來源:Coursera吳恩達深度學習課程
隨著語音識別的發展,越來越多的設備可以通過你的聲音來喚醒,這有時被叫做觸發字檢測系統(rigger word detection systems),我們來看一看如何建立一個觸發字系統,

觸發字系統的例子包括Amazon echo,它通過單詞Alexa喚醒;還有百度DuerOS設備,通過"小度你好"來喚醒;蘋果的Siri用Hey Siri來喚醒;Google Home使用Okay Google來喚醒,這就是觸發字檢測系統,假如你在臥室中,有一臺Amazon echo,你可以在臥室中簡單說一句: Alexa, 現在幾點了?就能喚醒這個設備,它將會被單詞"Alexa"喚醒,并回答你的詢問,Andrew想教會我們如何構建一個觸發字檢測系統,

如上圖所示,現在有一個這樣的RNN結構,我們要做的就是把一個音頻片段(an audio clip)計算出它的聲譜圖特征(spectrogram features)得到特征向量x^<1>, x^<2>, x^<3>...,然后把它放到RNN中,最后定義我們的目標標簽y,假如音頻片段中的這一點是某人剛剛說完一個觸發字,比如"Alexa",或者"小度你好" 或者"Okay Google",那么在這一點之前,你就可以在訓練集中把目標標簽都設為0,然后在這個點之后把目標標簽設為1,假如在一段時間之后,觸發字又被說了一次,比如是在這個點說的,那么就可以再次在這個點之后把目標標簽設為1,這樣的標簽方案對于RNN來說是可行的,并且確實運行得非常不錯,不過該演算法一個明顯的缺點就是它構建了一個很不平衡的訓練集(a very imbalanced training set),0的數量比1多太多了,
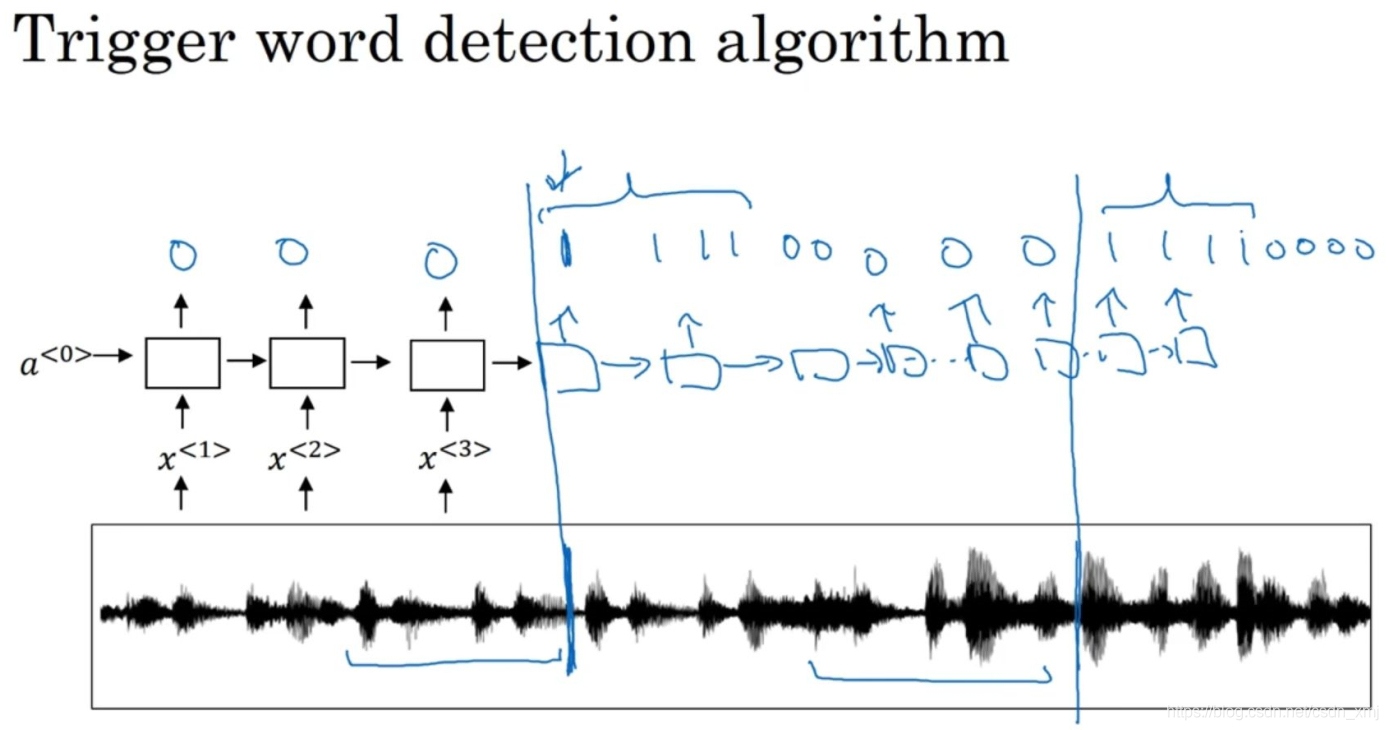
還有一個解決方法,雖然聽起來有點簡單粗暴,但確實能使其變得更容易訓練,如上圖所示,比起只在一個時間步上去輸出1,其實你可以在輸出變回0之前,多次輸出1,或說在固定的一段時間內輸出多個1,這樣就稍微提高了1與0的比例,在音頻片段中,觸發字剛被說完之后,就把多個目標標簽設為1,這里觸發字又被說了一次,說完以后,又讓RNN去輸出1,在之后的編程練習中,你可以進行更多這樣的操作,
Andrew:這就是觸發字檢測,希望你能對自己感到自豪,因為你已經學了這么多深度學習的內容,現在你可以只用幾分鐘時間,就能用一張幻燈片來描述觸發字能夠實作它,并讓它發揮作用,你甚至可能在你的家里用觸發字系統做一些有趣的事情,比如打開或關閉電器,或者可以改造你的電腦,使得你或者其他人可以用觸發字來操作它,
說明:記錄學習筆記,如果錯誤歡迎指正!轉載請聯系我,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291954.html
標籤:其他
上一篇:C語言的掃雷簡化版