為什么我們要deep learning?
你可能很直接說,這個答案很簡單啊,因為越deep,performance就越好,
下面是一個很早年的一個實驗(2011), Interspeech里面的某一篇paper
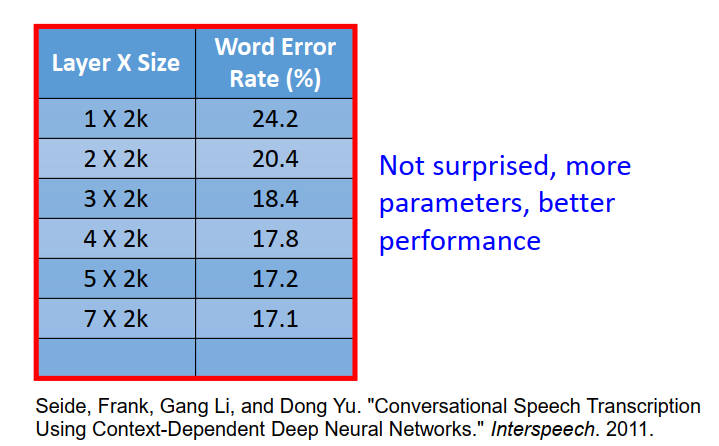
你會發現越來越deep以后,它的performance ,error rate就越來越低,
但是如果你稍微有一個ML的常識的話,這個結果并沒有讓你太surprise,因為本來model越多的parameter它cover的function set就越大,它的bias就越小,如果你今天有夠多的training data去控制它的 variance,一個引數比較多的model她performance比較好是很正常的,
真正要比較deep 和 shallow 的model的時候,應該調整deep 和shallow 的model 讓它們的引數是一樣多的,這樣才是公平的評比,
這種情況下,shallow的model就會是一個矮胖的model,deep的model就會是一個高瘦的model,
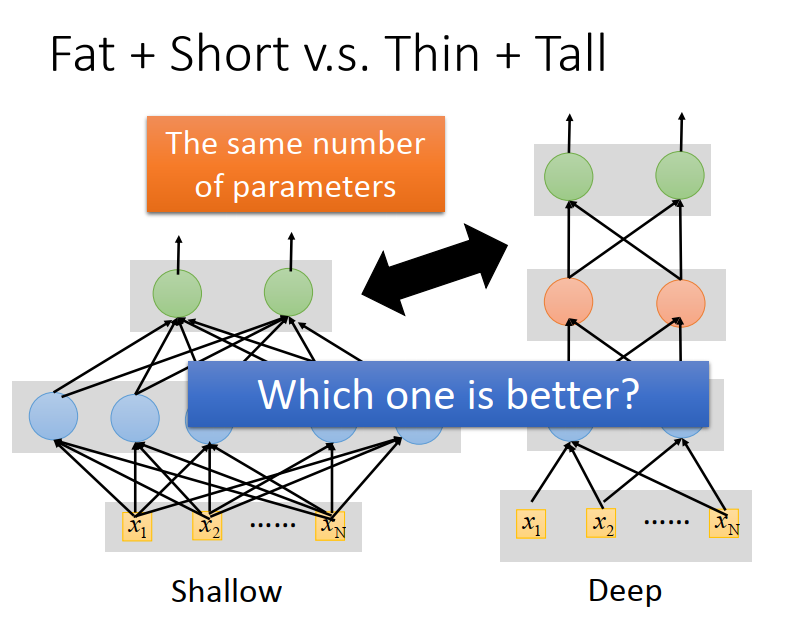
接下來的問題就是在公平的評比下,哪一個model比較強?
剛才那個實驗結果是有后半段的,
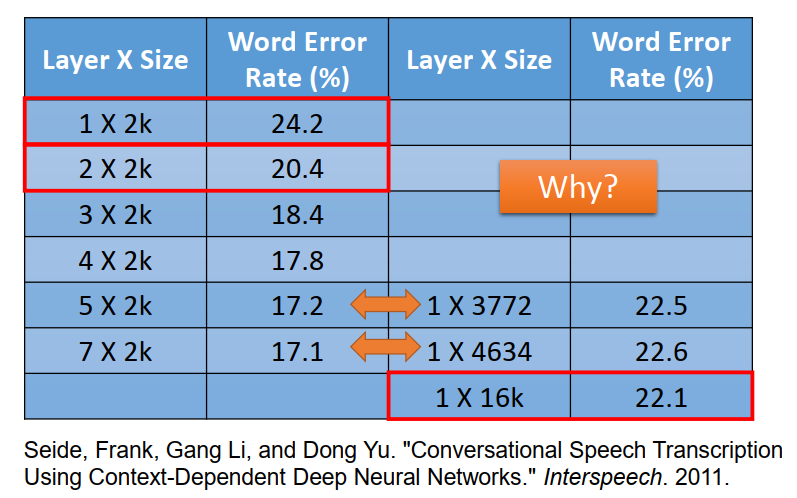
這個時候你會發現 一層的error rate 遠比多層的大,
5x2k 和 1x 3772 引數數目差不多,但error rate卻差很多,
(neuron 數目和引數數目是不一樣的概念,引數是w 和b的數目,)
為什么會這樣呢?
