帶頭雙鏈表
- 前言
- 1、雙鏈表的基本概念
- 2、雙鏈表的好處
- 3、雙鏈表的基本操作
- 頭檔案定義
- 1. 初始化
- 2. 創建一個新結點
- 3. 列印
- 4. 頭插
- 5. 頭刪
- 6. 尾插
- 7. 尾刪
- 8. 查找
- 9. 插入
- 10. 洗掉
- 11. 銷毀
- 總結
| 目錄 | 目錄 |
|---|---|
| 順序表 | 單鏈表(不帶附加頭結點) |
| 雙鏈表(帶附加頭結點) |
今天給大家講的是雙鏈表
前言
- 上一節,我們說到單鏈表,知道了單鏈表的一些缺點和注意事項,這一節我們來學習雙鏈表,看看雙鏈表是否能完美解決單鏈表的一些問題,
1、雙鏈表的基本概念
-
在雙鏈表中有兩個指標域和一個資料域,prev表示前驅指標(左指標),next表示后繼指標(右指標),data資料域,所以雙鏈表至少有三個域:
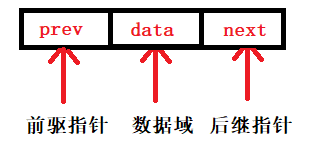
-
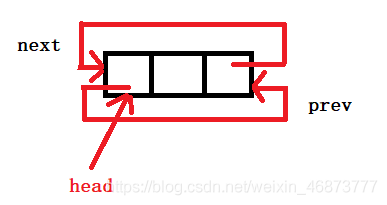
由于雙鏈表通常采用帶附加頭結點的回圈鏈表方式,所以雙鏈表帶有一個附加頭結點,它的data域可以不放資料,也可以存放一個特殊要求的資料,
空表:head->prev = head; head->next = head
非空表:
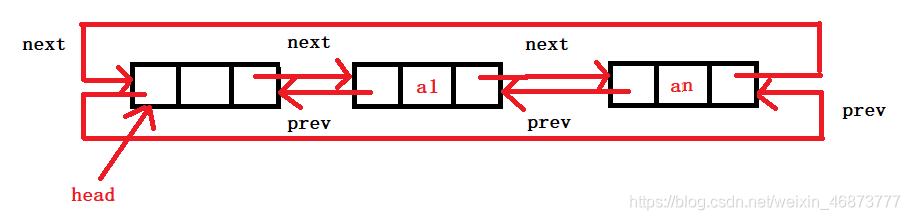
2、雙鏈表的好處
- 雙鏈表可以訪問前驅元素,也可以訪問后繼元素,時間開銷只有o(1)
- 插入洗掉一個結點時,不用在去找他的前驅結點,有前驅指標,直接將指向更改一下即可
3、雙鏈表的基本操作
頭檔案定義
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
// 帶頭+雙向+回圈鏈表增刪查改實作
typedef int LTDataType;//type的人重命名int為LTDataType
typedef struct ListNode
{
LTDataType data;//資料域
struct ListNode* next;//后繼指標
struct ListNode* prev;//前驅指標
}ListNode;
1. 初始化
- 這里可以封裝成BuyListNode函式去創建一個結點,也可以自己在初始化函式里面創建結點,
ListNode* ListCreate()
{
//ListNode* phead = (ListNode*)malloc(sizeof(ListNode));
ListNode* phead = BuyListNode(0);
/*if (phead == NULL)
{
perror("ListCreate:");
exit(-1);
}*/
phead->next = phead;//看上面畫的空表圖,指向自己即為空
phead->prev = phead;//同上
return phead;
}
2. 創建一個新結點
- 封裝成一個函式,為創建結點提供方便,
ListNode* BuyListNode(LTDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)//檢查記憶體是否分配成功
{
perror("ListCreate:");
exit(-1);
}
newnode->next = NULL;//后繼指標置空
newnode->prev = NULL;//前驅指標置空
newnode->data = x;//值為x
return newnode;
}
3. 列印
- 雙鏈表列印,定義 cur為第一個結點,注意結束條件不是 cur != NULL,而是 cur != head,到head才表示遍歷完一次!!!
