MapReduce是Hadoop的核心組件之一,是一種并行編程模型,用于大規模資料集(TB級別)的并行計算,MapReduce框架將并行計算抽象成為兩個函式:Map和Reduce,Hadoop MapReduce是基于HDFS的分布式編程框架,可以使沒有并行計算和分布式處理系統開發經驗的程式員有效利用分布式系統的豐富資源,
文章目錄
- 一、概述
- 1.MapReduce概述
- 2.Map函式和Reduce函式
- 二、MapReduce的作業流程
- 1.作業流程概述
- 2.MapReduce的各個執行階段
- 3.Shuffle程序詳解
- 總結
一、概述
1.MapReduce概述
2004年谷歌發表了關于MapReduce的論文,論文中指出MapReduce是谷歌的核心計算模型,是一種并行計算模型,它將運行在大規模集群上的復雜計算程序高度地抽象為兩個函式:Map函式和Reduce函式,
在MapReduce中,一個存盤在分布式檔案系統中的大規模資料集會被切成許多獨立的小資料塊,這些小資料塊可以被多個Map任務并行處理,MapReduce框架會為每個Map任務輸入一個資料子集,Map任務生成的結果會繼續作為Reduce任務的輸入,最終由Reduce任務輸出輸出最后結果,并寫入分布式檔案系統,特別需要注意的是,適合用MapReduce來處理的資料集需要滿足一個前提條件:待處理的資料集可以分解成許多小的資料集,而且每一個小資料集都可以完全并行地進行處理,
MapReduce的計算思想是將一個復雜問題分解成一系列子問題,通過Map函式對子問題分別進行處理,再通過Reduce函式對子問題處理后的結果進行匯總計算,從而得出計算結果,
Hadoop MapReduce的主要特點是:
- 易于編程,程式員只需要描述做什么,具體怎么做交給系統的執行框架處理,
- 良好的擴展性,可通過添加節點以擴展集群能力,
- 高容錯性,通過計算遷移或資料遷移等策略提高集群的可用性與容錯性,
2.Map函式和Reduce函式
MapReduce進行計算任務時,會將任務初始化為一個作業(Job),每個Job又被分解成若干任務(task),整個計算程序可以分為Map和Reduce兩個階段,這兩個階段分別用Map函式和Reduce函式表示,
Map函式在接收一個鍵/值對<key,value>的輸入,然后同樣產生一個新的鍵/值對<key,value>作為中間輸出,MapReduce會將所有具有相同key值的value匯總到一起傳遞給Reduce函式,
Reduce函式接收一個<key,(list of values)>形式的輸入,然后對這個value集合進行處理,每個Reduce產生0或1個輸出,Reduce的輸出也是<key,value>形式的,

二、MapReduce的作業流程
1.作業流程概述
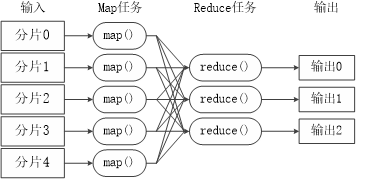
大規模資料集的處理包括兩個核心環節,Hadoop用分布式檔案系統HDFS實作分布式資料存盤,用MapReduce實作分布式計算,MapReduce的核心思想可以用“分而治之”來描述,一個大的MapReduce作業首先會被分成多個Map任務在多臺機器上并行執行,每個Map任務通常運行在資料存盤的節點上,計算和資料就可以放在一起運行,當Map任務結束后,會生成以<key,value>形式表示的許多中間結果,這些中間結果會被分發到多個Reduce任務在多臺機器上并行執行,具有相同key的<key,value>會被發送到同一個Reduce哪里,Reduce任務會對中間結果進行匯總計算得到最后結果,并輸出到分布式檔案系統中,