很多人認為,DL會work 是因為DL是暴力的方法,用一個很大很大的model,用一大堆的data,所以就得到了比較好的performance,其實不是這樣的,
如果今天只是單純的增加parameters,但是你是讓network變寬而不是長高的話,其實你對performance的幫助是比較小的,
因為當我們 在做deep learning 的時候其實我們是在做模組化這件事,
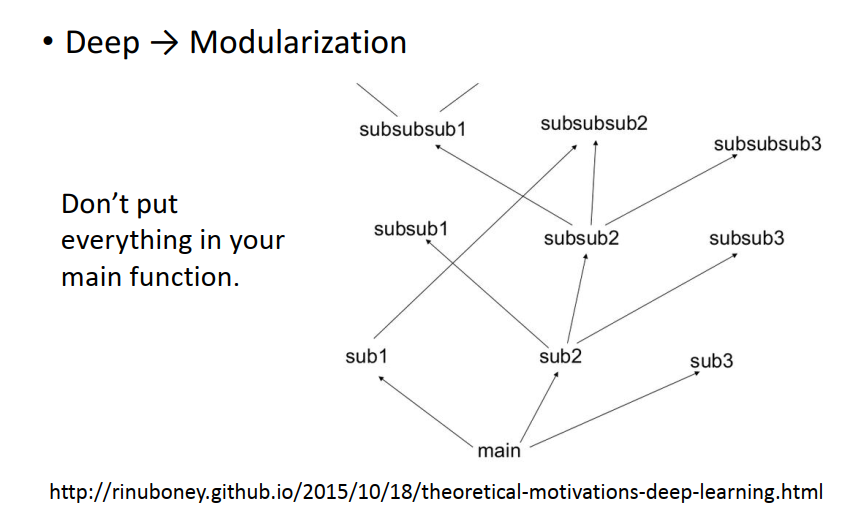
這樣做的好處是有一些function是可以共用的,
提高了復用率,單位神經元效率更高,
影像分類
假設我們要做影像分類
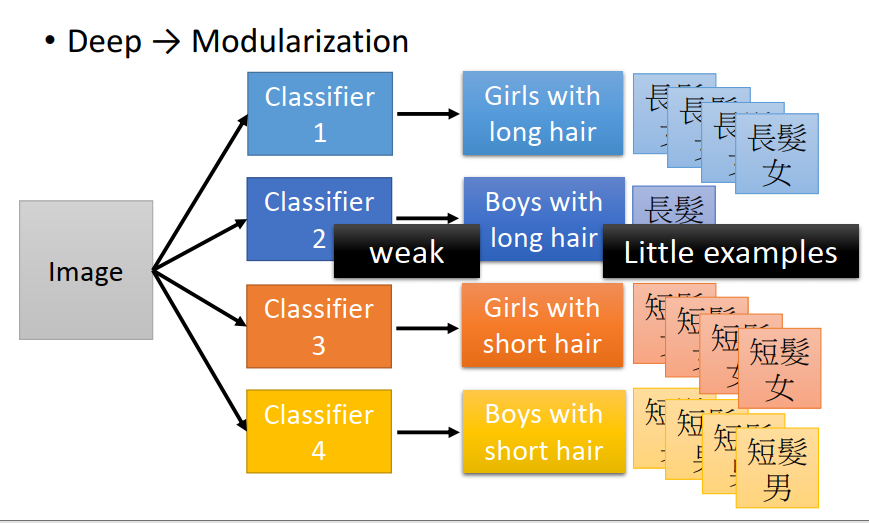
我們要把image分成四類,就去train4個classifier,問題是長頭發男生data是比較少的,
那怎么辦呢?
