鏈表
- 前言
- 一、單鏈表
- 1.單鏈表的結構
- 2.單鏈表的基本介面
- 1.我們先講講單鏈表的頭插
- 2.單鏈表的尾插
- 3.單鏈表的頭刪
- 4.單鏈表的尾刪
- 5.單鏈表的查找
- 6.單鏈表的洗掉
- 6.單鏈表所有代碼鏈接
- 一、帶頭回圈雙向鏈表
- 1.結構
- 2.帶頭回圈雙向鏈表的基本介面
- 1.帶頭回圈雙向鏈表的初始化
- 2.帶頭回圈雙向鏈表的查找
- 3.帶頭回圈雙向鏈表的任意位置插入
- 4.帶頭回圈雙向鏈表的頭插,尾插
- 5.帶頭回圈雙向鏈表的任意位置洗掉
- 6.帶頭回圈雙向鏈表的頭刪,尾刪
- 7.帶頭回圈雙向鏈表的全部代碼
- 總結
前言
鏈表的概念:鏈表是一種物理存盤結構上非連續、非順序的存盤結構,資料元素的邏輯順序是通過鏈表中的指標鏈接次序實作的,
鏈表的結構也有8種之多,分別是單向或者多向,帶頭或者不帶頭,
回圈或者非回圈,這里我們重點講的是單鏈表的結構和帶頭回圈雙向鏈表的結構,會了這兩種,其他的其實也只是小菜一碟!
學習原因:單鏈表作為圖的鄰接表,哈希桶等結構的子結構,而帶頭回圈雙向鏈表,這個結構雖然復雜,但是實作后在很多方便都很便利,我們下面會敘述,這篇文章主要介紹這兩種結構,下一篇會對鏈表的難點進行詳細敘述,
一、單鏈表
單鏈表對于中間/頭部插入洗掉比較遍歷,而且每次增容都是開一個空間,現開現用,不會浪費記憶體空間但是在能用鏈表和順序表的結構,我們優先還是使用順序表的結構,因為順序表隨機訪問率比較高
1.單鏈表的結構
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;
這里的SLTDateType表示鏈表當中存盤的資料型別,在代碼多的時候,我們修改這里就可以實作通用了,結構體當中存放的三個元素,struct SListNode* next表示下個元素的地址,data存放的就是當前元素的值
2.單鏈表的基本介面
// 動態申請一個節點
SListNode* BuySListNode(SLTDateType x);
// 單鏈表列印
void SListPrint(SListNode* plist);
// 單鏈表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 單鏈表的頭插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 單鏈表的尾刪
void SListPopBack(SListNode** pplist);
// 單鏈表頭刪
void SListPopFront(SListNode** pplist);
// 單鏈表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
// 單鏈表在pos位置之后插入x
// 分析思考為什么不在pos位置之前插入?
//答案,要遍歷一遍找到前一個,效率太低了
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 單鏈表洗掉pos位置之后的值
// 分析思考為什么不洗掉pos位置?
//答案:洗掉pos位置也要有pos位置的前一個
void SListEraseAfter(SListNode* pos);
// 單鏈表的銷毀
void SListDestory(SListNode** plist);
1.我們先講講單鏈表的頭插
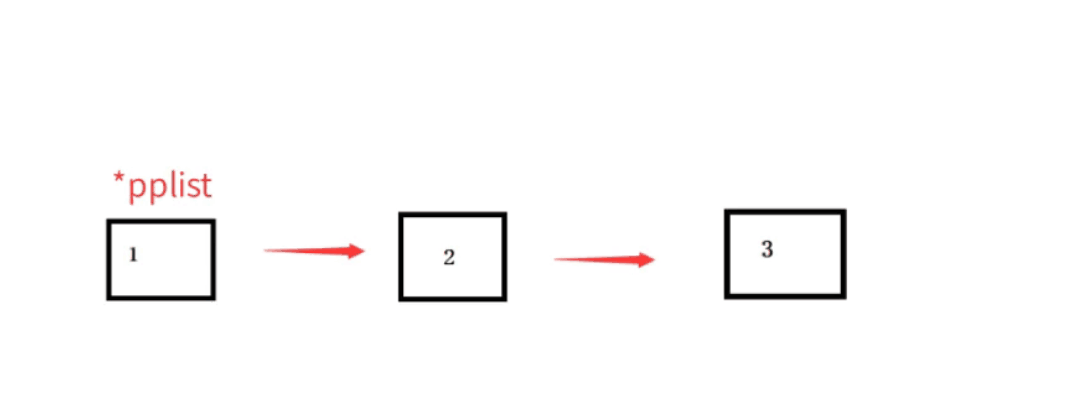
一開始我們在test函式可以創建一個SListNode* sl =NULL,表示有個單鏈表的sl的指標指向NULL,那我們就可以開始插入,這里先講講頭插,單鏈表的好處得益于相比順序表而言頭部的插入不用移動資料!!
