目錄
1、訓練程序(創建分類器)
1.1、目標物件資料樣本
1.2、目標物件分類器配置
1.3、目標物件分類器訓練
1.4、目標物件分類器輸出和評估
2、分類與識別
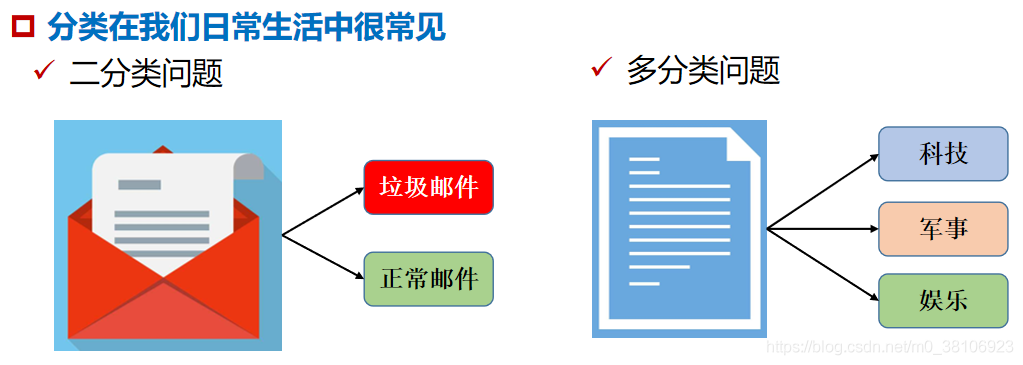
目標物件分類是指將未知樣品的形狀、顏色、紋理等顯著特征組成的向量與代表某一類樣本的特征向量(Feature Vector)進行比較,根據其匹配程度識別未知樣品類別歸屬的程序,
目標物件分類是機器視覺領域非常活躍的研究方向,在工業領域有極其廣泛的應用,例如對生產線上的零件按形狀、顏色等特征分揀,統計具有某種特征的零件,或通過辨別目標的類別進行質量檢測等,
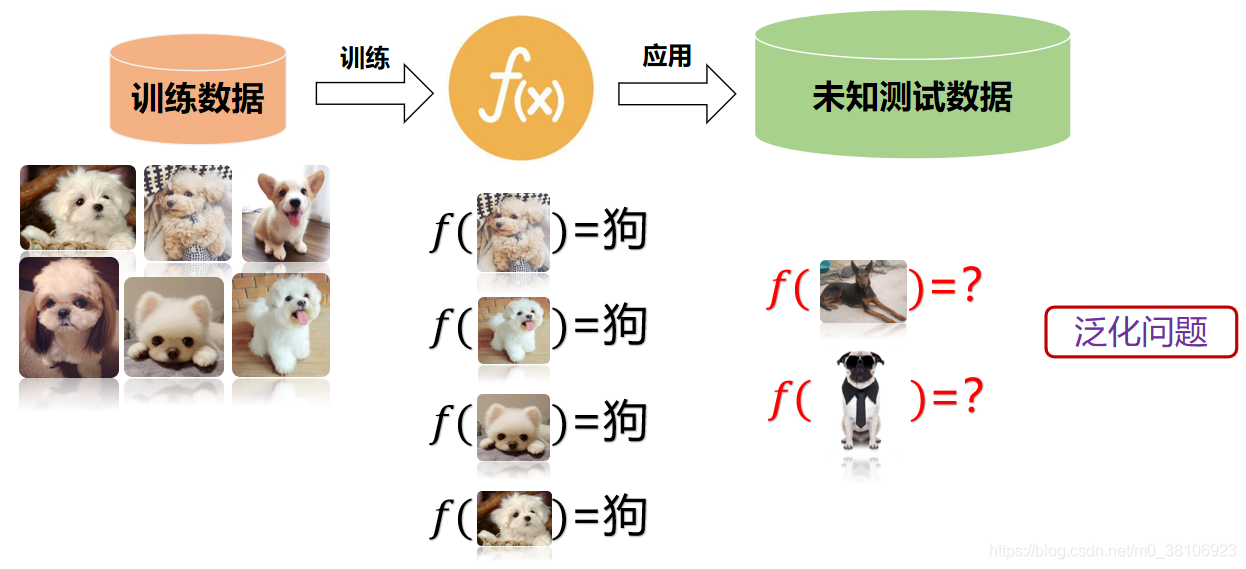
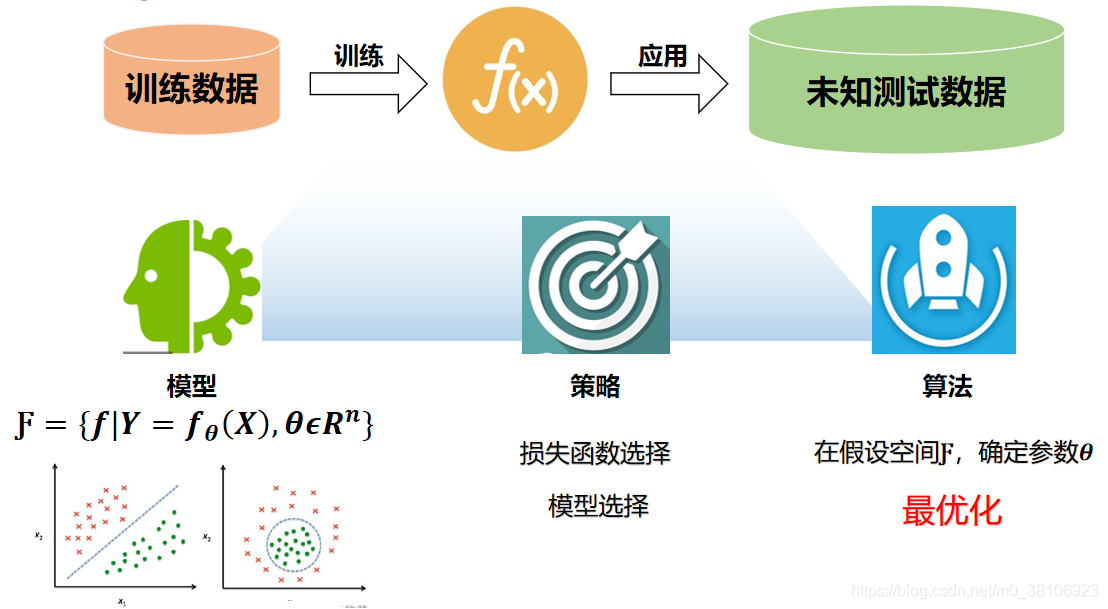
目標分類通常包括訓練(Training,也稱為學習)和分類(Classification)兩個程序,
- 訓練程序用于創建分類器(Classifier),包括樣本收集、分類器配置(確定特征向量和設定控制引數)、樣本訓練、分類器評測和保存等步驟,它既可以基于已有樣本集合(Sample Set)一次性完成,也可以通過不斷向樣本集添加樣本來漸進完成,訓練程序完成后會得到包含各樣本特征向量值及其類別歸屬資訊的分類器,一般來說,樣本集中屬于同一類別的樣本應具有相似的特征向量值,而類間距則應足夠大,
