最近有小伙伴面試,對資料結構和演算法比較頭疼,我整理了一波資料,幫助大家快速掌握資料結構和演算法的面試,感覺有用的小伙伴,點贊支持哦!
不叨叨,直接上干貨,
目錄
Q1:資料結構和演算法的知識點整理:
Q2:鏈表,佇列和堆疊的區別
Q3: 簡述快速排序程序
Q4:快速排序演算法的原理
Q5:簡述各類演算法時間復雜度、空間復雜度、穩定性對比
Q6:什么是 AVL 樹?
Q7:什么是紅?樹?
Q8:AVL 樹和紅?樹的區別?
Q9:B 樹和B+ 樹的區別?
Q10:排序有哪些分類?
Q11:直接插?排序的原理?
Q12:希爾排序的原理?
Q13:直接選擇排序的原理?
Q14:堆排序的原理?
Q15:冒泡排序的原理?
Q16:快速排序的原理?
Q17:回圈和遞回,你說下有什么不同的點?
Q18:排序演算法怎么選擇?
Q1:資料結構和演算法的知識點整理:
資料結構和演算法的需要掌握的知識點,我的好朋友啟艦整理的:

Q2:鏈表,佇列和堆疊的區別
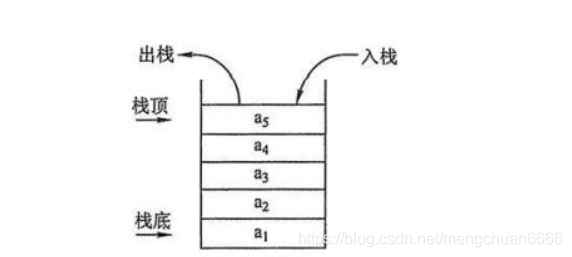
鏈表是一種物理存盤單元上非連續的一種資料結構,看名字我們就知道他是一種鏈式的結構,就像一群人手牽著手一樣,鏈表有單向的,雙向的,還有環形的,
佇列是一種特殊的線性表,他的特殊性在于我們只能操作他頭部和尾部的元素,中間的元素我們操作不了,我們只能在他的頭部進行洗掉,尾部進行添加,就像大家排隊到銀行取錢一樣,先來的肯定要排到前面,后來的只能排在隊尾,所有元素都要遵守這個操作,沒有VIP會員,所以走后門插隊的現象是不可能存在的,他是一種先進先出的資料結構,我們來看一下佇列的資料結構是什么樣的,
堆疊也是一種特殊的線性表,他只能對堆疊頂進行添加和洗掉元素,堆疊有入堆疊和出堆疊兩種操作,他就好像我們把書一本本的摞起來,最先放的書肯定是摞在下邊,最后放的書肯定是摞在了最上面,摞的時候不允許從中間放進去,拿書的時候也是先從最上面開始拿,不允許從下邊或中間抽出來,
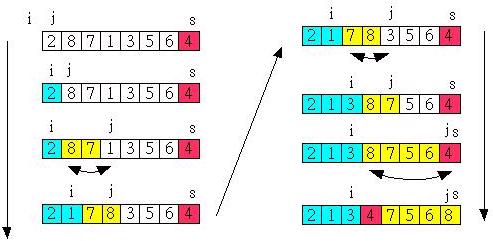
Q3: 簡述快速排序程序
1)選擇一個基準元素,通常選擇第一個元素或者最后一個元素,
2)通過一趟排序將待排序的記錄分割成獨立的兩部分,其中一部分記錄的元素值均比基準元素值小,另一部分記錄的元素值比基準值大,
3)此時基準元素在其排好序后的正確位置
4)然后分別對這兩部分記錄用同樣的方法繼續進行排序,直到整個序列有序,
Q4:快速排序演算法的原理
是對冒泡排序的?種改進,不穩定,平均/最好時間復雜度 O(nlogn),元素基本有序時最壞時間復雜度O(n2),空間復雜度 O(logn),
?先選擇?個基準元素,通過?趟排序將要排序的資料分割成獨?的兩部分,?部分全部?于等于基準 元素,?部分全部?于等于基準元素,再按此?法遞回對這兩部分資料進?快速排序,
快速排序的?次劃分從兩頭交替搜索,直到 low 和 high 指標重合,?趟時間復雜度 O(n),整個演算法的時間復雜度與劃分趟數有關,
最好情況是每次劃分選擇的中間數恰好將當前序列等分,經過 log(n) 趟劃分便可得到?度為 1 的?表, 這樣時間復雜度 O(nlogn),
最壞情況是每次所選中間數是當前序列中的最?或最?元素,這使每次劃分所得?表其中?個為空表 , 這樣?度為 n 的資料表需要 n 趟劃分,整個排序時間復雜度 O(n2),
Q5:簡述各類演算法時間復雜度、空間復雜度、穩定性對比
| 排序演算法 | 平均時間復雜度 | 最壞時間復雜度 | 空間復雜度 | 是否穩定 |
| 冒泡排序 | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 是 |
| 選擇排序 | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 不是 |
| 直接插入排序 | O(n2)O(n2) | O(n2)O(n2) | O(1)O(1) | 是 |
| 歸并排序 | O(nlogn)O(nlogn) | O(nlogn)O(nlogn) | O(n)O(n) | 是 |
| 快速排序 | O(nlogn)O(nlogn) | O(n2)O(n2) | O(logn)O(logn) | 不是 |
| 堆排序 | O(nlogn)O(nlogn) | O(nlogn)O(nlogn) | O(1)O(1) | 不是 |
| 希爾排序 | O(nlogn)O(nlogn) | O(ns)O(ns) | O(1)O(1) | 不是 |
| 計數排序 | O(n+k)O(n+k) | O(n+k)O(n+k) | O(n+k)O(n+k) | 是 |
| 基數排序 | O(N?M)O(N?M) | O(N?M)O(N?M) | O(M)O(M) | 是 |
Q6:什么是 AVL 樹?
