調度nodeName、nodeSelector、親和性、污點、容忍、洗掉節點
- 1、什么是調度?
- 2、nodeName
- 3、nodeSelector
- (1)節點親和性
- (2)pod親和與反親和
- 4、Taints(污點)
- (1)NoSchedule+標簽選擇
- (2)容忍
- 1.NoSchedule
- 2.NoExecute
- 5、cordon、drain、delete
- (1)cordon隔離
- (2)drain驅逐
- (3)delete洗掉
1、什么是調度?
調度器通過 kubernetes 的 watch 機制來發現集群中新創建且尚未被調度到 Node 上的 Pod,調度器會將發現的每一個未調度的 Pod 調度到一個合適的 Node 上來運行,
kube-scheduler 是 Kubernetes 集群的默認調度器,并且是集群控制面的一部分,kube-scheduler 是很靈活的,在設計上是允許你自己寫一個調度組件并替換原有的 kube-scheduler,
在做調度決定時需要考慮的因素包括:單獨和整體的資源請求、硬體/軟體/策略限制、親和以及反親和要求、資料局域性、負載間的干擾等等,
默認策略可以參考:https://kubernetes.io/docs/reference/scheduling/policies/
2、nodeName
nodeName 是節點選擇約束的最簡單方法,但一般不推薦,如果 nodeName 在 PodSpec 中指定了,則它優先于其他的節點選擇方法,直接就指定在哪個節點調度,
使用 nodeName 來選擇節點的一些限制:
(1)如果指定的節點不存在,
(2)如果指定的節點沒有資源來容納 pod,則pod 調度失敗,
(3)云環境中的節點名稱并非總是可預測或穩定的,
編輯pod.yaml 檔案
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: server2 %尋找node是server2的節點
[root@server2 ~]# kubectl apply -f pod.yaml %應用,創建pod
pod/nginx created
[root@server2 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 5s
[root@server2 ~]# kubectl get pod -o wide %調度到了server2(server2是master,一般不用它作業的,原因后面講)
