使用 ES + 云開發實戰優化網站搜索
大家好,我是魚皮,今天搞一場技術實戰,需求分析 => 技術選型 => 設計實作,從 0 到 1,帶大家優化網站搜索的靈活性,
ES + 云開發搜索優化實戰
本文大綱:
背景
我開發的 編程導航網站 已經上線 6 個月了,但是從上線之初,網站一直存在一個很嚴重的問題,就是搜索功能并不好用,
此前,為了追求快速上線,搜索功能就簡單地使用了資料庫模糊查詢(包含)來實作,開發是方便了,但這種方式很不靈活,
舉個例子,網站上有個資源叫 “Java 設計模式”,而用戶搜索 “Java設計模式” 就啥都搜不出來,原因是資源名中包含了空格,而用戶搜索時輸入的關鍵詞并不包含空格,
空格只是一種特例,類似的情況還有很多,比如網站上有個資源叫 “Java 并發編程實戰”,但用戶搜索 “Java 實戰” 時,明明前者包含 “Java” 和 “實戰” 這兩個詞,但卻是什么都搜不出來的,
要知道,搜索功能對于一個資訊聚合類站點是至關重要的,直接影響用戶的體驗,在你的網站上搜不到資源,誰還會用?
所以我也收到了一些小伙伴的禮貌建議,比如這位禿頭 Tom:

之前沒有優化搜索,主要是兩個原因:窮 + 怕麻煩,但隨著網站用戶量的增大,是時候填坑了!
技術選型
想要提高網站搜索靈活性,可以使用 全文搜索 技術,在前端和后端都可以實作,
前端全文搜索
有時,我們要檢索的資料是有限的,且所有資料都是 存盤在客戶端 的,
比如個人博客網站,我們通常會把每篇文章作為一個檔案存放在某目錄下,而不是存在后臺資料庫中,這種情況下,不需要再從服務器上去請求動態資料,那么可以直接在前端搜索資料,
有一些現成的搜索庫,比如 Lunr.js(GitHub 7k+ star),先添加要檢索的內容:
var idx = lunr(function () {
this.field('title')
this.field('body')
// 內容
this.add({
"title": "yupi",
"body": "wx搜程式員魚皮,閱讀我的原創文章",
"id": "1"
})
})
然后搜索就可以了:
idx.search("魚皮")
純前端全文搜索的好處是無需后端、簡單方便,可以節省服務器的壓力;無需連網,也沒有額外的網路開銷,檢索更快速,
后端全文搜索
區別于前端,后端全文搜索在服務器上完成,從遠程資料庫中搜索符合要求的資料,再直接回傳給前端,
目前主流的后端全文搜索技術是 Elasticsearch,一個分布式、RESTful 風格的搜索和資料分析引擎,

它的功能強大且靈活,但是需要自己搭建、定義資料、管理詞典、上傳和維護資料等,可操作性很強,需要一些水平,新手和大佬設計出的 ES 搜索系統那是天差地別,
所以,對于不熟悉 Elasticsearch 的同學,也可以直接使用現成的全文檢索服務,比如 Algolia,直接通過它提供的 API 上傳需要檢索的資料,再用它提供的 API 檢索就行了,它提供了一定的免費空間,對于小型網站和學習使用完全足夠了,
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-vXPF94km-1627881820886)(https://qiniuyun.code-nav.cn/image-20210729130939206.png)]
選擇
那么我的編程導航網站選擇哪種實作方式呢?