動圖:圖中的pphead為二級指標
從圖就可以看出,當我們沒有結點的時候,3這個結點的出現就要成為我們鏈表的頭,而newnode的出現便要將頭指向我們的2結點,這里有個重要的地方:test函式在呼叫我們的SListPushFront頭插需要二級指標,為什么呢?
打個比方,我們大家都有寫過兩個數的交換,想要交換兩個數就要傳這兩個數的地址,而我們現在從函式內部改變外部指標的指向,也就是改變它的值,所以這時我們也需要傳指標的地址!!!!
SListNode* BuySListNode(SLTDateType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
printf("申請失敗\n");
exit(-1);
}
newnode->next = NULL;
newnode->data = x;
return newnode;
}
因為這個創建結點的邏輯很多地方都用,我們單獨弄成介面,讓其他地方復用
void SListPushFront(SListNode** pplist, SLTDateType x)
{
//頭插在這里會改變頭節點的指向,要外面拿到也要二級指標
assert(pplist);
if (*pplist == NULL)//這里也要考慮這個問題(其實也可以不考慮),空鏈表就要給他創建
{
SListNode* newnode = BuySListNode(x);
*pplist = newnode;
}
else
{
SListNode* newnode = BuySListNode(x);
newnode->next = *pplist;
*pplist = newnode;
}
//這個地方也可以合并成一個邏輯,將else當中的邏輯拿來用就可以了,如下:
/*assert(pplist);
SListNode* newnode = BuySListNode(x);
newnode->next = *pplist;
*pplist = newnode;*/
}
這里對代碼進行解釋,assert斷言pplist是因為如果我們這里如果傳過來的指標的地址是NULL的話,就報錯,因為即使指標是NULL,但他的地址也一定不會是NULL,再看if (*pplist == NULL),代碼內部用到了解參考,所以也一定不能是NULL指標,斷言方便我們后續查錯
2.單鏈表的尾插
動圖:圖中的pphead為二級指標

尾插的邏輯相對頭插來說只有一個地方需要注意,就是當我們SListNode* sl =NULL的時候我們需要通過二級指標(同理上面)來改變外面的指向,sl當有已經指向有效結點的時候,我們只需要去遍歷找到尾,在尾部插入
void SListPushBack(SListNode** pplist, SLTDateType x)
{
assert(pplist);//檢測指標的地址是否為空
