Spark專題
1、Spark理論基礎
1.1、Spark基本概念
1.1.1、Application
(1)一個Application中可以有一到多個Job
(2)一個Application中可以出發多次Action,查發一次Action形成一個DAG,一個DAG對應一個Job
注意:應用程式的入口為用戶所定義的main方法
1.1.2、Job
(1)觸發一次Action形成一個完整的DAG,一個DAG對應一個Job
(2)一個job有多個stage,一個stage有多個Task
1.1.3、DAG
(1)有向無環圖,對多個RDD轉換程序和依賴關系的描述;
(2)觸發Action就會形成一個完整的DAG,一個DAG就是一個Job,
1.1.4、stage
(1)任務執行階段,順序執行,限制性后面的在執行前面的;
(2)一個stage對應一個Taskset,一個taskset的task的數量取決于stage中最后一個RDD磁區的數量,
1.1.5、Task
(1)保存同種計算邏輯的多個Task集合;
(2)一個Taskset中的Task計算邏輯都一樣,計算資料不一樣,
1.6、shuffle
作用:RDD上游的一個磁區將資料給了下游的RDD的多個磁區
shuffle程序:下游的task到上游拉取資料,不是上有task發送給下游的;
1.7、dependency
含義:依賴關系,父RDD和子RDD之間的依賴關系
1.8、RDD算子
RDD:保存計算的元資料
算子分類:
1、Transformtion算子 - 不觸發提交作業
:map,flatmap,union,groupby,filter,distinct
2、Action算子 - 觸發提交作業
:
1.9、partition - 磁區
概念:磁區式RDD內部并行計算的一個計算單元,是RDD資料集的邏輯分片
磁區的格式:決定計算粒度
磁區的個數:決定任務個數作用:通過相同的key放在相同節點,避免不同節點聚合key時進行shuffle操作產生的網路IO
- 磁區作用
1、增加并行度:
2、減少通信開銷: - 磁區原則:磁區個數 = 集群中CPU核心數目
1.10、并行度
Spark作業最大并行度=executor個數*每個excutor的cpu core數 :
1、Spark的當前并行度取決于task數,而task數=磁區數
:2、Spark給官方推薦磁區數為最大并行度的2-3倍,可以提交前計算的執行緒立刻倍后面的task使用,并且每個task處理的資料量會更少
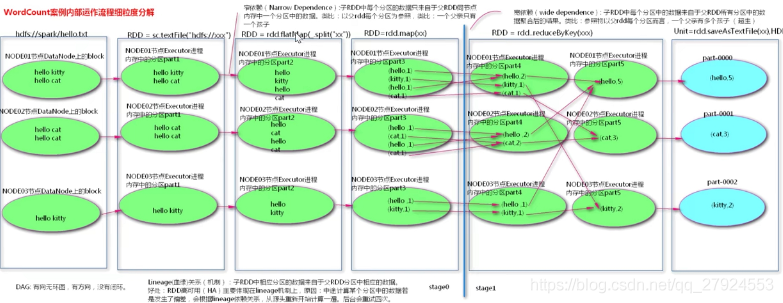
1.2、Spark架構
1.2.1、架構設計
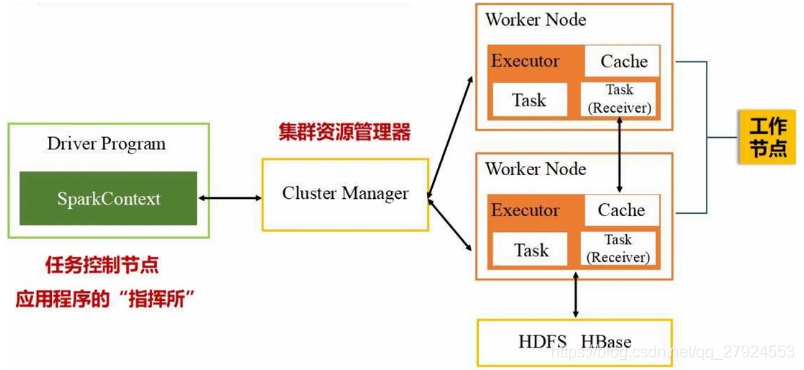

(1)Dirver
對Spark應用的整個執行程序進行管控,它是Spark應用程式的"master",
:在Spark應用執行時,Driver端會啟動很多服務的master端,這些服務的slave端運行在Executor上,這些服務的slave會向Driver端對應的master注冊或匯報運行狀態資訊
1、通過運行Spark應用的main函式來啟動Spark應用;
2、向資源管理平臺申請資源,并在Worker節點上啟動Executor;
3、創建SparkSession(包括SparkContext和SparkEnv),并對Spark應用進行規劃,編排,最后提交到Executor端執行;
4、收集Spark應用的執行狀態,并回傳執行結果;
(2)Executor
Executor是執行Spark應用的容器,
它的職責:就是根據Driver端的要求來啟動執行執行緒,執行task計算,上報任務狀態,并回傳執行結果,
(3)Sparksession
SparkSession:Spark SQL的入口點,
開發Spark SQL應用程式時首先要創建的物件之一,
在創建SparkSession時,會同時創建SparkContext和SparkEnv,
(4)Cluster Manager
集群資源管理器:負責為運行在資源管理跨框架上的應用程式分配資源,
- 可選擇
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-bAPSRicd-1627817366296)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Roaming/Typora/typora-user-images/image-20210801162428987.png)]](https://img.uj5u.com/2021/08/05/253068050708492.png)
