目錄
大資料入門系列文章
一、概念
二、架構及組件概念
三、讀寫流程
四、大白話
五、其他
大資料入門系列文章
最近在收集整理大資料入門文章,各位盆友關注點贊不迷路,每天都要開心鴨!
大資料入門系列文章
1.大資料入門-大資料是什么
2.大資料入門-大資料技術概述(一)
3.大資料入門-大資料技術概述(二)
4.大資料入門-三分鐘讀懂Hadoop
一、概念
HDFS英文全稱為:Hadoop Distributed File System,是指被設計成適合運行在通用硬體的分布式檔案系統,它和現有的分布式檔案系統有很多共同點,但同時,它和其他的分布式檔案系統的區別也是很明顯的,HDFS是一個高度容錯性的系統,適合部署在廉價的機器上,HDFS能提供高吞吐量的資料訪問,非常適合大規模資料集上的應用,HDFS放寬了一部分POSIX約束,來實作流式讀取檔案系統資料的目的,HDFS在最開始是作為Apache Nutch搜索引擎專案的基礎架構而開發的,HDFS是Apache Hadoop Core專案的一部分,
這里再強調一下幾個特點,注意看黑板,
超大檔案:可以存放TB到PB級別的資料量,
流式訪問:一次寫入,多次讀取,更加關注所有資料集的查詢時間,
商用硬體:機器都是普通的機器,可以組合起來一起使用,三個臭皮匠頂個諸葛亮,但是單節點故障會較多,所以要有一種機制和方法來迅速恢復業務,
不適合低延時資料:針對的問題和解決方案是高吞吐,所以不適合低延時資料,當然后面會有專門的低延時架構,所以問題出來了總有方案,不要慌,
不支持任意修改: 系統以讀資料為主,支持在文末追加資料,不支持任意修改,
二、架構及組件概念
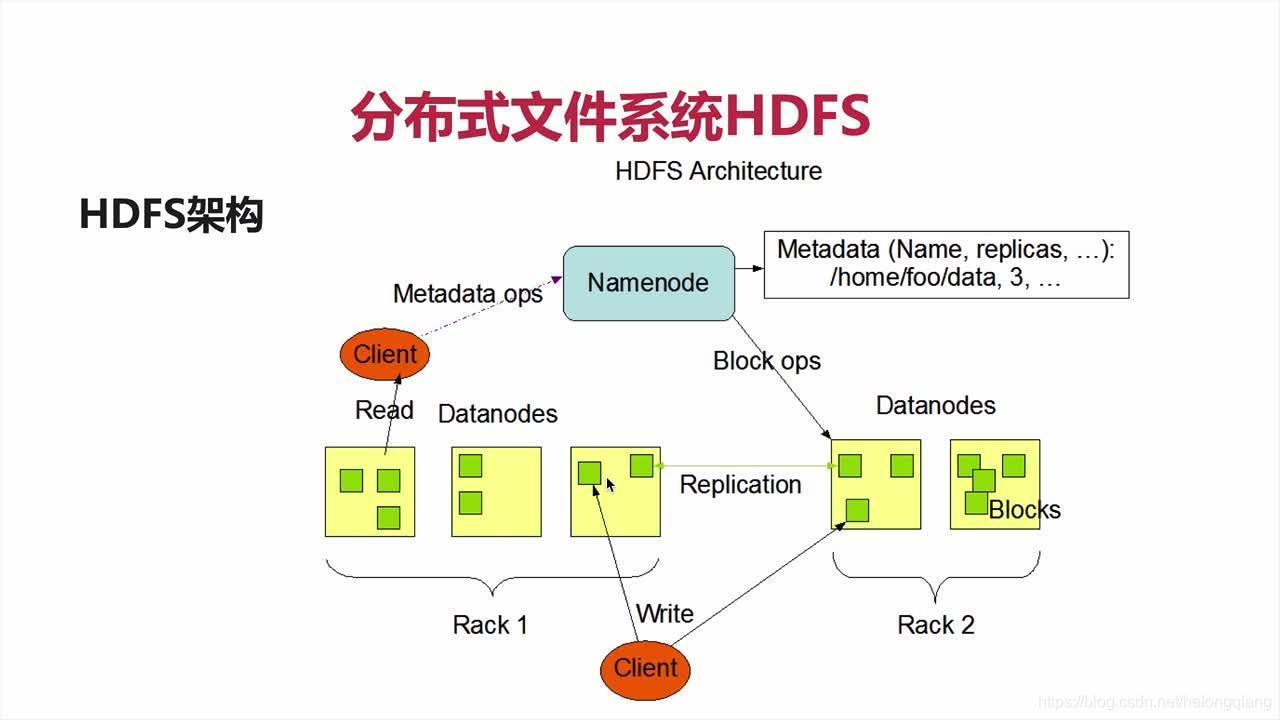