//情況一就是傳過來的是NULL,這時我們要改變他的頭,并且外面要拿到,所以這個地方只能用二級指標,用回傳的方式也可以,但是要用外面的頭指標接受
if (*pplist == NULL)
{
SListNode *newnode= BuySListNode(x);
*pplist = newnode;
}
else
{
SListNode* cur = *pplist;
while (cur->next)
{
cur = cur->next;
}
SListNode* newnode = BuySListNode(x);
cur->next = newnode;
}
}
其中的if邏輯就是要改變外面指標的指向,else就是在尾部上的插入
3.單鏈表的頭刪
單鏈表的頭刪需要注意什么呢,當只有一個元素的時候,我們應當也把傳進來的指標置成NULL,所以這里也不得不傳二級指標,當然用回傳值的方式也可以解決,但是這里使用二級指標更加恰當,在能夠完善我們的功能的情況下,我們才繼續追求介面的一致性
動圖:
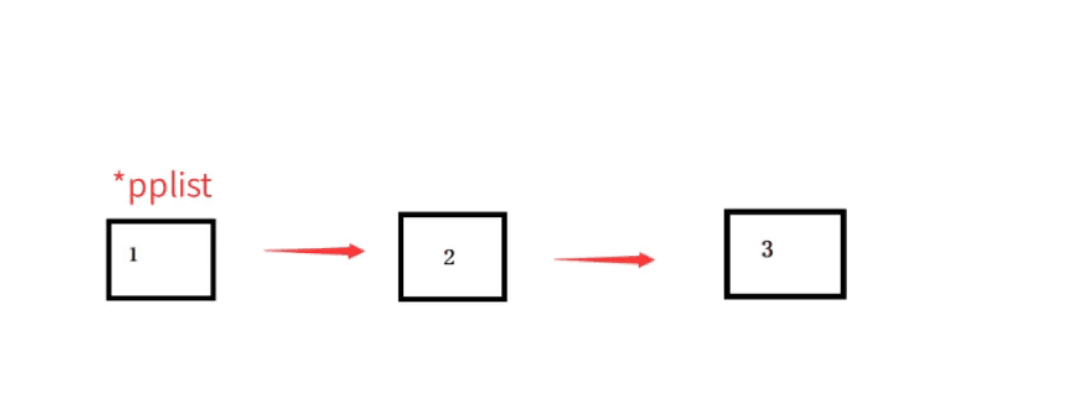
頭刪根據影片也可以看出頭刪每次都要跟新頭節點,并且當只剩下一個節點的時候要將外面的頭節點也置成NULL,所以我們這里也要用二級指標傳參
void SListPopFront(SListNode** pplist)
{
assert(pplist);
assert(*pplist);
SListNode* cur = (*pplist)->next;//保留下一個結點
free(*pplist);
*pplist = NULL;
*pplist = cur;
}
實作起來也相對容易,只需要每次保存下一個節點的地址,然后迭代往后面走就可以了
4.單鏈表的尾刪
尾刪的時候每次都要找到尾結點和尾結點的前一個指標,所以當我們只有一個節點的時候就可以free掉頭結點,把指標也置成NULL就可以了,所以這里也要用二級指標,當沒有節點的時候我們就用assert報錯
動圖: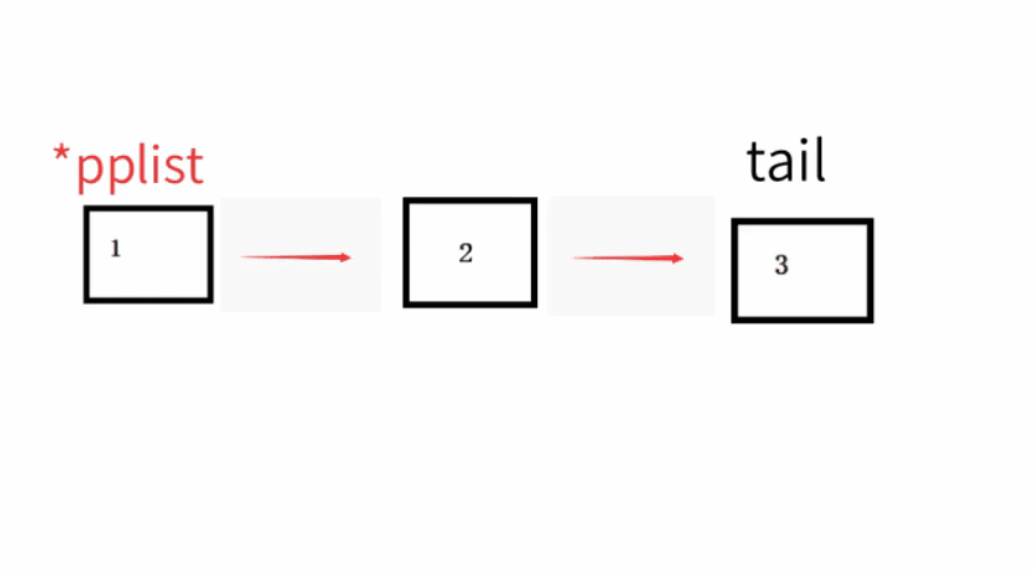
void SListPopBack(SListNode** pplist)
{
assert(pplist);
assert(*pplist);
//洗掉的時候若是空鏈表,我們這邊就報錯
//尾刪的時候有可能洗掉頭結點,所以用二級指標
SListNode* cur = *pplist;
SListNode* prev = NULL;
while (cur->next)
{
prev = cur;
cur = cur->next;
}
//情況一:洗掉的頭節點
if (cur == *pplist)
{
free(*pplist);
*pplist = NULL;
}
else
{
//在這里要注意還要處理prev的next指標!!