(5)Worker
集群中任何可以運行人物的節點:根據Cluster Manager的指令分配資源,執行應用程式,釋放資源,
1.2.2、運行架構
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-ktYV5eHz-1627817366297)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Roaming/Typora/typora-user-images/image-20210801161254923.png)]](https://img.uj5u.com/2021/08/05/253068050708497.png)
2、RDD基礎
2.1、RDD基本概念
RDD的含義:不保存要計算的資料,保存元資料,即資料的描述資訊和運算邏輯,比如資料要從哪里讀取,怎么運算,RDD:可認為是一個代理,對RDD進行操作,相當于在Driver端先是記錄下計算的描述資訊,然后生成task,將task調度到Executor端才執行真正計算邏輯,
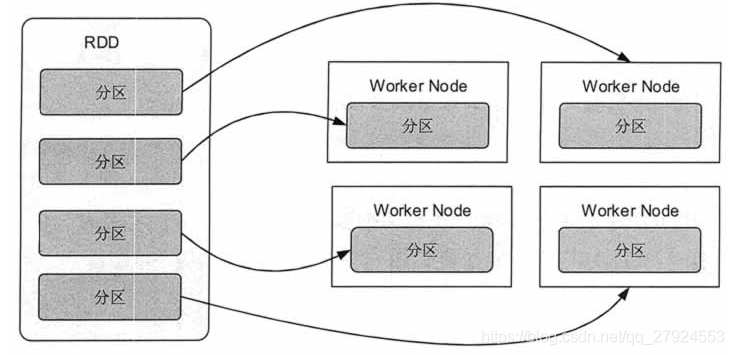
(1)只讀:不能修改,只能通過轉換生成新的RDD
(2)分布式:可分布在多臺機器上進行處理
(3)彈性:計算程序記憶體不足時會和磁盤進行資料交換
(4)基于記憶體:可以全部或部分快取在記憶體中,在多次計算間重用
2.2、RDD產生背景
Mapreduce框架缺點:都是把中間結果寫入到HDFS中,帶來的大量的資料復制、磁盤IO和序列化開銷;
RDD:將具體的應用邏輯表達為一系列轉換處理,不同RDD之間的轉換操作形成依賴關系,可以實作管道化,比買你中間存盤的結果,大大降低了資料復制、磁盤IO和序列化開銷;
2.3、RDD特點
高效容錯性:RDD的設計中,資料只讀,不可修改,如果需要修改資料,必須從父RDD轉換到子RDD,由此在不同RDD之間建立了血緣關系,不需要通過資料冗余的方式(比如檢查點)實作容錯,而只需要通過RDD父子依賴關系重新計算得到丟失的磁區來實作容錯,無需回滾整個系統,避免了資料復制的高開銷中間結果可持久化存盤到記憶體:資料在記憶體中的多個RDD操作之間進行傳遞,不需要落地到整個磁盤,避免了不必要的磁盤開銷
2.4、RDD的執行程序
? 采用了惰性呼叫,通過血緣關系鏈接起來的一系列RDD操作實作管道化,不用擔心有過多中間資料;
? 一個操作得到的結果不需要保存中間資料,直接管道化流入到下一個操作進行處理,保證了每個操作在處理邏輯的單一性;
1、啟動pyspark;
2、從HDFS檔案中讀取資料創建一個RDD;
3、定義一個過濾函式;
4、對創建好的RDD進行轉換操作得到一個新的RDD;
5、對轉換后的RDD持久化6、行動操作,用于計算一個RDD集合中包含的元素個數
***3和4:構建起fileRDD和filterRDD之間的依賴關系,形成DAG圖,這時候并沒有發生真正的計算,只是記錄轉換的軌跡;
***5:count()是一個行動型別的操作,觸發真正的計算,開始實際執行從fileRDD到filterRDD的轉換操作,并把結果持久化到記憶體中,最后計算出filterRDD中包含的元素個數,
2.5、RDD的任務調度
1、創建RDD物件
2、SparkContext:計算RDD之間的依賴關系,構建DAG
3、DAGScheduler:DAG圖分解成多個階段,每個階段包含了多個任務,每個任務會被任務調度器分發給各個作業節點上的Executor執行
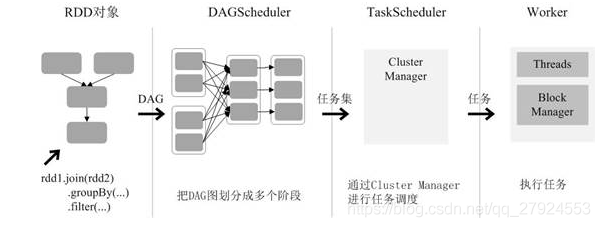
DagScheduler切分stageTaskScheduler切分taskShceduler都在driver上
2.6、RDD操作
2.6.1、轉換操作
-
每一次轉換操作,生成一個新的RDD
-
RDD惰性求值,整個轉換程序只是記錄了轉換的軌跡,并不會發生真正的計算
(1)filter(func)
#篩選出滿足函式func的元素,回傳一個新的資料集
lines = lines.filterlambda line:"spark" in line)
(2)map(func)
#每個元素傳遞到函式func中,并將結果回傳為一個新的資料集
lines = lines.map(lambda x:x+10)lines = lines.map(lambda x:x.split(" "))
(3)flatmap(func)
#于map()相似,但每個輸入元素都可以映射到0或多個輸出結果