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* head = pHead;
ListNode* cur = head->next;//第一個結點
while (cur != head)//等于頭指標,才表示一次遍歷完
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
4. 頭插
- 創建新結點,設定第一個結點,將頭指標和第一個結點的指向變化,
- 學了雙鏈表,我們應該看得出來,頭插可以呼叫插入的演算法,
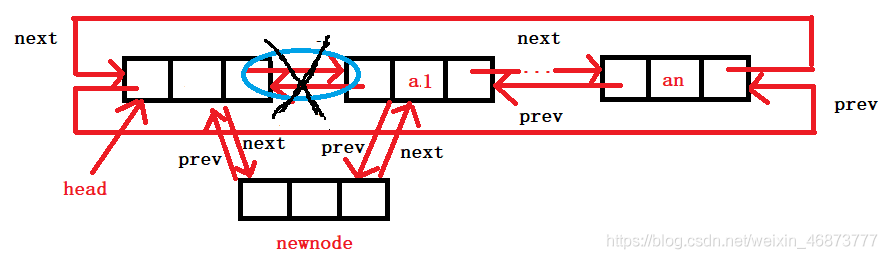
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
//ListInsert(pHead->next, x);//因為是在pos結點之前插入,這里可以復用插入演算法
ListNode* head = pHead;
ListNode* cur = head->next;//第一個結點
ListNode* newnode = BuyListNode(x);//創建新結點
head->next = newnode;//設定新結點為頭指標的下一個結點
newnode->prev = head;//新結點的前驅指標為頭指標
newnode->next = cur;//新結點的下一個結點為原來的第一個結點
cur->prev = newnode;//原來的第一個結點的前驅指標為新結點
}
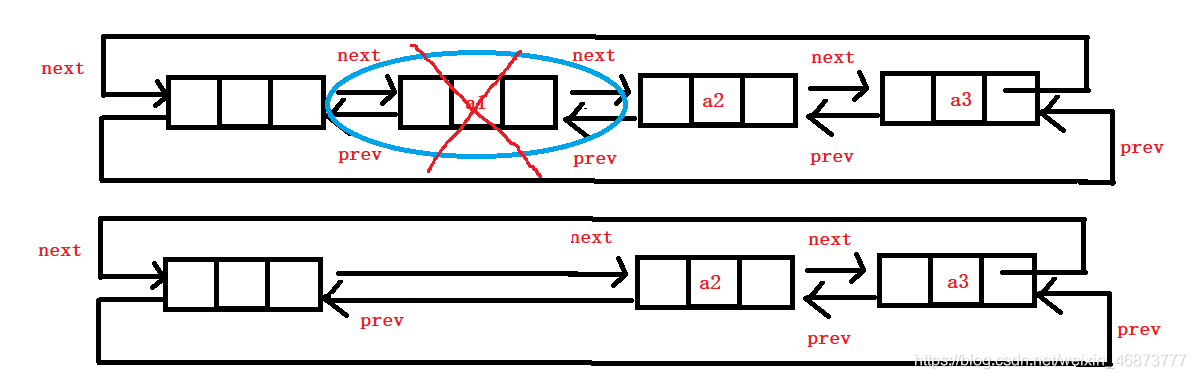
5. 頭刪
- 頭刪就比較簡單,直接將頭指標的后繼指標指向第二個結點,第二個結點的前驅指標指向頭指標即可,這里用第一個結點作為中間結點,
- 頭刪可以復用洗掉演算法,
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!(pHead->next == pHead));//還需要檢查是否為空,為空洗掉失敗