- 分類程序包括影像預處理、特征提取、特征計算、特征分類及分類結果評測等步驟,分類結束后,未知類別的樣本被設定某一類別標記,
下圖分別顯示了訓練和分類兩個階段的流程圖:
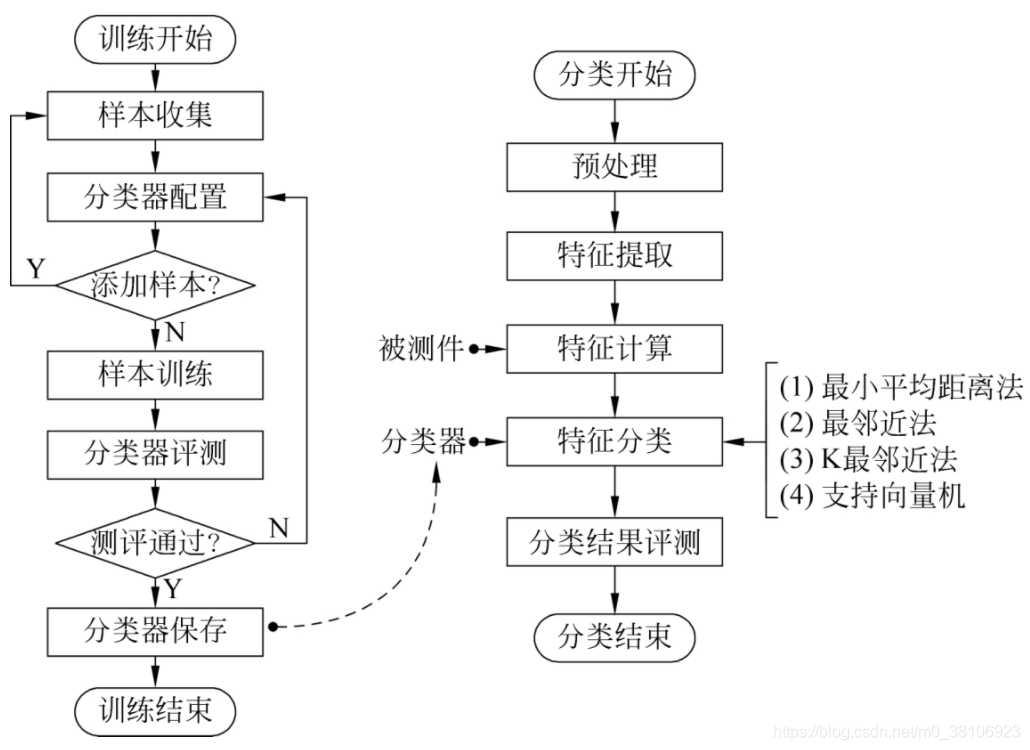
1、訓練程序(創建分類器)
訓練是目標分類的兩個程序之一,它主要用于生成包含各個樣本特征向量值及其類別歸屬資訊的分類器,分類器基于事先收集的訓練樣本集來創建,其中每個樣本的類別歸屬已知,樣本集確定后,就要對分類器進行配置,以確定訓練程序所依據的特征向量并設定控制引數,
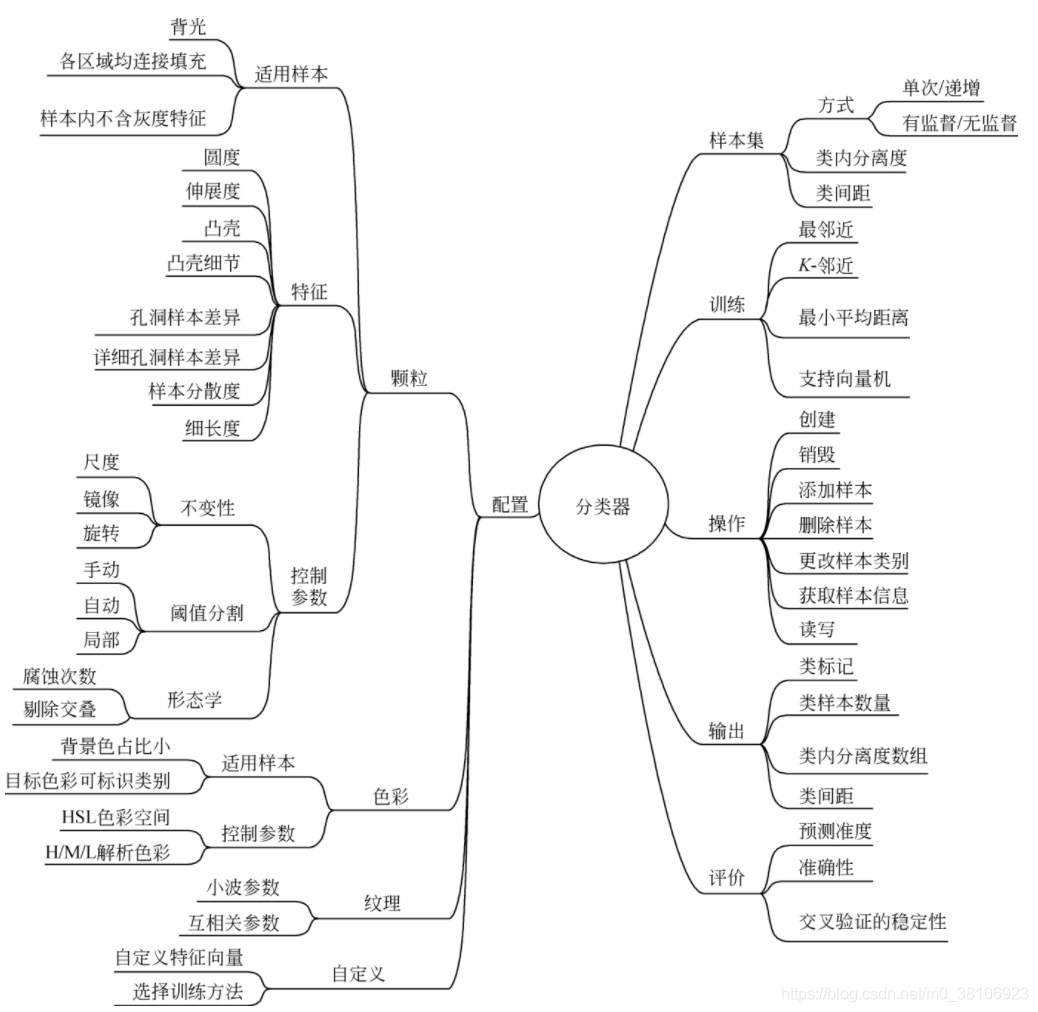
訓練時,系統會計算和記錄每個樣本的特征向量值,并對樣本進行分類,同時記錄樣本的類別資訊,訓練階段結束后,分類器可輸出各類中樣本的數量、類標記、類內分離度以及類間距等資訊,若要得知分類器的優劣,可通過計算分類器的可預測性(Predictability)、準確性(Accuracy)和交叉驗證的穩定性(CrossValidation Stability)指標對分類器進行定量評價,
下圖對分類器的創建和操作相關的關鍵資訊進行了匯總:
1.1、目標物件資料樣本
用于訓練的樣本集合中的樣本可以一次性收集完成,也可以漸進增減的方式來收集,

- 若收集的樣本類別歸屬已知,就可直接為樣本設定類標簽(Class Label),否則,則要通過聚類(Clustering)程序對樣本進行歸類,
- 若所有參與訓練的樣本都有類標簽,則稱訓練為有監督(Supervised)訓練;若樣本均無類標簽,則稱訓練為無監督(Unsupervised)訓練;
- 若樣本和其歸屬的類別資訊并不完全,則訓練程序稱為半監督(Semi-Supervised)訓練,例如只有部分樣本有明確的類標簽,或僅已知樣本可能得歸屬的幾種類資訊,但尚未確定每個樣本的類別歸屬等,
樣本集合的優劣可以通過類內分離度(Intraclass Deviation)和類間距(Interclass Distance)兩個指標來衡量,由于樣本集合中屬于同一類別的樣本一般具有相似的特征向量值,因此同一類內的樣本分離度應較小,而類與類之間的距離應足夠大,
1.2、目標物件分類器配置
確定了訓練的樣本資料集后,就需要對分類器進行配置,以確定訓練程序對樣本進行分類時所依據的特征向量,設定特征提取程序的引數,以及訓練程序是否要對樣本的尺度、旋轉和鏡像保持不變性等,
由于訓練程序和分類程序需要使用相同的特征向量,因此確定訓練樣本集特征向量的程序實際上就是為整個訓練和分類程序指定特征向量的程序,