lines = lines.flatMap(lambda x:x.split(" "))
(4)groupByKey()
#應用于(k,v)鍵值對的資料集,回傳一個新的(k,Iterable)形式的資料集
lines = lines.groupByKey()將key相同的值歸并為串列
(5)reduceByKey(func)
#應用于(k,v)鍵值對的資料集,回傳一個新的(k,v)形式的資料集,其中每個值是將每個key傳遞到函式func中進行聚合后的結果,
lines = lines.reduceByKey(**lambda a,b:a+b**)函式作用于key后面串列
2.6.2、行動操作
–執行真正計算的操作
(1)count()
#回傳資料集中的**元素個數**lines.count()
(2)collect()
#以**陣列**形式回傳資料集中的**所有元素**lines.collect()
(3)first()
#回傳資料集中的**第一個元素**lines.first()
2.6.3、持久化
-
持久化RDD會被保存在計算節點記憶體中被后面操作重復使用;
-
遇上第一個行動操作出發真正計算后,才會進行持久化,
(1)持久化
RDD.cache() #標記為持久化RDD.persist(MEMORY_AND_DISK):#將rdd作為反序列化物件存在JVM中,記憶體不足,保存在磁盤,先進先出
(2)移除持久化
RDD.unpersist()手動將持久化的RDD從快取中移除
2.7、RDD磁區
磁區作用 :
(1)增加并行度,并行計算
(2)減少通信開銷,未磁區時,需要涉及到大量的網路通信磁區個數 = 集群中CPU核心資料
(1)local[n]:磁區個數為n
(2)yarn:集群各種所有核心和2取較大值為磁區數
3、Spark任務調度
3.1、Spark執行流程
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-rV8twW4l-1627817366302)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Roaming/Typora/typora-user-images/image-20210730114144792.png)]](https://img.uj5u.com/2021/08/05/2530680507084910.png)
1、提交代碼:使用spark-submit提交代碼到服務器上
2、創建SparkContext:在SparkContest初始化的時候會創建DAGScheduler和TaskScheduler
3、創建Appliction:TaskScheduler會啟動一個后臺行程取集群Master注冊Application,申請任務資源,比如CPU,記憶體等等
4、啟動Executor:worker會啟動executor,Executor反向注冊到Dirver上,Driver結束SparkContext初始化,繼續執行代碼;
5、創建Job:每次執行到一個action算子,就會創建一個job,同時job會被提交到DAGScheduler
6、劃分Stage:.DAGScheduler會使用劃分演算法,將job劃分成多個stage,然后每個stage都會創建一個TaskSet,劃分stage依據是磁區間有無資料互動,也就是Shuffle程序
7、TaskSet分配:TaskScheduler會把TaskSet中的task通過task分配演算法提交到Executor上運行,遵循"計算向資料靠攏",TaskScheduler會根據節點上的資料,將對于的任務丟到該節點上,
8、創建執行緒池:Executor會創建執行緒池執行task,每個都會task被封裝成TaskRunner,*總的來說:Spark應用的執行就是stage分批次提交TaskSet到Executor,每個Task針對RDD的一個partition,執行定義的算子,直到所有問題完成
-
Spark的運行主要分為2部分 :
-
1、一部分是驅動程式,其核心是SparkContext;另一部分是Worker節點上Task,它是運行實際任務的,
-
2、程式運行的時候,Driver和Executor行程相互互動:運行什么任務,即Driver會分配Task到Executor,Driver 跟 Executor 進行網路傳輸; 任務資料從哪兒獲取,即Task要從 Driver 抓取其他上游的 Task 的資料結果,所以有這個程序中就不斷的產生網路結果.
