單鏈表的實作
- 為什么要寫單鏈表
- 代碼實作部分
- 總結和思考
為什么要寫單鏈表
之前我們寫過了一個資料結構——順序表,它可以在記憶體中連續的存放資料,但我們會發現,如果想要往其中插入一個資料,就必須要移動后面所有的資料,效率很低,于是就有了鏈表,鏈表在記憶體中是通過地址的方式來連接的,想要插入一個資料,不需要像順序表那樣復雜,只要將前一個節點的地址指向新的節點,然后將新的節點的地址指向下一個節點就可以了,具體實作我們看下面的代碼部分,
代碼實作部分
SList.h
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>
typedef int SLDataType;
typedef struct SListNode
{
SLDataType x;
struct SListNode* next;
}SListNode;
//值傳遞,不需要對外面頭結點進行改變
void SListPrint(SListNode* ps);
SListNode* SListFind(SListNode* phead, SLDataType x);
void SListInsertAfter(SListNode* pos, SLDataType x);
void SListEraseAfter(SListNode* pos);
int SListSize(SListNode* ps);
bool SListEmpty(SListNode* ps);
//地址傳遞,要對外面頭結點進行改變
void SListPopBack(SListNode** ps);
void SListPushBack(SListNode** ps, SLDataType x);
void SListPopFront(SListNode** ps);
void SListPushFront(SListNode** ps, SLDataType x);
void SListInsert(SListNode** pphead, SListNode* pos, SLDataType x); //在某個節點之前插入
void SListErase(SListNode** ps, SListNode* pos); //洗掉pos位置
🍎 這一部分有幾個要注意的點
1. 到底是傳一級指標還是傳二級指標?如果要改變傳入的頭節點(哪怕代碼中只有一小部分要改變頭結點,也要傳地址),就要傳地址,也就是二級指標,如果沒有任何地方需要改變頭結點,就值傳遞,也就是一級指標,這個點在下面的SList.c中也會具體講到,因為我當時寫代碼時我就在這個點上錯了好幾次
2.
typedef struct SListNode
{
SLDataType x;
struct SListNode* next;
}SListNode;
結構體里面一定要寫成struct SListNode這樣的寫法,不能寫成SListNode,雖然你typedef自己定義的是這個型別,但這樣就會造成一個先有雞還是先有蛋的問題,
SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"
//列印單聊表
void SListPrint(SListNode *ps)
{
while (ps)
{
printf("%d->", ps->x);
ps = ps->next;
}
printf("NULL\n");
}
//創建一個新的節點
SListNode* SListBuyNode(SLDataType x)
{
struct SListNode* n1 = (SListNode*)malloc(sizeof(SListNode));
if (n1 == NULL)
{
printf("creat fail\n");
exit(-1);
}
n1->x = x;
n1->next = NULL;
return n1;
}
//單鏈表尾刪
void SListPopBack(SListNode** ps)
{
assert(ps);
assert(*ps);
SListNode* tail = *ps;
SListNode* prev =*ps;
//單鏈表一個節點的情況
if ((*ps)->next == NULL)
{
free(*ps);
*ps = NULL;
}
//單鏈表中有節點的情況
else
{
while (tail->next) //注意這兒和列印的地方不一樣,這兒要這么寫,具體情況要具體分析,自己舉幾個列子就知道了
{
prev = tail;
tail = tail->next;
}
free(tail);
/*tail = NULL;*/
prev->next = NULL;
}
}
//單鏈表尾插
void SListPushBack(SListNode** ps, SLDataType x)
{
assert(ps);
SListNode* tail = *ps;
//沒有節點的情況
if (*ps == NULL)
{
*ps = SListBuyNode(x);
}
//有節點的情況
else
{
while (tail->next)
{
tail = tail->next;
}
tail->next = SListBuyNode(x);
}
}
//頭刪
void SListPopFront(SListNode** ps)
{
assert(ps);
assert(*ps);
//一個節點的情況
if ((*ps)->next == NULL)
{
free(*ps);
*ps = NULL;
}
//多個節點的情況
else
{
SListNode* next = (*ps)->next;
free(*ps);
*ps = next;
}
}
void SListPushFront(SListNode** ps, SLDataType x)
{
assert(ps);
//空節點的情況
if (*ps == NULL)
{
*ps = SListBuyNode(x);
}
//有節點的情況
else
{
SListNode* temp = *ps;
*ps = SListBuyNode(x);
(*ps)->next = temp;
}
//這樣寫也可以,因為if里面的情況包括在了else的情況里面,這樣寫可以減少代碼的重復,但上面一種寫法看起來更加的簡潔明了
//SListNode* temp = *ps;
//*ps = SListBuyNode(x);
//(*ps)->next = temp;
}
SListNode* SListFind(SListNode* phead, SLDataType x)
