機器學習面試題
- 1.機器學習專案流程詳細
- 1.1定位數學問題
- 1.2獲取資料
- 1.3特征預處理與特征選擇
- 1.4訓練模型與調優
- 1.5模型判定
- 1.6模型集成
- 1.7上線測驗
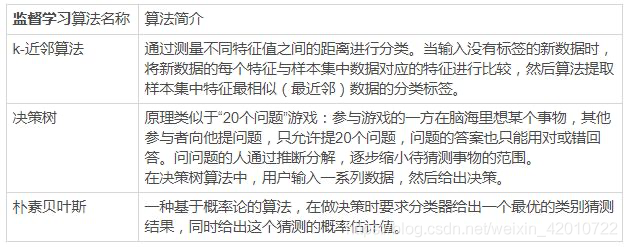
- 2.有監督學習和無監督學習的區別
- 2.1監督學習
- 2.2無監督學習
- 2.3常用演算法
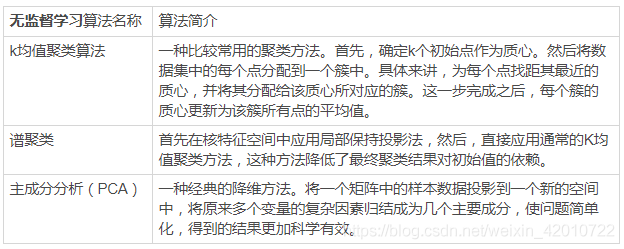
- 3.資料歸一化處理的作用
- 4.不需要做歸一化處理的演算法有哪些
- 5.資料預處理
- 6.類別型特征如何資料處理
- 6.1序號編碼
- 6.2獨熱編碼
- 6.3二進制編碼
- 7.介紹一下邏輯回歸LR
- 8.邏輯回歸與線性回歸的區別與聯系
- 9.SVM原理
- 10.LR與SVM的相同點與不同點
- 10.1相同點
- 10.2不同點
- 11.欠擬合和過擬合如何解決
- 11.1欠擬合解決方法
- 11.2過擬合解決方法
- 12.正則化的含義
- 12.1線性回歸擬合問題
- 12.2邏輯回歸擬合問題
- 13.L1和L2的區別
1.機器學習專案流程詳細
1.1定位數學問題
首先進行機器學習專案時,需要對自己的訓練目標進行明確定位,明確可以獲取怎么樣的資料(離散、連續),目標是一個分類還是回歸或者聚類,明確自己可以獲得的資料量,選擇合適的演算法
1.2獲取資料
資料決定了機器學習的結果上限,對于資料的選取,對于分類問題的,資料不能偏斜太過嚴重,
了解資料的量級,比如說有多少樣本,多少個特征,可以估算出其對記憶體的消耗程度,判斷訓練程序中記憶體是否能夠放得下,如果放不下就得考慮改進演算法或者使用一些降維的技巧了,
1.3特征預處理與特征選擇
對于模型來說,良好的資料能夠提取出很好的特征,使得模型發揮出很好的效果,
特征預處理、資料清洗就是對于模型來說很關鍵的一步,在模型訓練優化中,往往使演算法效果和性能到達顯著提高點效果,都是特征預處理與特征選擇中做出調整,
具體步驟包含:歸一化、離散化、因子化、缺失值處理、去除共線性等,
1.4訓練模型與調優
對于基于python實作演算法訓練,現在大部分演算法都已經實作python庫封裝了,直接呼叫即可,真正考驗水平的是調整這些演算法的引數,使得演算法更加優良,
1.5模型判定
模型判定就是告訴模型調優的具體調整方向和思路的,
過擬合、欠擬合是判斷模型好不好的重要一步,常見的方法有交叉驗繪制學習曲線等,