對機器視覺分類系統來說,樣本特征向量通常由二值化后的顆粒特征、目標的顏色、紋理或其他自定義的特征構成,以顏色和紋理構建特征向量的分類器配置較為直接,
基于自定義特征向量的分類器需要事先從影像中提取特征,構建自定義的特征向量,基于顆粒特征向量的分類器則根據預定義的特征向量,在保持尺度、旋轉和鏡像不變的情況下,根據目標形狀對其進行分類,
以下以基于顆粒特征向量的分類器為例,介紹分類器的配置,
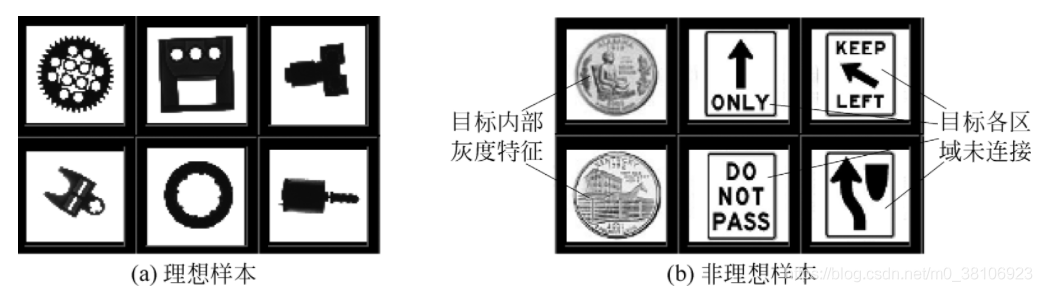
一般來說,基于顆粒特征向量的分類器能對滿足以下3個條件的樣本進行準確分類:
- 機器視覺光源為背光照射方式;
- 影像中樣本各部分相互連通;
- 影像中樣本各部分為實心填充,不含其他灰度特征,
下圖給出了基于顆粒特征向量進行分類的系統中理想樣本和非理想樣本的實體,
Nl Vision使用8個顆粒分析的特征來構建顆粒特征向量,以實作對樣本或被測目標按其形狀的訓練和分類,也就是說,Nl Vision基于顆粒特征向量的函式,內置了對目標按形狀進行分類的特征向量,
用于構建特征向量的8個顆粒特征如下表所示:
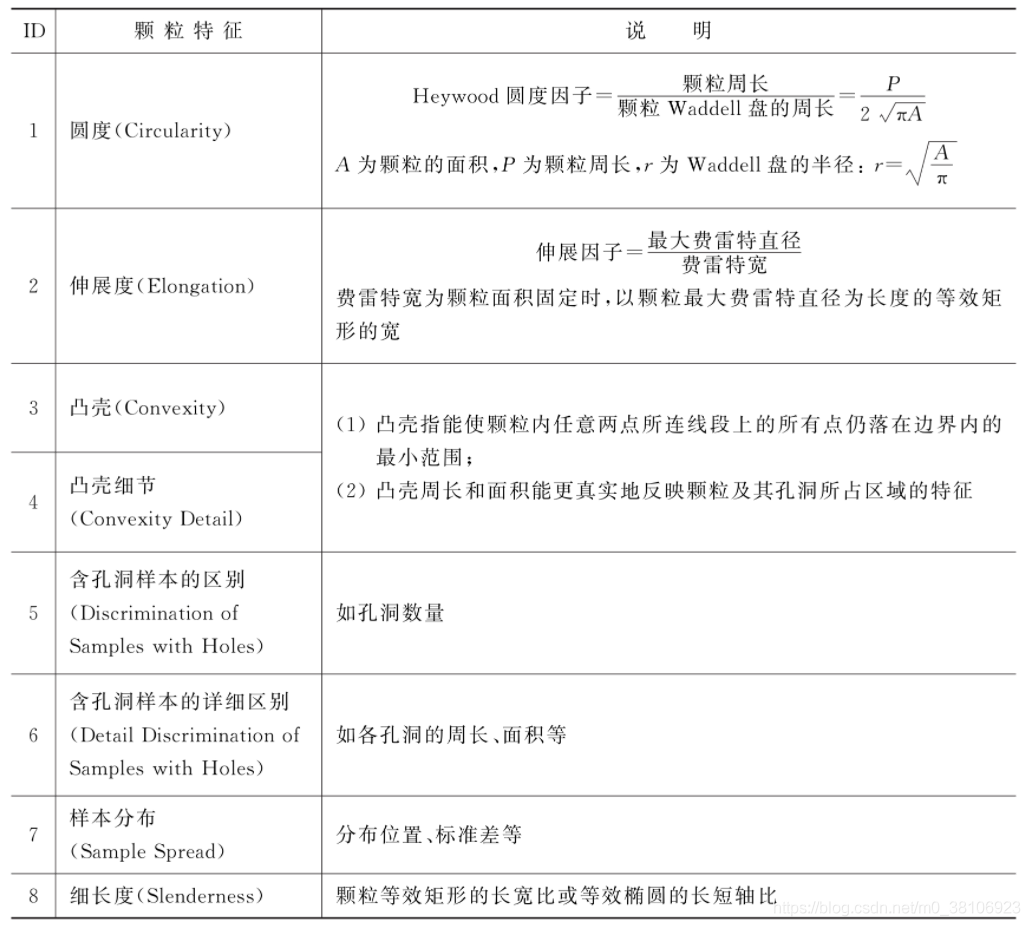
