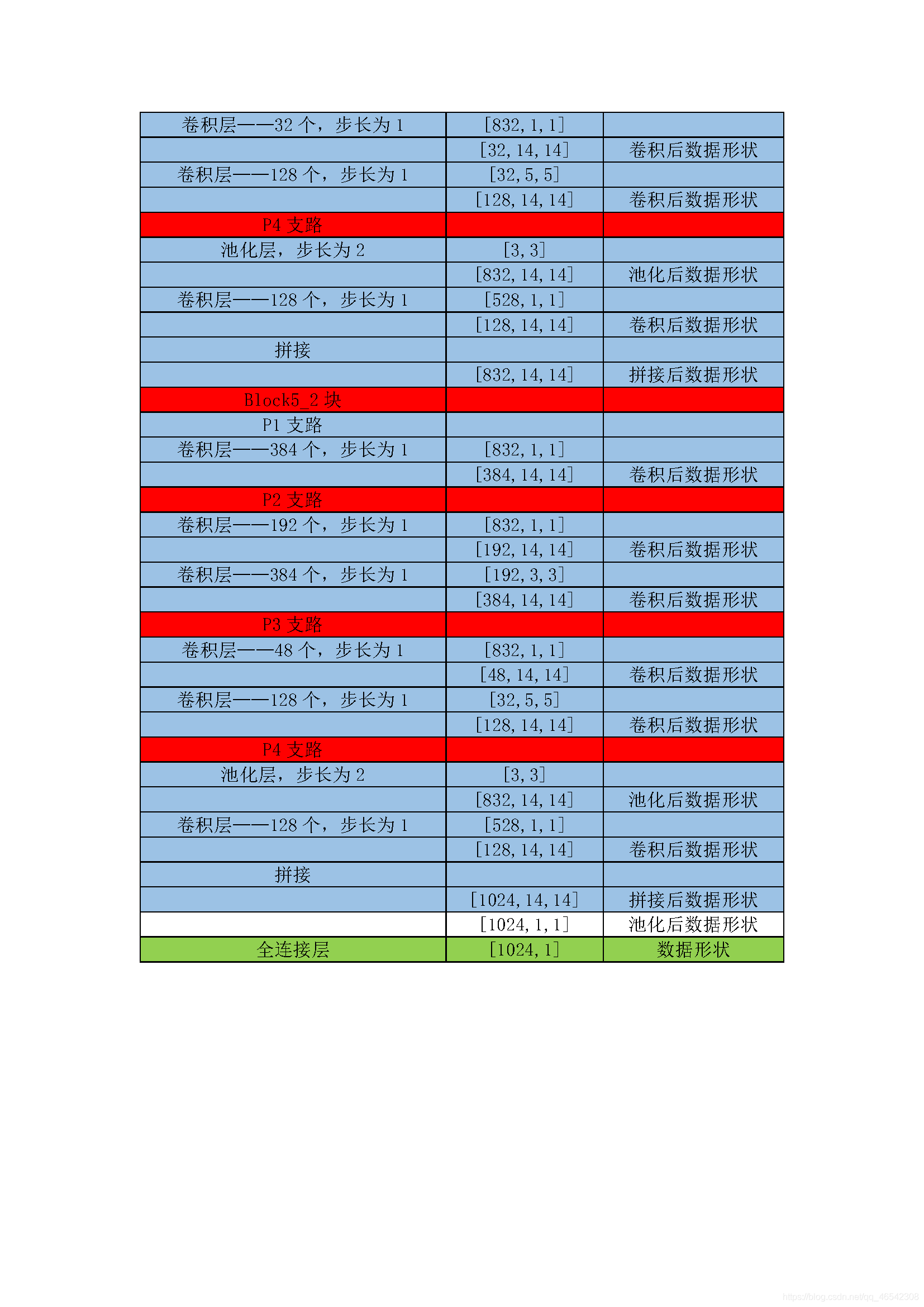
附上源代碼:
import cv2
import random
import numpy as np
import os
import paddle
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, AdaptiveAvgPool2D, Linear
import matplotlib.pyplot as plt
# 對讀入的影像資料進行預處理
def transform_img(img):
# 將圖片尺寸縮放道 224x224
img = cv2.resize(img, (224, 224))
# 讀入的影像資料格式是[H, W, C]
# 使用轉置操作將其變成[C, H, W]
img = np.transpose(img, (2,0,1)) # transpose作用是改變序列,(2,0,1)表示各個軸
img = img.astype('float32')
# 將資料范圍調整到[-1.0, 1.0]之間
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定義訓練集資料讀取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 將datadir目錄下的檔案列出來,每條檔案都要讀入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 訓練時隨機打亂資料順序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H開頭的檔案名表示高度近似,N開頭的檔案名表示正常視力
# 高度近視和正常視力的樣本,都不是病理性的,屬于負樣本,標簽為0
label = 0
elif name[0] == 'P':
# P開頭的是病理性近視,屬于正樣本,標簽為1
label = 1
else:
raise('Not excepted file name')
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定義驗證集資料讀取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 訓練集讀取時通過檔案名來確定樣本標簽,驗證集則通過csvfile來讀取每個圖片對應的標簽
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',') # 把每行的每個字符一個個分開,變成一個list
name = line[1]
label = int(line[2])
# 根據圖片檔案名加載圖片,并對影像資料作預處理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
DATADIR = 'D:/Pycharm 2020/Data set/Eye disease recognition/train/PALM-Training400/'
DATADIR2 = 'D:/Pycharm 2020/Data set/Eye disease recognition/validation/PALM-Validation400/'
CSVFILE = 'D:/Pycharm 2020/Data set/Eye disease recognition/labels.csv' # 必須是UTF-8編碼的CSV檔案
# 定義訓練程序
def train_pm(model, optimizer):
# 開啟0號GPU訓練
paddle.set_device('gpu:0')
# paddle.set_device('gpu:0')
print('start training ... ')
model.train()
epoch_num = 20
iter = 0
iters = []
train_losses = []
# 定義資料讀取器,訓練資料讀取器和驗證資料讀取器
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE, batch_size=10)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
loss = F.binary_cross_entropy_with_logits(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 10 == 0:
iters.append(iter)
train_losses.append(avg_loss.numpy())
iter = iter + 10
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向傳播,更新權重,清除梯度