{
SListNode* cur = phead;
while (cur) //這兒一定要寫cur,不能寫cur->next,不然最后一個節點是進不去的
{
if (cur->x == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
return NULL;
}
//在某個節點之前插入
void SListInsert(SListNode** ps, SListNode* pos, SLDataType x)
{
assert(ps);
SListNode* tail = *ps;
SListNode* prev = *ps;
//空節點的情況
if (*ps == NULL) //注意這兒千萬不能寫成tail,然后對tail進行操作
{
*ps = SListBuyNode(x);
}
//一個節點的情況
else if ((tail)->next == NULL)
{
struct SListNode* newnode = SListBuyNode(x);
*ps = newnode;
newnode->next = tail;
}
//多個節點的情況
else
{
while ((tail) != pos)
{
prev = tail;
tail = tail->next;
}
/*prev->next = SListBuyNode(x);
prev->next->next = tail; */ //因為前面的SListBuyNode是你自己創建的一塊空間,這塊空間不與原鏈表完整的連接在一起,所以這句代碼會出問題
struct SListNode* newnode = SListBuyNode(x);
newnode->next = tail;
prev->next = newnode;
}
}
//void SListInsert(SListNode** pphead, SListNode* pos, SLDataType x)
//{
// assert(pphead);
// assert(pos);
//
// // 1、頭插
// // 2、后面插入
// if (*pphead == pos)
// {
// SListPushFront(pphead, x);
// }
// else
// {
// // 找到pos位置的前一個節點
// SListNode* prev = *pphead;
// while (prev->next != pos)
// {
// prev = prev->next;
// }
//
// SListNode* newnode = SListBuyNode(x);
// newnode->next = pos;
// prev->next = newnode;
// }
//}
//在某個節點之后插入
void SListInsertAfter( SListNode* pos, SLDataType x)
{
SListNode* newnode = SListBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
//在某個位置之后洗掉
void SListEraseAfter(SListNode* pos)
{
SListNode* nextnext = pos->next->next;
free(pos->next);
pos->next = nextnext;
}
//洗掉pos這個位置
void SListErase(SListNode** ps,SListNode* pos)
{
assert(ps);
assert(*ps);
//一個節點的情況 ,因為這個時候頭結點變化了,所以要用2級指標傳參,而且不能像前面一樣,把*ps賦值給tail然后對tail進行操作了,因為那樣tail是影響不到外面的
if ((*ps)->next == NULL)
{
free(*ps);
*ps = NULL;
}
//多個節點的情況
else
{
SListNode* cur = *ps; //這兒也是,不可以對*ps直接用,要保護好*ps的位置,因為你不需要對頭進行改變,如果用*ps的話,那么外面也會接著變的
SListNode *prev = *ps;
while (cur!= pos)
{
prev = cur;
cur = cur->next;
}
SListNode *next = cur->next;
free(cur);
prev->next = next;
}
}
//計算有多少個節點
int SListSize(SListNode* ps)
{
int num = 0;
while (ps != NULL)
{
num++;
ps = ps->next;
}
return num;
}
//判斷是否為空
bool SListEmpty(SListNode* ps)
{
return ps == NULL;
}
🥑這兒就重點講幾個寫的時候覺得要注意的版塊以及一些要注意的點
1. 注意while里面到底是寫ps,還是ps->next來作為判斷,這里就要看你的需求了,最好自己舉幾個列子代進去分析.
2.到底能不能對ps解參考或者說到底這段代碼傳參時要不要傳二級指標,這是很重要的一個注意點,下面我們來對比幾段代碼
void SListPopBack(SListNode** ps)
{
assert(ps);
assert(*ps);
SListNode* tail = *ps;
SListNode* prev =*ps;
//單鏈表一個節點的情況
if ((*ps)->next == NULL)
{
free(*ps);
*ps = NULL;
}
//單鏈表中有節點的情況
else
{
while (tail->next) //注意這兒和列印的地方不一樣,這兒要這么寫,具體情況要具體分析,自己舉幾個列子就知道了
{
prev = tail;
tail = tail->next;
}
free(tail);
/*tail = NULL;*/
prev->next = NULL;
}
}
可以看到這個代碼在一個節點時對ps解參考了,又因為是二級指標,所以改變ps也就對外面的頭節點進行了改變,所以這兒是要傳二級指標的,因為你對代碼中對頭節點發生了改變,再看else中的代碼,我們會發現這里面會沒有ps, 而是在代碼最前面把ps賦值給了tail,然后改變tail,是就相當于是值傳遞了,無論tail怎么變ps都是不會變的,ps不變,外面的頭節點也不會變,這不正是我們想要的嗎,因為這鏈表中有節點的情況下,我們不希望改變ps,也就是頭節點,所以萬萬不能寫成*ps ,一開始我寫的時候并沒有注意到這個點,下面來看下我們當時是怎么犯下這個錯誤的,
