第1題
我們有如下的用戶訪問資料
| userId | visitDate | visitCount |
| u01 | 2017/1/21 | 5 |
| u02 | 2017/1/23 | 6 |
| u03 | 2017/1/22 | 8 |
| u04 | 2017/1/20 | 3 |
| u01 | 2017/1/23 | 6 |
| u01 | 2017/2/21 | 8 |
| u02 | 2017/1/23 | 6 |
| u01 | 2017/2/22 | 4 |
要求使用SQL統計出每個用戶的累積訪問次數,如下表所示:
| 用戶id | 月份 | 小計 | 累積 |
| u01 | 2017-01 | 11 | 11 |
| u01 | 2017-02 | 12 | 23 |
| u02 | 2017-01 | 12 | 12 |
| u03 | 2017-01 | 8 | 8 |
| u04 | 2017-01 | 3 | 3 |
資料
insert into action values('u01','2017/1/21',5);
insert into action values('u02','2017/1/23',6);
insert into action values('u03','2017/1/22',8);
insert into action values('u04','2017/1/20',3);
insert into action values('u01','2017/1/23',6);
insert into action values('u01','2017/2/21',8);
insert into action values('u02','2017/1/23',6);
insert into action values('u01','2017/2/22',4);1)創建表
create table action
(userId string,
visitDate string,
visitCount int)
row format delimited fields terminated by "\t";1)修改資料格式
select
userId,
date_format(regexp_replace(visitDate,'/','-'),'yyyy-MM') mn,
visitCount
from
action;t12)計算每人單月訪問量
select
userId,
mn,
sum(visitCount) mn_count
from
t1
group by userId,mn;t23)按月累計訪問量
select
userId,
mn,
mn_count,
sum(mn_count) over(partition by userId order by mn)
from t2;
最終SQL
select
userId,
mn,
mn_count,
sum(mn_count) over(partition by userId order by mn)
from
( select
userId,
mn,
sum(visitCount) mn_count
from
(select
userId,
date_format(regexp_replace(visitDate,'/','-'),'yyyy-MM') mn,
visitCount
from
action)t1
group by userId,mn)t2;第2題 京東
有50W個京東店鋪,每個顧客訪客訪問任何一個店鋪的任何一個商品時都會產生一條訪問日志,訪問日志存盤的表名為Visit,訪客的用戶id為user_id,被訪問的店鋪名稱為shop,請統計:
insert into visit values(3,'女裝');
insert into visit values(4,'女裝');
insert into visit values(5,'女裝');
insert into visit values(6,'女裝');
insert into visit values(7,'女裝');
insert into visit values(8,'女裝');
insert into visit values(8,'女裝');
insert into visit values(9,'女裝');
insert into visit values(10,'女裝');
insert into visit values(11,'女裝');
insert into visit values(1,'男裝');
insert into visit values(1,'男裝');
insert into visit values(1,'男裝');
insert into visit values(1,'男裝');
insert into visit values(2,'男裝');
insert into visit values(3,'男裝');
insert into visit values(4,'男裝');建表:
create table visit(user_id string,shop string) row format delimited fields terminated by '\t';1)每個店鋪的UV(訪客數)
select shop,count(distinct user_id) from visit group by shop;2)每個店鋪訪問次數top3的訪客資訊,輸出店鋪名稱、訪客id、訪問次數
(1)查詢每個店鋪被每個用戶訪問次數
select shop,user_id,count(*) ct
from visit
group by shop,user_id;t1(2)計算每個店鋪被用戶訪問次數排名
select shop,user_id,ct,rank() over(partition by shop order by ct) rk
from t1;t2(3)取每個店鋪排名前3的
select shop,user_id,ct
from t2
where rk<=3;(4)最終SQL
s
select shop,
user_id,
ct
from (select shop,
user_id,
ct,
rank() over (partition by shop order by ct) rk
from (select shop,
user_id,
count(*) ct
from visit
group by shop,
user_id) t1
) t2
where rk <= 3;第3題
已知一個表STG.ORDER,有如下欄位:Date,Order_id,User_id,amount,請給出sql進行統計:資料樣例:2017-01-01,10029028,1000003251,33.57,
建表:
create table order_tab(dt string,order_id string,user_id string,amount decimal(10,2)) row format delimited fields terminated by '\t';1)給出 2017年每個月的訂單數、用戶數、總成交金額,
select
date_format(dt,'yyyy-MM'),
count(order_id),
count(distinct user_id),
sum(amount)
from
order_tab
group by date_format(dt,'yyyy-MM');2)給出2017年11月的新客數(指在11月才有第一筆訂單)
select
count(user_id)
from
order_tab
group by user_id
having date_format(min(dt),'yyyy-MM')='2017-11';第4題
有一個5000萬的用戶檔案(user_id,name,age) a,一個2億記錄的用戶看電影的記錄檔案(user_id,url) b,根據年齡段觀看電影的次數進行排序?