過擬合的基本思路是增加資料降低模型復雜度,欠擬合的基本思路是提高特征數量和質量,增加模型復雜度,
1.6模型集成
對于一些單個模型無論怎樣調優模型效果都不是很好的,這時候需要對模型進行集成融合,常見的模型集成如基于決策樹的隨機森林,類似的還有Bagging、Boosting等,
1.7上線測驗
對于開發模型,模型的成與敗取決于在線上真實運行下,觀察運行的效果,這里不單需要評估模型的準確誤差等情況,還包括模型運行的時間復雜度,空間復雜度、穩定性等,
2.有監督學習和無監督學習的區別
2.1監督學習
監督學習是指學生從老師那里獲取知識、資訊,老師提供對錯指示、告知最終答案,學生在學習程序中借助老師的提示獲得經驗、技能,最后對沒有學習過的問題也可以做出正確解答,
在監督學習中,我們只需要給定輸入樣本集,機器就可以從中推演出指定目標變數的可能結果,機器只需從輸入資料中預測合適的模型,并從中計算出目標變數的結果,要實作的目標是“對于輸入資料X能預測變數Y”
2.2無監督學習
無監督學習是指在沒有老師的情況下,學生自學的程序,學生在學習的程序中,自己對知識進行歸納、總結,無監督學習中,類似分類和回歸中的目標變數事先并不存在,要回答的問題是“從資料X中能發現什么”,
2.3常用演算法
在深度學習應用中實作的機器學習的技術,也包含監督學習與無監督學習,常見的卷積神經網路就是一種監督學習方法,比如說影像分類(人臉識別,貓狗識別、行為識別等),對于無監督學習方法中,有生成對抗網路(GAN),GAN經常被用來做影像生成,
3.資料歸一化處理的作用
注意:對于需要做歸一化的資料,是因為資料各維度之間量綱不同(資料的單位屬性不同,如體重與身高,當然這里需要對選取的演算法來判斷),對于沒有量綱問題的,最好不要做歸一化處理,
做資料歸一化處理是需要結合選取的演算法綜合考慮的,比如:
- SVM:資料在各維度進行不均勻的伸縮后,最優解于原來不等價需要歸一化,
- LR:資料在各維度不均勻伸縮與原來等價的,不需要做歸一化,但在模型進行跌代演算法的時候,如果看下隨著迭代次數,損失值不收斂的話,就需要對資料進行歸一化,
4.不需要做歸一化處理的演算法有哪些
需要做歸一化的模型
- 基于距離計算的模型:KNN
- 通過梯度下降法求解的模型:線性回歸、邏輯回歸、支持向量機、神經網路
不需要做歸一化的模型
樹形模型不需要做歸一化,原因是它只關注輸入變數的分布和變數之間的條件概率(熵),如決策樹、隨機森林,
5.資料預處理
- 1.缺失值:填充缺失值fillna:
- i. 離散:None,
- ii. 連續:均值,