//洗掉pos這個位置
void SListErase(SListNode** ps,SListNode* pos)
{
assert(ps);
assert(*ps);
//一個節點的情況 ,因為這個時候頭結點變化了,所以要用2級指標傳參,而且不能像前面一樣,把*ps賦值給tail然后對tail進行操作了,因為那樣tail是影響不到外面的
if ((*ps)->next == NULL)
{
free(*ps);
*ps = NULL;
}
//多個節點的情況
else
{
SListNode *prev = *ps;
while (*ps!= pos)
{
prev = *ps;
*ps= (*ps)->next;
}
SListNode *next = (*ps)->next;
free(*ps);
prev->next = next;
}
}
寫完之后運行會發現輸出一串隨機值,而且后面的節點都沒了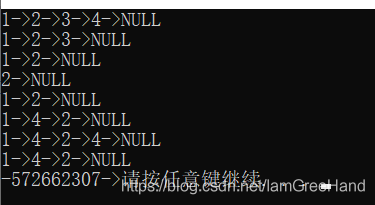
出現這種情況的原因正是因為在這個代碼中,你不需要改變頭節點,而你偏偏解參考了ps,且這個是地址傳遞,會影響到外面,因此頭節點一直被你竄改,也就不知道指向哪里了,所以會有隨機值,這里可以把*ps賦值給另外一個指標,又因為是值傳遞,所以那個指標的改變并不會影響頭節點
3. 連續寫兩個next時一定要注意,萬一出現問題,至于為什么,在代碼注釋中寫明了
//在某個節點之前插入
void SListInsert(SListNode** ps, SListNode* pos, SLDataType x)
{
assert(ps);
SListNode* tail = *ps;
SListNode* prev = *ps;
//空節點的情況
if (*ps == NULL) //注意這兒千萬不能寫成tail,然后對tail進行操作
{
*ps = SListBuyNode(x);
}
//一個節點的情況
else if ((tail)->next == NULL)
{
struct SListNode* newnode = SListBuyNode(x);
*ps = newnode;
newnode->next = tail;
}
//多個節點的情況
else
{
while ((tail) != pos)
{
prev = tail;
tail = tail->next;
}
/*prev->next = SListBuyNode(x);
prev->next->next = tail; */ //因為前面的SListBuyNode是你自己創建的一塊空間,這塊空間不與原鏈表完整的連接在一起,所以這句代碼會出問題
struct SListNode* newnode = SListBuyNode(x);
newnode->next = tail;
prev->next = newnode;
}
}
test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"
//void test1()
//{
// SListNode *n1 = (SListNode*)malloc(sizeof(SListNode));
// n1->x = 1;
// SListNode *n2 = (SListNode*)malloc(sizeof(SListNode));
// n2->x = 2;
// SListNode *n3= (SListNode*)malloc(sizeof(SListNode));
// n3->x =3;
// n1->next = n2;
// n2->next = n3;
// n3->next = NULL;
// SListPrint(n1);
// SListPopBack(&n1);
// SListPrint(n1);
// SListPopBack(&n1);
// SListPrint(n1);
//}
void test2()
{
struct SListNode* ps = NULL;
SListPushBack(&ps, 1);
SListPushBack(&ps, 2);
SListPushBack(&ps, 3);
SListPushBack(&ps, 4);
SListPrint(ps);
SListPopBack(&ps);
SListPrint(ps);
SListPopBack(&ps);
SListPrint(ps);
SListPopFront(&ps);
SListPrint(ps);
SListPushFront(&ps, 1);
SListPrint(ps);
SListNode* pos = SListFind(ps, 2);
SListInsert(&ps,pos,4);
SListPrint(ps);
pos = SListFind(ps, 2);
SListInsertAfter(pos, 4);
SListPrint(ps);
pos = SListFind(ps, 2);
SListEraseAfter(pos);
SListPrint(ps);
pos = SListFind(ps, 4);
SListErase(&ps,pos);
SListPrint(ps);
printf("%d\n", SListSize(ps));
printf("%d\n", SListEmpty(ps));
}
int main()
{
/*test1();*/
test2();
return 0;
}
💡至于測驗部分要注意的
1.要注意是傳地址還是傳值,如果要改變外面的頭節點的話就傳地址,不要的話就傳值,這一點在上面也強調過了,這里再重復強調下.
2. 要在某個位置洗掉或插入某個資料時,一定要先通過SListFind這個函式找到你要洗掉或插入的資料的那個位置的結構體,然后傳結構體過去,而不是傻乎乎的一直傳你要洗掉或插入的資料,以表明那個位置,
總結和思考
這次寫單鏈表并沒有上次寫順序表那么順利,主要是要不要解參考ps,也就是頭指標變化是要ps,傳地址,不需要改變頭指標時,萬萬不能ps,對其隨便改變,以后遇到這種類似的情況一定要相當注意;其次是命名方面,大部分命名還可以,但也有不足,比如ps這個就不好,可以命名成phead,這樣更加提醒自己是頭節點,同時這樣命名也更明了,總的來說,單鏈表在邏輯上并不難,細節很多,可能隨著更多的學習后會對單鏈表有一個更深入的理解.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291477.html
標籤:其他