安裝環境運行大致步驟:
- Python安裝:選擇3.8,安裝教程具體可查看:https://blog.csdn.net/liming89/article/details/109632064?ops_request_misc=&request_id=&biz_id=102&utm_term=pycharm%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-7-.pc_search_result_before_js&spm=1018.2226.3001.4187
下載官網:https://www.python.org/downloads/
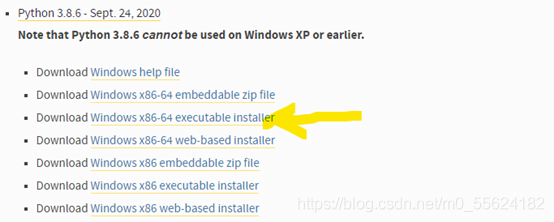
-
Pycharm 編輯器下載安裝:下載官網:
https://www.jetbrains.com/pycharm/download/#section=windows
安裝教程與Python安裝教程在一起 -
環境變數配置:配置教程:
https://www.cnblogs.com/huangbiquan/p/7784533.html -
安裝Anaconda:選擇Anaconda3,安裝教程具體可查看:
https://blog.csdn.net/u010210864/article/details/94580873
下載官網:https://www.anaconda.com/products/individual
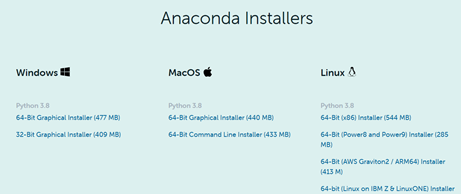
-
按步驟4教程安裝Tensorflow:
-
試運行CNN訓練mnist資料集的代碼:
# -*- coding: utf-8 -*-
# 使用卷積神經網路訓練mnist資料集
import gzip
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Reshape
import numpy as np
from sklearn.metrics import classification_report
import datetime
'''
# 裝載資料集(從網上下載)
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
'''
# 裝載資料集(本地匯入)
def load_data():
path = r"E:\PythonProject\CNN\MNIST_data\mnist.npz"
f = np.load(path)
train_images, train_labels = f['x_train'], f['y_train']
test_images, test_labels = f['x_test'], f['y_test']
f.close()
return (train_images, train_labels), (test_images, test_labels)
def load_data1():
path = "E:\\PythonProject\\CNN\\MNIST_data\\"
files = [path + 'train-images-idx3-ubyte.gz', path + 'train-labels-idx1-ubyte.gz',
path + 't10k-images-idx3-ubyte.gz', path + 't10k-labels-idx1-ubyte.gz']
# print(file)
with gzip.open(files[0], 'rb') as ip:
# 6萬張訓練圖片
train_images = np.frombuffer(ip.read(), np.uint8, offset=16)
train_images = train_images.reshape(60000, 28, 28)
with gzip.open(files[1], 'rb') as lp:
train_labels = np.frombuffer(lp.read(), np.uint8, offset=8)
with gzip.open(files[2], 'rb') as ip2:
# 1萬張測驗圖片
test_images = np.frombuffer(ip2.read(), np.uint8, offset=16)
test_images = test_images.reshape(10000, 28, 28)
with gzip.open(files[3], 'rb') as lp2:
test_labels = np.frombuffer(lp2.read(), np.uint8, offset=8)
# print(train_image)
return (train_images, train_labels), (test_images, test_labels)
if __name__ == '__main__':
# (train_images, train_labels), (test_images, test_labels) = load_data()
# print(len(train_labels))
(train_images, train_labels), (test_images, test_labels) = load_data1()
print(len(train_labels))
# 資料預處理
train_images = train_images.reshape((len(train_images), 28, 28, 1))
#此處采用float32是權衡了時間何空間開銷,float64精度高,但資料集會大大占用消耗的記憶體, 像素值映射到 0 - 1 之間
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((len(test_images), 28, 28, 1))
test_images = test_images.astype('float32')/255
train_labels = to_categorical(train_labels) # one-hot編碼
test_labels = to_categorical(test_labels)
# 添加模型
model1 = tf.keras.models.Sequential()
#第1層卷積,卷積核大小為3*3,32個,28*28為待訓練圖片的大小
model1.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model1.add(MaxPooling2D((2, 2)))
# 第2層卷積,卷積核大小為3*3,64個,激活函式relu
model1.add(Conv2D(64, (3, 3), activation='relu'))
model1.add(MaxPooling2D((2, 2)))
# 第3層卷積,卷積核大小為3*3,64個
model1.add(Conv2D(64, (3, 3), activation='relu'))
# 添加分類器
model1.add(Flatten())
model1.add(Dense(64, activation='relu'))
model1.add(Dense(10, activation='softmax'))
# 模型編譯
model1.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 保存模型資料到.\results\tb_results\路徑下
log_dir = '.\\results\\tb_results\\' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# 訓練模型
model1.fit(train_images, train_labels, epochs=5, batch_size=128, callbacks=([tensorboard_callback]))
# 在測驗集上對模型進行評估
test_loss, test_acc = model1.evaluate(test_images, test_labels)
print(test_loss, test_acc)
# print(model1.summary())
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291607.html
標籤:AI