free(cur);
cur = NULL;
prev->next = NULL;
}
}
代碼的邏輯也是先去判斷是否傳進來的是空指標,并且鏈表為NULL的時候我們也直接報錯,因為在c++list庫當中也是這樣子處理的,我們這里也借鑒學習,
5.單鏈表的查找
單鏈表的查找其實就是去遍歷一遍鏈表,找到就回傳結點的地址
SListNode* SListFind(SListNode* plist, SLTDateType x)
{
//這里不用斷言是因為plist可以是NULL指標,是外面頭節點的一個臨時拷貝
SListNode* cur = plist;
while (cur->next)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}
即找的到回傳結點地址,找不到回傳NULL
列印鏈表也是相同邏輯,當我們要修改單鏈表,拿到結點就可以直接操作了!!!
void SListPrint(SListNode* plist)
{
SListNode* cur = plist;
while (cur)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
6.單鏈表的洗掉
單鏈表的洗掉通常配合單鏈表的查找進行使用,并且通常是洗掉該節點的下一個結點,因為要洗掉當前結點需要找到上一個節點的位置,這樣就需要在遍歷一次,時間復雜度就高了,要洗掉當前位置我們會使用雙向鏈表的結構,下文會講到帶頭回圈的雙向鏈表結構!
void SListEraseAfter(SListNode* pos)
{
assert(pos);
assert(pos->next);
SListNode* nextnext = pos->next->next;
SListNode* next = pos->next;
//free(pos->next);
//pos->next = null;這種寫法是錯誤的,next并沒有置成NULL
free(next);
next = NULL;
pos->next = nextnext;
}
這里的保存下下個結點,洗掉該節點的下一個結點,并且將當前結點與下下個結點相連,并且只有一個結點的時候我們就報錯,動圖如下:
6.單鏈表所有代碼鏈接
單鏈表
一、帶頭回圈雙向鏈表
1.結構
// 帶頭+雙向+回圈鏈表增刪查改實作
typedef int LTDataType;
typedef struct ListNode
{
LTDataType _data;
struct ListNode* _next;
struct ListNode* _prev;
}ListNode;
對于帶頭回圈雙向鏈表,有個指標指向后一個結點,一個指向前一個結點,還有一個是存放的值
常見介面:
void ListInit(ListNode** ppHead);
// 創建回傳鏈表的頭結點.