//ListErase(pHead->next);//可以復用洗掉演算法
ListNode* head = pHead;//head為頭指標
ListNode* cur = head->next;//需要洗掉的頭結點
ListNode* next = cur->next;//第二個結點
free(cur);//釋放第一個結點
cur = NULL;//置空,防止變成野指標
head->next = next;//頭指標的后繼指標指向第二個結點
next->prev = head;//第二個結點的前驅指標指向頭指標
}
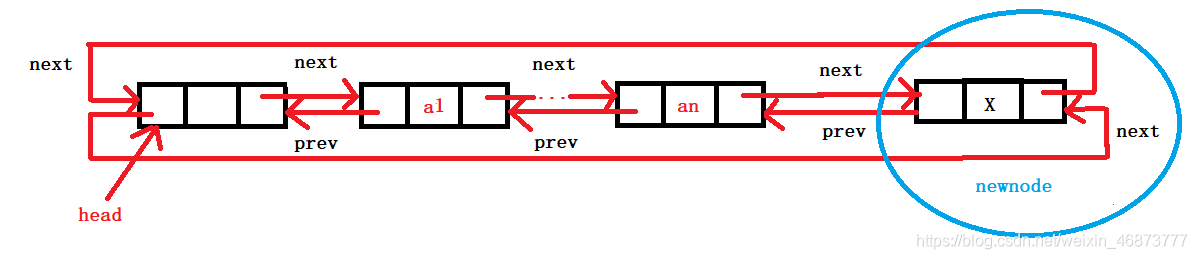
6. 尾插
- 將頭指標和尾結點的前驅指標和后繼指標的指向變化即可,
- 尾插可以復用插入演算法,
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
//ListInsert(pHead, x);//可以復用插入演算法
ListNode* head = pHead;//頭指標
ListNode* newnode = BuyListNode(x);//創建新結點
ListNode* cur = head->prev;//尾結點
cur->next = newnode;//尾結點指向新結點
newnode->prev = cur;//尾結點的前驅指標指向尾結點
head->prev = newnode;//頭指標的前驅指標指向新結點
newnode->next = head;//新結作為尾結點指向頭指標
}
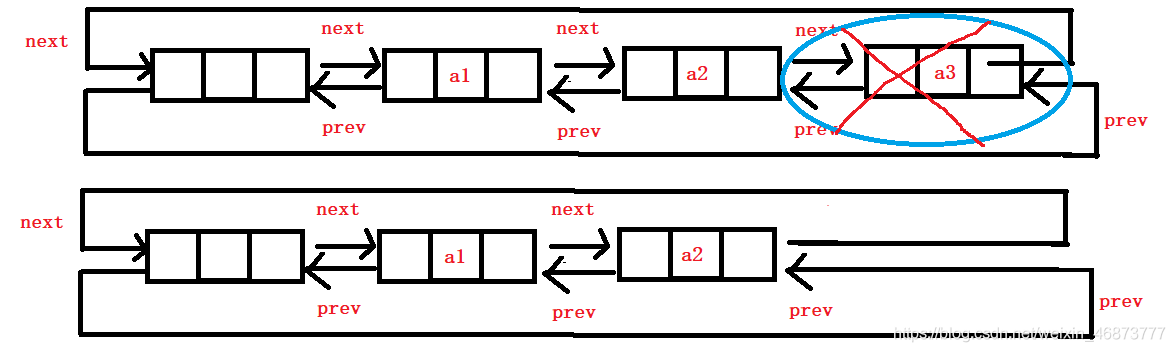
7. 尾刪
- 將頭指標指向倒數第二個結點介面,
- 尾刪可以復用洗掉演算法,
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!(pHead->next==pHead));//還需要檢查是否為空,為空洗掉失敗
//ListErase(pHead->prev);//可以復用洗掉演算法