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
# 二分類,sigmoid計算后的結果以0.5為閾值分兩個類別
# 計算sigmoid后的預測概率,進行loss計算
pred = F.sigmoid(logits)
loss = F.binary_cross_entropy_with_logits(logits, label)
# 計算預測概率小于0.5的類別
pred2 = pred * (-1.0) + 1.0
# 得到兩個類別的預測概率,并沿第一個維度級聯
pred = paddle.concat([pred2, pred], axis=1)
acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
paddle.save(model.state_dict(), 'palm.pdparams')
paddle.save(optimizer.state_dict(), 'palm.pdopt')
return iters, train_losses
# 定義Inception塊
class Inception(paddle.nn.Layer):
def __init__(self, c0, c1, c2, c3, c4, **kwargs):
'''
Inception模塊的實作代碼,
c1,圖(b)中第一條支路1x1卷積的輸出通道數,資料型別是整數
c2,圖(b)中第二條支路卷積的輸出通道數,資料型別是tuple或list,
其中c2[0]是1x1卷積的輸出通道數,c2[1]是3x3
c3,圖(b)中第三條支路卷積的輸出通道數,資料型別是tuple或list,
其中c3[0]是1x1卷積的輸出通道數,c3[1]是3x3
c4,圖(b)中第一條支路1x1卷積的輸出通道數,資料型別是整數
'''
super(Inception, self).__init__()
# 依次創建Inception塊每條支路上使用到的操作
self.p1_1 = Conv2D(in_channels=c0, out_channels=c1, kernel_size=1, stride=1)
self.p2_1 = Conv2D(in_channels=c0, out_channels=c2[0], kernel_size=1, stride=1)
self.p2_2 = Conv2D(in_channels=c2[0], out_channels=c2[1], kernel_size=3, padding=1, stride=1)
self.p3_1 = Conv2D(in_channels=c0, out_channels=c3[0], kernel_size=1, stride=1)
self.p3_2 = Conv2D(in_channels=c3[0], out_channels=c3[1], kernel_size=5, padding=2, stride=1)
self.p4_1 = MaxPool2D(kernel_size=3, stride=1, padding=1)
self.p4_2 = Conv2D(in_channels=c0, out_channels=c4, kernel_size=1, stride=1)
# # 新加一層batchnorm穩定收斂
# self.batchnorm = paddle.nn.BatchNorm2D(c1+c2[1]+c3[1]+c4)
def forward(self, x):
# 支路1只包含一個1x1卷積
p1 = F.relu(self.p1_1(x))
# 支路2包含 1x1卷積 + 3x3卷積
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
# 支路3包含 1x1卷積 + 5x5卷積
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
# 支路4包含 最大池化和1x1卷積
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 將每個支路的輸出特征圖拼接在一起作為最終的輸出結果
return paddle.concat([p1, p2, p3, p4], axis=1)
# return self.batchnorm()
class GoogLeNet(paddle.nn.Layer):
def __init__(self):
super(GoogLeNet, self).__init__()
# GoogLeNet包含五個模塊,每個模塊后面緊跟一個池化層
# 第一個模塊包含1個卷積層
self.conv1 = Conv2D(in_channels=3, out_channels=64, kernel_size=7, padding=3, stride=1)