Nl Vision將基于顆粒特征創建的特征向量稱為形狀描述符(Shape Descriptor),根據訓練和分類程序對目標尺度不變性(Scale lnvariant)、旋轉不變性(RotationInvariant)或鏡像對稱不變性(Mirror Symmetry lnvariant)的要求,形狀描述符可以由上表中8個特征中的一個或多個構成,
Nl Vision基于形狀描述符進行樣本訓練或目標分類時,支持旋轉、尺度和鏡像對稱不變性,也就是說,訓練或分類程序僅根據與形狀相關的特征進行,即使目標已被旋轉、縮放或鏡像對稱,只要其形狀特征未發生變化,都能被正確訓練和分類,
下圖給出了一個基于形狀描述符的訓練或分類程序,支持尺度、旋轉和鏡像對稱不變性的示例,

1.3、目標物件分類器訓練
完成分類器的配置后,就可以對樣本集合中的各個樣本進行訓練,
訓練程序實際是計算各個樣本特征向量的值并按照分類方法對該值進行歸類的程序,
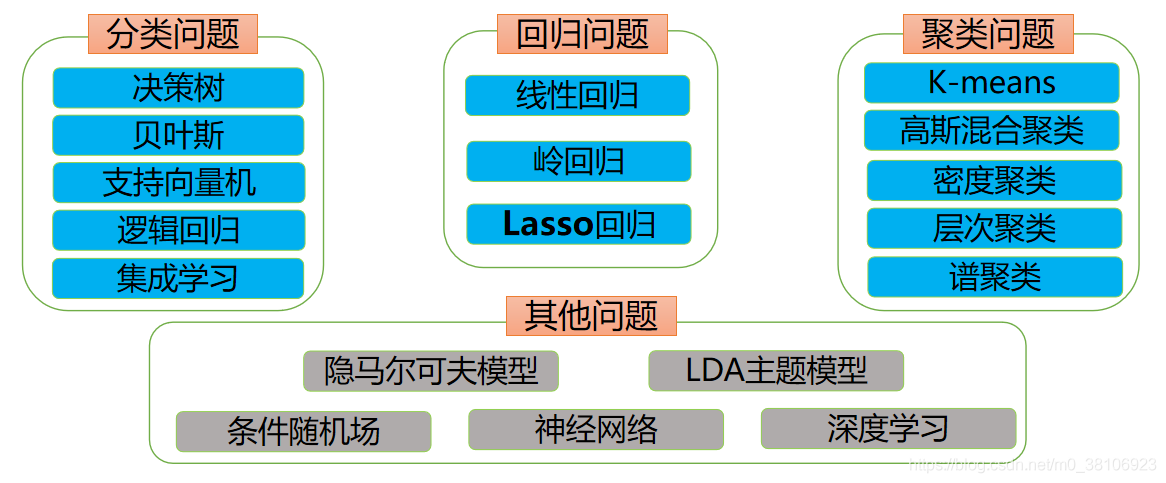
常用的分類方法包括最鄰近法(Nearest Neighbor)、K-鄰近法(K-Nearest Neighbor,KNN)、最小平均距離(Minimum Mean Distance)和支持向量機 (Support Vector Machine,SVM)4種,