你可以用模組化的概念,
假設我們現在不是直接去解這個問題,而是把原來的問題切成比較小的

這樣每個基本分類器都可以有足夠的訓練示例,
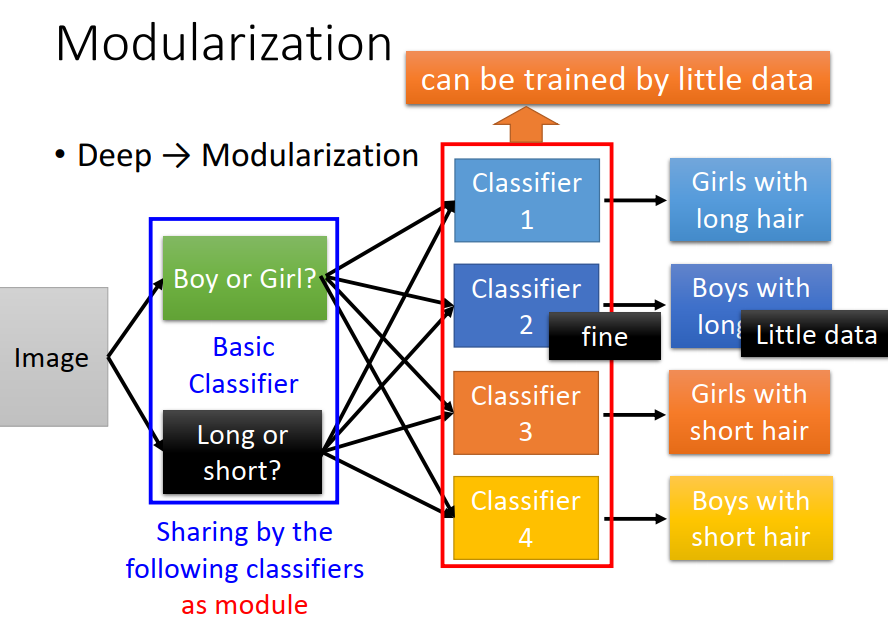
接下來每個classifier 就去參考這些basic classifier
所以后面這些classifier只需要用比較少的Training data就可以把結果做的很好,
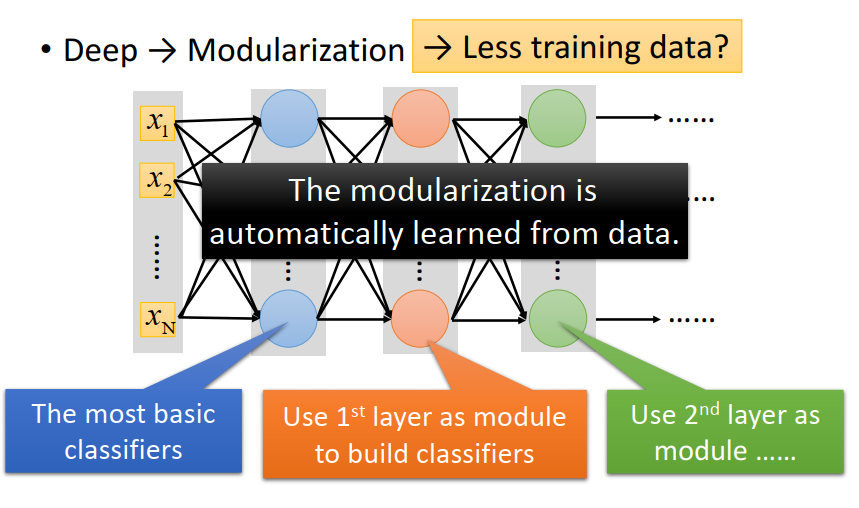
那deep 怎么跟modularization扯上關系呢?
