一、Spark的介紹
1、Spark定義
Spark是一種基于記憶體的快速、通用、可擴展的大資料分析的大規模計算引擎,(計算引擎:可以作為框架來使用,也可以作為一個行程運行在服務器內部,)
優點:
1.支持并行,效率高,計算快,
2.記憶體型計算引擎,
3.本身不存盤資料,借助hdfs/hbase/redis/rdbms等,
2、Spark VS MapReduce

mapreduce編程模型= map + shuffle + reduce
需求:通過單個map+reduce解決不了
解決方案:mr1.jar(map+reduce) ——> HDFS ——> mr2.jar(map+reduce) 對多個mr進行編排,

.算子().算子().算子()
中間算子的執行結果可以不需要落盤,直接交給后續算子操作,提高開發效率,執行效率,
spark執行程序中也有shuffle,也會產生落盤,
3、Spark內置模塊
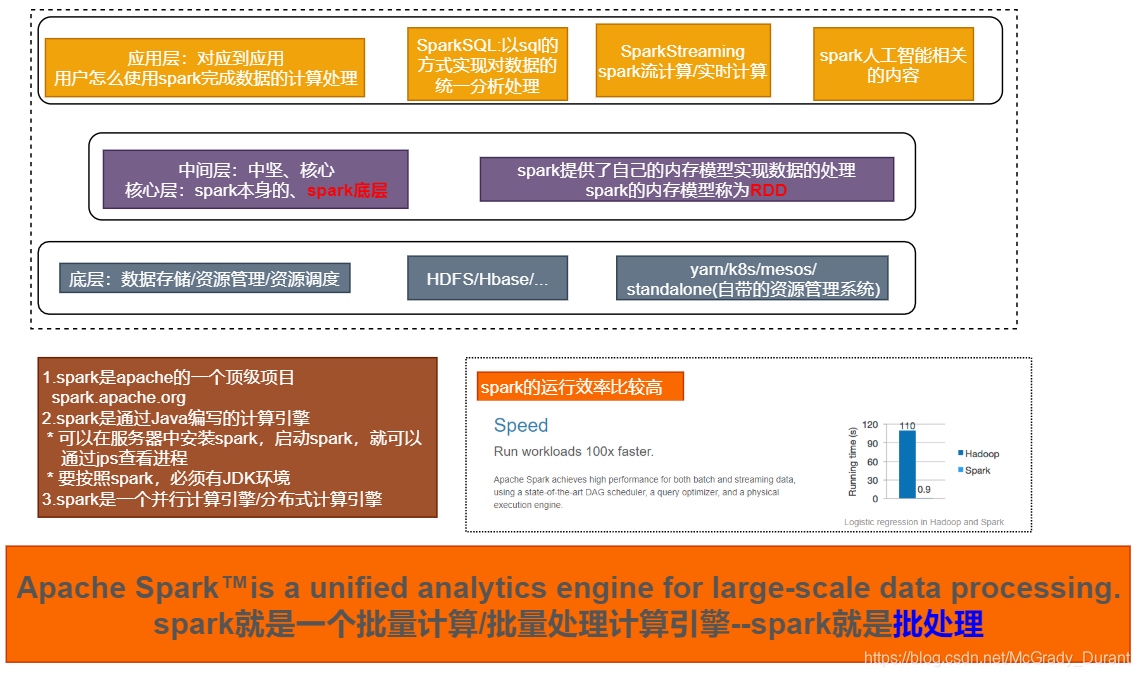
Spark Core:實作了Spark的基本功能,包含任務調度、記憶體管理、錯誤恢復、與存盤系統互動等模塊,Spark Core中還包含了對彈性分布式資料集(Resilient Distributed DataSet,簡稱RDD)的API定義,
Spark SQL:是Spark用來操作結構化資料的程式包,通過Spark SQL,我們可以使用 SQL或者Apache Hive版本的SQL方言(HQL)來查詢資料,Spark SQL支持多種資料源,比如Hive表、Parquet以及JSON等,
Spark Streaming:是Spark提供的對實時資料進行流式計算的組件,提供了用來操作資料流的API,并且與Spark Core中的 RDD API高度對應,
Spark MLlib:提供常見的機器學習(ML)功能的程式庫,包括分類、回歸、聚類、協同過濾等,還提供了模型評估、資料 匯入等額外的支持功能,
集群管理器:Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計 算,為了實作這樣的要求,同時獲得最大靈活性,Spark支持在各種集群管理器(Cluster Manager)上運行,包括Hadoop YARN、Apache Mesos,以及Spark自帶的一個簡易調度 器,叫作獨立調度器,
二、安裝Spark
1. Spark相關地址
1.官網地址
http://spark.apache.org/
2.檔案查看地址
http://spark.apache.org/docs/2.4.3/
3.下載地址
https://spark.apache.org/downloads.html
2. 重要角色
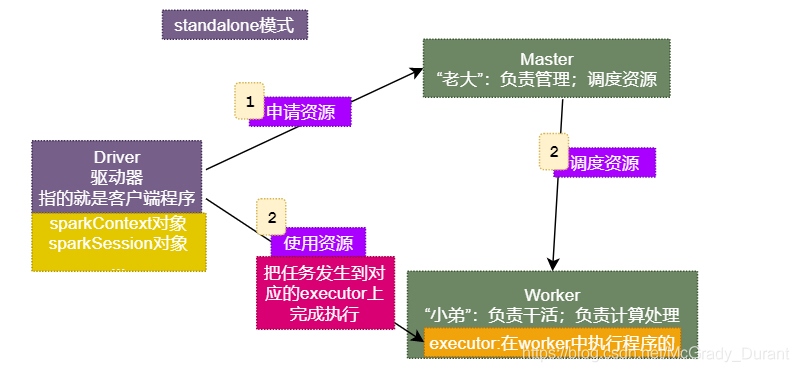
2.1 Driver(驅動器)
Spark的驅動器是執行開發程式中的main方法的行程,它負責開發人員撰寫的用來創建SparkContext、創建RDD,以及進行RDD的轉化操作和行動操作代碼的執行,
如果你是用spark shell,那么當你啟動Spark shell的時候,系統后臺自啟了一個Spark驅動器程式,就是在Spark shell中預加載的一個叫作 sc的SparkContext物件,如果驅動器程式終止,那么Spark應用也就結束了,
主要負責:
1)把用戶程式轉為job
2)跟蹤Executor的運行狀況
3)為執行器(Executor)節點調度任務(task)
4)UI展示應用運行狀況
2.2 Executor(執行器)
Spark Executor是一個作業行程,負責在 Spark 作業中運行任務,任務間相互獨立,Spark 應用啟動時,Executor節點被同時啟動,并且始終伴隨著整個 Spark 應用的生命周期而存在,
如果有Executor節點發生了故障或崩潰,Spark 應用也可以繼續執行,會將出錯節點上的任務調度到其他Executor節點上繼續運行,
主要負責:
1)負責運行組成 Spark 應用的任務,并將結果回傳給驅動器行程;
2)通過自身的塊管理器(Block Manager)為用戶程式中要求快取的RDD提供記憶體式存盤,RDD是直接快取在Executor行程內的,因此任務可以在運行時充分利用快取資料加速運算,
https://www.cnblogs.com/itboys/p/7782826.html
3. Standalone模式
準備作業:正常安裝JDK、Hadoop(啟動hdfs)
-
上傳并解壓spark安裝包
[root@spark1 modules]# tar -zxf spark-2.4.3-bin-hadoop2.7.tgz -C /opt/installs [root@spark1 installs]# mv spark-2.4.3-bin-hadoop2.7 spark2.4.3 -
修改組態檔