1.先把表按照user_id分組統計減少資料量
(
SELECT user_id,
count(url) count
FROM b
GROUP BY user_id
) c2.再把a和c關聯起來
SELECT a.user_id,
a.age,
Ifnull(c.count, 0),
from a
left join (
SELECT user_id,
count(url) count
FROM b
GROUP BY user_id
) c on c.user_id = a.user_id3、分組排序
SELECT d.*,
rank() over (PARTITION BY age ORDER BY count) rk
FROM (
SELECT a.user_id,
a.age,
ifnull(c.count, 0),
FROM a
LEFT JOIN (
SELECT user_id,
count(url) count
FROM b
GROUP BY user_id
) c ON c.user_id = a.user_id
) d第5題
有日志如下,請寫出代碼求得所有用戶和活躍用戶的總數及平均年齡,(活躍用戶指連續兩天都有訪問記錄的用戶)
日期 用戶 年齡
2019-02-11,test_1,23
2019-02-11,test_2,19
2019-02-11,test_3,39
2019-02-11,test_1,23
2019-02-11,test_3,39
2019-02-11,test_1,23
2019-02-12,test_2,19
2019-02-13,test_1,23
2019-02-15,test_2,19
2019-02-16,test_2,19
create table user_age(dt string,user_id string,age int)row format delimited fields terminated by ',';
insert into table user_age values ('11', 'test_1', 23);
insert into table user_age values ('11', 'test_2', 19);
insert into table user_age values ('11', 'test_3', 39);
insert into table user_age values ('11', 'test_1', 23);
insert into table user_age values ('11', 'test_3', 39);
insert into table user_age values ('11', 'test_1', 23);
insert into table user_age values ('12', 'test_2', 19);
insert into table user_age values ('13', 'test_1', 23);1)按照日期以及用戶分組,按照日期排序并給出排名
select dt,
user_id,
min(age) age,
rank() over (partition by user_id order by dt) rk
from user_age
group by dt, user_id; t12)計算日期及排名的差值
select user_id,
age,
date_sub(dt, rk) flag
from t1; t23)過濾出差值大于等于2的,即為連續兩天活躍的用戶
select user_id,
min(age) age
from t2
group by user_id, flag
having count(*) >= 2; t34)對資料進行去重處理(一個用戶可以在兩個不同的時間點連續登錄),例如:a用戶在1月10號1月11號以及1月20號和1月21號4天登錄,
select user_id,
min(age) age
from t3
group by user_id;t45)計算活躍用戶(兩天連續有訪問)的人數以及平均年齡
select
count(*) ct,
cast(sum(age)/count(*) as decimal(10,2))
from t4;6)對全量資料集進行按照用戶去重
?
