ElasticSearch簡介及ElasticSearch部署、原理和使用介紹
第一章:elasticsearch簡介
ElasticSearch是一個基于Lucene的搜索服務器,它提供了一個分布式多用戶能力的全文搜索引擎,基于RESTful web介面,Elasticsearch是用Java開發的,并作為Apache許可條款下的開放原始碼發布,是當前流行的企業級搜索引擎,
第一節 elasticSearch的使用場景
1、 為用戶提供按關鍵字查詢的全文搜索功能,
2、 實作企業海量資料的處理分析的解決方案,大資料領域的重要一份子,如著名的ELK框架(ElasticSearch,Logstash,Kibana),
第二節 常用資料庫存盤對比
| redis | mysql | elasticsearch | hbase | hadoop/hive | |
|---|---|---|---|---|---|
| 容量/容量擴展 | 低 | 中 | 較大 | 海量 | 海量 |
| 查詢時效性 | 極高 | 中等 | 較高 | 中等 | 低 |
| 查詢靈活性 | 較差 k-v模式 | 非常好,支持sql | 較好,關聯查詢較弱,但是可以全文檢索,DSL語言可以處理過濾、匹配、排序、聚合等各種操作 | 較差,主要靠rowkey,scan的話性能不行,或者建立二級索引 | 非常好,支持sql |
| 寫入速度 | 極快 | 中等 | 較快 | 較快 | 慢 |
| 一致性、事務 | 弱 | 強 | 弱 | 弱 | 弱 |
第三節 elasticsearch的特點
1.3.1 天然分片,天然集群
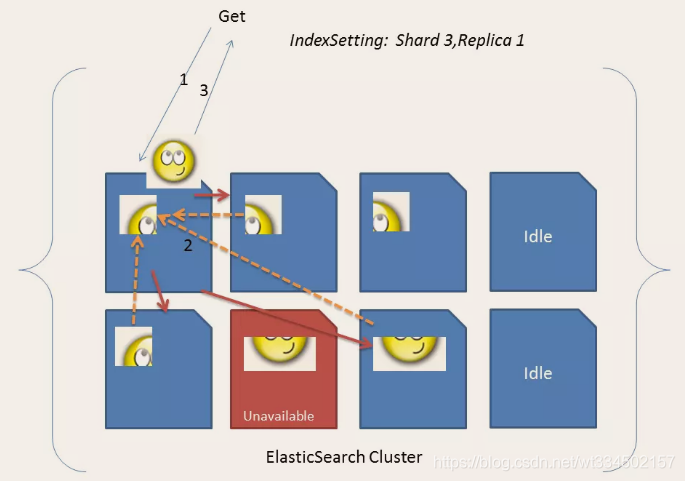
es 把資料分成多個shard,下圖中的P0-P2,多個shard可以組成一份完整的資料,這些shard可以分布在集群中的各個機器節點中,隨著資料的不斷增加,集群可以增加多個分片,把多個分片放到多個機子上,已達到負載均衡,橫向擴展,
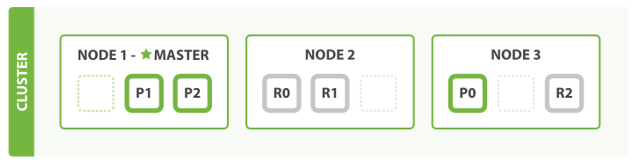
在實際運算程序中,每個查詢任務提交到某一個節點,該節點必須負責將資料進行整理匯聚,再回傳給客戶端,也就是一個簡單的節點上進行Map計算,在一個固定的節點上進行Reduces得到最終結果向客戶端回傳,
這種集群分片的機制造就了elasticsearch強大的資料容量及運算擴展性,
1.3.2 天然索引
ES 所有資料都是默認進行索引的,這點和mysql正好相反,mysql是默認不加索引,要加索引必須特別說明,ES只有不加索引才需要說明,
而ES使用的是倒排索引和Mysql的B+Tree索引不同,
第四節 lucene與elasticsearch的關系
lucene只是一個提供全文搜索功能類別庫的核心工具包,而真正使用它還需要一個完善的服務框架搭建起來的應用,
好比lucene是類似于發動機,而搜索引擎軟體(ES,Solr)就是汽車,
目前市面上流行的搜索引擎軟體,主流的就兩款,elasticsearch和solr,這兩款都是基于lucene的搭建的,可以獨立部署啟動的搜索引擎服務軟體,由于內核相同,所以兩者除了服務器安裝、部署、管理、集群以外,對于資料的操作,修改、添加、保存、查詢等等都十分類似,就好像都是支持sql語言的兩種資料庫軟體,只要學會其中一個另一個很容易上手,
從實際企業使用情況來看,elasticSearch的市場份額逐步在取代solr,國內百度、京東、新浪都是基于elasticSearch實作的搜索功能,國外就更多了 像維基百科、GitHub、Stack Overflow等等也都是基于ES的,
第二章:elasticSearch的安裝部署(含kibana)
2.1 下載地址
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
https://www.elastic.co/cn/downloads/past-releases#kibana
【注意】:
- es和kibana版本下載需一致
- 目前生產環境大多采用大版本6.x.x;7.x.x版本相對較新,但部署流程都一樣
2.2 機器規劃
3臺機器:
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
wangting@ops01:/home/wangting >cat /etc/hosts
127.0.0.1 ydt-cisp-ops01
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# elasticsearch
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
【注意】:如果在各節點的/etc/hosts中都配置了節點的ip決議,那后續在組態檔中,相關的ip配置都可以用決議名代替;
例如:network.host: 11.8.37.50 等同于 network.host: ops01
2.3 下載安裝包
wangting@ops01:/opt/software >ll | grep 6.6.0
-rw-r--r-- 1 wangting wangting 114106988 Aug 4 14:40 elasticsearch-6.6.0.tar.gz
-rw-r--r-- 1 wangting wangting 180704352 Aug 4 14:40 kibana-6.6.0-linux-x86_64.tar.gz
2.4 環境優化
2.4.1 優化1
系統允許 Elasticsearch 打開的最大檔案數需要修改成65536
wangting@ops01:/opt/software >sudo vim /etc/security/limits.conf
# End of file
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 65536
# 斷開重連會話
wangting@ops01:/home/wangting >ulimit -n
65536
這個配置不優化啟動服務會出現:
[error] max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] elasticsearch
2.4.2 優化2
允許最大行程數配置修該成4096;不是4096則需要修改優化
wangting@ops01:/home/wangting >sudo vim /etc/security/limits.d/20-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 4096
root soft nproc unlimited
這個配置不優化啟動服務會出現:
[error]max number of threads [1024] for user [judy2] likely too low, increase to at least [4096]
2.4.3 優化3
設定一個行程可以擁有的虛擬記憶體區域的數量
wangting@ops01:/home/wangting >sudo vim /etc/sysctl.conf
vm.max_map_count=262144
# 多載配置
wangting@ops01:/home/wangting >sudo sysctl -p
這個配置不優化啟動服務會出現:
[error]max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
2.5 解壓安裝
wangting@ops01:/opt/software >tar -xf elasticsearch-6.6.0.tar.gz -C /opt/module/
wangting@ops01:/opt/software >cd /opt/module/elasticsearch-6.6.0/
wangting@ops01:/opt/module/elasticsearch-6.6.0 >ll
total 448
drwxr-xr-x 3 wangting wangting 4096 Aug 4 15:13 bin
drwxr-xr-x 2 wangting wangting 4096 Jan 24 2019 config
drwxr-xr-x 3 wangting wangting 4096 Jan 24 2019 lib
-rw-r--r-- 1 wangting wangting 13675 Jan 24 2019 LICENSE.txt
drwxr-xr-x 2 wangting wangting 4096 Jan 24 2019 logs
drwxr-xr-x 29 wangting wangting 4096 Jan 24 2019 modules
-rw-r--r-- 1 wangting wangting 403816 Jan 24 2019 NOTICE.txt
drwxr-xr-x 2 wangting wangting 4096 Jan 24 2019 plugins
-rw-r--r-- 1 wangting wangting 8519 Jan 24 2019 README.textile
2.6 修改組態檔
wangting@ops01:/opt/module/elasticsearch-6.6.0 >cd config/
wangting@ops01:/opt/module/elasticsearch-6.6.0/config >cat elasticsearch.yml | grep -vE "^#|^$"
cluster.name: my-es
node.name: node-ops01
bootstrap.memory_lock: false
network.host: 11.8.37.50
http.port: 9200
discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"]
配置項說明:
cluster.name: my-es # 集群名稱;同一集群各節點名稱必須相同
node.name: node-ops01 # 當前節點名稱;可理解成在集群中各自用這個名稱區別
bootstrap.memory_lock: false # bootstrap自檢程式
network.host: 11.8.37.50 # 當前節點host主機
http.port: 9200 # es啟動埠
discovery.zen.ping.unicast.hosts: [“11.8.37.50”, “11.8.36.63”, “11.8.36.76”] # 自發現配置:新節點向集群報到的主機名
【注意】: 這些是常規配置,其它例如data存盤路徑,log存盤路徑等等都可以自定義根據情況去配置
2.7 分發安裝目錄
wangting@ops01:/opt/module >scp -r elasticsearch-6.6.0 ops02:/opt/module/
wangting@ops01:/opt/module >scp -r elasticsearch-6.6.0 ops03:/opt/module/
2.8 修改其它節點組態檔
# 節點ops02
wangting@ops02:/opt/module/elasticsearch-6.6.0/config >cat elasticsearch.yml | grep -vE "^#|^$"
cluster.name: my-es
node.name: node-ops02
bootstrap.memory_lock: false
network.host: 11.8.36.63
http.port: 9200
discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"]
# 節點ops03
wangting@ops03:/opt/module/elasticsearch-6.6.0/config >cat elasticsearch.yml | grep -vE "^#|^$"
cluster.name: my-es
node.name: node-ops03
bootstrap.memory_lock: false
network.host: 11.8.36.76
http.port: 9200
discovery.zen.ping.unicast.hosts: ["11.8.37.50", "11.8.36.63", "11.8.36.76"]
2.9 服務啟動
# 依次啟動3臺節點es,命令相同
wangting@ops01:/opt/module >cd /opt/module/elasticsearch-6.6.0/bin/
wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >./elasticsearch -d
wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >
【注意】:
- -d 為后臺運行,不加-d只能前臺運行,關了會話視窗服務也會同時終止
- 3臺機器都需要啟動elasticsearch
- 運行日志沒有配置定義,默認在服務目錄下:elasticsearch-6.6.0/logs/ ,有例外可以先查看日志
2.10 命令驗證es
wangting@ops01:/opt/module/elasticsearch-6.6.0/logs >curl http://11.8.37.50:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
11.8.36.63 26 88 0 0.05 0.13 0.10 mdi - node-ops02
11.8.37.50 28 87 0 0.06 0.10 0.08 mdi * node-ops01
11.8.36.76 26 53 0 0.06 0.07 0.06 mdi - node-ops03
【注意】:正常運行的es集群,curl各個節點nodes狀態都是可以回傳結果
2.11 安裝kibana
# 安裝kibana kibana只是一個工具 挑一臺服務器安裝即可
wangting@ops01:/opt/software >scp kibana-6.6.0-linux-x86_64.tar.gz ops03:/opt/software/
wangting@ops03:/opt/module/elasticsearch-6.6.0/bin >cd /opt/software/
wangting@ops03:/opt/software >tar -xf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/module/
wangting@ops03:/opt/software >cd /opt/module/kibana-6.6.0-linux-x86_64/config/
wangting@ops03:/opt/module/kibana-6.6.0-linux-x86_64/config >cat kibana.yml | grep -vE "^$|^#"
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://11.8.37.50:9200"]
wangting@ops03:/opt/module/kibana-6.6.0-linux-x86_64/config >cd ..
