前言
本文隸屬于專欄《1000個問題搞定大資料技術體系》,該專欄為筆者原創,參考請注明來源,不足和錯誤之處請在評論區幫忙指出,謝謝!
本專欄目錄結構和參考文獻請見1000個問題搞定大資料技術體系
正文
請結合我的這篇博客來理解本文:
一篇文章搞懂 HBase 的內部原理
讀操作
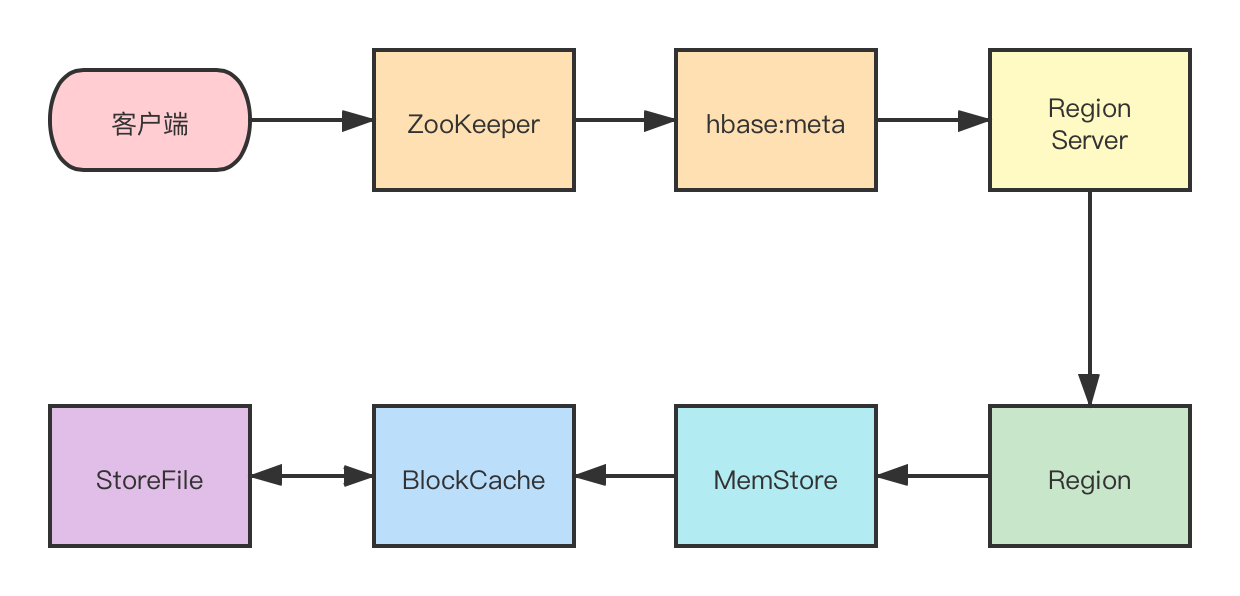
- 首先從 ZooKeeper 找到 meta 表的 region 位置,然后讀取 hbase:meta 表中的資料, hbase:meta 表中存盤了用戶表的 region 資訊
- 根據要查詢的 namespace 、表名和 rowkey 資訊,找到寫入資料對應的 Region 資訊
- 找到這個 Region 對應的 RegionServer ,然后發送請求
- 查找對應的 Region
- 先從 MemStore 查找資料,如果沒有,再從 BlockCache 上讀取
HBase 上 RegionServer 的記憶體分為兩個部分一部分作為 MemStore ,主要用來寫;,
另外一部分作為 BlockCache ,主要用于讀資料;
- 如果 BlockCache 中也沒有找到,再到 StoreFile(HFile) 上進行讀取