select user_id,
min(age) age
from user_age
group by user_id;t5
?7)計算所有用戶的數量以及平均年齡
select
count(*) user_count,
cast((sum(age)/count(*)) as decimal(10,1))
from t5;8)將第5步以及第7步兩個資料集進行union all操作
select 0 user_total_count,
0 user_total_avg_age,
count(*) twice_count,
cast(sum(age) / count(*) as decimal(10, 2)) twice_count_avg_age
from (
select user_id,
min(age) age
from (select user_id,
min(age) age
from (
select user_id,
age,
date_sub(dt, rk) flag
from (
select dt,
user_id,
min(age) age,
rank() over (partition by user_id order by dt) rk
from user_age
group by dt, user_id
) t1
) t2
group by user_id, flag
having count(*) >= 2) t3
group by user_id
) t4
union all
select count(*) user_total_count,
cast((sum(age) / count(*)) as decimal(10, 1)) user_total_avg_age,
0 twice_count,
0 twice_count_avg_age
from (
select user_id,
min(age) age
from user_age
group by user_id
) t5; t6
9)計算最終結果
select sum(user_total_count),
sum(user_total_avg_age),
sum(twice_count),
sum(twice_count_avg_age)
from (select 0 user_total_count,
0 user_total_avg_age,
count(*) twice_count,
cast(sum(age) / count(*) as decimal(10, 2)) twice_count_avg_age
from (
select user_id,
min(age) age
from (select user_id,
min(age) age
from (
select user_id,
age,
date_sub(dt, rk) flag
from (
select dt,
user_id,
min(age) age,
rank() over (partition by user_id order by dt) rk
from user_age
group by dt, user_id
) t1
) t2
group by user_id, flag
having count(*) >= 2) t3
group by user_id
) t4
union all
select count(*) user_total_count,
cast((sum(age) / count(*)) as decimal(10, 1)) user_total_avg_age,
0 twice_count,
0 twice_count_avg_age
from (
select user_id,
min(age) age
from user_age
group by user_id
) t5) t6;第6題
請用sql寫出所有用戶中在今年10月份第一次購買商品的金額,表ordertable欄位(購買用戶:userid,金額:money,購買時間:paymenttime(格式:2017-10-01),訂單id:orderid)
create table sixth (userid string,monty string ,paymenttime string,orderid string);
insert into table sixth values('001','100','2017-10-01','123123');
insert into table sixth values('001','200','2017-10-02','123124');
insert into table sixth values('002','500','2017-10-01','222222');
insert into table sixth values('001','100','2017-11-01','123123');select
userid,
paymenttime,
monty,
row_con
from
(
select
paymenttime,
userid,
monty,
orderid,
--下面的where起到了先過濾后排序的作用
row_number() over(partition by userid order by paymenttime) row_con
from sixth
where substring(`paymenttime`, 1,7) ='2017-10'
) t1
where t1.row_con=1;第7題
現有圖書管理資料庫的三個資料模型如下:
圖書(資料表名:BOOK)
| 序號 | 欄位名稱 | 欄位描述 | 欄位型別 |
| 1 | BOOK_ID | 總編號 | 文本 |
| 2 | SORT | 分類號 | 文本 |
| 3 | BOOK_NAME | 書名 | 文本 |
| 4 | WRITER | 作者 | 文本 |
| 5 | OUTPUT | 出版單位 | 文本 |
| 6 | PRICE | 單價 | 數值(保留小數點后2位) |
讀者(資料表名:READER)
| 序號 | 欄位名稱 | 欄位描述 | 欄位型別 |
| 1 | READER_ID | 借書證號 | 文本 |
| 2 | COMPANY | 單位 | 文本 |
| 3 | NAME | 姓名 | 文本 |
| 4 | SEX | 性別 | 文本 |
| 5 | GRADE | 職稱 | 文本 |
| 6 | ADDR | 地址 | 文本 |
借閱記錄(資料表名:BORROW LOG)
| 序號 | 欄位名稱 | 欄位描述 | 欄位型別 |
| 1 | READER_ID | 借書證號 | 文本 |
| 2 | BOOK_D | 總編號 | 文本 |
| 3 | BORROW_ATE | 借書日期 | 日期 |
(1)創建圖書管理庫的圖書、讀者和借閱三個基本表的表結構,請寫出建表陳述句,
(2)找出姓李的讀者姓名(NAME)和所在單位(COMPANY),
(3)查找“高等教育出版社”的所有圖書名稱(BOOK_NAME)及單價(PRICE),結果按單價降序排序,
(4)查找價格介于10元和20元之間的圖書種類(SORT)出版單位(OUTPUT)和單價(PRICE),結果按出版單位(OUTPUT)和單價(PRICE)升序排序,
(5)查找所有借了書的讀者的姓名(NAME)及所在單位(COMPANY),
(6)求”科學出版社”圖書的最高單價、最低單價、平均單價,
(7)找出當前至少借閱了2本圖書(大于等于2本)的讀者姓名及其所在單位,