wangting@ops03:/opt/module/kibana-6.6.0-linux-x86_64 >nohup bin/kibana &
2.12 界面驗證kibana
在哪個節點部署,則使用對應地址+5601埠訪問
http://11.8.36.76:5601/
第三章:elasticsearch的基本概念
第一節:關鍵詞解釋
| 關鍵詞 | 釋義 |
|---|---|
| cluster | 整個elasticsearch 默認就是集群狀態,整個集群是一份完整、互備的資料, |
| node | 集群中的一個節點,一般只一個行程就是一個node |
| shard | 分片,即使是一個節點中的資料也會通過hash演算法,分成多個片存放,默認是5片,(7.0默認改為1片) |
| index | 相當于rdbms的database(5.x), 對于用戶來說是一個邏輯資料庫,雖然物理上會被分多個shard存放,也可能存放在多個node中, 6.x 7.x index相當于table |
| type | 類似于rdbms的table,但是與其說像table,其實更像面向物件中的class , 同一Json的格式的資料集合,(6.x只允許建一個,7.0被廢棄,造成index實際相當于table級) |
| document | 類似于rdbms的 row、面向物件里的object |
| field | 相當于欄位、屬性 |
第二節:語法簡單示例:
GET /_cat/nodes?v # 查詢各個節點狀態
GET /_cat/indices?v # 查詢各個索引狀態
GET /_cat/shards/xxxx # 查詢某個索引的分片情況
第三節:elasticsearch 9200 9300埠區別
es正常啟動會有9200和9300兩個埠
1、9200作為Http協議,主要用于外部通訊;是 HTTP 協議的 RESTful 介面
2、9300作為Tcp協議,jar之間就是通過tcp協議通訊;集群間和 TCPClient 都走得它
第四章:elasticsearch restful api [DSL]
DSL: 全稱 Domain Specific language,即特定領域專用語言
第一節 es中保存的資料結構
一般在java代碼中,兩個物件如果放在關系型資料庫保存,例如存盤在MySQL中,則會被拆成2張表,Movie對應一張MySQL表,Actor對應另一張MySQL表;
package com.wangting.elasticsearch.test;
import java.util.List;
public interface Test {
public static void main(String[] args) {
public class Movie<Actor> {
String id;
String name;
Double doubanScore;
List<Actor> actorList;
}
public class Actor{
String id;
String name;
}
}
}
但是elasticsearch是用一個json來表示一個document,
{
"id": "1",
"name": "operation red sea",
"doubanScore": "8.5",
"actorList": [
{
"id": "1",
"name": "zhangyi"
},
{
"id": "2",
"name": "haiqing"
},
{
"id": "3",
"name": "zhanghanyu"
}
]
}
為便于理解,簡單和MySQL作一個對比,關鍵詞只是類似,并不是完全一個概念,功能差不多
| MySQL | elasticsearch |
|---|---|
| databases | index |
| table | type |
| row | document |
| column | field |
第二節 對資料常用操作
4.2.1 查看es中有哪些索引
比較類似MySQL中的show tables;
GET /_cat/indices?v
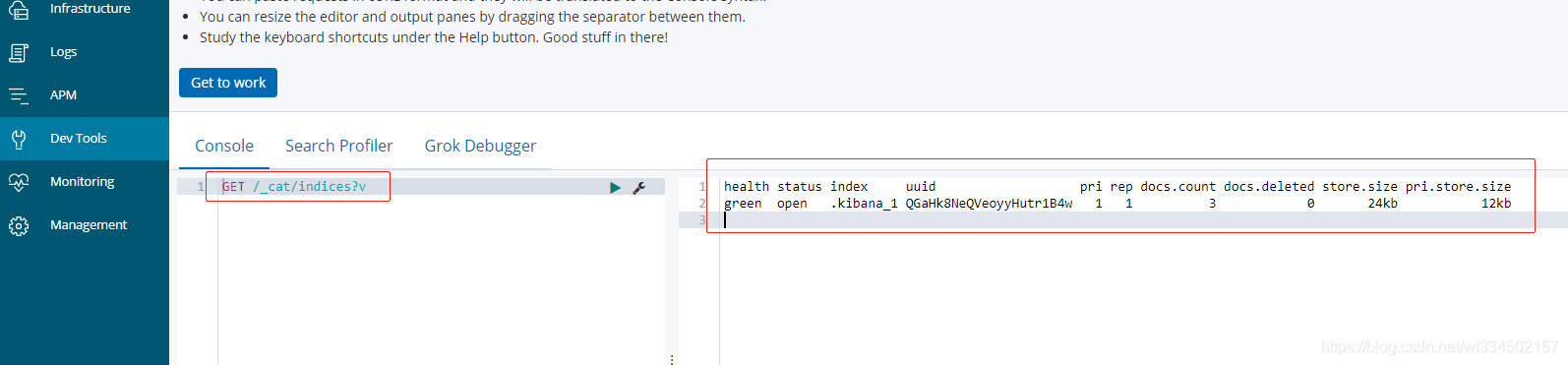
【注意】:
- es 中會默認存在一個名為.kibana的索引
- GET /_cat/indices?v 等同于命令列中curl http://11.8.37.50:9200/_cat/indices?v
- 最后的?v可以不加,但是不建議,因為這樣結果沒有表頭,查詢的結果相對較亂,不便于查閱
查詢索引表頭各關鍵詞釋義
| 關鍵詞 | 釋義 |
|---|---|
| health | green(集群完整) yellow(單點正常、集群不完整) red(單點不正常) |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引統一編號 |
| pri | 主節點幾個 |
| rep | 從節點幾個 |
| docs.count | 檔案數 |
| docs.deleted | 檔案被刪了多少 |
| store.size | 整體占空間大小 |
| pri.store.size | 主節點占空間大小 |
4.2.2 添加索引
比較類似MySQL中的create table;
PUT /indexname

【注意】:
#! Deprecation: the default number of shards will change from [5] to [1] in 7.0.0; if you wish to continue using the default of [5] shards, you must manage this on the create index request or with an index template
意思大致是:提示在大版本7.0.0以后,默認分片數將從5更改變為1,以后如想使用默認的5,就必須新建帶有索引模板的索引請求
再次查詢索引資訊:

4.2.3 洗掉索引
比較類似MySQL中的drop table;
DELETE /indexname
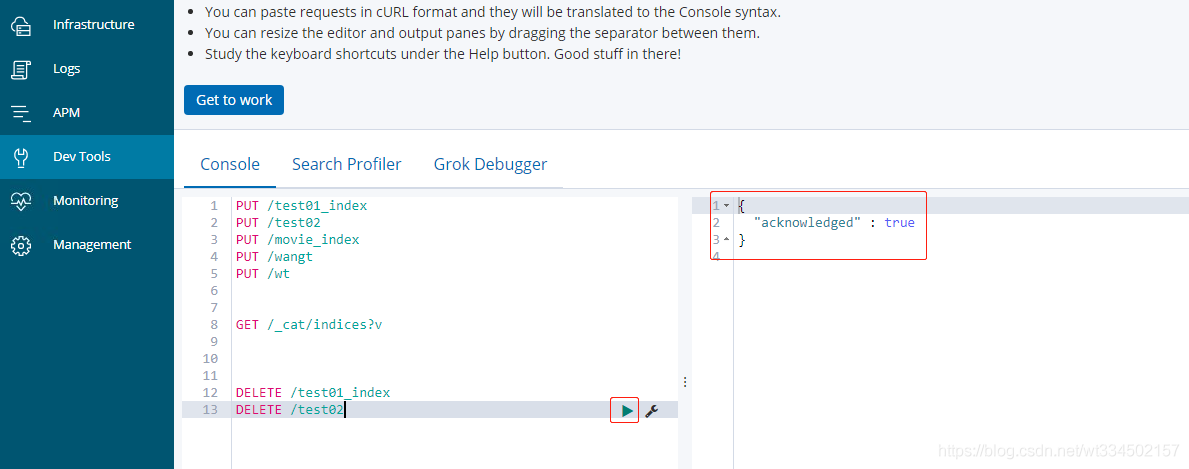
4.2.4 新增檔案
比較類似MySQL中某張表的insert into ;
語法:格式 PUT /index/type/id
如果上面示例的 movie_index索引洗掉了,重新建一下:PUT /movie_index
新增:
PUT /movie_index/movie/1
{
"id": 1,
"name": "operation red sea",
"doubanScore": 8.5,
"actorList": [
{
"id": 1,
"name": "zhang yi"
},
{
"id": 2,
"name": "hai qing"
},
{
"id": 3,
"name": "zhang han yu"
}
]
}
PUT /movie_index/movie/2
{
"id": 2,
"name": "operation meigong river",
"doubanScore": 8,
"actorList": [
{
"id": 3,
"name": "zhang han yu"
}
]
}
PUT /movie_index/movie/3
{
"id": 3,
"name": "incident red sea",
"doubanScore": 5,
"actorList": [
{
"id": 4,
"name": "zhang chen"
}
]
}
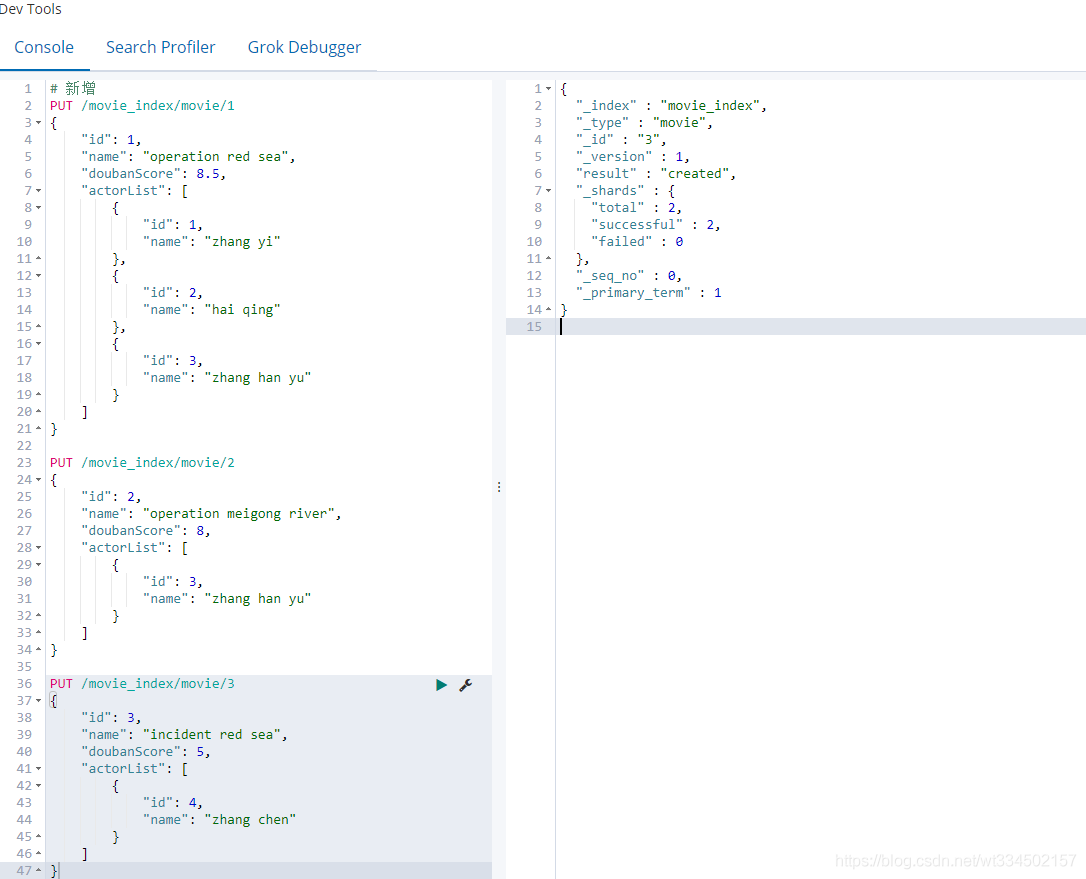
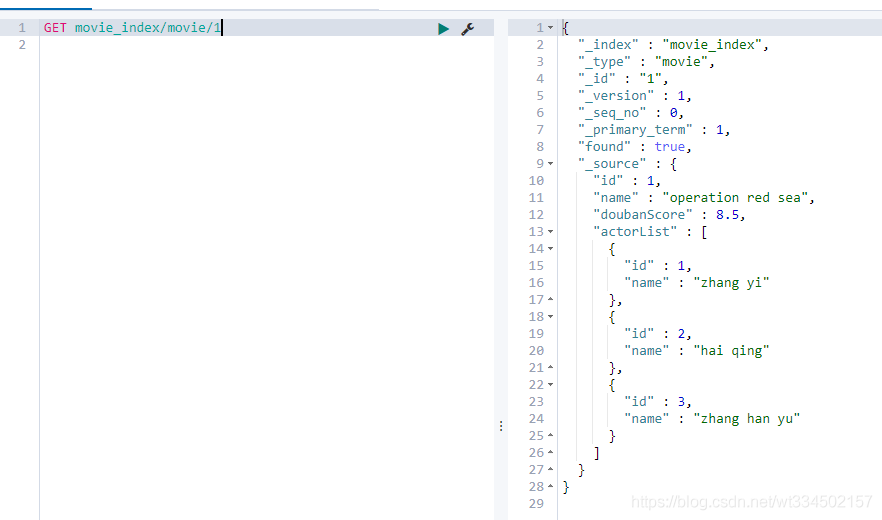
4.2.5 直接用id查找資料
比較類似MySQL中某張表的select where條件 ;
GET movie_index/movie/1
4.2.6 修改 - ( 修改整體替換資料 )
比較類似MySQL中某張表的alter table ;
【注意】: 和新增沒有區別 要求:必須包括全部欄位
PUT /movie_index/movie/3
{
"id": "3",
"name": "incident red sea",
"doubanScore": "5.0",
"actorList": [
{
"id": "1",
"name": "zhang chen"
}
]
}
4.2.7 修改 - ( 修改某個欄位 )
某個欄位的值內容修改
比較類似MySQL中某張表的alter table ;
POST movie_index/movie/3/_update
{
"doc": {
"doubanScore":"7.0"
}
}
某個欄位關閉索引
"name":{
"type": "keyword",
"index": false
}
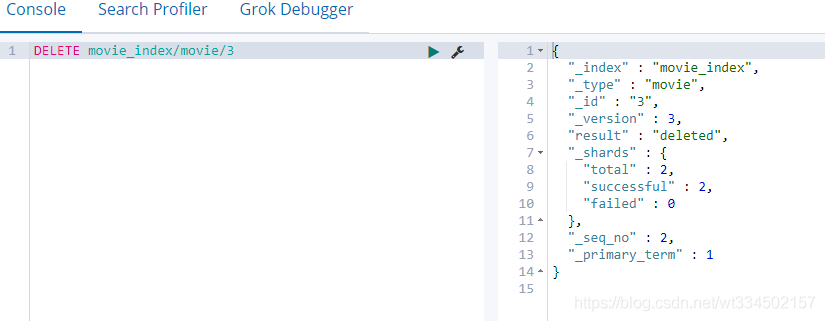
4.2.8 洗掉一個document
比較類似MySQL中某張表的DELETE FROM <表名> [WHERE 子句]
DELETE movie_index/movie/3
4.2.9 搜索type全部資料
比較類似MySQL中某張表select * from;
GET movie_index/movie/_search
4.2.10 按條件查詢(全部)
GET movie_index/movie/_search
{
"query":{
"match_all": {}
}
}
【注意】:按條件查詢時,條件中為空,則效果等同于查詢type中全部資料GET movie_index/movie/_search
4.2.11 按分詞查詢
比較類似MySQL中某張表select * from like %xxx%;但是僅僅像原理不同
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
}
}
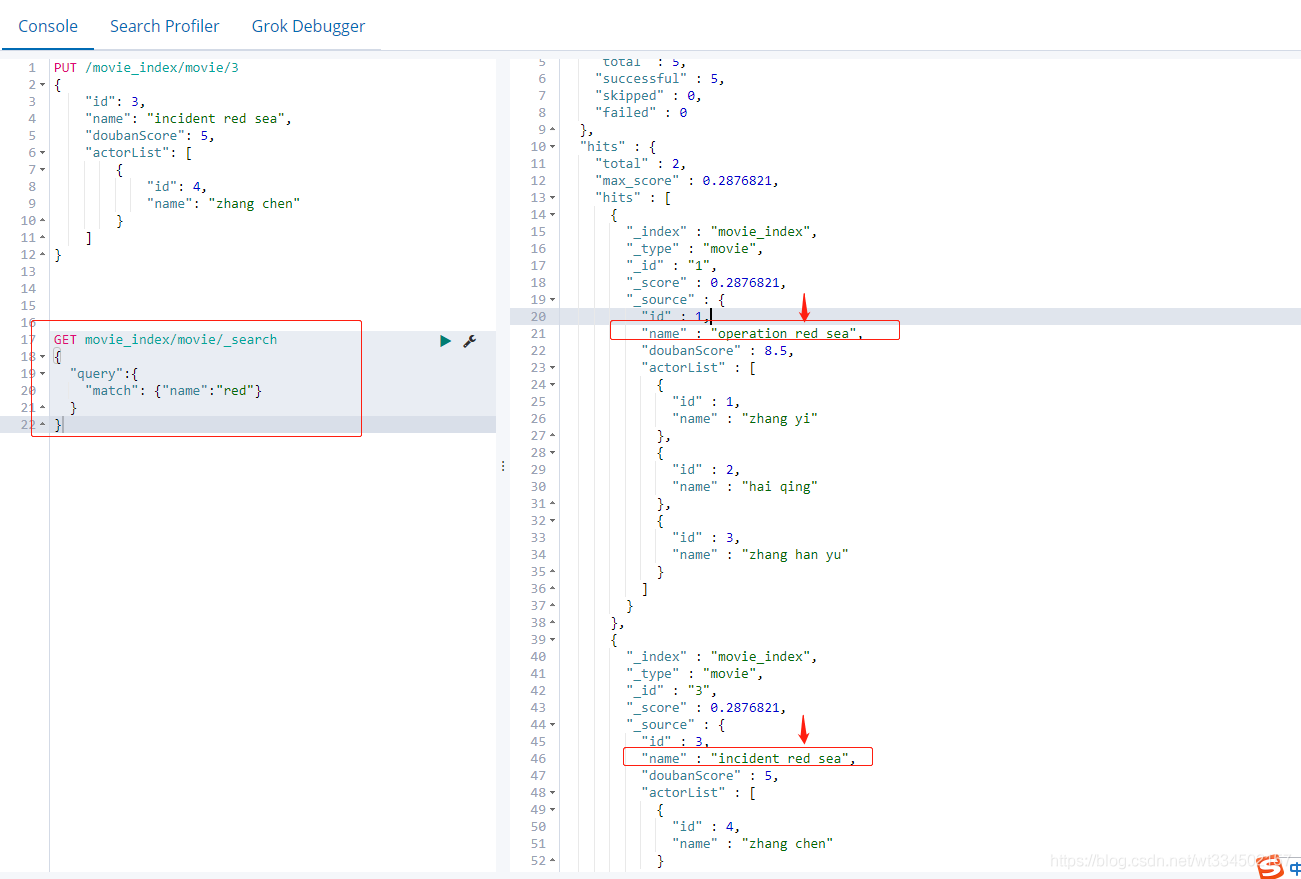
4.2.12 按分詞子屬性查詢
GET movie_index/movie/_search
{
"query":{
"match": {"actorList.name":"zhang"}
}
}
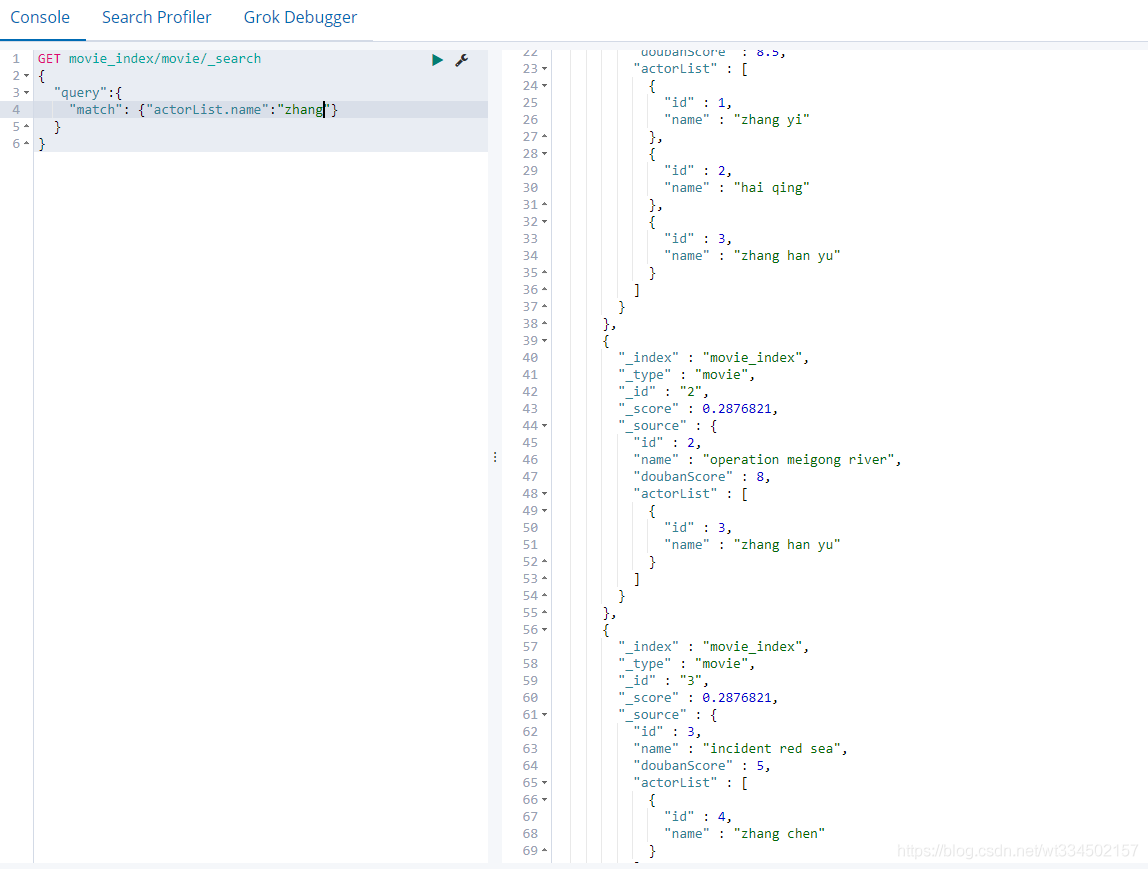
4.2.13 match phrase [ 短語查詢 ]
按短語查詢,不再利用分詞技術,直接用短語在原始資料中匹配
GET movie_index/movie/_search
{
"query":{
"match_phrase": {"name":"operation red"}
}
}
相當于operation red當成一個整體來查詢,不會operation查完再查詢red,并不做拆分一個個去匹配;name中單獨有operation和red的詞就不符合條件
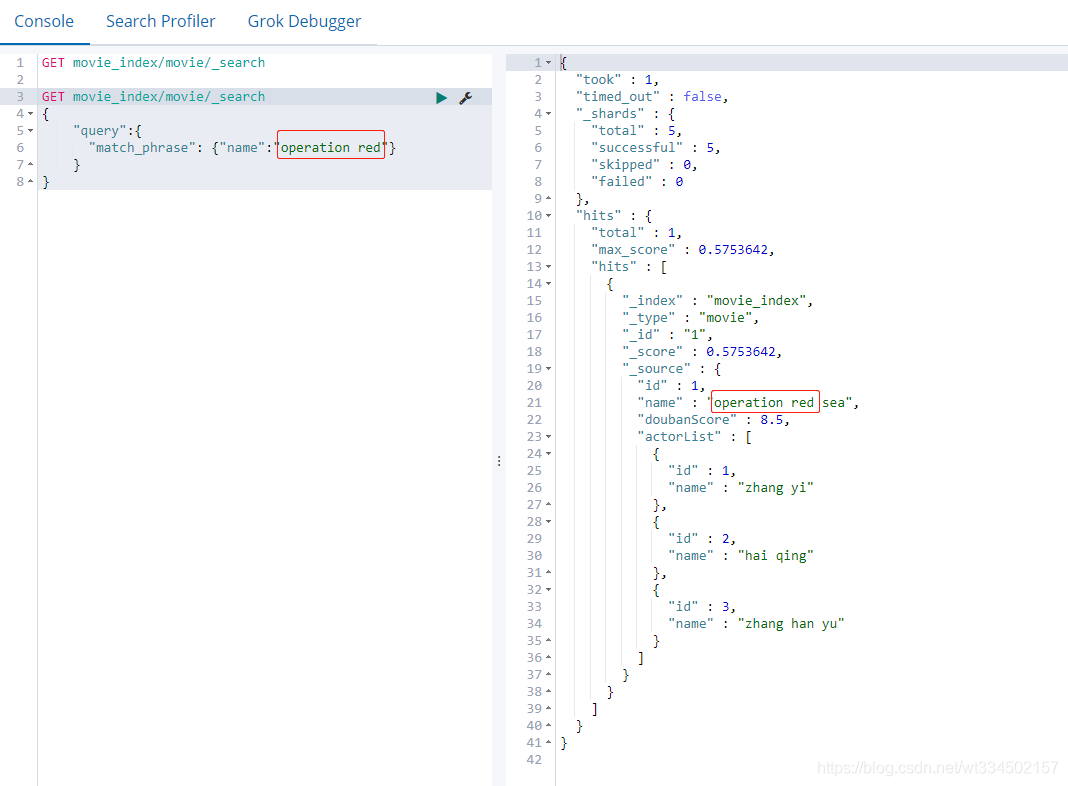
4.2.14 fuzzy查詢 [ 校正匹配 ]
fuzzy校正匹配分詞,當一個單詞都無法準確匹配,es通過一種演算法對非常接近的單詞也給與一定的評分,能夠查詢出來,但是消耗更多的性能,
GET movie_index/movie/_search
{
"query":{
"fuzzy": {"name":"rad"}
}
}
這個機制就相當于平時搜索百度內容時,輸入的內容可能輸錯了,主頁搜內容會提示:您是否要搜索是xxx,然后把搜索xxx的內容回傳
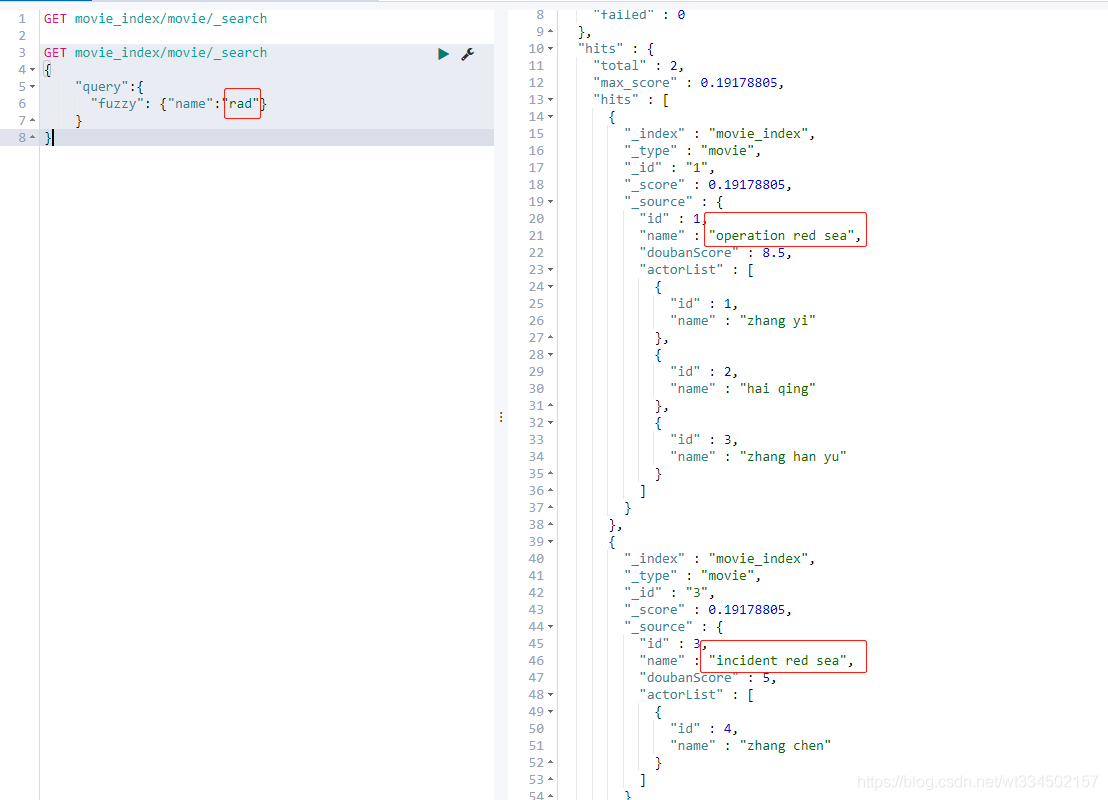
4.2.15 過濾–查詢后過濾(先查詢后過濾)
post_filter過濾為滿足條件的資料保留,不滿足的剔除;并不是符合post_filter給剔除,
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red"}
},
"post_filter":{
"term": {
"actorList.id": 3
}
}
}
先查詢滿足name中有red的是
id=1 -> “name”: “operation red sea”,
id=3 -> “name”: “incident red sea”,
在過濾出id為3的結果回傳
4.2.16 過濾–查詢前過濾(先過濾后查詢)
同樣需求下,先過濾后查詢優于先查詢后過濾
GET movie_index/movie/_search
{
"query":{
"bool":{
"filter":[ {"term": { "actorList.id": "1" }},
{"term": { "actorList.id": "3" }}
],
"must":{"match":{"name":"red"}}
}
}
}
4.2.17 過濾–按范圍過濾
? “name”: “operation red sea”,
? “doubanScore”: 8.5,
? “name”: “operation meigong river”,