- iii. 缺失值太多,則直接去除該列
- 2.連續值:離散化,有的模型(如決策樹)需要離散值
- 3.對定量特征二值化:核心在于設定一個閾值,大于閾值的賦值為1,小于等于閾值的賦值為0,如影像操作
- 4.皮爾遜相關系數:去除高度相關的列
6.類別型特征如何資料處理
類別型特征主要是指像性別(男、女)、血型(A、B、AB、O)這樣有限選項的取值特征,
對于這類的資料,除了使用決策樹這樣的樹形模型可以直接處理以外,對于邏輯回歸、支持向量機等模型,都需要對資料進行處理
具體處理方法有序號編碼、獨熱編碼、二進制編碼,
6.1序號編碼
使用相應的數字,根據數字大小對應到相應的類別中,比如說成績的不及格、良好、優秀,可以用1、2、3數字來相應表示,
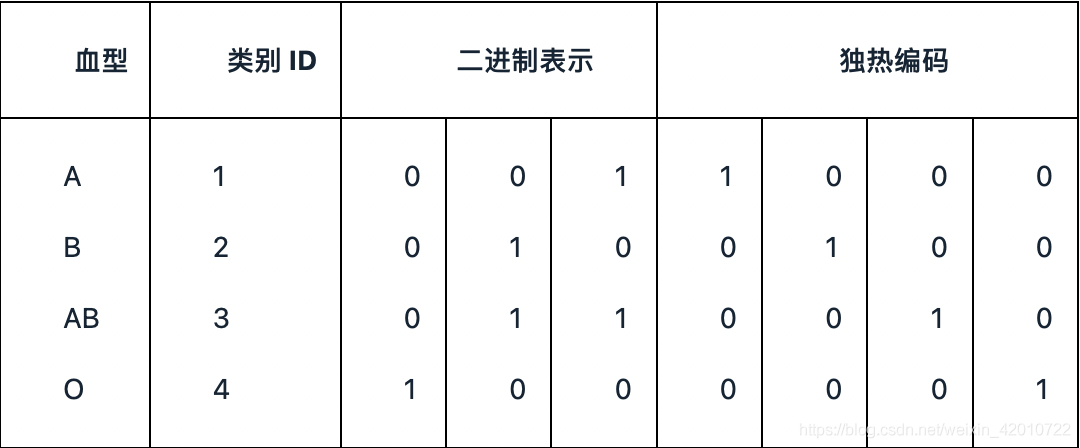
6.2獨熱編碼
獨熱編碼通常是類別轉換成對應稀疏向量,比如血型(A、B、AB、O)
A向量為:(1,0,0,0)
B向量為:(0,1,0,0)
AB向量為:(0,0,1,0)
O向量為:(0,0,0,1)
6.3二進制編碼
二進制編碼分二步,第一步先用序號編碼給每個類別賦予一個類別,然后將類別ID對應的二進制編碼作為結果,
7.介紹一下邏輯回歸LR
對于邏輯回歸模型它其實就是一個真實的二分類器模型,線性分類器,
給定一些資料點,它們分別屬于兩個不同的類,現在要找到一個線性分類器把這些資料分成兩類,
如果用
x
x
x表示資料點,用
y
y
y表示類別(y可以取1或者-1,分別代表兩個不同的類),一個線性分類器的學習目標便是要在n維的資料空間中找到一個超平面(hyper plane),這個超平面的方程可以表示為(
w
T
w^T
wT中的
T
T
T代表轉置)
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0
這里的
y
y
y取1或-1分類標注是源于logistic回歸,
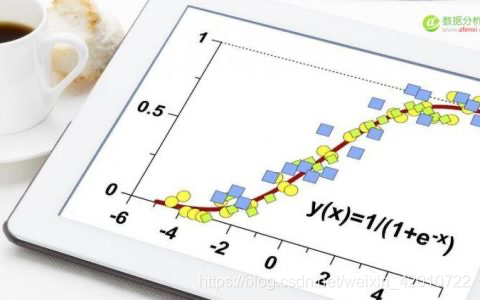
Logistic回歸目的是從特征學習出一個0/1分類模型,而這個模型是將特性的線性組合作為自變數,由于自變數的取值范圍是負無窮到正無窮,因此,使用logistic函式(或稱作sigmoid函式)將自變數映射到(0,1)上,映射后的值被認為是屬于y=1的概率,
h ( x ) = g ( w T x ) = 1 1 + e ? w T x h(x)=g(w^Tx)=\frac{1}{1+e^{-w^Tx}} h(x)=g(wTx)=1+e?wTx1?