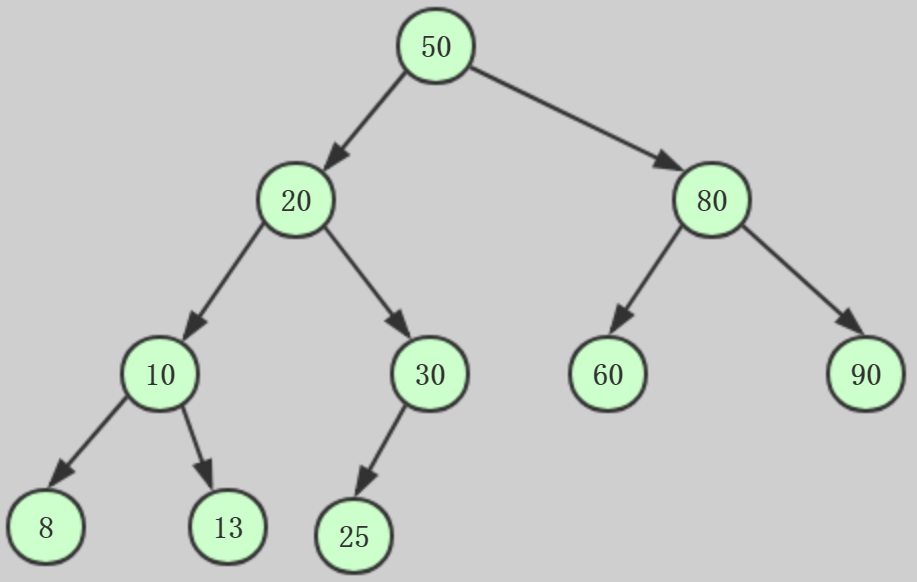
AVL 樹 是平衡?叉查找樹,增加和洗掉節點后通過樹形旋轉重新達到平衡,右旋是以某個節點為中?, 將它沉?當前右?節點的位置,?讓當前的左?節點作為新樹的根節點,也稱為順時針旋轉,同理左旋 是以某個節點為中?,將它沉?當前左?節點的位置,?讓當前的右?節點作為新樹的根節點,也稱為 逆時針旋轉,
Q7:什么是紅?樹?