-
Task調度
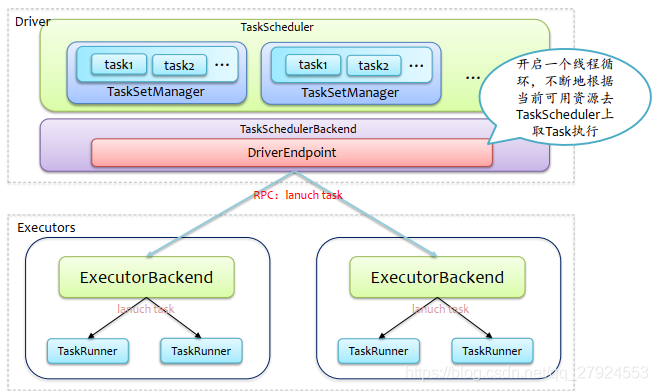
task調度:開啟一個執行緒回圈,不斷根據當前可用資源區TaskScheduler上取Task執行
3.2、Spark的資源配置
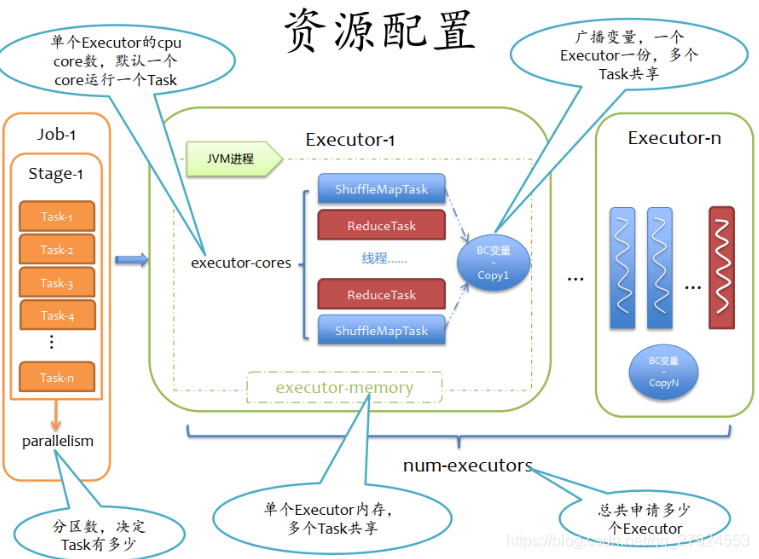
1、num-executors:總共申請多少個executor
2、executor-cores:單個Executor的cpu core數,默認一個core運行一個task
3、executor-memory:單個executor記憶體,多個task共享
4、parallelism:磁區數,決定task有多少5、BC-變數:廣播變數,一個executor一份,多個task共享
- 資源配置注意點
1、太大記憶體(executor-memory>15G) :資源浪費,影響其他業務:限制單個executor的記憶體不能超過14G
2、太大CPU核數(executor-core>5) :丟失了并發的優勢,例如:num-executor = 10,executor-cores=10 :申請等待時間和風險
3、太多的executor(num-executor>500) :申請等待時間和風險 :每個executor都是獨立的JVM,網路IO成本4、太多的磁區(parallelism>executor*cores*(3-5)) :任務過細,輪數太多 :增加driver的維護壓力
3.3、yarn-cluster運行流程
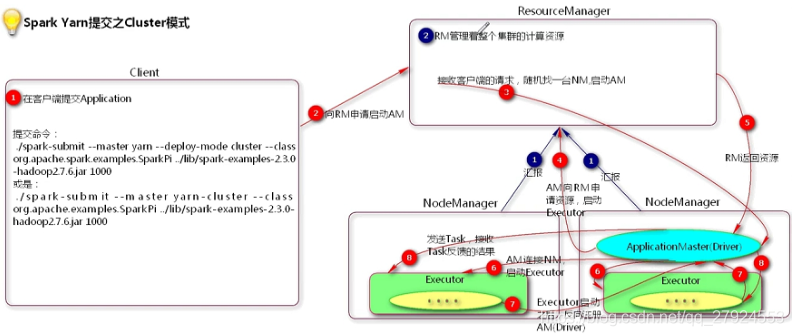
1、在客戶端提交Application
2、向RM申請啟動AM(RM管理整個集群的計算資源)
3、RM接收客戶端的請求,隨機找一臺NodeManager啟動Application Master
4、AM向RM申請資源,啟動executor
5、RM回傳executor所需要的資源
6、AM鏈接NM,啟動Executor
7、Executor啟動之后,反向注冊AM(Dirver)
8、AM發送task,接收Task反饋的結果
4、shuffle原理及優化
