文章目錄
- 前言
- 一、Scrapy是什么?
- 二、使用步驟
- 1.安裝Scrapy
- 2.創建Scrapy專案
- 3.Scrapy架構圖
- 三.實戰專案:爬取豆瓣電影TOP250電影資訊
- 1.items.py
- 2.pipelines.py
- 3.douban_spider.py
- 4.運行結果
前言
隨著大資料時代的來臨,資料對一個企業越來越重要,沒有資料的支撐,那么這個企業必然會落后于其它企業,那么怎么樣獲取資料呢?本篇文章將告訴你如何從互聯網上抓取有用的資料并持久化存盤
一、Scrapy是什么?
Scrapy 是一套基于基于Twisted的異步處理框架,純python實作的爬蟲框架,用戶只需要定制開發幾個模塊就可以輕松的實作一個爬蟲,用來抓取網頁內容以及各種圖片,非常之方便~
二、使用步驟
1.安裝Scrapy
pip install scrapy
2.創建Scrapy專案
scrapy startproject 專案名
3.Scrapy架構圖
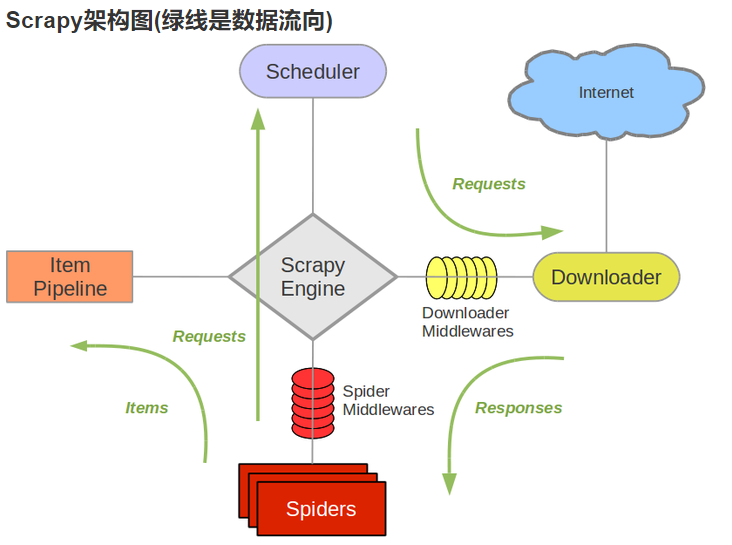
Item Pipeline:可以簡稱為資料結構,即要存盤的資料的結構,可以理解為面向物件中的類,這個模塊在Spiders模塊決議后,會進行回呼,
Spiders:資料決議模塊,即在此模塊中,只是做對資料的決議,并提取鏈接資訊發送給Scheduler模塊進行排隊,
Downloader:下載模塊,只做資料請求,并將回傳的資料放入Spiders中決議,
Scheduler:佇列模塊,只負責對請求的鏈接進行排序并發送給Downloader.
三.實戰專案:爬取豆瓣電影TOP250電影資訊
1.items.py
該模塊對應items模塊
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
##電影序號
movie_number=scrapy.Field()
##電影名字
movie_name=scrapy.Field()
##電影資訊
movie_tostar=scrapy.Field()
##星級
movie_star=scrapy.Field()
##評論人數
movie_evaluate=scrapy.Field()
##電影介紹
movie_introduction=scrapy.Field()
2.pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymongo
class DoubanPipeline:
def __init__(self) -> None:
host="mongodb://localhost"
prot="27017"
dbname="movie"
client=pymongo.MongoClient("mongodb://localhost:27017")
db=client[dbname]
self.movie_table=db['movie_table']
def process_item(self, item, spider):
print(item)
data=dict(item)