# 3x3最大池化
self.pool1 = MaxPool2D(kernel_size=3, stride=2, padding=1)
# 第二個模塊包含2個卷積層
self.conv2_1 = Conv2D(in_channels=64, out_channels=64, kernel_size=1, stride=1)
self.conv2_2 = Conv2D(in_channels=64, out_channels=192, kernel_size=3, padding=1, stride=1)
# 3x3最大池化
self.pool2 = MaxPool2D(kernel_size=3, stride=2, padding=1)
# 第三個模塊包含2個Inception塊
self.block3_1 = Inception(192, 64, (96, 128), (16, 32), 32)
self.block3_2 = Inception(256, 128, (128, 192), (32, 96), 64)
# 3x3最大池化
self.pool3 = MaxPool2D(kernel_size=3, stride=2, padding=1)
# 第四個模塊包含5個Inception塊
self.block4_1 = Inception(480, 192, (96, 208), (16, 48), 64)
self.block4_2 = Inception(512, 160, (112, 224), (24, 64), 64)
self.block4_3 = Inception(512, 128, (128, 256), (24, 64), 64)
self.block4_4 = Inception(512, 112, (144, 288), (32, 64), 64)
self.block4_5 = Inception(528, 256, (160, 320), (32, 128), 128)
# 3x3最大池化
self.pool4 = MaxPool2D(kernel_size=3, stride=2, padding=1)
# 第五個模塊包含2個Inception塊
self.block5_1 = Inception(832, 256, (160, 320), (32, 128), 128)
self.block5_2 = Inception(832, 384, (192, 384), (48, 128), 128)
# 全域池化,用的是global_pooling,不需要設定pool_stride
self.pool5 = AdaptiveAvgPool2D(output_size=1)
self.fc = Linear(in_features=1024, out_features=1)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2_2(F.relu(self.conv2_1(x)))))
x = self.pool3(self.block3_2(self.block3_1(x)))
x = self.block4_3(self.block4_2(self.block4_1(x)))
x = self.pool4(self.block4_5(self.block4_4(x)))
x = self.pool5(self.block5_2(self.block5_1(x)))
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc(x)
return x
# 創建模型
model = GoogLeNet()
print(len(model.parameters()))
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters(), weight_decay=0.001)
# 啟動訓練程序
iters, train_losses = train_pm(model, optimizer=opt)
# 畫出訓練程序中Loss的變化曲線
plt.figure()
plt.title("GoogleNet-train loss", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(iters, train_losses, color='red', label='train loss')
plt.grid()
plt.show()3.5 ResNet網路
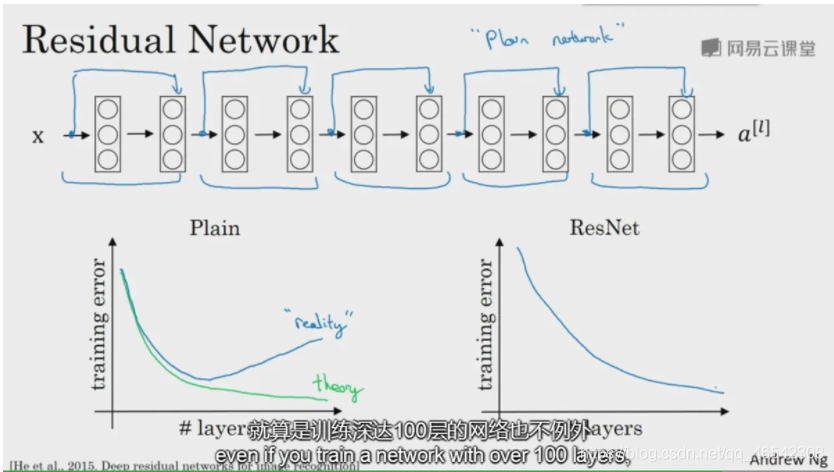
ResNet網路主要是在結構中加入了殘差塊,
ResNet網路對資料的卷積計算程序與上文中的計算程序都類似,只是在在某一層的線性模塊之后,非線性模塊之前增加前面某層的輸出,如下圖共有5個殘差塊,
我個人的理解最通俗來說就是在例如VGG網路基礎上各層之間跨層連接上一條線,實作跨層恒等變換,具體為什么這樣做,以及原理,可參考這篇博客:
https://blog.csdn.net/dulingtingzi/article/details/79870486
這個文章講的比較淺顯,也可以加深理解,
https://www.jianshu.com/p/b08e4724fcea
代碼如下:
import cv2
import random
import numpy as np
import os
import paddle
import paddle.nn.functional as F
import paddle.nn as nn
import matplotlib.pyplot as plt
# 對讀入的影像資料進行預處理
def transform_img(img):
# 將圖片尺寸縮放道 224x224
img = cv2.resize(img, (224, 224))
# 讀入的影像資料格式是[H, W, C]
# 使用轉置操作將其變成[C, H, W]
img = np.transpose(img, (2,0,1)) # transpose作用是改變序列,(2,0,1)表示各個軸
img = img.astype('float32')
# 將資料范圍調整到[-1.0, 1.0]之間
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定義訓練集資料讀取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 將datadir目錄下的檔案列出來,每條檔案都要讀入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 訓練時隨機打亂資料順序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H開頭的檔案名表示高度近似,N開頭的檔案名表示正常視力
# 高度近視和正常視力的樣本,都不是病理性的,屬于負樣本,標簽為0
label = 0
elif name[0] == 'P':
# P開頭的是病理性近視,屬于正樣本,標簽為1
label = 1
else:
raise('Not excepted file name')
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定義驗證集資料讀取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 訓練集讀取時通過檔案名來確定樣本標簽,驗證集則通過csvfile來讀取每個圖片對應的標簽
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',') # 把每行的每個字符一個個分開,變成一個list
name = line[1]
label = int(line[2])
# 根據圖片檔案名加載圖片,并對影像資料作預處理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每讀取一個樣本的資料,就將其放入資料串列中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 當資料串列的長度等于batch_size的時候,
# 把這些資料當作一個mini-batch,并作為資料生成器的一個輸出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余樣本數目不足一個batch_size的資料,一起打包成一個mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
DATADIR = 'D:/Pycharm 2020/Data set/Eye disease recognition/train/PALM-Training400/'
DATADIR2 = 'D:/Pycharm 2020/Data set/Eye disease recognition/validation/PALM-Validation400/'
CSVFILE = 'D:/Pycharm 2020/Data set/Eye disease recognition/labels.csv' # 必須是UTF-8編碼的CSV檔案
# 定義訓練程序
def train_pm(model, optimizer):
# 開啟0號GPU訓練
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
# paddle.set_device('gpu:0')
print('start training ... ')
model.train()
epoch_num = 20
iter = 0
iters = []
train_losses = []