資料塊:默認一個塊(block)的大小為128MB(HDFS的塊這么大主要是為了最小化尋址開銷),要在HDFS中存盤的檔案可以劃分為多個分塊,每個分塊可以成為一個獨立的存盤單元,與本地磁盤不同的是,HDFS中小于一個塊大小的檔案并不會占據整個HDFS資料塊,
NameNode:管理整個檔案系統的元資料,例如管理元資料,維護維護目錄結構、回應客戶端請求,
詳解說明:NameNode作為管理節點,它負責整個檔案系統的命名空間,并且維護著檔案系統樹和整棵樹內所有的檔案和目錄,這些資訊以兩個檔案的形式(命名空間鏡像檔案和編輯日志檔案)永久存盤在NameNode的本地磁盤上,除此之外,同時,NameNode也記錄每個檔案中各個塊所在的資料節點資訊,但是不永久存盤塊的位置資訊,因為塊的資訊可以在系統啟動時重新構建,
DataNode:復制管理用戶的檔案資料塊,例如管理用戶提交的資料 心跳機制 塊報告,
NameNode容錯性:NameNode作為管理節點,它的地位是非同尋常的,一旦NameNode宕機,那么所有檔案都會丟失,因為NameNode是唯一存盤了元資料、檔案與資料塊之間對應關系的節點,所有檔案資訊都保存在這里,NameNode毀壞后無法重建檔案,
第一種機制是備份那些組成檔案系統元資料持久狀態的檔案,比如:將檔案系統的資訊寫入本地磁盤的同時,也寫入一個遠程掛載的網路檔案系統(NFS),這些寫操作實時同步并且保證原子性,
第二種機制是運行一個輔助NameNode,用以保存命名空間鏡像的副本,在NameNode發生故障時啟用,(也可以使用熱備份NameNode代替輔助NameNode),
心跳機制:維護集群的可用性