紅?樹 是 1972 年發明的,稱為對稱?叉 B 樹,1978 年正式命名紅?樹,主要特征是在每個節點上增加?個屬性表示節點顏?,可以紅?或??,
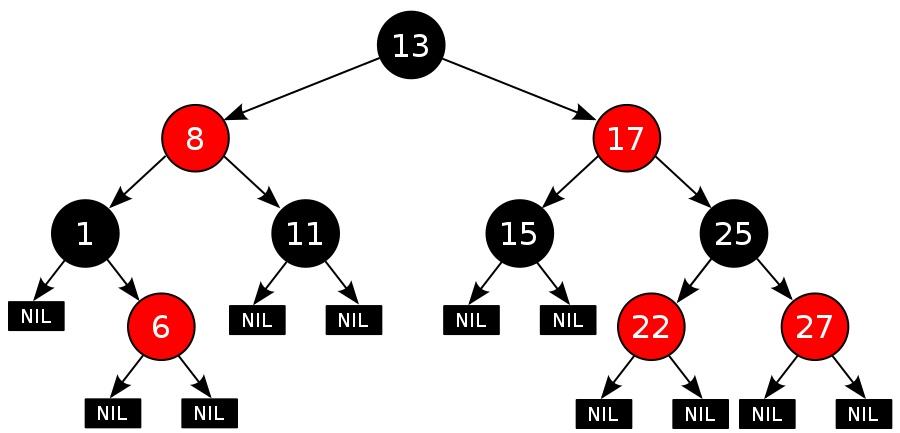
紅?樹和 AVL 樹 類似,都是在進?插?和洗掉時通過旋轉保持?身平衡,從?獲得較?的查找性能,與 AVL 樹 相?,紅?樹不追求所有遞回?樹的?度差不超過 1,保證從根節點到葉尾的最?路徑不超過最短路徑的 2 倍,所以最差時間復雜度是 O(logn),
紅?樹通過重新著?和左右旋轉,更加?效地完成了插?和洗掉之后的?平衡調整,紅?樹在本質上還是?叉查找樹,它額外引?了 5 個約束條件: ① 節點只能是紅?或??, ② 根節點必須是??, ③ 所有 NIL 節點都是??的, ④ ?條路徑上不能出現相鄰的兩個紅?節點, ⑤ 在任何遞回?樹中,根節點到葉?節點的所有路徑上包含相同數?的??節點,
這五個約束條件保證了紅?樹的新增、洗掉、查找的最壞時間復雜度均為 O(logn),如果?個樹的左?節點或右?節點不存在,則均認定為??,紅?樹的任何旋轉在 3 次之內均可完成,
Q8:AVL 樹和紅?樹的區別?
紅?樹的平衡性不如 AVL 樹,它維持的只是?種?致的平衡,不嚴格保證左右?樹的?度差不超過 1,這導致節點數相同的情況下,紅?樹的?度可能更?,也就是說平均查找次數會?于相同情況的 AVL 樹,
在插?時,紅?樹和 AVL 樹都能在?多兩次旋轉內恢復平衡,在洗掉時由于紅?樹只追求?致平衡,因此紅?樹?多三次旋轉可以恢復平衡,? AVL 樹最多需要 O(logn) 次,AVL 樹在插?和洗掉時,將向上回溯確定是否需要旋轉,這個回溯的時間成本最差為 O(logn),?紅?樹每次向上回溯的步?為 2,回溯成本低,因此?對頻繁地插?與洗掉紅?樹更加合適,
Q9:B 樹和B+ 樹的區別?
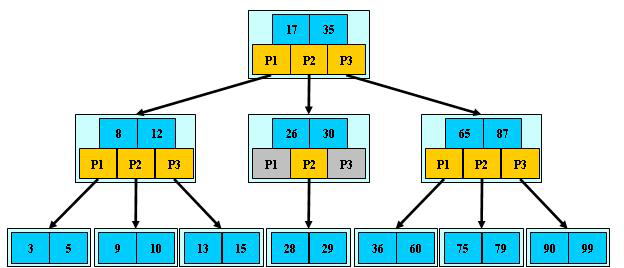
B 樹中每個節點同時存盤 key 和 data,? B+ 樹中只有葉?節點才存盤 data,?葉?節點只存盤 key,InnoDB 對 B+ 樹進?了優化,在每個葉?節點上增加了?個指向相鄰葉?節點的鏈表指標,形成了帶有順序指標的 B+ 樹,提?區間訪問的性能,
B+ 樹的優點在于: ① 由于 B+ 樹在?葉?節點上不含資料資訊,因此在記憶體?中能夠存放更多的key,資料存放得更加緊密,具有更好的空間利?率,訪問葉?節點上關聯的資料也具有更好的快取命 中率, ② B+樹的葉?結點都是相連的,因此對整棵樹的遍歷只需要?次線性遍歷葉?節點即可,? B 樹則需要進?每?層的遞回遍歷,相鄰的元素可能在記憶體中不相鄰,所以快取命中性沒有 B+樹好,但是 B 樹也有優點,由于每個節點都包含 key 和 value,因此經常訪問的元素可能離根節點更近,訪問也更迅速,
Q10:排序有哪些分類?
排序可以分為內部排序和外部排序,在記憶體中進?的稱為內部排序,當資料量很?時?法全部拷?到記憶體需要使?外存,稱為外部排序,
內部排序包括?較排序和??較排序,?較排序包括插?/選擇/交換/歸并排序,??較排序包括計數/ 基數/桶排序,
插?排序包括直接插?/希爾排序,選擇排序包括直接選擇/堆排序,交換排序包括冒泡/快速排序,
Q11:直接插?排序的原理?