ListNode* ListCreate(LTDataType x);
// 雙向鏈表銷毀
void ListDestory(ListNode* pHead);
// 雙向鏈表列印
void ListPrint(ListNode* pHead);
// 雙向鏈表尾插
void ListPushBack(ListNode* pHead, LTDataType x);
// 雙向鏈表尾刪
void ListPopBack(ListNode* pHead);
// 雙向鏈表頭插
void ListPushFront(ListNode* pHead, LTDataType x);
// 雙向鏈表頭刪
void ListPopFront(ListNode* pHead);
// 雙向鏈表查找
ListNode* ListFind(ListNode* pHead, LTDataType x);
// 雙向鏈表在pos的前面進行插入
void ListInsert(ListNode* pos, LTDataType x);
// 雙向鏈表洗掉pos位置的節點
void ListErase(ListNode* pos);
bool isEmpty(ListNode* pos);
2.帶頭回圈雙向鏈表的基本介面
1.帶頭回圈雙向鏈表的初始化
初始化時我們應該要創一個結點,讓節點的前指標和后指標都指向自己
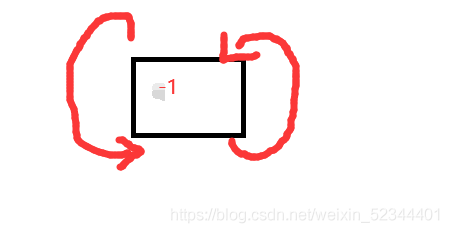
void ListInit(ListNode** ppHead)
{
assert(ppHead);
assert(*ppHead);
//這里malloc會回傳一個堆上的地址,所以要用二級指標接受
ListNode*newnode = ListCreate(-1);
if (newnode)
{
*ppHead = newnode;
(*ppHead)->_data = -1;
(*ppHead)->_next = *ppHead;
(*ppHead)->_prev = *ppHead;
}
else
printf("初始化失敗\n");
}
2.帶頭回圈雙向鏈表的查找