? “doubanScore”: 8,
? “name”: “incident red sea”,
? “doubanScore”: 5,
查出電影評分8分及以上的結果
GET movie_index/movie/_search
{
"query": {
"bool": {
"filter": {
"range": {
"doubanScore": {"gte": 8}
}
}
}
}
}
結果回傳id為1和2的資料
| 關鍵詞 | 功能 |
|---|---|
| gt | 大于 |
| lt | 小于 |
| gte | 大于等于 great than or equals |
| lte | 小于等于 less than or equals |
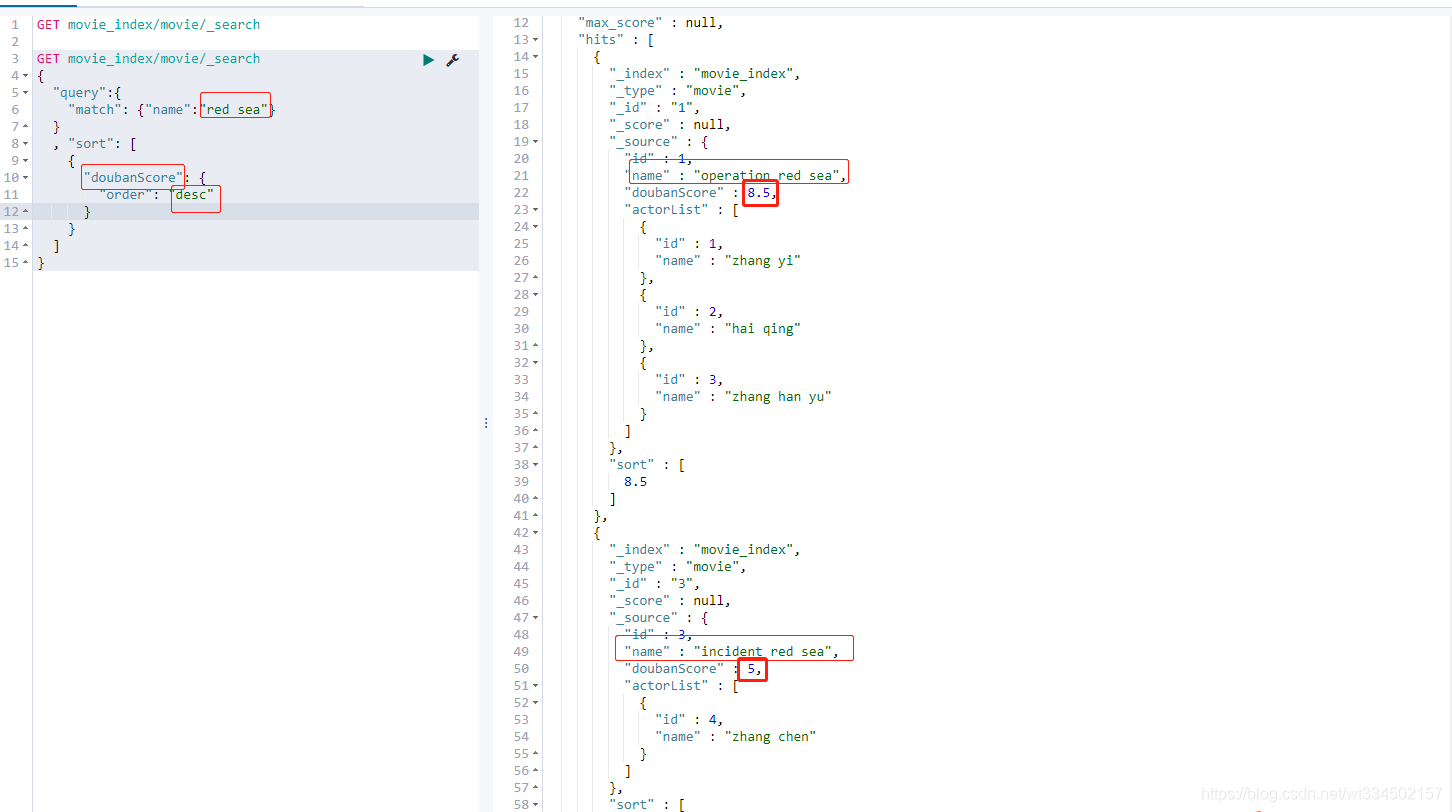
4.2.18 排序
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
}
, "sort": [
{
"doubanScore": {
"order": "desc"
}
}
]
}
先查出名稱包含red sea關鍵詞的資料,再根據查詢資料結果進行排序;asc 從小到大 | desc從大到小
4.2.19 分頁查詢
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
from定義了目標資料的偏移值
size定義當前回傳的事件數目,
如果不自定義數值則默認from為0,size為10,即所有的查詢默認僅僅回傳前10條資料,
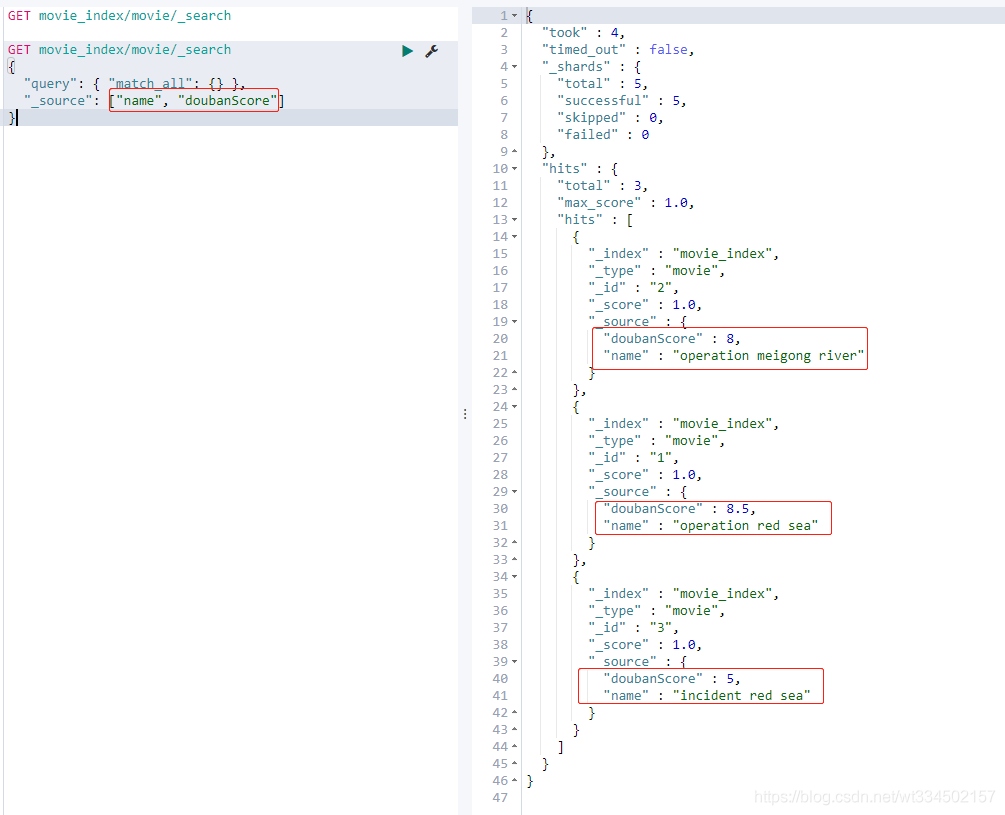
4.2.20 指定查詢的欄位
GET movie_index/movie/_search
{
"query": { "match_all": {} },
"_source": ["name", "doubanScore"]
}
4.2.21 高亮顯示
GET movie_index/movie/_search
{
"query":{
"match": {"name":"red sea"}
},
"highlight": {
"fields": {"name":{} }
}
}
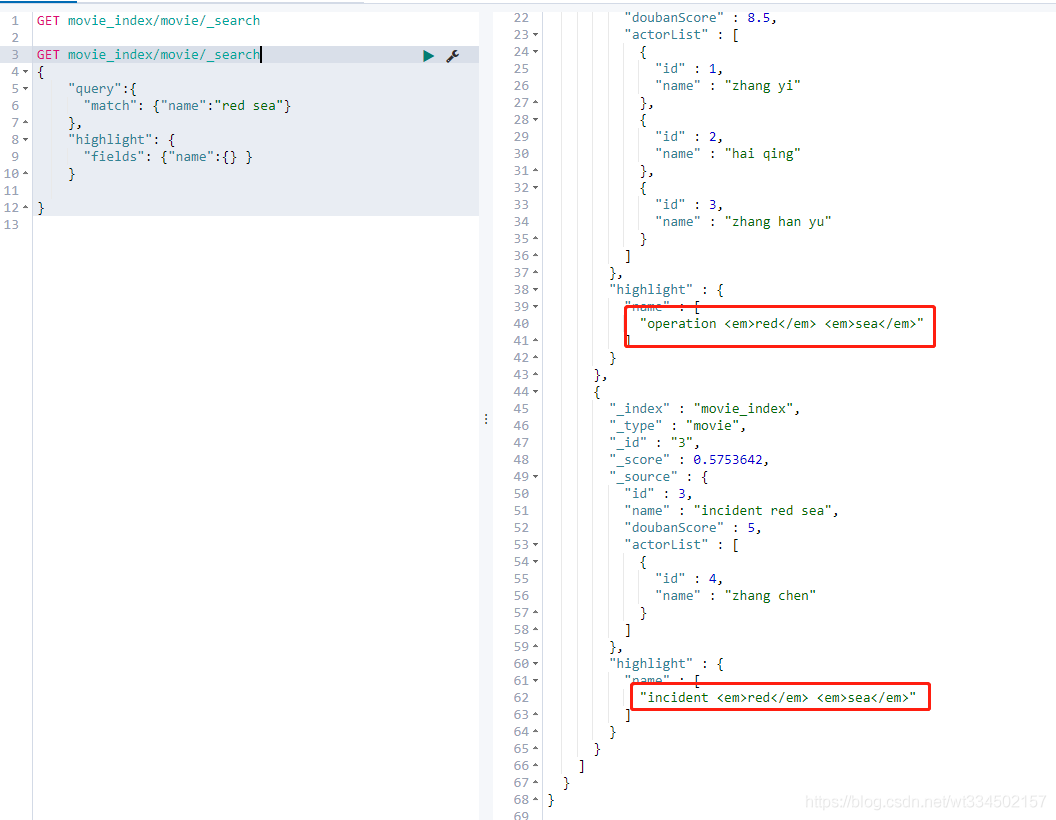
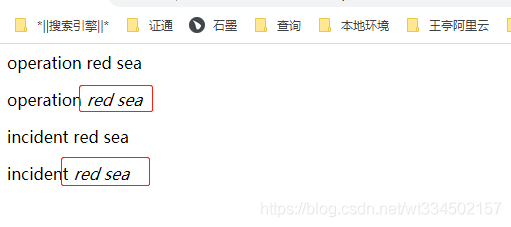
這里可以看到結果中包裹了一層em標簽,就是高亮顯示,加斜
可以創建個html后綴的檔案,輸入如下代碼,保存html檔案用瀏覽器打開,再進行觀察比對
<p>operation red sea</p>
<p>operation <em>red</em> <em>sea</em> </p>
<p>incident red sea </p>
<p>incident <em>red</em> <em>sea</em> </p>
4.2.22 聚合查詢
示例來說明1:取出每個演員共參演了多少部電影
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor": {
"terms": {
"field": "actorList.name.keyword"
}
}
}
}
# 查詢結果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "operation meigong river",
"doubanScore" : 8,
"actorList" : [
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "operation red sea",
"doubanScore" : 8.5,
"actorList" : [
{
"id" : 1,
"name" : "zhang yi"
},
{
"id" : 2,
"name" : "hai qing"
},
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"id" : 3,
"name" : "incident red sea",
"doubanScore" : 5,
"actorList" : [
{
"id" : 4,
"name" : "zhang chen"
}
]
}
}
]
},
"aggregations" : {
"groupby_actor" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "zhang han yu",
"doc_count" : 2
},
{
"key" : "hai qing",
"doc_count" : 1
},
{
"key" : "zhang chen",
"doc_count" : 1
},
{
"key" : "zhang yi",
"doc_count" : 1
}
]
}
}
}
示例來說明2:每個演員參演電影的平均分是多少,并按評分排序
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor_id": {
"terms": {
"field": "actorList.name.keyword" ,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score":{
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
# 查詢結果:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "operation meigong river",
"doubanScore" : 8,
"actorList" : [
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "operation red sea",
"doubanScore" : 8.5,
"actorList" : [
{
"id" : 1,
"name" : "zhang yi"
},
{
"id" : 2,
"name" : "hai qing"
},
{
"id" : 3,
"name" : "zhang han yu"
}
]
}
},
{
"_index" : "movie_index",
"_type" : "movie",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"id" : 3,