# 定義資料讀取器,訓練資料讀取器和驗證資料讀取器
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
loss = F.binary_cross_entropy_with_logits(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 10 == 0:
iters.append(iter)
train_losses.append(avg_loss.numpy())
iter = iter + 10
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向傳播,更新權重,清除梯度
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
# 運行模型前向計算,得到預測值
logits = model(img)
# 二分類,sigmoid計算后的結果以0.5為閾值分兩個類別
# 計算sigmoid后的預測概率,進行loss計算
pred = F.sigmoid(logits)
loss = F.binary_cross_entropy_with_logits(logits, label)
# 計算預測概率小于0.5的類別
pred2 = pred * (-1.0) + 1.0
# 得到兩個類別的預測概率,并沿第一個維度級聯
pred = paddle.concat([pred2, pred], axis=1)
acc = paddle.metric.accuracy(pred, paddle.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
paddle.save(model.state_dict(), 'palm.pdparams')
paddle.save(optimizer.state_dict(), 'palm.pdopt')
return iters, train_losses
# ResNet中使用了BatchNorm層,在卷積層的后面加上BatchNorm以提升數值穩定性
# 定義卷積批歸一化塊
class ConvBNLayer(paddle.nn.Layer):
def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act=None):
"""
num_channels, 卷積層的輸入通道數
num_filters, 卷積層的輸出通道數
stride, 卷積層的步幅
groups, 分組卷積的組數,默認groups=1不使用分組卷積
"""
super(ConvBNLayer, self).__init__()
# 創建卷積層
self._conv = nn.Conv2D(in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, bias_attr=False)
# 創建BatchNorm層
self._batch_norm = paddle.nn.BatchNorm2D(num_filters)
self.act = act
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
if self.act == 'leaky':
y = F.leaky_relu(x=y, negative_slope=0.1)
elif self.act == 'relu':
y = F.relu(x=y)
return y
# 定義殘差塊
# 每個殘差塊會對輸入圖片做三次卷積,然后跟輸入圖片進行短接
# 如果殘差塊中第三次卷積輸出特征圖的形狀與輸入不一致,則對輸入圖片做1x1卷積,將其輸出形狀調整成一致
class BottleneckBlock(paddle.nn.Layer):
def __init__(self, num_channels, num_filters, stride, shortcut=True):
super(BottleneckBlock, self).__init__()
# 創建第一個卷積層 1x1
self.conv0 = ConvBNLayer(num_channels=num_channels, num_filters=num_filters, filter_size=1, act='relu')
# 創建第二個卷積層 3x3
self.conv1 = ConvBNLayer(num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=stride, act='relu')
# 創建第三個卷積 1x1,但輸出通道數乘以4
self.conv2 = ConvBNLayer(num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None)
