目錄
一、大資料時代
二、TDengine設計思想
三、CAP理論和TDengine的特性
1、CAP理論
2、TDengine特性
四、資料模型
1、資料特點
2、超級表和表
3、資料查詢
a. 單表查詢
b. 多表聚合查詢
五、存盤模型
1、時序資料
2、標簽資料
3、元資料
一、大資料時代
大資料,已是技術發展中的重要領域,資料無處不在,支撐著大資料的中間件也不斷迭代更新,TDengine成為當中的優勢產品,生產應用場景不斷擴大,這一篇入門物聯網大資料:TDengine時序資料庫,從零學習了解大資料時代的解決方案!
二、TDengine設計思想
在生活中,各種IOT的聯網設備,比如智能手表、水表、汽車等,每時每刻都產生資料,這樣的資料是按時間順序的,
時間序列的資料一旦產生便是歷史不再發生變化,因此,資料寫入后不再有洗掉和修改的操作,因此,與MySQL等資料庫相比較,TDengine簡化了資料存盤的資料結構上,使得一些聚合查詢上可以通過預計算得到,更加高效,
TDengine最佳實踐說明,為每一個獨立產生資料 的IOT設備建立一張獨立的表,這樣保證了,不同設備之間存在時鐘不同步或者服務器網路延時的情況下,同一張表(來自同一個設備)的資料仍然可以保證是順序寫入的,
三、CAP理論和TDengine的特性
1、CAP理論
CAP理論在互聯網產品中是必然會應用到的理論,一致性Consistency、可用性Availability、磁區容錯性Partition tolerance,
一個分布式資料存盤系統最多只能同時滿足其中兩點,因此,分布式系統勢必只能在一致性和可用性中權衡做出選擇,
一致性:每個讀操作都可以得到一個最新寫的結果或者明確的錯誤回應,
可用性:每一個讀寫操作都可以得到一個非錯誤的回應(不保證最新),
磁區容忍性:無論節點間的網路問題導致了多少訊息丟失或者延遲到達,系統可以繼續運轉,
2、TDengine特性
TDengine在物聯網的場景下以犧牲部分功能支持的代價換來了超過10倍的性能提升,基于順序表結構的存盤,追加寫的插入,二分查找的查詢,結構化的定長資料,預計算的聚合結果等優化大大提升了時序資料存盤的讀寫性能,
TDengine支持按時間過期的方式洗掉陳舊的歷史資料避免無限量的資料增長,
四、資料模型
1、資料特點
研究發現,物聯網、車聯網、運維監測類資料還具有很多其他明顯的特征:
- 時間順序;
- 極少更新或洗掉;
- 資料量巨大;
- 資料高度結構化;
- 無需事務處理;
- 寫多讀少;
- 查詢分析更關注一段時間的趨勢,而不是某個特定時間點的值;
- 資料有保留期限;
- 需要各種統計和實時計算操作;
- 流量平穩,可根據設備數量和采集頻次預測出來,
根據這些資料的特征,TDengine采取經過特殊優化的存盤和計算設計來處理時序資料,系統處理能力很大提高,而且降低了系統運維的復雜度,
2、超級表和表
從上面介紹我們知道,TDengine為一個資料采集點建一個表,而且,這個表第一列必須是時間戳timestamp型別,
很明顯,表的數量巨大,難以管理,當應用需要做采集點之間的聚合操作,聚合的操作也變得復雜起來,為解決這個問題,TDengine引入超級表(Super Table,簡稱為STable)的概念,
