基于DCGAN的動漫頭像生成
資料
- 資料集:動漫圖庫爬蟲獲得,經過資料清洗,裁剪得到動漫頭像,解析度為3 * 96 * 96,共5萬多張動漫頭像的圖片,從知乎用戶何之源處下載,
- 生成器:輸入為隨機噪聲,輸出為歸一化到[-1,1]之間的原圖大小,
- 判別器:輸入圖片,輸出為圖片為真實的概率,范圍為[0,1],
模型
DCGAN目前是GAN在實際工程實踐中被采用最多的衍生網路,為了提高影像生成質量,增強其穩定性,許多研究學者嘗試進行優化,并提出了四點設計原則:
(1)卷積層代替池化層
池化操作會使卷積核在縮小的特征圖上覆寫了更大的影像視野,但是對網路性能的優化效果較小,使用卷積層代替池化層,讓網路自動選擇篩去不必要資訊,學習上采樣和下采樣程序,提高計算機運算能力,
(2)去掉全連接層
全連接層一般添加在網路的末層,用于將影像特征進行連接,可以減少特征資訊的損失,但是由于其引數過多,會產生過擬合、計算速度降低等問題,由于面部影像特征提取的感受野范圍較小,不需要提取全圖特征,所以為了避免上述問題,本專案中網路模型去掉了全連接層,
(3)批量歸一化
本課題中的生成器和判別器都是五層神經網路,每一層輸入的資料的復雜度都會逐層遞增,使輸出資料的分布發生變化,對網路引數的初始化和BP演算法的性能產生影響,將資料進行批量歸一化(Bach Normalization,BN),可以使輸出的資料服從某個固定資料的分布,把資料特征轉換為相同尺度,從而加速神經網路的收斂速度,
(4)激活函式
激活函式(Activation Function)具有連續可導的特性,可以使神經網路進行非線性變化,通過對數值優化來學習網路引數,提升網路的擴展性,本課題的生成器和判別器均為五層網路模型,計算量較大,每一層的激活函式選擇需要滿足高計算效率和訓練穩定兩點,其導函式的值域分布合理,
生成器
DCGAN生成器模型如下圖,共五層,本專案中生成器輸出通道數ngf默認為64,所以其中的通道數都減半,其他一樣,從輸入的100維的隨機噪聲,不斷上采樣反卷積操作,最終得到生成的假圖片,
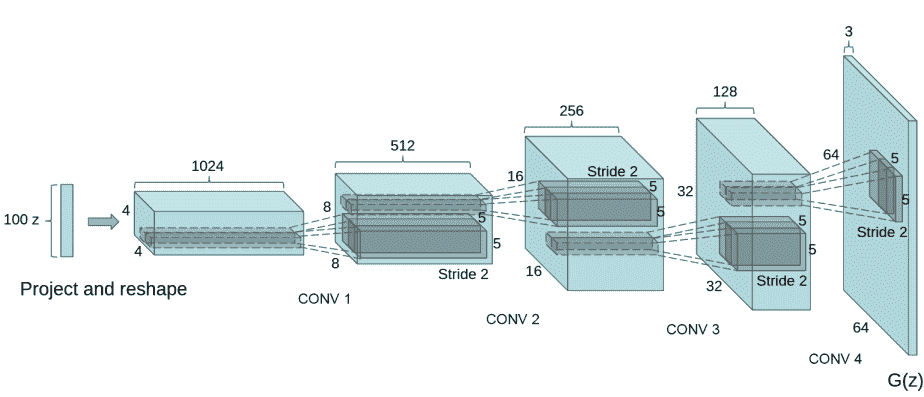
判別器
生成器整體框架逆過來,其中反卷積變為卷積,卷積核大小,步長等設定一樣,除最后一層外ReLU激活函式變為LeakyReLU,不斷下采樣,最后通過sigmoid函式輸出真實樣本概率值,也就是一個二分類網路,
損失函式
BCELoss是CrossEntropyLoss的一個特例,用于計算輸入 input 和標簽 label 之間的二值交叉熵損失值,
由于生成網路和判別網路的輸出層的激活函式分別為Than函式和Sigmoid函式,兩者都是S型函式,其函式特性會導致反向傳播演算法收斂速度降低,使用BCELoss函式后,解決了因sigmoid函式導致的梯度消失問題,
criterion = t.nn.BCELoss().to(device)
# 訓練判別器,分開訓練
## 盡可能的把真圖片判別為正確
error_d_real = criterion(output, true_labels)
error_d_real.backward()
## 盡可能把假圖片判別為錯誤
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
# 訓練生成器
error_g = criterion(output, true_labels)
優化器
選用Adam優化程式調整超引數,它結合了 AdaGrad 和 RMSProp 演算法最優的性能,不僅可以計算每個引數的自適應學習率,還可以通過訓練資料的不斷迭代使網路權重自動更新,相較于其他幾種演算法而言Adam演算法實作簡單、對計算機資源占用率較低,收斂速度也更快,
實驗
從https://pan.baidu.com/s/1eSifHcA 提取碼:g5qa下載資料(275M,約5萬多張圖片),把所有圖片保存于data/face/目錄下,這是因為用了默認的ImageFolder讀取資料集,標簽為faces,不需要重寫datasets類,
data/
└── faces/
├── 0000fdee4208b8b7e12074c920bc6166-0.jpg
├── 0001a0fca4e9d2193afea712421693be-0.jpg
├── 0001d9ed32d932d298e1ff9cc5b7a2ab-0.jpg
├── 0001d9ed32d932d298e1ff9cc5b7a2ab-1.jpg
├── 00028d3882ec183e0f55ff29827527d3-0.jpg
├── 00028d3882ec183e0f55ff29827527d3-1.jpg
├── 000333906d04217408bb0d501f298448-0.jpg
├── 0005027ac1dcc32835a37be806f226cb-0.jpg
訓練程序
(1)訓練判別器
- 先固定生成器
- 對于真圖片,判別器的輸出概率值盡可能接近1
- 對于生成器生成的假圖片,判別器盡可能輸出0