每一個neuron其實就是一個basic classifier
在實做中,怎么做模組化這件事情,是machine 自動學到的,
因為deep做的是modularization 所以deep 需要的Training data是比較少的,
某種程度上machine learning 跟 big data 是相反的,如果資料足夠多,那直接table look up就好了啊,
所以我們才需要machine去做舉一反三這件事情,去做學習這件事情,
所以我們 在做deep learning 的時候就是因為我們沒有足夠的training data ,所以我們才需要deep learning 讓它自己去學習,去舉一反三,
語音辨識
人類語言架構
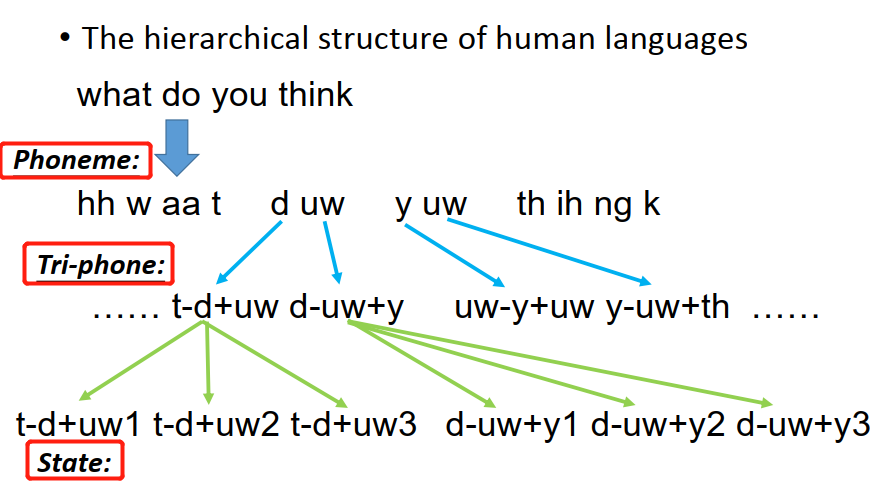
當你說一句話的時候,這句話是由一串 Phoneme組成,
同樣的Phoneme可能會有不一樣的發音,因為人類口腔器官的限制
為了表達這件事情,我們會給同樣的Phoneme不同的model,叫做Tri-phone,
一個Phoneme可以拆成幾個state,
語音辨識非常復雜,我們只講它的第一步
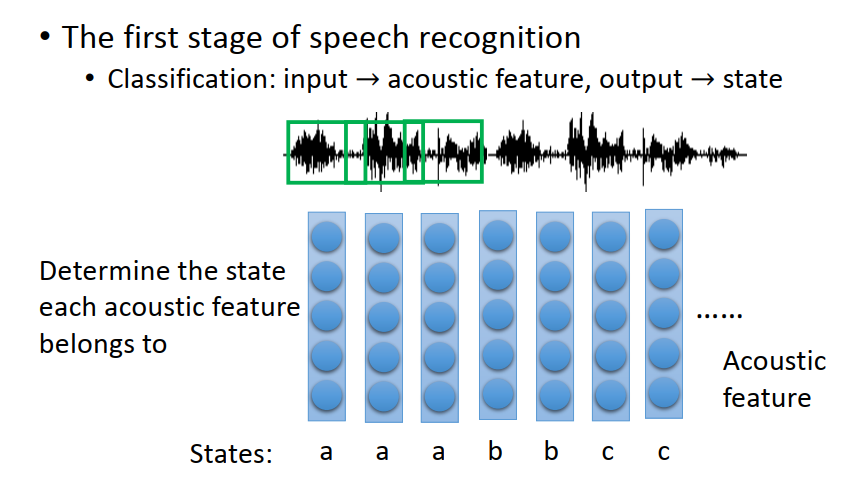
第一步你要做的事情:把acoustic feature 轉成 state,決定這些acoustic feature 屬于那些state,(要做語音辨識系統,還需要把states 轉成Phoneme ,再把Phoneme轉成文字,還要考慮同音異字的問題等等)