# 如果conv2的輸出跟此殘差塊的輸入資料形狀一致,則shortcut=True
# 否則shortcut = False,添加1個1x1的卷積作用在輸入資料上,使其形狀變成跟conv2一致
if not shortcut:
self.short = ConvBNLayer(num_channels=num_channels, num_filters=num_filters * 4, filter_size=1, stride=stride)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
# 如果shortcut=True,直接將inputs跟conv2的輸出相加
# 否則需要對inputs進行一次卷積,將形狀調整成跟conv2輸出一致
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
# 定義ResNet模型
class ResNet(paddle.nn.Layer):
def __init__(self, layers=50, class_dim=1):
"""
layers, 網路層數,可以是50, 101或者152
class_dim,分類標簽的類別數
"""
super(ResNet, self).__init__()
self.layers = layers
supported_layers = [50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(supported_layers, layers)
if layers == 50:
# ResNet50包含多個模塊,其中第2到第5個模塊分別包含3、4、6、3個殘差塊
depth = [3, 4, 6, 3]
elif layers == 101:
# ResNet101包含多個模塊,其中第2到第5個模塊分別包含3、4、23、3個殘差塊
depth = [3, 4, 23, 3]
elif layers == 152:
# ResNet152包含多個模塊,其中第2到第5個模塊分別包含3、8、36、3個殘差塊
depth = [3, 8, 36, 3]
# 殘差塊中使用到的卷積的輸出通道數
num_filters = [64, 128, 256, 512]
# ResNet的第一個模塊,包含1個7x7卷積,后面跟著1個最大池化層
self.conv = ConvBNLayer(num_channels=3, num_filters=64, filter_size=7, stride=2, act='relu')
self.pool2d_max = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
# ResNet的第二到第五個模塊c2、c3、c4、c5
self.bottleneck_block_list = []
num_channels = 64
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
num_channels=num_channels,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1, # c3、c4、c5將會在第一個殘差塊使用stride=2;其余所有殘差塊stride=1
shortcut=shortcut))
num_channels = bottleneck_block._num_channels_out
self.bottleneck_block_list.append(bottleneck_block)
shortcut = True
# 在c5的輸出特征圖上使用全域池化
self.pool2d_avg = paddle.nn.AdaptiveAvgPool2D(output_size=1)
# stdv用來作為全連接層隨機初始化引數的方差
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
# 創建全連接層,輸出大小為類別數目,經過殘差網路的卷積和全域池化后,
# 卷積特征的維度是[B,2048,1,1],故最后一層全連接的輸入維度是2048
self.out = nn.Linear(in_features=2048, out_features=class_dim,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Uniform(-stdv, stdv)))
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for bottleneck_block in self.bottleneck_block_list:
y = bottleneck_block(y)
y = self.pool2d_avg(y)
y = paddle.reshape(y, [y.shape[0], -1])
