文章目錄
- 聚類(Clustering)
- K-Means演算法
- 演算法優化
- 確定k值
- 二分K-Means演算法
- DBSCAN演算法
- 演算法流程
- 演算法優劣
本文為吳恩達機器學習課程的筆記系列第五篇,主要介紹幾個聚類演算法,包括經典的K-Means演算法,以及其拓展 二分K-Means演算法和另一個常用的DBSCAN演算法
聚類(Clustering)
聚類(Clustering)是將資料集劃分為若干相似物件組成的多個組(group)或簇(cluster)的程序, 使得同一組中物件間的相似度最大化, 不同組中物件間的相似度最小化 ,屬于無監督問題,
K-Means演算法
K K K 就是簇的數量,這個數字是人為選擇的,K-Means演算法是基于質心劃分的,
演算法流程:
- 首先隨機選擇 K K K 個點作為初始聚類中心,
- 對資料集的每個資料,評估其到 K K K 個中心點的距離,將其與距離最近的中心點關聯起來,
- 重新計算每個簇中的平均值,更新簇中心的位置
距離的判斷:歐幾里得距離或余弦相似度
演算法描述:
- μ ( i ) \mu^{(i)} μ(i) 表示第 i i i個聚類中心, x ( i ) x^{(i)} x(i) 表示第 i i i個樣本, m m m 表示樣本數
R e p e a t { ???? f o r ?? i = ?? 1 ?? t o ?? m : c ( i ) : = 與 樣 本 x ( i ) 最 近 的 簇 中 心 的 索 引 ???? f o r ?? k = ?? 1 ?? t o ?? K : μ ( k ) : = 第 k 個 簇 的 平 均 位 置 } \begin{aligned} &Repeat \{ \\ & \;\; for\; i =\; 1\; to\; m:\\ &\qquad c^{(i)} := 與樣本x^{(i)}最近的簇中心的索引 \\ &\;\;for\; k =\; 1\; to\; K: \\ &\qquad \mu^{(k)}:= 第k個簇的平均位置 \\ &\} \end{aligned} ?Repeat{fori=1tom:c(i):=與樣本x(i)最近的簇中心的索引fork=1toK:μ(k):=第k個簇的平均位置}?
演算法優化
K-Means同樣也要最小化聚類代價,而最小化的就是所有的資料點與其所關聯的聚類中心點之間的距離之和,引入K-Means的代價函式:
J ( c ( 1 ) , . . . , c ( m ) , μ ( 1 ) , . . . , μ ( K ) ) = 1 m ∑ i = 1 m ∣ ∣ x ( i ) ? μ c ( i ) ∣ ∣ 2 J(c^{(1)},...,c^{(m)},\mu^{(1)},...,\mu^{(K)})=\dfrac{1}{m}\sum\limits_{i=1}^{m}||x^{(i)}-\mu^{c^{(i)}}||^2 J(c(1),...,c(m),μ(1),...,μ(K))=m1?i=1∑m?∣∣x(i)?μc(i)∣∣2 J J J 也稱畸變函式(Distortion Function)
實際上,在第一個for回圈里,也就是給樣本分配簇中心時,就是在減小 c ( i ) c^{(i)} c(i) 引起的代價;在第二個for回圈里,則是在減小 μ ( k ) \mu^{(k)} μ(k) 引起的代價,
確定k值
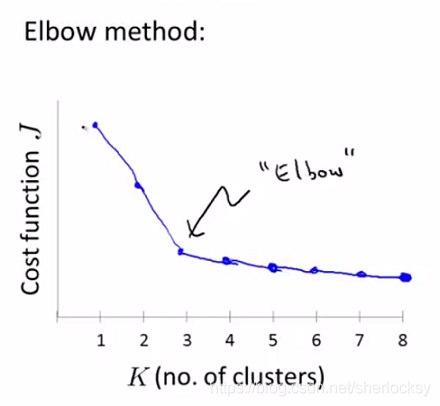
因為不同的初始化很有可能會引起不同的聚類結果,所以應用聚類演算法時往往進行多次隨機初始化,計算相應代價函式,應用 肘部法則(Elbow Method),選擇較為明顯的“肘關節”部分對應的 k 值作為聚類數,如下圖:
下面補充幾個其它常見的聚類演算法:
二分K-Means演算法
二分 K-Means(bisecting kmeans)演算法,相較于常規的 K-Means,二分 K-Means 不急于一來就隨機 K個聚類中心,而是首先把所有點歸為一個簇,然后將該簇一分為二,計算各個所得簇的代價函式(即誤差),選擇誤差最大的簇再進行劃分(即最大程度地減少誤差),重復該程序直至達到期望的簇數目,
誤差采用 SSE(Sum of Squared Error)即誤差平方和,SSE越小,簇中的物件越集中 ,
該演算法為貪心演算法,計算量不小,
DBSCAN演算法
DBSCAN演算法是基于密度的演算法,該演算法將具有足夠高密度的區域劃分為簇,并在具有噪聲的空間資料庫中發現任意形狀的簇,它將簇定義為密度相連的點的最大的集合,
基本概念:
- E p s Eps Eps 鄰域:給定物件半徑 E p s Eps Eps 內的鄰域稱為該物件的 E p s Eps Eps 鄰域,
- M i n P t s MinPts MinPts:給定鄰域包含的點的最小數目,用以決定點 p p p是簇的核心部分還是邊界點或噪聲,
- 核心物件:如果物件的 E p s Eps Eps 鄰域包含至少 M i n P t s MinPts MinPts 個的物件,則稱該物件為核心物件,
- 邊界點:邊界點不是核心點,但落在某個核心點的鄰域內,稠密區域邊緣上的點,
- 噪音點:既不是核心點,也不是邊界點的任何點, 稀疏區域中的點,