1.4、目標物件分類器輸出和評估
根據以上幾節論述,在對分類器的訓練程序結束后,應確定下列與分類器和樣本相關的資訊:
- 樣本集中的樣本被訓練為哪幾類;
- 每類中樣本的數量;
- 每個類中樣本的分離度;
- 類與類的間距;
- 分類器所使用分類方法(引擎)的相關資訊等,
因此,正常情況下這些資訊都應在分類器訓練程序結束后作為分類器的輸出資訊提供給其他程式代碼使用,在程式運行程序中,這些資訊可由程式代碼參考分類器會話獲得,若要離線使用這些資訊,則需要將它們保存在分類器檔案中,以備后續讀取訪問,
可以基于對樣本的分類訓練結果來計算分類器對某一類的預測準度(Classifier Predictability)和分類準確性(Classifier Accuracy),并進而評價分類器的質量,分類器的預測準度是指將樣本分類到某一指定類別時樣本屬于該指定類的概率,

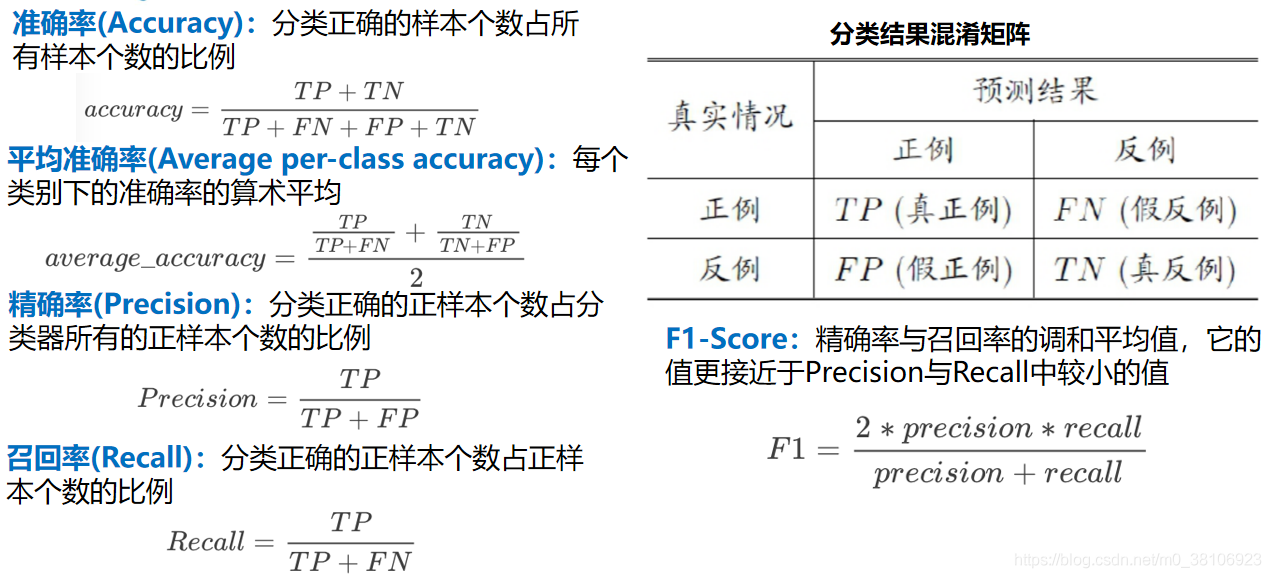
假定分類器使用的樣本集含有30個樣本,其中屬于A、B、C 3個類的樣本各占10個,若某一分類器對樣本集進行訓練分類后的分布如下表所示,則依據樣本分類分布表可計算分類器預測準度和分類準確性,
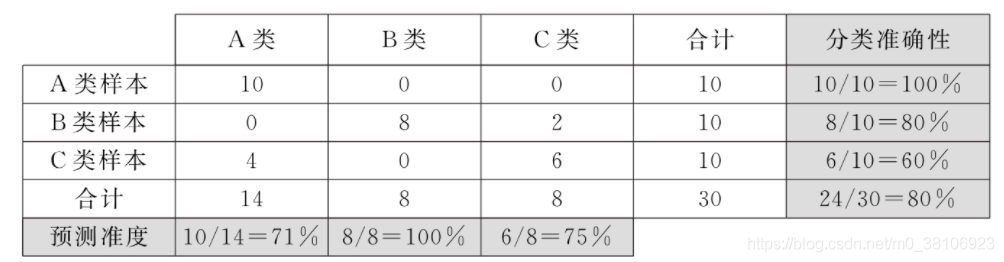