其中命
z
=
w
T
x
z=w^Tx
z=wTx,函式影像如下圖所示,
8.邏輯回歸與線性回歸的區別與聯系
第一邏輯回歸和線性回歸都是廣義的線性回歸,
其次經典線性模型的優化目標函式是最小二乘,而邏輯回歸則是似然函式,
另外線性回歸在整個實數域范圍內進行預測,敏感度一致,而分類范圍,需要在[0,1],邏輯回歸就是一種減小預測范圍,將預測值限定為[0,1]間的一種回歸模型,因而對于這類問題來說,邏輯回歸的魯棒性比線性回歸的要好
9.SVM原理
對于線性可分的兩類點(或多類點),通過一個超平面或多個(三維平面),實作這幾類點的完全分開,
其基本模型定義為特征空間上的間隔最大的線性分類器,其學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解,
以二分類模型為列,如果用
x
x
x表示資料點,用
y
y
y表示類別(1,-1分別代表兩種不同的類),將這樣的資料點放入到對應的空間中,對于SVM分類器學習目的就是在這樣一個空間中,找到一個超平面使這個超平面到二類資料點之間的距離最大,
這個超平面可以用分類函式
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0表示,當f(x) 等于0的時候,x便是位于超平面上的點,而f(x)大于0的點對應 y=1 的資料點,f(x)小于0的點對應y=-1的點,如下圖所示:
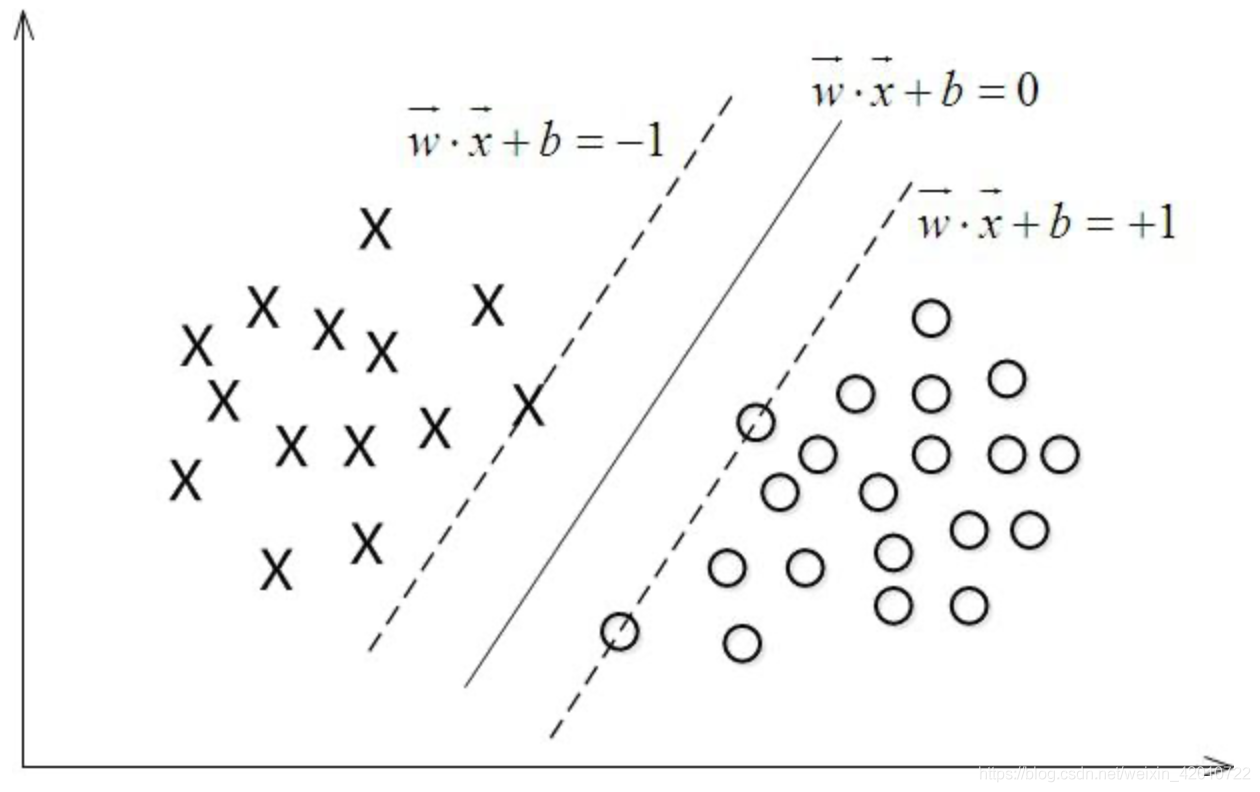
10.LR與SVM的相同點與不同點
10.1相同點
- 都是線性分類器,都是要求一個最佳的分類超平面
- 都是監督學習演算法
- 都是判別模型,判別模型,不關心資料是怎么生成的,它只關心資料之間的差別,然后用差別來簡單對資料進行分類,
10.2不同點
- 損失函式不同
LR的損失函式是交叉熵:
J ( θ ) = ? 1 m [ ∑ i = 1 m y i l o g h θ ( x i ) + ( 1 ? y i ) l o g ( 1 ? h θ ( x i ) ) ] J(\theta)=-\frac{1}{m}[\sum_{i=1}^m{y^{i}logh_{\theta}(x^i)+(1-y^i)log(1-h_{\theta}(x^i))}] J(θ)=?m1?[∑i=1m?yiloghθ?(xi)+(1?yi)log(1?hθ?(xi))]