首先,該網站的資源數是不固定的、無規律動態更新的,因此不適合前端全文檢索,
其次,考慮到日后網站的資料量會比較大,而且可能要根據用戶的搜索動態地去優化檢索系統(比如自定義編程詞典),因此考慮使用 Elasticsearch 技術 自行搭建搜索引擎,而不用現成的全文檢索服務,這樣今后自己想怎么定制系統都可以,此外,不用向其他平臺發送網站資料,能保證資料的安全,

ES 安裝
確定使用 Elasticsearch 后,要先搭建環境,
可以自己購買服務器,再按照官方檔案一步步手動安裝,對于有一定規模的個人網站來說,雖然搭建程序不難,但后期的維護成本卻是巨大的,比如性能分析、監控、告警、安全等等,都需要自己來配置,尤其是后期網站資料量更大了,還要考慮搭建集群、水平擴容等等,
因此,我選擇直接使用云服務商提供的 Elasticsearch 服務,這里選擇騰訊云,自動為你搭建了現成的 ES 集群服務,還提供了可視化架構管理、集群監控、日志、高級插件、智能巡檢等功能,
雖然 ES 服務的價格貴,但節省下大量時間成本,對我來說是值得的,
還有個很方便的定制化搜索服務 Elastic App Search,大家感興趣可以試試,
ES 公共服務
我們的目標是優化網站資源的搜索功能,但接下來要做的不是直接撰寫具體的業務邏輯,而是先開發一個 公共的 ES 服務 ,
其實對 ES 的操作比較簡單,可以先簡單地把它理解為一個資料庫,那么公共的 ES 服務應具有基本的增刪改查功能,供其他函式呼叫,
實作
由于編程導航的后端使用的是騰訊云開發技術,用 Node.js 來撰寫服務,所以選用官方推薦的 @elastic/elasticsearch 庫來操作 ES,
沒用過云開發也沒事,可以先把它理解為一個后端,歡迎閱讀我之前的文章:了解云開發 ,
代碼很簡單,先是建立和 ES 的連接,此處為了保證資料安全,使用內網地址:
const client = new Client({
// 內網地址
node: 'http://10.0.61.1:9200',
// 用戶名和密碼
auth: {
username: esConfig.username,
password: esConfig.password,
},
});
然后是撰寫增刪改查,這里做一步 抽象,通過 switch 等分支陳述句,根據請求引數來區分操作、要操作的資料等,這樣就不用把每個操作都獨立寫成一個介面了,
// 接受請求引數
const { op, index, id, params } = event;
// 根據操作執行增刪改查
switch (op) {
case 'add':
return doAdd(index, id, params);
case 'delete':
return doDelete(index, id);
case 'search':
return doSearch(index, params);
case 'update':
return doUpdate(index, id, params);
}
在云開發中,假如某個函式太久沒被呼叫,就會釋放資源,下次請求時,會進行冷啟動,重新創建資源,導致介面回傳較慢,因此,把多個操作封裝到同一個函式中,也可以減少冷啟動的幾率,
具體的增刪改查代碼就不贅述了,對著 ES Node 的官方檔案看一遍就行了,后面會把代碼開源到編程導航倉庫中(https://github.com/liyupi/code-nav),
本地除錯
撰寫好代碼后,可以用云開發自帶的 tcb 命令列工具在本地執行該函式,
記得先把 ES 的連接地址改成公網,然后輸入一行命令就行了,比如我們要向 ES 插入一條資料,傳入要執行的函式名、請求引數、代碼路徑:
tcb fn run
--name <functionName>
--params "{\"op\": \"add\"}"
--path <functionPath>
執行成功后,就能在 ES 中看到新插入的資料了(通過 Kibana 面板或 curl 查看):

遠程測驗
本地測驗好公共服務代碼后,把 ES 連接地址改成內網 IP,然后發布到云端,
接下來試著撰寫一個其他的函式來訪問公共 ES 服務,比如插入資源到 ES,通過 callFunction 請求:
// 添加資源到 ES
function addData() {
// 請求公共服務
app.callFunction({
name: 'esService',
data: {
op: 'add',
index: 'resource',
id,
params: data,
}
});
}
但是,資料并沒有被成功插入,而是回傳了介面超時,Why?
內網配置
通過日志得知是 ES 連接不上,會不會是因為發布上線的 ES 公共服務所在的機器和 ES 不在同一個內網呢?