NameNode啟動的時候,會有一個加載元資料(資料的資料,類似于表的索引)和塊報告(DataNode會定時(可以再組態檔中設定,所以一定要時間同步)對塊資訊進行統計)的程序,NameNode通過心跳機制維護整個集群的可用性,如果塊報告上傳失敗,NameNode不會更新元資料,在塊報告的時候就會將其洗掉掉,
塊快取:資料通常情況下都保存在磁盤,但是對于訪問頻繁的檔案,其對應的資料塊可能被顯式的快取到DataNode的記憶體中,以堆外快取的方式存在,一些計算任務(比如MapReduce)可以在快取了資料的DataNode上運行,利用塊的快取優勢提高讀操作的性能,
高可用性:通過備份NameNode存盤的檔案資訊或者運行輔助NameNode可以防止資料丟失,但是依舊沒有保證了系統的高可用性,一旦NameNode發生了單點失效,那么必須能夠快速的啟動一個擁有檔案系統資訊副本的新NameNode,
這個就是主NameNode與備份的NameNode之間的互動了,
存放策略:默認的HDFS block放置策略在最小化寫開銷和最大化資料可靠性、可用性以及總體讀取帶寬之間進行了一些折中,一般情況下復制因子為3,HDFS的副本放置策略是將第一個副本放在本地節點,將第二個副本放到本地機架上的另外一個節點而將第三個副本放到不同機架上的節點,這種方式減少了機架間的寫流量,從而提高了寫的性能,機架故障的幾率遠小于節點故障,這種方式并不影響資料可靠性和可用性的限制,并且它確實減少了讀操作的網路聚合帶寬,因為檔案塊僅存在兩個不同的機架, 而不是三個,檔案的副本不是均勻地分布在機架當中,1/3在同一個節點上,1/3副本在同一個機架上,另外1/3均勻地分布在其他機架上,這種方式提高了寫的性能,并且不影響資料的可靠性和讀性能,
三、讀寫流程
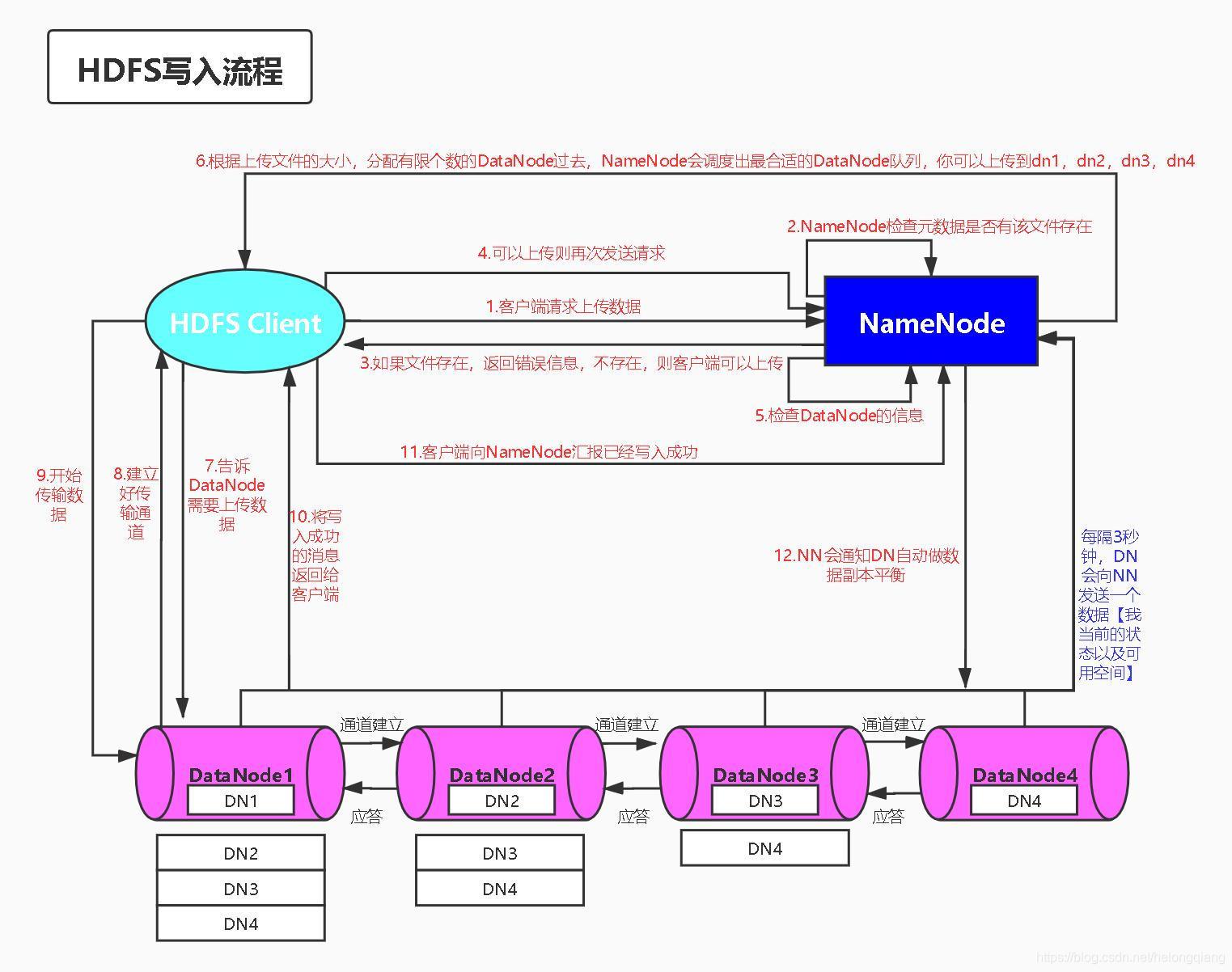
寫資料流程
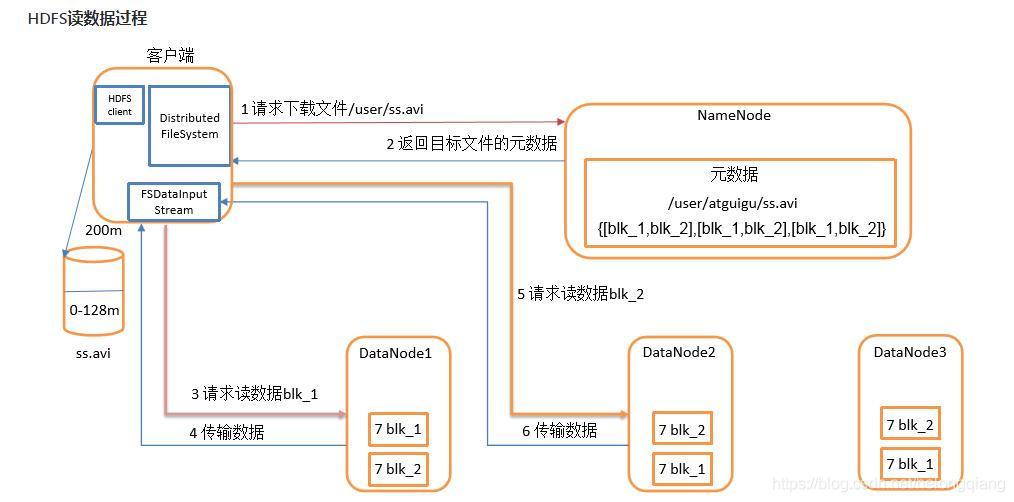