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 19s 10.244.179.115 server2 <none> <none>
%實驗完成,洗掉pod
3、nodeSelector
nodeSelector 是節點選擇約束的實用形式,它的原理是匹配某些特殊的標簽,滿足該條件的節點就可以被調度過去,
創建目錄
編輯pod.yaml檔案
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test %該pod的標簽是env=test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector: %選擇標簽disktype=ssd的node
disktype: ssd
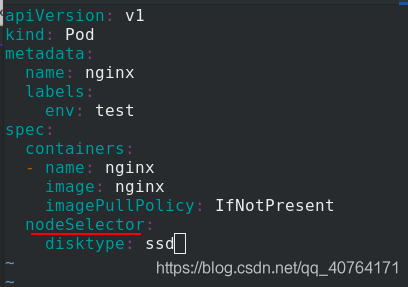
應用pod.yaml檔案,創建pod,查看狀態為pending,因為三個節點都沒有ssd這個標簽,
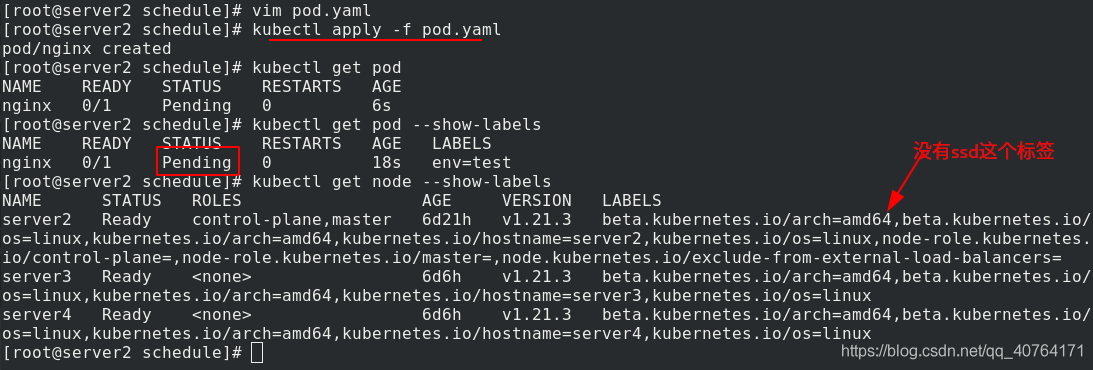
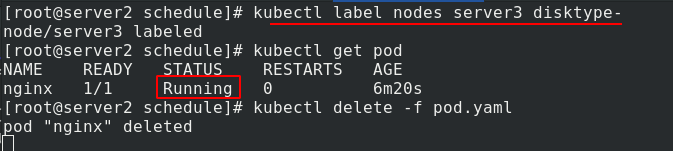
給server3加標簽disktype=ssd,再次查看pod的狀態,已經running了
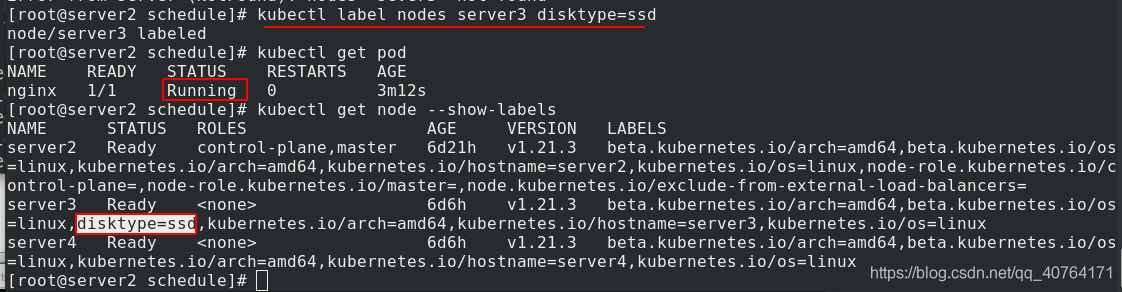
洗掉標簽后,查看pod的狀態,還是running,這是因為,pod已經調度過去了,洗掉標簽也不影響
洗掉pod,凈化環境
(1)節點親和性
nodeSelector 提供了一種非常簡單的方法來將 pod 約束到具有特定標簽的節點上,親和與反親和功能極大地擴展了你可以表達約束的型別,你可以發現規則是“軟”/“偏好”,而不是硬性要求,因此,如果調度器無法滿足該要求,仍然調度該 pod,
節點親和中的三個引數:
(1)requiredDuringSchedulingIgnoredDuringExecution 必須滿足
(2)preferredDuringSchedulingIgnoredDuringExecution傾向滿足
(3)IgnoreDuringExecution 表示如果在Pod運行期間Node的標簽發生變化,導致親和性策略不能滿足,則繼續運行當前的Pod,
nodeaffinity還支持多種規則匹配條件的配置如下:
| 表示 | 含義 |
|---|---|
| In | label 的值在串列內 |
| NotIn | label 的值不在串列內 |
| Gt | label 的值大于設定的值,不支持Pod親和性 |
| Lt | label 的值小于設定的值,不支持pod親和性 |
| Exists | 設定的label 存在 |
| DoesNotExist | 設定的 label 不存在 |
參考:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
編輯pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx
affinity:
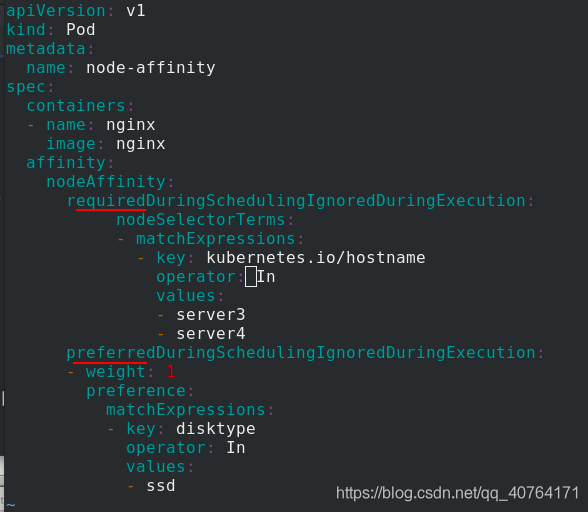
nodeAffinity: %node親和性
requiredDuringSchedulingIgnoredDuringExecution: %必須滿足該模塊的條件
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In %以下條件在串列內,才可調度
values: %調度的節點必須是server3或server4
- server3
- server4
preferredDuringSchedulingIgnoredDuringExecution: %優先匹配滿足該模塊條件的節點,不滿足也沒事
- weight: 1 %權重為1
preference:
matchExpressions:
- key: disktype %匹配條件是disktype這個鍵值為ssd
operator: In
values:
- ssd
應用,創建pod,由于現在server3和server4都沒有ssd這個標簽,且都滿足硬性條件,所以隨機調度到了server3

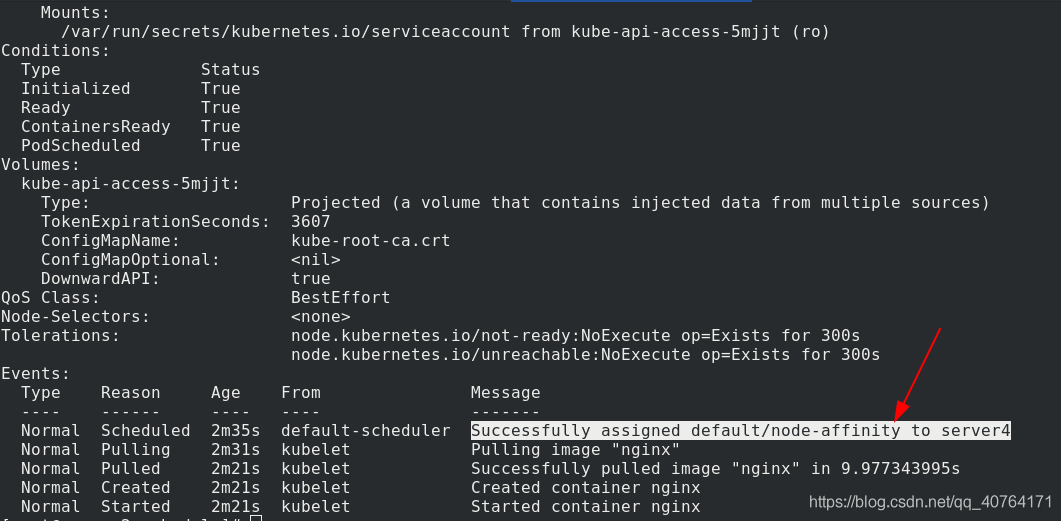
洗掉上個pod,給server4添加disktype=ssd這個標簽,再次創建pod,查看,調度到了server4

查看詳細資訊也可以看到,該pod由于node的親和性,調度到了server4
(2)pod親和與反親和
除了上面的節點的親和性,也可以使用 pod 的標簽來約束,而不是使用節點本身的標簽,來允許哪些 pod 可以或者不可以被放置在一起,
pod 親和性和反親和性:
(1)podAffinity 主要解決POD可以和哪些POD部署在同一個拓撲域中的問題(拓撲域用主機標簽實作,可以是單個主機,也可以是多個主機組成的cluster、zone等,)即pod2想和某些特殊的pod1在同一個節點作業
(2)podAntiAffinity主要解決POD不能和哪些POD部署在同一個拓撲域中的問題,它們處理的是Kubernetes集群內部POD和POD之間的關系,即pod2想避開某些特殊的pod1所在的那個節點
Pod 間親和與反親和在與更高級別的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用時,它們可能更加有用,可以輕松配置一組應位于相同定義拓撲(例如,節點)中的作業負載,Pod 間親和與反親和需要大量的處理,這可能會顯著減慢大規模集群中的調度,
首先純凈實驗環境

編輯 pod2.yaml 檔案
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels: %nginx這個pod的標簽是app=nginx
app: nginx
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1
kind: Pod
metadata:
name: mysql
labels: %mysql這個pod的標簽是app=mysql
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env: %環境變數
- name: "MYSQL_ROOT_PASSWORD"
value: "westos"
affinity:
podAffinity: %pod親和性
requiredDuringSchedulingIgnoredDuringExecution: %必須滿足以下條件
- labelSelector:
matchExpressions:
- key: app %標簽app=nginx
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
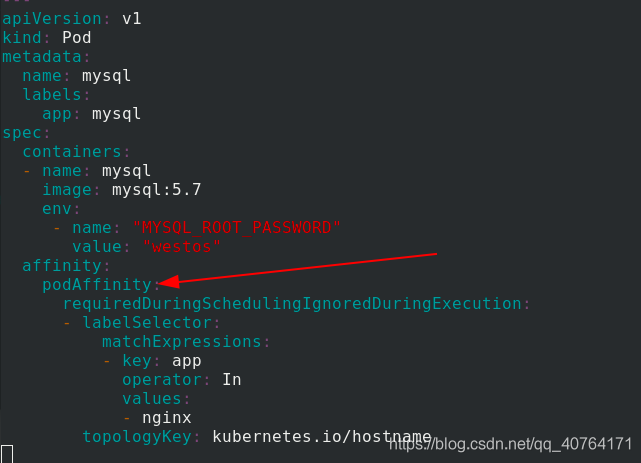
應用pod2.yaml 檔案,創建pod,查看兩個pod,他們在同一個節點上,因為mysql專門匹配有nginx這個標簽的pod,nginx去哪個節點,mysql就去哪個節點,生產環境中也確實有這種需要,nginx服務和mysql資料庫要放在一起,
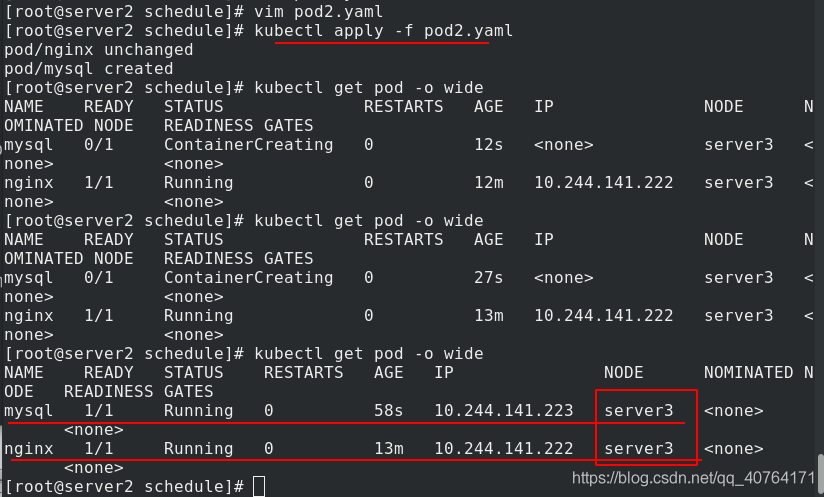