[root@spark1 installs]# cd spark2.4.3/conf [root@spark1 conf]# mv slaves.template slaves [root@spark1 conf]# mv spark-env.sh.template spark-env.sh [root@spark1 conf]# vi slaves #配置Spark集群節點主機名 hadoop10 [root@spark1 conf]# vi spark-env.sh #宣告Spark集群中Master的主機名和埠號 SPARK_MASTER_HOST=spark1 SPARK_MASTER_PORT=7077 -
在spark中配置JAVA_HOME
[root@spark1 conf]# cd .. [root@spark1 spark]# cd sbin [root@spark1 sbin]# vi spark-config.sh #在最后增加 JAVA_HOME 配置 export JAVA_HOME=/opt/installs/jdk1.8 -
啟動Spark
[root@spark1 spark]# sbin/start-all.sh [root@spark1 spark]# jps 分別查看三個節點的啟動結果 2054 Jps 2008 Worker 1933 Master
spark兩種測驗方式:
bin/spark-shell (基于命令列的方式)
bin/spark-submit (基于jar包提交的方式)
新建一個a.txt如下,并且上傳到hdfs之上
hello hello hello
world world hello
[root@spark1 spark]# bin/spark-shell --master spark://spark1:7077
scala> sc.textFile("hdfs://spark1:9000/a.txt")
.flatMap(_.split(" "))
.map((_,1))
.groupBy(_._1)
.map(t=>(t._1,t._2.size))
.collect
res0: Array[(String, Int)] = Array((hello,4), (world,2))
4. JobHistoryServer配置

1. 修改spark-default.conf.template名稱, 修改spark-default.conf檔案,開啟Log
[root@spark1 conf]# mv spark-defaults.conf.template spark-defaults.conf
[root@spark1 conf]# vi spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://spark1:9000/spark-logs
2. 修改spark-env.sh檔案,添加如下配置
[root@spark1 conf]# vi spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop10:9000/spark-log"
3. 啟動對應的服務
[root@spark1 spark]# sbin/start-history-server.sh
[root@spark1 spark]# jps
9645 HistoryServer # 對應啟動的行程名稱
4. 查看歷史服務
http://spark1:18080
5. Spark On Yarn模式
yarn這個資源調度器不但可以為hadoop的mapreduce申請資源,同時也可以為spark申請資源,運行spark作業
standalone資源調度器只能運行spark作業
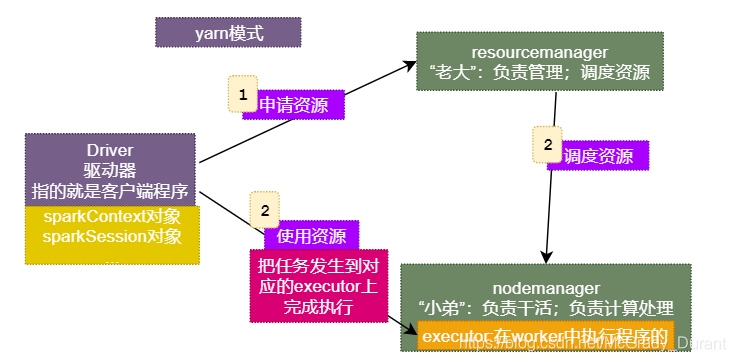
準備作業:正常安裝JDK、Hadoop(啟動hdfs和yarn)
1. 修改yarn-site.xml檔案
<!--是否啟動一個執行緒檢查每個任務正使用的物理記憶體量,如果任務超出分配值,則直接將其殺掉,默認是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否啟動一個執行緒檢查每個任務正使用的虛擬記憶體量,如果任務超出分配值,則直接將其殺掉,默認是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2. 修改spark-env.sh,添加如下配置:
注意和standalone的區別,不需要在配置SPARK_MASTER_HOST和SPARK_MASTER_PORT
SPARK_HISTORY_OPTS可以繼續使用
[root@spark1 conf]# vi spark-env.sh
#不需要在配置SPARK_MASTER_HOST和SPARK_MASTER_PORT 因為不需要啟動master行程
#因為spark的作業要交給hadoop中的yarn資源度器
YARN_CONF_DIR=/opt/installs/hadoop2.9.2/etc/hadoop
啟動yarn
3. 執行一個程式
#方式1