SVM的損失函式是:
L ( w , b , a ) = 1 2 ∣ ∣ w ∣ ∣ 2 ? ∑ i = 1 n α i ( y i ( w T x i + b ) ? 1 ) L(w,b,a)=\frac{1}{2}||w||^2-\sum_{i=1}^n\alpha_{i}(y_{i}(w^Tx_{i}+b)-1) L(w,b,a)=21?∣∣w∣∣2?∑i=1n?αi?(yi?(wTxi?+b)?1) - 兩種模型對資料和引數的敏感度程度不同,對于SVM模型,在分類邊界線附近的資料點對模型的影響更多,對于LR,受所有資料點的影響,模型的好壞依賴于資料分布
- SVM基于距離分類、LR基于概率分類
- SVM損失函式自帶正則化,而LR必須格外在損失函式之外添加
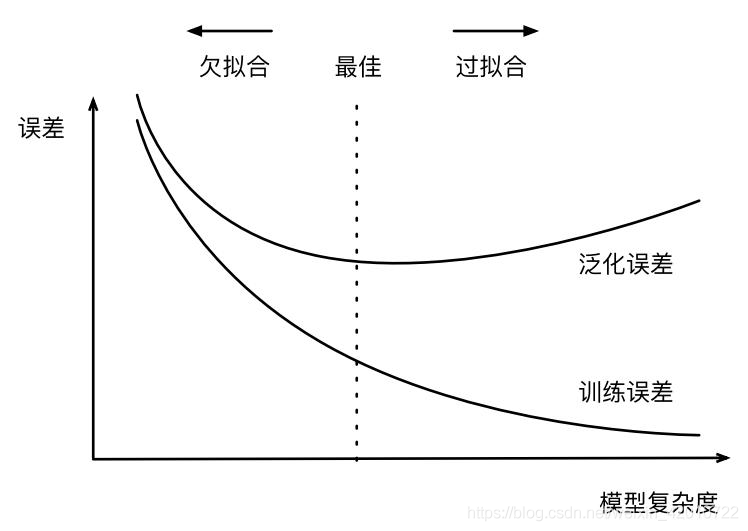
11.欠擬合和過擬合如何解決
欠擬合與過擬合從直觀上看如下圖所示,在機器學習專案中,我們不僅要降低訓練的誤差,同時我們的模型也要用到實際應用中,使實際的誤差(泛化誤差)較低,由下圖看出:
- 隨著模型的訓練程序進行,模型的復雜度越高,訓練誤差就低,但是模型在泛化誤差上很高(模型做的太專一了,對于其他的資料集它不能很好的適應),這就是過擬合
- 隨著模型訓練程序進行,模型的復雜度越低,訓練誤差就低,模型的泛化誤差自然就很高,
11.1欠擬合解決方法
- 減少正則化引數
- 嘗試使用更高級的模型(如使用SVM、神經網路等)
- 添加其他特征項、添加多項式特征
11.2過擬合解決方法
- 正則化(L1和L2)
- 隨機失活(dropout):這個方法主要使用在神經網路中,具體方法讓神經網路中部分神經元沒有被激活(也就是不使用這部分神經元),
- 逐層歸一化:也主要使用在神經網路中,具體方法在神經元每一層輸出后,再進行一次歸一化,
12.正則化的含義
以線性回歸損失函式為列,加入正則化后函式如下:
L
o
s
s
=
1
N
∑
i
=
1
N
(
y
i
?