所以需要在云開發控制臺更改 ES 公共服務的私有網路配置,選擇和購買 ES 時同樣的子網就行了:
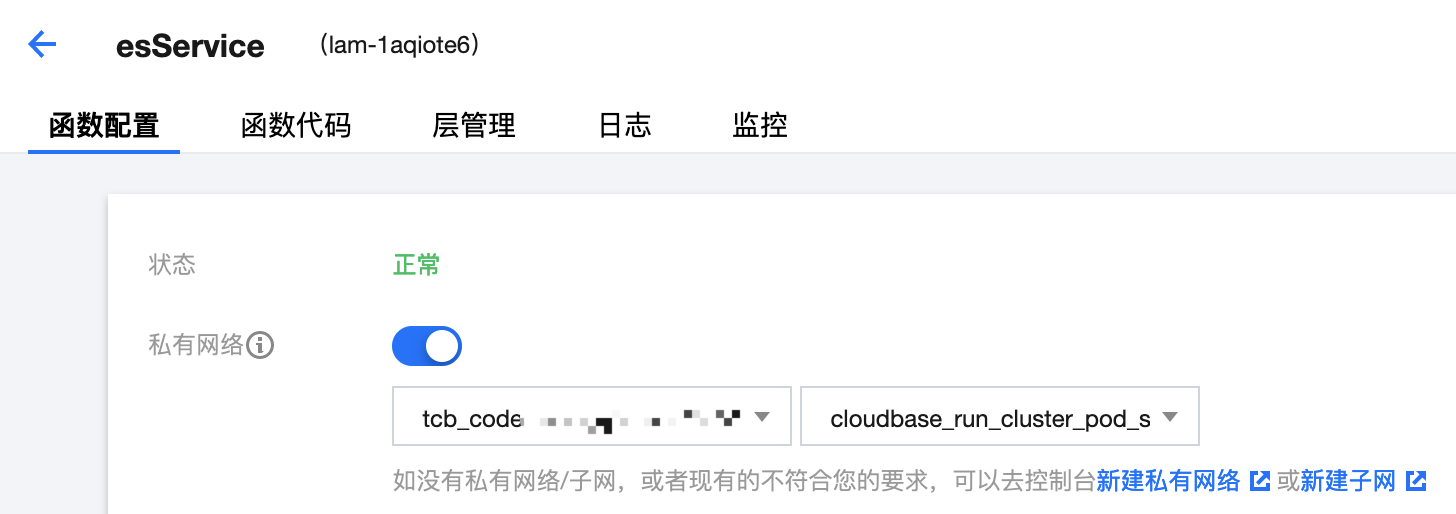
修改之后,再次遠程請求 ES 公共服務,資料就插入成功了~
資料索引
開發好 ES 公共服務后,就可以撰寫具體的業務邏輯了,
首先要在 ES 中建立一個索引(類似資料庫的表),來約定資料的型別、分詞等資訊,而不是允許隨意插入資料,
比如為了更靈活搜索,資源名應該指定為 “text” 型別,以開啟分詞,并指定 ik 中文分詞器:
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
而點贊數應設定為 “long” 型別,只允許傳入數字:
"likeNum": {
"type": "long"
}
最好還要為索引指定一個別名,便于后續修改欄位時重建索引:
"aliases" : { "resource": {}}
撰寫好建立索引的 json 配置后,通過 curl 或 Kibana 去呼叫 ES 新建索引介面就行了,
資料同步
之前,編程導航網站的資源資料都是存在資料庫中的,用戶從資料庫中查詢,而現在要改為從 ES 中查詢,ES 空空如也可不行,得想辦法把資料庫中的資源資料同步到 ES 中,
這里有幾種同步策略,
雙寫
以前,用戶推薦的資源只會插入到資料庫,雙寫是指在資源插入資料庫的時候,同時插入到 ES 就好了,
聽上去挺簡單的,但這種方式存在一些問題:
- 會改動以前的代碼,每個寫資料庫的地方都要補充寫入 ES,
- 會存在一邊兒寫入失敗、另一邊兒成功的情況,導致資料庫和 ES 的資料不一致,

那有沒有對現有代碼 侵入更小 的方法呢?