我想要比較一下過去用deep learning 之前和用deep learning 之后在語音辨識上模型有什么不同,這樣就更能體會為什么deep learning 在語音上會有更顯著的提升?
傳統的方法:HMM-GMM
我們假設每個state 屬于一個acoustic feature的 分布是stationary的,
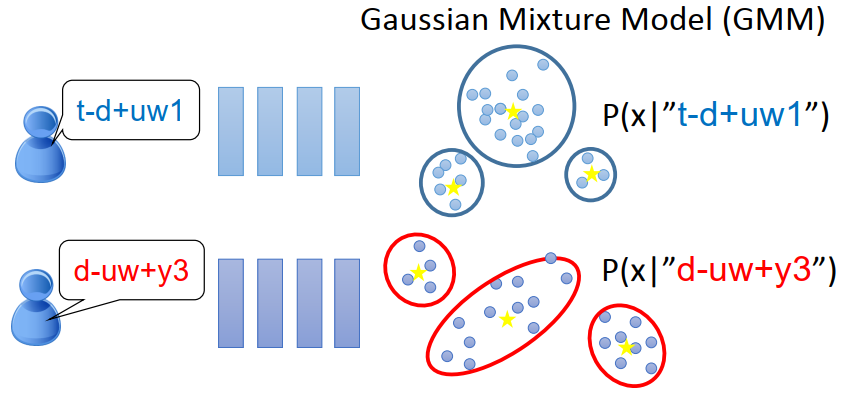
這一招其實根本不太work,因為Tri-phone的數目太多了,
大概兩萬七千個Tri-phone 每個Tri-phone又有3個state,每個state都要用一個Gaussian Mixture Model來描述,引數太多了,你的Training data根本不夠,
有一些不同的state會共用同一個model,由經驗決定那些state共用
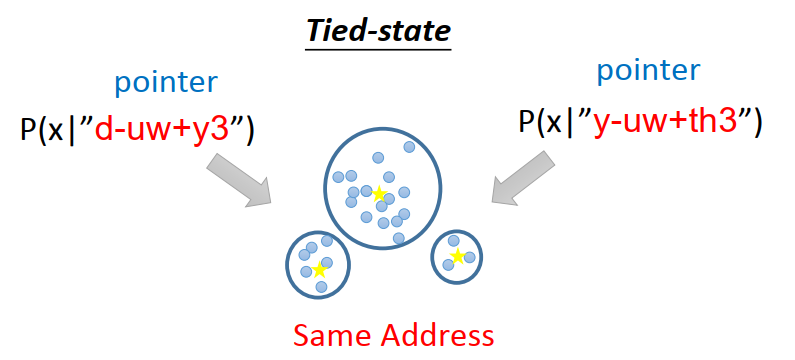
在HMM-GMM中,所有的phoneme都是獨立建模的,這不是模仿人類聲音的有效方法
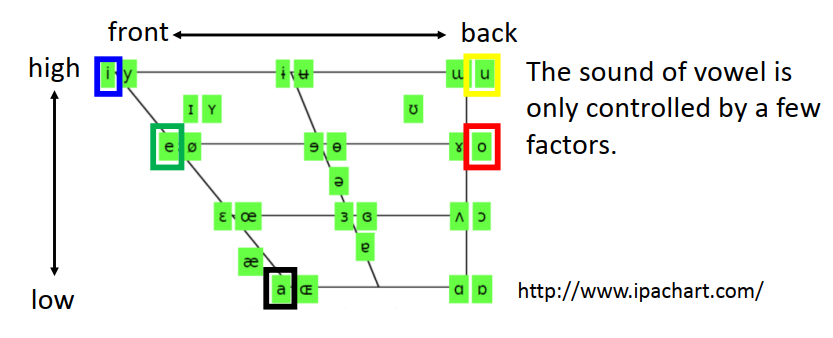
這張圖畫出來人類語言所有的母音,母音的發音只受到三件事情的影響,
舌頭的前后位置,上下位置,嘴型
a -e-i 舌頭是由低到高的,i和u的差別是舌頭前后位置不同,
如果是Deep Learning
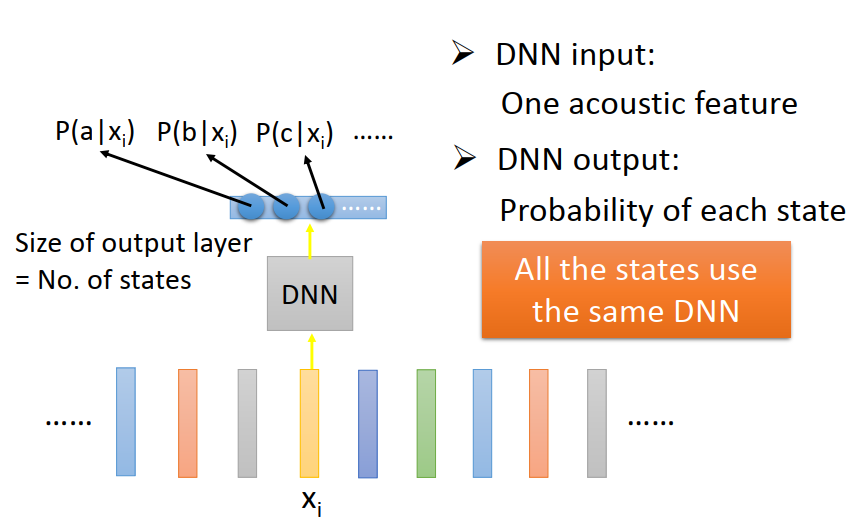
最關鍵的一點是,所有的state都共用一個DNN,
如果今天你把DNN它的某一個hidden layer拿出來,顏色就是5個母音,神奇的是兩者分布是大概相同的