select
t1.name,
t1.company
from
(
select
r.name name,
r.company company
from borrow_log b
join reader r on
b.reader_id=r.reader_id
) t1
group by t1.name,t1.company having count(*)>=2;(8)考慮到資料安全的需要,需定時將“借閱記錄”中資料進行備份,請使用一條SQL陳述句,在備份用戶bak下創建與“借閱記錄”表結構完全一致的資料表BORROW_LOG_BAK.井且將“借閱記錄”中現有資料全部復制到BORROW_1.0G_ BAK中,
create table if not exists borrow_log_bak
select * from borrow_log;(9)現在需要將原Oracle資料庫中資料遷移至Hive倉庫,請寫出“圖書”在Hive中的建表陳述句(Hive實作,提示:列分隔符|;資料表資料需要外部匯入:磁區分別以month_part、day_part 命名)
(10)Hive中有表A,現在需要將表A的月磁區 201505 中 user_id為20000的user_dinner欄位更新為bonc8920,其他用戶user_dinner欄位資料不變,請列出更新的方法步驟,(Hive實作,提示:Hlive中無update語法,請通過其他辦法進行資料更新)
hive在1.1.0版本之前不可以更新資料,在之后可以更改在建表后面添加: stored as orc TBLPROPERTIES('transactional'='true')
但update操作非常慢
第8題
有一個線上服務器訪問日志格式如下(用sql答題)
時間 介面 ip地址
2016-11-09 14:22:05 /api/user/login 110.23.5.33
2016-11-09 14:23:10 /api/user/detail 57.3.2.16
2016-11-09 15:59:40 /api/user/login 200.6.5.166
… …
求11月9號下午14點(14-15點),訪問/api/user/login介面的top10的ip地址
create table eight_log(`date` string,interface string ,ip string);
insert into table eight_log values ('2016-11-09 11:22:05','/api/user/login','110.23.5.23');
insert into table eight_log values ('2016-11-09 11:23:10','/api/user/detail','57.3.2.16');
insert into table eight_log values ('2016-11-09 23:59:40','/api/user/login','200.6.5.166');
insert into table eight_log values('2016-11-09 11:14:23','/api/user/login','136.79.47.70');
insert into table eight_log values('2016-11-09 11:15:23','/api/user/detail','94.144.143.141');
insert into table eight_log values('2016-11-09 11:16:23','/api/user/login','197.161.8.206');
insert into table eight_log values('2016-11-09 12:14:23','/api/user/detail','240.227.107.145');
insert into table eight_log values('2016-11-09 13:14:23','/api/user/login','79.130.122.205');
insert into table eight_log values('2016-11-09 14:14:23','/api/user/detail','65.228.251.189');
insert into table eight_log values('2016-11-09 14:15:23','/api/user/detail','245.23.122.44');
insert into table eight_log values('2016-11-09 14:17:23','/api/user/detail','22.74.142.137');
insert into table eight_log values('2016-11-09 14:19:23','/api/user/detail','54.93.212.87');
insert into table eight_log values('2016-11-09 14:20:23','/api/user/detail','218.15.167.248');
insert into table eight_log values('2016-11-09 14:24:23','/api/user/detail','20.117.19.75');
insert into table eight_log values('2016-11-09 15:14:23','/api/user/login','183.162.66.97');
insert into table eight_log values('2016-11-09 16:14:23','/api/user/login','108.181.245.147');
insert into table eight_log values('2016-11-09 14:17:23','/api/user/login','22.74.142.137');
insert into table eight_log values('2016-11-09 14:19:23','/api/user/login','22.74.142.137');select
ip,
count(*) ct
from
eight_log
where
substring(`date`,1,13)>='2016-11-09 14'
and
substring(`date`,1,13)<'2016-11-09 15'
and interface ='/api/user/login'
group by
ip
order by
ct desc
limit 10;第9題
有一個充值日志表如下:
CREATE TABLE `credit_log`
(
`dist_id` int(11)DEFAULT NULL COMMENT '區組id',
`account` varchar(100)DEFAULT NULL COMMENT '賬號',
`money` int(11) DEFAULT NULL COMMENT '充值金額',
`create_time` datetime DEFAULT NULL COMMENT '訂單時間'
)ENGINE=InnoDB DEFAUILT CHARSET-utf8
請寫出SQL陳述句,查詢充值日志表2015年7月9號每個區組下充值額最大的賬號,要求結果:
區組id,賬號,金額,充值時間
create table nine_log(