"name" : "incident red sea",
"doubanScore" : 5,
"actorList" : [
{
"id" : 4,
"name" : "zhang chen"
}
]
}
}
]
},
"aggregations" : {
"groupby_actor_id" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "hai qing",
"doc_count" : 1,
"avg_score" : {
"value" : 8.5
}
},
{
"key" : "zhang yi",
"doc_count" : 1,
"avg_score" : {
"value" : 8.5
}
},
{
"key" : "zhang han yu",
"doc_count" : 2,
"avg_score" : {
"value" : 8.25
}
},
{
"key" : "zhang chen",
"doc_count" : 1,
"avg_score" : {
"value" : 5.0
}
}
]
}
}
}
keyword 是某個字串欄位,專門儲存不分詞格式的副本 ,在某些場景中只允許只用不分詞的格式,比如過濾filter 比如 聚合aggs, 所以欄位要加上.keyword的后綴
keyword功能:
- 不進行分詞,直接索引
- 支持模糊、精確查詢
- 支持聚合
第三節 中文分詞
elasticsearch本身自帶的中文分詞,就是單純把中文一個字一個字的分開,根本沒有詞匯的概念,但是實際應用中,用戶都是以詞匯為條件,進行查詢匹配的,如果能夠把文章以詞匯為單位切分開,那么與用戶的查詢條件能夠更貼切的匹配上,查詢速度也更加快速,
GET _analyze
{
"text": ["wang ting niubi","今天給力"]
}
# 結果如下:
{
"tokens" : [
{
"token" : "wang",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "ting",
"start_offset" : 5,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "niubi",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "今",
"start_offset" : 16,
"end_offset" : 17,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "天",
"start_offset" : 17,
"end_offset" : 18,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "給",
"start_offset" : 18,
"end_offset" : 19,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "力",
"start_offset" : 19,
"end_offset" : 20,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
通過示例可以明顯看出,“wang ting niubi”,“今天給力”;英文分詞根據空格分詞相對合理,但中文一個個字拆開顯然不合適(今天 、給力 兩個詞語沒有被識別)
分詞器下載網址:https://github.com/medcl/elasticsearch-analysis-ik
【注意】:建議找到和es版本一致的ik版本最佳;找到zip包下載
安裝
# 進入es的plugins目錄
wangting@ops01:/home/wangting >cd /opt/module/elasticsearch-6.6.0/plugins/
# 創建一個插件目錄(一個插件對應一個plugins下的子目錄)
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >mkdir ik
# 下載ik插件zip包
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >ls
elasticsearch-analysis-ik-6.6.0.zip
# 解壓縮安裝包并清理zip檔案
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >unzip elasticsearch-analysis-ik-6.6.0.zip && rm elasticsearch-analysis-ik-6.6.0.zip
# 目錄結構
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >ll
total 1432
-rw-r--r-- 1 wangting wangting 263965 May 6 2018 commons-codec-1.9.jar
-rw-r--r-- 1 wangting wangting 61829 May 6 2018 commons-logging-1.2.jar
drwxr-xr-x 2 wangting wangting 4096 Aug 26 2018 config
-rw-r--r-- 1 wangting wangting 54693 Jan 30 2019 elasticsearch-analysis-ik-6.6.0.jar
-rw-r--r-- 1 wangting wangting 736658 May 6 2018 httpclient-4.5.2.jar
-rw-r--r-- 1 wangting wangting 326724 May 6 2018 httpcore-4.4.4.jar
-rw-r--r-- 1 wangting wangting 1805 Jan 30 2019 plugin-descriptor.properties
-rw-r--r-- 1 wangting wangting 125 Jan 30 2019 plugin-security.policy
# 分發插件至其它節點
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik >cd ..