這個邏輯跟單鏈表的查找一摸一樣,就是要控制結束的標志我們用cur表示第一個結點,cur == phead的時候我們就完成了遍歷,同理列印鏈表
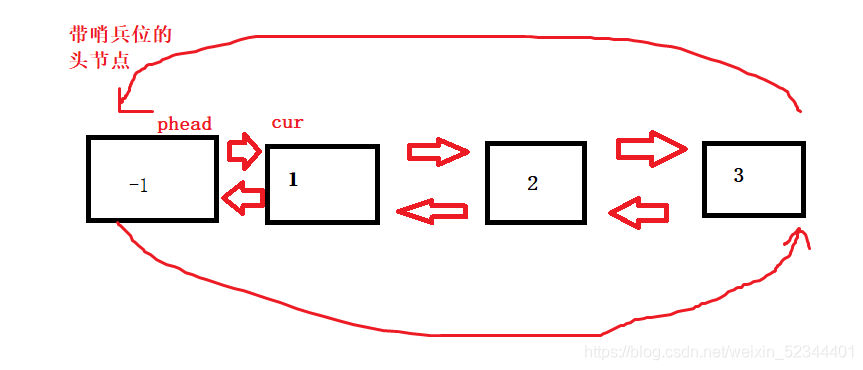
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->_next;
while(cur != pHead)
{
if (cur->_data == x)
return cur;
cur = cur->_next;
}
return NULL;
}
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
printf("%d ", cur->_data);
cur = cur->_next;
}
printf("\n");
}
3.帶頭回圈雙向鏈表的任意位置插入
我們在很多地方都會用到創建一個結點的邏輯,所以我們把他獨立出來
ListNode* ListCreate(LTDataType x)//創建一個結點
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
newnode->_data = x;
newnode->_next = newnode->_prev = NULL;
return newnode;
}
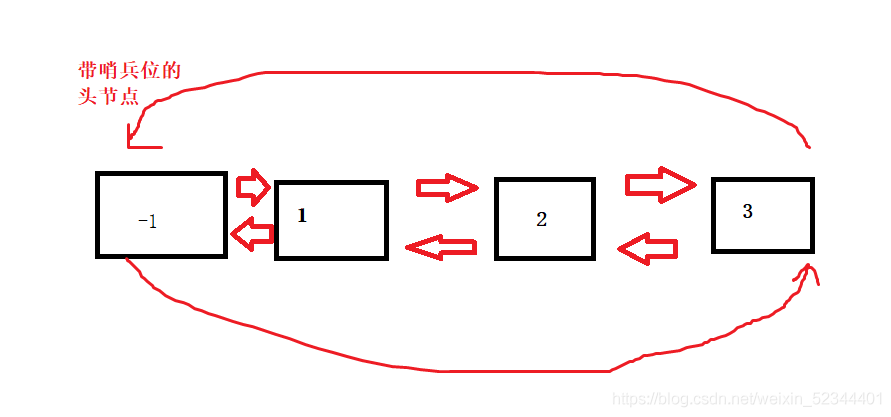
與單鏈表不同,帶頭回圈雙向鏈表是一種使用起來非常遍歷的結構,找到我們要插入的pos位置,記錄上一個結點(相比單鏈表不需要遍歷一遍鏈表)
就可以進行鏈接
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* prev = pos->_prev;
ListNode* newnode = ListCreate(x);
prev->_next = newnode;
newnode->_prev = prev;
pos->_prev = newnode;
newnode->_next = pos;
}
4.帶頭回圈雙向鏈表的頭插,尾插