dist_id int,
account string,
money int,
create_time string
)
insert into table nine_log values (1,'001',100,'2015-07-09');
insert into table nine_log values (1,'002',500,'2015-07-09');
insert into table nine_log values (2,'001',200,'2015-07-09');select
t1.dist_id,
t1.account,
t1.money,
t1.create_time
from
(
select
dist_id,
account,
create_time,
money,
rank() over(partition by dist_id order by money desc) rank
from nine_log
where create_time='2015-07-09'
)t1
where rank=1;
create table nine_log(
dist_id int,
account string,
money int,
create_time string
)select
t1.dist_id,
t1.account,
t1.money,
t1.create_time
from
(
select
dist_id,
account,
create_time,
money,
rank() over(partition by dist_id order by money desc) rank
from nine_log
where create_time='2015-07-09'
)t1
where rank=1;第10題
有一個賬號表如下,請寫出SQL陳述句,查詢各自區組的money排名前十的賬號(分組取前10)
CREATE TABIE `account`
(
`dist_id` int(11)
DEFAULT NULL COMMENT '區組id',
`account` varchar(100)DEFAULT NULL COMMENT '賬號' ,
`gold` int(11)DEFAULT NULL COMMENT '金幣'
PRIMARY KEY (`dist_id`,`account_id`),
)ENGINE=InnoDB DEFAULT CHARSET-utf8第11題
1)有三張表分別為會員表(member)銷售表(sale)退貨表(regoods)
(1)會員表有欄位memberid(會員id,主鍵)credits(積分);
(2)銷售表有欄位memberid(會員id,外鍵)購買金額(MNAccount);
(3)退貨表中有欄位memberid(會員id,外鍵)退貨金額(RMNAccount);
2)業務說明:
(1)銷售表中的銷售記錄可以是會員購買,也可是非會員購買,(即銷售表中的memberid可以為空)
(2)銷售表中的一個會員可以有多條購買記錄
(3)退貨表中的退貨記錄可以是會員,也可是非會員
(4)一個會員可以有一潭訓多條退貨記錄
查詢需求:分組查出銷售表中所有會員購買金額,同時分組查出退貨表中所有會員的退貨金額,把會員id相同的購買金額-退款金額得到的結果更新到會員表中對應會員的積分欄位(credits)
create table member(
memberid int,
credits double
);
create table sale(
memberid int,
MNAccount double
);
insert into sale values(1,345.9);
insert into sale values(1,3435.9);
insert into sale values(1,3245.9);
insert into sale values(2,3435.9);
insert into sale values(3,2345.9);
insert into sale values(3,3345.9);
insert into sale values(null,345.9);
create table regoods(
memberid int,
RMNAccount double
);
insert into regoods values(1,256.9);
insert into regoods values(1,2526.9);
insert into regoods values(1,2516.9);
insert into regoods values(2,2546.9);
insert into regoods values(3,2156.9);
insert into regoods values(3,2256.9);
insert into regoods values(null,256.9);insert into table member
select t1.memberid memberid,
t1.MNAccount - t2.RMNAccount credits
from (select memberid,
sum(MNAccount) MNAccount
from sale
where memberid is not null
group by memberid) t1
join
(select memberid,
sum(RMNAccount) RMNAccount
from regoods
where memberid is not null
group by memberid) t2
on t1.memberid = t2.memberid第12題 百度
現在有三個表student(學生表)、course(課程表)、score(成績單),結構如下:
create table student
(
id bigint comment ‘學號’,
name string comment ‘姓名’,
age bigint comment ‘年齡’
);
create table course
(
cid string comment ‘課程號,001/002格式’,
cname string comment ‘課程名’
);
Create table score
(
uid bigint comment ‘學號’,
cid string comment ‘課程號’,
score bigint comment ‘成績’
) partitioned by(event_day string)
insert into student values(1,'zhangsan1',18);
insert into student values(2,'zhangsan2',19);
insert into student values(3,'zhangsan3',16);
insert into student values(4,'zhangsan4',13);
insert into student values(5,'zhangsan5',20);
insert into student values(6,'zhangsan6',24);
insert into student values(7,'zhangsan7',23);
create table course
(
cid string ,
cname string
);
insert into course values ('001','math');