超級表:同一型別資料采集點的集合,指某一特定型別的資料采集點的集合,同一型別的資料采集點的表結構是完全一樣的,而靜態屬性(也叫標簽,包括地點、設備的分組id等)不一樣,一個系統有N個不同型別的資料采集點,就需要建立個超級表(Super Table),
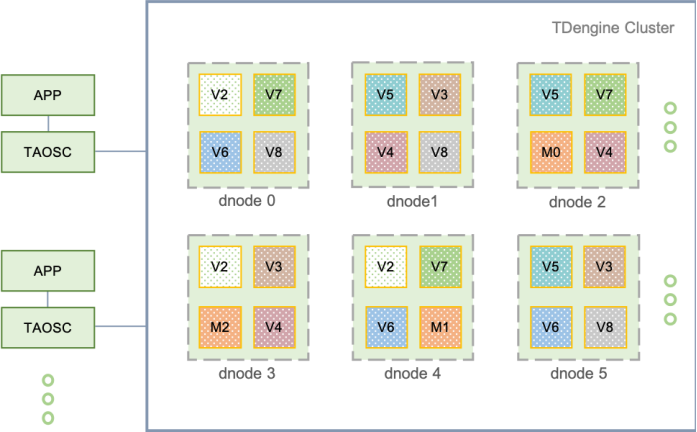
TDengine架構示意圖
主要邏輯單元:物理節點(pnode)、資料節點(dnode)、虛擬節點(vnode)、管理節點(mnode)、虛擬節點組(VGroup)、驅動程式(Taosc),
TDengine架構的詳細部分這里暫時不展開,不影響后面的閱讀,
3、資料查詢
TDengine提供豐富地查詢功能,除了常規聚合查詢,還提供對時序資料的視窗查詢、統計聚合等功能,查詢處理功能由客戶端、vnode、mnode節點協同完成,
a. 單表查詢
SQL陳述句決議和校驗作業在客戶端完成,決議SQL陳述句并生成抽象語法樹(AST),再進行校驗和檢查,以及向mnode請求查詢中指定表的元資料資訊,
然后,根據元資料資訊中的End Point,將查詢請求序列化后發送到該表所在的dnode,dnode接收識別出指向的vnode,將訊息轉發到vnode查詢執行佇列,dnode查詢執行佇列中的作業執行緒會等待vnode執行緒執行完成,再將查詢結果回傳給客戶端,
b. 多表聚合查詢
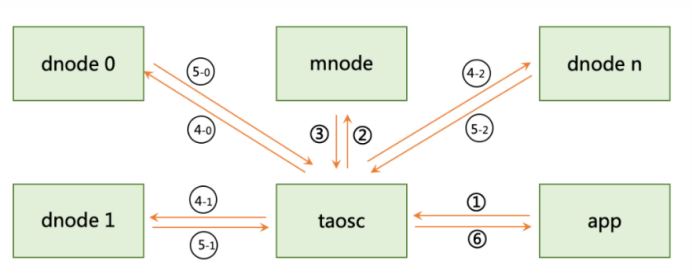
- APP應用將一個查詢條件發往系統;
- Taosc將超級表的名字發往mnode(管理節點);
- mnode將超級表擁有的vnode串列發回taosc;
- Taosc將計算的請求跟標簽過濾條件發往這些vnode對應的資料節點;
- 每個vnode先在記憶體中找出自己節點里符合的標簽過濾條件的表集合,然后掃描存盤的時序資料完成聚合計算,將結果回傳taosc;
- Taosc將多個資料節點回傳的結果做最后的聚合,回傳給應用,
這里涉及到的標簽資料、元資料的概念,可以繼續看以下內容,對于管理節點、資料節點的概念,屬于TDengine結構的具體內容,暫時不展開討論,
五、存盤模型
1、時序資料
存放在vnode,由data、head、last三個檔案組成,資料量大,不支持洗掉操作,update引數為1時才能更新操作,一個采集點一種表,一個時間段的資料是連續的,寫入是簡單追加操作,這樣對單個采集點的插入和查詢操作,性能達到最優,
2、標簽資料
存放在vnode的meta檔案,支持CRUD操作,資料量不大,N張表就有N條記錄,可以全記憶體存盤,
3、元資料
存放在mnode,包含系統節點、用戶、DB、Table Schema,支持CRUD,資料量不大,可全記憶體存盤,而且客戶端有快取,查詢量不大,
這一篇主要是學習大資料內容時,入門TDengine應用的簡單總結,整理了一些基本且關鍵知識,
如果覺得不錯歡迎“一鍵三連”哦,點贊收藏關注,評論提問建議,歡迎交流學習!一起加油進步,我們下篇見!
濤思資料TDengine官方檔案:https://www.taosdata.com/cn/documentation/
本篇內容首發我的CSDN博客:https://csdn-czh.blog.csdn.net/article/details/119089953
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291567.html
標籤:其他