穩定,平均/最差時間復雜度 O(n2),元素基本有序時最好時間復雜度 O(n),空間復雜度 O(1),
每?趟將?個待排序記錄按其關鍵字的??插?到已排好序的?組記錄的適當位置上,直到所有待排序 記錄全部插?為?,
直接插?沒有利?到要插?的序列已有序的特點,插?第 i 個元素時可以通過?分查找找到插?位置insertIndex,再把 i~insertIndex 之間的所有元素后移?位,把第 i 個元素放在插?位置上,
Q12:希爾排序的原理?
?稱縮?增量排序,是對直接插?排序的改進,不穩定,平均時間復雜度 O(n^1.3^),最差時間復雜度O(n2),最好時間復雜度 O(n),空間復雜度 O(1),
把記錄按下標的?定增量分組,對每組進?直接插?排序,每次排序后減?增量,當增量減? 1 時排序完畢,
Q13:直接選擇排序的原理?
不穩定,時間復雜度 O(n2),空間復雜度 O(1),
每次在未排序序列中找到最?元素,和未排序序列的第?個元素交換位置,再在剩余未排序序列中重復 該操作直到所有元素排序完畢,
Q14:堆排序的原理?
是對直接選擇排序的改進,不穩定,時間復雜度 O(nlogn),空間復雜度 O(1),
將待排序記錄看作完全?叉樹,可以建??根堆或?根堆,?根堆中每個節點的值都不?于它的?節點 值,?根堆中每個節點的值都不?于它的?節點值,
以?根堆為例,在建堆時?先將最后?個節點作為當前節點,如果當前節點存在?節點且值?于?節點,就將當前節點和?節點交換,在移除時?先暫存根節點的值,然后?最后?個節點代替根節點并作 為當前節點,如果當前節點存在?節點且值?于?節點,就將其與值較?的?節點進?交換,調整完堆 后回傳暫存的值,
Q15:冒泡排序的原理?
穩定,平均/最壞時間復雜度 O(n2),元素基本有序時最好時間復雜度 O(n),空間復雜度 O(1),
?較相鄰的元素,如果第?個?第?個?就進?交換,對每?對相鄰元素做同樣的?作,從開始第?對 到結尾的最后?對,每?輪排序后末尾元素都是有序的,針對 n 個元素重復以上步驟 n -1 次排序完畢,
當序列已經有序時仍會進?不必要的?較,可以設定?個標志記錄是否有元素交換,如果沒有直接結束?較,
Q16:快速排序的原理?
是對冒泡排序的?種改進,不穩定,平均/最好時間復雜度 O(nlogn),元素基本有序時最壞時間復雜度O(n2),空間復雜度 O(logn),
?先選擇?個基準元素,通過?趟排序將要排序的資料分割成獨?的兩部分,?部分全部?于等于基準 元素,?部分全部?于等于基準元素,再按此?法遞回對這兩部分資料進?快速排序,
快速排序的?次劃分從兩頭交替搜索,直到 low 和 high 指標重合,?趟時間復雜度 O(n),整個演算法的時間復雜度與劃分趟數有關,
最好情況是每次劃分選擇的中間數恰好將當前序列等分,經過 log(n) 趟劃分便可得到?度為 1 的?表, 這樣時間復雜度 O(nlogn),
最壞情況是每次所選中間數是當前序列中的最?或最?元素,這使每次劃分所得?表其中?個為空表 , 這樣?度為 n 的資料表需要 n 趟劃分,整個排序時間復雜度 O(n2),
Q17:回圈和遞回,你說下有什么不同的點?
遞回演算法:
優點:代碼少、簡介,
缺點:它的運行需要較多次數的函式呼叫,如果呼叫層數比較深,需要增加額外的堆疊處理,比如引數傳遞需要壓堆疊等操作,會對執行效率有一定影響,但是,對于某些問題,如果不使用遞回,那將是極端難看的代碼,
回圈演算法:
優點:速度快,結構簡單,
缺點:并不能解決所有的問題,有的問題適合使用遞回而不是回圈,如果使用回圈并不困難的話,最好使用回圈,
Q18:排序演算法怎么選擇?
資料量規模較?,考慮直接插?或直接選擇,當元素分布有序時直接插?將??減少?較和移動記錄的次數,如果不要求穩定性,可以使?直接選擇,效率略?于直接插?,
資料量規模中等,選擇希爾排序,
資料量規模較?,考慮堆排序(元素分布接近正序或逆序)、快速排序(元素分布隨機)和歸并排序穩定性),?般不使?冒泡,
好了,整理結束,小伙伴們點贊、收藏、評論,一鍵三連走起呀,下期見~~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292724.html
標籤:其他
上一篇:2021年8月前端面試題最新出爐(二)—HTTP協議
下一篇:用手機如何查看當地的2g信號強度