讀資料流程
四、大白話
這個東西就是為了解決資料量大而出來的,其思想是利用多個機器聯合的力量來構造一個龐大的集群,讓作業在各個機器上面運行,然后匯總到一個地方,當然每個機器是比較菜雞的,但是菜雞多了,每個人貢獻一點,整個組織的力量就大了,這個和我們現在組織一樣,有個領導者,就是NameNode,來管理我們的職員DataNode,你今天做了什么作業,寫個日報給我,每天用心跳機制提醒一個,你應該寫日報了,然后他能知道每個職員的情況,當然這里不能嚴格的類比,因為每個職員都不一樣,但是DataNode是一樣的,復制策略就是說,你走了我再招人培養,當然一般的老板不會這樣做,花費人力成本太高了,但是當市場上這樣的人多了之后,其實你就可以隨時被替換了,所以好好學習,天天向上吧,畢竟還有吃飯,我們只有把自己的獨特性弄出來之后,你就成為唯一的,且不能被辭掉的那個人了,
五、其他
下一篇:介紹資料倉庫Hive,
雞湯:今日事,今日畢,
備注:以上資料來自網路,侵刪,
參考資料
https://blog.csdn.net/qq_43755771/article/details/90725393
https://www.cnblogs.com/gzshan/p/10981007.html
來來來,看這里,如果你覺得這篇文章對您有幫助,請關注點贊加收藏,想要了解更多請關注公眾號聯系博主,祝您生活愉快,身心健康!
大資料入門系列文章
1.大資料入門-大資料是什么
2.大資料入門-大資料技術概述(一)
3.大資料入門-大資料技術概述(二)
4.大資料入門-三分鐘讀懂Hadoop
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292905.html
標籤:其他