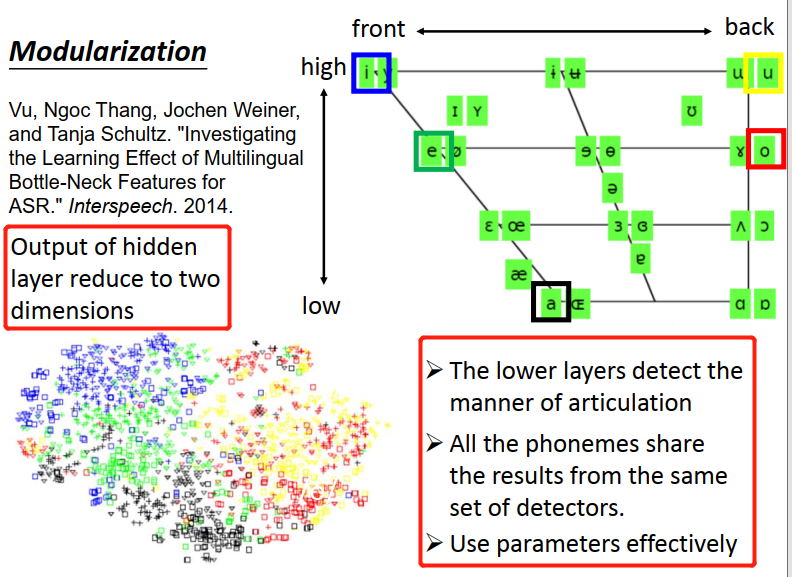
所以你會發現:
DNN 比較 lower的layers 是檢測發音方式
所有的音素共享來自同一套探測器的結果,
有效地使用引數
比較lower(靠近input)的layer先知道了發音方式以后,接下來的layer再根據這個結果去決定說現在的發音是屬于哪一種state或是哪一個phoneme(做到了模組化這件事)
甚至還有一個理論:任何連續的function,input 是一個n維的vector,output 是一個m維的vector,它都可以用一個hidden layer 的neural network來表示,只要你這個hidden layer的neuron 夠多,它可以表示成任何function,

那既然一個hidden layer的neural network 它可以表示成任何function,而我們在做machine learning 的時候想要的就只是一個function而已,
那做Deep 的意義何在呢?
但是這個理論,有一件事沒有告訴我們的是,要做到這件事情效率如何?
是的,淺層網路可以代表任何函式,然而,使用深層結構更有效,
如果上面模組化的概念你沒有聽太懂,那下面舉另外一個例子
其實邏輯電路可以跟neural network類比
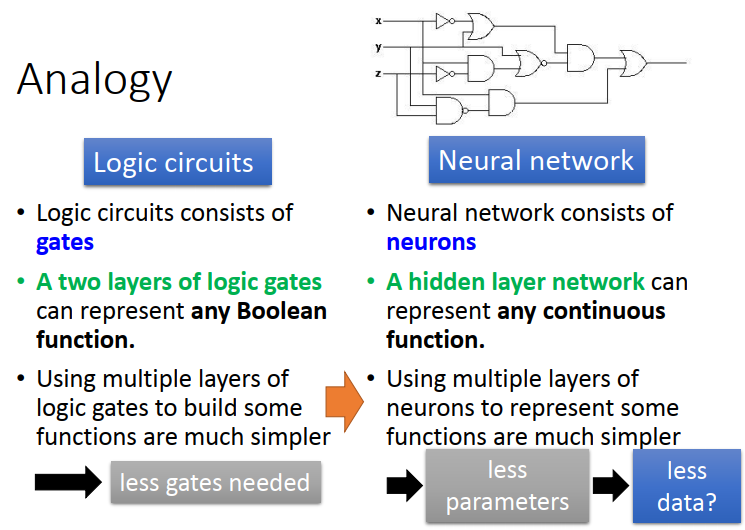
| 邏輯電路: | 神經網路: |
|---|---|
| 邏輯電路由gates組成 | 神經網路由neuron組成 |