從 StoreFile 中讀取到資料之后,不是直接把結果資料回傳給客戶端,而是把資料先寫入到 BlockCache 中,目的是為了加快后續的查詢;然后在回傳結果給客戶端,
寫操作
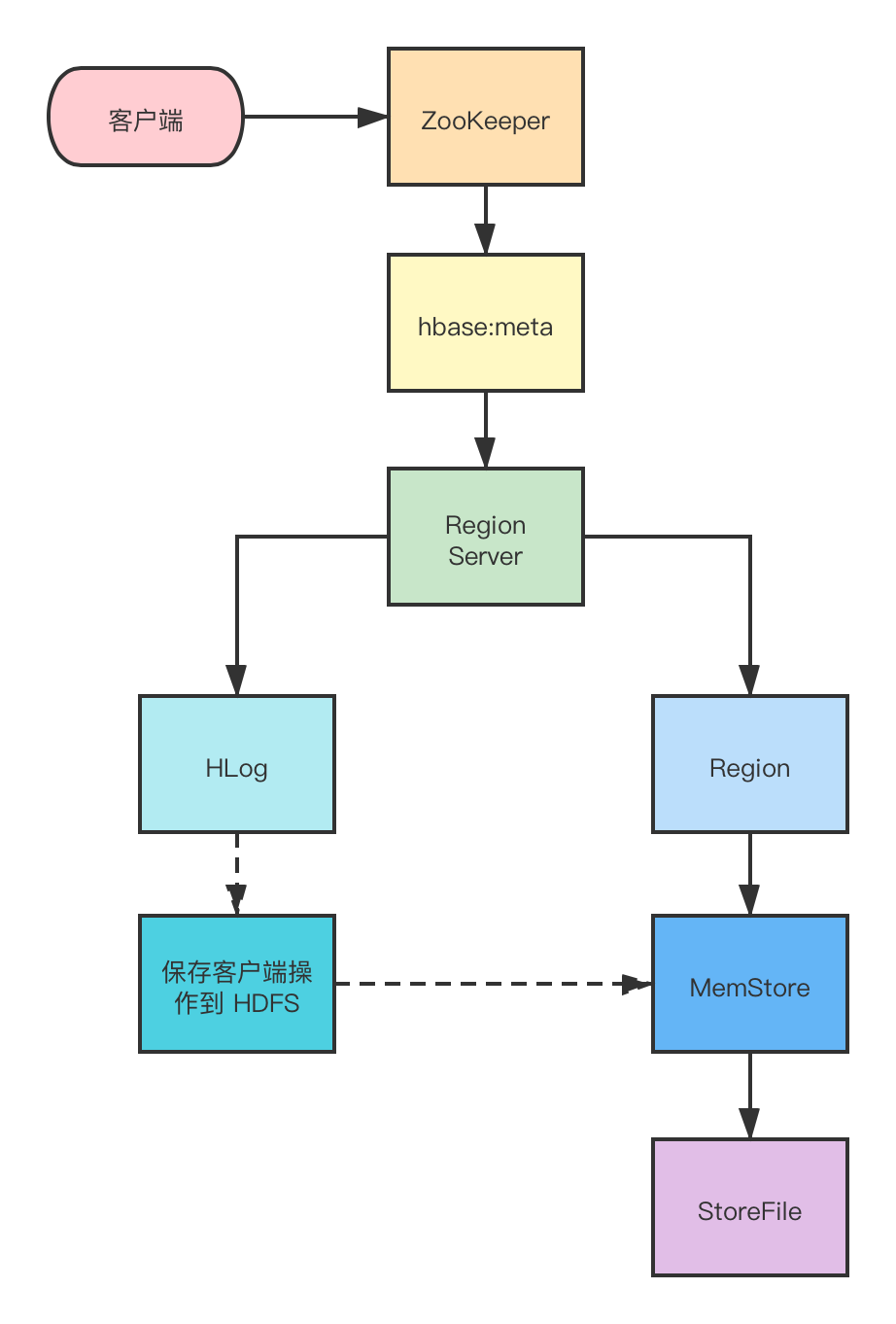
- 首先從 ZooKeeper 找到 hbase:meta 表的 Region 位置,然后讀取 hbase:meta 表中的資料, hbase:meta 表中存盤了用戶表的 Region 資訊
- 根據 namespace 、表名和 rowkey 資訊找到寫入資料對應的 Region 資訊
- 找到這個 Region 對應的 RegionServer ,然后發送請求
- 把資料分別寫到 HLog ( WriteAheadLog )和 MemStore 各一份
- MemStore 達到閾值后把資料刷到磁盤,生成 StoreFile 檔案
- 洗掉 HLog 中的歷史資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292898.html
標籤:其他
上一篇:Web前端開發應該具備哪些知識
下一篇:Zookeeper概念