下面測驗pode的反親和,修改pod2.yaml 檔案,由原來的pod親和變為pod反親和
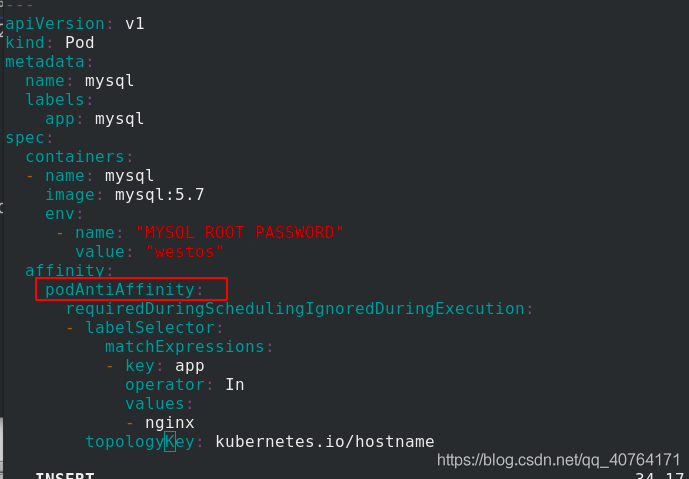
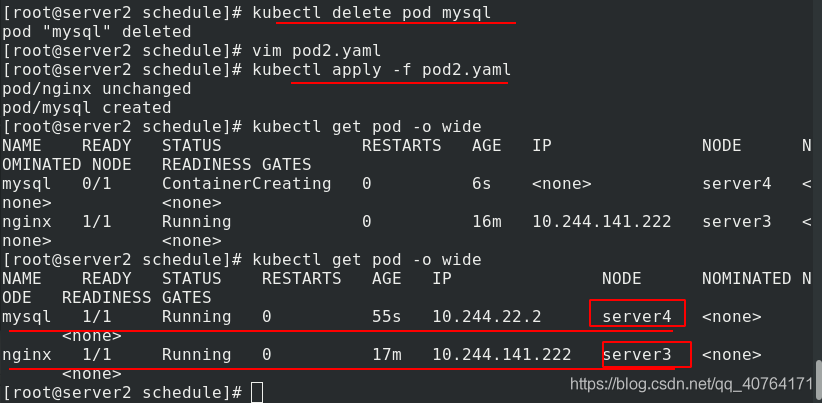
應用pod2.yaml 檔案,創建pod,可以看到,mysql和nginx專門不在同一個節點上
4、Taints(污點)
NodeAffinity節點親和性,是Pod上定義的一種屬性,使Pod能夠按我們的要求調度到某個Node上,而Taints則恰恰相反,它可以讓Node拒絕運行Pod,甚至驅逐Pod,
Taints(污點)是Node的一個屬性,設定了Taints后,Kubernetes是不會將Pod調度到這個Node上的,于是Kubernetes就又給Pod設定了個屬性Tolerations(容忍),只要Pod能夠容忍Node上的污點,那么Kubernetes就會忽略Node上的污點,就能夠(不是必須)把Pod調度過去,
舉個不太恰當的例子:假如一個人有犯罪前科(Taints)來應聘,我是飯店老板,那么我可能不喜歡他,甚至驅逐他,不讓他在這作業等等,但是如果我比較大度(Tolerations),我不計較你的前科(Taints),那我就可以把你留在我這當服務生,
可以使用命令 kubectl taint 給節點增加一個 taint:
kubectl taint nodes node1 key=value:NoSchedule 創建
kubectl describe nodes server1 |grep Taints 查詢
kubectl taint nodes node1 key:NoSchedule- 洗掉
其中[effect] 可取值: [ NoSchedule | PreferNoSchedule | NoExecute ]
| 引數 | 含義 |
|---|---|
| NoSchedule | POD 不會被調度到標記為 taints 的節點 |
| PreferNoSchedule | NoSchedule 的軟策略版本(最好不要調度到標記為 taints 的節點) |
| NoExecute | 該選項意味著一旦 Taint 生效,如該節點內正在運行的 POD 沒有對應 Tolerate 設定,會直接被逐出 |
注意上面的nodename調度方式無視污點,nodename的優先級最高,nodename說去哪里就去哪里