- shuffle:下一個 Stage 向上一個 Stage 要資料這個程序
- shuffle時機:RDD存在寬依賴的時候
- shuffle的種類:在spark-1.6版本之前,一直使用HashShuffle,在spark-1.6版本之后使用Sort-Base Shuffle
4.1、Spark shuffle內部原理
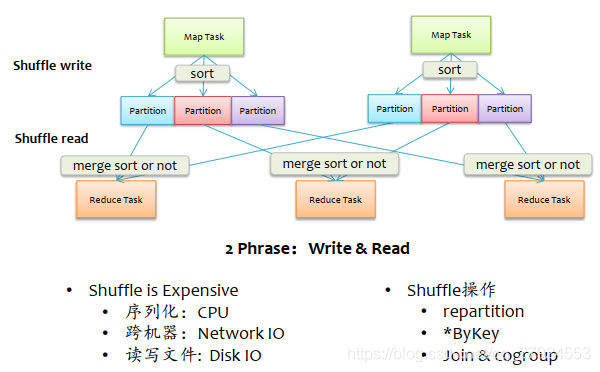
shuffle操作:
repartition,*ByKey,Join&cogroup
- Spark Shuffle實體 - 詞頻統計
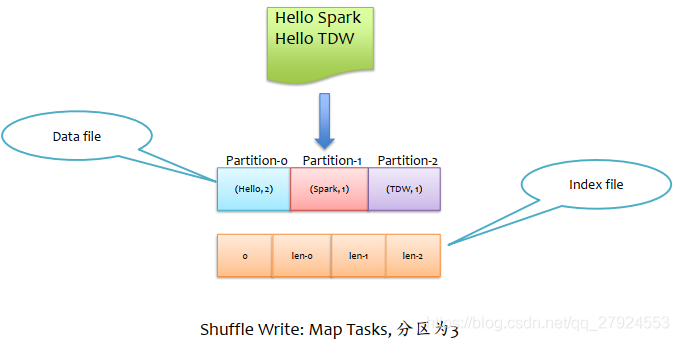
1、shuffle write:map Tasks,磁區數為3
每一個ShuffleMapTask:都會產生一個data檔案和index檔案
合并:只是將該ShuffleMapTask的各個partition對應的磁區檔案合并到data檔案而已
2、shuffle read:read Tasks
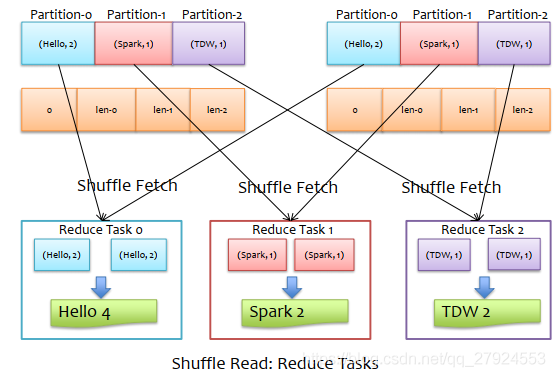
4.2、shuffle調優
1、資料落地時,partition數不易過多:在保存到hdfs前,盡量控制partition數,避免落地后小檔案較多影響后續加載,落地前呼叫rdd.coalesce(num_partition)減少partition數
2、主動shuffle-repartition:如果磁區數少,可增大磁區,將任務細分 :提高后續分布式運行的速度
3、調整shuffle read并發度:記憶體緊俏時,減少shuffle read并發 :記憶體充足時,增加shuffle read并發
4、多表join:如果要join多個RDD,請使用cogroup
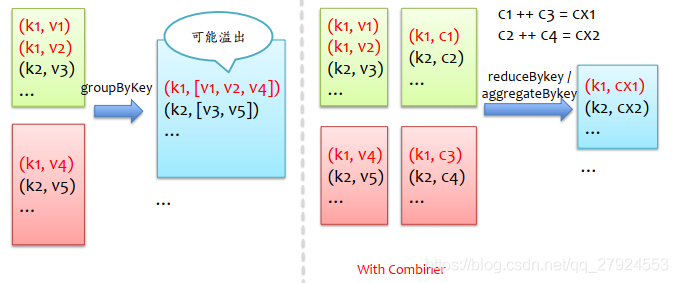
5、避免使用groupBykey進行聚合操作
特征:groupbykey.mapvalues(_.sum)
改進:rdd.reduceBykey()
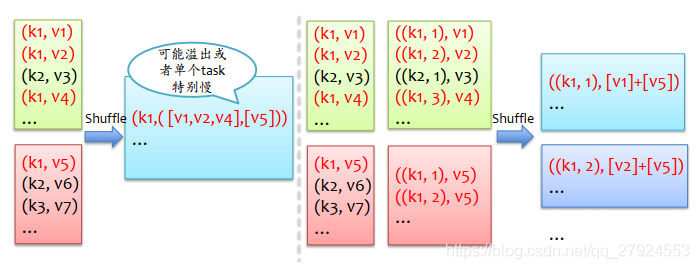