定時同步
如果對資料實時性的要求不高,可以選擇定時同步,每隔一段時間將最新插入或修改的資料從資料庫復制到 ES 上,
實作方式有很多種,比如用 Logstash 資料傳輸管道,或者自己撰寫定時任務程式,這樣就完全不用改現有的代碼,
實時同步
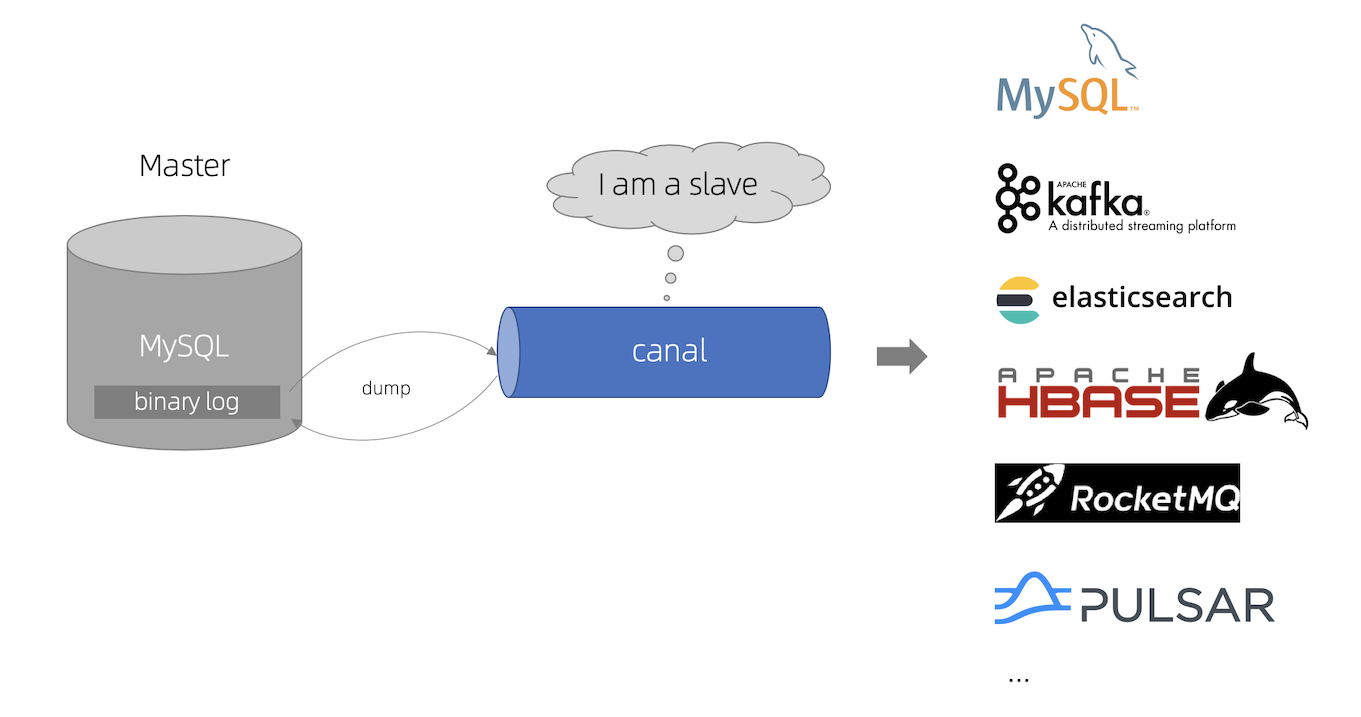
如果對資料實時性要求很高,剛剛插入資料庫的資料就要能立刻就能被搜索到,那么就要實時同步,除了雙寫外,還可以監聽資料庫的 binlog,在資料庫發生任何變更時,我們都能感知到,
阿里有個開源專案叫 Canal ,能夠實時監聽 MySQL 資料庫,并推送通知給下游,感興趣的朋友可以看看,
實作
由于編程資源的搜索對實時性要求不高,所以定時同步就 ok,
云開發默認提供了定時函式功能,我就直接寫一個云函式,每 1 分鐘執行一次,每次讀取資料庫中近 5 分鐘內發生了變更的資料,以防止上次執行失敗的情況,此外,還要配置超時時間,防止函式執行時間過長導致的執行失敗,
在云開發 - 云函式控制臺就能可視化配置了,需要為定時任務指定一個 crontab 運算式:

開啟定時同步后,不要忘了再撰寫并執行一個 首次 同步函式,用于將歷史的全量資料同步到 ES,
資料檢索
現在 ES 上已經有資料了,只剩最后一步,就是怎么把資料搜出來呢?
首先我們要學習 ES 的搜索 DSL(語法),包括如何取列、搜索、過濾、分頁、排序等,對新手來講,還是有點麻煩的,尤其是查詢條件中布爾運算式的組合,稍微不注意就查不出資料,所以建議大家先在 Kibana 提供的除錯工具中撰寫查詢語法:

查出預期的資料后,再撰寫后端的搜索函式,接受的請求引數最好和原介面保持一致,減少改動,
可以根據前端傳來的請求動態拼接查詢語法,比如要按照資源名搜索:
// 傳了資源名if (name) { // 拼接查詢陳述句 query.bool.should = [ { match: { name } } ];}
由此,整個網站的搜索優化完畢,
再去試一下效果,現在哪怕我輸入一些多 “魚” 的詞,也能搜到了!