insert into course values ('002','english');
insert into course values ('003','chinese');
DROP table if exists score;
Create table score
(
Id bigint,
cid string ,
score bigint
)
partitioned by(event_day string)
insert into score partition(event_day ='20190301') values (1,'001',50);
insert into score partition(event_day ='20190301') values (1,'002',55);
insert into score partition(event_day ='20190301') values (1,'003',60);
insert into score partition(event_day ='20190301') values (2,'001',null);
insert into score partition(event_day ='20190301') values (2,'002',60);
insert into score partition(event_day ='20190301') values (2,'003',70);
insert into score partition(event_day ='20190301') values (3,'001',80);
insert into score partition(event_day ='20190301') values (3,'002',65);
insert into score partition(event_day ='20190301') values (3,'003',80);
insert into score partition(event_day ='20190301') values (4,'001',70);
insert into score partition(event_day ='20190301') values (4,'002',75);
insert into score partition(event_day ='20190301') values (4,'003',90);
insert into score partition(event_day ='20190301') values (5,'001',null);
insert into score partition(event_day ='20190301') values (5,'002',65);
insert into score partition(event_day ='20190301') values (5,'003',75);
insert into score partition(event_day ='20190301') values (6,'001',65);
insert into score partition(event_day ='20190301') values (6,'002',85);
insert into score partition(event_day ='20190301') values (6,'003',84);
insert into score partition(event_day ='20190301') values (7,'001',65);
insert into score partition(event_day ='20190301') values (7,'002',59);
insert into score partition(event_day ='20190301') values (7,'003',94);其中score中的id、cid,分別是student、course中對應的列請根據上面的表結構,回答下面的問題
1)請將本地檔案(/home/users/test/20190301.csv)檔案,加載到磁區表score的20190301磁區中,并覆寫之前的資料
load data local inpath '/home/users/test/20190301.csv' overwrite into table score partition (event_day='20190301');2)查出平均成績大于60分的學生的姓名、年齡、平均成績
select id,s.name,s.age,avg(score)
from score
group by id having avg(score)>60
join
student s
on s.id=score.id3)查出沒有‘001’課程成績的學生的姓名、年齡
select t2.name,
t2.age
from (select Id
from score
where cid = '001'
and score is null) t1
join student t2
on t1.Id = t2.id;4)查出有‘001’\’002’這兩門課程下,成績排名前3的學生的姓名、年齡
select t2.id,
student.age
from (select id
from (select *,
rank() over (partition by cid order by score desc) rank
from score
where cid = '001'
or cid = '002') t1
where rank <= 3) t2
join student
on t2.id = student.id
group by t2.id, student.age;
--最后的group by是為了去重5)創建新的表score_20190317,并存入score表中20190317磁區的資料
create table if not exists score_20190317 as select * from score where event_dayk='20190317';6)如果上面的score表中,uid存在資料傾斜,請進行優化,查出在20190101-20190317中,學生的姓名、年齡、課程、課程的平均成績
##map資料傾斜時負載均衡
set hive.map.aggr = true
##groupby資料傾斜時負載均衡
set hive.groupby.skewindata = true
select
uid,
cid,
avg(score),
s.age
from score
where event_day>='20190101' and event_day<='20190317'
group by uid,cid
join
student s
on s.id=score.uidHive中的Predicate Pushdown簡稱謂詞下推,主要思想是把過濾條件下推到map端,提前執行過濾,以減少map到reduce的傳輸資料,提升整體性能
所謂下推,即謂詞過濾在map端執行;所謂不下推,即謂詞過濾在reduce端執行
inner join時,謂詞任意放都會下推
left join時,左表的謂詞應該寫在where后,右表的謂詞應寫在join后
right join時,左表的謂詞應該寫在join后,右表的謂詞應寫在where后
7)描述一下union和union all的區別,以及在mysql和HQL中用法的不同之處?