| 只要兩層邏輯閘就可以表示任何Boolean function | 一個hidden layer可以表示任意連續函式 |
| 使用多層邏輯門來構建一些電路要簡單得多 =》 | 用多層神經元來表示某些功能要簡單得多 |
兩層邏輯閘就可以表示任何Boolean function ,你可以用兩層邏輯閘就做一臺電腦,但是沒有人這么做,
如果沒有聽懂,在舉一個生活中的例子,
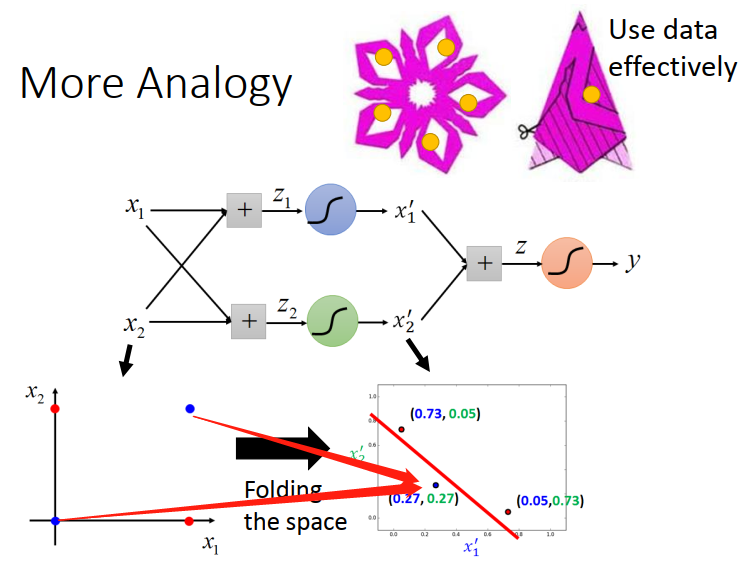
假設input的點有四個,紅色的是一類,藍色的是一類,之前我們說如果你沒有deep learning ,只是linear的model話,無論你怎么做,都沒有辦法把它們分開,
當你加了hidden layer的時候,就做了一個feature transform,好像把這個平面折疊一樣,這就好比說剪窗花的時候把紙折疊,如果你戳一個洞,展開后,折紙其他部分也會有洞,一個data就會發揮5個data的威力,
所以當你做deep learning 的時候,是比較有效率的來使用你的data,
下面是一個實體:
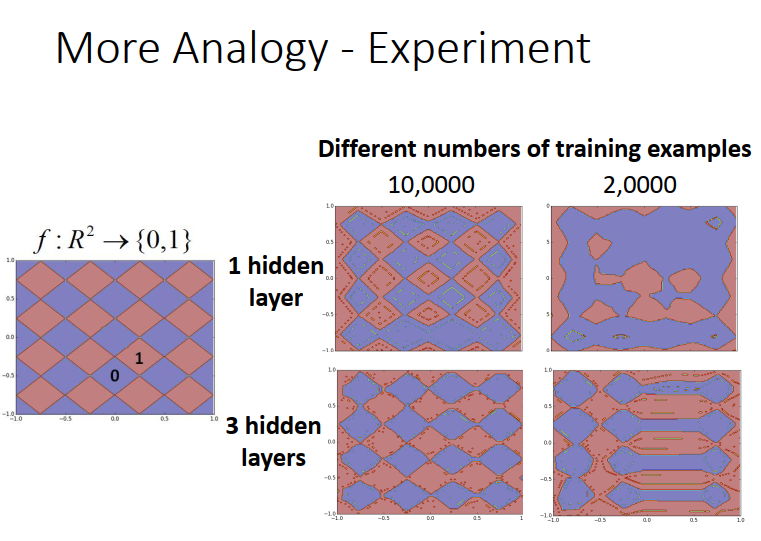
有特別調整1個hidden layer 和3個hidden layer的引數,使其大概相同,
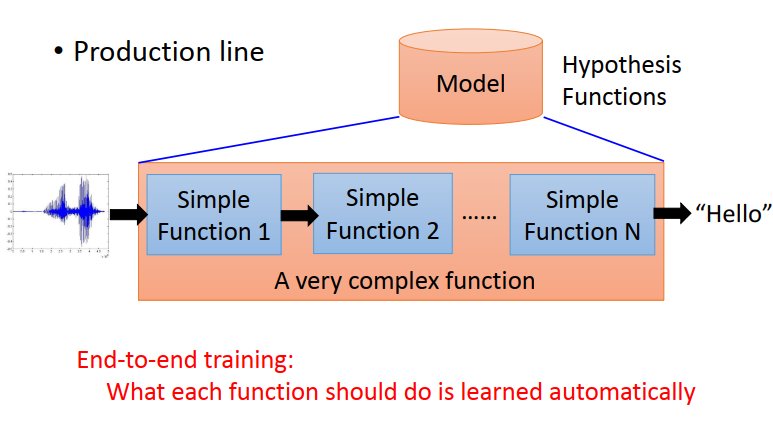
用deep learning 另外一個好處是我們可以做End-to-end Learning
所謂End-to-end Learning 每個函式應該做什么是自動學習的