(1)NoSchedule+標簽選擇
前面說到server2是集群的master,默認不會work只會調度,原因就在與server2有污點,NoSchedule
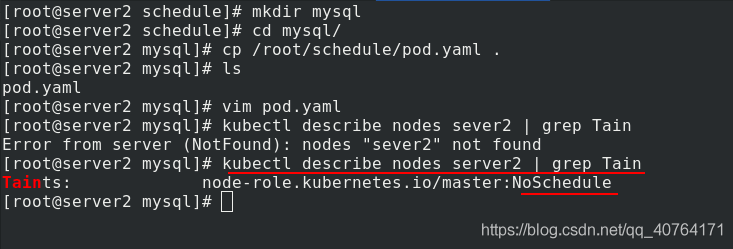
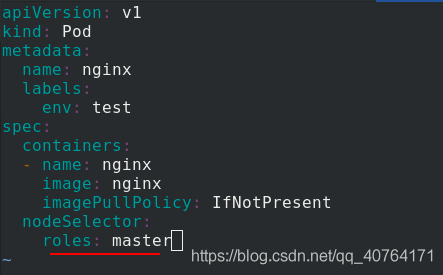
編輯pod.yaml 檔案
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
roles: master %匹配標簽roles=master的節點
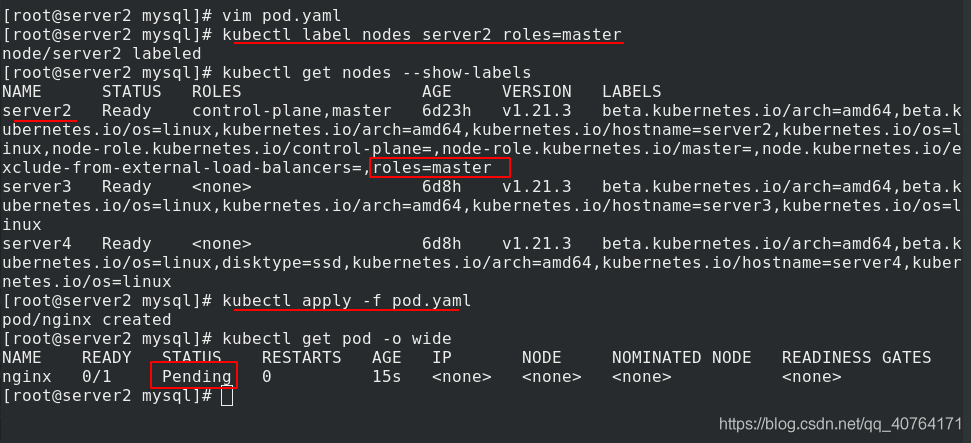
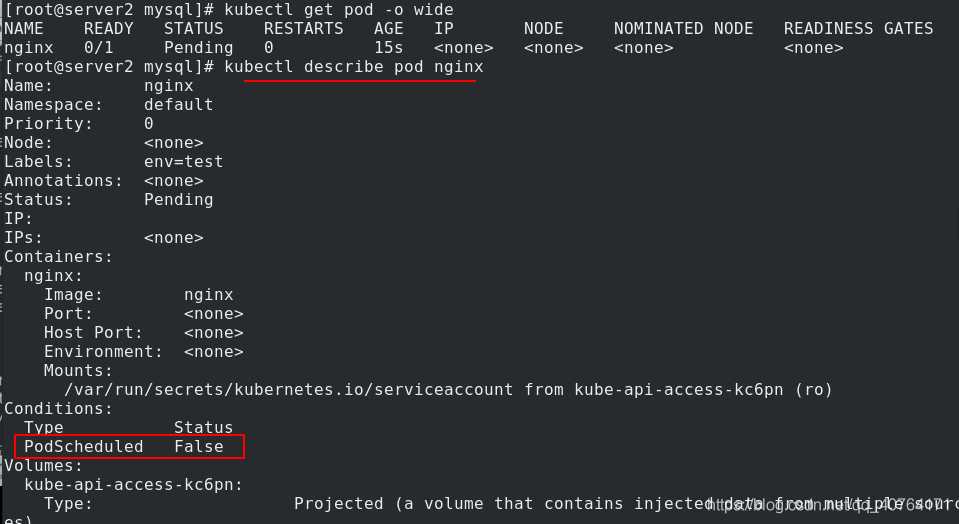
給server2添加roles=master標簽,應用pod.yaml 檔案,創建pod,查看pod的狀態為pending,原因是創建pod時,要尋找標簽是roles=master的節點,找到了server2,但是server2上有污點,NoSchedule,pod就無法調度到server2,那么pod只能等待,說明標簽選擇無法覆寫污點
顯示調度失敗
(2)容忍
tolerations中定義的key、value、effect,要與node上設定的taint保持一致:
(1)如果 operator 是 Exists ,value可以省略,
(2)如果 operator 是 Equal ,則key與value之間的關系必須相等,
(3)如果不指定operator屬性,則默認值為Equal,
還有兩個特殊值:
(1)當不指定key時,再配合Exists 就能匹配所有的key與value ,可以容忍所有污點,
(2)當不指定effect時 ,則匹配所有的effect,
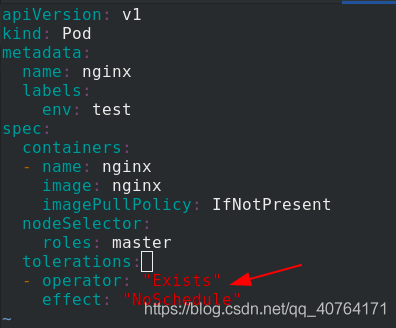
1.NoSchedule
修改pod.yaml 檔案
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
roles: master
tolerations: %容忍NoSchedule這個污點,即裝作看不見NoSchedule這個污點
- operator: "Exists"
effect: "NoSchedule"
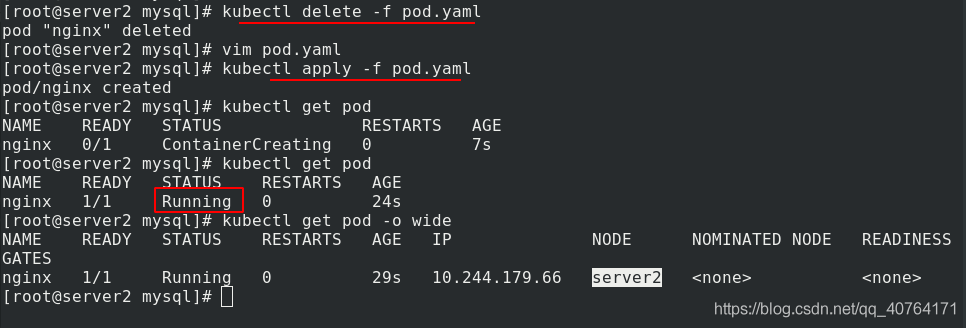
洗掉上個的pod,重新應用pod.yaml 檔案,查看狀態,running了
