計算機是如何存盤字符的?
? 大學都學過計算機相關的基礎知識,計算機只能計算二進制資料,因為二進制表示起來最方便,計算機電子元器件表示兩個狀態很簡單,比如高壓和低壓,對應的就是1和0,如果設計出10種狀態,那么計算機的設計會相當復雜,
? 計算機想存盤我們現實世界的字符,也就是我們常用的漢子或者字母,最簡單的方法就是把每個字符都對應一個數字,數字都能轉為二進制,這樣相當于計算機間接的存盤了字符,實際上,計算機科學家們也的確是這么做的,由此,便誕生了各種字符集,各個國家的字符都有對應的數字,
都有哪些字符集
? 計算機發明之初,沒有考慮那么多,作為現代計算機的發源地,當時也只考慮了美國的需求,所以只需要128個字符,稱之為ASCII編碼或者ASCII字符集(叫法不同而已,但是我覺得叫字符集更準確),128個字符,如果用數字一一對應,一共只需7位二進制數字,計算機存盤的最小單位是byte,即8位,ASCII字符集把最高位設定為0,用剩下的7位來表示字符,下圖便展示了ASCII中,數字與字符的對應關系,
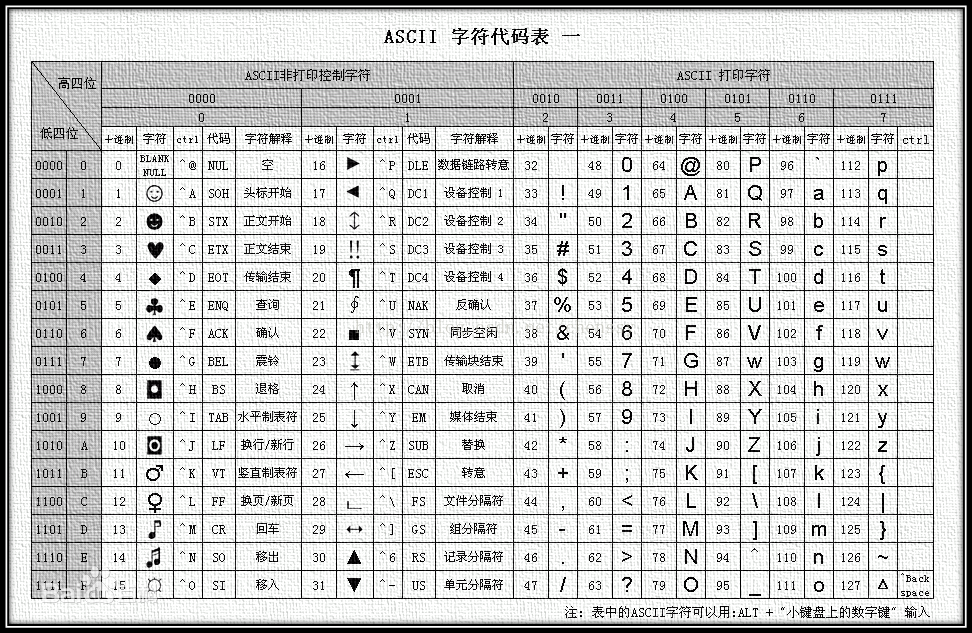
? 圖中把ASCII字符集分為了兩大部分,列印和非列印,列印部分好解釋,就是會輸出在顯示設備上的,可以看看我們的鍵盤上,一般也都會有這些字符,非列印部分更多的是控制目的,比如NUL表示空字符,\n表示換行,\r表示回車等,
? 對于美國來說,ASCII是夠用了,但是其他很多國家顯然就不夠用了,下面簡單說說一些常見的,ISO 8859-1和Windows-1252,這兩個都加入了西歐字符,兩者基本一樣,ISO 8859-1號稱是用于西歐國家的標準字符集,但是Windows-1252更常用些,
? 中文的第一個標準字符集是GB2312,有大約7000個漢字和一些罕用詞和繁體字,其使用兩個位元組表示漢字,GBK建立在GB2312的基礎上,并向下兼容,共計包含了21000個漢字,其中包含了繁體字,GB18030進一步增強了GBK,同樣可以向下兼容,共包含了76000個字符,其中有很多少數民族字符,以及中日韓統一字符,但是兩個位元組已經表示不了GB18030中的所有字符了,GB18030使用了長編碼,有的字符是兩個位元組,有的是四個位元組,兩個位元組的編碼中,表示范圍和GBK一樣,除了以上表示中文的字符集外,還有個Big5,是針對繁體字的,廣泛應用于灣灣省和香港那邊,
? 前面說了這么多,是不是覺得很麻煩,不同的國家地區,還得用不用的字符集,前面講到的所有字符集統稱為非Unicode字符集,為了解決每個國家不同字符集間的不兼容現狀,便有了Unicode字符集,它做了一件事,就是給世界上所有字符都分配了一個唯一的數字編號,有110多萬,但大部分都在0x0000~0xFFFF之間,即65536個,
? **這些數字編號一般用16進制表示,但是要注意,只是分配了個數字編號,并不像上面的非Unicode字符集一樣,這個數字也表示字符對應的二進制,**至于Unicode字符集中,每個字符對應的二進制是多少,有幾種不同的方案,主要有UTF-8、UTF-16、UTF-32,
? UTF-32最簡單,也符合我們的正常邏輯,數字編號的二進制形式,就是這個字符對應的二進制,缺點就是,每個字符都用四個位元組表示,顯然對于常用字符這是非常浪費的,UTF-16和GB18030一樣,有個用兩個位元組有的用四個位元組,UTF-8使用最廣,其使用的是變長位元組,每個字符使用的位元組個數與Unicode中的數字編號有關,編號小的用的位元組就少,編號大的用的位元組就多,位元組個數從1~4不等,
亂碼怎么恢復
? 看到這里,為什么亂碼相信你肯定知道了,無非就是使用了不同的字符集,導致決議錯誤,那么該怎么恢復亂碼呢?如果你知道原編碼方式最好,直接切換成對應的字符集即可,比如在一些可以切換編碼方式的文本編輯器里、HTML的原資訊設定、IDE的設定等,
? 但是如果不知道的話,也沒什么太好的方式,只能一個個嘗試了,我們可以寫個簡單的小程式,通過遍歷常見字符集,來試著決議出亂碼的原有格式,以Java為例:String newStr = new String(str.getBytes(charsets[i]),charsets[j]),這句代碼的意思就是:假設亂碼str原來是charsets[j]編碼的,被錯誤決議為charsets[i]編碼的,在嘗試前,切記要對原檔案做備份,因為多次錯誤的決議和轉換,可能很難再恢復成正常的字符了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291644.html
標籤:其他