- 直接密度可達: 如果 p p p 在 q q q 的 E p s Eps Eps鄰域內, 而 q q q 是一個核心物件, 則稱物件 p p p 從物件 q q q 出發時是直接密度可達的 (directly densityreachable),
- 密度可達: 如果存在一個物件鏈 p 1 , p 2 , . . . , p n , p 1 = q , p n = p p_1,p_2,...,p_n,p_1=q,p_n=p p1?,p2?,...,pn?,p1?=q,pn?=p, 對于 p i ∈ D ( 1 ≤ i ≤ n ) p_i\in D(1\le i\le n) pi?∈D(1≤i≤n), p i + 1 p_{i+1} pi+1? 是 p i p_i pi? 從關于 E p s Eps Eps 和 M i n P t s MinPts MinPts 直接密度可達的,則 對 象 p p p 是 從物件 q q q 關于 E p s Eps Eps 和 M i n P t s MinPts MinPts 密 度 可 達 的 (densityreachable),
- 密度相連: 如果存在物件 O ∈ D O\in D O∈D, 使物件 p p p 和 q q q 都是從 O O O 關于 E p s Eps Eps 和 M i n P t s MinPts MinPts 密度可達的, 那么物件 p p p 到 q q q 是關于 E p s Eps Eps 和 M i n P t s MinPts MinPts 密度相連的(density-connected),
- 基于密度的簇:是基于密度可達性的最大的密度相連的物件的集合 ,
- 噪聲:不包含在任何簇中的物件,
DBSCAN演算法, 就是檢查資料集中每個點的 E p s Eps Eps 鄰域來搜索簇,
演算法流程
( 1 ) 首先將資料集 D 中 的 所 有 對 象 標 記 為 未 處 理 狀 態 ( 2 ) f o r ?? 數 據 集 D 中 每 個 對 象 p ?? d o ( 3 ) i f ?? p 已 經 歸 入 某 個 簇 或 標 記 為 噪 聲 ?? t h e n ( 4 ) c o n t i n u e ; ( 5 ) e l s e ( 6 ) 檢 查 對 象 p 的 E p s 鄰 域 E ( p ) ; ( 7 ) i f ?? E ( p ) 包 含 的 對 象 數 小 于 M i n P t s ?? t h e n ( 8 ) 標 記 對 象 p 為 邊 界 點 或 噪 聲 點 ; ( 9 ) e l s e ( 10 ) 標 記 對 象 p 為 核 心 點 , 并 建 立 新 簇 C ; ( 11 ) f o r ?? E ( p ) 中 所 有 尚 未 被 處 理 的 對 象 q ?? d o ( 12 ) 檢 查 其 E p s 鄰 域 E ( p ) , 若 E ( p ) 包 含 至 少 M i n P t s 個 對 象 , 則 將 E ( p ) 中 未 歸 入 任 何 一 個 簇 的 對 象 加 入 C \begin{aligned} &(1) \text{首先將資料集}D中的所有物件標記為未處理狀態 \\ &(2) for\;資料集D中每個物件p \;do \\ &(3) \quad if \;p已經歸入某個簇或標記為噪聲\;then\\ &(4) \qquad continue;\\ &(5) \quad else\\ &(6) \qquad 檢查物件p的Eps鄰域 E(p); \\ &(7) \qquad \quad if \;E(p)包含的物件數小于MinPts \;then \\ &(8) \qquad \qquad 標記物件p為邊界點或噪聲點;\\ &(9) \qquad \quad else\\ &(10) \qquad \qquad 標記物件p為核心點,并建立新簇C;\\ &(11) \qquad \qquad for\; E(p)中所有尚未被處理的物件q\; do\\ &(12) \qquad \qquad \quad 檢查其Eps鄰域E(p),若E(p)包含至少MinPts個物件,則將E(p) 中未歸入任何一個簇的物件加入C \end{aligned} ?(1)首先將資料集D中的所有對象標記為未處理狀態(2)for數據集D中每個對象pdo(3)ifp已經歸入某個簇或標記為噪聲then(4)continue;(5)else(6)檢查對象p的Eps鄰域E(p);(7)ifE(p)包含的對象數小于MinPtsthen(8)標記對象p為邊界點或噪聲點;(9)else(10)標記對象p為核心點,并建立新簇C;(11)forE(p)中所有尚未被處理的對象qdo(12)檢查其Eps鄰域E(p),若E(p)包含至少MinPts個對象,則將E(p)中未歸入任何一個簇的對象加入C?
演算法優劣
優勢:
- 不需要指定簇個數
- 擅長找到離群點(檢測任務)
- 可以發現任意形狀的簇
- 只需兩個引數
劣勢:
- 引數難以選擇(引數對結果的影響非常大)
- 高維資料有些困難(可以做降維)
上一篇文章地址:機器學習入門之支持向量機SVM
下一篇文章地址:機器學習入門之PCA與ICA
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292621.html
標籤:AI