f
(
x
i
)
)
2
+
r
(
d
)
Loss=\frac{1}{N}\sum_{i=1}^N{(y_{i}-f(x_{i}))^2}+r(d)
Loss=N1?∑i=1N?(yi??f(xi?))2+r(d)
其中
1
N
∑
i
=
1
N
(
y
i
?
f
(
x
i
)
)
2
\frac{1}{N}\sum_{i=1}^N{(y_{i}-f(x_{i}))^2}
N1?∑i=1N?(yi??f(xi?))2表示全模型的損失函式,
r
(
d
)
r(d)
r(d)表示正則項懲罰復雜模型,
其中,損失函式鼓勵我們的模型盡量去擬合訓練資料,使得最后的模型會有比較少的 bias,而正則化項則鼓勵更加簡單的模型,因為當模型簡單之后,有限資料擬合出來結果的隨機性比較小,不容易過擬合,使得最后模型的預測更加穩定
對損失函式加入正則化的目的是為了防止過擬合,這里就針對不同情況的過擬合問題進行分析,
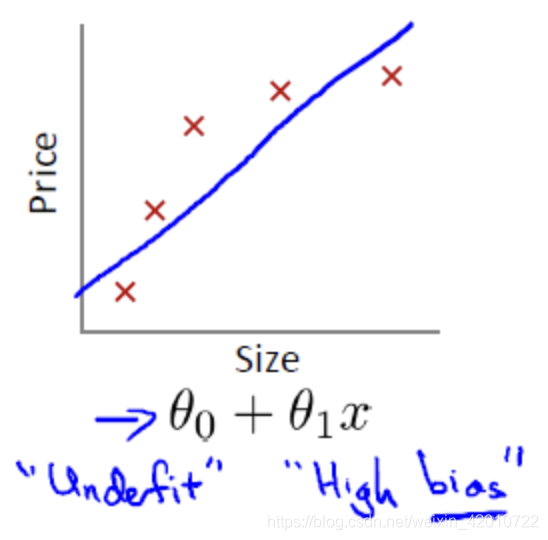
設定size為模型引數個數,price為模型損失值大小
12.1線性回歸擬合問題
欠擬合(underifit,也稱高偏差high bias)
合適的擬合
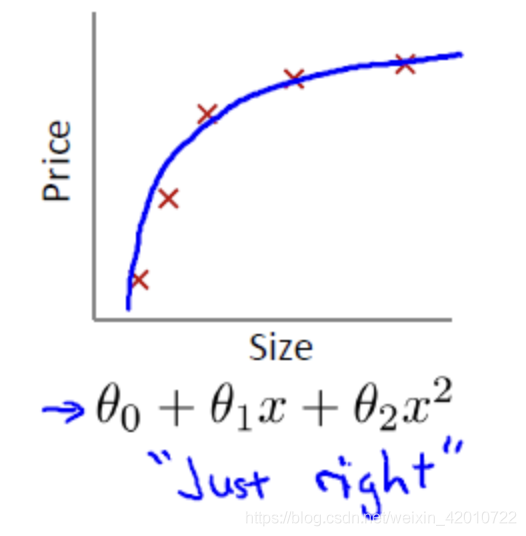