不同的Map任務之間不會進行通信,不同的Reduce任務之間也不會發生任何資訊交換,用戶不能顯式地從一臺機器向另一臺機器發送訊息,所有的資料交換都是通過MapReduce框架自身去實作的,
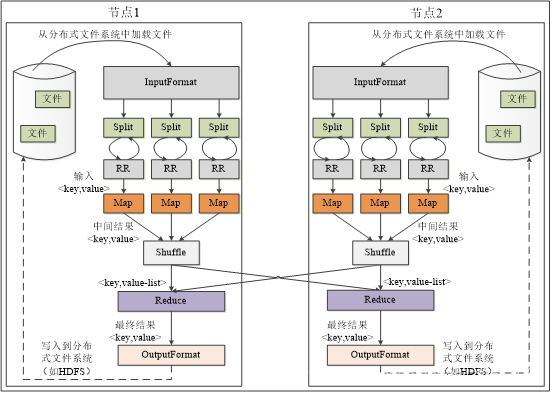
2.MapReduce的各個執行階段
(1)MapReduce框架使用InputFormat模塊做Map前的預處理,將輸入檔案切分成邏輯上的多個InputSplit,InputSplit是MapReduce對檔案進行處理和運算的輸入單位,每個InputSplit并沒有對檔案進行實際切割,只是記錄了要處理的資料的位置和長度,
(2)因為InputSplit是邏輯切分而非物理切分,還需要通過RecordReader(RR)根據InputSplit中的資訊處理InputSplit的具體記錄,加載資料并轉換為適合Map任務讀取的鍵值對,輸入給Map任務,
(3)Map任務會根據用戶自定義的映射規則,輸出一系列的<key,value>作為中間結果,
(4)為了讓Reduce可以并行處理Map的結果,需要對Map的輸出進行一定的磁區、排序、合并、歸并等操作,得到<key,value>形式的中間結果,在交給對應的Reduce進行處理,這個程序稱為Shuffle,
(5)Reduce以一系列<key,value-list>中間結果作為輸入,執行用戶定義的邏輯,輸出結果給OutouFormat模塊,
(6)OutputFormat模塊會驗證輸出目錄是否已經存在輸出結果型別是否符合組態檔中的配置型別,如果都滿足,就輸出Reduce的結果到分布式檔案系統,
3.Shuffle程序詳解
(1)Shuffle程序簡介
Shuffle是指對Map輸出結果進行磁區、排序、合并等處理交給Reduce的程序,因此,Shuffle程序分為Map端的操作和Reduce端的操作,
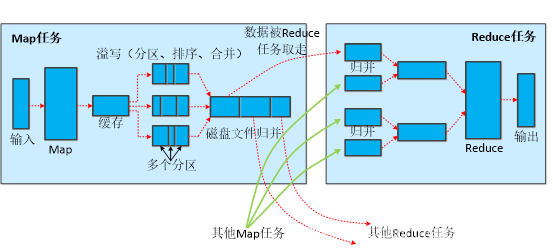
(2)Map端的Shuffle程序
每個Map任務分配一個快取,MapReduce默認100MB快取,一般會設定溢寫比例0.8,磁區默認采用哈希函式,排序是默認的操作,排序后可以合并(Combine),合并不能改變最終結果,
在Map任務全部結束之前進行歸并,歸并得到一個大的檔案,放在本地磁盤,檔案歸并時,如果溢寫檔案數量大于預定值(默認是3)則可以再次啟動Combiner,少于3則不需要,JobTracker會一直監測Map任務的執行,并通知Reduce任務來領取資料,

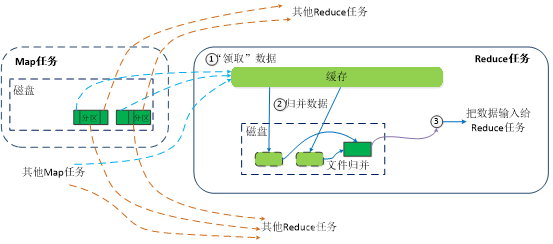
(3)Reduce端的Shuffle程序
- Reduce任務通過RPC向JobTracker詢問Map任務是否已經完成,若完成,則領取資料
- Reduce領取資料先放入快取,來自不同Map機器,先歸并,再合并,寫入磁盤
- 多個溢寫檔案歸并成一個或多個大檔案,檔案中的鍵值對是排序的
- 當資料很少時,不需要溢寫到磁盤,直接在快取中歸并,然后輸出給Reduce
總結
本節介紹了MapReduce的Map函式和Reduce函式以及作業流程,本篇文章借鑒了下面兩本大資料書籍,在此鄭重感謝,
《大資料技術原理與應用(第2版)》 林子雨編著
《大資料原理與技術》 黃史浩編著
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292170.html
標籤:其他
上一篇:大資料必學框架-Flume
下一篇:訊息佇列之Kafka從入門到小牛