6、資料傾斜處理 - join
:對key進行分桶,將大資料量的key落地到一個主機上
缺點:小表會膨脹,整體運行緩慢
5、Broadcast原理及實踐
- Broadcast:用于處理共享組態檔
Broadcast:將資料從一個節點發送到其他的節點上例如 Driver 上有一張表,而 Executor 中的每個并行執行的Task (100萬個Task) 都要查詢這張表的話,那我們通過 Broadcast 的方式就只需要往每個Executor 把這張表發送一次就行了,Executor 中的每個運行的 Task 查詢這張唯一的表,而不是每次執行的時候都從 Driver 中獲得這張表!
5.1、Broadcast基本原理
- No broadcast:每次啟動都要傳輸大物件broadcast:每個executor傳輸一次大物件,并使用torrent加工網路傳輸
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-K7YjZ1QT-1627817366312)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Roaming/Typora/typora-user-images/image-20210730144900857.png)]](https://img.uj5u.com/2021/08/05/2530680507084919.png)
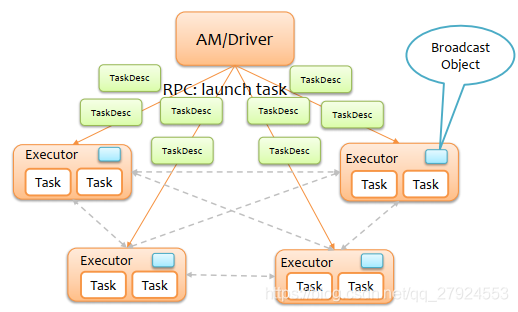
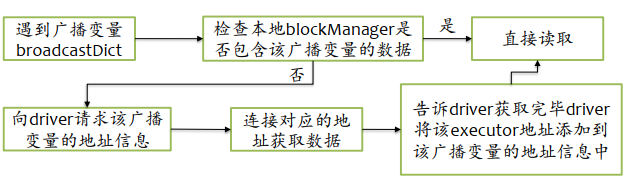
5.2、Broadcast實踐 - 廣播變數
- 廣播變數:實際上就是Driver端的變數通過Broadcast方法傳輸到Executor端,Executor端不能修改廣播變數的值,使用廣播變數是為了減少Executor端的資料備份,減少Executor端的記憶體,
- 注意:如果任務邏輯中會使用比較大的物件(大于10M),例如靜態查找表,則考慮將其變成廣播變數
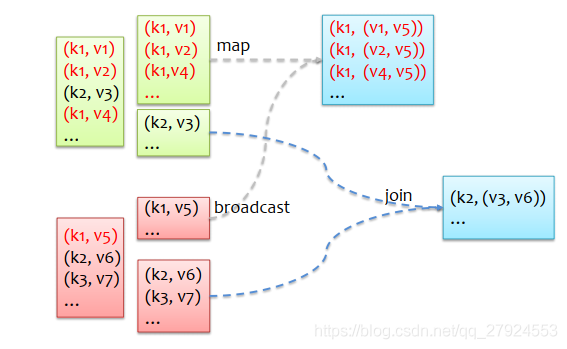