ListNode* head = pHead;//頭指標
ListNode* tail = head->prev;//尾結點
ListNode* newtail = tail->prev;//倒數第二個結點
free(tail);//這里記住還要釋放,防止記憶體泄漏
tail = NULL;//置空,防止變成野指標
newtail->next = head;//倒數第二個結點指向頭指標,成為尾結點
head->prev = newtail;//頭指標指向倒數第二個結點
}
8. 查找
- 查找跟單鏈表的查找方法是一樣的,找到回傳該結點,未找到回傳NULL
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* head = pHead;//頭指標
ListNode* cur = head->next;//第一個結點
while (cur != head)//條件是不等于頭指標
{
if (cur->data == x)//找到回傳該結點
return cur;
cur = cur->next;//迭代
}
return NULL;//未找到回傳NULL
}
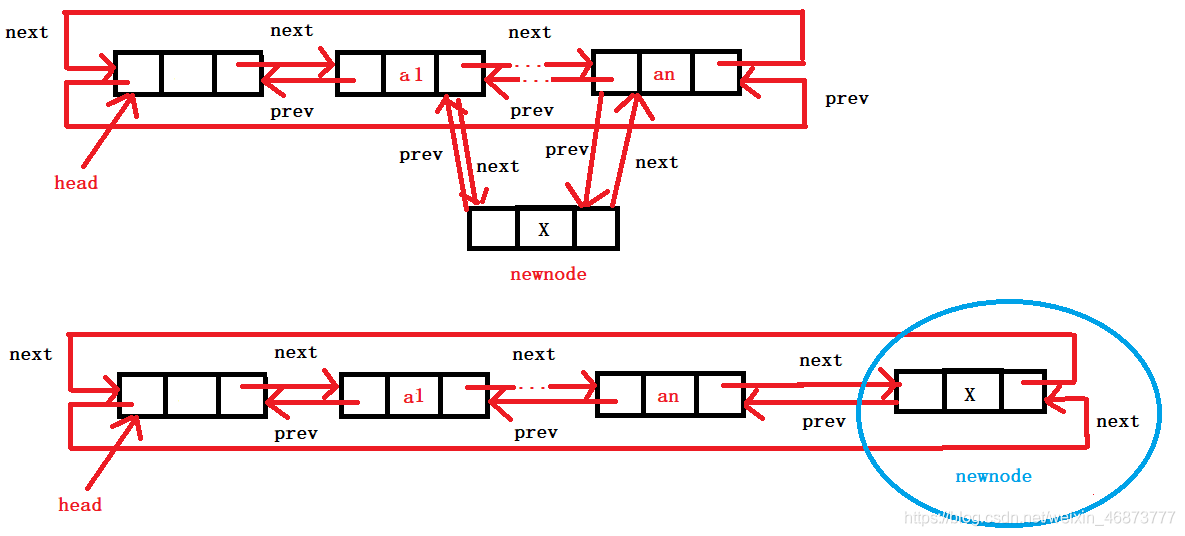
9. 插入
- 插入有三種插入的點,頭插,尾插,還有在中間結點插入
- 演算法是一樣的,自己注意前驅指標和后繼指標的變化即可
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* cur = pos;//在pos結點前插入
ListNode* prev = cur->prev;//pos的前一個結點
ListNode* newnode = BuyListNode(x);//創建新結點
newnode->prev= prev;//新結點的前驅指標指向pos的前一個結點
prev->next = newnode;//pos的前一個結點指向新結點
newnode->next = cur;//新結點指向pos結點
cur->prev = newnode;//pos結點的前驅指標指向新結點