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >scp -r ik ops02:/opt/module/elasticsearch-6.6.0/plugins/
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >scp -r ik ops03:/opt/module/elasticsearch-6.6.0/plugins/
【注意】:插件安裝需重啟es才生效,否則使用不到對應功能,如下圖
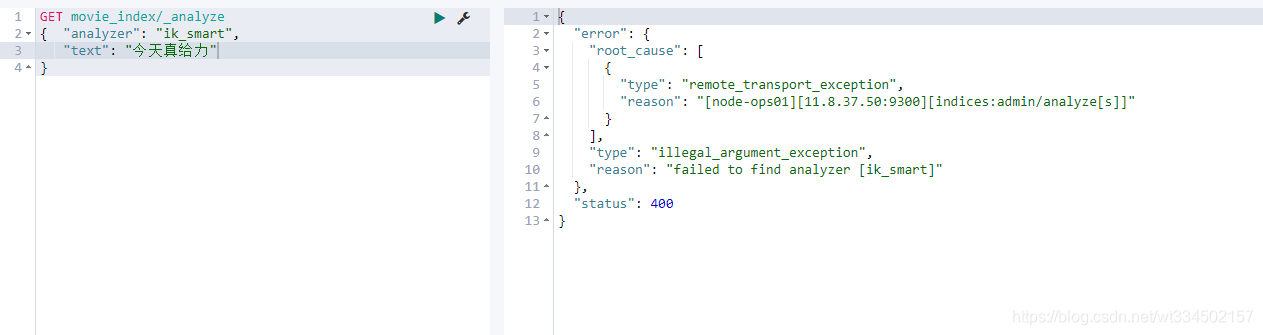
重啟es:
# 節點ops01 ; 查找es對應行程號
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >jps | grep Elasticsearch|awk -F" " '{print $1}'
95973
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >kill -9 95973
# 節點ops02 ; 查找es對應行程號
wangting@ops02:/opt/module/elasticsearch-6.6.0/plugins >jps | grep Elasticsearch|awk -F" " '{print $1}'
109175
wangting@ops02:/opt/module/elasticsearch-6.6.0/plugins >kill -9 109175
# 節點ops03 ; 查找es對應行程號
wangting@ops03:/opt/module/elasticsearch-6.6.0/plugins >jps | grep Elasticsearch|awk -F" " '{print $1}'
41777
wangting@ops03:/opt/module/elasticsearch-6.6.0/plugins >kill -9 41777
# 各節點均使用如下命令再次啟動es
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins >cd /opt/module/elasticsearch-6.6.0/bin/
wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >./elasticsearch -d
測驗使用ik中文分詞
常用的ik分詞器功能有ik_smart和ik_max_word
ik_smart
逐個去匹配,每個字使用1次
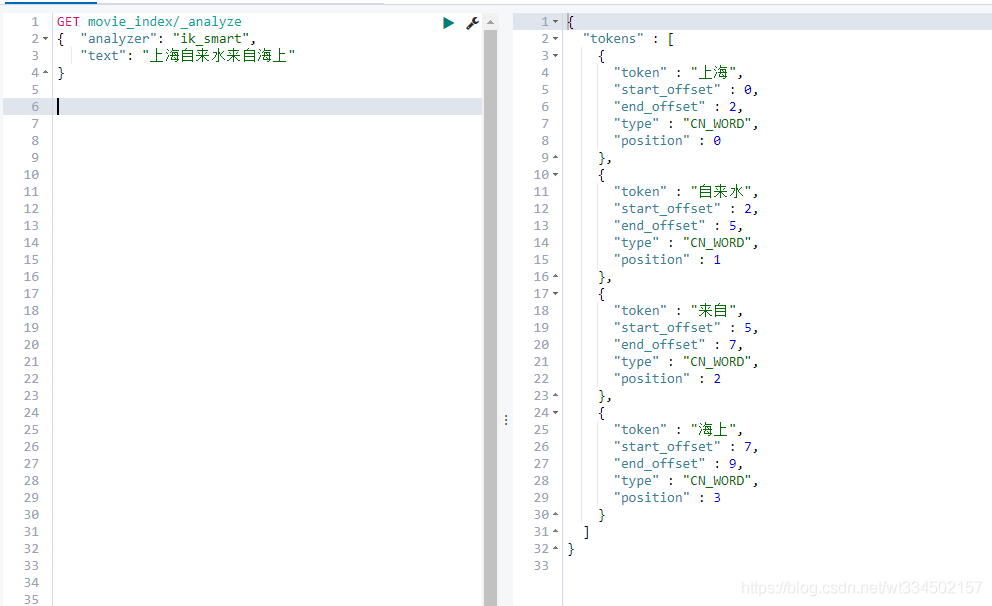
ik_max_word
逐個去匹配,每個字前后能連成詞都會展示,相當于盡可能多的形成關系詞
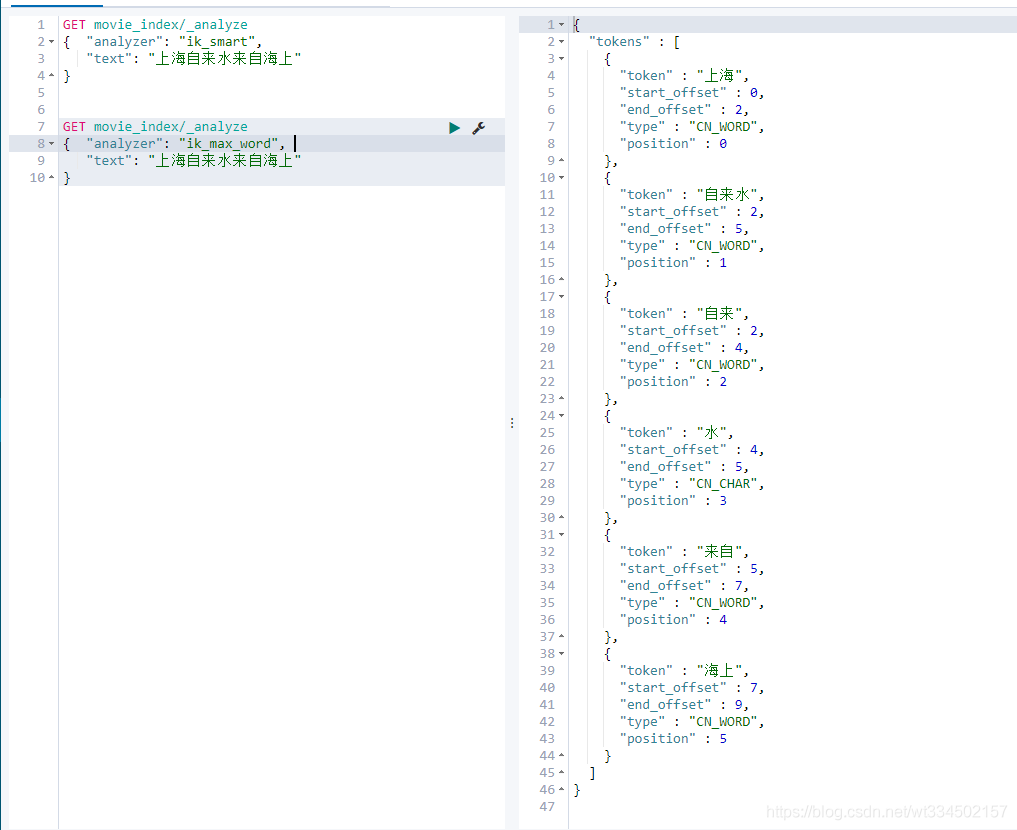
【注意】:從上面示例可以看出,不同的分詞器,分詞有明顯的區別,所以以后定義一個type不能再使用默認的mapping,要手工建立mapping來指定分詞器, 因為要根據使用場景選擇適用合理的分詞器
自定義中文詞庫
生活中,經常會出現一些新的熱門詞語,比如近期我接觸最多的就是yyds永遠的神,,,如果始終用之前的詞庫,那像 永遠的神 就可能分成:永遠、的、神,不會是我們所想的永遠的神作為一個整體,
那這種情況就需要維護一套用戶自定義的中文詞庫,
在沒有自定義中文詞庫之前,我們先查一個示例,把結果留下,一會安裝完自定義詞庫后作為對比:
安裝前:
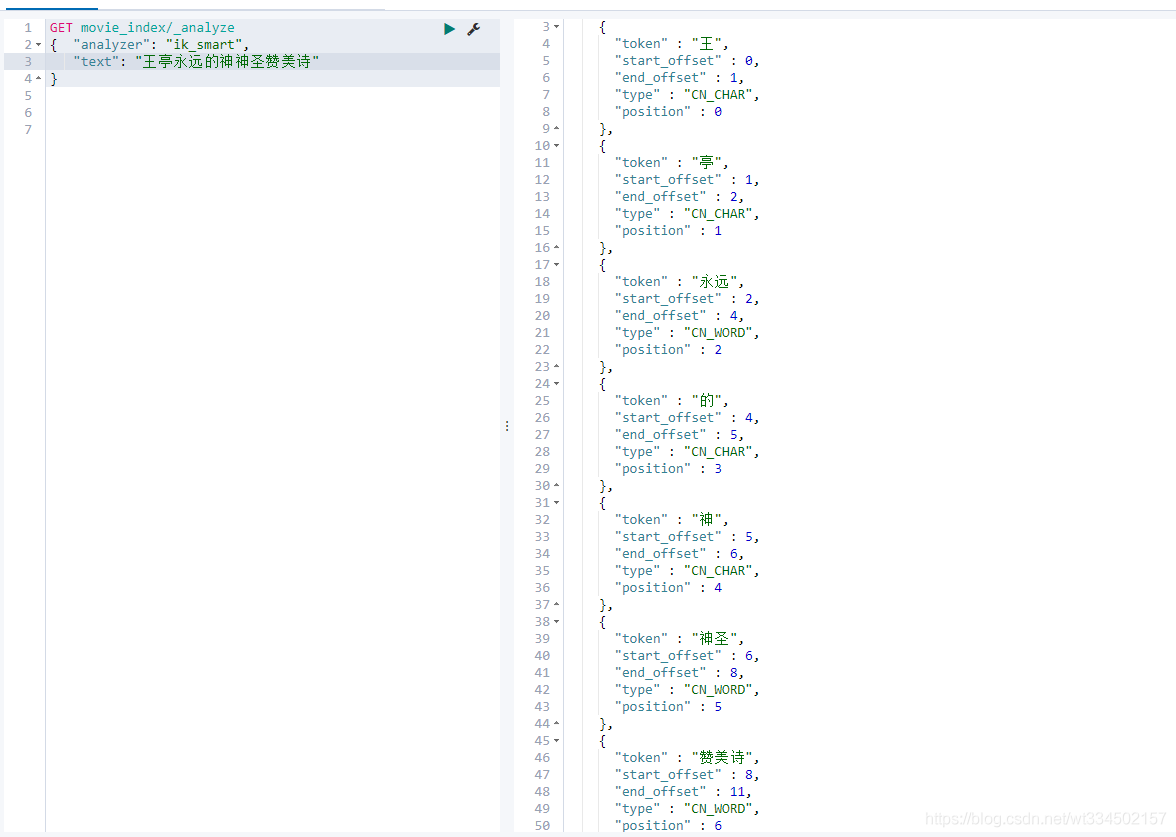
安裝部署自定義詞庫:
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >pwd
/opt/module/elasticsearch-6.6.0/plugins/ik/config
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >ls
extra_main.dic extra_single_word.dic extra_single_word_full.dic extra_single_word_low_freq.dic extra_stopword.dic IKAnalyzer.cfg.xml main.dic preposition.dic quantifier.dic stopword.dic suffix.dic surname.dic
# 修改ik插件的config/IKAnalyzer.cfg.xml配置
# <entry key="remote_ext_dict">http://11.8.38.86/fenci/esword.txt</entry> 這行配置一個nginx代理地址
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 擴展配置</comment>
<!--用戶可以在這里配置自己的擴展字典 -->
<entry key="ext_dict"></entry>
<!--用戶可以在這里配置自己的擴展停止詞字典-->
<entry key="ext_stopwords"></entry>
<!--用戶可以在這里配置遠程擴展字典 -->
<entry key="remote_ext_dict">http://11.8.38.86/fenci/esword.txt</entry>
<!--用戶可以在這里配置遠程擴展停止詞字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
# 切換至有nginx服務的機器上(沒有nginx需要自行部署安裝)
root@ops04:/usr/local/nginx-1.10/conf #cd /usr/local/nginx-1.10/
root@ops04:/usr/local/nginx-1.10 #mkdir ik
root@ops04:/usr/local/nginx-1.10 #cd ik
root@ops04:/usr/local/nginx-1.10/ik #mkdir fenci
root@ops04:/usr/local/nginx-1.10/ik #cd fenci
root@ops04:/usr/local/nginx-1.10/ik/fenci #echo "王亭" >> esword.txt
root@ops04:/usr/local/nginx-1.10/ik/fenci #echo "永遠的神" >> esword.txt
root@ops04:/usr/local/nginx-1.10/ik/fenci #echo "神圣贊美詩" >> esword.txt
root@ops04:/usr/local/nginx-1.10/ik/fenci #cat esword.txt
王亭
永遠的神
神圣贊美詩
root@ops04:/usr/local/nginx-1.10/ik/fenci #vim /usr/local/nginx-1.10/conf/nginx.conf