[root@spark1 spark]# bin/spark-shell --master yarn
scala> sc.textFile("hdfs://spark1:9000/a.txt")
.flatMap(_.split(" "))
.map((_,1))
.groupBy(_._1)
.map(t=>(t._1,t._2.size))
res0: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[6] at map at <console>:25
scala> res0.collect
res1: Array[(String, Int)] = Array((hello,4), (world,2))
#方式2
[root@spark1 spark]# bin/spark-submit --master yarn --class com.baizhi.test1.SparkWordCount /opt/spark-day1-1.0-SNAPSHOT.jar
jar包對應的程式中設定master為yarn new SparkConf().setMaster("yarn").setAppName("wc")
注意:在執行任務前先啟動hdfs和yarn
三、開發部署第一個Spark程式

1. 創建一個maven專案,并且匯入相關依賴
<!-- spark依賴-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<!-- maven專案對scala編譯打包 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
2. 撰寫Spark Driver代碼
package com.baizhi.test1
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
//1.創建SparkContext
val sparkConf: SparkConf =
new SparkConf().setMaster("spark://spark1:7077").setAppName("wc")
val sc = new SparkContext(sparkConf)
//2.讀取檔案內容,執行SparkRDD任務
sc.textFile("hdfs://spark1:9000/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(t => (t._1, t._2.size))
.saveAsTextFile("hdfs://spark1:9000/results")
//3.關閉SparkContext
sc.stop()
}
}
4. 執行mvn pacake指令打包程式
5. 將打包的程式上傳到遠程集群執行以下腳本
[root@spark1 spark]# bin/spark-submit --master spark://spark1:7077 --class com.baizhi.test1.SparkWordCount /opt/spark-day1-1.0-SNAPSHOT.jar
spark-submit方式適用于生產環境,當然spark也支持本地測驗,無需構建spark環境即可測驗spark代碼
四、本地模式
本地Spark程式除錯需要使用local提交模式,即將本機當做運行環境,Master和Worker都為本機,
創建SparkConf的時候設定額外屬性,表明本地執行:
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
local: 只啟動一個executor
local[k] : 啟動k個executor
local[*] : 啟動跟cpu數目相同的executor
代碼如下(示例):
package com.baizhi.test1
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
//1.創建SparkContext
val sparkConf: SparkConf =
new SparkConf().setMaster("local[*]").setAppName("wc")
val sc = new SparkContext(sparkConf)
//2.讀取檔案內容,執行SparkRDD任務
sc.textFile("file:///f:/datas/a.txt")
.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.map(t => (t._1, t._2.size))
.saveAsTextFile("file:///f:/datas/results")
//3.關閉SparkContext
sc.stop()
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292659.html
標籤:其他