self.movie_table.insert_one(data)
return item
3.douban_spider.py
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
##爬蟲名字
name = 'douban_spider'
##允許的域名
allowed_domains = ['movie.douban.com']
##入口url
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
next=response.xpath('//*[@id="content"]/div/div[1]/div[2]/span[3]/a/@href').extract()
my_list=response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in my_list:
my_item=DoubanItem()
my_item['movie_number']=item.xpath('./div[@class="item"]//em/text()').extract_first()
my_item['movie_name']=item.xpath('./div[@class="item"]/div[@class="info"]//a/span[1]/text()').extract_first()
my_item['movie_tostar']=item.xpath('./div[@class="item"]/div[@class="info"]//div[@class="bd"]/p/text()').extract_first()
my_item['movie_star']=item.xpath('./div[@class="item"]/div[@class="info"]//div[@class="star"]/span[2]/text()').extract_first()
my_item['movie_evaluate']=item.xpath('./div[@class="item"]/div[@class="info"]//div[@class="star"]/span[4]/text()').extract_first()
my_item['movie_introduction']=item.xpath('./div[@class="item"]/div[@class="info"]//p[@class="quote"]/span[1]/text()').extract_first()
yield my_item
if next:
yield scrapy.Request("https://movie.douban.com/top250"+next[0],self.parse)
4.運行結果
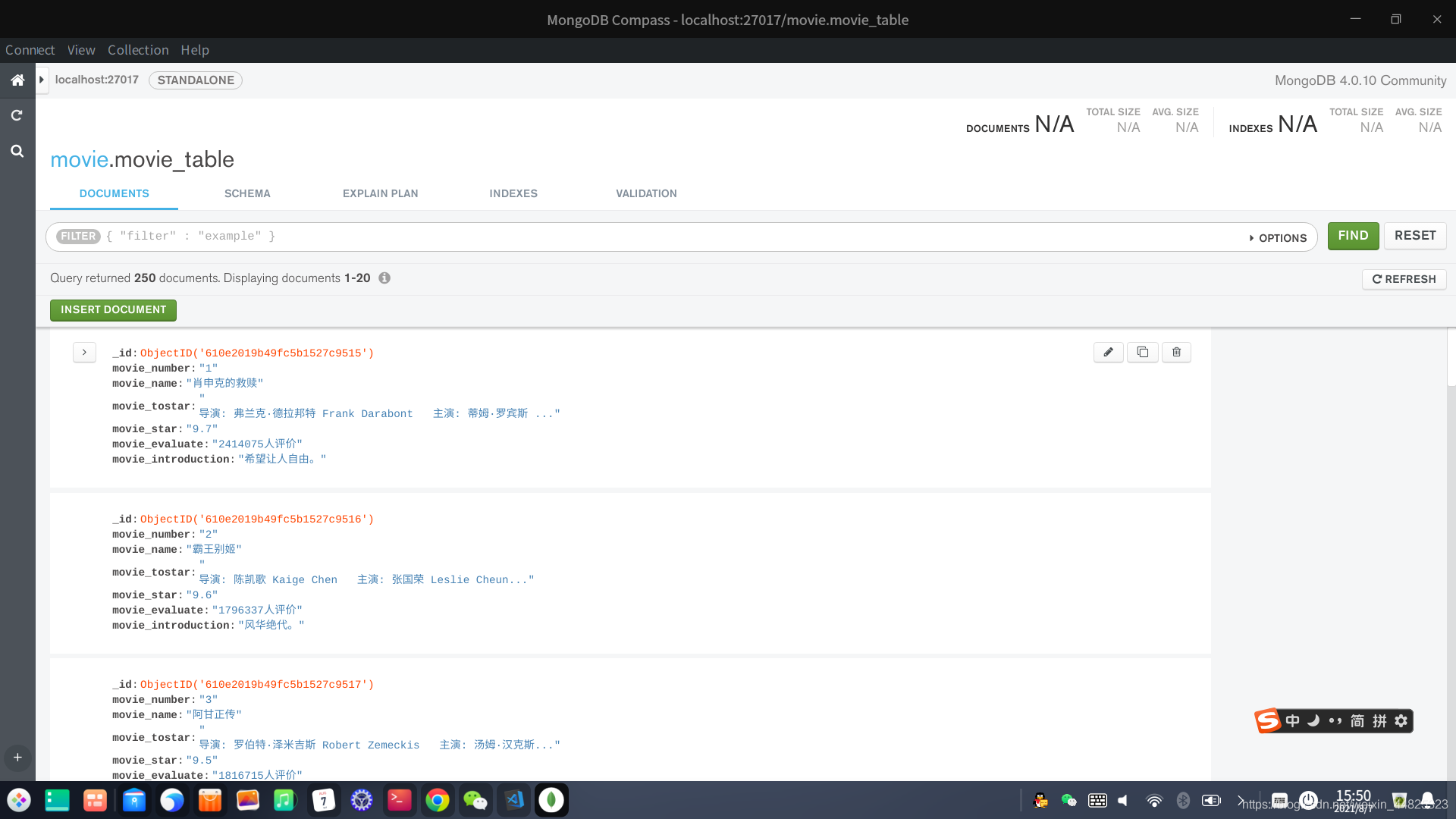
附帶原始碼:下載原始碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292616.html
標籤:其他