(2)訓練生成器
- 固定判別器
- 生成器生成圖片,盡可能使生成的圖片讓判別器輸出為1
(3)回傳第一步,回圈交替進行
本次訓練程序,每1個batch訓練一次判別器, 每5個batch訓練一次生成器,可以嘗試改變訓練比例,改變兩者的學習率實驗,觀察哪種效果最好,
在訓練判別器時,需要對生成器生成的圖片用detach()操作進行計算圖截斷,避免反向傳播將梯度傳到生成器中,因為在訓練判別器時,我們不需要訓練生成器,也就不需要生成器的梯度,
在訓練判別器時,需要反向傳播兩次,一次是希望把真圖片判定為1,一次是希望把假圖片判定為0.也可以將這兩者的資料放到一個batch中,進行一次前向傳播和反向傳播即可,但是研究發現,分兩次的方法更好,
對于假圖片,在訓練判別器時,希望判別器輸出為0;而在訓練生成器時,希望判別器輸出為1,這樣實作判別器和生成器互相對抗提升,
測驗
python main.py generate --gpu --vis False --netd-path checkpoints/netd_199.pth --netg-path checkpoints/netg_199.pth --gen-img result.png --gen-num 64
使用最后一次迭代的到的訓練網路進行驗證,生成器網路為netd_199.pth,判別器網路為netg_199.pth,從生成的512張圖中,根據判別器中輸出的值,選擇結果最好的64張圖,并存盤在本地,命名為result.png:
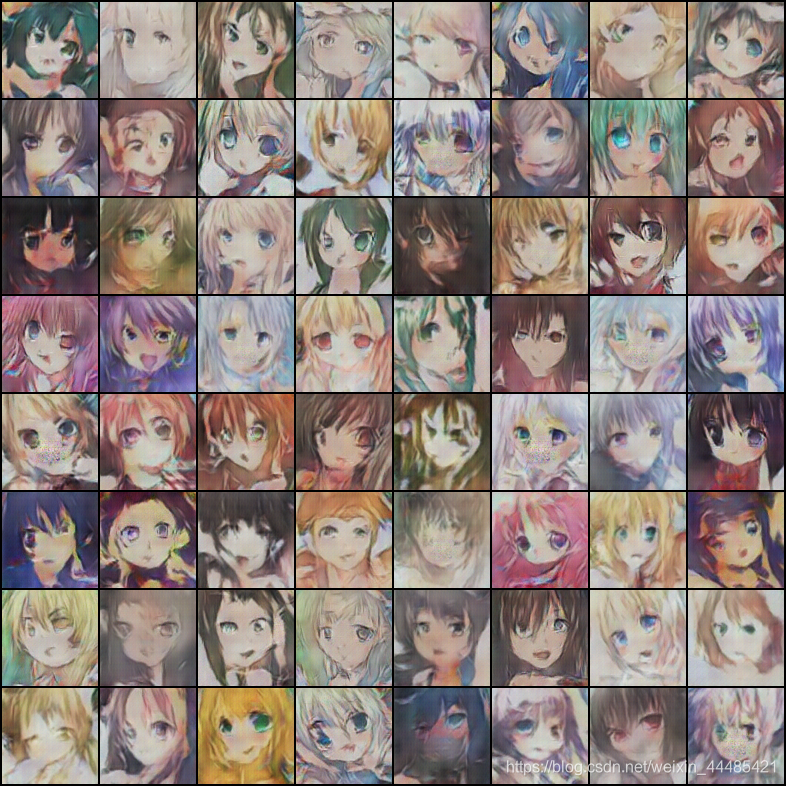
結果分析
生成器和判別器損失函式變化如下,可以看到訓練程序還是不穩定,
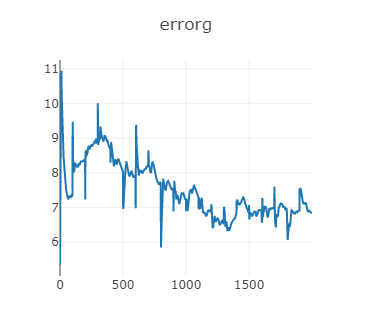 生成器損失變化
生成器損失變化
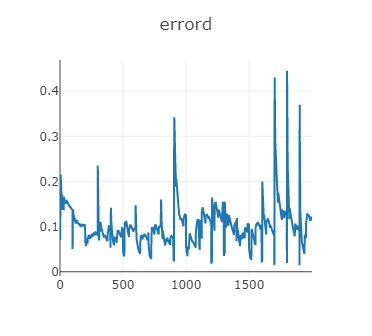 判別器損失變化
判別器損失變化
問題及改進:
-
樣本資料有些比較模糊,檢查影像樣本庫,在樣本數量足夠的情況下,檢查樣本中是否存在非動漫影像,動漫風格是否類似,樣本的表情、發色等面部屬性是否足夠豐富,
-
模型訓練不穩定,將訓練次數比例和學習率結合,動態調整,判別器訓練效果太好,會導致生成器反向調整引數,生成一些已經被識別為“真”的樣本,特殊情況下,還輸出許多面部特征畸變的影像,導致樣本缺乏多樣性和準確性,
完整代碼
main.py用于訓練和測驗
# coding:utf8
import os
import ipdb
import torch as t
import torchvision as tv
import tqdm
from model import NetG, NetD
from torchnet.meter import AverageValueMeter
class Config(object):
data_path = 'data/' # 資料集存放路徑
num_workers = 4 # 多行程加載資料所用的行程數
image_size = 96 # 圖片尺寸
batch_size = 256
max_epoch = 200
lr1 = 2e-4 # 生成器的學習率
lr2 = 2e-4 # 判別器的學習率
beta1 = 0.5 # Adam優化器的beta1引數
gpu = True # 是否使用GPU
nz = 100 # 噪聲維度
ngf = 64 # 生成器feature map數
ndf = 64 # 判別器feature map數
save_path = 'imgs/' # 生成圖片保存路徑
vis = True # 是否使用visdom可視化
env = 'GAN' # visdom的env
plot_every = 20 # 每間隔20 batch,visdom畫圖一次
debug_file = '/tmp/debuggan' # 存在該檔案則進入debug模式
d_every = 1 # 每1個batch訓練一次判別器
g_every = 5 # 每5個batch訓練一次生成器
save_every = 10 # 每10個epoch保存一次模型
netd_path = None # 'checkpoints/netd_.pth' #預訓練模型
netg_path = None # 'checkpoints/netg_211.pth'
# 只測驗不訓練
gen_img = 'result.png'
# 從512張生成的圖片中保存最好的64張
gen_num = 64
gen_search_num = 512
gen_mean = 0 # 噪聲的均值
gen_std = 1 # 噪聲的方差
opt = Config()
def train(**kwargs):
for k_, v_ in kwargs.items():
setattr(opt, k_, v_)
device=t.device('cuda') if opt.gpu else t.device('cpu')
if opt.vis:
from visualize import Visualizer
vis = Visualizer(opt.env)
# 資料
transforms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size),
tv.transforms.CenterCrop(opt.image_size),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
print(opt.data_path)
dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms)
dataloader = t.utils.data.DataLoader(dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.num_workers,
drop_last=True
)
# 網路
netg, netd = NetG(opt), NetD(opt)
map_location = lambda storage, loc: storage
if opt.netd_path:
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device)
# 定義優化器和損失
optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999))
optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999))
criterion = t.nn.BCELoss().to(device)
# 真圖片label為1,假圖片label為0
# noises為生成網路的輸入
true_labels = t.ones(opt.batch_size).to(device)
fake_labels = t.zeros(opt.batch_size).to(device)
fix_noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)
noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)
errord_meter = AverageValueMeter()
errorg_meter = AverageValueMeter()
epochs = range(opt.max_epoch)
for epoch in iter(epochs):
for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)):
real_img = img.to(device)
if ii % opt.d_every == 0:
# 訓練判別器
optimizer_d.zero_grad()
## 盡可能的把真圖片判別為正確
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward()
## 盡可能把假圖片判別為錯誤
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises).detach() # 根據噪聲生成假圖
output = netd(fake_img)
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
optimizer_d.step()
error_d = error_d_fake + error_d_real
errord_meter.add(error_d.item())
if ii % opt.g_every == 0:
# 訓練生成器
optimizer_g.zero_grad()
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises)
output = netd(fake_img)
error_g = criterion(output, true_labels)
error_g.backward()
optimizer_g.step()
errorg_meter.add(error_g.item())
if opt.vis and ii % opt.plot_every == opt.plot_every - 1:
## 可視化
if os.path.exists(opt.debug_file):
ipdb.set_trace()
fix_fake_imgs = netg(fix_noises)
vis.images(fix_fake_imgs.detach().cpu().numpy()[:64] * 0.5 + 0.5, win='fixfake')
vis.images(real_img.data.cpu().numpy()[:64] * 0.5 + 0.5, win='real')