例如第一列中,分類至A類的14個樣本中有10個來自A類的正確分類樣本和4個來自C類的錯誤樣本,由此可知,分類器對A類的預測準度為71%,表中的各行表示屬于每類的樣本被分類器分至不同類的情況,例如表中第二行,10個屬于B類的樣本有8個被正確分類,2個被錯誤地分至C類,因此分類器對B類的分類準確性為80%,
2、分類與識別
基于樣本資料集完成訓練程序后,即可得到包含樣本數量、類別、特征以及分類方法等資訊的分類器,而使用該分類器,就能將未知類別的目標與分類器中的樣本進行比較,以實作目標的分類、統計或質量檢測等應用,
目標的歸類、分揀或統計的應用實作思路較為直接,一般使用訓練得到的顏色、形狀、紋理或自定義特征分類器對目標直接進行分類,并根據結果控制執行機構動作,例如,基于目標分類的質量檢測應用則不僅需要使用訓練得到的分類器對被測件進行分類識別,還要按照分類結果的可信度(ClassificationConfidence)和識別結果的可信度(ldentification Confidence)的大小來判斷被測件的合格性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291593.html
標籤:其他
上一篇:python-tensorflow和pytorch版本的手寫數字識別
下一篇:JVM運算元堆疊之堆疊頂快取