有時候我們要處理的問題很負責,model 會是一個生產線,這個生產線由很多簡單的function,
沒有deep learning之前:
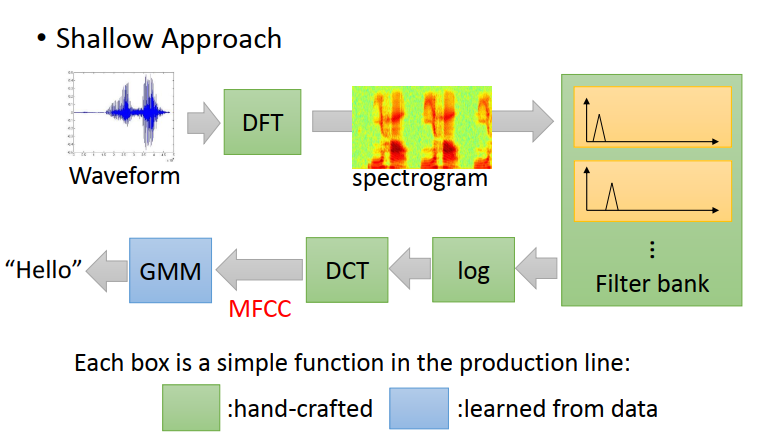
在整個生產線,只有GMM部分是由Training data學出來的,其他綠色都是由“古圣先賢”總結出來的,
用了deep learning 后每個函式應該做什么是自動學習的
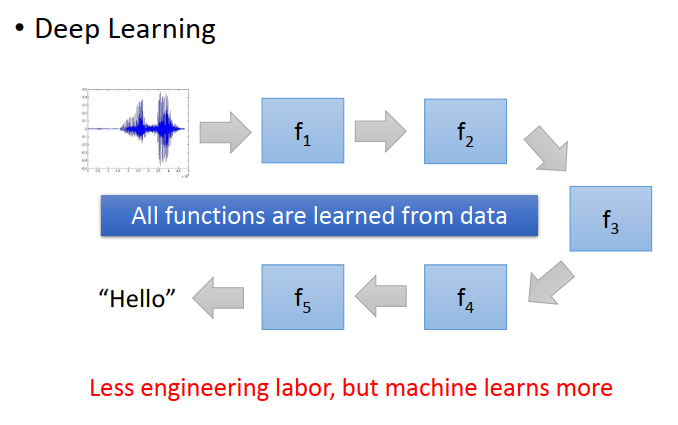
Deep Learning 還有什么好處呢?
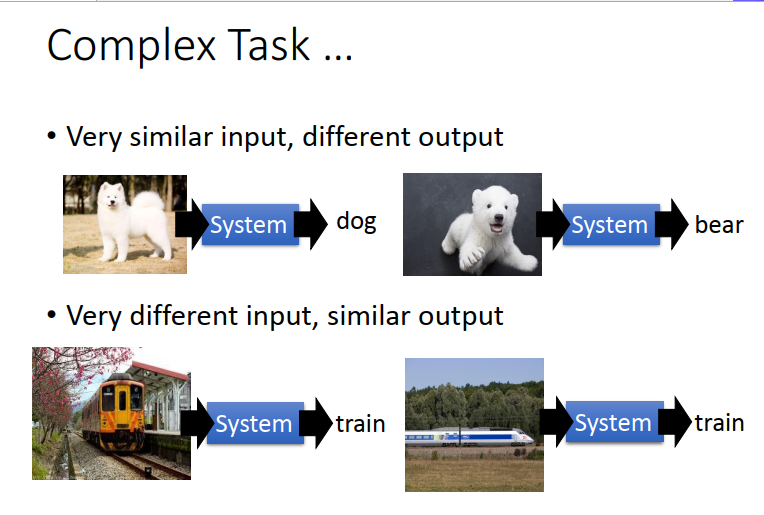
當面對更復雜的task的時候,如果你的network只有一層的話,你沒有辦法把一樣的東西變成不一樣的,沒有辦法把不一樣的變的很想,
語音辨識的實體:

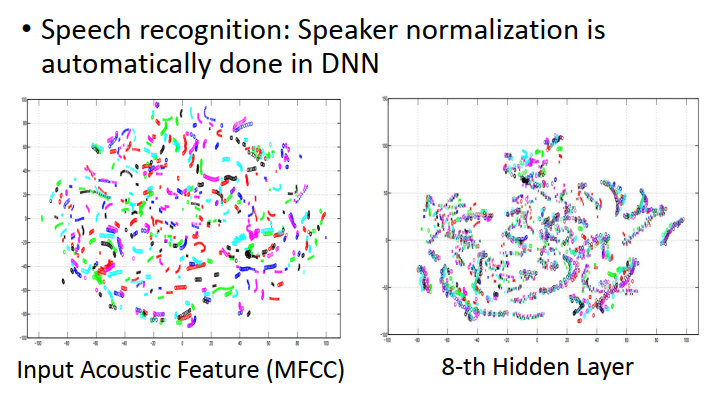
不同的顏色代表不同人說的話,這些人說的句子是一樣的,同樣的句子不同的說,聲音訊號看其實是差別非常大的(左圖),如果你只看第一次的hidden layer,不同人說的同樣的句子看起來還是很不一樣,如果你看第八個hidden layer的時候,不同人說的句子自動被 歸類到一起,
也就是說DNN它把很多看起來很不像的東西,它知道說它們應該是一樣的,在經過很多layer 轉換的時候,就把它們歸到一起,
手寫數字識別的實體:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292150.html
標籤:其他