y = self.out(y)
return y
# 創建模型
model = ResNet()
# 定義優化器
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters(), weight_decay=0.001)
# 啟動訓練程序
iters, train_losses = train_pm(model, optimizer=opt)
# 畫出訓練程序中Loss的變化曲線
plt.figure()
plt.title("ResNet-train loss", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(iters, train_losses, color='red', label='train loss')
plt.grid()
plt.show()
四,幾種CNN的訓練效果比較
注:此訓練結果只能做參考,每個模型都只是只跑了20~40epochs,模型訓練并沒有完全穩定下來,且VGG訓練效果過差的原因應該是本人NVIDIA 1050Ti太不給力,只能把batch_size調為1才能讓模型跑起來,使得VGG訓練效果很差,按照理論來說,VGG的訓練準確率應超過90%,
各個模型訓練程序中的loss可視化如下列各圖所示:
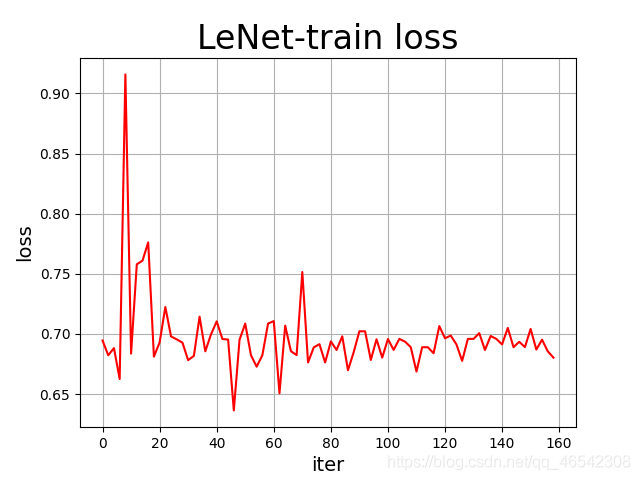
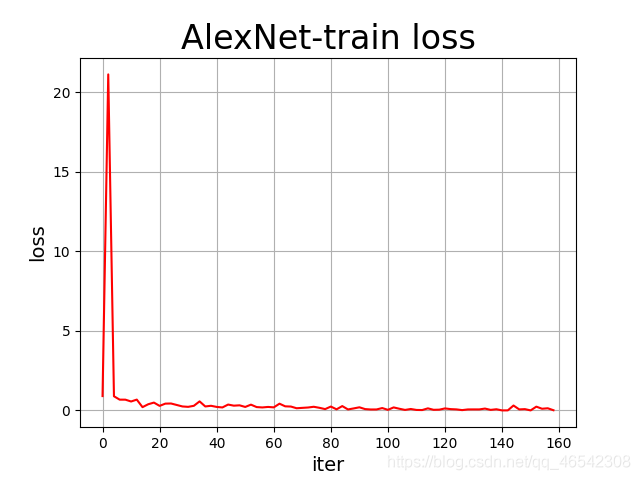
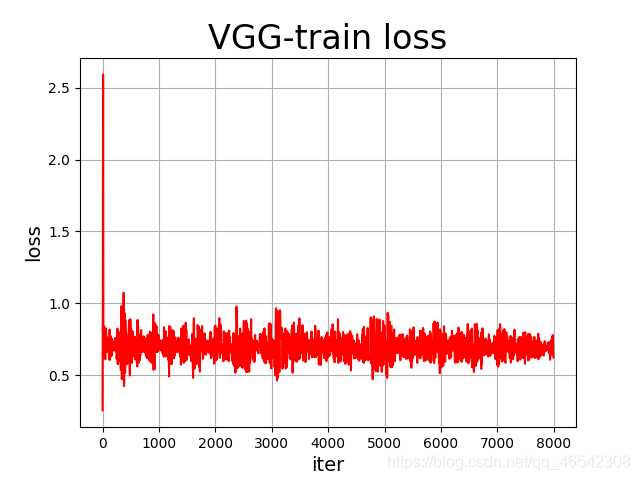
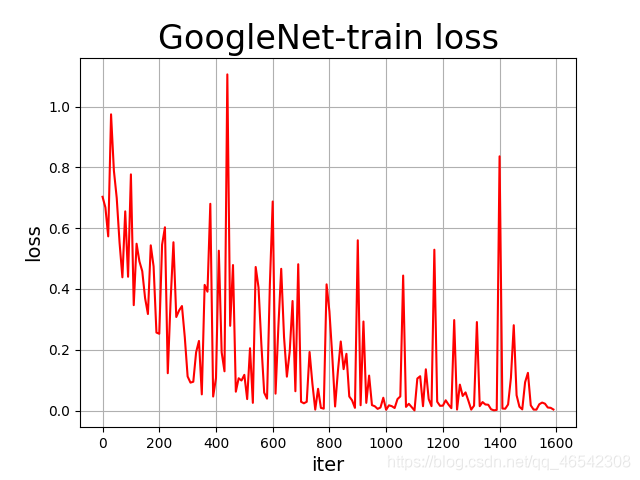
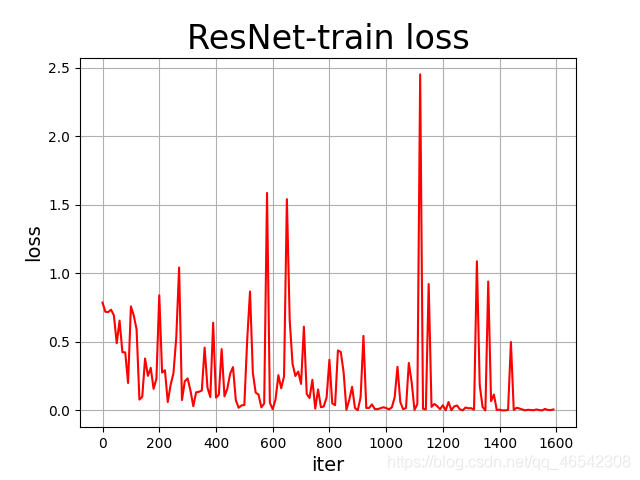
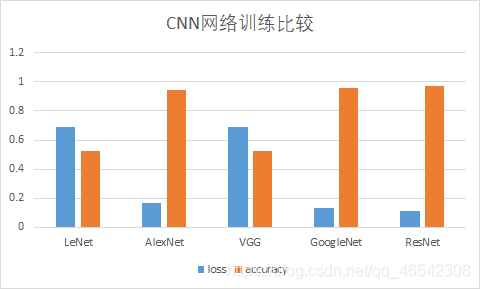
資料統計如下:
| loss | accuracy | |
| LeNet | 0.691962 | 0.524554 |
| AlexNet | 0.166790 | 0.941964 |
| VGG | 0.692041 | 0.527500 |
| GoogleNet | 0.132089 | 0.955000 |
| ResNet | 0.113273 | 0.970000 |
五,實際判斷效果實戰
上面模型評估的效果不錯,但輸入一張具體的圖片后究竟是否能判斷準確,以一張正常高度近視的圖片為例來測驗,代碼如下(直接加上面代碼下面即可):
# 定義檢測程序
model = AlexNet()
params_file_path = 'D:/Pycharm 2020/Projects/PaddlePaddle 2.1/眼疾圖片識別/palm.pdparams' # 路徑最后不能再加/
img_path = 'D:/Pycharm 2020/Data set/Eye disease recognition/verify/Severe myopia.jpg'
# 加載模型引數
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
# 灌入資料
model.eval()
img = cv2.imread(img_path)
img_transform = transform_img(img)
img_array = np.array(img_transform).astype('float32')
img_array = img_array.reshape((1,3,224,224))
# 模型反饋分類標簽的對應概率
results = model(paddle.to_tensor(img_array))
print(results)
Predicted_result = np.array(results).astype('float32')
Predicted_result = Predicted_result[0][0]
# 根據輸出值接近0與1的程度來進行分類
if abs(Predicted_result-1) < abs(Predicted_result-0):
print("本次識別分類的結果是:病理性近視,真實結果是:正常的高度近視")
elif abs(Predicted_result-1) > abs(Predicted_result-0):
print("本次識別分類的結果是:正常高度近視或一切正常,真實結果是:正常的高度近視")
else:
print('本次無法做出判斷,請再次強化神經網路訓練')結果顯示,能夠判斷準確,本文只拿了一個例子來說明,并不具有說服力,真正成熟還需要大量例子測驗檢驗,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291266.html
標籤:其他
上一篇:用c語言實作猜數字游戲
下一篇:影像基本操作