vis.plot('errord', errord_meter.value()[0])
vis.plot('errorg', errorg_meter.value()[0])
if (epoch+1) % opt.save_every == 0:
# 保存模型、圖片
fix_fake_imgs = netg(fix_noises)
tv.utils.save_image(fix_fake_imgs.data[:64], '%s/%s.png' % (opt.save_path, epoch), normalize=True,
range=(-1, 1))
t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch)
t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch)
errord_meter.reset()
errorg_meter.reset()
@t.no_grad()
def generate(**kwargs):
"""
隨機生成動漫頭像,并根據netd的分數選擇較好的
"""
for k_, v_ in kwargs.items():
setattr(opt, k_, v_)
device=t.device('cuda') if opt.gpu else t.device('cpu')
netg, netd = NetG(opt).eval(), NetD(opt).eval()
noises = t.randn(opt.gen_search_num, opt.nz, 1, 1).normal_(opt.gen_mean, opt.gen_std)
noises = noises.to(device)
map_location = lambda storage, loc: storage
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device)
# 生成圖片,并計算圖片在判別器的分數
fake_img = netg(noises)
scores = netd(fake_img).detach()
# 挑選最好的某幾張
indexs = scores.topk(opt.gen_num)[1]
result = []
for ii in indexs:
result.append(fake_img.data[ii])
# 保存圖片
tv.utils.save_image(t.stack(result), opt.gen_img, normalize=True, range=(-1, 1))
if __name__ == '__main__':
import fire
fire.Fire()
print('over')
model.py模型檔案
# coding:utf8
from torch import nn
class NetG(nn.Module):
"""
生成器定義
"""
def __init__(self, opt):
super(NetG, self).__init__()
ngf = opt.ngf # 生成器feature map數
self.main = nn.Sequential(
# 輸入是一個nz維度的噪聲,我們可以認為它是一個1*1*nz的feature map
nn.ConvTranspose2d(opt.nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 上一步的輸出形狀:(ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 上一步的輸出形狀: (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 上一步的輸出形狀: (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上一步的輸出形狀:(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh() # 輸出范圍 -1~1 故而采用Tanh
# 輸出形狀:3 x 96 x 96
)
def forward(self, input):
return self.main(input)
class NetD(nn.Module):
"""
判別器定義
"""
def __init__(self, opt):
super(NetD, self).__init__()
ndf = opt.ndf
self.main = nn.Sequential(