5.3、Broadcast實踐 - MapJoin
Mapjoin:會避免shuffle 傳統join操作:會導致shuffle操作 Mapjoin操作:使用Broadcast甲骯一個資料量小的RDD作為廣播變數
- MapJoin處理資料傾斜
實作方式:將RDD分割成兩部分進行join
6、Cache
- 落地:將RDD保存到記憶體或者磁盤上
6.1、Cache基本原理
- 基本原理:對多次使用的RDD進行持久化,
- 此時Spark就會根據你的持久化策略,將RDD中的資料保存到記憶體或者磁盤中,以后每次對這個RDD進行算子操作時,都會直接從記憶體或磁盤中提取持久化的RDD資料,然后執行算子,而不會從源頭處重新計算一遍這個RDD,再執行算子操作,
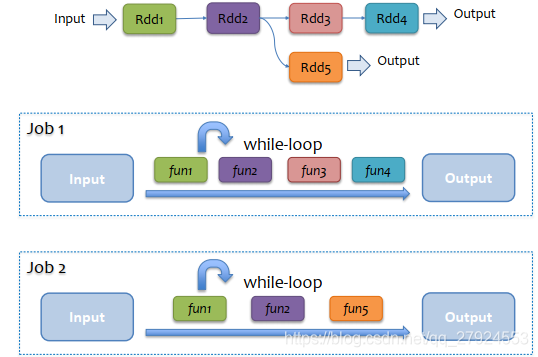
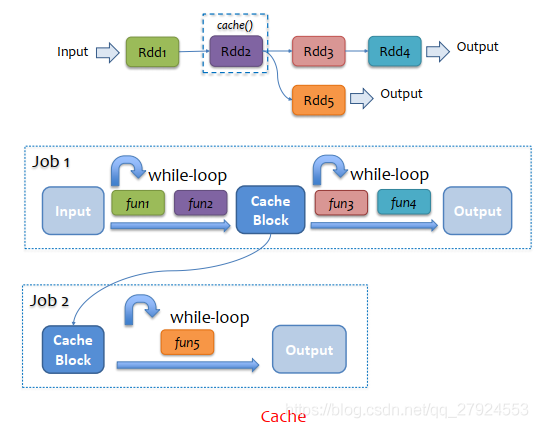
6.2、Cache原則
persist原則
1、長鏈型的RDD,每個都不需要Cache,spark會鏈式執行
2、樹形的RDD,分叉處的RDD,精良Cache
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-cBwuLpNl-1627817366319)(C:/Users/%E6%9D%8E%E6%B5%B7%E4%BC%9F/AppData/Roaming/Typora/typora-user-images/image-20210730171838746.png)]](https://img.uj5u.com/2021/08/05/2530680507084924.png)
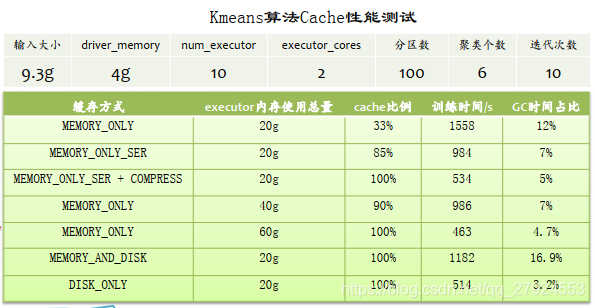
6.3、Cache性能
記憶體充足時推薦:rdd.persist(StorageLevel.MEMORY_ONLY)
記憶體稀缺時推薦:rdd.persist(Storagelevel.MEMORY_ONLY_SER)
7、CheckPoint
- 落地:將RDD保存到HDFS上
7.1、CheckPoint基本原理