8)簡單描述一下lateral view語法在HQL中的應用場景,并寫一個HQL實體
比如一個學生表為:
| 學號 | 姓名 | 年齡 | 成績(語文|數學|英語) |
| 001 | 張三 | 16 | 90,80,95 |
需要實作效果:
| 學號 | 成績 |
| 001 | 90 |
| 001 | 80 |
| 001 | 95 |
create table student(
`id` string,
`name` string,
`age` int,
`scores` array<string>
)
row format delimited fields terminated by '\t'
collection items terminated by ',';
select
id,
score
from
student lateral view explode(scores) tmp_score as score;第13題
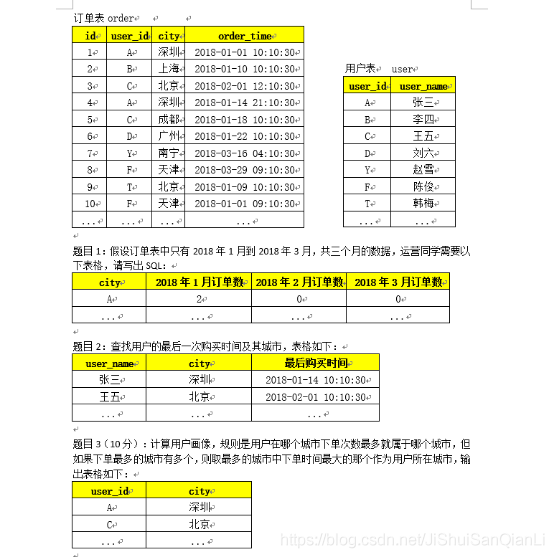
第14題
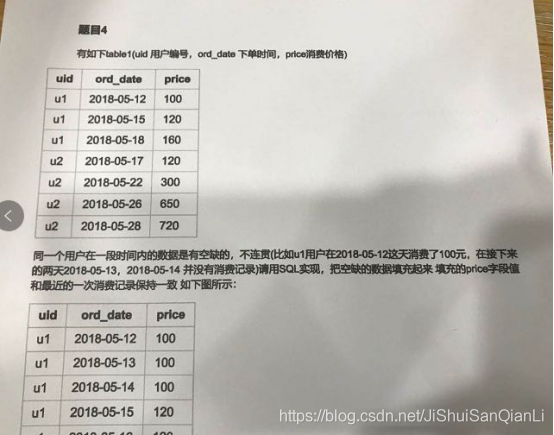
第15題
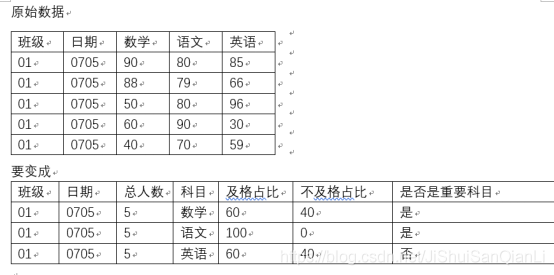
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291814.html
標籤:其他