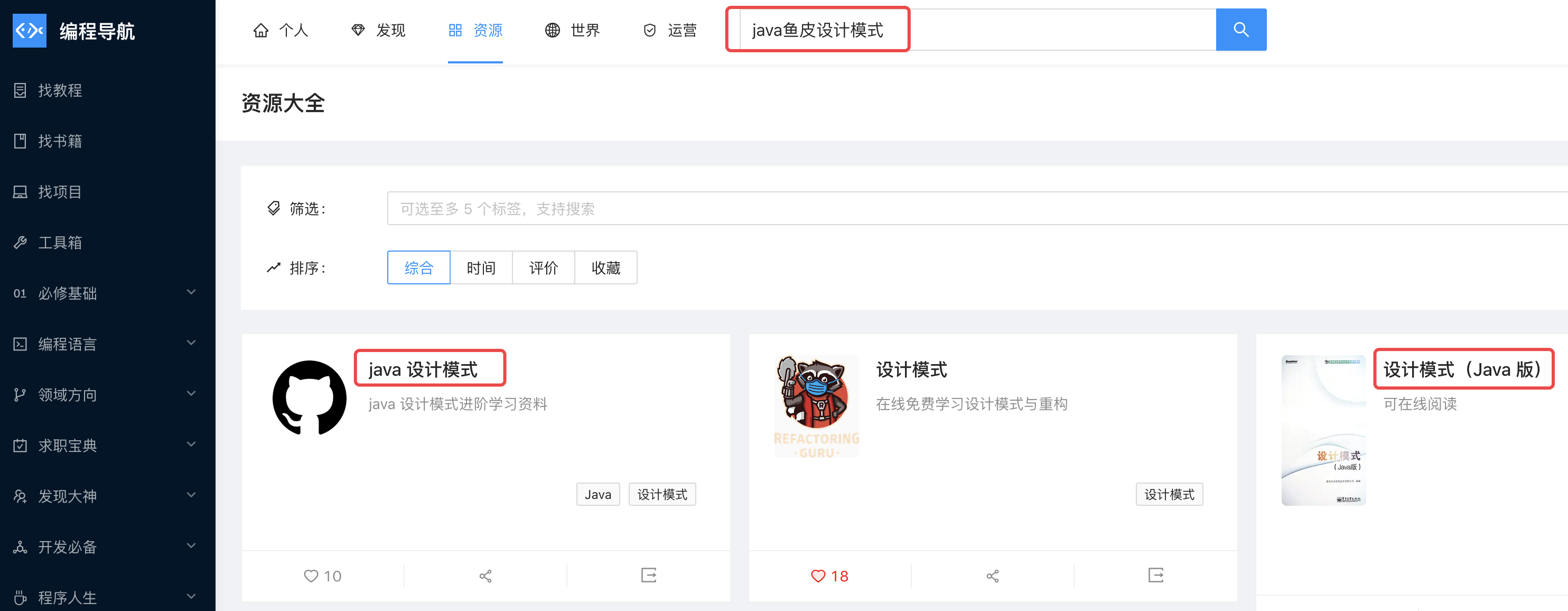
ES 是怎么實作靈活搜索的呢?歡迎閱讀 這篇文章 ,
新 ES 搜索介面的發布并不意味著老的資料庫查詢介面淘汰,可以同時保留,按名稱搜索資源時用新介面,更靈活;而根據審核狀態、搜索某用戶發布過的資源時,可以用老介面,從資料庫查,從而分攤負載,職責分離,讓對的技術做對的事情!
以上就是本期分享,有幫助的話點個贊吧 ??
我是魚皮,最后再送大家一些 幫助我拿到大廠 offer 的學習資料:
跑了,留下 6T 的資源!
歡迎閱讀 我從 0 自學進入騰訊的編程學習、求職、考證、寫書經歷,不再迷茫!
我學計算機的四年,共勉!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291817.html
標籤:其他