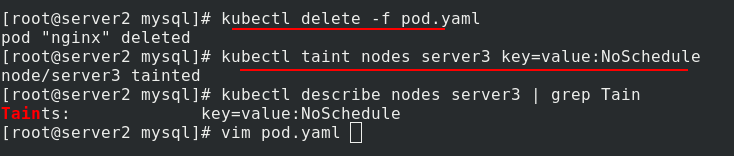
洗掉上個的pod,給server3也添加一個污點,NoSchedule,
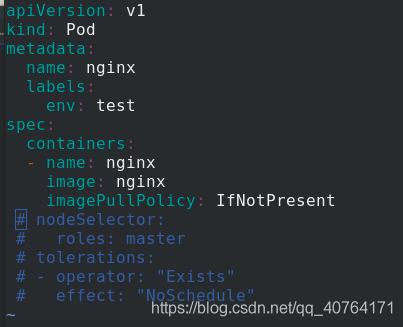
修改pod.yaml 檔案,注釋掉匹配標簽模塊和容忍模塊,
應用pod.yaml 檔案,節點只能去server4,因為server2和server3都有污點
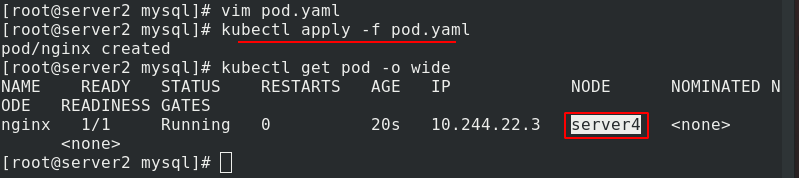
2.NoExecute
NoExecute:該選項意味著一旦 Taint 生效,如該節點內正在運行的 POD 沒有對應 Tolerate 設定,會直接被逐出,被驅逐到其他node節點,
洗掉以前的pod

修改pod.yaml 檔案
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd %匹配標簽disktype=ssd
tolerations:
- operator: "Exists"
effect: "NoSchedule" %容忍NoSchedule這個污點
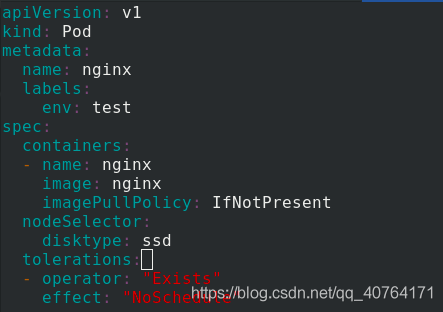
查看標簽,之前給server4添加了ssd這個標簽,應用pod.yaml 檔案,pod被調度到server4
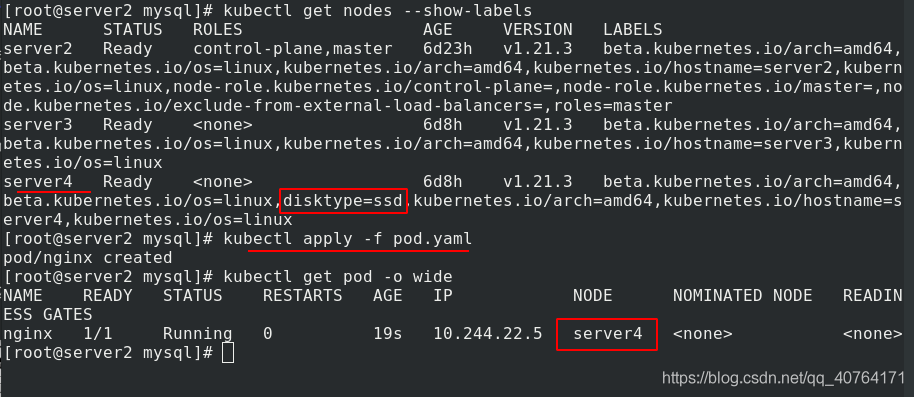
給server4添加污點key=value:NoExecute,可以看到添加完成后,之前在server4上的pod立馬被驅離了
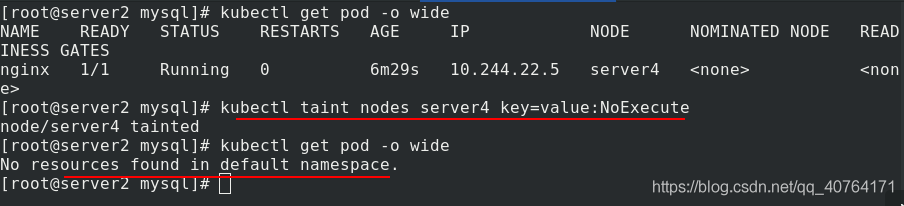
當pod.yaml 檔案改為
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd %匹配標簽disktype=ssd
tolerations:
- operator: "Exists"
effect: "NoExecute" %容忍NoExecute這個污點
為Pod設定容忍后,應用pod.yaml 檔案,server4又可以運行Pod了
測驗完成后,取消污點kubectl taint nodes server4 key:NoExecute-
5、cordon、drain、delete
影響Pod調度的指令還有:cordon、drain、delete,后期創建的pod都不會被調度到該節點上,但操作的暴力程度不一樣,逐漸遞增,
