文章目錄
- 一、什么是全文索引
- 二、ElasticSearch簡介
- 概述
- 三、IK分詞器
- 簡介
- 四、Kibana使用-掌握DSL陳述句
- 簡介
- Spring Data
一、什么是全文索引
? 我們在瀏覽各種網頁的情況下,無不例外需要涉及到搜索的需求,然而像淘寶、京東這類的大流量公司,存盤的資料量達到上億的情況下,若還是撰寫select陳述句去查詢每一條記錄,老板早就把你開了,在高資料量的情況下,要實作快速,哦不,迅速查詢的需求,我們就要使用到全文索引,
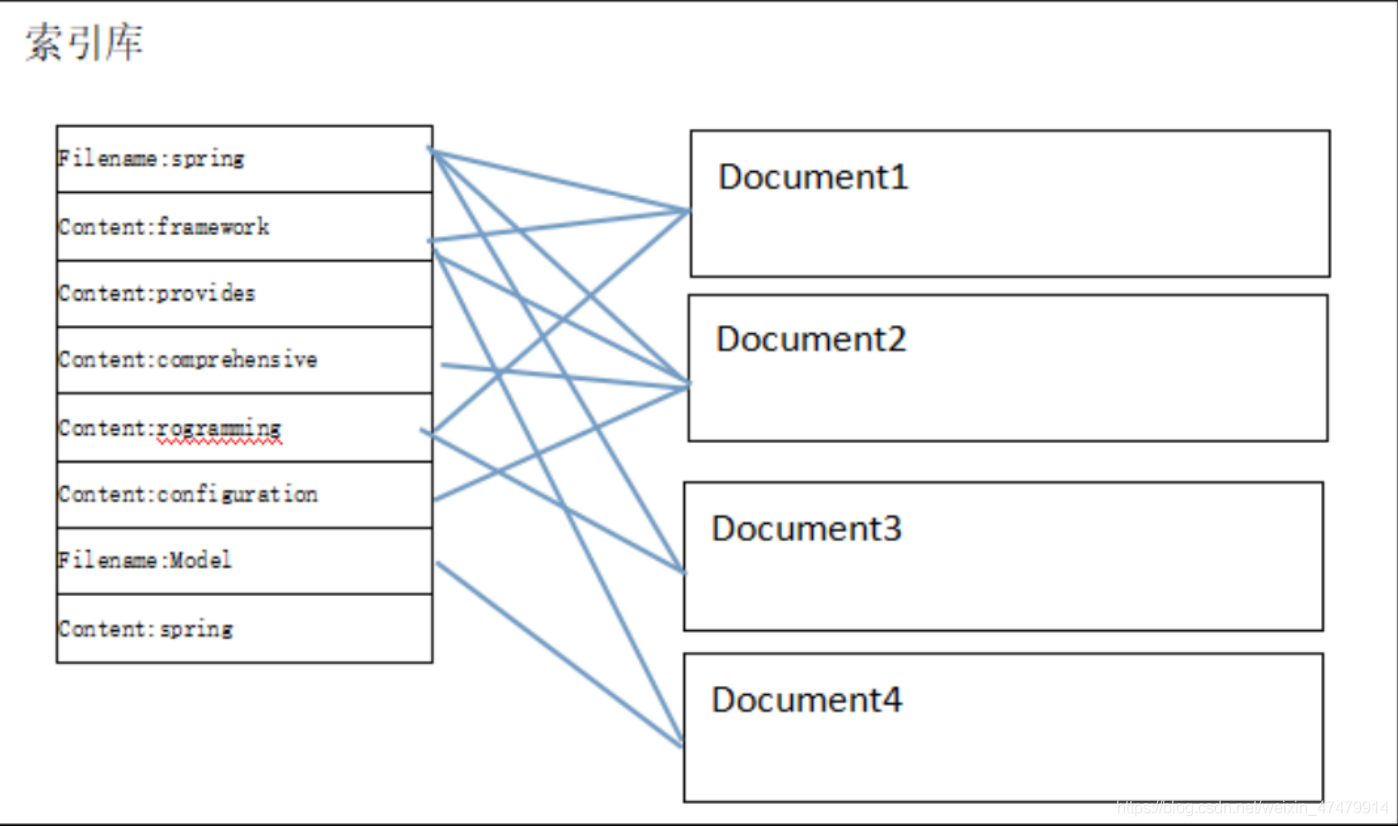
二、ElasticSearch簡介
概述
? Elasticsearch是面向檔案(document oriented)的,這意味著它可以存盤整個物件或檔案(document),然而它不僅僅是存盤,還會索引(index)每個檔案的內容使之可以被搜索,在Elasticsearch中,你可以對檔案(而非成行成列的資料)進行索引、搜索、排序、過濾,Elasticsearch比傳統關系型資料庫如下:

三、IK分詞器
簡介
? 簡單來說,IK分詞器可以把一句話分為幾個詞,方便索引的建立和查找,例如:“我是大帥哥”—>“我” “是” “大帥哥”,
? IK分詞器3.0的特性如下:
- 采用了特有的“正向迭代最細粒度切分演算法“,具有60萬字/秒的高速處理能力,
- 采用了多子處理器分析模式,支持:英文字母(IP地址、Email、URL)、數字(日期,常用中文數量詞,羅馬數字,科學計數法),中文詞匯(姓名、地名處理)等分詞處理,
- 對中英聯合支持不是很好,在這方面的處理比較麻煩.需再做一次查詢,同時是支持個人詞條的優化的詞典存盤,更小的記憶體占用,
- 支持用戶詞典擴展定義,
- 針對Lucene全文檢索優化的查詢分析器IKQueryParser;采用歧義分析演算法優化查詢關鍵字的搜索排列組合,能極大的提高Lucene檢索的命中率,
四、Kibana使用-掌握DSL陳述句
簡介
? 我們在搭建好的ElasticSearch中往往無法滿足我們復雜的業務需求,Kibana 是一款開源的資料分析和可視化平臺,它是 Elastic Stack 成員之一,設計用于和 Elasticsearch協作,您可以使用 Kibana 對Elasticsearch 索引中的資料進行搜索、查看、互動操作,您可以很方便的利用圖表、表格及地圖對資料進行多元化的分析和呈現,Kibana 可以使大資料通俗易懂,它很簡單,基于瀏覽器的界面便于您快速創建和分享動態資料儀表板來追蹤 Elasticsearch 的實時資料變化,
? 我們通過DSL陳述句便可對索引庫中的資料進行增刪改查業務,具體api可參考鏈接: DSL陳述句API,
Spring Data
? Spring Data是一個用于簡化資料庫訪問,并支持云服務的開源框架,其主要目標是使得對資料的訪問變得方便快捷,并支持map-reduce框架和云計算資料服務, Spring Data可以極大的簡化JPA的寫法,可以在幾乎不用寫實作的情況下,實作對資料的訪問和操作,除了CRUD外,還包括如分頁、排序等一些常用的功能,具體api可參考鏈接: Spring Data Elasticsearch-----API.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291812.html
標籤:其他