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
# 增加如下配置:
location /fenci/ {
root ik;
}
root@ops04:/usr/local/nginx-1.10/ik/fenci #/usr/local/nginx-1.10/sbin/nginx -s reload
# 地址必須和IKAnalyzer.cfg.xml配置項對應;也可以先把nginx弄好再配置IKAnalyzer.cfg.xml合理些
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >curl http://11.8.38.86/fenci/esword.txt
王亭
永遠的神
神圣贊美詩
# 修改的xml配置,分發至其它節點
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >scp IKAnalyzer.cfg.xml ops02:/opt/module/elasticsearch-6.6.0/plugins/ik/config/
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >scp IKAnalyzer.cfg.xml ops03:/opt/module/elasticsearch-6.6.0/plugins/ik/config/
# 重啟es(各節點)
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >jps | grep Elasticsearch|awk -F" " '{print $1}'
13077
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >kill -9 13077
wangting@ops01:/opt/module/elasticsearch-6.6.0/plugins/ik/config >cd /opt/module/elasticsearch-6.6.0/bin/
wangting@ops01:/opt/module/elasticsearch-6.6.0/bin >./elasticsearch -d
重啟es后重新再測驗:(已經可以成功識別出新定義的詞語)
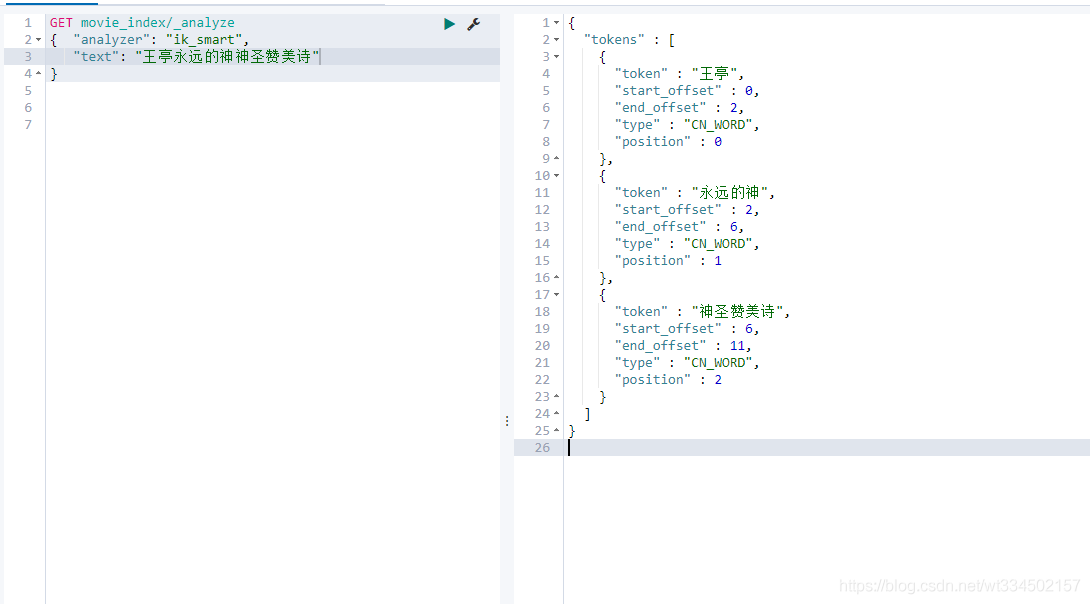
第四節 關于mapping
type可以類比成table,MySQL在create table時會定義每個欄位的欄位型別約束;那es每個欄位的資料型別也是可以定義的;實際上每個type中的欄位是什么資料型別,由es的mapping定義,
【注意】:如果沒有設定mapping,則系統會自動根據一條資料的格式來推斷出應該的資料格式
4.4.1 查看type的mapping
GET movie_index/_mapping/movie
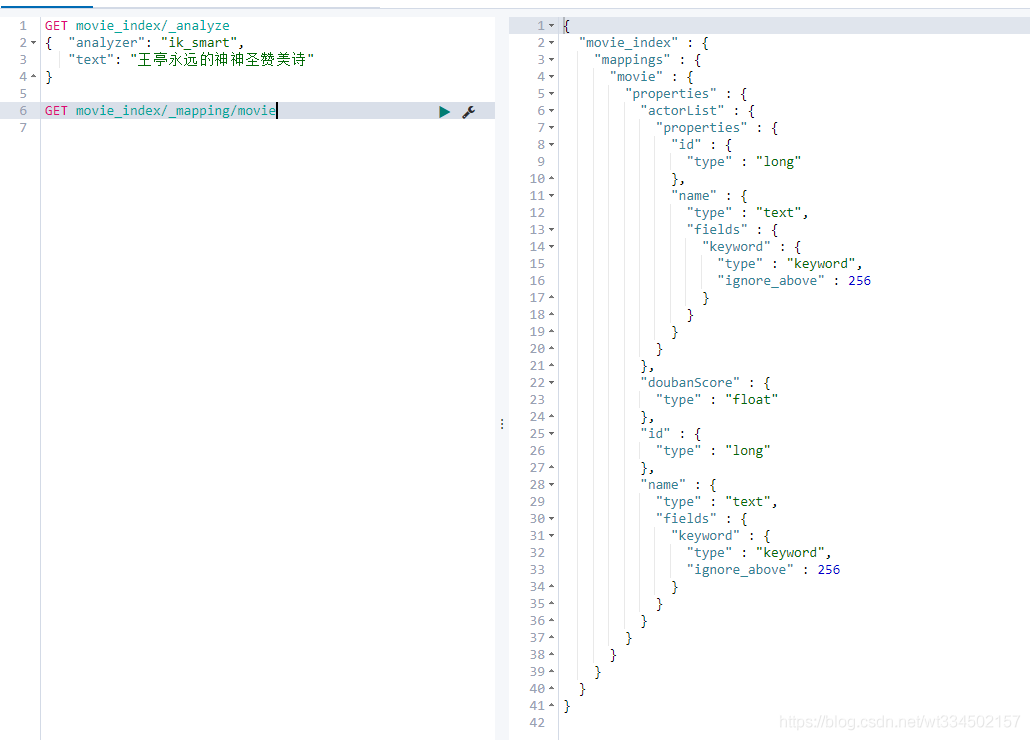
常見的型別:
? true/false → boolean
? 1020 → long
? 20.1 → double
? “2018-02-01” → date
? “hello world” → text + keyword
【注意】:
-
默認type只有text型別會進行分詞,keyword是不會分詞的字串,
-
mapping除了自動定義,還可以手動定義,但是只能對新加的、沒有資料的欄位進行定義,一旦有了資料就無法再做修改了,
-
雖然每個Field的資料放在不同的type下,但是同一個名字的Field在一個index下只能有一種mapping定義,
4.4.2 基于中文文辭搭建索引
創建mapping
PUT movie_chn
{
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text"
, "analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
name -> 定義成text型別 使用ik中文分詞ik_smart
執行結果:
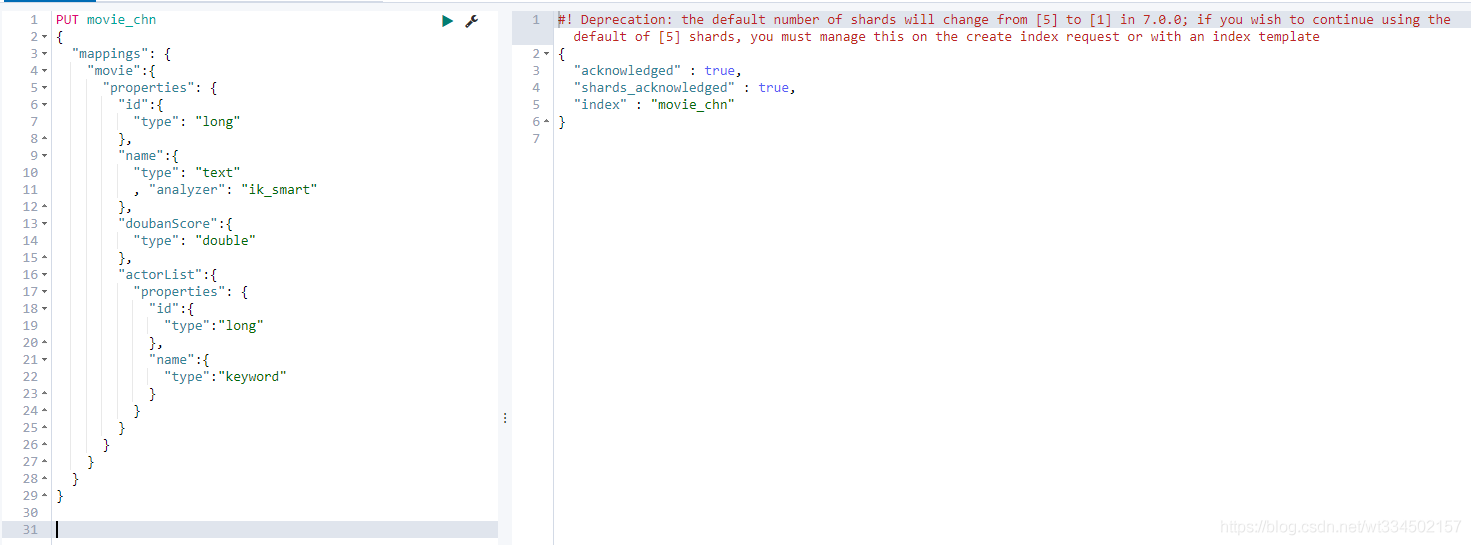
創建完成后
PUT插入資料:
# 資料1
PUT /movie_chn/movie/1
{ "id":1,
"name":"紅海行動",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"張譯"},
{"id":2,"name":"海清"},
{"id":3,"name":"張涵予"}
]
}
# 資料2
PUT /movie_chn/movie/2
{
"id":2,
"name":"湄公河行動",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"張涵予"}
]
}
# 資料3
PUT /movie_chn/movie/3
{
"id":3,
"name":"紅海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"張晨"}
]
}
name:紅海行動、湄公河行動、紅海事件
測驗查詢效果:
查詢電影名為紅海戰役的結果:
GET /movie_chn/movie/_search
{
"query": {
"match": {
"name": "紅海戰役"
}
}
}
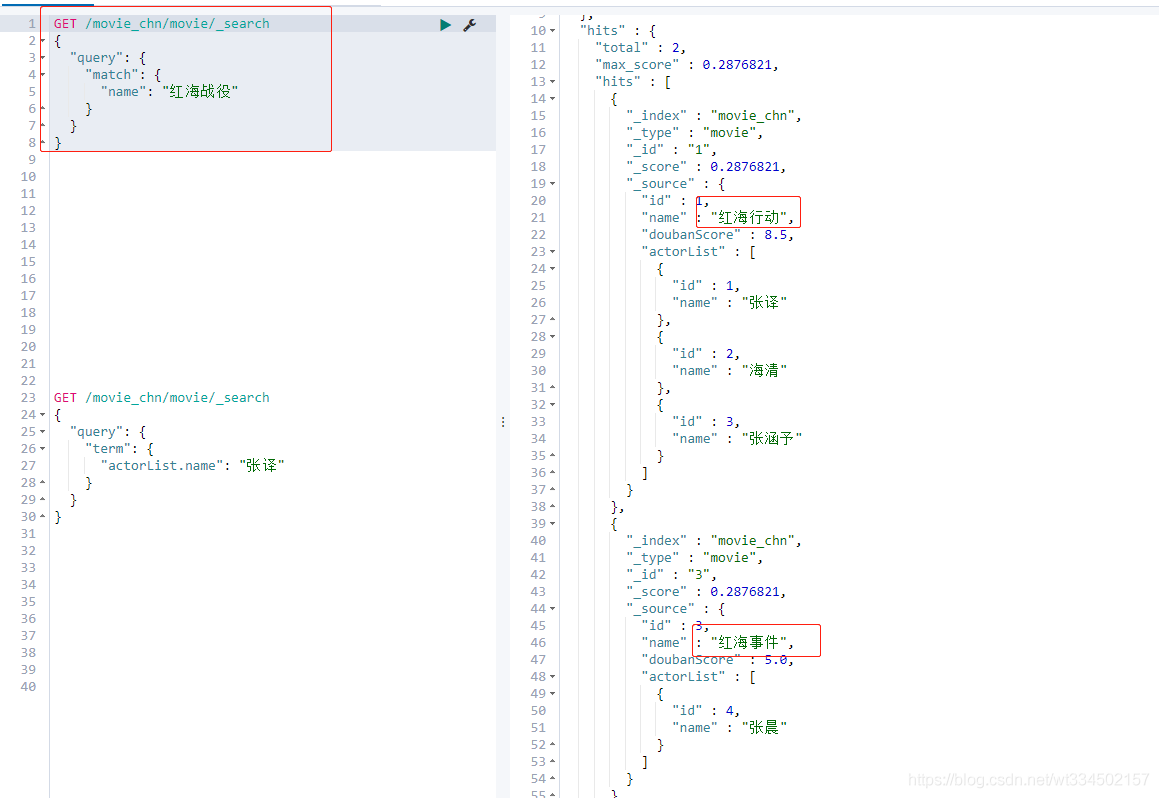
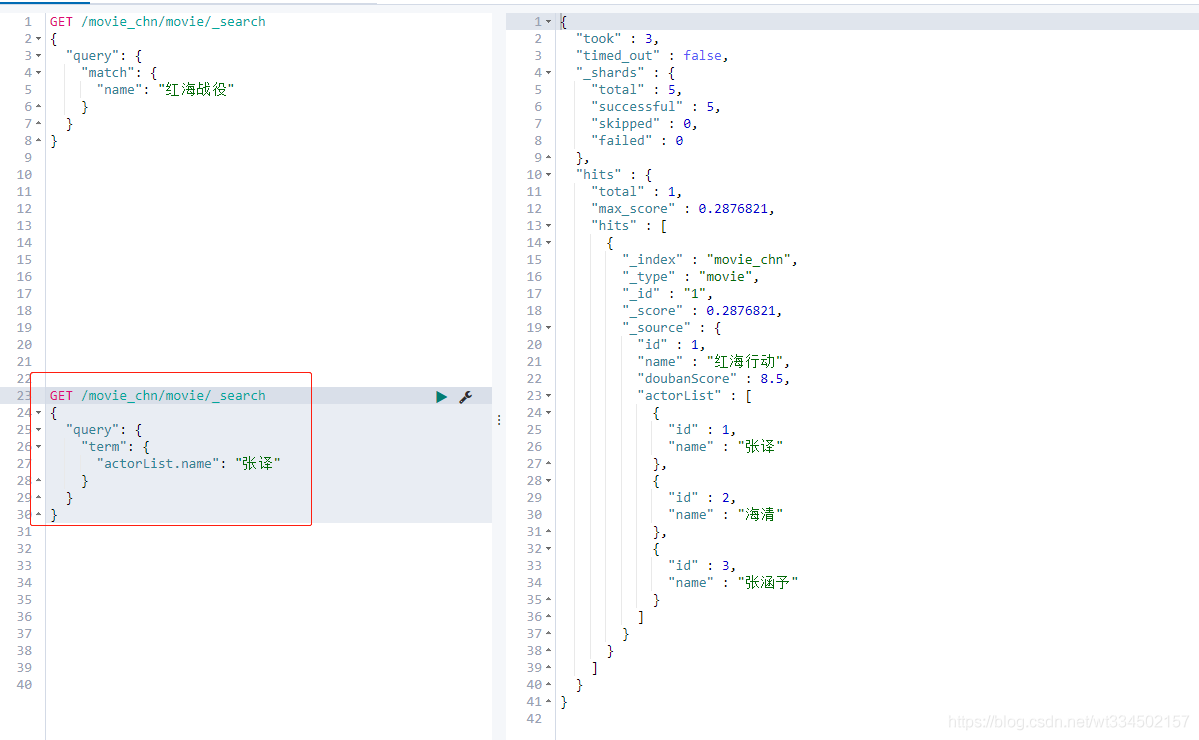
查詢演員有張譯的結果:
GET /movie_chn/movie/_search
{
"query": {
"term": {
"actorList.name": "張譯"
}
}
}
第五節 索引別名 _aliases
索引別名就像一個快捷方式或軟連接,可以指向一個或多個索引,也可以給任何一個需要索引名的API來使用,別名 帶給我們極大的靈活性,允許我們做下面這些:
1.給多個索引分組 (例如, last_three_months -> 可以指向多個)
2.給索引的一個子集創建視圖
3.在運行的集群中可以無縫的從一個索引切換到另一個索引
4.5.1 創建索引別名
PUT movie_chn_2
{ "aliases": {
"movie_chn_2020-query": {}
},
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text"
, "analyzer": "ik_smart"
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
定義別名:
“aliases”: {
“movie_chn_2020-query”: {}
}
已存在的索引增加別名
POST _aliases
{
"actions": [