過擬合(overfit,也稱高方差high variance)
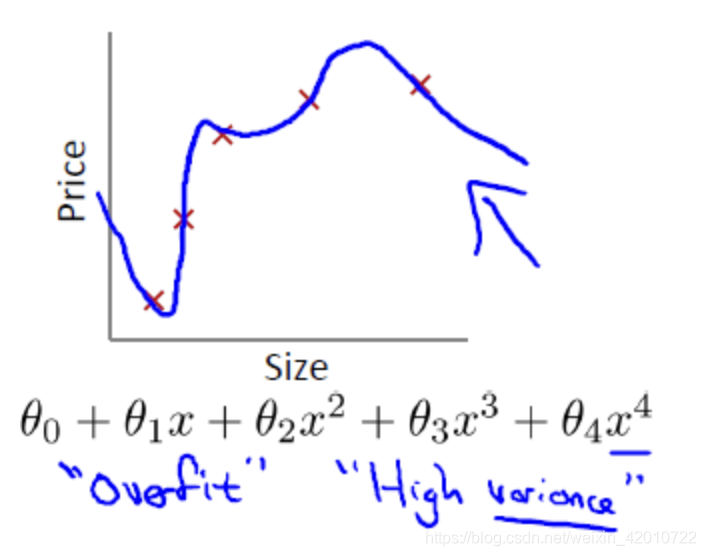
12.2邏輯回歸擬合問題
欠擬合
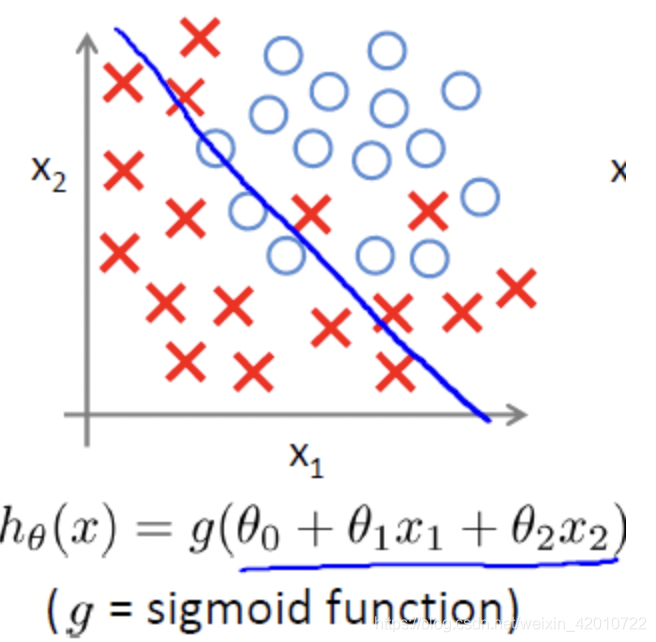
合適的擬合
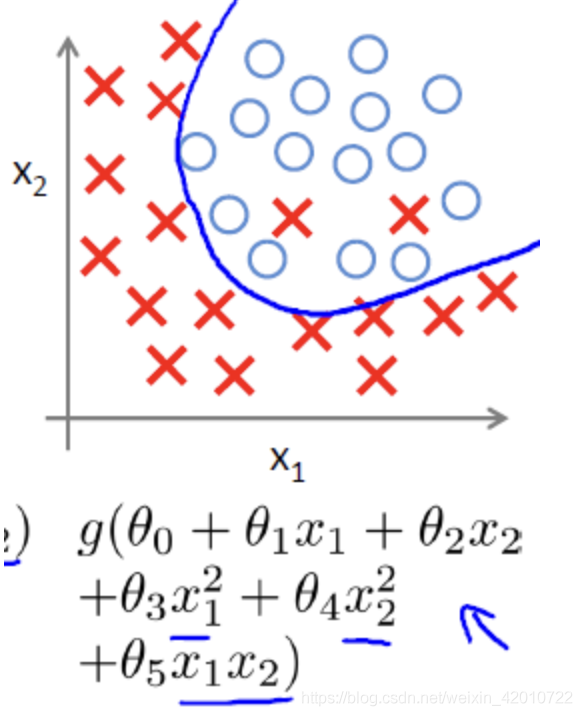
過擬合
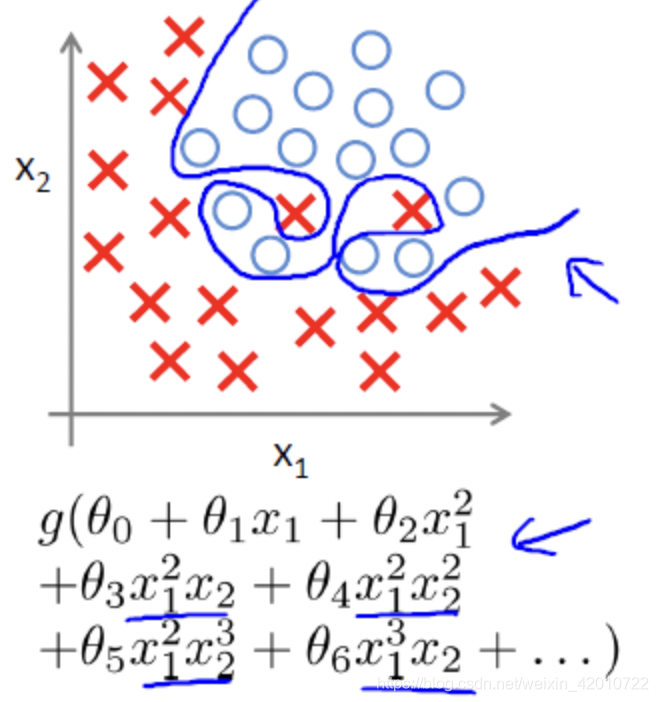
對于解決過擬合問題,通常考慮兩種途徑來解決:
a) 減少特征的數量:
-人工的選擇保留哪些特征;
-模型選擇演算法
b) 正則化
-保留所有的特征,但是降低引數的量/值;
-正則化的好處是當特征很多時,每一個特征都會對預測y貢獻一份合適的力量
13.L1和L2的區別
L1范數(L1 norm)是指向量中各個元素絕對值之和,L2范數(L2 norm)是指向量各個元素平方和的1/2次平方,
比如 向量A=[1,-1,3], 那么A的L1范數為
∣
1
∣
+
∣
?
1
∣
+
∣
3
∣
|1|+|-1|+|3|
∣1∣+∣?1∣+∣3∣,那么A的L2范數為
1
2
(
∣
1
∣
2
+
∣
?
1
∣
2
+
∣
3
∣
2
)
\frac{1}{2}(|1|^2+|-1|^2+|3|^2)
21?(∣1∣2+∣?1∣2+∣3∣2)
L1范數:
m
i
n
1
2
n
s
a
m
p
l
e
s
∣
∣
x
w
?
y
∣
∣
2
2
+
α
∣
∣
w
∣
∣
1
min\frac{1}{2n_{samples}}||xw-y||_{2}^2+\alpha||w||_{1}
min2nsamples?1?∣∣xw?y∣∣22?+α∣∣w∣∣1?
L2范數:
m
i
n
1
2
n
s
a
m
p
l
e
s
∣
∣
x
w
?
y
∣
∣
2
2
+
α
∣
∣
w
∣
∣
2
2
min\frac{1}{2n_{samples}}||xw-y||_{2}^2+\alpha||w||_{2}^2
min2nsamples?1?∣∣xw?y∣∣22?+α∣∣w∣∣22?
L1和L2的差別,為什么一個讓絕對值最小,一個讓平方最小,會有那么大的差別呢?看導數一個是1一個是w便知, 在靠進零附近, L1以勻速下降到零, 而L2則完全停下來了. 這說明L1是將不重要的特征(或者說, 重要性不在一個數量級上)盡快剔除, L2則是把特征貢獻盡量壓縮最小但不至于為零
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292854.html
標籤:AI