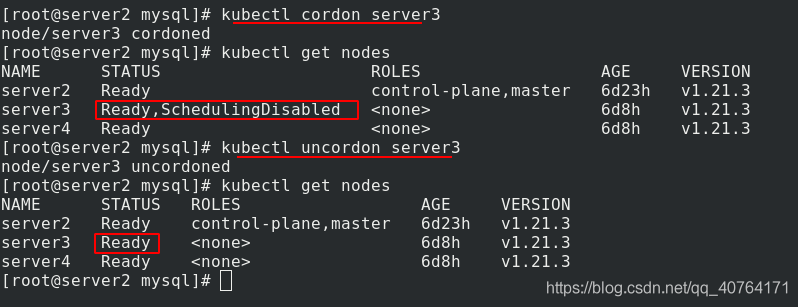
(1)cordon隔離
cordon 停止調度,影響最小,只會將node調為SchedulingDisabled,新創建pod,不會被調度到該節點,節點原有pod不受影響,仍正常對外提供服務,
隔離server3后,狀態為SchedulingDisabled,新的pod不會被調度到server3,
取消隔離后,恢復正常
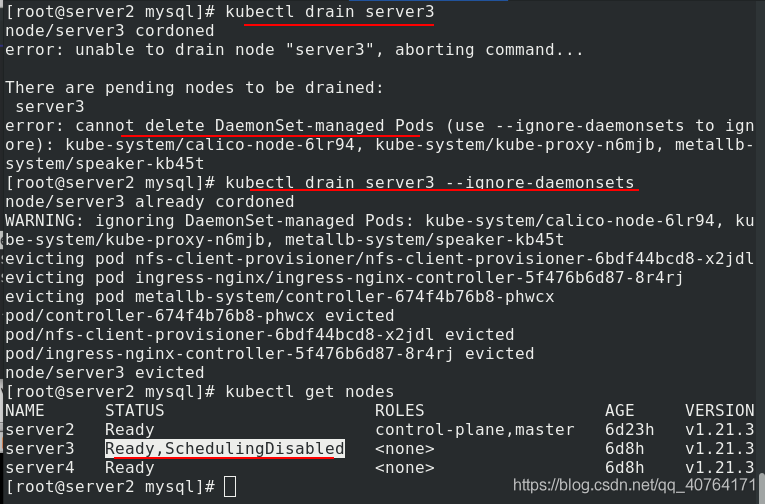
(2)drain驅逐
drain 驅逐節點:
首先驅逐node上的已有pod,在其他節點重新創建,然后將節點調為SchedulingDisabled,
驅逐server3時,顯示錯誤,是因為有daemonset這個控制器,他的特點就是每個節點上部署一個,和驅逐策略沖突,所以我們需要忽略daemonset產生的pod,把其他pod驅逐,查看狀態會顯示SchedulingDisabled,同時可以查看pod的數量銳減
kubectl uncordon server3 %恢復
(3)delete洗掉
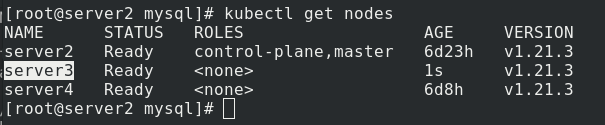
delete 洗掉節點,最暴力的一個,首先驅逐node上的pod,在其他節點重新創建,然后,從master節點洗掉該node,master失去對其控制,
kubectl delete node server3 %洗掉server3
可以看到洗掉后,連接直接拒絕了

如要恢復調度,需進入node節點server3,重啟kubelet服務,重新連接master
[root@server3 ~]# systemctl restart kubelet %基于node的自注冊功能,恢復使用
server3恢復正常
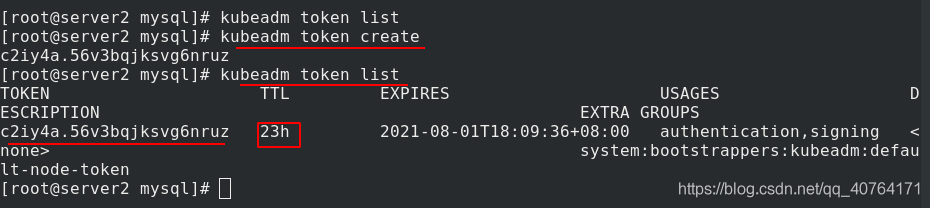
補充:上面講了已經連接過的節點被洗掉后,如何恢復,下面講解如何添加一個新的節點,
我們第一想法是使用剛開始初始化后產生的token令牌添加新的節點,但是那個token只有24小時的有效期,所以需要重新建立token,如下圖,建立token,查看,有效期確實為24小時,然后把這個新的token給準備添加的節點,加入集群,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291745.html
標籤:其他
上一篇:Docker網路