{ "add": { "index": "movie_chn_2", "alias": "movie_chn_2020-query" }}
]
}
# 可以繼續增加
POST _aliases
{
"actions": [
{ "add": { "index": "movie_chn_2", "alias": "movie_chn_2020-query" }}
]
}
也可以通過加過濾條件縮小查詢范圍,建立一個子集視圖
POST _aliases
{
"actions": [
{ "add":
{ "index": "movie_chn_2",
"alias": "movie_chn0919-query-zhhy",
"filter": {
"term": { "actorList.id": "3"
}
}
}
}
]
}
4.5.2 查詢別名
GET movie_chn_2020-query/_search
4.5.3 洗掉某個索引別名
POST _aliases
{
"actions": [
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_2020-query" }}
]
}
4.5.4 為別名切換
POST /_aliases
{
"actions": [
{ "remove": { "index": "movie_chn_2", "alias": "movie_chn_2021-query" }},
{ "add": { "index": "movie_chn", "alias": "movie_chn_2021-query" }}
]
}
4.5.5 查詢別名串列
GET _cat/aliases?v

第六節 索引模板
Index Template 索引模板,是創建索引的模具,其中可以定義一系列規則來幫助我們構建符合特定業務需求的索引的 mappings 和 settings,通過使用 Index Template 可以讓我們的索引具備可預知的一致性,
索引模板可以更方便的建立索引,例如當還沒有建好索引的時候,es獲取到第一條資料進來需要保存時,如果資料里的索引前綴可以匹配到索引模板的index pattern,則es會根據模板直接生成該索引
4.6.1 分割索引
分割索引就是根據時間間隔把一個業務索引切分成多個索引,
舉例:
把order_info變成order_info_0801,order_info_0802,order_info_0803,…
這樣做的好處有兩個:
- 結構變化的靈活性:因為elasticsearch不允許對資料結構進行修改,但是實際使用中索引的結構和配置難免變化,那么只要對下一個間隔的索引進行修改,原來的索引位置原狀,這樣就有了一定的靈活性,
- 查詢范圍優化: 因為一般情況并不會查詢全部時間周期的資料,那么通過切分索引,物理上減少了掃描資料的范圍,也是對性能的優化,
4.6.2 創建索引模板
PUT _template/template_movie
{
"index_patterns": ["movie_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"movie_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
其中 “index_patterns”: [“movie_test*”], 的含義就是凡是往movie_test開頭的索引寫入資料時,例如向movie_test_001索引寫入資料,如果索引movie_test_001不存在,那么es會根據movie_test模板自動建立索引,
shard數量設定:
"settings": {
"number_of_shards": 1
},
在 “aliases” 中用{index}表示,獲得真正的創建的索引名,
POST movie_test_20210801/_doc
{
"id":"100",
"name":"aaa"
}
POST movie_test_20210801/_doc
{
"id":"101",
"name":"bbb"
}
POST movie_test_20210802/_doc
{
"id":"102",
"name":"ccc"
}
POST movie_test_20210801/_doc
{
"id":"103",
"name":"ddd"
}
4.6.3 查詢已有模板串列
GET _cat/templates
4.6.4 查看某個模板詳情
GET _template/template_movie*
第一條資料進來需要保存時,如果資料里的索引前綴可以匹配到索引模板的index pattern,則es會根據模板直接生成該索引
4.6.1 分割索引
分割索引就是根據時間間隔把一個業務索引切分成多個索引,
舉例:
把order_info變成order_info_0801,order_info_0802,order_info_0803,…
這樣做的好處有兩個:
- 結構變化的靈活性:因為elasticsearch不允許對資料結構進行修改,但是實際使用中索引的結構和配置難免變化,那么只要對下一個間隔的索引進行修改,原來的索引位置原狀,這樣就有了一定的靈活性,
- 查詢范圍優化: 因為一般情況并不會查詢全部時間周期的資料,那么通過切分索引,物理上減少了掃描資料的范圍,也是對性能的優化,
4.6.2 創建索引模板
PUT _template/template_movie
{
"index_patterns": ["movie_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"movie_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
其中 “index_patterns”: [“movie_test*”], 的含義就是凡是往movie_test開頭的索引寫入資料時,例如向movie_test_001索引寫入資料,如果索引movie_test_001不存在,那么es會根據movie_test模板自動建立索引,
shard數量設定:
"settings": {
"number_of_shards": 1
},
在 “aliases” 中用{index}表示,獲得真正的創建的索引名,
POST movie_test_20210801/_doc
{
"id":"100",
"name":"aaa"
}
POST movie_test_20210801/_doc
{
"id":"101",
"name":"bbb"
}
POST movie_test_20210802/_doc
{
"id":"102",
"name":"ccc"
}
POST movie_test_20210801/_doc
{
"id":"103",
"name":"ddd"
}
4.6.3 查詢已有模板串列
GET _cat/templates
4.6.4 查看某個模板詳情
GET _template/template_movie*
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292656.html
標籤:其他