}
10. 洗掉
- 洗掉跟插入是一樣的,也有頭刪,尾刪,洗掉中間結點
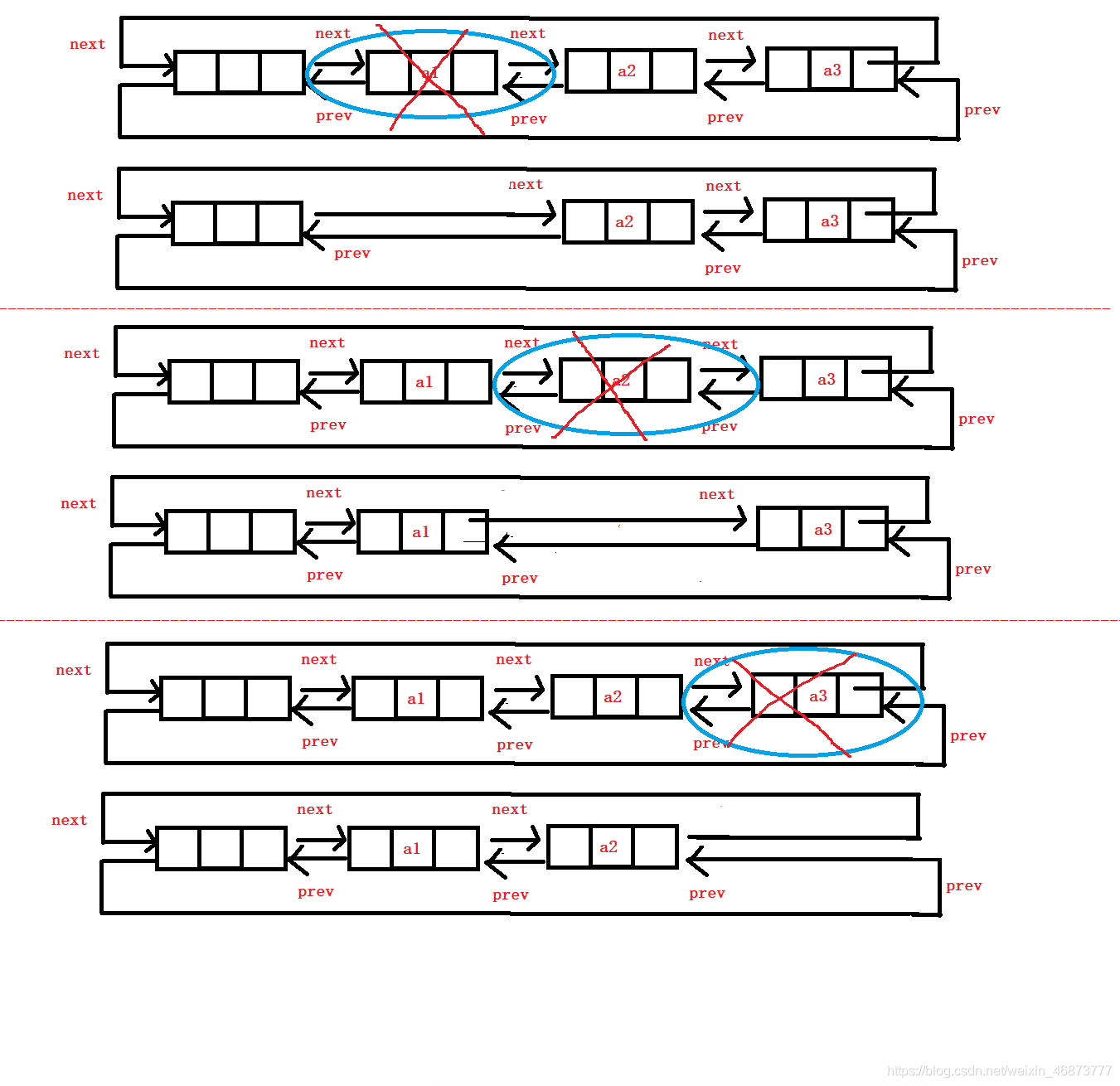
```c
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* cur = pos;//查找的結點
ListNode* prev = cur->prev;//pos的前一個結點
ListNode* next = cur->next;//pos的后一個結點
free(cur);//釋放,防止記憶體泄漏
cur = NULL;//置空,防止變成野指標
prev->next = next;//pos的前一個結點指向pos的后一個結點
next->prev = prev;//pos的后一個結點指向pos的前一個結點
}
11. 銷毀
- 讓cur作為第一個結點,迭代一個一個洗掉即可,記得釋放記憶體,防止記憶體泄漏
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->next;//第一個結點
while (cur != pHead)//不等于頭指標,才進行回圈
{
ListNode* next = cur->next;//迭代結點
free(cur);//釋放,防止記憶體泄漏
cur = next;//迭代
}
free(pHead);//防止記憶體泄漏
pHead = NULL;//置空,防止變成野指標
}
總結
- 細心的小伙伴可以發現,頭插、頭刪、尾插、尾刪,都可以復用插入、洗掉演算法,
- 正式因為有了前驅指標,整個演算法才比較容易,所以利用雙鏈表去查找,插入,洗掉某個結點是非常容易的,但是也要注意指標的指向,不要誤用!!!
還有其他的點需要讀者自己去看書領悟,作者在這里就不多解釋了,只有自己敲得多,題做的多才會慢慢領悟!!!

創作不易,記得三連!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292948.html
標籤:其他