# 輸入 3 x 96 x 96
nn.Conv2d(3, ndf, 5, 3, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 輸出 (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 輸出 (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 輸出 (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 輸出 (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() # 輸出一個數(概率)
)
def forward(self, input):
return self.main(input).view(-1)
visualize.py可視化
# coding:utf8
from itertools import chain
import visdom
import torch
import time
import torchvision as tv
import numpy as np
class Visualizer():
"""
封裝了visdom的基本操作,但是你仍然可以通過`self.vis.function`
呼叫原生的visdom介面
"""
def __init__(self, env='default', **kwargs):
import visdom
self.vis = visdom.Visdom(env=env, use_incoming_socket=False,**kwargs)
# 畫的第幾個數,相當于橫座標
# 保存(’loss',23) 即loss的第23個點
self.index = {}
self.log_text = ''
def reinit(self, env='default', **kwargs):
"""
修改visdom的配置
"""
self.vis = visdom.Visdom(env=env,use_incoming_socket=False, **kwargs)
return self
def plot_many(self, d):
"""
一次plot多個
@params d: dict (name,value) i.e. ('loss',0.11)
"""
for k, v in d.items():
self.plot(k, v)
def img_many(self, d):
for k, v in d.items():
self.img(k, v)
def plot(self, name, y):
"""
self.plot('loss',1.00)
"""
x = self.index.get(name, 0)
self.vis.line(Y=np.array([y]), X=np.array([x]),
win=(name),
opts=dict(title=name),
update=None if x == 0 else 'append'
)
self.index[name] = x + 1
def img(self, name, img_):
"""
self.img('input_img',t.Tensor(64,64))
"""
if len(img_.size()) < 3:
img_ = img_.cpu().unsqueeze(0)
self.vis.image(img_.cpu(),
win=(name),
opts=dict(title=name)
)
def img_grid_many(self, d):
for k, v in d.items():
self.img_grid(k, v)
def img_grid(self, name, input_3d):
"""
一個batch的圖片轉成一個網格圖,i.e. input(36,64,64)
會變成 6*6 的網格圖,每個格子大小64*64
"""
self.img(name, tv.utils.make_grid(
input_3d.cpu()[0].unsqueeze(1).clamp(max=1, min=0)))
def log(self, info, win='log_text'):
"""
self.log({'loss':1,'lr':0.0001})
"""
self.log_text += ('[{time}] {info} <br>'.format(
time=time.strftime('%m%d_%H%M%S'),
info=info))
self.vis.text(self.log_text, win=win)
def __getattr__(self, name):
return getattr(self.vis, name)
參考鏈接:https://cloud.tencent.com/developer/article/1697328
代碼來自:https://github.com/chenyuntc/pytorch-book/tree/master/chapter07-AnimeGAN
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291773.html
標籤:AI