這些邏輯都可以復用ListInsert的邏輯
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListInsert(pHead, x);
}
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListInsert(pHead->_next, x);
}
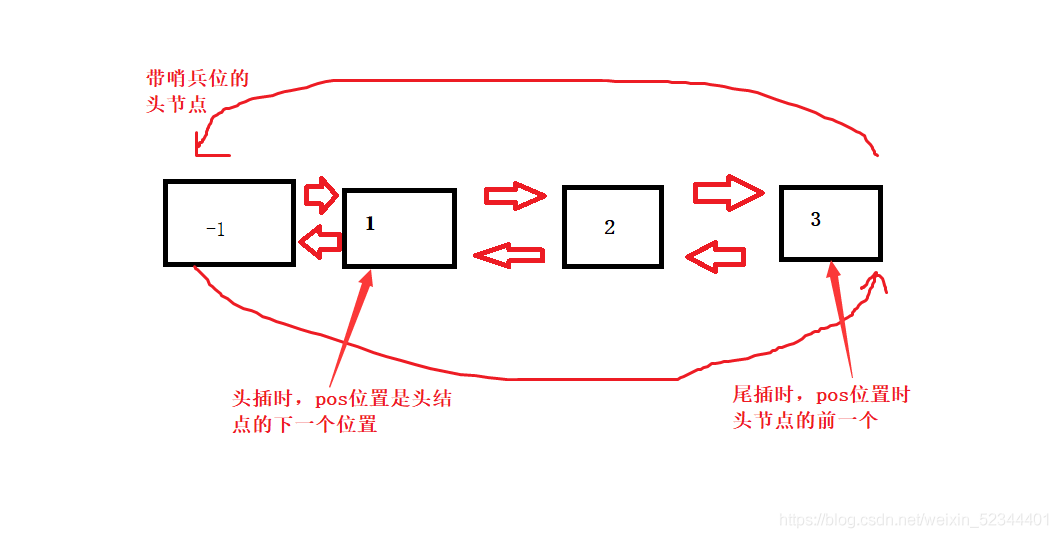
5.帶頭回圈雙向鏈表的任意位置洗掉
洗掉資料時我們需要判斷是否有有效資料,如果沒有的話我們直接報錯處理,代碼和圖結合觀看
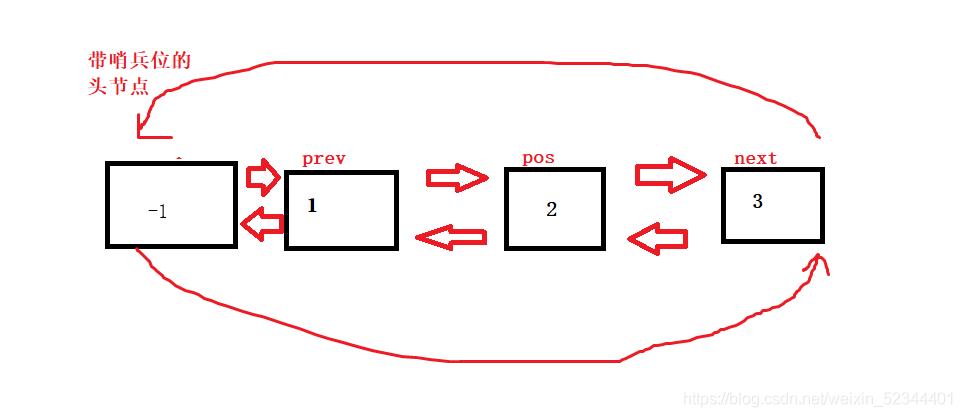
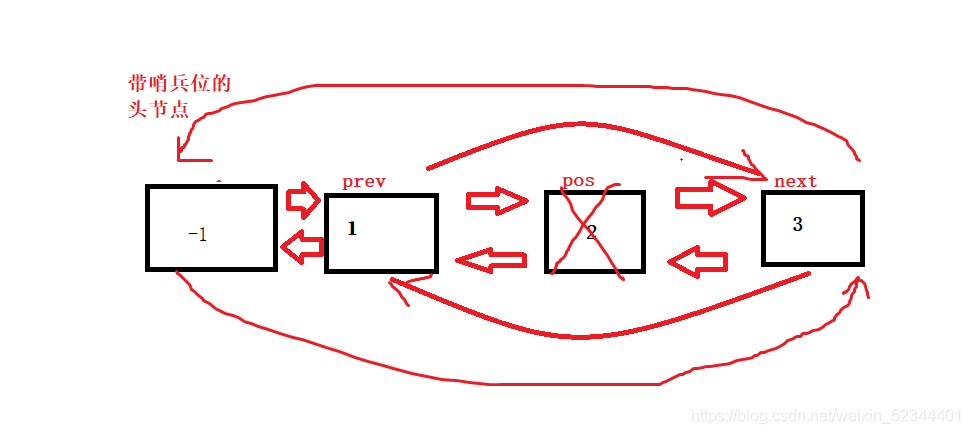
void ListErase(ListNode* pos)
{
assert(pos);
assert(!isEmpty(pos));
ListNode* prev = pos->_prev;
ListNode* next = pos->_next;
free(pos);
pos = NULL;
prev->_next = next;
next->_prev = prev;
}
6.帶頭回圈雙向鏈表的頭刪,尾刪
我們這里就可以復用ListErase的邏輯了
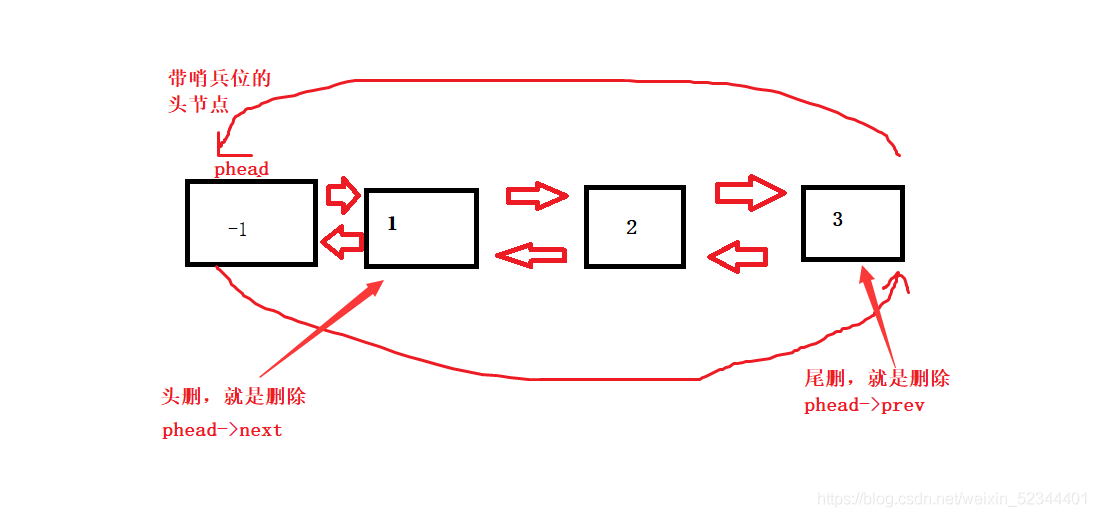
void ListPopFront(ListNode* pHead)
{
ListErase(pHead->_next);
}
void ListPopBack(ListNode* pHead)
{
ListErase(pHead->_prev);
}
簡簡單單的兩段代碼,這就是這種結構的好處,很多地方都能實作復用!!
7.帶頭回圈雙向鏈表的全部代碼
帶頭回圈雙向鏈表
總結
到此,我們就完成了鏈表的兩種實作方式,下一個博客就講講鏈表的帶環和回圈佇列的實作,看到這里不妨給個一鍵三連把!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292950.html
標籤:其他