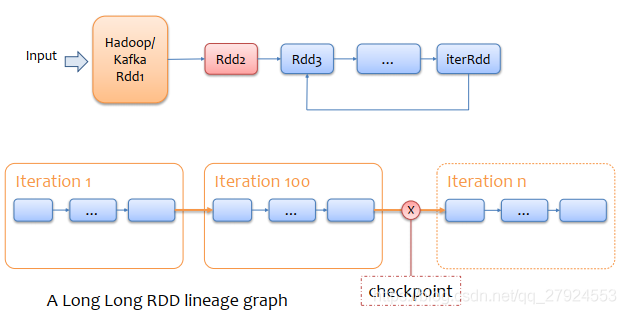
- 斷鏈:隨著迭代的進行,RDD依賴關系越來越長,driver維護壓力變大,可能driverOOM,可能會斷鏈
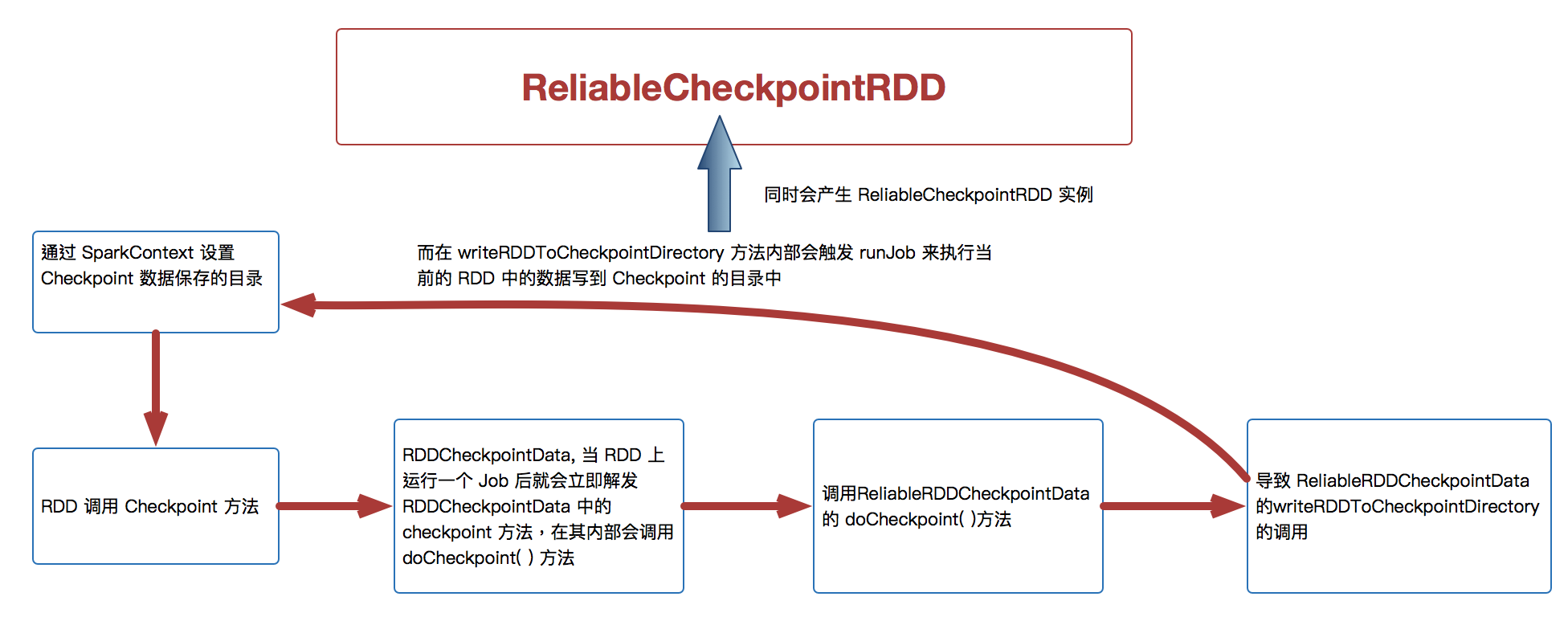
- Checkpoint:針對整個RDD 計算鏈條中特別需要資料持久化的環節(后面會反覆使用當前環節的RDD) 開始基于HDFS 等的資料持久化復用策略,通過對 RDD 啟動 Checkpoint 機制來實作容錯和高可用;
- 讀取資料優先級:
1、當RDD使用cache機制從記憶體中讀取資料,
2、如果資料沒有讀到,會使用checkpoint機制讀取資料,
3、此時如果沒有checkpoint機制,那么就需要找到父RDD重新計算資料了,因此checkpoint是個很重要的容錯機制,
7.2、CheckPoint的作用
元資料CheckPoint作用:通過保存在HDFS上的定義資訊來恢復應用程式中運行worker的節點的故障,
主要為了從driver故障中恢復
資料CheckPoint作用:通過保存在HDFS上的RDD來恢復斷鏈造成的故障
7.3、cache與checkpoint的區別
cache與checkpoint的區別在于
- 1、checkpoint會導致斷鏈,執行checkpoint后不再保存依賴鏈
- 前者持久化只是將資料保存在BlockManager中但是其lineage是不變的,但是后者checkpoint執行完后,rdd已經沒有依賴RDD,只有一個checkpointRDD,checkpoint之后,RDD的lineage就改變了,
- 2、持久化存盤保存在記憶體或磁盤上在程式運行結束后就會自動洗掉,檢查點保存的RDD狀態保存在HDFS上,只能手動清理
- :persist或者cache持久化的資料丟失的可能性更大,因為可能磁盤或記憶體被清理,但是checkpoint的資料通常保存到hdfs上,放在了高容錯檔案系統,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291808.html
標籤:其他